

Готовим гибридную систему мониторинга + щепотка observability дабы нанести непоправимую пользу всему прогрессивному человечеству. С ароматом кофе, перед использованием можно добавить свои данные по вкусу.
Посмотреть работы мастеров недавнего прошлого и настоящего можно здесь. Богатый выбор, яркие краски и интересные композиции, но чего-то не хватает. Отсутствует как класс десктопное решение для быстрого и удобного сбора, хранения и визуализации. Такой lightweight гибрид системы управления данными Apache NiFi + ClickHouse + QlickView.
Общее описание
Архитектура приложения предполагает сбор, хранение и работу с данными локально.

Кратко преимущества:
Гибкая и удобная конфигурация настроек сбора данных, хранения и их визуализации;
Хранение данных локально в специализированной колоночной БД, автоматическая дедупликация данных и сжатие;
Продвинутая визуализация данных со встроенной аналитикой. Автоматическое определение функции отображения данных (Count, Sum, Average) по типу данных;
Возможность использовать готовые шаблоны для сбора данных.
Конфигурация
Настройки приложения хранятся в основных сущностях Профиль, Задание, Подключение и Запрос. С помощью данной модели обеспечивается гибкое хранение метаданных, которые используются для сбора данных и их отображения.
Профиль представляет собой хранилище информации о конкретном профиле, включая его название, краткое описание и список заданий, которые должны быть выполнены при запуске данного профиля.
Задание содержит список запросов, которые должны быть выполнены в рамках данного задания. Каждое задание также содержит имя запроса, краткое описание, подключение и частота запросов к удаленной системе.
Подключение хранит всю необходимую информацию о деталях подключения к удаленной системе по JDBC. Атрибуты подключения: имя, URL-адрес, имя пользователя, пароль, а также информацию о расположение файла и название класса JDBC Driver-а.
Запрос представляет собой текст SQL-запроса, который отправляется на сервер для получения данных. Каждый запрос также содержит информацию о его названии, краткое описание, способе наполнения данных (локально или на сервере) и режиме загрузки данных (прямой, JDBC в режиме реального времени, пакетная загрузка данных из JDBC источника).

В параметрах Запроса есть настройка наполнение данных Gather Data SQL в которой доступны два варианта:
By Client — когда мы загружаем данные напрямую из удаленной системы в локальную БД;
By Server — когда данные заполняются отдельным процессом или агентом на сервере и мы регулярно подгружаем изменения в локальную БД, отслеживая их по столбцу с меткой времени Timestamp.
Также, внутри интерфейса Запроса присутствуют вложенные сущности Метаданные и Метрики.
Метаданные содержат информацию о конфигурации таблицы в локальном хранилище данных движка FBase по данным запроса.
Метаданные таблицы: имя, тип хранения(обычная таблица или таблица для хранения данных временных рядов), тип индексирования (локальный или глобальный), сжатие данных, столбец таблицы для метки времени, метаданные столбцов таблицы. Также в интерфейсе отображается подключение к источнику данных задания в котором выполняется данный запрос. Это нужно для того, чтобы подгрузить метаданные по запросу в локальное хранилище.
Метрики это сущность для отображения специальным образом подготовленных статистик. Атрибуты Метрики: имя, ось X (всегда столбец Timestamp), ось Y (имя столбца), группировка данных (по столбцу), функция (способ обработки отображаемых данных), способ графического отображения данных (линейный, stacked графики), значение по умолчанию (при отображении данных детализации для stacked графиков). Внизу отображается список всех сохраненный Метрик по данному запросу.

Шаблоны
Шаблоны позволяют быстро подключить функциональность по сбору данных. Нет необходимости вручную заполнять всю конфигурацию. Просто выбираете профиль, указываете параметры подключения, расположение Jar и строку драйвера JDBC, собираете метаданные по запросу, указываете поле для отслеживания меток времени и можно работать.

Screencast подключения шаблона, 4 Мб

Хранение данных
Хранение данных в приложении реализованно с использованием специализированной базы данных блочно-колоночного типа со сжатием FBase. Настройки хранения располагаются в интерфейсе Запросы -> Метаданные. В самой БД поддерживается хранение данных обычных таблиц и таблиц для хранения данных временных рядов, но мы пока используем Time-series.
Доступны три типа хранения данных по столбцам:
RAW — данные хранятся как идентификатор типа int Java;
ENUM — данные хранятся как идентификаторы типа byte Java;
HISTOGRAM — когда сохраняются только данные, начальный и конечный индекс появления их в столбце.
Типы хранения данных по столбцам определяются в настройках на уровне таблицы или блока (настройка Глобальное или Локальное индексирование). Локальное индексирование на уровне блока - это функция по автоматическому выбору соответствующего типа хранения для блока на основе распределения данных. Выбор типа хранения в данном варианте производится автоматически. Поддерживается сжатие данных. Настройки по включению/отключению сжатия данных и выбору типа хранения можно делать на лету, без остановки сбора данных.

Визуализация данных
В приложении поддерживаются несколько вариантов визуализации данных:
В режиме реального времени
Данные визуализируются по мере их поступления. Для отображения данных в этом режиме необходимо выбрать соответствующую метрику или столбец запроса в интерфейсе Real-time. В интерфейсе Details есть возможность выбора функций Count, Sum и Average. Для числовых значений возможен выбор любой из этих функций, для строковых данных нельзя вызвать подсчет суммы и расчет среднего значения. Функция As is находится в разработке. Для Count есть ограничение в максимум 50 групп, которые можно отобразить на графике. Пока при превышении порога график просто не отображается. Работаем над тем, чтобы отображать такой тип данных. В приоритете удобство, скорость и надежность.

Screencast интерфейс real-time 3 Mb

Просмотр истории
Данные отображаются за предыдущий период наблюдения. Для этого необходимо выбрать метрику или столбец запроса и указать диапазон в разделе History, при выборе поля Custom есть возможность более детального выбора диапазона при помощи интерфейсов Relative и Absolute. Как видно и Quick и выбор диапазона дат выглядит аналогично как и в Кибана.

Screencast просмотра истории 3,9 Мб

Визуализация данных по подстроке
Ad-hoc запросы, когда данные отображаются по определенному ключевому слову для данных Real-Time. Для этого необходимо перейти в интерфейс Search, указать подстроку для поиска не меньше 3 символов и нажать Go. Данные покажут вхождения подстроки во всех сырых данных с группировкой по столбцам. Практически тоже самое как и в Кибана выглядит полнотекстовый поиск.
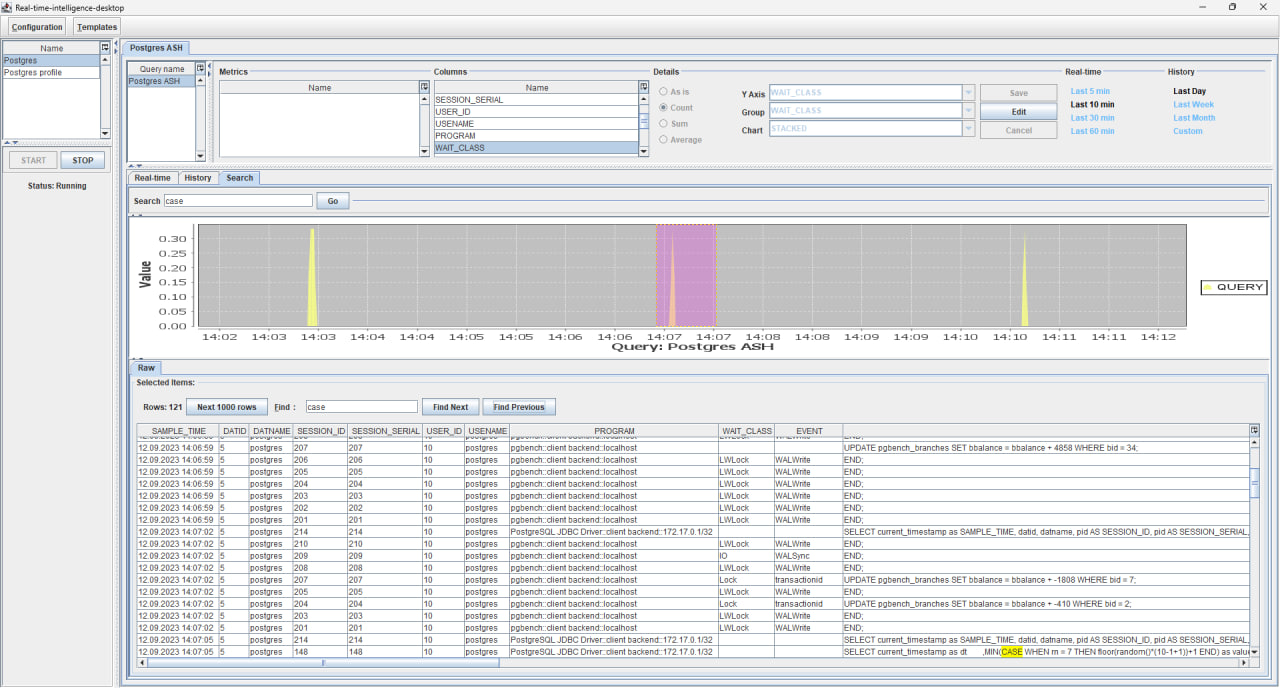
Screencast ad-hoc запросы 4,8 Мб

Просмотр взаимосвязей в данных
Функционал реализован в виде Gantt-графиков, показывает в визуальном виде результат выполнения группового запроса по выделенному временному диапазону, только отображаются значения COUNT не в абсолютных значениях, а в процентах. Сразу понятно какие показатели в топе по определенной группе.
SELECT event, wait_class, COUNT(wait_class)
FROM table
WHERE timestamp beetwen begin and end
GROUP BY event, wait_class
Просмотр Raw-данных
При выборе диапазона отображается форма для просмотра Raw-данных. Можно смотреть исходные данные, искать значения по подстроке.

Варианты использования
Хорошо всем знакомый мониторинг. Есть функционал сбора данных метрик, есть возможность подтягивать данные с сервера записанные внешними агентами. В общем и целом для задач мониторинга небольшого парка систем или специализированных случаев когда нужна скорость получения результата — вполне себе вариант;
Сбор расширенной диагностики и ее анализ. Бывают задачи, когда нужно проверить как функционирует тот или иной компонент системы. Или вся база в расширенном режиме сбора метрик. И нужно по быстрому получить больше данных чем обычно используется;
Нагрузочное тестирование. Например проверка как работает система после установки обновлений. Или изменения параметров. Или провести регресс-тесты и замерить что SLA в норме или нет;
Обучение, обмен знаниями. Некоторые концепции проще объяснить не словами, а с помощью визуализации, real-time посмотреть реакции системы на определенный тип нагрузки. Например, посмотреть статистики потребления ресурсов при откате транзакции в БД Oracle или в Postgres.
Упорядочивание локальной работы с данными. Решаем проблему быстро собрать данные, обработать и использовать эти процедуры в дальнейшем, при повторном использовании. Есть возможность хранить настройки конфигурации JSON в git – Monitoring as Code.
Отслеживание параметров датчиков Интернета вещей (IoT). Легко подключиться, быстро снять показания. Составить отчет. Также можно применять и в диагностике, данные собираем и тут же смотрим, что не так, детекция аномалий, в режиме реального времени. Не проблема реализовать поддержку специализированных протоколов – Java это сейчас уже не язык программирования а экосистема в которой есть поддержка практически всех форматов взаимодействия;
Технологическая карта
Исходные коды проекта открыты по лицензии Apache 2.0 и выложены на GitHub. В наличии документация на русском и английском.
Приложение изначально разрабатывалось с прицелом на использование свежих версий Java. Сейчас код пишем с поддержкой новых возможностей JDK версии 17 и выше. Надеемся в скором времени поисследовать внедрение виртуальных потоков.
Из интересного в коде и инфраструктуре
CI/CD. Задача минимум была поддерживать две версии систем сборки и деплоя. Так получилось, что мы работаем с Gitea. А у ней появилась своя реализация CI/CD pipeline-ов Gitea Actions с обратной совместимостью с Githab Actions. Как обычно смотреть pipeline в корне проекта .gitea. Инструкция есть в README.
DI. Система сложная, большое количество объектов со своими жизненными циклами. Надо всем этим как-то управлять. Используем Dagger 2 и Custom scopes. Все устраивает, единственно настройка требует написания немало кода но плюсы перевешивают. Смотреть детали в модуле desktop, пакет ru.rti.desktop.config и ru.rti.desktop.Application.
Java Swing. Не утихают споры по поводу того, что использовать в качестве API для кроссплатформенной графической подсистемы в своих проектах на десктоп. В пользу Java Swing у меня всегда один аргумент – компания JetBrains. Она уже более два десятка лет использует эту технологию для создания графического интерфейса для своих IDE. Также мы еще используем виджеты от SwingX и организуем код с помощью Model-View-Presenter (MVP), всегда стараемся разделять логику и визуальное представление. Начать можно с ru.rti.desktop.view.
Layout Manager. Используем все что есть в Swing и дополнительно есть такая утилита Painless Gridbag. Очень удобная штука, сильно помогает размещать компоненты так как нам нужно и спасает от boilerplate-a. В описании проекта написано так. A small utility that removes the painfulness when working with Swing's GridBagLayout using fluent API. Подтвержаю на 100%, тот случай когда количество звезд не отражает реальной полезности данной библиотеки. Tri-bao - красавчик!
Хранение данных. База данных FBase блочно-колоночного типа на Java. В качестве backend-a – Berkley DB Java Edition. Задача хранения решает на отлично, дедупликация и сжатие из коробки. Такой ClickHouse на минималках. Документация в наличии, тесты тоже: полный набор от от unit заканчивая интеграционными и нагрузочными и даже автотесты тоже есть. По скорости конечно уступает ClickHouse раз в 10 в среднем, но на локальных объемах это сильно быстрее чем обычный табличный формат для наших задач. По занимаемому месту на диске уступает ClickHouse процентов на 10-15% с сжатием, но это мы еще не оптимизировали опцию локального индексирования. Там прирост будет еще больше и по скорости тоже.
Визуализация. Старый добрый JFreeChart все еще актуален. Да, по скорости отстает от лучших в своем классе на JVM или JChart2d. Но тут нужен крепко подумать, чтобы переключаться на что-то другое.
Тесты. Тесты GUI в наличии, но их немного пока, только для настроек конфигурации. Так как устаканиваем архитектуру и внутренний API. Пока справляемся с ручным тестированием, но баги все равно периодически беспокоят. Отдельная история это запуск тестов в связке с Dagger 2, начать можно с MainComponentTest. Запуск GUI тестов включен в CI/CD процедуры через dummy display:xvfb-run.
JSON. Использовали сначала для хранения настроек YAML snakeyaml, но не зашло из-за багов. Плюс JSON как-то приятнее и понятнее, более human readable, добрее что-ли. Используем Gson от Google.
Шаблоны. Храним в коде в resources. Приходится обработку делать отдельно для работы с ними из IDEA и при запуске исполняемым jar-файлом. Смотреть детали в ru.rti.desktop.helper.FilesHelper.
Интернализация, поддержка RU и EN, но подключена еще не везде. См. ru.rti.desktop.prompt.Internationalization.
Журналирование. Используем Log4j2 так как самый быстрый по тестам.
Lombok. Все еще в строю.
Дальнейшие планы
Оформить внешний вид через LaF, подключить светлую и темную тему. FlatLaf вроде неплох.
Включить и отладить быстрое создание метрик на главной странице мониторинга.
Привести в нормальный вид систему отчетности – все графики и детализации по выбранным данным из любой части конфигурации в html или pdf.
Реализация поддержки сбора данных из источников данных по HTTP/REST/JSON.
Исключение необходимости ручного выбора диапазонов в данных, обновление статистик по ключевым словам в интерфейсе Search. Доверим эту рутину автоматике.
Подготовка прототипов для различных вариантов визуализации (поддержка обработки данных с группировкой свыше 50 элементов туда же), выбор наиболее подходящего решения.
Предиктивная аналитика, поиск корреляций. Подключение специализированных пакетов для анализа данных.
Выгрузка данных в разных форматах (CSV, возможно Jupiter notebook-ах etc.).
Поддержка
Приложение разрабатывается при поддержке Фонда содействия инновациям по конкурсу Код-Цифровые технологии — Результаты.
Вот такая получается картинка, надеюсь было интересно и будет полезно.
Спасибо за внимание!