
Приветствуем читателей Хабра! Мы, команда дата-сайентистов и дата-аналитиков компании «ДатаЛаб»* (ГК «Автомакон»), запускаем серию статей, в которых поднимем актуальные темы и предложим свои решения проблемных ситуаций онлайн-ритейла. Каждый день мы решаем бизнес-задачи ритейла по повышению продаж, сокращению издержек и управлению рисками.
Стартуем со статьи, в которой рассмотрим одну из самых распространенных проблем в онлайн-ритейле – отсутствие товара (out-of-stock) в моменте и поделимся рекомендациями по ее устранению.
В статье мы описываем наш реальный опыт – проект для российской сети магазинов и сервиса бесплатной доставки«ВкусВилл».
Опустим лирическое введение про современный и динамичный мир, где практически вся деловая и бытовая активность перенесена в онлайн. Перейдем к делу и поместим в контекст: вы сами, скорее всего, не раз оказывались в ситуации, когда в онлайн-магазине при поиске нужного товара или в карточке товара встречали надпись, сообщающую об его отсутствии в магазине в данный момент. Отметим, что эта проблема намного опаснее именно в онлайн-ритейле, чем в офлайн-рознице. В магазинах можно быстро убрать ценник и выставить другие позиции на место закончившегося товара. В онлайн-магазинах зачастую товар, которого «нет в наличии», остается в каталоге и находится в поиске. И вот представьте или вспомните свой опыт: люди, полные надежд на успешную покупку, проваливаются в карточку такого товара и сталкиваются с разочарованием, потому что не могут его приобрести.
Острота проблемы и варианты решения
В ритейле отсутствие товара даже в течение нескольких минут может привести без преувеличения к катастрофе. Клиенты недовольны – сразу уходят за товаром в другой магазин на время или же навсегда, что моментально негативно отражается на доходах компании. Подобные ситуации отрицательно влияют и на репутацию магазина. Что можно подумать о магазине, в котором часто нет того, что нужно?
Причин возникновения проблемы out-of-stock может быть несколько: пиковый спрос, задержки в поставках, ошибки в управлении запасами, технические проблемы. Хорошая новость в том, что все решаемо. Опишем некоторые варианты устранения описанной проблемы:
1. Автоматический подбор аналогов
Один из вариантов решения проблемы отсутствующих товаров в ритейле – использование моделей машинного обучения для автоматического подбора аналогов. Система анализирует данные о покупателе, товаре и его характеристиках, чтобы подобрать наиболее подходящий аналог товара.
2. Система предварительного заказа
Ритейлеры могут использовать систему предварительного заказа, которая позволяет покупателям заказать отсутствующие на данный момент товары. Когда товар появится в наличии, он автоматически отправится покупателю.
3. Система оповещения о поступлении товара в продажу
Ритейлеры могут использовать систему оповещения, которая уведомляет покупателей о появлении товара в продаже. Это может быть полезным для покупателей, которые хотят получить определенный товар, но не знают, когда он появится в магазине.
4. Использование аналогов товаров из других магазинов
Ритейлеры могут использовать аналоги товаров из других магазинов для замены отсутствующих товаров. В этом случае необходимо согласование между магазинами и покупателем.
5. Внутренняя резервация товара
Ритейлеры могут сделать внутреннюю резервацию товара для покупателя, чтобы он мог купить его, когда он станет доступен.
Как видите, есть различные виды решения проблемы отсутствия товара в ритейле. Они могут быть полезными для улучшения клиентского опыта, сохранения лояльности клиента и репутации магазина.
Мы предлагаем рассмотреть более подробно именно первый вариант с применением ML-моделей – автоматический подбор аналогов. Именно использование моделей машинного обучения для создания системы генерации и подбора аналогов товаров в продуктовом онлайн-ритейле позволяет быстро заменить товар, которого нет в магазине, на более подходящий аналог и сохранить лояльность покупателя.
Сложности и проблемы, с которыми столкнулись
Считаем, что в историях решения проблем важен не только результат, но и сам путь со всеми препятствиями. Поэтому в этом блоке мы честно расскажем не только достижениях, но и о проблемах, с которыми были вынуждены столкнуться.
Трудность реализации
Подбор аналогов не совсем простая задача особенно в продуктовом ритейле, где требуется более точная «настройка» по разным и далеко не всегда очевидным параметрам. Например, по упаковке, весу или объему, назначению, вкусовым факторам, составу, пищевой ценности. В таком случае уже необходимо применение как текстовых, так и CV-моделей.
Ручная обработка данных
На данный момент во «ВкусВилле» около 37 000 товаров, и у каждого свои характеристики. Особое внимание стоит обратить на категорию товаров. Это краеугольный камень в обработке данных – чем подробнее размечены категории товаров, тем более точно модель предсказывает.
Количество товаров-аналогов
Важно иметь в наличии достаточное количество товаров-аналогов, чтобы каждый покупатель мог найти нужный ему вариант. Например, в магазине всего два вида сладкой газировки – дюшес и тархун, а далее система из-за недостатка товаров рекомендует другие разные напитки: сок, морс, молоко и другое.
Основная суть проекта
Для начала стоит понять, что у каждого товара есть своя карточка, в которой указано не только его наименование и представлено его изображение, но и другие важные параметры: стоимость, вес, единицы измерения и т.д. Все эти параметры помогают клиенту в полной мере ознакомиться с продуктом, сравнить и выбрать для себя наиболее подходящий. Для команды разработки – это тонны данных, которые так любят нейронные сети.

Основная суть проекта довольно проста – все параметры, которые представлены в карточке товара необходимо объединить в один большой вектор и уже в массиве векторов-товаров через косинусное расстояние искать похожие позиции.
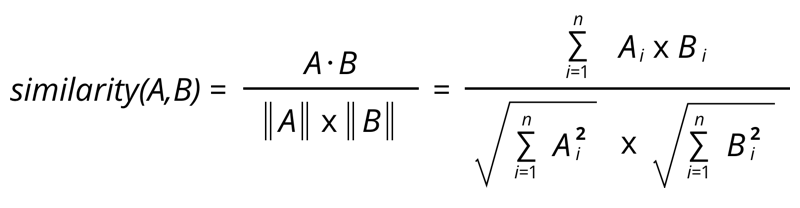

Формирование датасета
Для обучения нейронных сетей необходимо внушительное количество данных о всех товарах, которые есть в онлайн-магазине. Данные включают все характеристики товаров: вес, материал, производитель, цвет и т.д. Для обучения нейронных сетей необходима информация о категориях товаров и другие характеристики. На этапе экспериментов с подачей данных, мы отметили, что не все данные улучшают метрики моделей. Необходимо собрать действительно много данных, при этом важно выбрать только самые ключевые из них.
Обработка данных включает в себя:
Ручную разметку категорий;
Загрузку изображений и соединение их с товарами;
Сохранение только нужных параметров товара.

Обучение
На этапе обучения мы много экспериментировали с различными предобученными моделями и их соединениями. Остановились на двух моделях: за текст отвечает – rubert-tiny2, а за изображения – resnet-34, предобученная на imagenet. В процессе тюнинга сетей остро встал вопрос с затуханием градиента. Это проблема возникала на моменте, когда для NLP составляющей брались достаточно крупные модели такие, как LaBSE. Эксперименты с крупными моделями показали, что у них изначально хорошие представления о нашем домене, и тюнинг был менее эффективным. В связи с этим, мы решили использовать более компактные модели, но с большим дообучением на предметной области.
Наша архитектура выглядела следующим образом: текстовая модель с выходным полносвязным слоем размерности 768 и картиночная модель с полносвязным слоем размерность которого 256. Мы добились меньшей приоритизации картиночной фичи над текстовыми, что позитивно отразилось на наших бизнес-метриках. После этого идет еще один блок полносвязным слоем, который уже и является классификатором. После обучения мы срезаем последний слой с классификатора, чтобы получить скрытое состояние, которое и является эмбеддингом товара.

В процессе работы мы провели множество экспериментов, в том числе:
Пробовали обучаться с дополнительными головами у текстовой и картиночной модели;
Добавляли слой ArcFace для более четкого представления эмбеддингов.
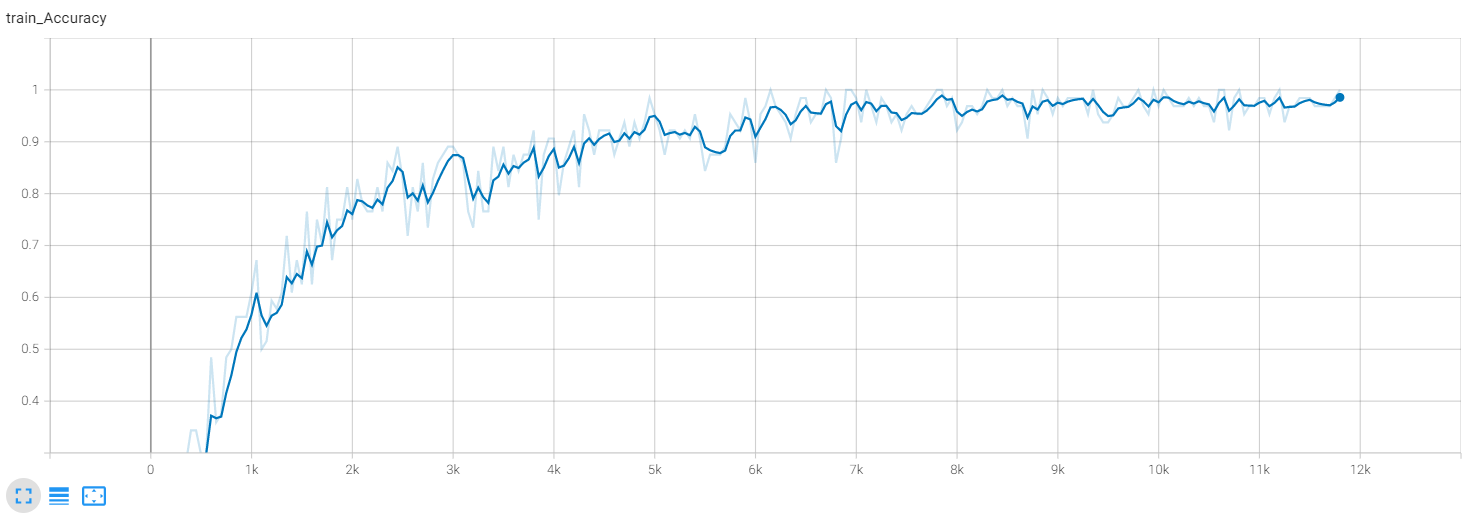
Процесс обучения заключался в решении задачи классификации определенного товара в его категорию самого низкого уровня. Обучения производилось на GPU (Tesla V100) и в целом не занимало очень много времени. Эмпирическим путем было установлено, что модель показывает наилучшее качество около 20 эпохи.


Выводы, к которым мы пришли
Использование моделей машинного обучения для автоматического подбора аналогов товаров при отсутствии их в онлайн-магазине – ключевое средство для улучшения работоспособности магазинов. Они могут улучшить клиентский опыт, увеличить продажи и уменьшить количество времени и денег, которые требуются для возврата или обмена товара. В целом такой подход ценен и может привести к большим результатам, увеличить прибыль компании.
При этом, не стоит забывать, что существуют риски и сложности использования этих моделей. У технологии есть свои ограничения и слабости – она может показать неудачные результаты, если модели обучаются на недостаточном объеме данных и информации.
Для достижения максимального эффекта следует вести дальнейшее наблюдение за улучшением системы, постоянно обновлять и добавлять новые данные. А вот подробнее, как это стоит делать, мы расскажем уже в следующей статье. Следите за обновлениями!
Будем рады услышать ваше мнение о нашем подходе и ответить на ваши вопросы. Оставляйте свои комментарии под статьей и активно участвуйте в обсуждении. Ваши мнения, вопросы и предложения могут внести ценный вклад в нашу работу!
*«ДатаЛаб» — команда профессионалов в области аналитики, больших данных, разработки программного обеспечения, машинного обучения и искусственного интеллекта.
S_A
Можно вам предложить присмотреться к
https://www.marqo.ai/
?