

Хабр, привет!
Меня зовут Илья Казначеев, я техлид в команде #CloudMTS.
Представьте, что у вас есть распределенный процесс. Он состоит из сотни шагов: часть из них выполняется последовательно, часть — параллельно. Каждый шаг подразумевает один или несколько вызовов отдельных сервисов. Управление состоянием в такой системе — задача сложная. Как сделать так, чтобы изменение состояния происходило детерминированно: чтобы транзакция либо выполнилась, либо нет, чтобы процесс либо завершился полностью, либо откатился полностью. Как понять, что произошла ошибка, а главное – что нужно сделать, чтобы процесс пошел дальше или перезапустился.
Такую задачу мы решали для одного из наших сервисов Containerum Kubernetes Service, и в этой статье я расскажу, как мы научились управлять распределенными транзакциями, включающими 200–300 шагов и дюжину сервисов.
Сразу скажу, что в статье речь пойдет не о распределенных транзакциях баз данных, а о транзакциях уровня бизнес-логики приложения.
Итак, когда клиент в Консоли управления нажимает на кнопку «Создать кластер Kubernetes», запускается многоступенчатый процесс, задействующий несколько сервисов: создаются виртуальные машины, виртуальные сети, диски, сам кластер и его сущности.
В очень сокращенном виде путь выглядит примерно так:
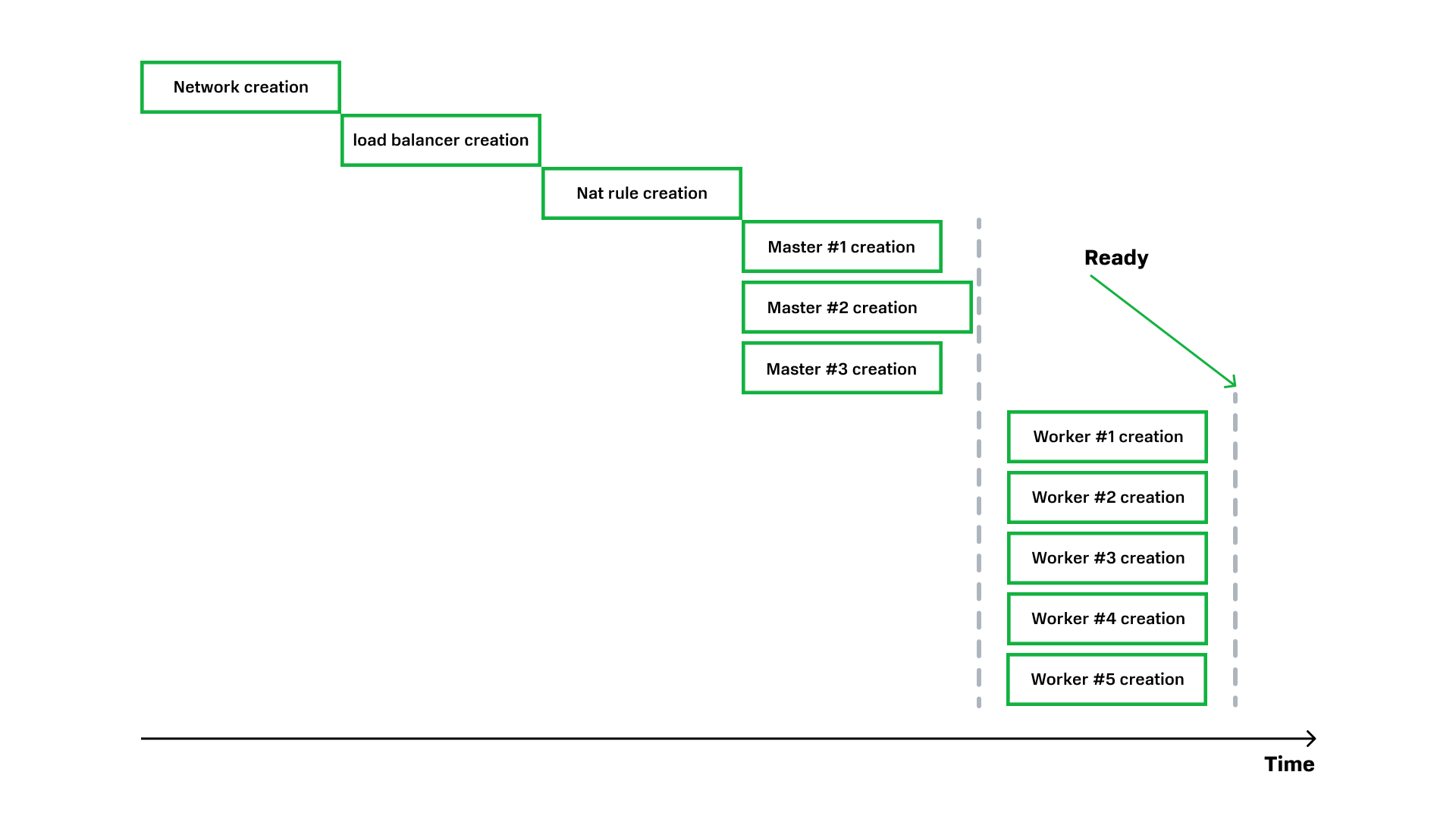
На каждом этапе этого верхнеуровневого пайплайна спрятана еще одна или даже несколько цепочек процессов. Ниже пример того, на какие процессы раскладывается шаг worker creation из картинки выше.
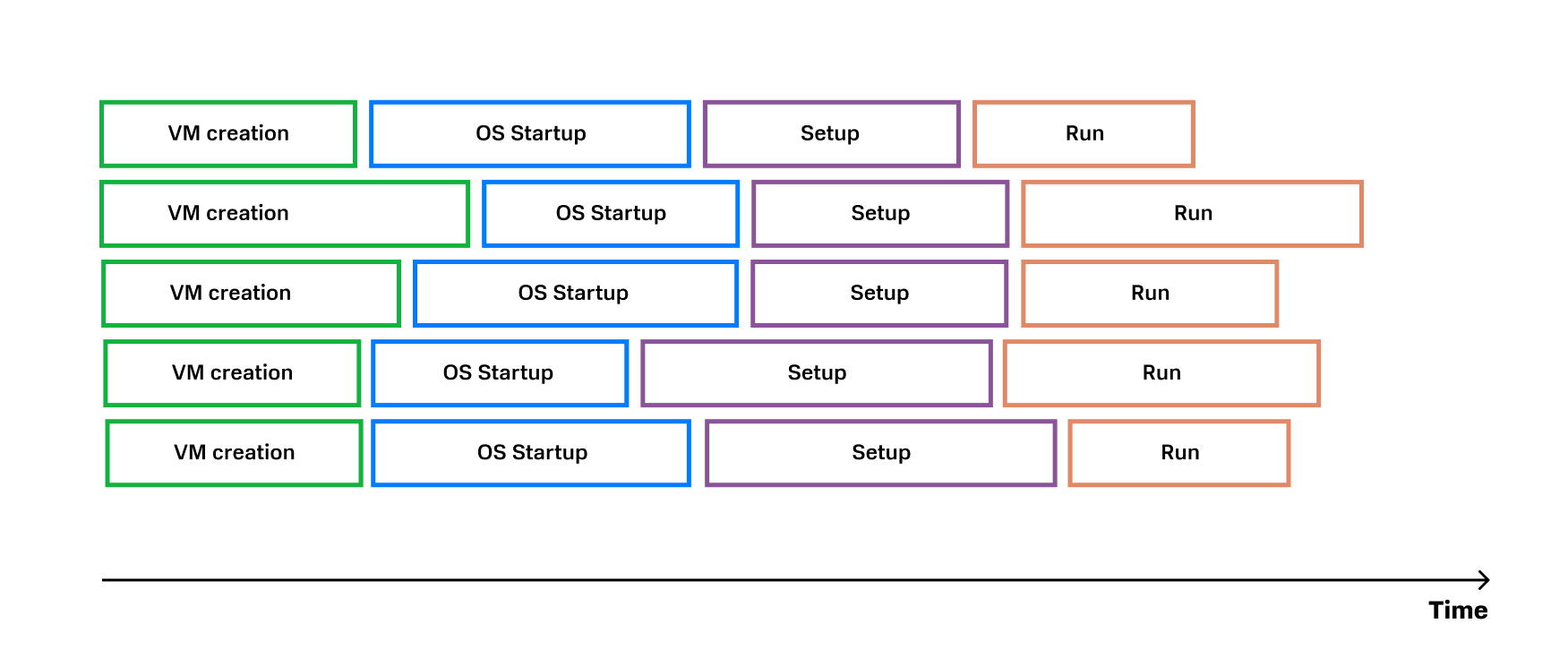
И такая «матрешка» ожидает нас на каждом этапе.
А что, если у одной из ВМ не стартанула ОС? Как нам обработать ошибку? Удалить эту проблемную машину и пересоздать ее? Или нужно всю группу машин удалить? И какой компонент системы должен принимать решение о дальнейших действиях?
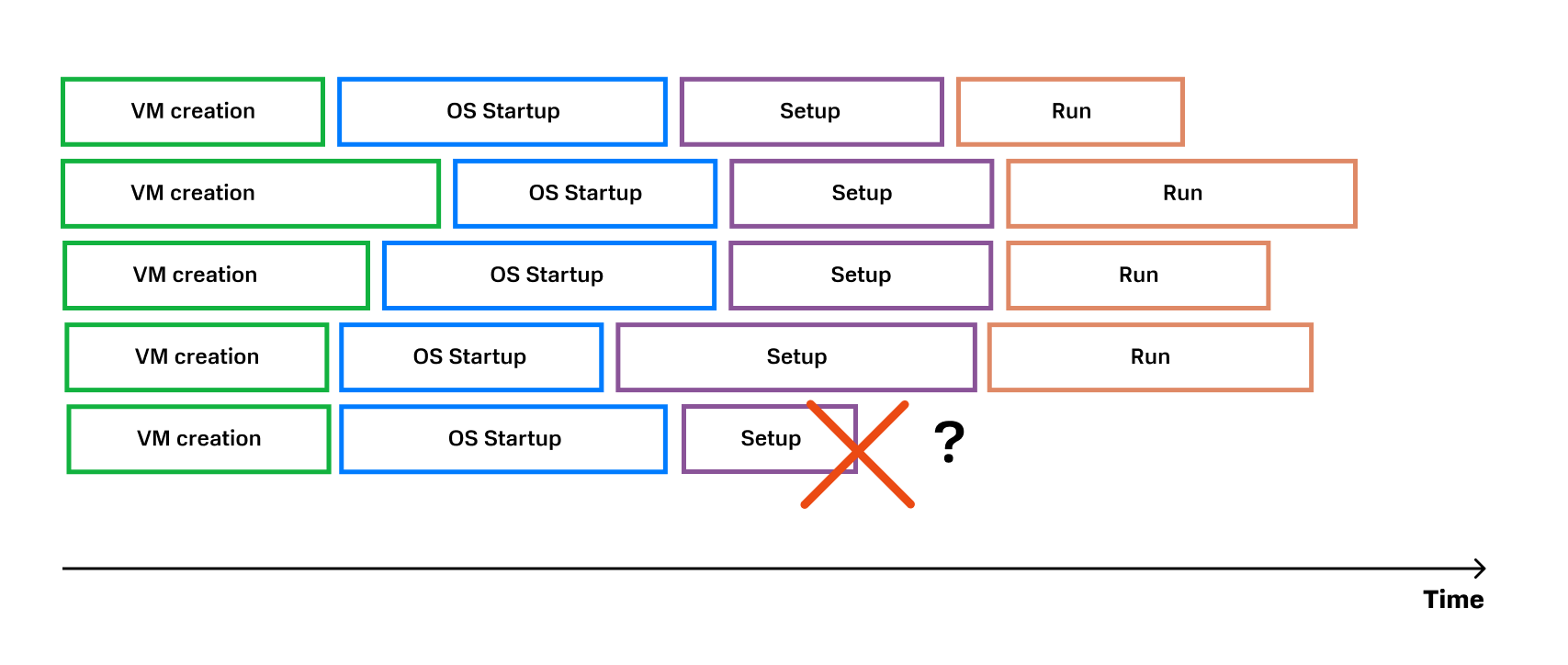
Чтобы ответить на эти вопросы, нам нужно:
- понимать, в каком состоянии находится каждый элемент системы;
- обеспечить однозначность этого состояния (создается, изменяется и прочее) и его согласованную обработку.
Domain-driven design
Для решения этих задач мы пошли по пути Domain-driven design (DDD). Описали сущности сервиса в виде доменов. Каждый отдельный сервис (сетевой сервис, платформа виртуализации, кластер Kubernetes и так далее) — это доменный агрегат, представляющий собой древовидную структуру из доменов.
Вот, например, так выглядит доменный агрегат кластера Kubernetes, где кластер — это корень доменного агрегата, а нода, группа нод, LB — домены.
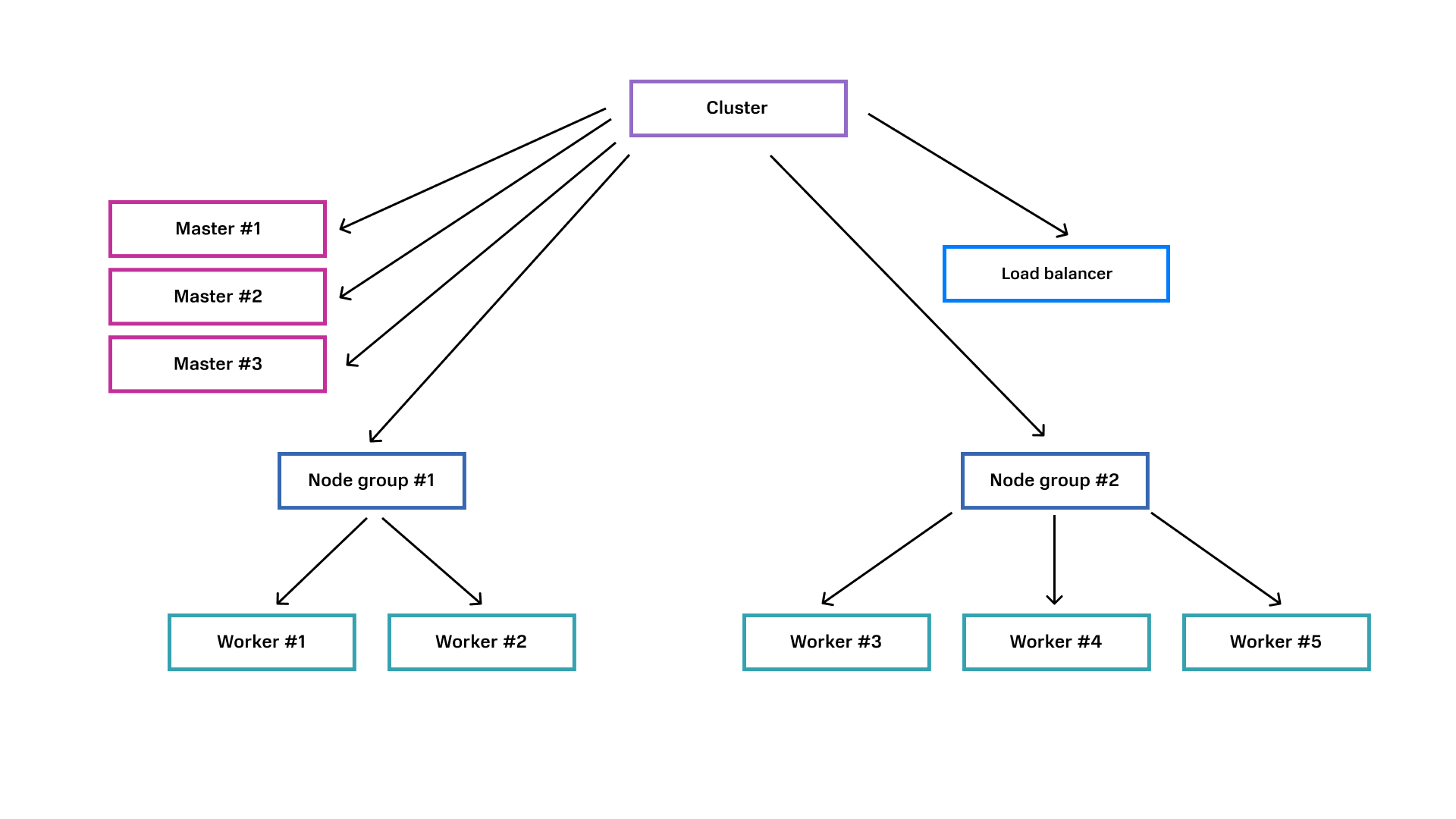
Применяя подходы DDD, мы смогли разделить сложную логику сервиса на отдельные слабосвязанные компоненты (домены), каждый из которых имеет свое состояние. Это позволило значительно упростить работу над параллельными процессами и обработку множества событий, происходящих на протяжении жизненного цикла кластера.
DDD и конечные автоматы (FSM)
Следующий момент — это понять, как управлять состояниями доменных сущностей и переходами между ними. Для этого мы описали для каждого домена свой набор состояний с помощью конечных автоматов (Finite-state machine, FSM).
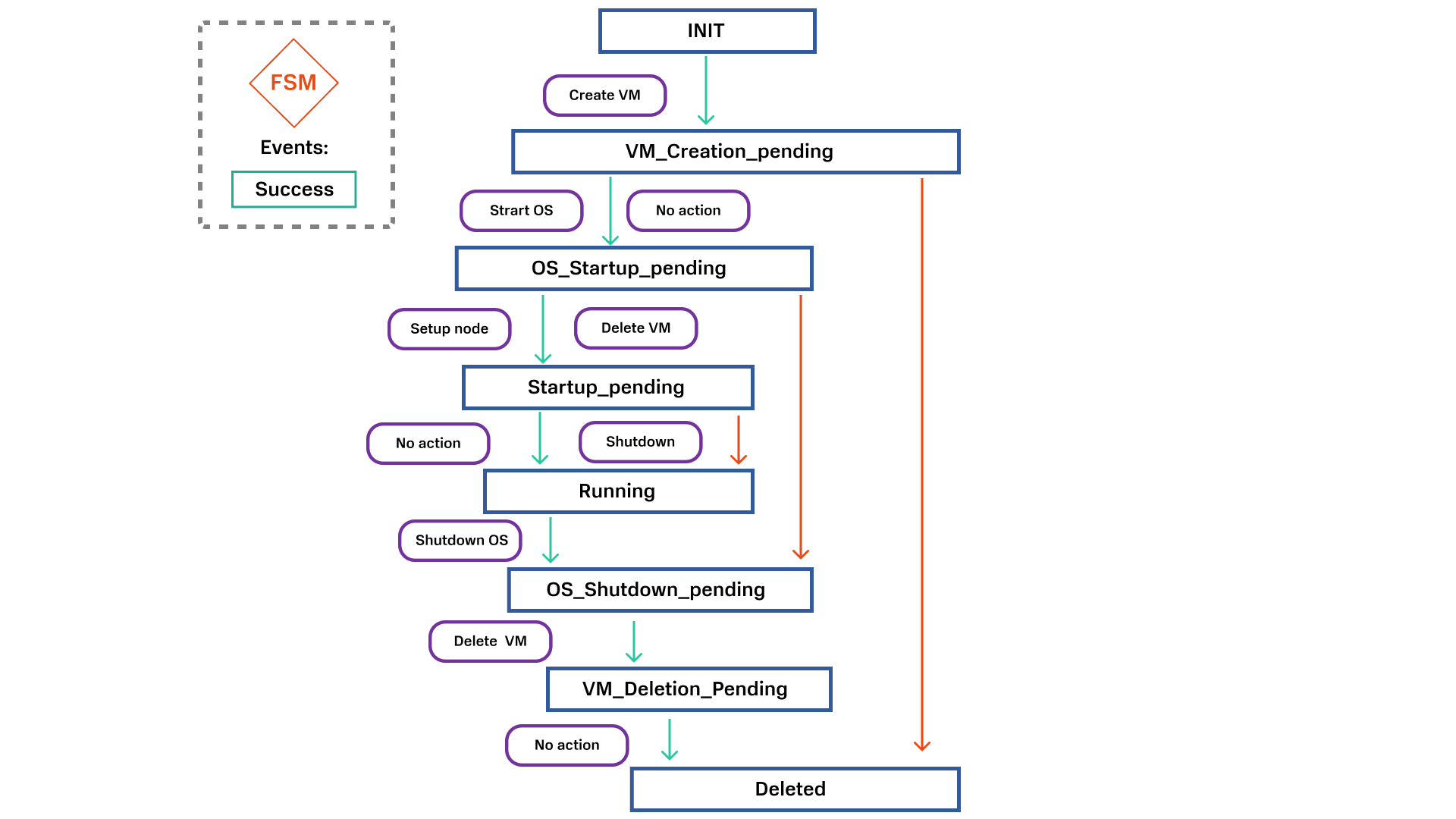
Вот как выглядит схема конечных автоматов для одного домена — ноды внутри кластера Kubernetes:

Использование конечных автоматов помогло нам сделать обработку ошибок, согласованную с состоянием. Если при создании виртуальной машины у нас происходит ошибка, мы понимаем, что она не создалась, и сразу переходим к статусу «Удалено». Если мы ее создали, но она застревает в статусе OS_Startup_Pending, то мы сразу можем перейти к удалению ВМ.
В результате весь процесс не зависает при ошибке, а откатывается назад и перезапускается.
Теперь поднимемся на один уровень выше и посмотрим, как происходит обработка событий в рамках одного доменного агрегата — кластера Kubernetes. В этой древовидной схеме у нас появляются дочерние и родительские сущности. Сущность, которая находится на более высоком уровне, является родительской по отношению к той, которая ниже. Например, кластер — родительская сущность для групп worker-нод, master-нод, load balancer. Изменение состояния одной дочерней сущности запускает действия или изменения состояний родительской сущности и наоборот. Когда происходит ошибка, родительская сущность принимает решение, что делать дальше.
Теперь посмотрим на примере и картинках.
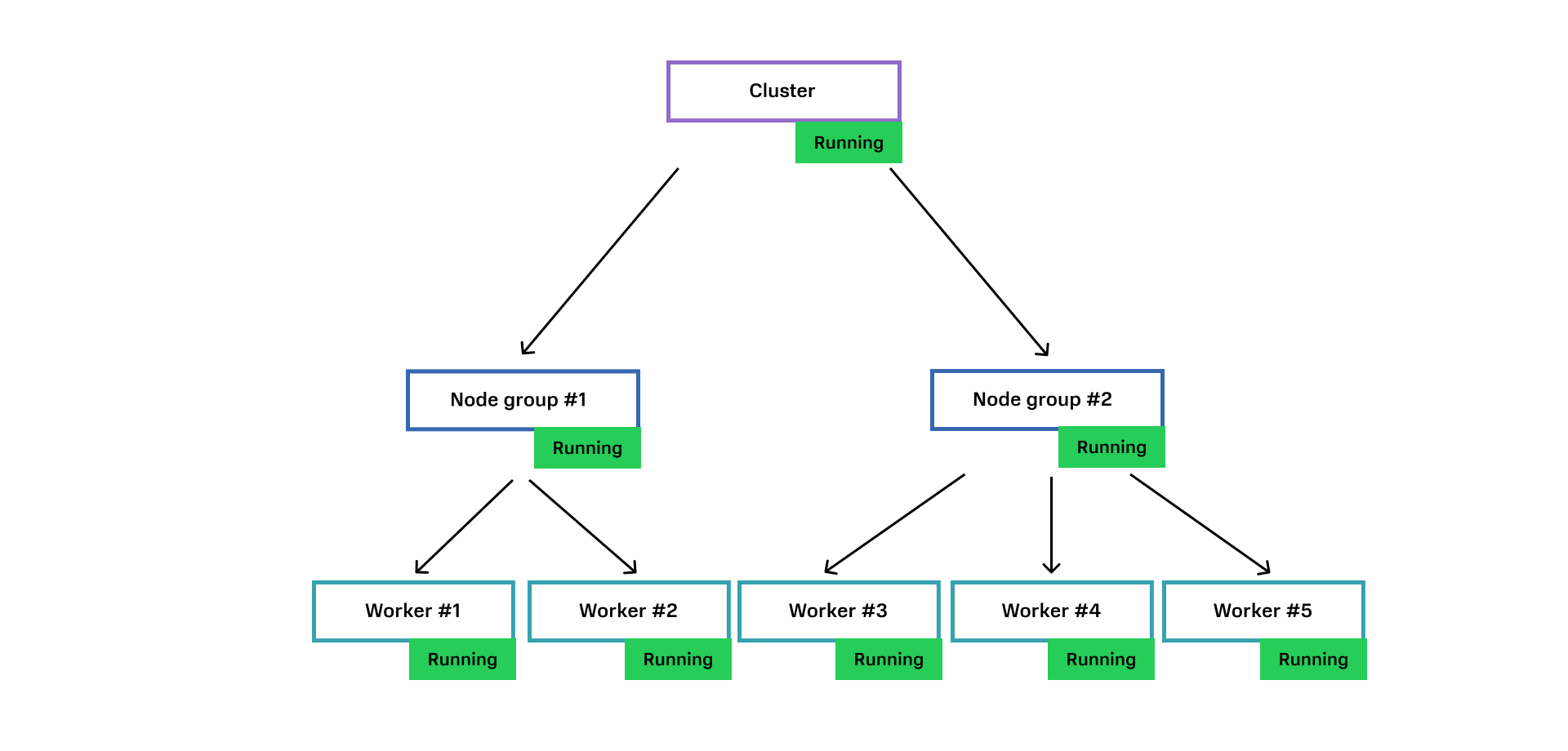
Вот наш доменный агрегат «кластер Kubernetes». В момент времени каждая доменная сущность находится в своем состоянии, например, у Node Group #1 ноды еще создаются, а у Node Group #2 все машины уже запущены.
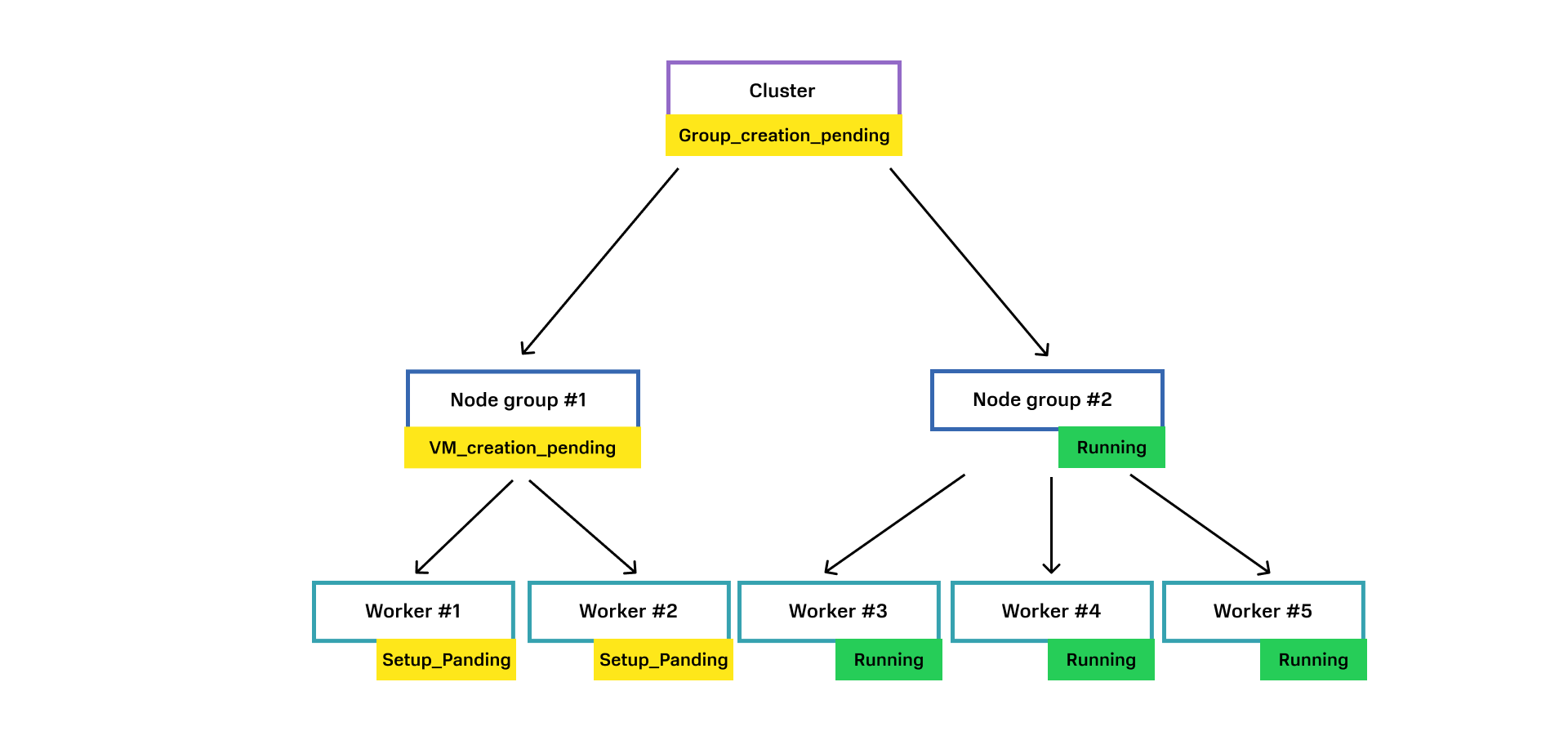
Обмен данными о состоянии между доменными сущностями происходит следующим образом:
1. От сервиса виртуализации приходит ответ, что Node Worker #1 создалась. Node Worker #1 переходит в состояние Running.

2. Node Worker #1 отправляет родительской сущности Node Group #1 событие о том, что машина создалась. Родительская сущность Node Group #1 проверяет, все ли Worker’ы созданы. Если не все, значит ждем.
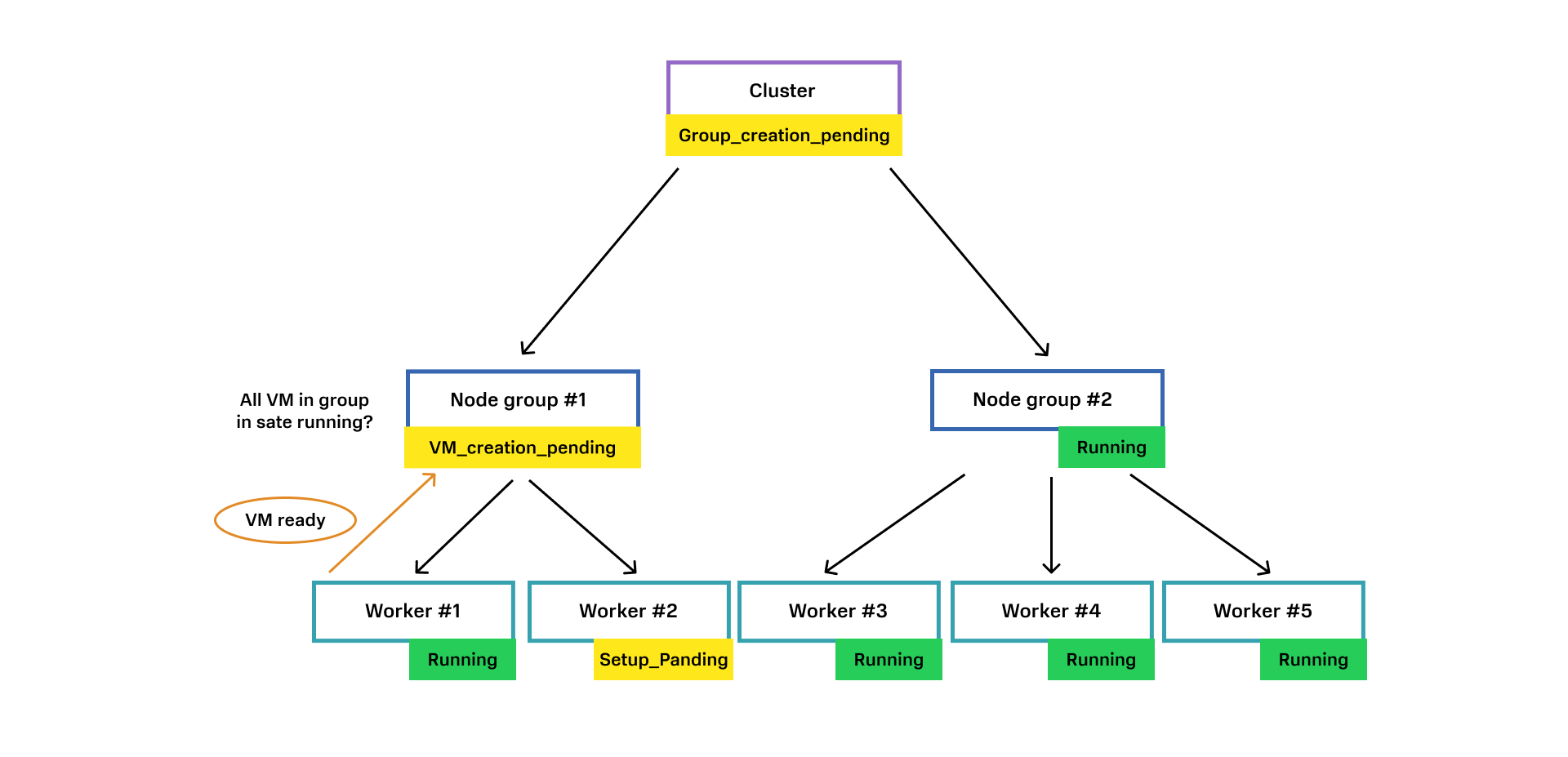
3. От сервиса виртуализации приходит событие о создании ВМ для Worker #2.

4. Worker #2 переходит в состояние Running и отправляет событие родительской сущности Node Group #1.

5. Родительская сущность Node Group #1 проверяет, все ли Worker’ы находятся в статусе Running. Если да, значит Node Group #1 тоже меняет состояние на Running.
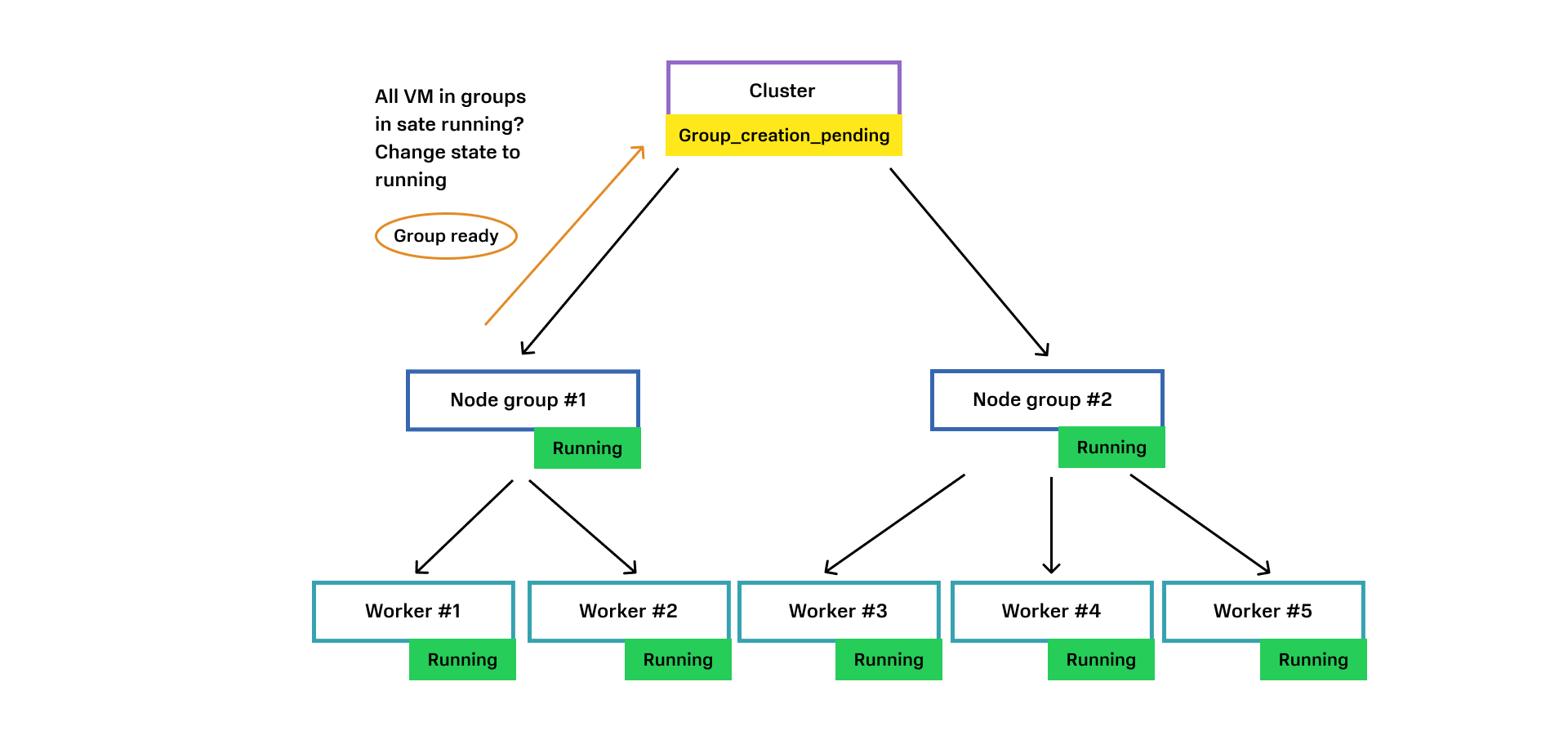
6. Node Group #1 отправляет своей родительской сущности Cluster событие о своем состоянии. Cluster проверяет, все ли Node Group готовы. В случае утвердительного ответа также меняет свое состояние на Running.
При обработке ошибок происходит похожий процесс:
1. Если приходит ошибка о том, что не получилось создать виртуальную машину, мы меняем статус Worker Node #1 и сообщаем родителю, что произошла ошибка.

2. Родитель Node Group #1 решает, что делать в этом случае: пересоздать одну ноду / удалить все ноды или отправить сообщение наверх своему родителю Cluster сообщение об ошибке. Тогда уже Cluster должен решать, что делать дальше.

Подытожим. Каждый доменный агрегат состоит из группы доменных сущностей. Конечный автомат состояний и переходов между ними описывает поведение каждой сущности. При этом изменение состояния каждой доменной сущности может вызывать события как вниз, так и вверх по древовидной структуре доменного агрегата.
Такая архитектура делает доменные сущности независимыми в своем поведении (логика состояний, действий и проверок не просачивается вниз или вверх по дереву), и при этом они связаны в рамках одного доменного агрегата.
Пару слов про то, что мы использовали для воплощения этой логики. Для FSM мы взяли статическую реализацию через switch. На наш взгляд, он не портит логику и читабельность кода. Если вы, как и мы, используете компилируемый язык (в нашем случае — Go), это дает дополнительные возможности для проверки при компиляции.
Состояния доменов хранятся персистентно в базе данных PostgreSQL.
Взаимодействие между сервисами происходит по модели CQRS (Command and Query Responsibility Segregation). Мы разделили все запросы на синхронные queries (Read operations) и асинхронные commands (CUD operations). Первые выполняются по протоколу gRPC, команды — через Apache Kafka.
Собственно распределенные транзакции
Выше мы разобрали, как схема с DDD и конечными автоматами работает с состояниями в одной доменной сущности и одном доменном агрегате (микросервисе). Теперь посмотрим, как тот же принцип работает в рамках распределенного процесса, охватывающего несколько доменных агрегатов, и как между ними будут передаваться данные о состоянии.
Для примера возьмем сервис управления кластером Kubernetes и сетевой сервис. Для развертывания кластера Kubernetes нужно создать балансировщик нагрузки. Для этого в домен, который отвечает за сеть, отправляется команда «создать LB с таким названием и параметрами». У этого Provisioning Service описан свой конечный автомат. Он по нему проходит, создает LB и сообщает о том, что все готово. Мы это сообщение принимаем в первом сервисе и переходим на следующее состояние.
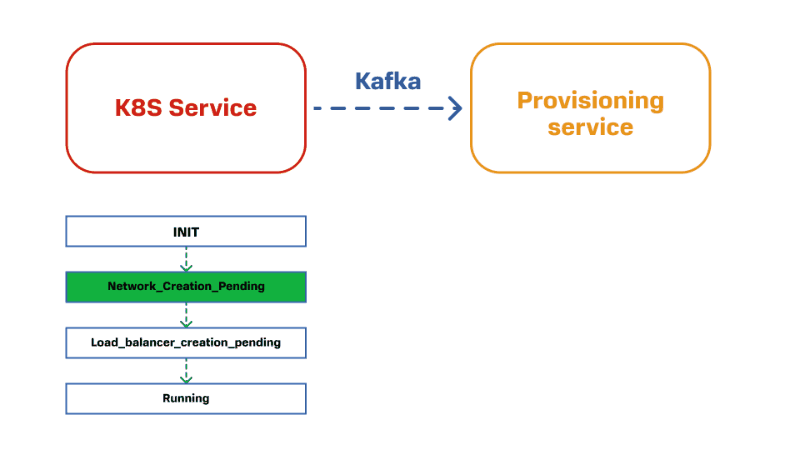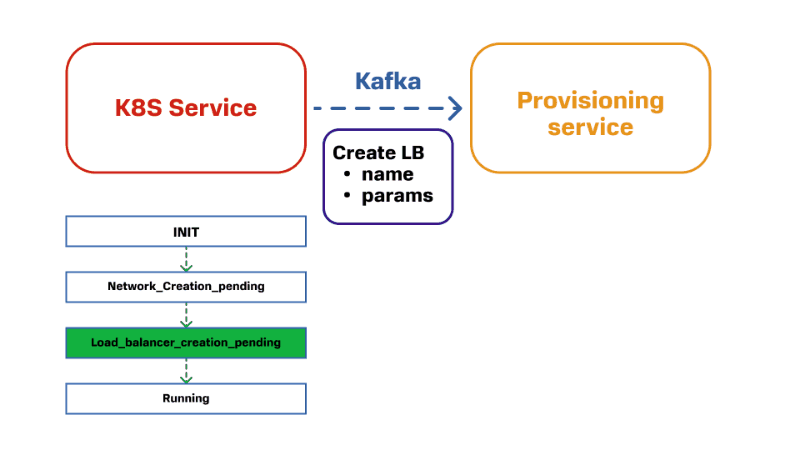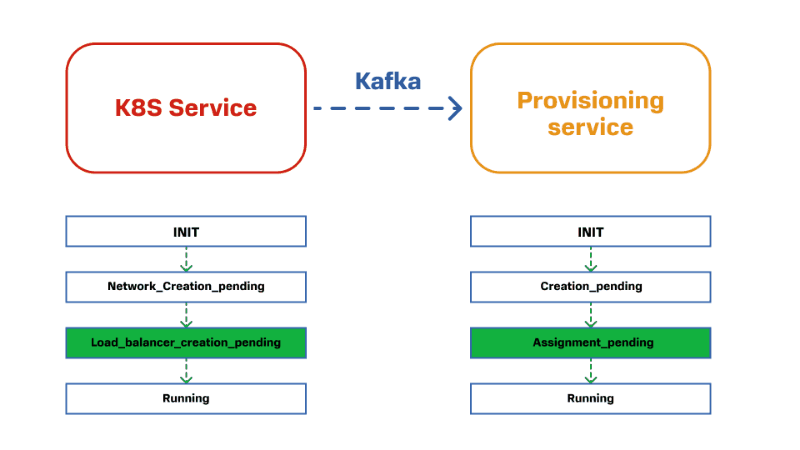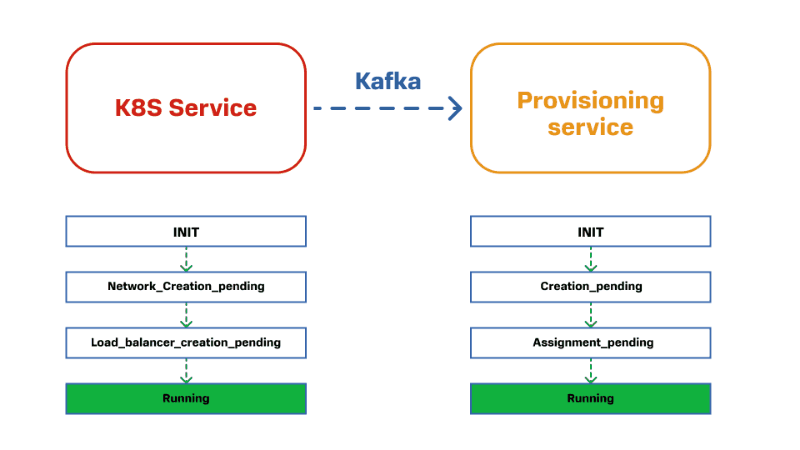
Если смотреть на это более укрупненно, то получается следующая картина:
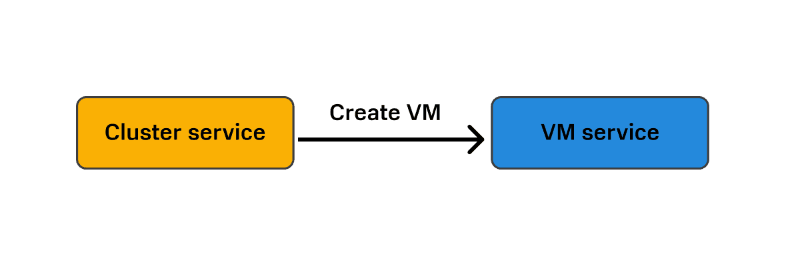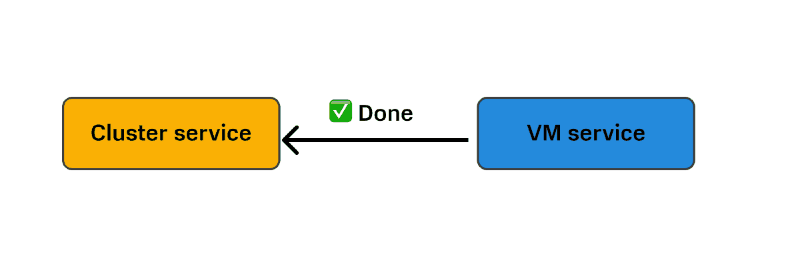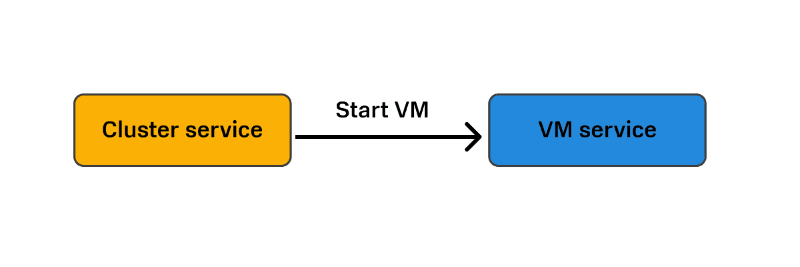
Вот эта цепочка операций между двумя сервисами и будет называться распределенной транзакцией. Ее атомарность обеспечивается тем, что у нас в любой момент времени есть состояние каждого компонента этой транзакции: каждой доменной сущности и каждого доменного агрегата, которые входят в эту транзакцию.
Это состояние хранится в базе данных соответствующего сервиса. Если что-то происходит не по плану, у нас есть четкий сценарий, описанный в виде конечного автомата.

При разворачивании кластера Kubernetes мы имеем дело с целой цепочкой таких транзакций. Например, когда Cluster service обращается к VM service, а он в свою очередь обращается к Virtualisation platform с тем, чтобы она запустила ВМ. Для Cluster service множество шагов выглядят как один шаг, и он не знает, что VM service обращается к Virtualisation platform.

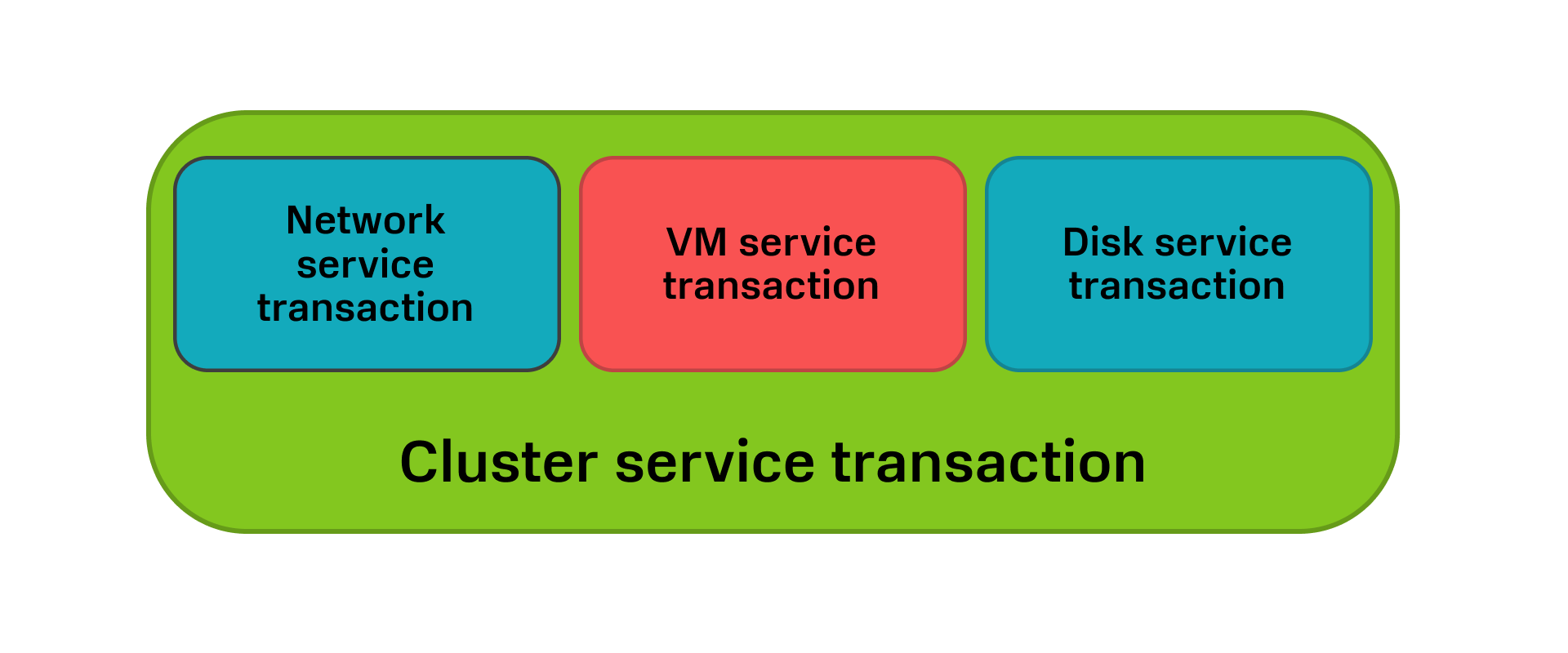
У нас получаются вложенные друг в друга транзакции: транзакция уровня Cluster service включает в себя более низкоуровневую транзакцию — VM service.
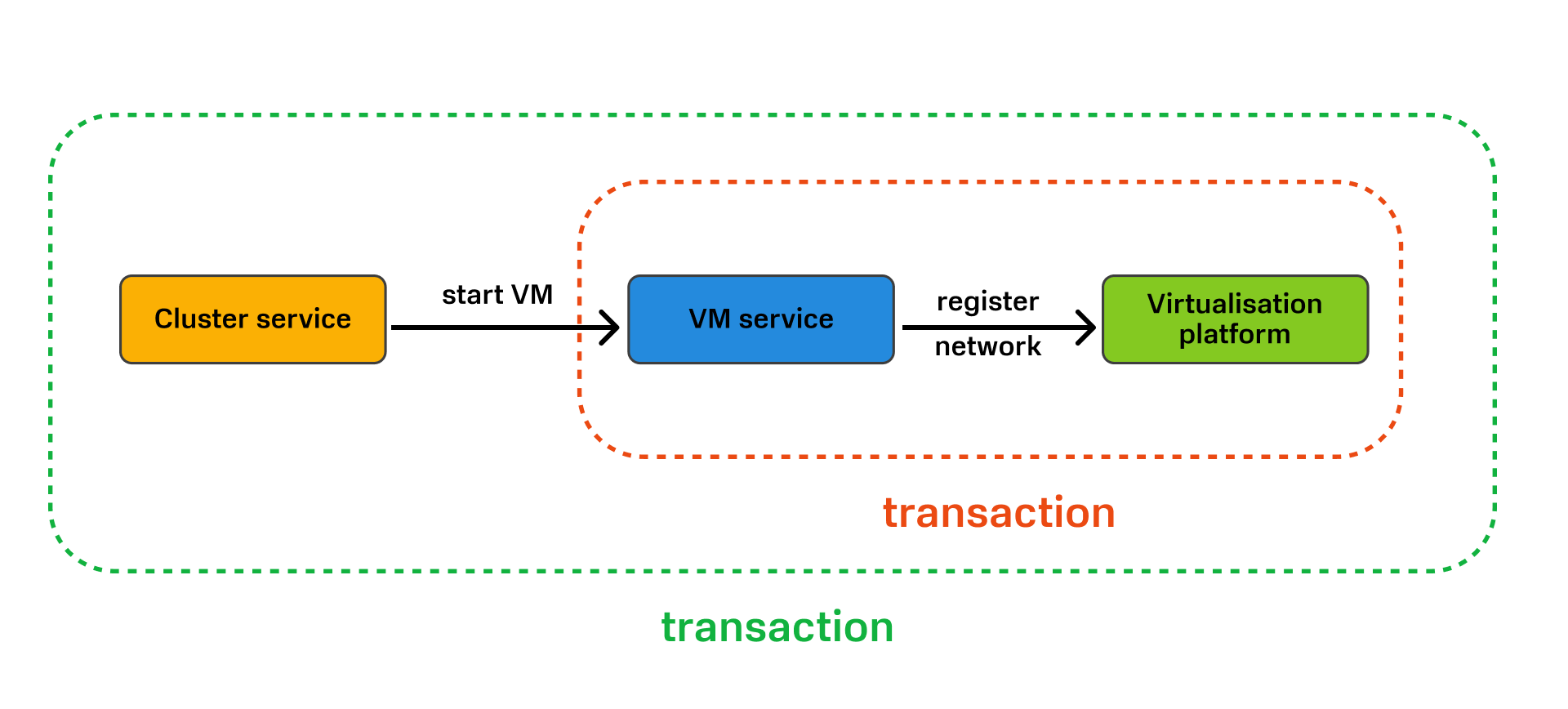
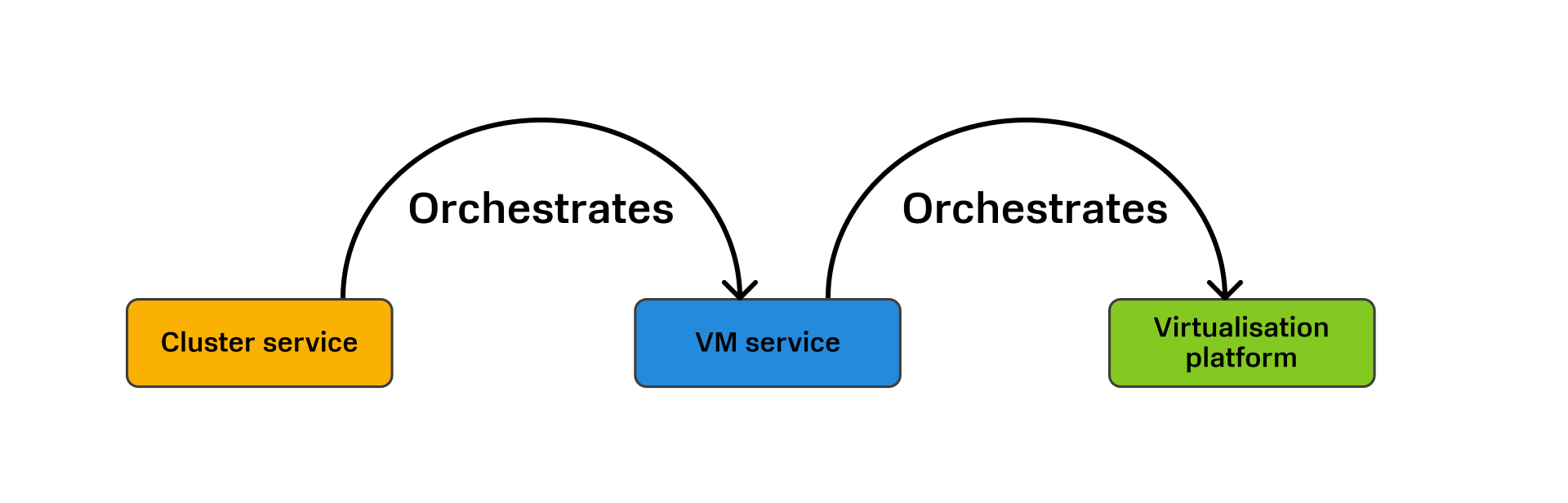
В итоге у нас получается, что cluster service «оркестрирует» VM service, а VM service «управляет» Virtualization platform.
Распределенная транзакция Cluster service может быть частью другой, более высокоуровневой транзакции.
Допустим, мы создаем какой-нибудь SaaS-сервис, для которого нужен кластер Kubernetes.
Тогда в ней будет спрятана транзакция по созданию кластера, где, как в матрешке, живут другие транзакции. Причем для более высокоуровневой транзакции это будет выглядеть как один шаг «Запросить создание кластера».
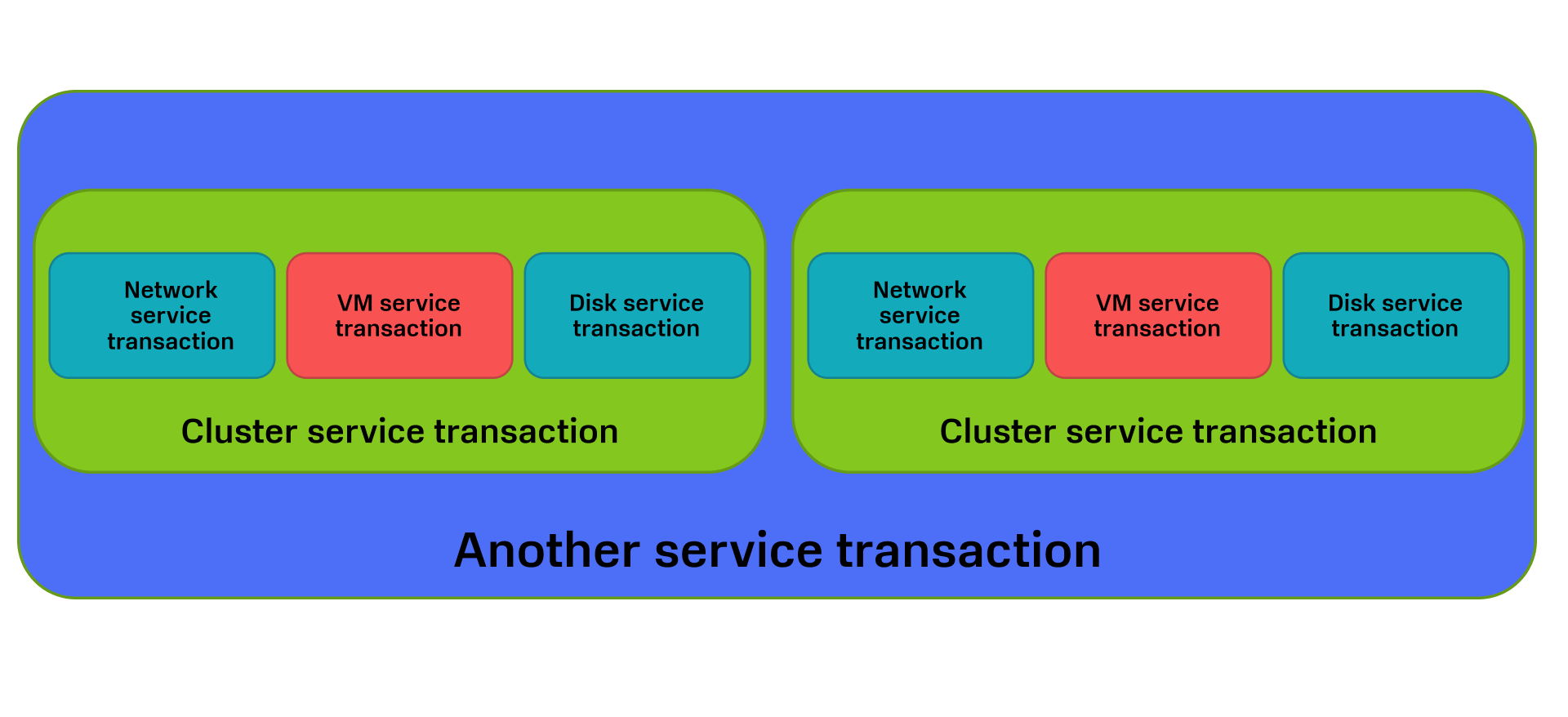
При чем тут саги?
Когда я предлагаю решить вышеописанную задачку на собеседовании, люди либо не знают, как это сделать, либо говорят: «Ой да сагу добавим, и все заработает». В действительности это не так.
Описанный подход действительно может напоминать хореографическую сагу. И это была бы она, если бы не одно но: в распределенной транзакции нет последовательности шагов, как в хореографический саге, зато есть много вложенных транзакций.
Кроме того, в хореографической саге нужно читать код разных сервисов, чтобы разобраться, как выполняется процесс. То есть мы не можем в каком-то одном месте увидеть целиком процесс, только реакцию на отдельные события. Поэтому с хореографическими сагами в случае поломок трудно понять, что именно сломалось, после какого деплоя процесс перестал работать.
В нашем случае весь процесс целиком в рамках отдельного домена можно посмотреть в одном месте.
Наша реализация также преодолевает ограничения и недостатки оркестрируемой саги. В ней, как понятно из названия, есть оркестратор, и он должен знать про все сервисы, которые задействованы в процессе. Получается, доменная логика сервисов просачивается в оркестратор. Это означает, что когда мы изменяем сервис, нам нужно менять и оркестратор.
В нашем решении нет оркестратора. Доменная логика сервиса А инкапсулирована внутрь сервиса А, она не выходит за его рамки. При этом домен А не знает про доменную логику внутри домена B. Он лишь знает некий контракт домена B, который заключается в том, что он может создать, удалить сеть/ВМ/LB, но никак не управляет тем, что внутри домена А. Такие же отношения между доменами B и С.
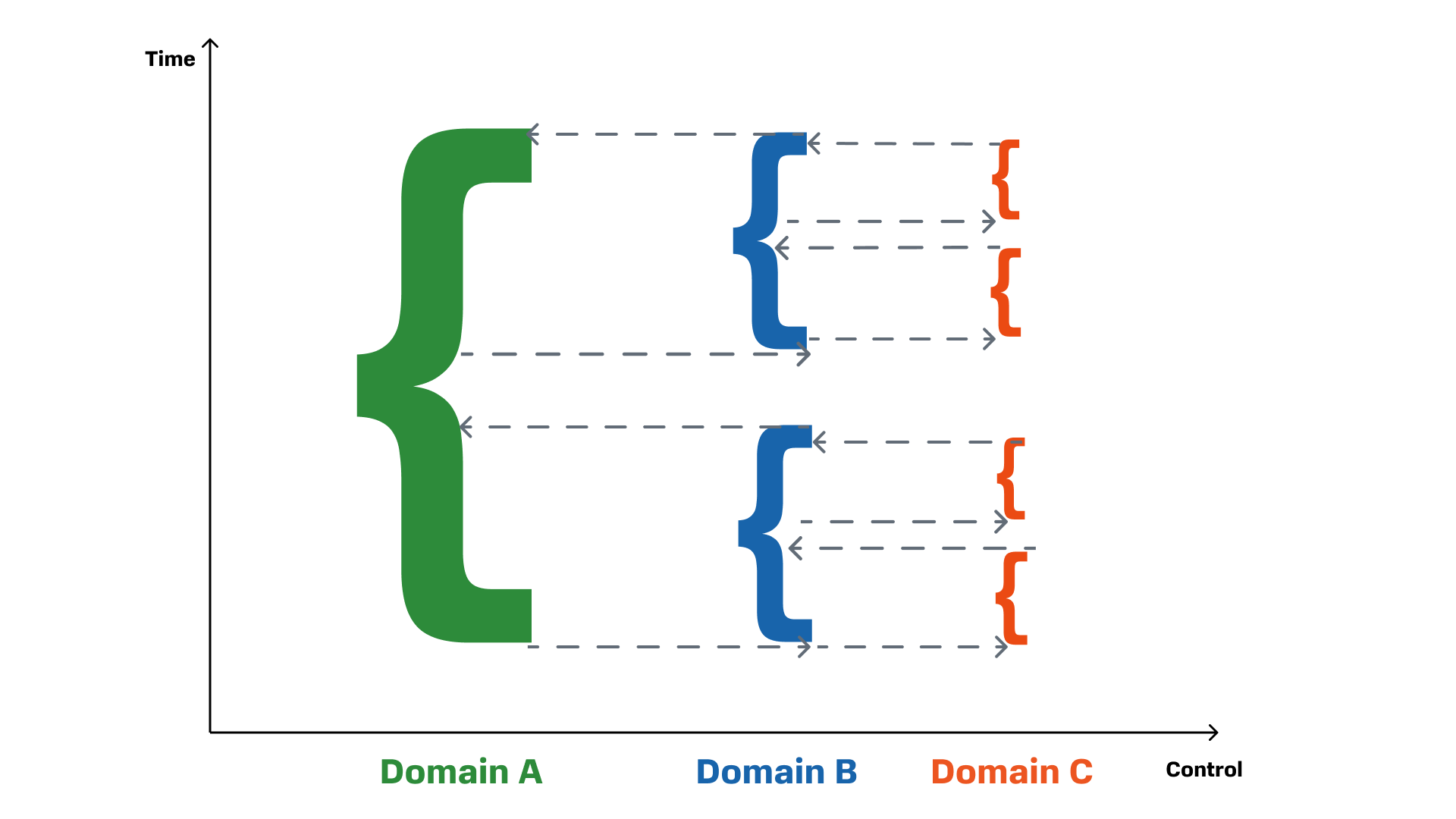
В итоге получается вот такое дерево транзакций. У нас есть корневая транзакция в корневом домене, к которому мы обращаемся, например, через API. Она порождает дочерние транзакции в других доменах, которые в свою очередь запускают транзакции в дочерних доменах. Каждый из этих слоев управляет только тем слоем/транзакцией, который он порождает. Управляет с точки зрения ее запуска, но не управляет тем, что внутри.
Что в итоге
Схема, которую мы получили с помощью доменной модели и конечных автоматов, помогла выстроить управление распределенными транзакциями в 200–300 шагов, которые могут отрабатывать минуты. Вот ее основные преимущества:
- Доменная логика «не вытекает» из домена, а доменные транзакции независимы. Это дает возможность комбинировать какие угодно сервисы и в каком угодно порядке.
- Домен не знает о внутренности других доменов. Если идем вверх по этой цепочке вызова, то мы знаем, кто нас вызывает, если вниз, то мы знаем только его контракт. В обоих случаях мы не знаем, что внутри другого домена, и нам не нужно управлять его транзакцией.
- Распределенная транзакция наблюдаема. Ее легко мониторить, легко добавить в какой-нибудь распределенный трейсинг, где будет видна вся транзакция, сервисы, которые в ней задействованы. Это нам позволяет за минуту находить и локализовывать ошибки в продакшене в экосистеме из пары дюжин микросервисов.
tessob
Из прочитанного я не совсем понял как именно выполнялись ролбеки, которые были упомянуты в самом начале, и как обеспечивалась работа параллельных транзакций, когда изменяются состояния разных объектов.
Color
Пояснительная бригада прибыла.
У каждого домена для каждого переходного состояния (то есть когда какой-то процесс происходит над сущностью) есть обработка "хорошего" и "плохого" сценария. Например, при создании ВМ в состоянии, когда мы ждем запуска ОС, в "хорошем" сценарии (при ответе, что ОС запущена), мы перейдем в следующее состояние, попутно затригеррив соответствующее действие. В "плохом" сценарии (при ответе, что произошла ошибка), мы переходим в соответствующее началу роллбека состояние, попутно запустив удаление ВМ. Для каждого отдельно взятого состояния конкретное действие будет разным, потому что в разных состояниях может понадобится выполнять разные действия для роллбека, но процесс роллбека запускается в любом случае, и проходит через все состояния, чтобы откатить/удалить сущность.
В случае всего доменного агрегата один домен (например, нода в кластере) начав или уже выполнив роллбек, сообщит родительскому домену (группа нод) о том, что произошло, и родительский домен в зависимости от своего состояния принимает решение, а что же делать дальше. Таким образом роллбек или другой процесс выполнится на всем доменном агрегате, причем может выполняться параллельно для разных доменов в одном агрегате.
Что касается разных доменов, то в случае ошибки в одном из них, он выполнит свой роллбек и вернет другому (по цепочке на последней картинке снизу-вверх) сообщение о том, что запрошенная операция завершилась ошибкой, и тот запустит свой процесс роллбека, и так произойдет по всей цепочке транзакций в этом дереве.
Мы используем CQRS для общения между доменами (читай, микросервисами), где команды отправляются асинхронно через брокер сообщений. Соответственно нам ничего не мешает отправить параллельно кучу таких сообщений (например, когда мы хотим одновременно создать набор похожих сущностей, но по каким-то причинам не используем батчинг), и потом при обработке ответов от них триггерим продолжение процесса, когда ответ придет ото всех.
В случае ошибки в одной из дочерних транзакций (снова см. последнюю картинку), мы также согласованно с состояниями FSM обрабатываем эту ошибку и решаем, что делать дальше в рамках домена, который инициировал операци.