

Привет, Хабр! Меня зовут Анджей, я QA-лид в Сравни. В этой статье давайте попробуем если не победить, то хотя бы побороться вот с какой ситуацией: вроде всё сделали хорошо и проверяли, а сайт всё равно пролежал на выходных с 500-ми ошибками. Помогать с тестированием нам будет Kubernetes-инструментарий в общем (Helm) и механизм хуков в частности.
Проверки: перспективная теория vs суровая практика
Чтобы подобного не происходило, можно обложить тестами вообще всё – теоретически, это может помочь, но на практике такой подход не всегда срабатывает, к сожалению. Сроки горят, фича нужна была вчера, поэтому если даже и были собраны Postman-коллекции, то их благополучно забыли (или не успели; или решили, что в этот раз можно без них).
Ок, а что, если эти проверки сделать частью пайплайна выкатки? Чтобы одним билдом догнать двух зайцев: и стенд собрать, и сервис проверить перед релизом.
Тут на практике снова есть проблемы:
Когда твоё приложение билдится 10 минут (или 20, или полчаса, или впишите своё значение), то не всегда поднимается рука добавить туда ещё больше тестов.
Причины, почему долго билдится, могут быть разными (из-за инфраструктуры, неоптимального пайплайна или чего-то ещё), и проблему нельзя назвать повсеместной (есть счастливчики, у кого всё быстро собирается) – но бывает.
Тесты будут актуальны только в том случае, когда приложение уже собрано и работает. Поэтому добавлять прогон коллекций в пайплайн выкатки может быть не лучшей идеей.
И вот грустил я об этом всём, читал канал коллег из DevOps-команды в рабочем мессенджере, увидел сообщение про Helm Hooks. Про Helm до этого немного знал, с хуками не сталкивался.
Решил узнать больше об этом механизме, и в процессе знакомства родилась идея: давайте с помощью этой штуки запускать проверки без участия человека. При этом не по расписанию, а по необходимости – когда наше приложение обновлено или собрано впервые.
Дальнейшее было делом техники, сработало даже лучше, чем я ожидал, и вот я здесь, чтобы поделиться опытом.
Найти: использование Helm Hooks для автоматических проверок
Итак, мы хотим прогонять Postman-коллекции, делать это регулярно (всегда), на рабочем приложении. Будем считать, что проверки нацелены на все ручки сервиса или определённый сценарий, например, happy path.
В погоне за быстрыми релизами не всегда бывает достаточно информации по задаче. Правки, которые вроде бы не имеют отношения к функциональности, прикрученной к некоторой ручке, ломают эту самую функциональность, а смотреть в то место и не предполагалось – такое по моему опыту случается сильно чаще, чем хотелось бы.
Проверок много, стендов много, так что давайте попробуем всё это провернуть с минимальным количеством усилий с нашей стороны, в идеале – автоматически.
А помогут нам с этим Helm Hooks.
Да кто он такой, этот ваш Helm Hook
Давайте сверимся по матчасти: Helm – это менеджер пакетов для Kubernetes, который помогает управлять приложениями (определять, устанавливать, обновлять).
Helm предоставляет механизм Hook, позволяющий вмешиваться в определенные моменты жизненного цикла выпуска. Например, вы можете использовать хуки для загрузки ConfigMap или Secret во время установки до загрузки любых других параметров. Хук может выполнить резервное копирование базы данных перед установкой, а затем выполнить восстановление данных. И так далее.
Вариантов для использования хуков – много.
Проверки с помощью хуков: концепция
Для наших целей мы будем использовать хуки post-install и post-upgrade. Они умеют определять состояние подов микросервиса после развертывания. После того, как установлено, что поды запущены, 1/1 и работают корректно, самостоятельно запускают джоб, в котором реализуются прописанные хуку сценарии (Job – временно создаваемая сущность, которая при появлении реализует заложенные в неё сценарии; больше информации – тут, тут и тут).
Эта их особенность поможет запустить проверки полностью автоматически в период, когда приложение после развертывания совершенно точно будет в рабочем состоянии, без необходимости как-либо дополнительно проверять, работает ли приложение после выкатки.
Проверки с помощью хуков: пошаговый путь
Давайте рассмотрим работу хука на примере простого приложения. Для этого соберём конфигурационный Dockerfile, в котором описаны инструкции для применения при сборке Docker-образа и запуске контейнера. Подробнее о работе с Dockerfile можно почитать тут.
FROM ubuntu:22.04 as base
RUN apt-get update && \
apt-get install -y curl gnupg2 && \
apt-get install wget && \
wget -h && \
curl -sL https://deb.nodesource.com/setup_20.x | bash - && \
apt-get install -y nodejs
COPY ./hook/postrun.sh postrun.sh
RUN chmod +x ./postrun.sh
RUN npm install -g newman && \
npm install -g newman-reporter-slackmsg
RUN cat ./postrun.sh && \
echo "================== \nThis is the end... \n=================="
CMD cat ./postrun.sh
FROM ubuntu:22.04 as base – используем базовый образ убунты, на которую сможем установить актуальную версию Node.js.
RUN apt-get update && \ – обновляем индекс и списки пакетов для дальнейшей загрузки.
apt-get install -y curl gnupg2 && \ – устанавливаем curl; понадобится при установке Node.js.
apt-get install wget && \ – устанавливаем утилиту wget, через неё будем качать нужные файлы из репозитория.
wget -h && \ – выводим подсказку (--help) по использованию wget; используется как своего рода проверка работоспособности утилиты при сборке образа.
curl -sL https://deb.nodesource.com/setup_20.x | bash - && \ – скачиваем нужное для установки необходимой версии Node.js.
apt-get install -y nodejs && \ – устанавливаем Node.js.
COPY ./hook/postrun.sh postrun.sh – копируем файл исполняемого скрипта в текущую директорию.
RUN chmod +x ./postrun.sh – выдаём права скрипту, чтобы его можно было запустить.
npm install -g newman && \ – устанавливаем утилиту newman, которую впоследствии используем для прогона тестов.
npm install -g newman-reporter-slackmsg – устанавливаем дополнительные пакеты для newman, которые выполняют функцию репортера. Они преобразуют прогон в красоту, которую потом можно показывать людям в алертах.
RUN cat ./postrun.sh && \ – выводим содержимое скрипта, который будет осуществлять прогон. Тоже проверка, чтобы понимать, что именно будет выполняться.
echo -e "================== \nThis is the end... \n==================" – просто обозначаем конец действий при сборке образа, чтобы было проще это отследить.
CMD cat ./postrun.sh – то же самое, что и RUN, только не выполняется в процессе сборки образа. Добавлено, чтобы была секция CMD, на всякий случай, если понадобится что-то изменить, но вообще, вместо CMD будут использоваться инструкции из command (если есть) в YAML-файле.
Исполняемый скрипт: postrun.sh
#!/bin/bash
echo -e "=============================== \nСодержимое исполняемого скрипта \n===============================" && \
cat ./postrun.sh && \
echo -e "========= \nК О Н Е Ц \n=========" && \
sleep 3s && \
echo -e "======================== \nСкачиваем файл коллекции \n========================" && \
wget -O collection.json --header "Authorization: token $GHT" $COLL && \
echo -e "======================================== \nОткрываем скачанный файл collection.json \n========================================" && \
cat ./collection.json && \
echo -e "========= \nК О Н Е Ц \n========="
echo -e "======================== \nСкачиваем файл окружения \n========================" && \
wget -O environment.json --header "Authorization: token $GHT" $ENVR && \
echo -e "========================================= \nОткрываем скачанный файл environment.json \n=========================================" && \
cat ./environment.json && \
echo -e "========= \nК О Н Е Ц \n========="
echo -e "======================= \nЗапускаем прогон тестов \n=======================" && \
newman run collection.json -e environment.json \
--env-var "Url=$Url" \
--suppress-exit-code \
--reporter-slackmsg-collection $REPO \
--reporter-slackmsg-environment $BRANCH -r slackmsg \
--reporter-slackmsg-webhookurl $SLACK && \
echo -e "====================================================== \nВсё. У тебя есть минута, чтобы стянуть логи, если надо \n======================================================" && \
sleep 60s
echo – просто вывод любой далее написанной информации в консоль. Флаг -е позволяет использовать перенос строк \n, чтобы получать сообщения вида:
=======================
Запускаем прогон тестов
=======================
Используется тут как логирование. Чтобы при эксцессах было понятнее, на каком шаге случилась проблема.
&& – логический оператор "и", который означает, что следующая команда будет выполнена, только если предыдущая была выполнена успешно.
\ – символ переноса строки, чтобы можно было писать скрипт не в одну строку, а с помощью нескольких, компактно.
cat ./ postrun.sh && \ – выводим содержимое скрипта, который будет осуществлять прогон, чтобы понимать, что именно будет выполняться.
sleep 3s && \ – пауза в 3 секунды, чтобы успеть проанализировать скрипт, пока логи не побежали дальше.
wget -O collection.json --header "Authorization: token $GHT" $COLL && \ – скачиваем файл коллекции из репозитория. Флаг -O позволяет сразу переименовать файл в нужный для исполнения в скрипте, что в свою очередь убирает необходимость соблюдения нейминга для пользователя. Аналогичная команда используется и для скачивания окружения.
cat ./collection.json && \ – выводим содержимое ранее скачанного файла. Используется как проверка на то, что файл действительно скачан и не имеет некорректных данных. Аналогичная команда используется для проверки скачанного файла окружения.
newman run collection.json – собственно, сам прогон тестов. Если тесты прошли успешно, хук завершится корректно. Если какие-то из тестов упали, то деплой завершится с ошибкой (да, там будут ещё и повторные попытки прогона, но итог всё равно один).
-e environment.json – флаг, который указывает, из какого файла брать ранее заданные переменные окружения в Postman.
--env-var "Url=" – флаг, с помощью которого задаём значения для ранее прописанных переменных окружения в Postman. В данном случае мы указываем, какое значение хотим передать переменной Url.
Так как одним из наиболее распространненых корпоративных мессенджеров является Slack, то я возьму его за пример с использованием репортеров и организации нотификаций в корпоративный мессенджер. В любом случае, можно найти репортеры, подходящие под ваш мессенджер, либо написать такие самостоятельно.
$REPO – переменная, которая хранит в себе название сервиса, для которого используется прогон коллекции. Передаётся флагом --reporter-slackmsg-collection в репорт в строку Collection.
$BRANCH – переменная, которая хранит в себе название ветки, для которой осуществляется развёртывание. Передается флагом --reporter-slackmsg-environment в репорт в строку Environment.
-r slackmsg – флаг, инициализирующий отправку репорта (в данном примере – в Slack).
$SLACK – переменная, которая хранит в себе адрес слак-хука, который мы положили в волт. Передаётся флагом --reporter-slackmsg-webhookurl.
Все эти переменные были указаны в теле хука.
sleep 60s – пауза в минуту, чтобы можно было успеть скачать логи при необходимости. Будем учитывать, что джоб в арго моментально исчезает после завершения в нём каких-либо действий.
Алгоритм действий
Создаём коллекцию в Postman для нашего сервиса.
Экспортируем собранную коллекцию из Postman в файл.
Аналогично экспортируем окружение из Postman в файл.
Загружаем эти два файла в любое место в нашем репозитории. Например, это может быть отдельный репозиторий для хранения таких артефактов. Либо вы можете положить эти файлы в репозиторий того сервиса, к которому они относятся.
Добавляем файлы коллекции и окружения в репозиторий.
Ищем в репозитории YAML-файл нашего сервиса (как правило, лежит в папке .k8s) и редактируем его, вставляя следующий блок:
hooks:
- name: newman-tests
image:
newman-tests
tag: 1.1.3
env:
- name: GHT
value: secrets
- name: Url
value: 'ingress сервиса, например: example.service.ru'
- name: ENVR
value: 'https://raw.githubusercontent.com/repo/service/hook/environment.json'
- name: COLL
value: 'https://raw.githubusercontent.com/repo/service/hook/collection.json'
- name: SLACK
value: vault:secrets/slack#webhook
- name: REPO
value: "servicename"
- name: BRANCH
value: "{{ .Values.Branch }}"
command:
- "/bin/bash"
- "-c"
- "./postrun.sh"
stage: post-install, post-upgrade
resources:
cpu: 150m
memory: 512Mihooks – инициализация хука; блок, в котором прописываются нужные хуки.
name – имя хука.
image – образ, из которого будет формироваться хук (тот самый, что собирали в Dockerfile).
tag – тэг этого образа; грубо говоря, версия этого образа.
env – переменные окружения, которые планируется использовать в работе хука.
- name: GHT
value: secrets
Переменная GHT используется для передачи токена репозитория для дальнейшего скачивания файлов.
- name: Url
value: 'ingress сервиса, например: example.service.ru'
Переменная Url передает, соответственно, url в файл environment.json, который, в свою очередь, потом будет использоваться в collection.json при прогоне тестов.
- name: ENVR
value: 'https://raw.githubusercontent.com/repo/service/hook/environment.json'
В переменной ENVR указывается ссылка на скачивание файла Postman-окружения из репозитория.
- name: COLL
value: 'https://raw.githubusercontent.com/repo/service/hook/collection.json'
В переменной COLL указывается ссылка на скачивание файла Postman-коллекции из репозитория.
- name: SLACK
value: vault:secrets/slack#webhook
Переменная SLACK используется для прописывания url для webhook.
- name: REPO
value: "servicename"
Переменная REPO используется для указания проекта, для которого будет осуществляться прогон. Далее эта переменная будет выводиться в репорт с помощью скрипта. Так как нет подходящих переменных для определения имени репозитория автоматически, то придётся эту переменную прописать самостоятельно.
- name: BRANCH
value: "{{ .Values.Branch }}"
Переменная BRANCH используется для отображения ветки, для которой осуществлялось развёртывание. Далее эта переменная будет выводиться в репорт с помощью скрипта.
command – команды, которые будут выполнены при активизации хука.
stage – указывает на конкретизацию вида используемого хука.
post-install – выполняет команды, заложенные в хук, после первого развертывания приложения
post-upgrade – выполняет команды, заложенные в хук, при последующих обновлениях приложения (развёртывания следующих версий уже существующего сервиса).
resources – указание ресурсов, используемых при развертывании хука.
сpu – процессор.
memory – оперативная память.
7. Сохраняем изменения; теперь можно выкатывать.
8. Всё!
Эти тесты теперь будут крутиться всегда – и во время выкатки в мастер, и во время веточных выкаток (если ветка была выделена именно из мастера с этими изменениями).
А результаты прогонов отправляются в тот канал, который настроили в вашем корпоративном мессенджере:
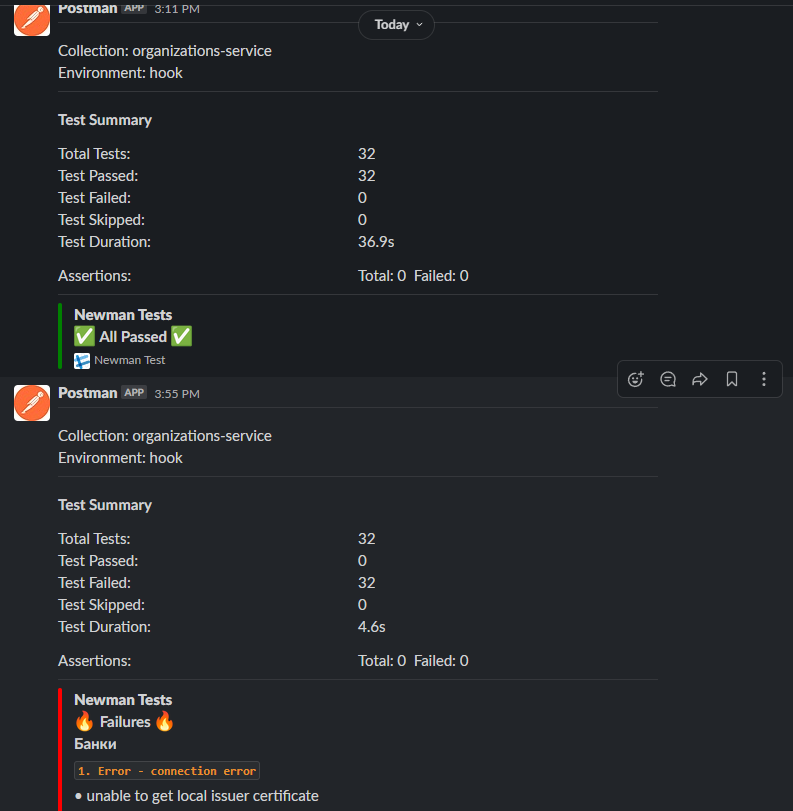
Итого: ключевые возможности хуков для проверок
Итак, теперь у нас есть механизм, который довольно легко запустить: один раз собираем образ, а дальше нужно будет только положить в репозиторий файлы коллекций и окружения, а также добавить секцию хука в YAML-файл приложения. И всё, дальше будет работать!
Прогоны осуществляются автоматически, так как хук сам понимает, когда приложение раскатано или обновлено, и затем стартует сценарий, который в хук заложили.
Ещё хук понимает, что приложение по какой-то причине не работает. В таком случае наши тесты не станут прогоняться на заведомо нерабочем приложении, что в итоге избавит нас от лишних алертов о том, что тесты не прошли.
Такой прогон также запускается параллельно, что никоим образом не блокирует работу или тестирование сервиса.
А после завершения сценария хук ещё и сам за собой удаляет все ресурсы k8s, тем самым не раздувая их в пределах квоты.
Ограничения хуков и финальные рекомендации
Понятное дело, что описанный выше подход подойдёт не для только лишь всех. Первым и основным препятствием на вашем пути может стать архитектура проекта. Могут не использоваться k8s и/или Helm – в этом случае механизм применить не получится.
Могут возникнуть проблемы для многосоставных сервисов: когда сервис зависит от множества интеграций, которые хранятся с ним в одном репозитории и разворачиваются вместе с основным сервисом. Такое развёртывание не всегда идёт по порядку – какому-то из сервисов везёт с раннером и он выкатывается быстрее, а какому-то другому не везёт.
В таком случае выкатка будет происходить “вразнобой”, отслеживать полную готовность будет непросто.
Кроме того, хук отслеживает этап цикла только для того сервиса, в который он добавлен. Как следствие, добавление хука по описанному выше сценарию приведёт к тому, что хук по готовности основного приложения запустит сценарии с проверками, которые завершатся с ошибками, так как интеграции ещё не готовы частично или полностью.
И да, нужно обязательно обращать внимание на ресурсы: для Helm-хуков они свои, и их может не хватить, поэтому лучше задать с запасом.
Если говорить про Postman-коллекции и их прогон, то стоит выделить дополнительные тесты для ручек (например, ассерт на статус-код, содержимое json и тому подобное). В противном случае, смысла в таких проверках не очень-то и много – если там лишь голый get и неважно, что он там ответит.
Newman нынче требует версию Node.js от 16 и старше. Если решите поставить версию 20 на будущее, то она ставится не на всё (например, на Ubuntu 18 – уже нет). Поэтому выбирайте заранее актуальную операционную систему для своего образа (у меня это Ubuntu 22.04).
Helm-хуки делают дело
Прямо сейчас мы в Сравни активно внедряем механизм Helm-хуков, предварительно договорившись, какие проверки для ручек мы точно хотим видеть (не голый get). Некоторые команды уже настроили себе сценарии прогона юнит-тестов через хуки.
В ближайших планах – прикрутить миграции баз данных для стендов и перенастроить нагрузочное тестирование.
А ещё планируем добавить алерты об удалении стендов: по нашему процессу стенды удаляются автоматически через определенный промежуток времени, и иногда этого времени не хватает, если фича глобальная или тяжёлая.
Насколько это вообще уместно — искать механизмы для проверки качества кода не среди специализированных инструментов, сфокусированных на тестировании, а среди DevOps-штук (и кто знает, в каких ещё смежных областях)? На мой взгляд, это оправданно ровно настолько, насколько мы ценим возможность забыть о скрупулезных проверках сервиса по каждой ручке, потратив немного времени на настройку автоматических проверок. Откуда бы оно ни взялось, главное – чтобы работало.