

Я изучил, как реализовать функцию косинуса при помощи нескольких разных подходов. Одна из реализаций почти в три раза быстрее, чем math.h, но придётся смириться с точностью до четырёх знаков после запятой.
Задавались ли вы когда-нибудь вопросом, как в математической библиотеке вашего любимого языка программирования реализованы тригонометрические функции, например, косинус? Это настолько популярная функция, что её можно встретить в каждой математической библиотеке, поэтому реализация должна быть довольно простой, ведь так? Ну уж нет. Почти совершенно точно, что это не так.
Моё исследование началось с того, что мой друг и коллега Стивен Марц работал над ядром операционной системы и я предложил, чтобы он отрисовал на экране функцию косинуса. Я часто использую косинус в качестве «hello, world» для графических приложений. Возникла проблема: его ядро не задействовало стандартную библиотеку C (а значит, прощай math.h!), а целевой платформой являлась архитектура RISC-V (а значит, никаких подобий команды fcos Intel!).
Так началось моё долгое приключение.
Стоит сказать, что я не математик и не гуру программирования систем. На самом деле, за десять лет изучения в колледже математики и computer science я каким-то образом так и не прошёл курс тригонометрии. Поэтому я расскажу о своих трудностях изучения и реализации косинуса на C. Мои цели были следующими:
- Достаточно простая реализация, чтобы даже я мог понять код.
- Достаточно точная реализация, чтобы ни один смертный не заметил погрешности.
- Достаточно быстрая, чтобы её можно было использовать в видеоигре.
Мы изучим множество способов вычисления косинуса и несколько оптимизаций. Так как я не мастер языка C, то буду избегать сложных трюков и микрооптимизаций (но если вам они известны, то напишите мне!). На самом деле, я часто буду делать выбор в пользу более читаемого кода вместо чуть более производительного. В процессе работы мы будем проводить бенчмарки, чтобы понимать последствия своих действий. Весь код и бенчмарки можно найти в репозитории GitHub.
▍ Почему мне важен косинус?
За всё время кодинга косинус я использовал только в одной ситуации: игры, игры, игры.
function move(obj) {
obj.x += obj.speed * Math.sin(obj.rotation);
obj.y += obj.speed * Math.cos(obj.rotation);
}Это базовый код, который я использовал практически во всех своих играх для перемещения объекта в нужном направлении. Это мог быть игрок в виде сверху или летающие по экрану снаряды.
Визуально это выглядит так:

Возможно, не стоит смотреть слишком долго…
▍ Способы вычисления косинуса
Когда я решил забраться в эту потустороннюю кроличью нору, то обнаружил способ аппроксимации косинуса при помощи ряда Тейлора.

Похоже, это стандартный способ вычисления косинуса в математических уровнях, по крайней мере, в высокоуровневых. Чем больше членов, тем точнее будет аппроксимация.
Мне в голову пришла мысль об использовании таблицы поиска. Это массив предварительно вычисленных значений, в котором можно искать ближайшее значение косинуса для введённых данных. Во времена, когда вычислительные ресурсы были ограниченными, такой способ использовался довольно часто. Мне не удалось найти на GitHub проектов, в которых для тригонометрических функций используется таблица, но уверен, что они существуют.
Также в моих поисках часто встречался термин CORDIC. Это итеративный способ вычисления функций наподобие синуса и косинуса при помощи только сложения, вычитания, битового сдвига и небольшой таблицы поиска. Его часто реализовывали аппаратно, начиная с конца 1950-х, или в ПО, которое работало в маломощных CPU или микроконтроллерах, например, применяемых в калькуляторах. Этот способ был довольно популярен в прошлом, он использовался в математическом сопроцессоре Intel 8087, калькуляторах TI-85 и HP-48G. Однако я не смог найти ссылок на использование его сегодня. Подробнее о нём можно прочитать в статье Википедии или в исходной научной статье с описанием способа; также можно изучить его реализацию на C. Я не буду сравнивать свои способы с ним, но мне немного любопытно, насколько хорошо он себя проявляет. Вот иллюстрация из исходной статьи:
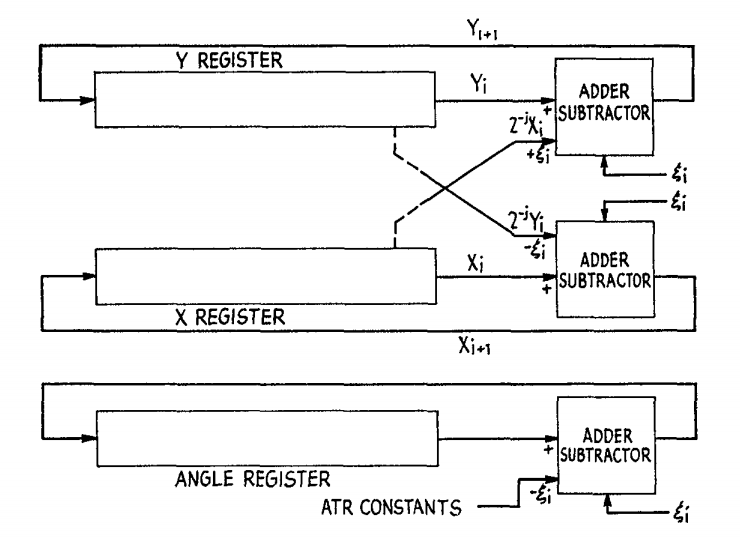
Также есть команда fcos процессоров Intel. Эта команда вычисляет косинус по значению с плавающей запятой в радианах в интервале от -2^63 до 2^63, сохраняемому в регистре FPU, и заменяет это значение результатом. Не знаю, используется ли по-прежнему в современных процессорах Intel способ CORDIC, а если да, то реализован ли он аппаратно или программно. Дизассемблировав несколько программ, использующих косинус, я не смог найти ни одной, задействующей команду fcos. Хотя она быстра, была задокументирована неточность этой команды, которая наиболее заметна, когда аргумент приближается к числам, кратным pi/2. Подробности можно прочитать в неофициальной документации или в официальной справке Intel.
Надо сказать, что любой человек в здравом уме и памяти воспользуется math.h языка C. И для повседневного использования, вероятно, так и нужно поступать. Но помните, что мы не можем использовать ничего из стандартной библиотеки. К тому же это было бы неинтересно. Я сравнил точность функции косинуса из math.h на своём компьютере с Wolfram Alpha. Выяснилось, что math.h точна до 15 знаков после запятой, а это больше, чем мне когда-либо понадобится.
Чтобы понять, как косинус вычисляет стандартная библиотека, я взглянул на исходники множества реализаций стандартной библиотеки C. Glibc, Newlibc, Musl и так далее. И хотя, похоже, во всех них использовался ряд Тейлора, мне сложно было во всех них разобраться. Все они сильно отличались друг от друга, часто использовали множество компактных функций, применяли магические числа, имели таблицы предварительно вычисленных значений и активно задействовали трюки с битами. Разработчики потратили много времени на то, чтобы сделать их быстрыми.
Вот скриншот того, как я изучал соответствующий код Musl. От cos() к __cos(), а потом к __rem_pio2().

Уф…
▍ Подготовка бенчмарка
В процессе реализации различных способов вычисления косинуса я буду сравнивать их по двум параметрам: времени выполнения и точности. Для проверки времени выполнения каждая функция вычисляется 100 миллионов раз с интервалом входных значений, время исполнения замеряется при помощи функции clock файла time.h. Для проверки точности я беру разность результатов моей функции и результатов math.h для всего интервала входных значений, и возвращаю наихудшее значение. Например, точность 0.0002 означает, что в наихудшем случае моя реализация для одного входного значения среди большого интервала значений на 0.0002 отличалась от результатов math.h.
Вот соответствующий код:
// Замеряем время выполнения в секундах. Чем меньше число, тем лучше.
double runtime(double (*func)(double))
{
clock_t start = clock();
for (int i = 0; i < 100000000; i++)
{
volatile double c = func(i / 10000.0);
(void)c;
}
return (clock() - start) / (double)CLOCKS_PER_SEC;
}
// Находим наихудший случай точности по сравнению с math.h. Чем меньше, тем лучше.
double accuracy(double (*func)(double))
{
double w = -1;
double start = 0;
double stop = CONST_2PI;
double step = 0.0000001;
for (double i = start; i < stop; i += step)
{
double c = absd(func(i) - cos(i));
if (c > w)
{
w = c;
}
}
return w;
}Бенчмарк компилировался при помощи clang 11.0.3 и запускался на 13-дюймовом MacBook Pro 2018 с CPU i7 на 2,7 ГГц и 16 ГБ ОЗУ.
Весь код бенчмарков можно найти в репозитории GitHub. Благодарю доктора Марца за то, что он переписал его, повысив удобство интерфейса.
▍ Первая попытка: наивный ряд Тейлора с литералами
Сначала я попробовал трансляцию ряда Тейлора с четырьмя членами:
double cos_taylor_literal_4terms_naive(double x) {
return 1 - ((x*x)/(2)) + ((x*x*x*x)/(24)) - ((x*x*x*x*x*x)/(720)) + ((x*x*x*x*x*x*x*x)/(40320));
}Он казался на удивление точным, когда я начал тестировать его со входными значениями наподобие 0.1 и 0.235. Мой энтузиазм угас, когда я сравнил его график с графиком math.h:
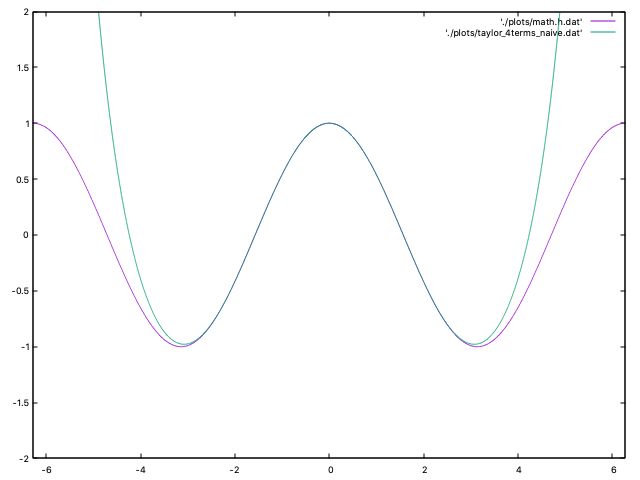
Фиолетовая линия — это math.h, а зелёная — моя функция. Между -pi и +pi она выглядит вполне неплохо, но потом начинаются резкие отклонения.
Возможно, поможет увеличение количества членов.
double cos_taylor_literal_6terms_naive(double x) {
return 1 - ((x*x)/(2)) + ((x*x*x*x)/(24)) - ((x*x*x*x*x*x)/(720)) + ((x*x*x*x*x*x*x*x)/(40320)) - ((x*x*x*x*x*x*x*x*x*x)/(3628800)) + ((x*x*x*x*x*x*x*x*x*x*x*x)/(479001600));
}Попробуем нарисовать график…

Гораздо лучше. Но всё равно при приближении к 2pi начинаются сильные погрешности.
▍ Вторая попытка: улучшенный ряд Тейлора с литералами
На этом этапе мне пришли в голову три возможных улучшения: уменьшение интервала входных значений, снижение количества избыточных вычислений и дальнейшее добавление новых членов.
Первым делом я попробовал уменьшить интервал. Чем больше входное значение, тем менее точен этот способ. Так как косинус повторяется каждые 2pi, нам достаточно просто выполнить x = x % (2*pi);. Однако в C оператор деления с остатком не работает с числами с плавающей запятой, поэтому мы создали собственный.
#define modd(x, y) ((x) - (int)((x) / (y)) * (y))
double cos_taylor_literal_6terms_2pi(double x)
{
x = modd(x, CONST_2PI);
return 1 - ((x * x) / (2)) + ((x * x * x * x) / (24)) - ((x * x * x * x * x * x) / (720)) + ((x * x * x * x * x * x * x * x) / (40320)) - ((x * x * x * x * x * x * x * x * x * x) / (3628800)) + ((x * x * x * x * x * x * x * x * x * x * x * x) / (479001600));
}Он показывает себя лучше для значений в пределах 2pi, но всё равно очень неточен при значениях, близких к 2pi. Можно улучшить ситуацию, потому что значения косинуса эквивалентны при каждом числе, кратном pi, меняется только знак. Мы можем выполнить mod на 2pi, вычесть pi, если значение больше pi, вычислить ряд Тейлора, а затем добавить нужный знак. То есть на самом деле мы вычисляем косинус только от 0 до pi.
double cos_taylor_literal_6terms_pi(double x)
{
x = modd(x, CONST_2PI);
char sign = 1;
if (x > CONST_PI)
{
x -= CONST_PI;
sign = -1;
}
return sign * (1 - ((x * x) / (2)) + ((x * x * x * x) / (24)) - ((x * x * x * x * x * x) / (720)) + ((x * x * x * x * x * x * x * x) / (40320)) - ((x * x * x * x * x * x * x * x * x * x) / (3628800)) + ((x * x * x * x * x * x * x * x * x * x * x * x) / (479001600)));
}Это помогло существенно улучшить точность при близких к 2pi входных значениях.
Следующая оптимизация включает в себя устранение некоторых избыточных вычислений. Можно заметить, что в коде часто используется x*x. Я всего лишь уменьшил количество умножений, добавив double xx = x * x;.
double cos_taylor_literal_6terms(double x)
{
x = modd(x, CONST_2PI);
char sign = 1;
if (x > CONST_PI)
{
x -= CONST_PI;
sign = -1;
}
double xx = x * x;
return sign * (1 - ((xx) / (2)) + ((xx * xx) / (24)) - ((xx * xx * xx) / (720)) + ((xx * xx * xx * xx) / (40320)) - ((xx * xx * xx * xx * xx) / (3628800)) + ((xx * xx * xx * xx * xx * xx) / (479001600)));
}Производительность существенно улучшилась! Также я попробовал double xxxx = xx * xx;, но не увидел особой разницы, поэтому двинулся дальше.
Я всё ещё не знал точно, сколько членов использовать, поэтому попробовал до десяти членов, чтобы проверить, как это улучшит точность:
double cos_taylor_literal_10terms(double x)
{
x = modd(x, CONST_2PI);
char sign = 1;
if (x > CONST_PI)
{
x -= CONST_PI;
sign = -1;
}
double xx = x * x;
return sign * (1 - ((xx) / (2)) + ((xx * xx) / (24)) - ((xx * xx * xx) / (720)) + ((xx * xx * xx * xx) / (40320)) - ((xx * xx * xx * xx * xx) / (3628800)) + ((xx * xx * xx * xx * xx * xx) / (479001600)) - ((xx * xx * xx * xx * xx * xx * xx) / (87178291200)) + ((xx * xx * xx * xx * xx * xx * xx * xx) / (20922789888000)) - ((xx * xx * xx * xx * xx * xx * xx * xx * xx) / (6402373705728000)) + ((xx * xx * xx * xx * xx * xx * xx * xx * xx * xx) / (2432902008176640000)));
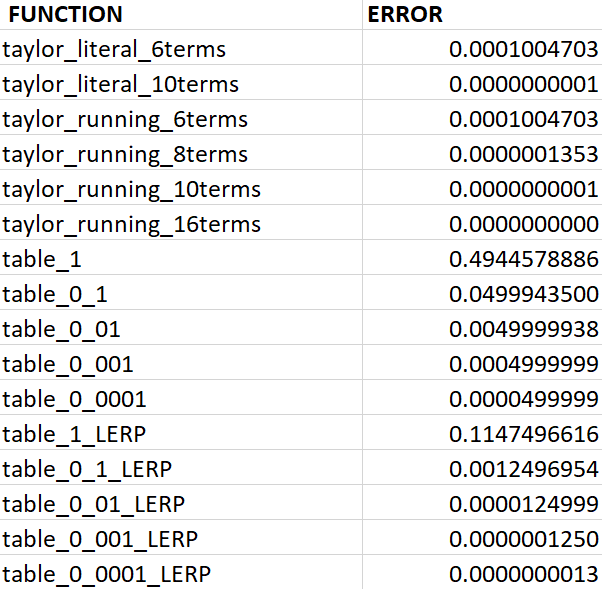
}После этого график с десятью членами начал полностью накладываться на math.h. Прогресс! При сравнении наихудшего случая точности с math.h четыре члена были ужасны. Шесть членов отличались на 0.0001, а это больше точности, чем мне нужно. Десять членов отклонялись всего на 0.00000000007. Ура!
Однако увеличение количества членов приводит к резкому росту времени исполнения. Судя по бенчмарку, наивное решение с четырьмя членами занимает всего 0,4 секунды, с шестью членами — 0,94 секунды, а с десятью — 1,46 секунды. А math.h требуется всего 1,04 секунды при большей точности.
Добавление новых членов при такой методике показалось мне довольно нелепым, поэтому я двинулся дальше.
▍ Третья попытка: ряд Тейлора со скользящим произведением
Когда я показал свои результаты доктору Марцу, он провернул какую-то алгебраическую магию и отправил мне свою модифицированную версию. В его методике устраняется большой объём избыточных вычислений благодаря сохранению результатов, а также появилась возможность указания количества нужных членов. В некоторых областях применения может быть удобно иметь параметр, управляющий степенью точности/скоростью.
double cos_taylor_running_yterms(double x, int y)
{
int div = (int)(x / CONST_PI);
x = x - (div * CONST_PI);
char sign = 1;
if (div % 2 != 0)
sign = -1;
double result = 1.0;
double inter = 1.0;
double num = x * x;
for (int i = 1; i <= y; i++)
{
double comp = 2.0 * i;
double den = comp * (comp - 1.0);
inter *= num / den;
if (i % 2 == 0)
result += inter;
else
result -= inter;
}
return sign * result;
}Ради бенчмарков я не использовал эту версию со вторым параметром. Вместо этого я дублировал функцию и прописал в цикле постоянные значения (например, 6, 10 и 16).
При добавлении новых членов точность возрастает крайне несущественно. При 16 членах наихудший случай точности отличается на 0.0000000000000009, однако бенчмарк времени исполнения занимает 2,57 секунды. Это ни в коем случае не медленно… если не сравнивать с math.h.
▍ Четвёртая попытка: таблица поиска
Мне хотелось попробовать способ с таблицей поиска. Смысл заключался в предварительном вычислении множества значений и записи их в массив. Таблицы поиска существовали задолго до компьютеров, поэтому методика не нова. В данном случае я надеялся, что увеличив объём используемой памяти, я получу большой рост скорости и обеспечу при этом достаточную степень точности.
Для генерации таблицы поиска доктор Марц написал скрипт на Python, генерирующий файл заголовка C, содержащий массив, в котором каждый элемент — это значение косинуса, вычисленное с помощью math.h. Очень умно!
from math import cos, pi
def main(f, PRECISION, NAME):
f.write("double %s[] = {\n" % NAME)
j = 0
p = 0.0
while True:
f.write("{:.20f}, ".format(cos(p)))
j += 1
p += PRECISION
if p > 2*pi:
break
f.write("1.0 };\n")
f.write("const int %s_size = %d;\n" % (NAME, j+1))
if __name__ == '__main__':
main(open("costable_1.h", "w"), 1.0, "costable_1")
main(open("costable_0_1.h", "w"), 0.1, "costable_0_1")
main(open("costable_0_01.h", "w"), 0.01, "costable_0_01")
main(open("costable_0_001.h", "w"), 0.001, "costable_0_001")
main(open("costable_0_0001.h", "w"), 0.0001, "costable_0_0001")Мы хотели протестировать таблицы с разной точностью, поэтому сгенерировали таблицы с 8 значениями, 64 значениями, 630 значениями, 6285 значениями и 62833 значениями. Расплачиваться за это пришлось ценой увеличения размера исполняемого файла. Влияние таблиц 1.0 и 0.1 незаметно, однако остальные таблицы увеличили размер исполняемого файла примерно на 5 КБ, 50 КБ и 500 КБ.
double absd(double a) { *((unsigned long *)&a) &= ~(1UL << 63); return a; }
double cos_table_0_01(double x)
{
x = absd(x);
x = modd(x, CONST_2PI);
return costable_0_01[(int)(x * 100 + 0.5)];
}Таблицы обеспечивают хороший баланс точности. Наихудший случай точности для самой маленькой таблицы составляет 0.49, то есть пользоваться ею нельзя. Но с каждым увеличением размера таблицы мы получаем на один знак после запятой больше точности: 0.049, 0.0049, 0.00049 и 0.000049. Тест времени исполнения для каждой таблицы равен примерно 0.38. А это быстро! (На самом деле, нам удалось снизить время исполнения примерно до 0.33, но код стал некрасивым.)
▍ Пятая попытка: таблица поиска с LERP
Да, таблица поиска — это отлично, но мы можем улучшить показатели для значений, которых в ней нет. Представляю вашему вниманию линейную интерполяцию. Звучит круто, но на самом деле это просто вычисление взвешенного среднего между двумя значениями. Если входного значения нет в таблице, мы вычисляем аппроксимацию на основании того, какой элемент таблицы ближе. Код:
#define lerp(w, v1, v2) ((1.0 - (w)) * (v1) + (w) * (v2))
double cos_table_0_01_LERP(double x)
{
x = absd(x);
x = modd(x, CONST_2PI);
double i = x * 100.0;
int index = (int)i;
return lerp(i - index, /* вес */
costable_0_01[index], /* нижнее значение */
costable_0_01[index + 1] /* верхнее значение */
);
}▍ Окончательное сравнение
Вот таблица сравнения наших функций при наихудшем случае точности по сравнению с math.h (чем меньше, тем лучше!):
А вот сравнение времени исполнения наших функций при вычислении 100 000 000 значений (чем меньше, тем лучше!):

▍ Вывод
Так что же мы порекомендуем использовать? По возможности math.h. Ни одна из этих функций не является особо медленной, а большинство из них достаточно точно. Но когда в следующий раз я буду делать игру, активно использующую тригонометрические функции, то воспользуюсь таблицей 0_001.
До встречи в новой кроличьей норе!

Комментарии (28)
leshabirukov
19.06.2023 14:08+5Ваша спираль эпилепсии, - как раз отличный случай применить CORDIC, но не в версии "цифра за цифрой", а в версии "посчитать синусы и косинусы последовательных близких углов".
Честно посчитав (co)sin(x0=0) используйте формулу
sin (x+a) = sin(x) + a*cos(x) cos (x+a) = cos(x) - a*sin(x)Здесь **a**-постоянное приращение угла, то есть, малая константа, в идеале - степень двойки, собственно, именно тогда умножение превращается в элегантный сдвиг.
То есть, для каждого следующего угла сохраняйте и используйте в расчётах синус и косинус предыдущего.

AetherNetIO
19.06.2023 14:08+3Для вычисления ряда значений можно применить аналогию рисования линии брезенхема. Для функций с максимальным значением модуля производной не больше единицы в дискретном пространстве будет точно вычислять

VT100
19.06.2023 14:08+5Трэш начинается уже в ряду Тейлора. Уж на что я - не математик и то - знаю о симметрии и периодичности тригонометрических функций. Дальше читать не стал.

sim31r
19.06.2023 14:08+1Если вычислять четверть периода, может быть разрыв при стыковке непрервыной функции, или проблема с первой и второй производной в точках стыковки.



alex-open-plc
19.06.2023 14:08+1Ну уж коль была попытка найти таблицы, то это хорошо забытое старое... Таблицы Брадиса.
И да, вычисления можно свести к целым числам.

dph
19.06.2023 14:08Ну, не настолько забытое.
Насколько помню, в MSX для тригонометрических функций как раз использовались таблицы с интерполяцией.

NeoCode
19.06.2023 14:08А вот интересно, есть ли достаточно эффективный (но не табличный) способ вычисления синуса и косинуса для чисел с фиксированной точкой (т.е. обычный целочисленный тип, где INT_MAX принят за 1)? Для простоты пусть будет даже обычный int8.
Интересно в том числе на аппаратном уровне: наверное можно составить таблицу истинности, по ней провести оптимизацию через карты Карно и попытаться вывести битовую формулу, из которой уже можно составить схему некоего синусатора на логических элементах, преобразующего int8 значение угла в int8 значение синуса.

Refridgerator
19.06.2023 14:08На Zx Spectrum кто-то делал, но не факт, что без таблиц. На современных процессорах вряд ли можно преимущество по скорости получить, единственный смысл — когда точность больше 15 цифр требуется.
NeoCode
19.06.2023 14:08Мне в этом вопросе интересна скорее сама математическая суть данного процесса. Как будет выглядеть логическая схема для синуса, будет ли она простой и элегантной или бессистемным нагромождением и мешаниной элементов, будут ли в ней какие-то закономерности, позволяющие ее масштабировать на большие разрядности и т.д.
sim31r
19.06.2023 14:08+2Ряд Тейлора из статьи чем плох? пара умножений и деление на число кратное 2. Деление на 2! это сдвиг побитовый числа вправо например.
Как вариант промежуточный вариант с упрощенным рядом Тейлора из одного члена и таблицей из нескольких значений. Или линейной / квадратичной апроксимацией между значениями таблицы. Можно подобрать баланс между размером таблицы и сложностью вычислений.
У меня для микроконтроллеров была идея сделать 2-3 таблицы. Первая, например 10 абсолютных значений функции. Потом 10 значений первой производной. Потом 10 значений второй производной. И результат соответственно
Y = K1 + dX*K2 + dХ^2*K3
где K значения из таблиц, dX расстояние между узлом записанным в таблицу и значением на входе. Если они совпадают, то dx=0 и значение берется сразу из таблицы первой. Плюс вручную можно оптимизировать таблицу, например K3 обнулить в начале синусоиды, нам небольшой изгиб и хватает линейной интерполяции, синус почти как прямая линия. Тогда и лишнее умножение не потребуется.

Dukarav
Вспоминается анекдот "А Вы куда звонили, сэр?"
Встроенные в язык sin, cos или, например, арктангенс, для процессоров x86 естественно реализуются встроенными функциями FPU. Именно для этого они в FPU и вводились. Другое дело, что для игрушек часто достаточно очень приближенных значений.
В FPU есть также замечательная функция sincos, которая сразу считает и sin и cos, быстрее, чем отдельными расчетами. При этом sin и cos часто идут такими парами, например, в комплексных числах.
В используемом нами PL/1-KT из-за этого даже добавлена встроенная функция sincos и она активно используется, например, при расчете орбитальных данных.
А автору статьи (который сам признается, что не математик) остается пожелать познакомиться с полиномами Чебышёва, о которых он, похоже, не слышал.
vadimr
Современные процессоры поддерживают инструкции FPU 8087 для совместимости, но в новых программах они не используются. Отчасти это связано с повсеместным более-менее буквальным внедрением стандарта IEEE 754, не предусматривающего 80-битных чисел, как в 8087, зато налагающего очень строгие требования на совпадение результатов вычислений с математически предсказываемыми.
Насколько мне известно, синус и косинус в современных компиляторах для x86_64 вычисляются библиотечными процедурами на основе наборов команд SSE*.
Что касается содержания статьи, то исходно ясно, что для небольшой точности достаточно таблицы.
Dukarav
Команды SSE* предназначены для параллельного выполнения одной операции с разными наборами операндов и непосредственно отношения к алгоритмам вычисления триногометрических функций не имеют. Насколько мне известно, в современных FPU триногометрические функции вычисляются полиномами Чебышёва, а квадратный корень - по методу Ньютона.
vadimr
Я глубоко не вникал, но думаю, что вычисление полинома Чебышёва векторизуется и в таком качестве обрабатывается. Ну и SSE* просто включает набор операций вещественной арифметики, ничто на худой конец не мешает их выполнять в том числе и над векторами из единственного элемента.
Вот, к примеру, что происходит в gfortran:
Вызывается некая подпрограмма _sin, обменивающаяся значениями через SSEшный регистр XMM0.
Dukarav
А у меня в системной библиотеке вот так
Refridgerator
marsianin
SSE это ещё и скалярные операции. И прочитайте наконец интеловское руководство по оптимизации. Там чёрным по белому написано: не используйте инструкции x87 FPU, они медленные, и сохранены только для совместимости со старым софтом.
Dukarav
Если Вы имеете ввиду "Intel® 64 and IA-32 Architectures
Optimization Reference Manual", то там не говорится, что "сохранены только для совместимости". Там, например утверждается, что
А кроме этого, изначально речь шла о триногометрических функциях, которых нет в SSE. Единственная команда FCOS во время выполнения не обращается к памяти, что сейчас очень ускоряет работу. Кстати, во время ее выполнения можно заниматься, например, целыми вычислениями.
Использование 80 бит в FPU вместо 64 в SSE2 замедляет работу, но зато намного корректней результат округляется до 64 бит.
И если в игрушках этого не требуется, то во многих задачах требования к точности сосвсем другие. Например, один градус отклонения от надира на высоте орбиты МКС - это 7 км на поверхности Земли. В игрушке наплевать, что монстр чуть-чуть не там, где был бы "в натуре". А в реальных задачах может и не наплевать.
Поэтому вычисления FPU более точные, а для триногометрических (и трансцендентных) функций и более быстрые.
marsianin
Почему-то у меня в документе написано другое: "Scalar floating-point SIMD instructions have lower latencies than equivalent x87 instructions. Scalar SIMD floating-point multiply instruction may be pipelined, while x87 multiply instruction is not. Although x87 supports transcendental instructions, software library implementation of transcendental function can be faster in many cases."
Refridgerator
Это не так. FPU не используют те, кому он не нужен. А кому нужен, те возмущаются его отсутствием у компилятора от Майкрософта. Если бы он был только для обратной совместимости — его бы не стали добавлять в 64-х битный режим. Однако он там есть. Вот если бы Интел в SSE добавили 128-битный формат с плавающий точкой — вот тогда бы да, можно было бы списывать FPU. Но увы.
Jianke
Если считать через CUDA, скорость насколько будет лучше/хуже?
Refridgerator
Если только один синус — то конечно хуже, надо же данные сначала отдать в GPU, а затем забрать, это всё дорогостоящие накладные расходы. Если миллион синусов — то конечно лучше. Ну и есть нюанс, что не все GPU поддерживают double, хотя накостылять повышенную точность через 2 single при желании можно.
vadimr
CUDA предназначена для векторно-конвейерных вычислений с большим объёмом одинаковых операций. На одиночной операции инициализация займёт гораздо дольше времени, чем сама операция.
slonopotamus
Не гуглится :(
JustMoose
Возможно вот этот: https://www.anekdot.ru/id/-321919003/