

Привет, меня зовут Сергей — я руководитель DevOps-направления KTS.
Мы в компании периодически партнёримся с интересными ребятами и вместе организуем мероприятия: встреча предпринимателей, онлайн-квартирник, День продакт-менеджмента. Этот цикл из трёх статей — текстовая версия выступления со Дня Техдира. Выступление было подготовлено совместно с Southbridge и у него два автора:

Сергей Маленко
руководитель DevOps-юнита KTS

Сергей Бондарев
архитектор Southbridge
Доклад был посвящён истории развития деплоя приложений, основным моделям и их сравнению. Мы достаточно детально пройдёмся по Pull-модели и покажем, как с помощью «передовых» инструментов организовать управление инфраструктурой больших проектов и дать возможность разработчикам самостоятельно заказывать элементы в инфраструктуре под нужды своих приложений.
Всего на основе доклада мы подготовили три статьи, которые пойдут по порядку:
Как было и развивалось ← вы здесь ????
для понимания контекста рассмотрим, как итеративно изменялся подход к развёртыванию приложенийЧто такое ArgoCD и зачем он нужен, с примерами использования
рассмотрим относительно новый виток в развитии деплоя приложений, посмотрим, какие вопросы можно закрыть с помощью этого инструментаКак управлять инфраструктурой в GitOps с помощью Crossplane
новый подход к IaC и как его можно объединить с ArgoCD
В этой части, подготовленной Сергеем Бондаревым, мы расскажем, как программисты работали раньше:
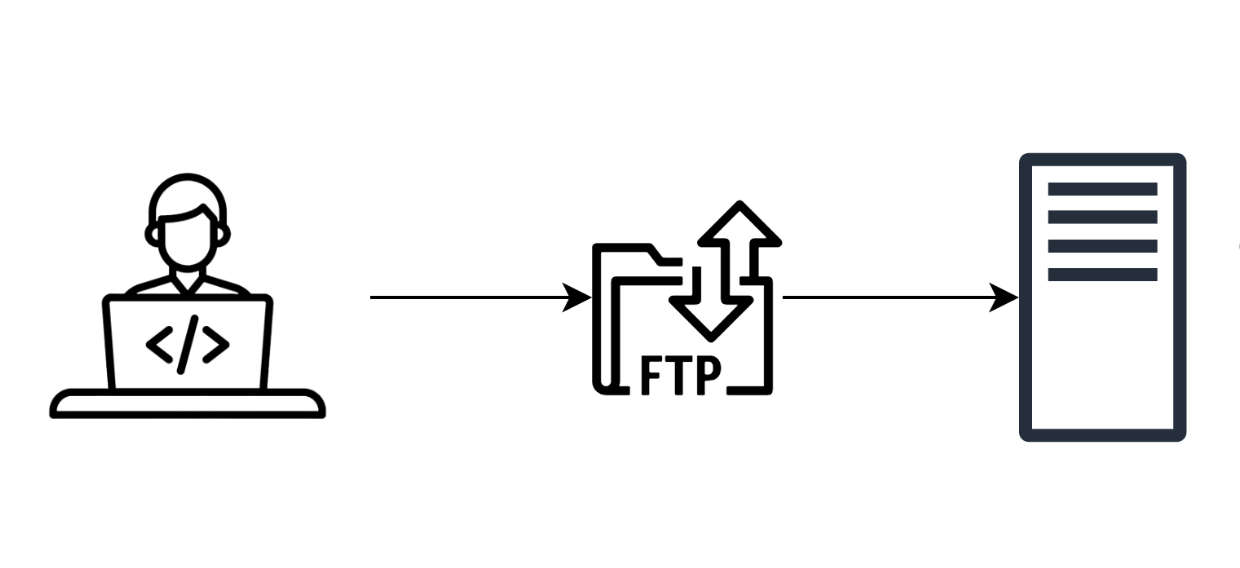
Протокол FTP
FTP — старый протокол для передачи файлов по сети. Появился он в 1971 году задолго до HTTP и даже до TCP/IP. Программисты писали код на компьютере, потом по FTP выкладывали его на сервер и получали сайт. Сильные программисты писали код прямо на сервере. Обычно, на продакшене:
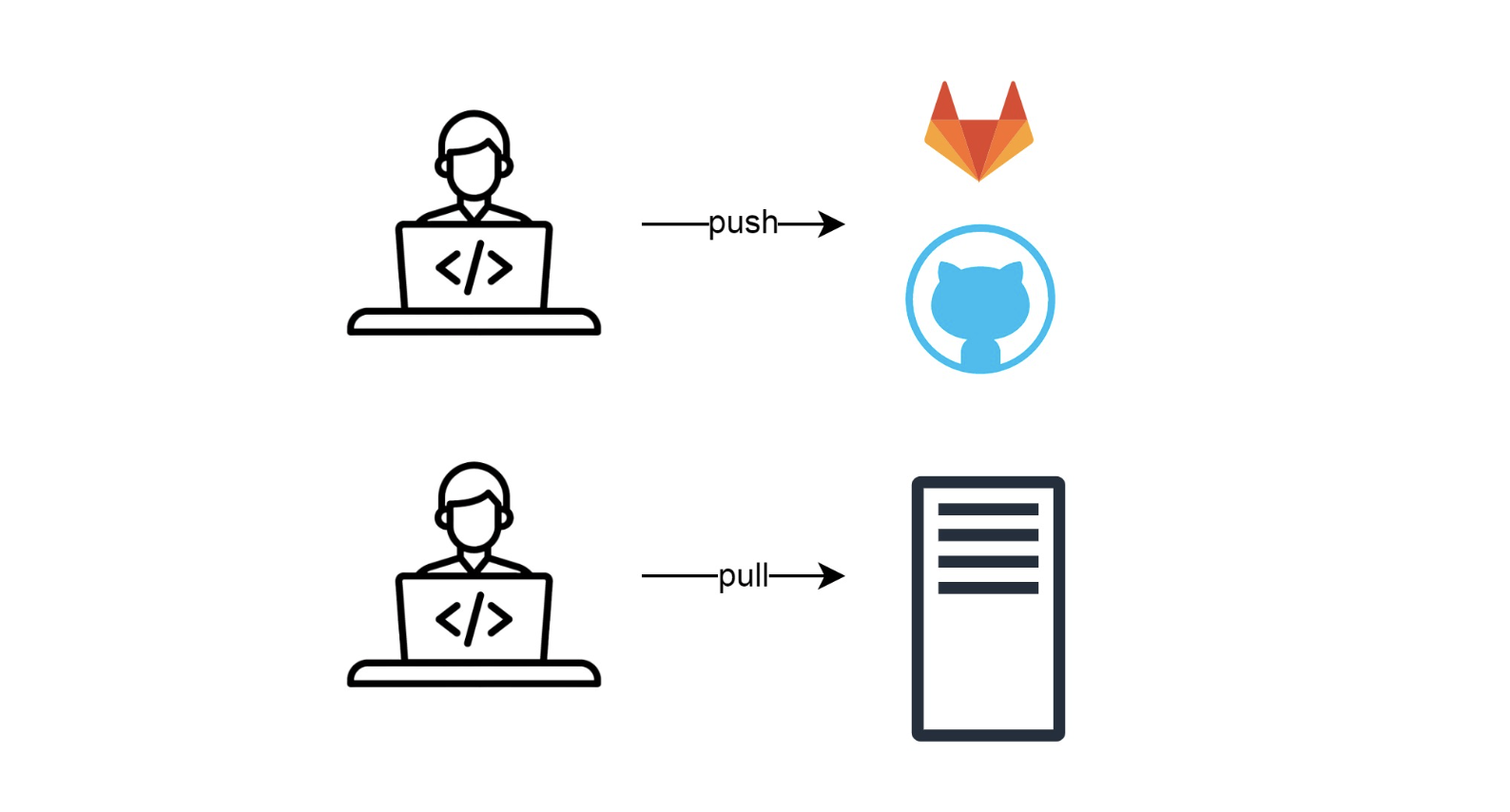
GIT
Когда кода стало больше, придумали Git — место, где код хранится.
Программист пишет код на своей машине и отправляет его в Git через Github/Gitlab. Потом подключается к серверу, выполняет там команду git pull, получает весь код, который сохранил в хранилище, перезапускает сервисы и production-стенд обновляется:
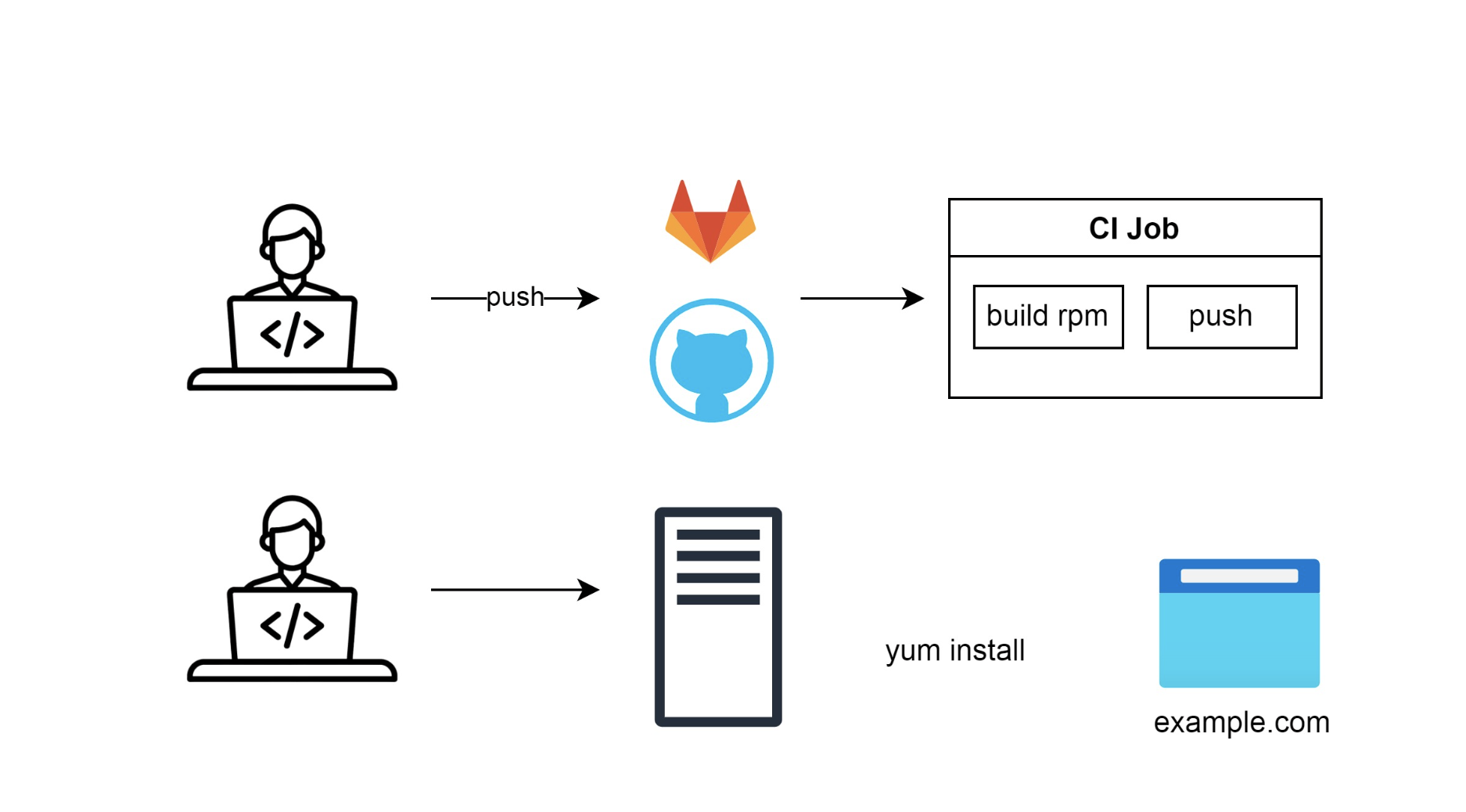
Автоматизация сборки
Позже решили, что плохо выкладывать код напрямую на сервер: хотя бы потому, что человек может забыть что-то выполнить руками.
Начали собирать пакеты для операционных систем, например RPM или Deb, и хранить их в отдельных репозиториях, сборщиках артефактов и автоматизировать этот процесс.
Так придумали первый CI — запуск автоматических заданий по пушу в репозиторий: сборка пакетов и отправка их в репозиторий. Далее программист отправлялся на сервер и вручную устанавливал пакет.
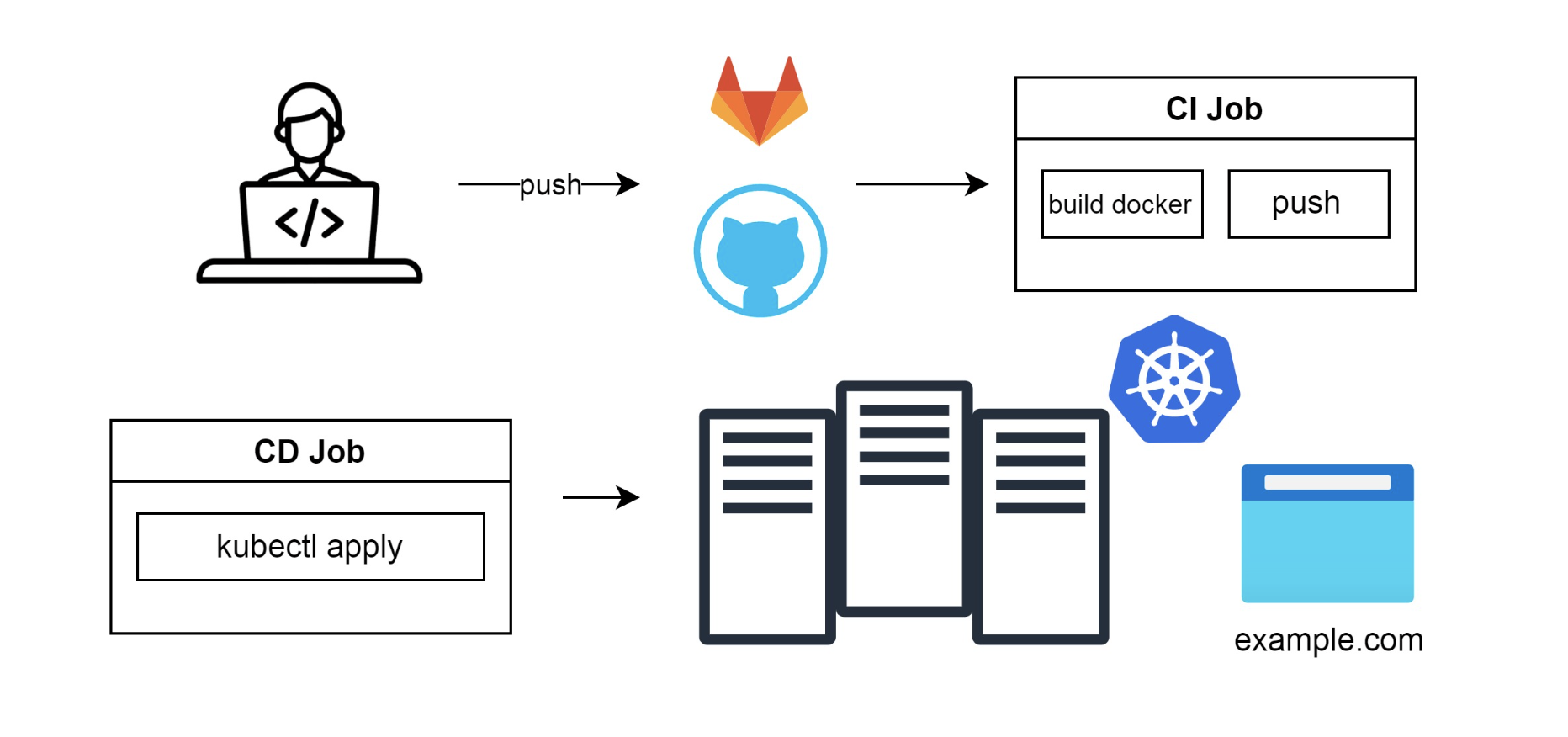
Автоматизация деплоя
Вместо человека, который делал yum install, поставили робота. Когда пакет собрался, робот подключается к серверу и запускает скрипт, например, Ansible-сценарий. Этот сценарий делает yum install, и production-стенд обновляется и перезапускается:

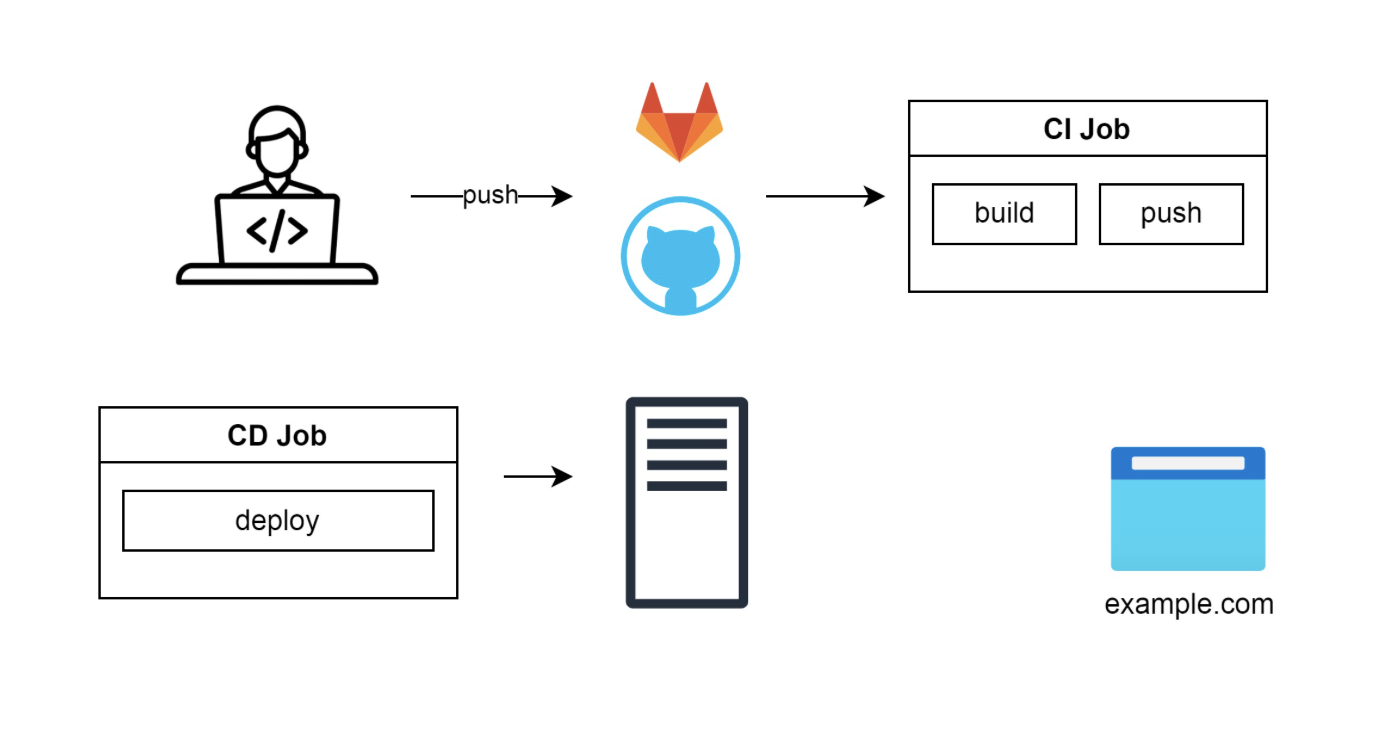
Позже появился Docker, и проект стало можно упаковать в образ, который гораздо легче запускать на любых ОС. Docker-файл — простой набор команд в отличие от спецификации для RPM-пакета, который надо долго изучать. В Docker пользователь сразу получает слепок операционки, в котором программа прекрасно работает. Заменяем сборку пакетов на сборку Docker-образа, пушим его в репозиторий образов, и после CD Job запускает что-то вроде docker compose up. Все сервисы поднимаются на одном сервере:

Kubernetes
Когда проект разрастается, появляются проблемы отказоустойчивости и нехватки места на одной виртуальной машине. Для решения этого вопроса появились оркестраторы. Самый популярных из них — kubernetes. Вместе с оркестраторами появляется и новый подход — микросервисная архитектура, когда огромные сервисы дробятся на отдельные, где каждый отвечает только за свою область.
Теперь мы можем заменить деплой через docker-compose на использование kubectl в CI джобе, сохранив автоматизацию.
Читайте нашу обзорную статью о Kubernetes и других оркестраторах.
Helm
Представим, что проектов много, а yaml-манифесты для Kubernetes похожи друг на друга. Их можно шаблонизировать. Для этого и подключают Helm, который помогает управлять приложениями, установленными в Kubernetes.
Нужно заменить применение через kubectl apply на helm upgrade и установить приложения в Kubernetes:
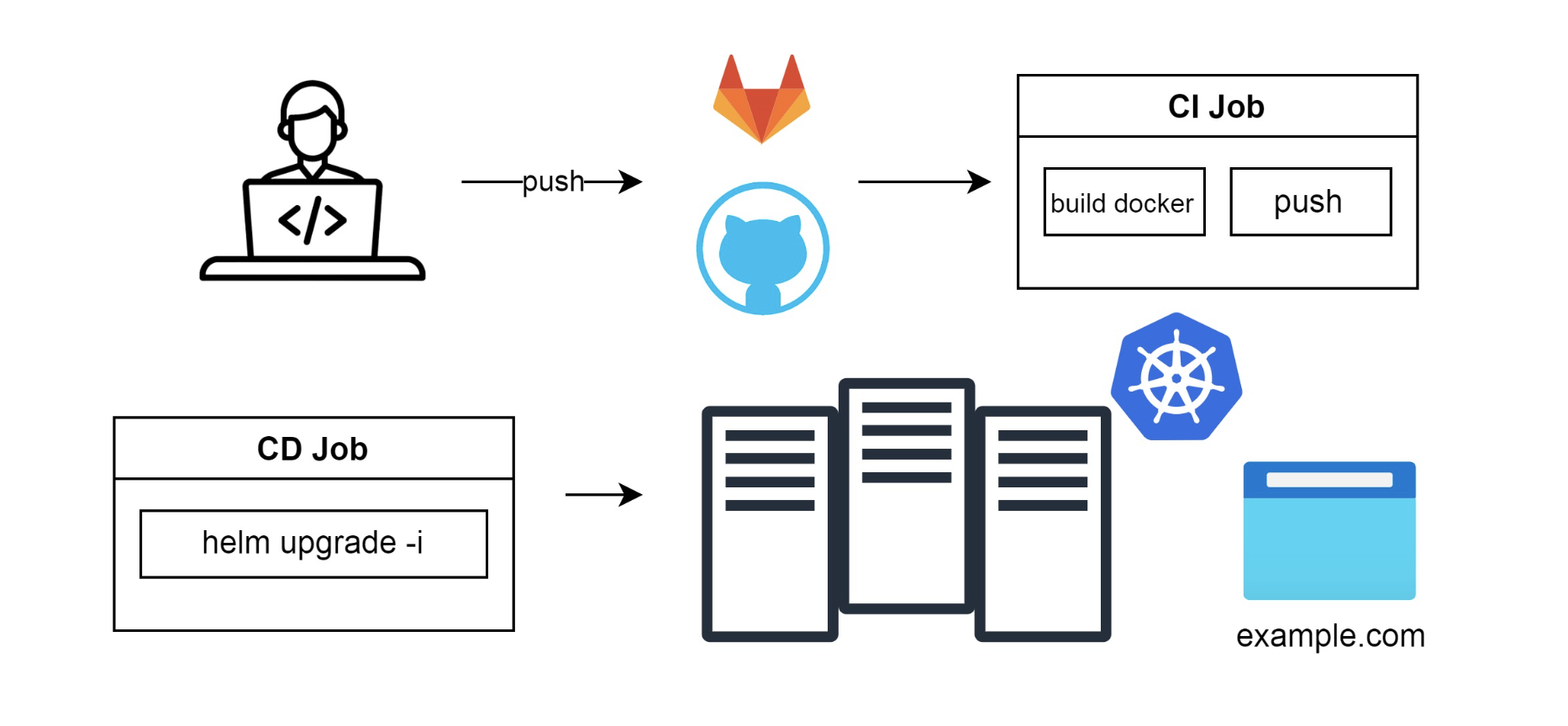
В какой-то момент программистам стало мало одного кластера под production. Они захотели полноразмерное окружение, чтобы было как продакшен, но не совсем: чтобы проверять новые версии и проводить интеграционное тестирование. Девопсы сделали второй кластер Kubernetes, завели на него домен а-ля “test.example.com” и отдали программистам. Стало так:

Программисты попробовали, но оказалось, что команд разработки много. Нужно много стендов, чтобы все могли работать со своим тестовым кластером. Девопсы сделали руками пять стендов. Получился один продакшен-кластер и один тестовый, на котором пять разных неймспейсов-стендов для окружений:
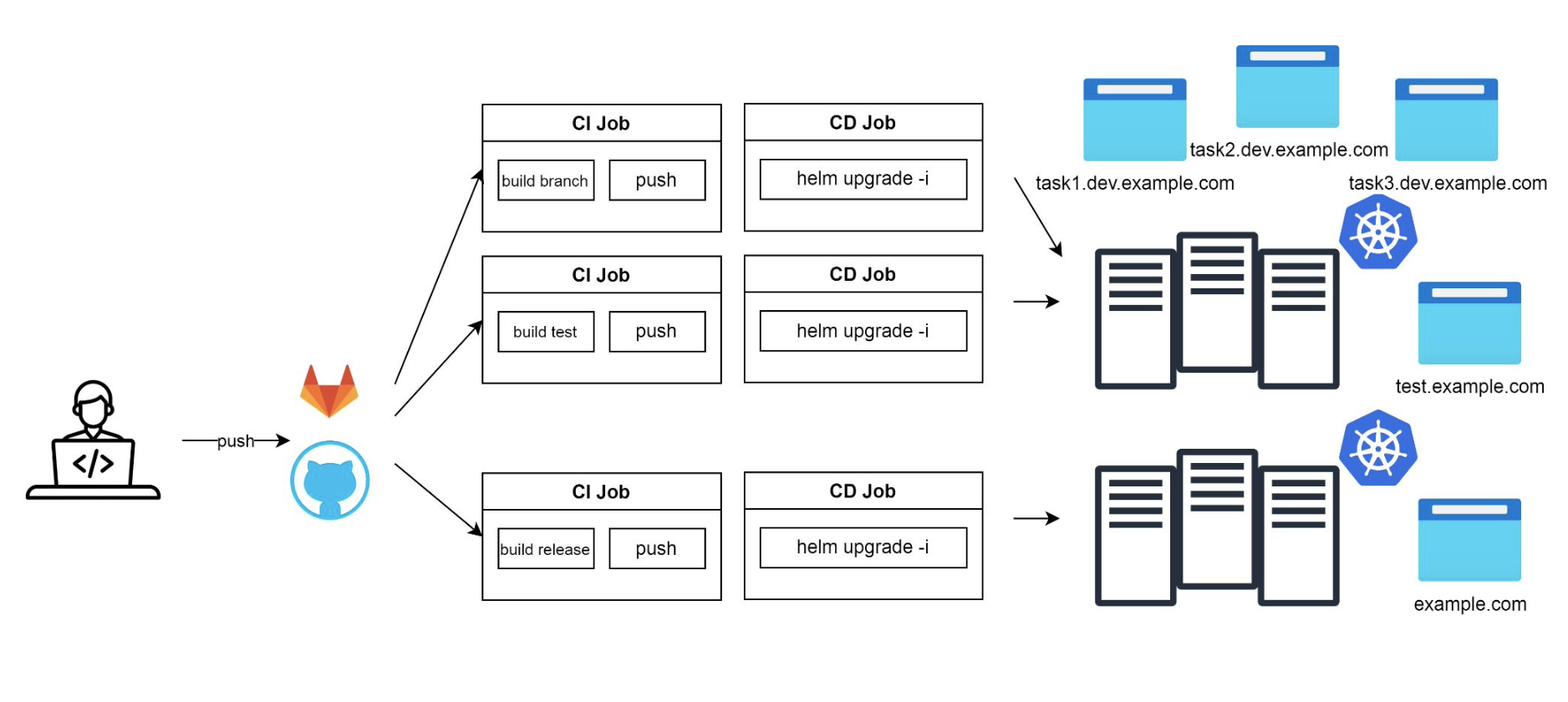
5 стендов оказалось мало. Команда разработки разрастается и параллельно разрабатывает намного больше фичей, поэтому программисты вынуждены ждать друг друга, чтобы получить доступ к какому-то освобожденному стенду.
Динамические окружения
Стенды сделали динамическими: они поднимаются под каждую фичу автоматически. Добавили шаг «создать окружение» в CI/CD Job. Теперь, когда программист хочет сделать новую фичу и создаёт новую ветку в репозитории, под неё поднимается окружение тестирования и разработки:

Классическая push-модель
Если сжать схему динамических окружений, получится классическая push-модель.
По событию «push кода в репозиторий» запускается процесс. Этот процесс строит окружение для тестирования/продакшна, собирает проект и артефакты, запускает процесс деплоя проекта на это окружение, тестирует. В итоге получается автоматический деплой приложения в различные среды:

Плюсы
Просто внедряется. Использует традиционный подход с известными утилитами. Такую модель проще всего внедрить внутри команды в компании
Универсальная. Можно разворачивать модели для любой нагрузки и добиться универсальности в подходах к CI/CD. Push-модель проста в адаптации и часто применяется для CD. Она удобна тем, что CD — скрипт на bash или другом языке автоматизации. Он выполняет команды, которые иначе вы бы делали вручную: kubectl apply или helm upgrade и так далее…
Легко расширяется. В реальной жизни схема развивается до такого масштаба:

Минусы Helm
Helm призван быть темплейтом yaml-манифестов и деплоером этих манифестов в кластеры Kubernetes. Helm хорошо делает yaml-манифесты из темплейтов, при переносе их в кластер Kubernetes могут возникать проблемы.
Невменяемые ошибки. Те, кто работал с Helm, наверняка видели ошибки типа такой:
Error convering YAML to JSON: yaml: line 12: did not find expected keyНеясно — в каком файле, в каком темплейте, какая линия 12. Темплейт в yaml может расползтись на двести строчек. Остается действовать методом тыка: идти в темплейты и отрезать половину. Смотришь, останется ошибка или нет — и так ищешь ее.
Нельзя посмотреть логи упавших подов. У тех, кто ставил Helm Chart параметром wait, был подобный случай. Программист ждёт, что в чарте поднимутся поды и завершится выполнение установки чарта. Обычно он указывает ключик atomic, который позволяет откатиться назад, если установка прошла неудачно. Программист ставит wait 500 секунд и atomic. Запускается процесс деплоя чарта. Проходит 500 секунд. Внезапно релиз не установился, и всё откатилось:
kubectl logs admin-687fcb89ff-knk93
Error from server (NotFound): pods "admin-687fcb89ff-knk93" not foundОказывается, логи собираются централизованно. Приходится искать их при помощи Kibana — по времени, неймспейсу, названию пода. Авось что-нибудь найдется.
Посмотреть логи пода простой командой kubectl logs невозможно, потому что к этому моменту Helm удалил все поды, которые были в состоянии CrashLoopBackOff и не стали ready, чтобы откатиться назад на предыдущий релиз.
Эту проблему можно решать хуками helm. Они запускаются, если не прошёл релиз, который вытягивает логи из упавших подов. Но тут возникает ещё одна проблема — тайм-ауты.
Статус pending-upgrade. Cтавим тайм-аут 500 секунд. Если за 500 секунд хук не успеет отработать, чарт оказывается в статусе pending upgrade или pending install:
helm ls -a
NAME NAMESPACE REVISION UPDATED STATUS CHART
admin dev23 3 2022-07-25 pending-upgrade admin-3.3.1 Это самая страшная штука, которая может случиться с Helm. После этого он отказывается работать с чартом и зависает. Запускается второй раз CI, где делается команда helm upgrade, которая завершается с ошибкой и говорит, что с чартом кто-то уже работает.
Получается, есть процесс, который следит за тем, что происходит в кластере. После этого он завершается, за собой не чистит и остается в подвешенном состоянии. Второй раз он уже запускается и как бы говорит: «там кто-то работает, кто — не знаю, но на всякий случай ничего делать не буду».
Чтобы решить эту проблему, нужно удалять чарт целиком или сделать Helm Rollback: откатить руками релиз на предыдущий. Но это ручные операции, которые ломают автоматизацию на корню.
Pull-модель и GitOps
У нас есть CI-система: разработчики пушат в неё, потом пайплайны идут в инфраструктуру и что-то меняют. Например, настройки подключения к БД или ingress-контроллеру:
В pull-модели ситуация несколько другая. Появляется хранилище, в котором разработчики или админы хранят конфигурацию. Добавляется дополнительный элемент — агент. Его задача — синхронизировать с инфраструктурой состояние, которое описано в хранилище.
GitOps — одна из реализаций pull-модели. В ней Git выступает в качестве хранилища всех конфигураций. Источник правды — Git. Все изменения, которые проводятся с инфраструктурой, проходят только через него. Потом агент применяет изменения и дальше поддерживает это состояние.

Особенности GitOps-модели:
Источник правды — Git
Все действия только через git
Добавляется агент, который синхронизирует состояние
Допустим, мы что-то поменяли руками в инфраструктуре — например, количество реплик приложения. Агент поймёт, что это не совпадает с написанными установками в источнике правды и вернёт всё в исходное состояние.
Преимущества Pull-модели:
Все изменения точно проходят через Git — можно будет найти автора изменений, и по тексту коммита понять, для чего это делалось (если вы за этим следите, конечно)
Гарантия того, что в вашей инфраструктуре развернуто ровно то, что описано в этом репозитории. В случае Push-модели вы не можете понять состояние, потому что все применяется из разных CD-Job
Лёгкость внесения изменений, касающихся сразу нескольких проектов — всё находится в репозитории
Инструменты:
ArgoCD
Flux
Weaveworks
В следующей статье мы подробно рассмотрим ArgoCD, так как это самый популярный инструмент, реализующий Gitops-подход.
Что дальше
В этой части мы рассказали, как развивались подходы к деплою приложений, и немного затронули GitOps модель — альтернативу классической push модели.
Во второй части будет: как работает Argo CD и как устроен GitOps-подход
В третьей части будет: как управляется инфраструктура
Комментарии (3)

MrAlone
00.00.0000 00:00Те, кто работал с Helm, наверняка видели ошибки типа такой:
Те, кто работает с Helm, используют lint и template, плюс какой-нибудь IDE, который будет подсвечивать ошибки.
felixd7u
"Чтобы решить эту проблему, нужно удалять чарт целиком или сделать Helm Rollback: откатить руками релиз на предыдущий. Но это ручные операции, которые ломают автоматизацию на корню."
Попробуйте удалить секрет, хранящий состояние последнего битого релиза и перезапустить Helm. Поды при этом не удаляются, как при удалении всего приложения.
Sermalenk Автор
Да, этот вариант тоже можно добавить в статью, спасибо
Естественно, поправить все можно ручным способом без каких-то страшных последствий, но здесь внимание акцентировалось именно на поломке автоматизированного процесса