
Привет, меня зовут Лев Хакимов, я — DevOps-инженер. Одно время работал над проектом Госуслуг, а сейчас в брокерской платформе в Сбере. Уже больше двух лет играю в CTF команде ONO, которая даже как-то вошла в ТОП-10 по России, а ещё я — один из организаторов VrnCTF, Воронежского CTF для школьников и студентов.
Все мы любим Kubernetes, хакать, и котиков. В этой статье будет это всё, в том числе котики.

Разберёмся с основными понятиями
Эти термины многим знакомы, но для статьи важно обозначить принципиальные моменты. Дальше они понадобятся.
Container и VM
Первое, что нужно сделать — поставить знак между словами:
Container ( ? ) VM
Думаю, большинство из вас поставит знак ≠ и будут, конечно, совершенно правы. Ведь несмотря на то, что задача этих технологий изолировать одни процессы от других, в контейнерах и виртуальных машинах это происходит на разных уровнях.

В случае с виртуальными машинами у нас есть слой инфраструктуры (железа), на который сверху раскатан гипервизор. Относительно него и ставятся программные пакеты с ОС, которые изолируют не только программный уровень, но в придачу процессор и оперативную память. В случае с контейнерами всё это крутится на одной ОС, и изоляция идёт на программном уровне. Занимается этими вопросами движок для контейнеризации, будь то ContainerD, RKT, Podman, или же Docker в сочетании с ContainerD — на ваш вкус.
Разница, скорее, именно в уровнях на которых происходит виртуализация:
Контейнер — виртуализация происходит на программном уровне, то есть выше уровня операционной системы.
Виртуальная машина — виртуализация происходит на всех уровнях вплоть до железа.
Linux Namespaces
Далее — краткий экскурс в Linux Namespaces.
Это абстракция над ресурсами одной ОС, которая позволяет изолировать определённые ресурсы или определённые процессы, протекающие в вашей системе. В современном ядре Linux есть 7 пространств имен:
Cgroups, изолируют по CPU и по памяти.
IPC (InterProcessConnection) или межпроцессное взаимодействие.
Network (по сети).
Mount.
Можно изолироваться по файловой системе и вы просто не выйдете из песочницы, которую вам предоставят.
PID.
Можно изолироваться по идентификаторам процессам, то есть запущенный в этой изолированной среде процесс будет иметь PID1 и ничего не будет знать о родительских процессах, а вот родительский может за ним приглядывать.
User — по пользователям.
UTS — по времени.
Capabilities
Классическая UNIX-система подразумевает, что есть пользователь с ограниченными правами, и root, которому позволено всё, а никакие проверки не выполняются. Но это слишком грубая система. Большинству иногда хочется делегировать процессу какие-то root полномочия, но при этом root давать не хочется. Для этого и придуманы capabilities — это разрешения процессов на исполнение служебных вызовов. Их около 20 штук, они определены в capabilities.h.
Вот примеры от сравнительно безобидного CAP_CHOWN до весьма неприятных, имеющих приставку SYS в названии:
CAP_CHOWN — смена UID и GID.
CAP_KILL — посылка сигналов sigkill, sigterm, sigint.
CAP_SYS_MODULE — установка модулей ядра.
CAP_SYS_ADMIN — монтирование и размонтирование файловых систем.
Классическое разделение прав выглядит примерно так:

В случае с контейнерами всё это можно перенести и на контейнерную среду.
Как сделать дырявый контейнер?
Итак, настало время сборника вредных советов для юных админов, если такие читают эту статью.
Если у вас задача вручную запустить контейнер, и вы хотите дать ему как можно больше привилегий, следуйте этим советам, например:
docker run <image_name> — privileged
В этом случае от вас нужно поставить флаг privileged, сразу выдать все возможные привилегии, которые только есть, и быть уверенным, что это сделает вашему приложению только лучше. Работать оно от этого стабильнее не станет, но зато будет больше возможностей.
docker run <image_name> — cap-add <capabilities>
Можно прицельно поставить capabilities, благо, их 20 штук. В случае, если вы поставите те, которые вам посоветуют, вполне возможно, что-то из этого и выйдет. Скорее всего, хакеру это понравится.
Вендорные приколы, о которых вам не сказали.
Расскажу один маленький интересный случай из жизни. В прошлом году мы проводили VrnCTF в облаке. У одного известного отечественного cloud-провайдера взяли виртуальные машины. CTF подразумевает, что в нём есть задачи, которые представляют инфраструктуру из веб-сервера, какой-нибудь БД. Одна из задач была с Jenkins, где надо было эксплуатировать ряд уязвимостей, выбраться в контейнер, внутри контейнера эскалироваться до root, и там уже получить флаг с данными и сдать его в чек-систему. Не планировалось только, что из контейнера можно сбежать.
Мы раскатывались на этих машинах, как всегда, в последний момент, когда получили задачи. В пять часов утра за три часа до соревнования нам было лень проводить операции по внесению пользователя в группу Docker, хотя, казалось бы, банальные вещи. Мы справедливо посчитали, что если попробуем выполнить старт composed-проекта из-под sudo Docker, то ничего глобально не изменится. Ведь Docker — это всего лишь клиент, который отдаёт команды Docker-сокету, а уже Docker-сокет отдаёт команды на ContainerD с конфигурациями по запуску наших контейнеров.
По идее, никаких привилегий от запуска Docker под sudo, не должно было быть. Но каково было наше неприятное изумление, когда нас хакнули и сбежали на хост. Причём сделали это ребята из 10 класса. При дальнейшем анализе выяснилось, что Docker, который мы получили вместе с виртуальными машинами при заказе, был как раз в привилегированном режиме. Мы этого просто не знали, и все контейнеры по умолчанию стартовали с полным набором capabilities.
Подобные вещи всё-таки стоит проверять, если вы работаете со сторонними, не своими виртуальными машинами — мало ли, что там может быть.
Что можно сделать в привилегированном контейнере?
Как поступить, если мы оказались в контейнере, каким-либо образом туда проникли, и понимаем, что контейнер привилегированный:
Смонтировать хостовую файловую систему в контейнер, если там есть тот же CAP_SYS_ADMIN (потому что можем).
-
В некоторых случаях можно воспользоваться docker daemon socket — вообще подарок!
Клиент daemon работает с socket, который отдаёт команды, и мы можем отправлять наши конфигурации и команды на socket Docker. Есть контейнеры, которые этот сокет с хоста прокидывают внутрь себя. Например, это системы сборки типа Docker in Docker. Когда у вас есть сборка, вам надо в контейнере произвести Docker-сборку, прогнать тесты, поднять тестовое окружение и можно воспользоваться daemon-сокетом, его просто прокидывают с хоста. Да, этот контейнер может быть не привилегированным, однако, если у вас есть все полномочия, вы можете запустить такой контейнер и что-то выполнить.
Можно каким-то способом заставить контейнер выполнить reverse-shell на хосте и уже подключиться к нему.
Это основные способы. Давайте случай с reverse-shell рассмотрим чуть подробнее.
Хакнуть docker через reverse-shell
Reverse-shell — это перенаправление оболочки ввода-вывода (консоль) атакуемой машины куда-то, куда вам удобно. Например, вы захватываете терминал и передаёте его через TCP-сокет на компьютер, до которого можно достучаться.
Предположим, мы оказались в некоем контейнере. Первое, что нам захочется сделать — выполнить команду capsh. Она идёт в пакете libpcap и выводит все доступные capabilities прямо из контейнера.
Выполняем, и видим, что у нас стоит cap_sys_module.

Значит, можно попробовать инъецировать модуль ядра. Больше никаких зацепок мы не видим. Сделаем модуль и попробуем его запустить.
Сплойт:

Конечно, назвать это суперсложным сплойтом язык не повернётся, но тем не менее. Всё, что он делает — это выкачивает готовый reverse-shell, подставляет туда ваш статический IP и порт, и просто запускает эту команду в оболочке ядра модуля для Linux.
Что осталось с ним делать?
Компилируем, получаем .ko-модуль (kernel object).
Открываем на компе, в данном случае мы считаем, что этот контейнер смотрит в интернет и вы можете его куда-то перенаправить.
nc --vlnp <YOUR_PORT> — слушаем порт.
insmod sploit.ko — помещаем в модуль Linux Kernel.
Поздравляю! Вы великолепны! Возьмите в награду БД с персональными данными! У вас сразу множество наград, на хост можно дальше предпринимать какие-то шаги.
Но хорошо, вы почти на середине статьи, и возникает логичный вопрос: «А где же k8s?». Docker — хорошо, но не все же его используют и вообще этот доклад про Kubernetes.
Kubernetes
Думаю, не надо рассказывать, что Kubernetes — это классное ПО для оркестрации контейнерных приложений, в каком-то смысле state-машина, которая позволяет:
автоматически развертывать ПО;
поддерживать жизнедеятельность заданного количества реплик;
обеспечивать ещё много интересных фишек (RBAC, ingress, различные операторы).
Классная крутая система! Конечно, Kubernetes по сравнению с Docker выглядит как что-то навороченное. Тем не менее кто работал с ним глубже, чем обычный пользователь, понимает, что это относительно низкоуровневая штука. Далеко не все вещи там реализованы или предусмотрены заранее. Поэтому и существуют коробки типа Openshift или Rancher, в которых закрыты и решены основные проблемы. Как полагают многие, в частности, менеджеры, которые не особо знакомы c k8s, если у вас есть Kubernetes, это решает почти все ваши проблемы — и программы в Kubernetes работают в 200 раз быстрее, и вопросы безопасности там возникают, потому что любая статья по k8s обязательно утыкается в RBAC.
Kubernetes безопасен, у нас есть RBAC!
Role Based Access Control (RBAC) — система разделения прав на выполнение операций в кластере, основанная на ролях.
RBAC — это ролевая система, то есть вы готовите какую-то роль, отдаёте ей permissions на создание, просмотр, выполнение, удаление различных кубовых манифестов, и эту роль присваиваете аккаунту. Казалось бы, всё классно. Но когда вы уходите от того, что у вас k8s занимаются только админы, передаете его как сервис, то ваша продуктовая команда может заказать namespace и сама с ним поиграться. Конечно, вы не хотите давать этой продуктовой команде слишком много полномочий, а ограничить их можно с помощью RBAC.
Представим, что у вашей команды есть какой-то сервис-аккаунт, по которому они туда заходят. Они не могут посмотреть сторонние namespace, а только свои ресурсы, создавать только свой деплоймент, смотреть, что они создали, почитать логи. Но глобально повлиять на k8s не смогут.
Но у RBAC есть одна серьёзная проблема: он не влияет на привилегии контейнеров, а работает на уровне Kubernetes и на уровне объектов Kubernetes.
Как стать хакером в k8s за 2 минуты?
А сейчас коротенькая драма в семи актах с прологом, эпилогом и даже неожиданным предательством.
Пролог
Итак, представьте, наше главное действующее лицо — это милый junior-котик, который только вышел в новую продуктовую команду.

В команде есть множество задач, и котику говорят: «Смотри, у нас есть микросервис, вот новая фича, её надо реализовать, и заодно давай мигрируем наш проект, который был раскатан где-то там, в Kubernetes!».
Хорошо, наш котик всё разработал, поставил новые пакеты, потому что есть новые функциональности, а новые пакеты ведь всегда хорошо, это же что-то новое! Дальше ему нужно было как-то раскатиться в Kubernetes. Он пошел в соседнюю команду, скопировал helm-чарт, попробовал запуститься — ничего не получилось. Приклад падает, разбираться не хочется.
Котик идет на StackOverflow, пытается посмотреть там. Как известно, джуниор от миддла отличается тем, что он копирует не с ответов, а с вопросов. Скопировал котик какие-то поля, завел то, что ему насоветовали, нажал helm install и все заработало, Pod поднялся.
Теперь давайте посмотрим, какие возможности у нашего ограниченного по всем правам джуниор-котика были, и что он потенциально мог себе затащить. Для этого попробуем создать свой под, который выполнит не совсем то, что бы нам хотелось.
Заставим наш под не умирать
Мы будем создавать Pod, даже не деплоймент. Чтобы заставить Pod не умирать, воспользуемся любым образом ОС: нам пойдет всё, что запускается. Запускаем бесконечный цикл, просто чтобы он сразу не завершился.

Разрешим не изолироваться от хоста
Сразу поставим параметры true:

Можно не изолироваться ни по сети, ни по межпроцессному взаимодействию, ни по PID, потому что мы можем так сделать. А если можем, то почему бы и нет?
В придачу он еще и привилегированным будет!
Потому что привилегированный контейнер всегда лучше, чем непривилегированный.

Заставим POD уехать на мастер
Просто сделаем nodeSelector на мастер:

Очень хотим так сделать! И тут сталкиваемся с тем, что рядом с джуниор-котиком был еще один джуниор-котик, но со стороны сисадмина, который при раскатке Kubernetes поставил тейнт, что на мастер шедулиться нельзя.
А если на мастер шедулиться нельзя?
Это что, значит, у котика не получится случайно положить продакшен? Да не в коей мере!
Нам можно!
Конечно, ему это можно сделать — он же может поставить tolerations к этой заразе и уехать на мастер, даже несмотря на то, что ему явно это запретили.

И самое главное!
Напоследок давайте мы просто смаунтим в контейнер весь хост и достанем всё, что там лежит — сертификаты и какой-нибудь классный манифест.

Дальше мы можем заходить и развлекаться — весь кластер в нашем полном распоряжении, полный карт-бланш. Можем хоть все контейнеры удалить — почему нет.
Эпилог
Настало время обещанного эпилога:
Предоставляем K8s как сервис.
Junior-котик сделал себе в коде pip install dobriy_mainer:6.9.6.
Теперь компания тратит электроэнергию в пользу благородных хакеров.
От чего мы защищаемся? Мы защищаемся от того самого джуниор-котика или от того, что он потенциально может себе поставить и притащить?
Если ваш проект не использует договоренности по пакетам и версиям, какие проверены, какие нет, у него нет Proxy Nexus со своими доверенными пакетами,тогда у него потенциально нет возможности легко затащить новый непроверенный пакет. Особенно это всё стало резко актуально после 24 февраля. Вы можете себе поставить хоть прекрасный майнер в систему, который будет поджирать ваши ресурсы, либо просто что-нибудь сломаете или потеряете, и потом будете искать свои данные на saverudata — почему нет?
Будем лечить!
Настало время подлечиться. Что самое интересное, в Kubernetes есть возможности, как от этого защищаться, причём они поставляются из коробки, но Kubespray по умолчанию их выключает. Надо их переключать, чтобы они при установке установились и подключились.
Admission Controller
Валидатор и модификатор манифестов, встроенный в K8s — это основные ворота.
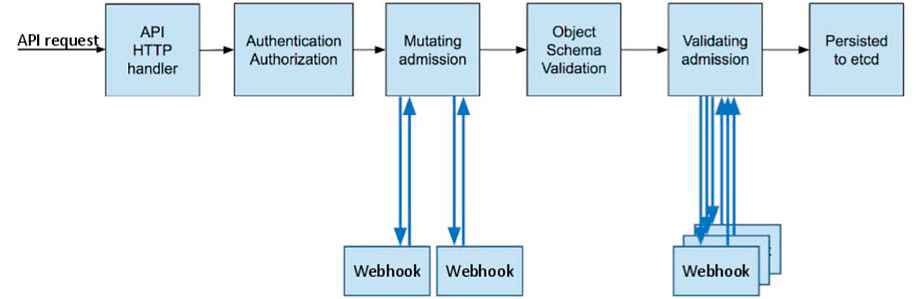
Admission Controller — перехватчик. Как только API сервер принял ваш реквест с манифестом, он может туда как добавить новые поля через мутацию, так и провалидировать поля и, в случае запрещённых полей, отклонить ваш манифест.
Для чего это сделано? В случае с мутациями очень удобно пользоваться этим механизмом, потому что ваш разраб потенциально не должен ничего знать про устройство кластера — куда надо отшедулить ваш Pod, как он должен там располагаться. Это всё можно дотащить на этом этапе, написав только конфигурацию. Такие поля могут подставиться автоматически.
Pod Security Admission
Вопрос валидации — всегда очень актуальная тема. Но есть такая штука, как Pod Security Admission Controller
Pod Security Admission объявляет особый Admission Controller, который следит за соблюдением политик безопасности в кластере. Этот уже готовый контроллер имеет три политики безопасности:
Enforce — строгая политика, которая отклонит, если у вас есть какие-то запрещённые поля. Контроллер не даст задеплоиться и выведет событие, что деплой отменен.
Audit — даст задеплоиться, но это будет зафиксировано в журнале аудита.
Warn — просто в событиях объявит предупреждение, что вы что-то не то используете, но, так и быть, поставлю.
Admission Controller основывается на стандартах Pod Security.
Pod Security Standards
Это уже готовые профили (levels) безопасности для Pod:
Privileged — самый легкий, где почти всё можно.
Baseline — базовый.
Restricted — самый ограниченный.
Более подробно, какие поля входят, какие нет, можно узнать в документации, просто не все до этого доходят.
Вешаем на Namespace лейбл
Конечно, приятно, что всё это включается сравнительно легко. При выдаче namespace вы навешиваете туда пару levels с нужными параметрами, запускаете, и получаете стандартную безопасность.

Никаких дополнительных средств мы не привлекали.
Это очень классная штука, с которой стоит познакомиться. Но она сравнительно свежая и работает с версии 1.23, а всё, что ниже, не поддерживается. Если у вас версия кластера ниже, конечно, рекомендую обновиться. Тем не менее есть встроенный механизм и в более старых версиях.
Pod Security Policies (deprecated)
Сейчас не рекомендуется пользоваться Pod Security Policies, он отмечен как deprecated, скорее всего, скоро вообще исчезнет. Фактически это просто YAML-манифест, в котором можно указать, какие вещи из securityContext и какие настройки в манифесте пода мы можем запретить.
SecurityContext
Наверняка вы видели эту штуку в манифестах. Довольно часто, когда что-то не взлетает, вы тоже идете на StackOverflow, а там рекомендуют что-нибудь перетыкнуть. Но надо знать, что вы, собственно, тыкаете:
runAsNonRoot
Классно, кажется, что всего лишь один манифест, одна строчка — я пишу runAsNonRoot true, и внутри контейнера проект будет запускаться не от root, а от какого-то пользователя. Сразу вопрос — от какого? Эта строчка проблем не решает, потому что в контейнере уже должен быть заготовлен дефолтный пользователь, от которого вы сможете стартовать. Если таких пользователей нет, это не сработает. Так же, как и в случае если пользователь есть, но у него не выданы все permissions на папки и права на исполнение.
runAsUser / runAsGroup
Позволяет выбрать какого угодно пользователя. Но обычный пользователь может не подойти. В ноде есть готовый пользователь нод, который позволяет это делать, в Jenkins есть пользователь Jenkins, специально для этого заготовленный. Но надо смотреть документацию, не всегда это есть. Ну и сборщик для Java типа JIP может тоже создать этого пользователя автоматически.
seLinuxOptions и seccompProfile
Использование настроек seLinux и seccomp напоминает старый хороший анекдот: «Этот парень положил нам сервер» — «Он кто, хакер?» — «Нет, просто дурак». Почему? Потому что seLinux — это как раз вопросы безопасности, а seccomp позволяет вам разрешать или запрещать определенные siscall. В обычной практике в большинстве случаев это никому не нужно, а если нужно, то можно это обсудить индивидуально.
Priveleged и Capabilities
Об этом говорили выше. Тут тоже всё понятно, можно перечислить список с capabilities.
Read-only filesystem
Полезная штука. Чтобы злоумышленник не мог подменить вашу конфигурацию приложения в процессе, очень рекомендуется пользоваться этим флажком.
procMount
Позволяет в режиме unmask не маскировать proc-систему, это тоже далеко не всегда нужно.
fsGroup
Дает групповые права на примаученные тома.
Sysctls
Это аналог Sysctl в Linux. Этот флаг тоже не рекомендуется использовать, потому что большинству людей, ставящих обычное приложение, он в принципе не нужен.
Посмотреть на систему глазами хакера
Давайте посмотрим на систему глазами хакера, какие есть тулзы. Если кто-то играл в CTF или в pentest, возможно, вам что-то покажется знакомым.
PEASS-ng
Наверняка тот, кто играл в HackTheBox, знаком с этой утилитой. Это готовый набор башовых скриптов для поиска привилегированных инструкций и их дальнейшей эскалации. Он позволяет провести сканирование вашей системы. Она больше предназначена для VM, но нормально работает и в контейнерах. Она пытается найти уязвимости на Linux-серверах, которые потенциально там могут быть, и предоставляет простой аудит-отчёт.
LinPEAS
Это скрипт для поиска уязвимостей на Linux-серверах и контейнерах. Можно запустить в любом Pod кластера и посмотреть отчет по потенциальным уязвимостям.
CDK
Более пропатченная, улучшенная версия. Принципиально это другое приложение, но суть та же. Это статический Go-бинарь, который не только составит вам отчет об изолированной среде, но и предложит возможный эксплойт. Эта утилита не только составит аудит, но и попытается предложить вам какие-то банальные скрипты и эксплойты. Можно попробовать ими воспользоваться, иногда даже работает.
А есть тулзы только для аудита?
Это инструменты для аудита, которые можно применить в коммерческой среде.
CIS Kubernetes Benchmark
Это набор уже готовых аудит-скриптов, который можно выполнить и посмотреть, какие отчеты он составит. Также это ещё набор определенных best practices по настройке Kubernetes.
Для сетевого трафика: Network Policy
Стандартный, поставляемый в Kubernetes из коробки (OSI 3-4) firewall, в котором вы можете достаточно легко настроить ingress и egress правила для объектов k8s, и определить входящий и исходящий трафик для подов. Почему? Потому что по умолчанию для Pod в Kubernetes разрешён совершенно весь трафик как для внутренних объектов k8s, так и для внешних ресурсов. В частности, если у вас Prometheus оператор стоит в отдельном space, но разворачивался просто helm’ом без особых манипуляций с ним, то ссылки стандартно тоже будут совпадать. Соответственно, потенциальный хакер, оказавшись в Pod, сможет выгружать метрики о вашем кластере. Это может дать ему определенные сведения о системе и составить вектор атаки.
Ресурсов много не бывает
Когда идёт поставка k8s как сервиса, с ресурсами надо быть особенно осторожным. Ведь для команды никогда не бывает много ресурсов, все хотят воспользоваться всем, что им предоставлено.
ResourceQuotas & LimitRange
В Kubernetes есть два объекта ResourceQuotas и LimitRange, позволяющие задавать квоты ресурсов по CPU и памяти для namespace.
Их особенности:
Позволяют ограничить namespace по ресурсам.
Могут ограничить по ресурсам и количеству запущенных поды.
Избавляют от проблемы, когда кто-то создаст 1000000000 Pod в кластере и положит его.
В частности, это избавляет вас от того, что разработчик пил кофе, пролил на клавиатуру, кнопка залипла на нолике и — вуаля! — в кластере появилась куча подов. Вероятно, Kubernetes это не убьёт, но ему будет определённо плохо от такого количества объектов. Особенно если это случилось в пятницу вечером, когда команда сопровождения пошла отдыхать. Вероятно, это доставит определенные неудобства.
Чтобы такого не случалось, можно просто изолировать по ресурсам определенные namespace, тогда весь кластер сразу не ляжет.
HuckF1nn
как вкатиться в CTF?