
Приветствую всех! Меня зовут Адахан, и я студент колледжа при факультете "Программная инженерия и высокие технологии" (коротко: Data Scientist). Решив написать статью, я решил поделиться своим опытом и знаниями, которые, надеюсь, окажутся полезными для начинающих специалистов в области анализа данных.
В наше время огромное количество данных формируется и хранится в базах данных, и умение эффективно работать с этой информацией — ключевой навык для аналитиков данных. В статье я расскажу о том, как использовать SQL для работы с данными в базах данных и как Python может стать мощным инструментом для доступа и анализа этих данных.
Про какие данные идет речь?
Про данные которые хранятся в табличном виде. Прям как в excel, только с id (уникальный идентификатор)

Например, таблица студентов:
id |
name |
1 |
Руслан |
2 |
Максат |
3 |
Алибек |
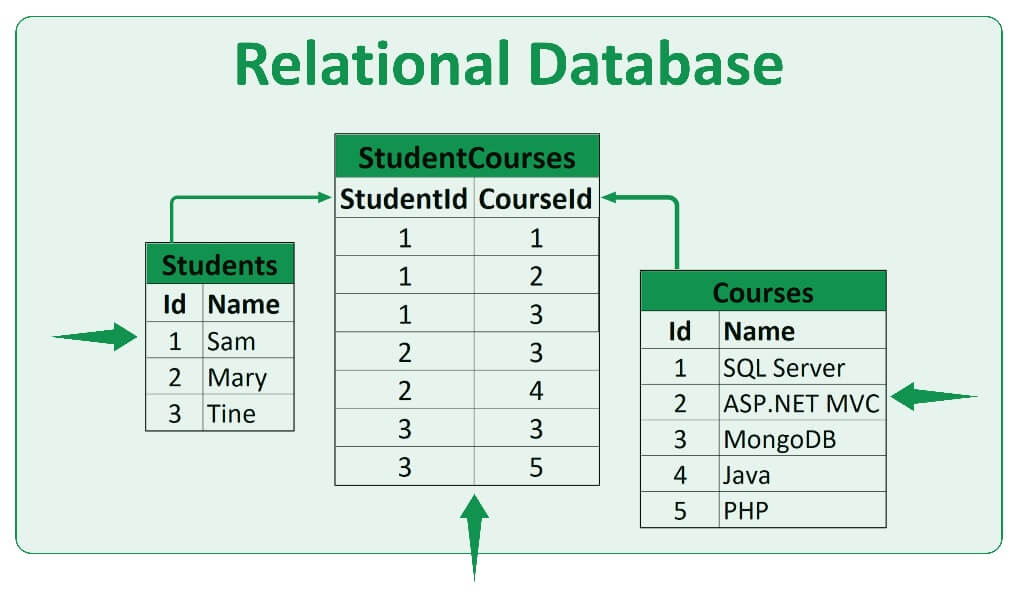
Только вот это простейший пример из самых простых. В реальной жизни, в реальных программах этих таблиц могут быть очень много и каждый из них может быть связан с друг другом ????. Кстати, это называется Relational Database (связные таблицы). Например, у вас появилась новая таблица, где есть названии курсов по колледжу и их id. Вдруг, вам поручили создать еще одну таблицу, где есть имя студента и курс в который он/она ходит. Вы то легко напишите это в excel, только вот в базе нужно создать новую связную таблицу, в одной будет храниться id студентов, в другой id курсов:

Таким образом, когда мы будем выводить данные из таблички "StudentCourses" она будет ссылаться на другие две таблички, а именно на их id, которое можно назвать еще "Primary Key", откуда будет брать имена студентов и наименовании курсов. Вот еще наглядный пример если не понял :)
{kind=link}
То есть, вместо того чтобы записывать одну большую таблицу, мы создали несколько. Данный процесс называют "нормализацией".
Если заметили, выше на схеме, таблички "Students" и "Courses" имеют айдишки, которые мы назвали "Primary Key" (первичный ключ), а вот эти же айдишки в таблице "StudentCourses" будут называться "Foreign Key" (внешний ключ). А тип связи называется многие ко многим, что будет означать, что у многих студентов могут быть много разных курсов.
Вот пример заполнения таблицы "StudentCourses":
student_id |
course_id |
1 |
2 |
2 |
2 |
3 |
2 |
1 |
4 |
1 |
5 |
Смотрим в старую табличку, где под id=1, это Руслан, то есть у Руслана есть курсы по id = 2, 4, 5, а их наименовании хранятся в табличке "Courses".
???? Таких типов связей четыре:
Один к Одному (One-to-One):
Каждая строка в одной таблице связана с одной и только одной строкой в другой таблице, и наоборот.
Пример: Таблица "Студенты" связана с таблицей "Паспорта", где каждый студент имеет только один паспорт, и у каждого паспорта есть только один студент.
Один ко Многим (One-to-Many):
Каждая строка в одной таблице может быть связана с несколькими строками в другой таблице, но каждая строка во второй таблице связана только с одной строкой в первой таблице.
Пример: Таблица "Отделы" связана с таблицей "Сотрудники", где каждый отдел может иметь несколько сотрудников, но каждый сотрудник может быть связан только с одним отделом.
Многие ко Многим (Many-to-Many):
Множество записей в одной таблице может быть связано с множеством записей в другой таблице.
Эта связь обычно реализуется с использованием дополнительной промежуточной таблицы, которая содержит внешние ключи обеих таблиц.
Пример: Таблица "Студенты" связана с таблицей "Курсы" через промежуточную таблицу "Расписание", где студенты могут записаться на несколько курсов, и каждый курс может иметь несколько студентов.
Саморекурсия (Self-Referencing):
Таблица имеет отношение к самой себе.
Пример: Таблица "Сотрудники" может содержать столбец "Руководитель", который ссылается на другую запись в той же таблице, указывая, кто является руководителем каждого сотрудника.
Что такое SQL?
Structured Query Language — «язык структурированных запросов».
Стандартный язык с помощью которого ты можешь извлекать, вставлять, удалять, в целом манипулировать данными в базе данных.
Для всего этого делаются так называемые "sql-запросы", а видов у них целых четыре:
DDL (Data Definition Language). Определяет и изменяет структуру базы данных, такие как создание, изменение и удаление таблиц.
DML (Data Manipulation Language). Осуществляет манипуляции с данными внутри таблиц, включая операции вставки (INSERT), обновления (UPDATE) и удаления (DELETE).
DCL (Data Control Language). Управляет правами доступа к данным, включая выдачу разрешений и отзыв прав.
TCL (Transaction Control Language). Осуществляет управление транзакциями, такими как фиксация (COMMIT) и откат (ROLLBACK) изменений.
Думаю в этой статье ограничимся первыми двумя, вот простые наглядные примеры:
1. DDL (Data Definition Language):
1.1 Создаем таблицу «employees»:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
job_title VARCHAR(100),
salary DECIMAL(10, 2)
);1.2 Изменение таблицы (добавление колонки):
ALTER TABLE employees
ADD COLUMN hire_date DATE;1.3 Удаление таблицы:
DROP TABLE employees;2. DML (Data Manipulation Language):
2.1 Вставка данных:
INSERT INTO employees (employee_id, first_name, last_name, job_title, salary, hire_date)
VALUES (1, 'John', 'Doe', 'Software Engineer', 75000.00, '2022-01-01');2.2 Обновление данных:
UPDATE employees
SET salary = 80000.00
WHERE employee_id = 1;2.3 Обновление данных:
DELETE FROM employees
WHERE employee_id = 1;А для чего СУБД?
Database Management System - система управления базами данных.
До этого мы говорили про данные и SQL-запросы чтобы работать с ними. Только вот, где все это можно увидеть, потрогать в визуальном плане? Для этого создаются программные обеспечении, предназначенные для создания и управления базами данных. Они также предоставляют интерфейс для взаимодействия с этими данными.
Примеров много, например я использую PostgreSQL + pgAdmin, но так как мы изучаем (в колледже) Flask, а там обычно встроен SQLite, что делает его удобным для небольших и простых веб-приложений, будем использовать именно его.
???? Доступ к данным через Python (SQLite3)
Давайте вспомним, как мы доставали данные из csv файла через Pandas, вроде это было вот так:
import pandas as pd
df = pd.read_csv('test.csv')И выводиться таблица. Только вот теперь нужно будет доставать данные через подключение к БД. А вот через Pandas, NumPy будем в дальнейшем манипулировать данными.
Создаем новый проект. Можете использовать любой IDE (Интегрированная среда разработки), я же буду использовать VScode и начнем с установки Flask:
pip install flaskПишем в app.py следующее:
from flask import Flask, render_template
import sqlite3
app = Flask(__name__)
# конфигурация базы данных (SQLite)
DATABASE = 'example.db'
# функция для создания подключения к базе данных
def get_db():
db = sqlite3.connect(DATABASE)
db.row_factory = sqlite3.Row
return db
# Инициализация базы данных
def init_db():
with app.app_context():
db = get_db()
with app.open_resource('schema.sql', mode='r') as f:
db.cursor().executescript(f.read())
db.commit()
# Маршрут для отображения данных из базы
@app.route('/')
def show_data():
db = get_db()
cursor = db.execute('SELECT id, name, age FROM users')
users = cursor.fetchall()
return render_template('index.html', users=users)
if __name__ == '__main__':
init_db() # Инициализация базы данных перед запуском приложения
app.run(debug=True)
-
get_db()- Функция для создания подключения к базе данных:Создает соединение с базой данных SQLite, указанной в переменной
DATABASE.Устанавливает
row_factoryвsqlite3.Row, что позволяет получать результаты запроса в виде объектовRow.Возвращает объект соединения с базой данных.
-
init_db()- Инициализация базы данных:Открывает соединение с базой данных.
Считывает содержимое файла
schema.sql, который содержит SQL-код для создания таблицы пользователей.Исполняет SQL-код для создания таблицы.
Фиксирует изменения в базе данных.
-
show_data()- Маршрут для отображения данных из базы:Создает соединение с базой данных.
Выполняет SQL-запрос
SELECT id, name, age FROM users, который извлекает данные из таблицыusers.Получает результаты запроса в виде списка пользователей.
Возвращает результат запроса, передавая его в шаблон HTML
index.htmlс использованием Flask-функцииrender_template.
В предположении, что у нас имеется файл schema.sql с определением таблицы пользователей:
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER NOT NULL
);А также файл templates/index.html для отображения данных:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Users</title>
</head>
<body>
<h1>User List</h1>
<ul>
{% for user in users %}
<li>{{ user['name'] }}, {{ user['age'] }} years old</li>
{% endfor %}
</ul>
</body>
</html>
Таким образом, мы создаем простое Flask-приложение, которое использует базу данных SQLite для хранения пользовательских данных. Приложение создает таблицу "users" с полями id, name и age. Маршрут / извлекает данные из базы и передает их в шаблон HTML для отображения.
В итоге, проект выглядит следующим образом:

Единственное, что я изменил, это добавил sql-запросы для добавление данных в БД:
db.execute('INSERT INTO users (name, age) VALUES (?, ?)', ('Никита', 19))
db.execute('INSERT INTO users (name, age) VALUES (?, ?)', ('Артур', 18))В терминале запускаем веб-приложение:
python app.py(можете перейтиhttp://127.0.0.1:5000/ - адрес по умолчанию)

Все это довольно простые примеры, и нужно понимать что это низкоуровневый способ, но иногда он может быть полезен для простых приложений.
import sqlite3
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
cursor.execute('SELECT * FROM users')
users = cursor.fetchall()Просто подключаемся (3 строка), создаем объект курсора (4), выполняем sql-запрос (5) и извлекаем всё (6), сохраняя в переменной "users" в виде списка кортежей. То есть, после выполнения этих шагов переменная users содержит все строки из таблицы "users". Каждая строка представлена в виде кортежа, и переменная users представляет собой список таких кортежей.
С использование SQLAlchemy (ORM)
Выше мы смогли получить данные через методы и sql-код, только вот есть другой способ, например использование SQLAlchemy. SQLAlchemy упрощает взаимодействие с базой данных и предоставляет возможность использования ORM (Object-Relational Mapping) для работы с данными в объектно-ориентированной форме.
Перепишем app.py:
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# Конфигурация базы данных (SQLite)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///example.db'
db = SQLAlchemy(app)
# Модель для таблицы "users"
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50), nullable=False)
age = db.Column(db.Integer, nullable=False)
# Создание всех таблиц в базе данных
db.create_all()
# Маршрут для отображения данных из базы
@app.route('/')
def show_data():
users = User.query.all()
return render_template('index.html', users=users)
if __name__ == '__main__':
app.run(debug=True)-
Добавлена конфигурация SQLAlchemy:
app.config['SQLALCHEMY_DATABASE_URI']устанавливает URI для подключения к базе данных. В данном случае, мы используем SQLite.
-
Определена модель User:
Создан класс
User, который наследуется отdb.Model(базового класса SQLAlchemy для моделей).Определены атрибуты класса (
id,name,age), которые соответствуют столбцам таблицы "users".
-
Создание всех таблиц в базе данных:
db.create_all()создает все таблицы, определенные в нашем приложении.
-
Заменен код для извлечения данных:
users = User.query.all()используется для извлечения всех записей из таблицы "users" с использованием ORM.
+ Бонус (Получение данных через API)
Да-да, данные можно получать с API через Python. Стопе, а вы знаете что такое API? ????

API (Application Programming Interface) - Как Книга Рецептов для Разработчиков.
Ведь, он определяет какие запросы вы можете отправлять, какие данные вы будете получать в ответ, и как взаимодействовать с приложением или сервисом.
Данные передаются в формате JSON & XML. Два основных формата для передачи данных по API – JSON (JavaScript Object Notation) и XML (eXtensible Markup Language). JSON стал более популярным благодаря своей легковесности и простоте чтения.
Как выглядит синтаксис XML:
<person>
<name>Азамат</name>
<age>30</age>
<address>
<city>Bishkek</city>
<zip>12345</zip>
</address>
<contacts>
<contact type="email">azamat@gmail.com</contact>
<contact type="phone">0707777777</contact>
</contacts>
</person>
А теперь JSON:
{
"person": {
"name": "Азамат",
"age": 30,
"address": {
"city": "Bishkek",
"zip": "12345"
},
"contacts": [
{
"type": "email",
"value": "azamat@gmail.com"
},
{
"type": "phone",
"value": "0707777777"
}
]
}
}
Что это такое и в каком формате ясно, но а как теперь достать эти данные с помощью Python инструментов? Для этого нам понадобиться библиотека requests и пример API для тестовых данных. В качестве примера будем использовать Agify.io. (побольше таких api тут) С помощью него можно предсказывать возраст по имени. Мы будем отправлять https/http запросы через методы GET/POST ????
Для того чтобы получить данные, нам нужно отправить запрос к их API: https://api.agify.io
В формате: https://api.agify.io?name=azamat

Я вручную вставил ссылку, и мы видим следующие данные в виде json, где возраст Азамата равен 34 годам. Но вручную мы это делать не будем, из за чего напишем код, который, например будет доставать возраст при вводе имени пользователем.
Когда человек вводит что-то, мы сохраняем это в переменную "name", и можем вставить это в url: https://api.agify.io?name={name}
Меняем наш старый код в app.py на новый:
from flask import Flask, render_template, request
import requests
app = Flask(__name__)
# Адрес Agify.io API
agify_api_url = "https://api.agify.io"
@app.route("/", methods=["GET", "POST"])
def index():
predicted_age = None
if request.method == "POST":
# Получаем имя из формы
name = request.form.get("name")
# Отправляем запрос к Agify.io API
response = requests.get(f"{agify_api_url}?name={name}")
if response.status_code == 200:
# Парсим JSON-ответ
data = response.json()
# Извлекаем предполагаемый возраст
predicted_age = data.get("age")
return render_template("index.html", predicted_age=predicted_age)
if __name__ == "__main__":
app.run(debug=True)index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Agify.io Age Prediction</title>
</head>
<body>
<h1>Agify.io Age Prediction</h1>
<form method="post">
<label for="name">Enter Name:</label>
<input type="text" id="name" name="name" required>
<button type="submit">Predict Age</button>
</form>
{% if predicted_age %}
<p>Predicted Age: {{ predicted_age }} years</p>
{% endif %}
</body>
</html>
В терминале: python app.py
Результат:


Заключение
Начиная с excel, видов связей, sql запросов мы пришли к разным видам извлечения данных через Python инструменты. Данные, их очень много, и data scientist специалисту нужно уметь правильно извлекать, обрабатывать, манипулировать этими данными. Надеюсь вы дальше углубитесь в эти темы, удачного пути!
На этом всё, the end :)
Комментарии (11)

nameisBegemot
28.12.2023 06:28+1Справедливости ради, это не пример доступа к базам через пион. Это пример орм на фласке.

lair
28.12.2023 06:28В наше время огромное количество данных формируется и хранится в базах данных, и умение эффективно работать с этой информацией — ключевой навык для аналитиков данных. В статье я расскажу о том, как использовать SQL для работы с данными в базах данных и как Python может стать мощным инструментом для доступа и анализа этих данных.
[...]
но так как мы изучаем Flask, а там обычно встроен SQLite, что делает его удобным для небольших и простых веб-приложений,Так у вас статья про доступ к данным для анализа данных или про изучение Flask?

Akina
28.12.2023 06:28+3Это не статья, а какая-то каша. Взять немного фактов, причём не проверяя, правильно ли они взяты, добавить воды и перемешать. И.. надеюсь, всё же опечатки, а не ошибки, но что-то их многовато.
это называется Relation DataBase (связные таблицы).
Во-первых, таки Relational. Во-вторых, Database переводится как "база данных", при чём тут таблицы?
То есть, вместо того чтобы записывать одну большую таблицу, мы создали несколько. Данный процесс называют "нормализацией".
Данный процесс так не называется. Нормализация - это составная часть процесса разработки схемы, по которой будут создаваться эти "несколько таблиц".
Один к Одному (One-to-One)
В реальности практически не существует. Мало кто решается на создание такой связи. Обычно это One-to-(One or Zero).
Саморекурсия (Self-Referencing)
Всего лишь частный случай One-to-Many. Выделять его как какой-то особый тип связи - совершенно безосновательно.
======
Дальше, в общем, даже смотреть не стал. Как показывают предыдущие комментарии - наверное, и правильно.

ssmaslov
28.12.2023 06:28Писали бы уж "мне лично one to one в практике не встречалось" . One to one (оно же горизонтальное партиционирование) типпичный прием при создании нагруженых систем, я буквально ежедневно вижу то на что "почти никто не решается" в реализации десятков разных систем...
По исходной статье - название действительно не соответствует содержанию
Akina
28.12.2023 06:28One to one (оно же горизонтальное партиционирование) типпичный прием при создании нагруженых систем, я буквально ежедневно вижу то на что "почти никто не решается" в реализации десятков разных систем...
Вы уверены, что имеете именно one-to-one? то есть оба взаимно-ссылающихся поля/выражения не только уникальны, но и NOT NULL? Такая связь реализуема далеко не в каждой СУБД, ибо требует отложенной проверки целостности внешних ключей. Если отложенной проверки нет, то при наличии такой связи ни в одну из ссылающихся таблиц нельзя добавить запись, ибо она не имеет соответствия в другой таблице, и проверка на ссылочную целостность в момент добавления приведёт к ошибке.
Я, например, использовал этот факт в MySQL для простого создания преопределённых статических Read-only таблиц - без удаления внешнего ключа с такой таблицей вообще ничего нельзя сделать... правда, ценой двойного дискового пространства.

prolibek
28.12.2023 06:28Неплохая статья для начинающих, однако, автору следует попрактиковаться в написании статей и программировании. Рекомендую к прочтению чайникам.

Grommy
28.12.2023 06:28Согласен - отлично годится для общего обзора 0" на пальцах", а дальше - можно и почитать, кому интересно и хочется :)
Спасибо автору!

ValeryGL
28.12.2023 06:28-2Зачёт за картинку, правда очень понравилась. У меня тоже была идея объяснять, что такое (СУ)БД через сравнение с табличками Excel

Vest
28.12.2023 06:28+1Зачем?
nameisBegemot
28.12.2023 06:28Ну по сути, реляционные базы данных, иллюстрируются как эксель таблицы. Ну или эксель и реляционные базы внешне схожи, если не вдаваться в реализацию
Vest
28.12.2023 06:28Не надо так делать. В Экселе можно много чего творить, что БД не должна делать. Хоть рейтрейсинг обсчитывайте.
Пусть человек изучает БД по классике, как будто бы Экселя и нет вовсе. Все так учили, никто не помер.
nameisBegemot
Ну по сути, реляционные базы данных, иллюстрируются как эксель таблицы. Ну или эксель и реляционные базы внешне схожи, если не вдаваться в реализацию