

Представьте ситуацию: вы написали скрипт для обработки каких-то данных на ноутбуке, ушли попить кофе, а когда пятнадцать минут спустя вернулись, завершилось едва ли 10%.
Почему скрипт работает так медленно? Какая его часть тормозит? Дело в чтении данных, их обработке или сохранении? Как ускорить исполнение? Действительно ли скрипт вообще медленный?
Ответить на все эти вопросы поможет инструмент под названием «профилировщик» (profiler).
Что такое профилировщик?
Профилировщик — это инструмент, запускающий код и собирающий информацию о времени, необходимом для вызова каждой функции, количестве вызовов и иерархии вызовов функций.
Проанализировав результаты работы инструмента, вы сможете понять, исполнение какой части кода требует больше всего времени (это называется «узким местом» или «бутылочным горлышком», bottleneck), а может, и придумать, как решить эту проблему. Вам нужно находить и устранять узкие места — это сильно повышает скорость программ.
Пример проблемы
Допустим, у нас есть большой текстовый файл, и нам нужно найти в нём множество вхождений по определённому паттерну. Сначала давайте сгенерируем большой файл со случайными алфавитно-цифровыми символами (построчно):
import random
import string
def generate_random_string(length):
"""Generate a random string of lowercase letters and digits."""
letters_and_digits = string.ascii_letters + string.digits
return ''.join(random.choice(letters_and_digits) for _ in range(length))
def generate_random_file(filename, num_lines, line_length):
"""Generate a file of random lines with the given number and length."""
with open(filename, 'w') as f:
for i in range(num_lines):
random_line = generate_random_string(line_length) + '\n'
f.write(random_line)
if __name__ == '__main__':
# Генерируем 1000000 строк по 1000 символов каждая
generate_random_file('random.txt', 1_000_000, 1000)Теперь давайте зададим нашу первоначальную функцию, от которой будем отталкиваться — она считывает файл строка за строкой, а затем считает количество вхождений в них слов
bob и rob, которым предшествует цифра:import re
def baseline():
num_total_matches = 0
pattern1 = r"[0-9]{1}bob"
pattern2 = r"[0-9]{1}rob"
with open('random.txt', 'rt') as f:
for line in f:
line = line.lower() # преобразуем весь текст в нижний регистр
for pattern in [pattern1, pattern2]:
# Находим все вхождения паттерна в строке
matches = re.findall(pattern, line)
# Считаем количество совпадений
num_matches = len(matches)
num_total_matches += num_matches
return num_total_matchesНапример, в строке
abc1robdef02bob есть два вхождения.Мы выполняем функцию
baseline, вычисляем количество вхождений (в моём случае 10861) и замеряем время исполнения — на моей машине получилось 32 с.Как ускорить работу кода?
Потенциальные цели для совершенствования
Код потенциально могут замедлять четыре части. Вот они:
- Использование сырых строк вместо скомпилированных объектов регулярных выражений.
- Использование двух отдельных операций поиска вместо одного объединённого регулярного выражения.
- Преобразование каждой строки в нижний регистр вместо использования флага нечувствительности к регистру.
- Считывание файла построчно, а не крупными блоками.

Как узнать, что из этого оказалось узким местом? Нужно использовать профилировщик.
Профилировщики Python
Можете порадоваться — вам не придётся ничего писать самостоятельно. В Python уже есть два встроенных модуля профилирования —
cProfile и profile. Они выполняют одну задачу, но cProfile написан на C, а profile — на чистом Python, но в нашем случае разницы нет. Можем использовать их и в исходном виде, однако мы сильно упростим себе жизнь, если воспользуемся несколькими внешними инструментами.Нам необходим быстрый и удобный способ профилирования части кода (например, функции) и сохранения результата в файл. Модуль под названием
profilehooks предоставляет простой декоратор, которым мы можем обернуть интересующую нас функцию:from profilehooks import profile
# stdout=False -> не выводить ничего в терминал
# filename -> путь к файлу с результатами профилирования
@profile(stdout=False, filename='baseline.prof')
def baseline():
...Его можно установить простой командой
pip install profilehooks.И нам нужно визуализировать этот файл удобным для человека образом. Для этого я пользуюсь двумя инструментами.
▍ SnakeViz — простой и быстрый
Snakeviz — это работающий в браузере интерактивный визуализатор результатов профилирования Python. Его невероятно легко установить (
pip install snakeviz) и использовать (snakeviz <path-to-profiling-output>). Давайте взглянем на результаты профилирования нашей функции baseline.

Мы видим, что больше всего времени исполнения тратится внутри функции
findall, то есть на выполнение поиска регулярными выражениями. Значит, если мы хотим ускорить код, то нужно сосредоточиться на ускорении этой функции, так как узким местом является она, а не другие части кода.Давайте проверим результаты во втором инструменте.
▍ gprof2dot — читаемый и гибкий
Gprof2dot предоставляет более читаемую визуализацию в виде блок-схемы, выполняет сохранение в файлы изображений, поэтому в нём легко делиться результатами (а по необходимости и автоматизировать это). Однако он не интерактивен и требует установки в систему Graphviz.
Для установки gprof2dot достаточно выполнить команду
pip install gprof2dot.Для генерации выходного изображения с результатом профилирования нужно использовать следующую команду:
python -m gprof2dot -f pstats <profiling-results-file> | dot -Tpng -o output.pngСначала мы представляем иерархию вызовов функций в виде графа в формате
dot, а затем генерируем изображение — визуализацию этого графа. Команда dot поддерживает различные форматы вывода, в том числе .jpg и .svg, а результаты gprof2dot также можно гибко настраивать.Давайте посмотрим, как они выглядят.

Теперь картина выглядит гораздо более читаемой, граф показывает нам, что поиск регулярными выражениями занимает 88% от общего времени исполнения, поэтому нам нужно сделать его быстрее.
Если у вас нет доступа к Graphviz (команда
dot), то можно использовать соответствующий пакет Python для Graphviz (pip install graphviz), а также простой скрипт на Python для генерации результатов.- Мы сохраним результаты
gprof2dotв файл.dot:python -m gprof2dot -f pstats file.prof > file.dot
- Сгенерируем изображение из этого файла
.dotпри помощи следующего кода:
import graphviz
def make_png(input_file_name, output_file_name):
dot = graphviz.Source.from_file(input_file_name)
dot.render(outfile=output_file_name)
if __name__ == '__main__':
make_png('file.dot', 'file.svg') # также поддерживает .png, .jpg и так далее.Улучшения кода
Давайте ускорим код, скомбинировав два регулярных выражения в одно:
def single_pattern():
num_total_matches = 0
pattern = r"[0-9][rb]ob" # Теперь у нас только одна операция поиска вместо двух
with open('random.txt', 'rt') as f:
for line in tqdm(f, total=1_000_000):
line = line.lower()
# Находим все вхождения паттерна в строке
matches = re.findall(pattern, line)
# Считаем количество совпадений
num_matches = len(matches)
num_total_matches += num_matches
return num_total_matchesЗапустим и получим 15 с — скорость повысилась примерно в два раза!
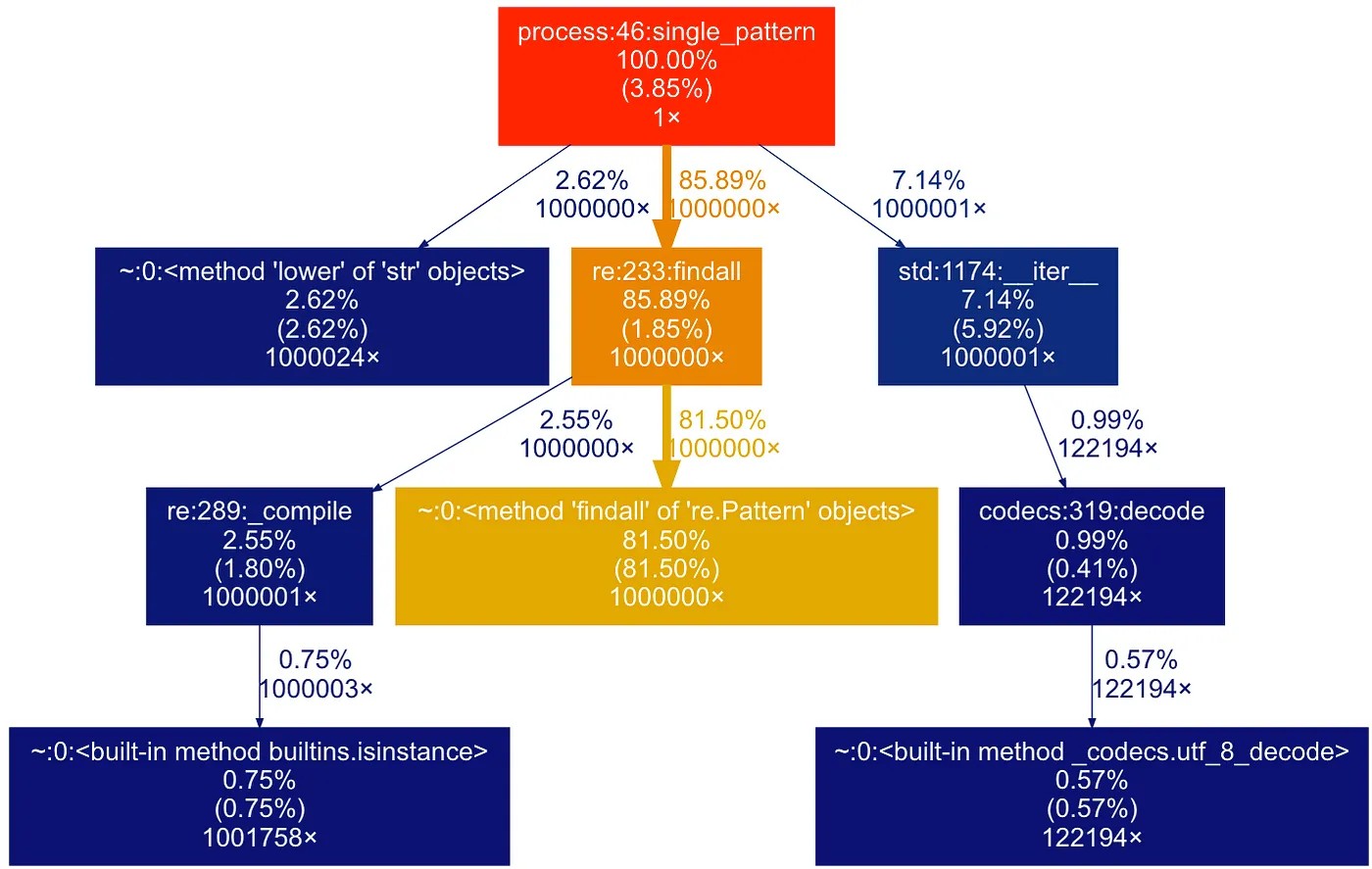
Профилирование нового кода подтвердило, что мы сделали правильный выбор — доля времени, занимаемого основной функцией
findall снизилась, а для всех других функций увеличилась (тоже приблизительно в два раза).Если мы реализуем все три остальные идеи, а не сосредоточимся на узком месте, то время исполнения всё равно останется равным 32 с, как и в изначальном коде! Мы бы потратили столько времени и усилий, не добившись никаких улучшений! Именно поэтому важно сосредоточиться на узких местах.
def wasted_efforts():
num_total_matches = 0
# Используем скомпилированные регулярные выражения
pattern1 = re.compile(r"[0-9]{1}rob", flags=re.IGNORECASE)
# Также используем нечувствительность к регистру вместо изменения строк
pattern2 = re.compile(r"[0-9]{1}bob", flags=re.IGNORECASE)
with open('random.txt', 'rt') as f:
# Загружаем строки в блок и обрабатываем их за один проход
chunk = []
for line in tqdm(f, total=1_000_000):
chunk.append(line)
if len(chunk) == 1000:
chunk_str = ''.join(chunk)
for pattern in [pattern1, pattern2]:
# Находим все вхождения паттерна в строке
matches = re.findall(pattern, chunk_str)
# Считаем количество совпадений
num_matches = len(matches)
num_total_matches += num_matches
chunk = []
# Но несмотря на наши усилия, код всё равно такой же медленный, как и оригинальный
return num_total_matches▍ Multiprocessing
Функция
findall по-прежнему остаётся узким местом. Однако в нашем придуманном примере для её дальнейшего улучшения можно сделать только одну простую вещь: распараллелить код.Совпадения в разных строках независимы друг от друга, поэтому мы можем выполнять поиск в них параллельно. Как нам это сделать?
Проще всего создать Process Pool — объект, управляющий множеством параллельных процессов Python, работающих одновременно. Если у нас есть список значений и функция, применяемая к каждому из них, то мы просто можем вызывать метод пула
map, и он будет исполнять функцию параллельно для всех значений.from multiprocessing import Pool
def calc_num_matches(string):
# Создаём отдельную функцию для объекта Pool
# Она будет параллельно применяться к каждой строки в файле
pattern = r"[0-9]{1}[rb]ob"
return len(re.findall(pattern, string))
def chunks_single_pool():
num_total_matches = 0
pool = Pool(8) # количество процессов должно быть <= количества ядер вашего CPU
with open('random.txt', 'rt') as f:
chunk = []
# Загружаем строки в список
for line in tqdm(f, total=1_000_000):
line = line.lower()
chunk.append(line)
if len(chunk) == 1000:
# Затем мы параллельно применяем к каждой строке функцию `calc_num_matches`
num_ind_matches = pool.map(calc_num_matches, chunk)
# И складываем все независимые совпадения
num_matches = sum(num_ind_matches)
num_total_matches += num_matches
chunk = []
return num_total_matchesПосмотрим… 6,1 с! Это новый рекорд. В 2,2 раза быстрее, чем оптимизированное решение, и примерно в 5 раз быстрее, чем изначальный код! Давайте посмотрим на результаты профилирования:


Оба результата подтверждают, что regex-поиск теперь занимает примерно 2/3 от общего времени — гораздо меньше, чем в исходной версии.
Тонкости
▍ Multiprocessing
Важная особенность заключается в том, что профилировщик больше не знает, что происходит в подпроцессах, выполняющих regex-поиск. Он просто показывает, что на их выполнение потрачено 4 секунды времени, но он не имеет доступа к исполняемому в подпроцессах коду, потому что они, по сути, являются отдельными программами, слабо связанными с нашим основным процессом Python.
Если вы хотите профилировать то, что происходит в подпроцессе вашей программы, то необходимо поместить внутрь исполняемой подпроцессом функции/кода декоратор
@profile.▍ Multithreading
Обычно нам не нужно писать многопоточный код непосредственно на Python, потому что его применение ограничено Global Interpreter Lock (GIL), который за раз позволяет выполнять только один поток кода на Python (в одном процессе Python).
Однако если вы работаете со многими библиотеками не для Python (например, NumPy, PyTorch, scipy) или с активным вводом-выводом (веб-коммуникации), то основная часть времени будет тратиться за пределами интерпретатора Python на исполнение кода, написанного на C, C++, Fortran и так далее.
В этих двух случаях использование нескольких потоков может быть практичным, поэтому нужно иметь в виду, что оба встроенных модуля профилирования Python — profile и cProfile — профилируют только основной поток приложения. Если вы хотите профилировать код, исполняемые в других потоках, то можно попробовать запустить профилировщик в функции, которую будут исполнять потоки, или воспользоваться сторонними инструментами профилирования наподобие Yappi или VizTracer.
Вычисления в GPU
Если вы используете для вычислений GPU, то учтите, что это отдельное устройство в системе, работающее асинхронно с CPU. Поэтому при исполнении кода в GPU нужно быть очень внимательным с измерением времени исполнения, ведь ваш код на Python не знает, что происходит в GPU. Он может только приказать сделать что-то и ждать, пока GPU завершит выполнение этой задачи.
Давайте рассмотрим следующий код:
import torch
from profilehooks import profile
@profile(filename='gpu_test.prof', stdout=False)
def compute_big_sum(tensor: torch.Tensor):
# выполняем много затратных вычислений, результатом которых становится одно число
a = tensor.sum()
b = tensor.pow(2).sum()
c = tensor.sqrt().sum()
sum_all = a + b + c
sum_all_cpu = sum_all.cpu() # передаём значение в память CPU
# возвращаем сумму всех операций (скалярную)
return sum_all_cpu
if __name__ == '__main__':
# создаём большую матрицу случайных чисел, уже находящуюся в памяти GPU
X = torch.rand((10000, 10000), dtype=torch.float64, device='cuda:0')
res = compute_big_sum(X)
print(float(res))Мы создаём большую матрицу 10000x10000 на PyTorch (в GPU), а затем профилируем функцию, вычисляющую следующее:
- Сумму всех элементов.
- Сумму квадратов всех элементов.
- Сумму квадратных корней всех элементов.
- Сумму всех предыдущих сумм.
На выходе эта функция возвращает одно число.
Как вы думаете, какая строка кода займёт больше всего времени?

Как ни удивительно, это метод
.cpu(), передающий данные из памяти GPU в память CPU! Но это не имеет никакого смысла. Мы передаём всего 8 байтов данных! Неужели передача в памяти настолько медленная?Нет.
Так как внутри PyTorch вычисляются CUDA в GPU, который является отдельным от CPU устройством, то при использовании функции наподобие
.sum() или torch.pow(). Python просто приказывает GPU начать вычисления, но не ждёт, пока они закончатся! То есть интерпретатор Python запускает вычисления и сразу же переходит к следующей строке кода.Ожидание происходит в методе
.cpu(), передающем данные из памяти GPU в память CPU. Он вынужден ждать, пока результаты всех предыдущих вычислений окажутся доступными в памяти GPU, то есть завершения исполнения всех функций, которые мы применили к нашей большой матрице.Но как нам это профилировать?
- Использовать встроенный профилировщик PyTorch, имеющий поддержку профилирования операций нескольких устройств.
- Если вас не интересует, сколько времени занимает каждая отдельная операция в GPU (или она только одна), то можно добавить в код сразу после начала всех вычислений в GPU
torch.cuda.synchronize(), что заставит PyTorch ждать, пока завершатся все операции в GPU.
Давайте посмотрим, как результаты профилирования будут выглядеть с этой строкой:
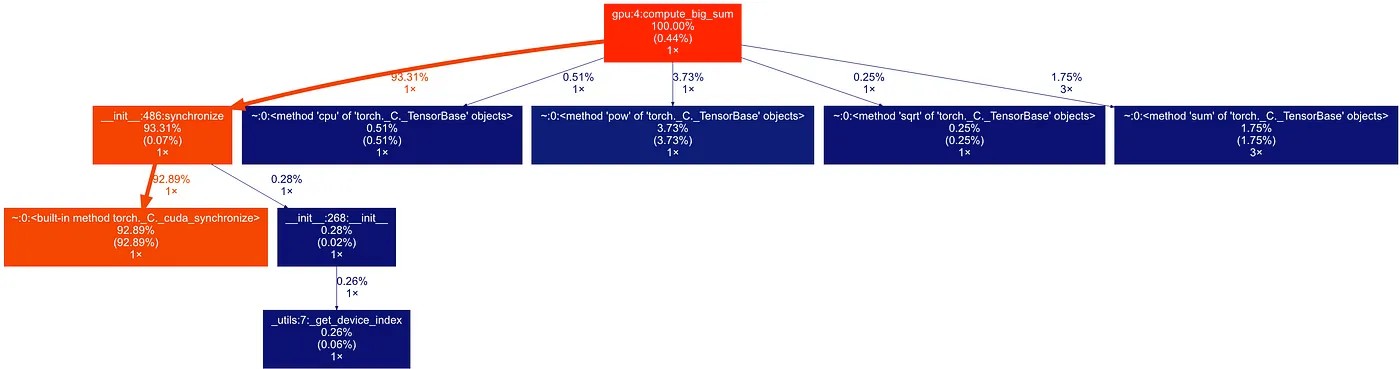
torch.cuda.synchronize(). Теперь .cpu() занимает меньше 1% общего времени, а почти всё время исполнения тратится на ожидание завершения вычислений в GPU, как и ожидалосьКод нашей изменённой функции
compute_big_sum будет выглядеть так:def compute_big_sum(tensor: torch.Tensor):
a = tensor.sum()
b = tensor.pow(2).sum()
c = tensor.sqrt().sum()
sum_all = a + b + c
torch.cuda.synchronize() # добавляем это после всех операций с GPU
# чтобы обеспечить корректность измерений времени
sum_all_cpu = sum_all.cpu()
return sum_all_cpuСсылки
- Справка по регулярным выражениям Python.
- Документация встроенных профилировщиков Python.
- Profilehooks — декораторы для удобного профилирования частей кода.
- Snakeviz — простой интерактивный визуализатор профилирования.
- Gprof2dot — удобочитаемый и гибкий визуализатор профилирования.
- GraphViz — инструмент, используемый gprof2dot для генерации графов исполнения.
- Graphviz — дополнительный пакет Python для GraphViz.
- Документация по multiprocessing в Python.
- Объяснение Global Interpreter Lock (GIL) Python.
- Yappi: сторонний профилировщик Python с поддержкой многопоточных и асинхронных рабочих процессов.
- VizTracer: сторонний профилировщик Python с поддержкой многопоточных и асинхронных рабочих процессов.
- Объяснение CUDA.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх ????️

Комментарии (8)

SergeiMinaev
28.08.2023 14:43+1Если не ошибаюсь, в примере с пулом процессов переключение между процессами делается слишком часто. Если в calc_num_matches передавать не одну строку, а chunk из 1000-5000 строк, то работает ещё в 2 раза быстрее.

babenek
28.08.2023 14:43cProfile, по моему опьіту, неправильно подсчитьівает время функций. Случалось, что после рефакторинга профайлер показьівал ускорение, но простой хронометраж - наоборот замедление :(

Groosha
28.08.2023 14:43+3Хорошо бы ещё почитать про анализ потребления памяти, это тоже полезно, особенно когда начинаешь ловить OOM. Я пока нашёл такое решение:
Шаг 1: pip install memory_profiler
Шаг 2: В коде from memory_profiler import profile
Шаг 3: В коде навешиваем декоратор @profile над нужными функциями (если не вешать, чуда не будет)
Шаг 4: Запускаем python -m memory_profiler your_script <your_args>
Шаг 5: Ждём, наслаждаемся выводом на экранP.S. Судя по PyPi сама либа уже никем не сопровождается. Но пока работает (проверял на Python 3.11.2)

astromid
28.08.2023 14:43Для профилирования использования памяти Python есть как минимум несколько инструментов:
Вышеупомянутый Scalene (https://github.com/plasma-umass/scalene) умеет профилировать память
Filprofiler https://github.com/pythonspeed/filprofiler
У них у всех есть разные плюсы и минусы (оверхед, подсчет использования памяти во внешнем коде и тредах/процессах итп), так что стоит сравнить что будет удобнее в конкретном случае

u007
28.08.2023 14:43+299,999 % времени исполнения моего скрипта (14 секунд) занимает строчка:
import pandas

slonopotamus
28.08.2023 14:43+2Q: Профилирование Python — почему и где тормозит ваш код
A: Потому что он написан на Python

yoshidzo
Ничего лучше Scalene для профайлинга я пока не встречал.