

Недавно я прочитал статью, в которой автор на простом примере рассказывает, как работает алгоритм распознавания движения. Это напомнило мне собственные исследования алгоритмов аналитики видео-потоков. Многие знают, что существует отличный проект OpenCV. Это обширная кроссплатформенная библиотека компьютерного зрения, содержащая множество различных алгоритмов. Однако разобраться в ней не так уж просто. Можно найти множество публикаций и примеров о том, как и где использовать машинное зрение, но не о том, как оно устроено. А именно этого часто и не хватает для понимания процесса, особенно когда только начинаешь изучать данную тему.
В этой статье я расскажу про архитектуру видеоаналитики.
Общая схема работы анализа видеоизображения представлена ниже.
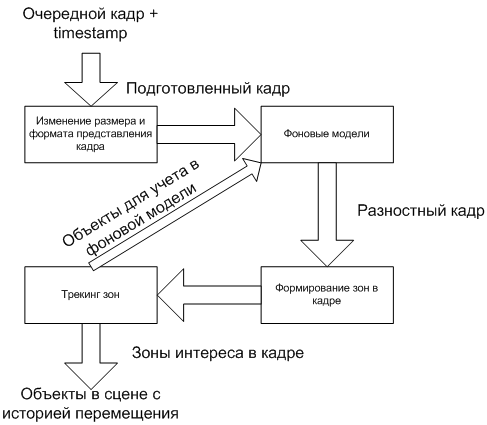
Процесс делится на несколько последовательных этапов. На выходе каждого из них информация о происходящем в кадре дополняется все большими деталями. Также могут быть обратные связи между этапами, чтобы более тонко реагировать на изменения в кадре.
Рассмотрим схему более детально.
Что такие видео-поток
Для начала нужно определиться, что же такое видео-поток. Хотя существует множество форматов видео-данных, суть их сводится к одному: последовательности кадров с определенной частотой в секунду. Кадр — изображение, характеризующееся разрешением и форматом (количеством бит на пиксель и их интерпретацией: какие биты за какую составляющую цвета отвечают). Внутри потока может быть использовано сжатие кадров для уменьшения объема передаваемых данных, но при показе на экране кадры всегда разжимаются до исходного состояния. Непосредственно алгоритмы аналитики всегда так же работают с несжатыми кадрами.
Таким образом видео поток характеризуется частотой кадров, их форматом и разрешением.
Важно отметить, что аналитика всегда в одно и то же время имеет дело только с одним кадром. То есть они обрабатываются последовательно. Кроме того, при очередной обработке, важно знать, сколько прошло времени после предыдущего кадра. Эту величину можно вычислить из частоты, но более практичным подходом является сопровождение кадра временной меткой — timestamp.
Изменение размера и формата представления кадра
Первым этапом является подготовка кадра. Как правило, он значительно уменьшается в размерах. Дело в том, что в дальнейшей обработке будет участвовать каждый пиксель изображения. Соответственно, чем меньше кадр, тем быстрее все будет работать. Естественно, при сжатии теряется часть информации в кадре. Но это не критично, а даже полезно. Объекты, с которыми работает аналитика, в основном достаточно большие, чтобы не пропасть из кадра при сжатии. А вот всевозможный “шум”, связанный с качеством камеры, освещенностью, природными факторами, будет уменьшен.
Изменение разрешения происходит путем объединения нескольких пикселей исходного изображения в один. От способа объединения зависит та часть информации, которая будет сохранена.
Например, квадрат 3х3 пикселя исходного изображения должен быть преобразован в один пиксель результата. Можно просуммировать все 9 пикселей, можно взять сумму только 4-х угловых пикселей, а можно только один центральный.
4 угловых пикселя:

Сумма всех пикселей:

Центральный пиксель:

Результат будет везде немного отличаться и по скорости и по качеству. Но иногда бывает так, что способ, теряющий больше информации, дает более ровную картинку, чем тот, который использует все пиксели.
Другим действием на данном этапе является изменение формата изображения. Цветные изображения, как правило, не используются, так как это тоже увеличивает время обработки кадра. Например, RGB24 содержит 3 байта на каждый пиксель. А Y8 только один, при этом не намного уступая в информативности первому.
Y8=(R+G+B)/3.
В результате получится то же изображение, но в градациях серого:


Фоновые модели
Это самый важный этап обработки. Целью данного этапа является формирование фона сцены и получение разности между фоном и новым кадром. От алгоритмов этого этапа будет зависеть качество работы всей схемы в целом. Если какой то объект будет принят как фон или наоборот часть фона будет выделена как объект, то дальше исправить будет уже что-то сложно.
В самом простом случае как фон можно взять кадр с пустой сценой:

Выберем кадр с объектом:

Если перевести эти кадры в Y8 и вычесть из кадра с объектом фон, то получим следующее:

Для удобства можно произвести бинаризацию: заменить значение всех пикселей больших 0 на 255. В итоге из градации серого мы перейдем к черно-белому изображению:

Вроде бы все хорошо, объект отделен от фона, имеет четкие границы. Но, во-первых, выделилась и тень объекта. А во-вторых, вверху кадра видны артефакты от шума изображения.
На практике такой подход никуда не годится. Любая тень, блик света, изменение яркости камеры испортят весь результат. Именно в этом и заключается вся сложность задачи. Объекты должны быть отделены от фона, при этом необходимо игнорировать природные факторы и шумы изображения: световые блики, тени от зданий и облаков, колеблющиеся ветки растений, артефакты сжатия кадров и т.д. При этом если вы ищите оставленный предмет, то наоборот, он не должен стать частью фона.
Существует множество алгоритмов, решающих эти проблемы с разной эффективностью. От простого усреднения фона до использования вероятностных моделей и машинного обучения. Многие из них есть в OpenCV. Причем можно и комбинировать несколько подходов, что даст еще лучший результат. Но чем сложнее алгоритм, тем больше времени занимает обработка очередного кадра. При живом видео хотя бы в 12.5 кадров в секунду у системы есть только 80 мс на обработку. Поэтому выбор оптимального решения будет зависеть от задачи и ресурсов, выделенных на ее выполнение.
Фоновые модели
Разностный кадр сформирован. Мы видим на нем белые объекты на черном фоне:


Теперь нужно отделить объекты друг от друга и сформировать зоны, объединяющие пиксели объектов:

Это можно сделать используя, например, connected component labeling.
Тут сразу становятся видны все недостатки фоновой модели. Человек сверху разделен на несколько частей, много артефактов, тени от людей. Однако часть этих недостатков можно исправить на данном этапе. Зная область объекта, его высоту и ширину, плотность пикселей, можно отфильтровать лишние объекты.
На кадре сверху синими рамками указаны объекты, которые участвуют в дальнейшей обработке, а зелеными — отфильтрованные. Тут тоже возможны ошибки. Как видно, человек сверху, разделенный на несколько частей, тоже был отфильтрован из-за своих размеров. Эту проблему можно решить, например, за счет использования перспективы.
Возможны и другие ошибки. Например, несколько объектов могут быть объединены в один. Так что и на данном этапе есть большое поле для экспериментов.
Трекинг зон
Наконец на последнем этапе зоны превращаются в объекты. Тут используется результат обработки нескольких последних кадров. Главная задача – определить, что зона на двух соседних кадрах является одним и тем же объектом. Признаки могут быть самые разнообразные: размер, плотность пикселей, цветовые характеристики, предсказание направления движения и т.д. Тут-то и важны временные метки кадров. Они позволяют вычислить скорость объекта и пройденное им расстояние.
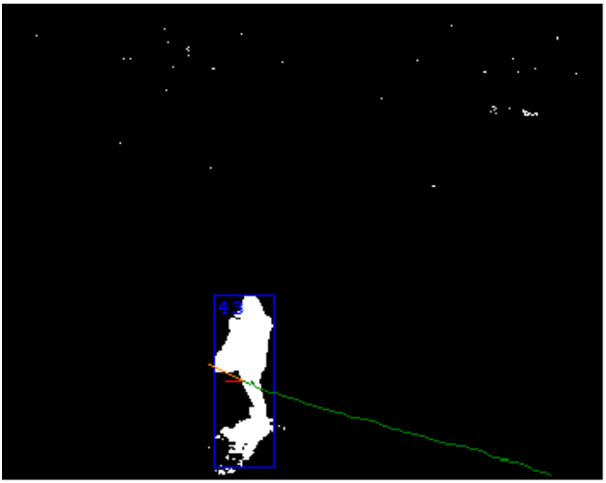
На данном этапе можно исправить разовые ошибки предыдущего. Например, склеенные объекты можно разделить, учитывая их историю движения. С другой стороны, тут возможны проблемы. Самая главная из них — пересечение 2-х объектов. Частный случай этой проблемы, когда больший объект на длительное время заслоняет меньший.
Объекты для учета в фоновой модели
В архитектуре могут присутствовать обратные связи, улучшающие работу предыдущих этапов. Первое, что приходит на ум — использовать информацию об объектах в сцене при формировании фона.
Например, так можно отличить отставленный предмет и не делать его частью фона. Или бороться с “призраками”: если при создании фона на сцене был человек, то когда он уйдет, на его месте появится объект-“призрак”. Понимая, что в этом месте начинается траектория движения объекта, можно быстро убрать “призрака” в фон.
Результат
Результатом работы всех этапов является список объектов в сцене. Каждый из них характеризуется размерами, плотностью, скоростью, траекторией, направлением движения и другими параметрами.
Этот список и используется при аналитике сцены. Можно определить пересечение объектом линии или движение в неправильном направлении. Можно подсчитать количество объектов в заданной зоне, праздное шатание, падение и множество других событий.
Заключение
Современные системы видео-аналитики достигли очень хороших результатов, однако до сих пор они остаются сложным многоступенчатым процессом. Причем знание теории далеко не всегда дает хороший практический результат.
На мой взгляд, создание хорошей системы машинного зрения — это очень сложный процесс. Настройка алгоритмов — очень трудоемкое и долгое дело, в которое вмешиваются еще и тонкости программной реализации. Тут требуется множество экспериментов. И, хотя OpenCV в этом деле бесценна, она не является гарантом результата, потому что инструментами, которые она содержит, нужно еще суметь правильно воспользоваться.
Надеюсь, что данная статья поможет понять как это все работает и какие инструменты OpenCV на каких этапах можно применить.
Комментарии (3)

mkarev
21.11.2015 19:14Собственно про аналитику ничего не сказано.
Как именно определить «падение», «праздное шатание», драку, пожар, и т.д., и т.п.?
В статье описан способ дешевой сегментации без конкретики как бороться с возникающими при этом проблемами (смена освещения, тени, перекрытия)
PS: Если исходное видео кодированное, то необходимость расчета яркости отпадает, кадры там уже в цветовом формате YUV. Плюс для снижения вычислительных затрат на сегментацию, можно использовать синтаксические элементы из кодированного видеопотока, например, векторы движения.
Kwent
А почему использована упрощенная модель перевода в градации серого, а не какая-нибудь каноничная с коэффициентами типа такой: Y' = 0.299 R + 0.587 G + 0.114 B?
AlexandrSurkov
Это просто пример. Основная цель статьи — рассказать зачем нужно делать те или иные вещи. А уж как именно их делать — это тема для целой книги, например такой :)