

В этом материале я бы хотел поделиться с начинающими AI-художниками информацией, которая сразу отвечает на все вопросы, и помогает начать использовать StableDiffusion в качестве генеративного инструмента.
Я бы очень сильно хотел чтобы такой материал попался мне, когда я только начинал познавать возможности SD. Тут я попытался кратко и концентрированно описать все те знания и инструменты, которые имеют большое практическое значение при работе c SD.
Так же в конце будет изложен mindset, который необходимо иметь чтобы научиться пользоваться SD. Я буквально попытаюсь научить вас думать как AI художник.
Поэтому без лишних слов, начинаем.
Установка
Рассмотрим самый простой и распространённый вариант установки SD к себе на компьютер.
Предполагается что у вас есть:
Windows 10+
nvidia rtx 3xxx +
опытный пользователь ЭВМ
Обновляем драйвер
Nvidia долго не могла починить баг связанный с замедлением работы SD. В последних версиях он был починен, по этому перед тем как начинать, следует обновить драйвер до последней версии.
Референсные значения скорости:
6-7 it/sпри генерации512x512семплеромEuler A
Если скорость меньше, значит с драйвером до сих пор что-то не так, и можно попробовать другую версию.
Окружения для установки и запуска
Для работы, установки и обновления Stable Diffusion на компьютере должен быть установлен Python 3.10 и git.
Скачать можно тут:
-
https://www.python.org/ftp/python/3.10.6/python-3.10.6-embed-amd64.zip
ВАЖНО: при установке нужно поставить галочку
Add to PATH
Установка WebUI
Нужно выбрать место куда будет устанавливаться SD. В папке должно быть свободно 100+ гб. Сам SD займёт порядка 30, остальное место будет нужно для моделей, каждая из которых весит от 2 до 6гб.
Отдельную папку для SD создавать не нужно, разве что общую папку для AI софта по типу: D:/AI.
-
Открываем консоль в папке куда собираемся установить SD
В папке правой кнопкой ->
git bash hereлибо в пути пишем
cmd(да только эти 3 буквы), жмёмEnter
Копируем:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git sd-webuiВставляем нажимая правой кнопкой по консоли
Enter (SD начинает скачиваться в папку
sd-webui)Дожидаемся пока скачается весь репозиторий
Открываем папку
sd-webuiЗапускаем
webui-user.bat(ждём минут 20 пока он доустановит все зависимости)Можно так же добавить ярлык на рабочий стол для этого файла, чтобы каждый раз не лезть в папку для запуска SD.
Возможны и другие варианты установки, но этот лучше остальных так как:
У вас в системе появляется
gitМожно легко обновлять и откатывать версию SD
Расширения можно накатывать и откатывать в ручную
Можно тестировать фичи SD из раннего доступа
Аргументы запуска
У SD есть ряд параметров, которые влияют на его производительность.
Если у вас карта от Nvidia, то советую отредактировать файл webui-user.bat добавив/заменив нём параметр COMMANDLINE_ARGS на следующий:
set COMMANDLINE_ARGS=--opt-sdp-attention --opt-channelslast
Это самый быстрый конфиг для nvidia для карт 3xxx + серии.
Полный список параметров и оптимизаций:
WebUI
Работа со Stable Diffusion'ом происходит через специальный интерфейс - webui. Реализаций интерфейсов существует большое множество, но мы рассмотрим только самые интересные и практически полезные.
automatic1111
Есть много разных интерфейсов для SD. Но самый лучший из них - Automatic1111. Можно сказать что это референсная реализация, которая является стандартной на сегодняшний день. В первую очередь для неё делают все расширения, новые алгоритмы, оптимизации и т.п.
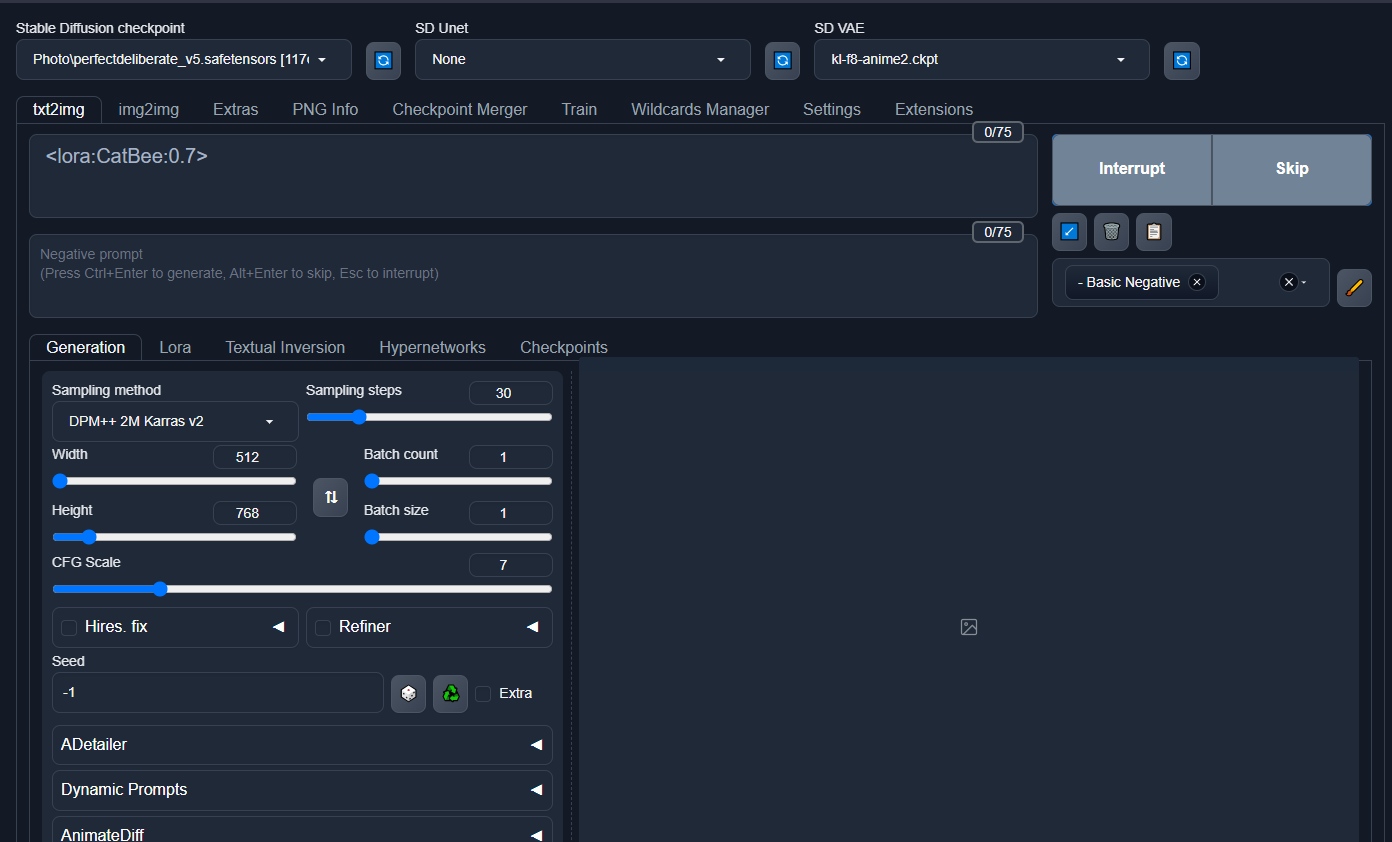
Но, есть и другие интересные инструменты, которые имеют скорее экспериментальный характер.
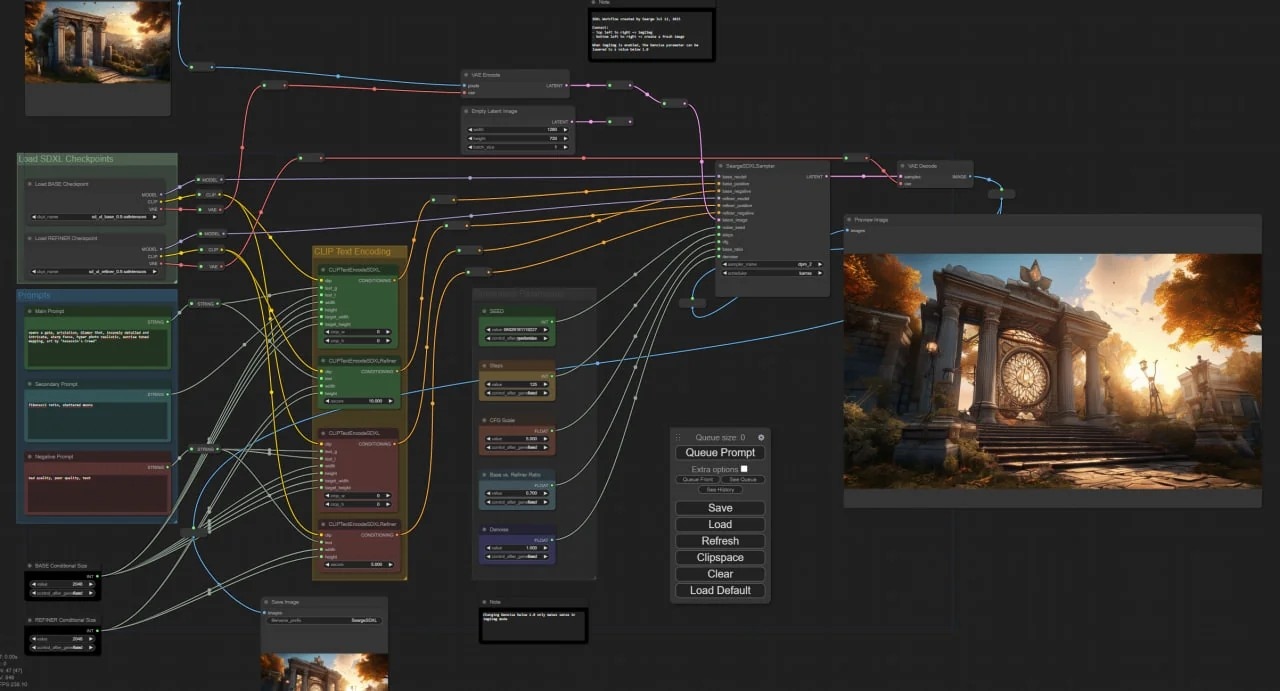
ComfyUI
К их числу я бы отнёс ComfyUI - WebUI построенный на принципах визуального программирования, где ты строишь граф и определяешь Pipeline генерации SD. Штука интересная, но слабо практически применимая, так как сложность взаимодействия возрастает значительно, но практической ценности для повседневных задач сильно не добавляется. Этакий спорт высоких достижений в мире StableDiffusion'a.
Можно установить как отдельно стоящее приложение, а так же есть Extension для Automatic'a.
Fooocus
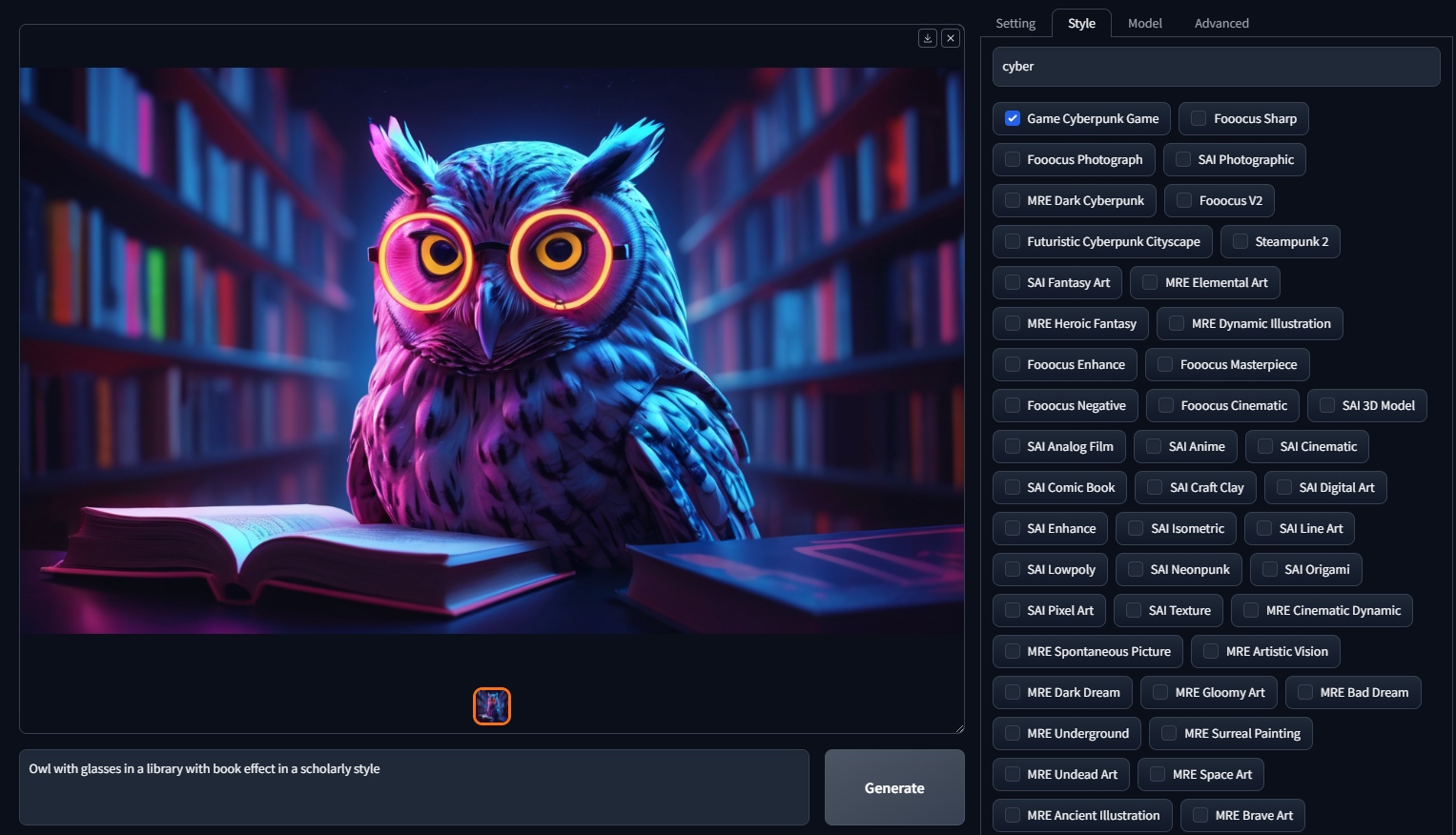
Так же есть Fooocus. Он находится на обратной стороне распределения. Максимально казуальная, неконтролируемая игрушка с одной кнопкой. Пользователю доступен Prompt, и пара параметров. Так же из плюсов стоит отметить большое кол-во заготовленных стилей. Авторы декларируют что у них некоторые алгоритмы реализованы круче/интереснее, и скорее всего это так. Но, отсутствие возможности адекватного изменения параметров, фиксированные разрешения, и попытка сделать всё за пользователя делают Fooocus игрушкой, а не профессиональным инструментом. В любом случае попробовать стоит.
Хороший обзор: Fooocus v2 — бесплатный Midjourney у вас на компьютере. Подробная инструкция по установке и использованию нейросети / Хабр
Модели
Stable Diffusion - архитектура нейросети. Сам по себе алгоритм её реализующий ни чего толком не сгенерит. Для этого нужны специальные "модели", представляющие собой набор весов для этой нейросети.
Базовые модели и SD-чекпоинты
Есть два пригодных для использования типа базовых моделей: 1.5 и XL.
1.5 это модели первого поколения, которые имеют меньший размер и тренировались на изображениях 512x512. Существует огромное кол-во чекпоинтов, основанных на базе 1.5: для самых разных стилей, уровней реалистичности и т.п. Так же модели на 1.5 работают быстрее чем XL (в 2-4 раза).
XL это один из последних этапов развития SD. Тренировали её на картинках 1024x1024 что с ходу дало больше деталей в текстурах и мелких деталях, но не сильно повлияло на крупные детали (композиция, форма, анатомия). Чекпоинтов меньше чем для 1.5, но XL относительно молодая технология, со временем их будет становиться больше.
Чекпоинт - дообученная базовая модель.
Разрешение на котором обучалась базовая модель влияет на появление крупных артефактов, которые возникают при "задирании" разрешения на этапе генерации.
Самая большая база чекпоинтов находится на сайте https://civitai.com
Чтобы добавить скачанную модель (.safetensors, .ckpt) в SD нужно:
положить её в папку
/sd-webui/models/Stable-Diffusionнажать кнопку обновить ???? рядом с селектором моделей
выбрать новую модель
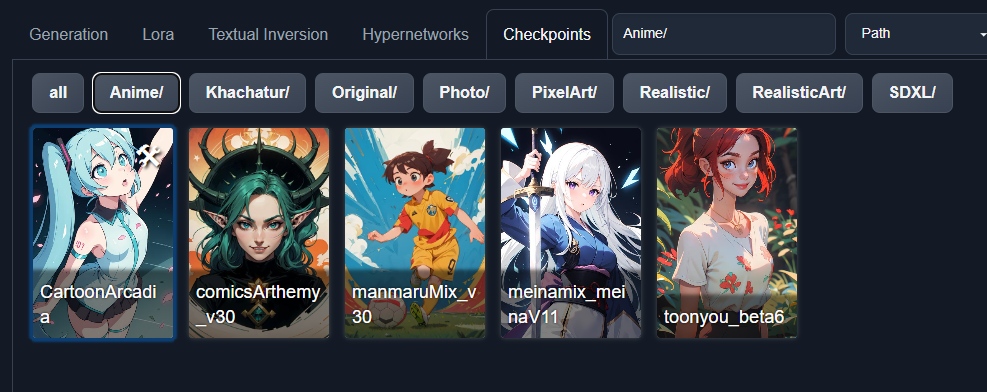
Для удобства советую создать в папке с моделями, поддиректории по типам моделей:
/models
/Stable-Diffusion
/Anime
/Art
/Realistic
/Pixelart
/...
Имя подпапки будет добавлено в список селектора наверху, и во вкладке с чекпоинтами добавятся одноимённые кнопки:
Формат чекпоинтов и их размер не влияет на качество генерации изображений. По этому не стоит отдавать предпочтение более крупным моделям. Если вы не собираетесь их обучать не заморачивайтесь. Предпочтение стоит отдавать .safetensors, исходя из соображений безопасности, так как в него нельзя встраивать произвольный код, который будет выполняться при загрузке моделей.
VAE
На последней стадии генерации SD применяет Variational Auto Encoder (VAE), чтобы окончательно "отрендерить" картинку. В моделях со встроенным VAЕ, результат генерации сразу будет хорошим. Но некоторые модели не имеют его в своём составе, и картинки в результате получаются тусклыми и мыльными. В этом случае имеет смысл использовать кастомный VAE.

Как правило, в описании модели есть ссылка на скачивание рекомендуемого VAE. Но если её там нет, имеет смысл воспользоваться чем-то вроде: https://civitai.com/models/23906/kl-f8-anime2-vaehttps://civitai.com/models/23906/kl-f8-anime2-vae
VAE устанавливаются в папку: /sd-webui/models/VAE
Quick Setting
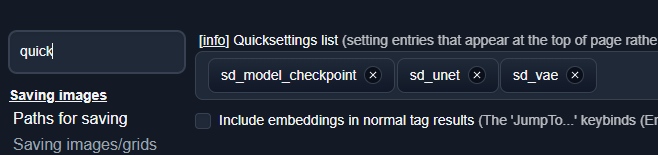
Так же для удобства советую добавить селектор VAE в Quick Setting чтобы его можно было быстро включать и отключать:
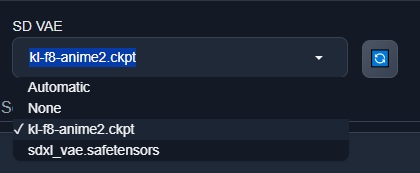
Для этого в настройках WebUI нужно найти слово quick, и в найденное поле добавить элемент sd_vae:
Lora, Lycrois, Textual Inversion, Hypernetworks
Помимо базовых моделей которые могут всё, есть ещё мини модели, которые применяются поверх базовой и заставляют её генерить какие-то конкретные концепции (персонаж, стиль, одежда, композиция, и другое).
Для SD было создано большое кол-во разных технологий FineTuneing'a. Самой удачной оказалась LoRA. Она лучше остальных подхватывает концепцию, быстро обучается (10-15 минут), и не требует слишком крупного датасета (можно обучить на 5-10 картинках).
На Civit'е есть огромное кол-во Lora для самых разных концепций.
Чтобы использовать lora при генерации, нужно:
Скачать модель
.safetensorsПоложить в папку
/sd-webui/models/LoraВо вкладке Lora нажать
Refresh-
Ткнуть на добавившуюся Lora -> в промпт добавится что-то типа
<lora:CatBee:0.7>Catbee- имя модели Lora0.7- степень её влияния. 1 = 100%. Сила может быть больше 1Большинство Lora лучше всего работает в диапазоне
0.3 - 0.8
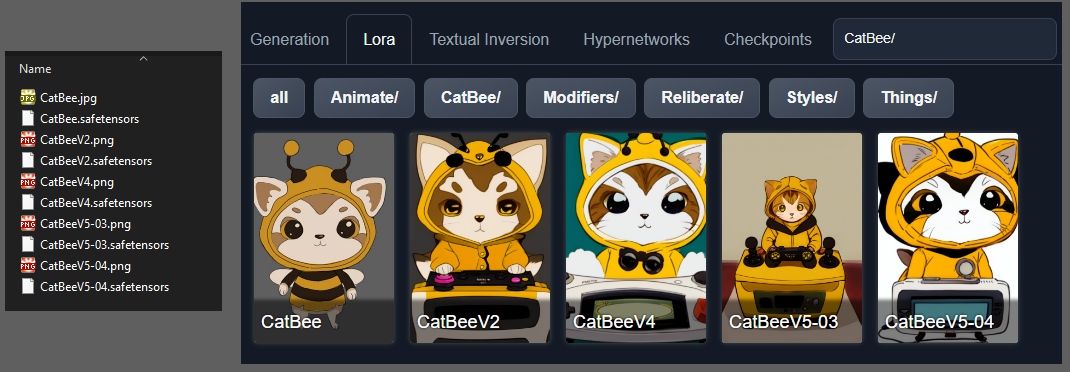
Так же я советую в папку к Lora'м и Checkpoint'ам добавлять одноимённые изображения, чтобы потом было проще ориентироваться в коллекции моделей:
Стоит отметить, что XL LoRA может работать только с XL моделями.
Prompting (txt2img)
Любая генерация начинается c Prompt'а.
Propmt - строка с набором терминов и специальных команд, которая определяет то что в итоге будет сгенерировано.
Prompt из текста преобразуется в набор чисел (токенов), который затем поступает на вход алгоритма генерации SD. Из этого следует что SD не особо понимает "смысл" того что вы пишете, сколько ищет соответствие набору ваших токенов в своём гиперпространстве. И затем создаёт на их основе изображение.
Что стоит добавлять в промпт:
-
Конкретные понятия
имя персонажа (
Shrek,King Arthur,Putin)-
возраст + пол
young,adult,maturegirl,girlfriend,woman,wife,grandma, ...
цвета
элементы окружения
одежду
...
-
Действие
Dancing,Jumpint,Fighting,Sitting on Sofa..
-
Стили
CyberpunkEngraving...
-
Художников / Фотографов
by SamDoesArtby Simon Stalenhagby Tim Walker...
Чего не стоит добавлять:
Попытки объяснить "как человеку". Не нужно пытаться написать понятное человеку правильно построенное предложение. Просто пишите через запятую набор понятий. Вес токенов получающихся на основе предлогов, пунктуации и прочих вспомогательных лингвистических конструкций стремится к нулю.
-
Огромные списки бестолковых токенов:
highly detailed, majestic, Baugh's brushwork infuses the painting with a unique combination of realism and abstraction, greg rutkowski, surreal gold filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr, realistic painting, natural skin, textured skin, Baugh's distinctive style captures the essence of the girl's enigmatic nature, inviting viewers to explore the depths of her soul, award winning art, artstationЭто ни чего не даст, скорее наоборот, ваши собственные токены будут размыты этим мусором
Asian в Negative. Глаза откроются, но это будет неестественно, лучше найдите то понятие которое склоняет модель к генерации азиатов, либо выберете другой Checkpoint. А еще лучше дописать в Positive - European, это сработает гораздо лучше.
Positive Negative
SD на вход принимает 2 промпта. Негативный и позитивный.
Как следует из названия, один будет усиливать появление тех или иных вещей в генерации, а второй будет ослаблять. Но надо понимать, что со 100% вероятностью исключить или заставить SD что-то сгенерить - не получится. Это скорее подсказки которые настоятельно советуют что-то делать или не делать.
В подавляющем большинстве случаев стоит использовать какой-то простой базовый Negative, чтобы в среднем улучшить генерации и сделать их более красивыми.
Я использую следующий Negative в качестве Базового:
[deformed | disfigured], poorly drawn, [bad : wrong] anatomy, [extra | missing | floating | disconnected] limb, (mutated hands and fingers), blurry
Он добавлен в конфиг SD, и мне не приходится каждый раз вводить его руками.
Чтобы добавить в конфиг SD negative prompt. Нужно:
открыть в текстовом редакторе (блокнот) файл:
/sd-webui/ui-config.json-
в параметр
"txt2img/Negative prompt/value"и"img2img/Negative prompt/value"вставить вышеприведённую строку:
Добавляем negative в Config WebUI'ки сохранить, перезапустить SD
теперь этот промпт всегда будет добавляться при запуске SD в поле Negative
Усилители токенов
Любое слово/понятие в промпте можно усиливать или ослаблять. Для этого слово нужно взять в скобки и добавить через двоеточие степень усиления:
green sigaret->(green: 0.6) sigaretслово Green ослаблено до 60%thick wooman->(thick woman: 1.3)понятие усилено до 130%
Так же это можно делать быстро:
Выделить слово/фразу, с помощью
Ctrl + UpилиCtrl + Down, нарулить нужное усилении/ослабление.
Styles
Если вы часто добавляете набор понятий, имеет смысл превратить их в стиль.
Стиль - это именованная строка, которая разворачивается в изначальную фразу, и добавляется в негативный или позитивный промпт в зависимости от настройки. К примеру у меня негативный промпт оформлен в виде стиля и добавлен в конфиг, чтобы длинная фраза не мозолила глаза.
Параметры генерации
Помимо propmpt'a большую роль играют параметры генерации. В SD этих параметров не так много, по этому мы разберём их все.
Resolution
Разрешение генерируемого изображения.
В целом всё просто: чем больше изображение, тем дольше генерация и больше артефактов.
Все модели обучаются на наборе изображений фиксированного размера (512x512 или 1024x1024). Наименьшее кол-во проблем будет именно с этими "опорными" разрешениями. Если попытаться слишком сильно отойти от опорного размера, SD будет повторяться, создавая 2-3-5-10 копий одного и того же, и терять композицию. Поэтому базовые изображения стоит генерить в диапазоне +30-60% процентов от базового и затем апскейлить получившийся результат.
HighresFix
Одним из возможных решений для генерации больших изображения является функция HighRes Fix.
При её включении SD делит генерацию изображения на несколько стадий:
Генерация основы (например 512x768)
Апскейл (
1x,1.5x,2x,3x,4x, ...)Проход img2img с теми же параметрами, для увеличенного изображения (при апскейле
x2будет 1024x1536)
Таким образом ценой большего времени, мы получаем на выходе изображение более высокого разрешения и детализации.
Refiner
С приходом архитектуры SDXL. Automatic1111 добавил в WebUI возможность запуска второго прохода за счёт Refiner моделей.
Так как Refiner по сути это некоторое подобие img2img, мы можем использовать другой Checkpoint для доработки базового результата. Это бывает полезно если базовая модель генерит интересные стилистически, но не особо качественные, изображения. Refiner, за счёт другой модели, позволяет сохранять базовую форму и сюжет, дорабатывая при этом детали.
В реализации от Automaiс1111 проход Refiner'а может работать не только с SDXL моделями, но так же и с "обычными" 1.5. Правило одно - не смешивать модели разных типов.
Sampler
Одним из важных аспектов работы SD является алгоритм семплирования модели. Разные алгоритмы имеют разные свойства и производительность, и подходят для разных задач.
В основном используются семплеры:
Euler A- гладкий идеализированный результат (50+ шагов для хорошего качества)DPM++ 2M Karras- семплер общего назначения, быстро даёт качественный результат (20 шагов), обладает хорошей вариативностьюHeun- Хорошо подходит для постобработки и добавления микродеталей.
Все остальные семплеры либо более медленные, либо дают более странные результаты. В WebUI они добавлены по той причине, что Automatic1111 - это референсная реализация, и в ней просто присутствуют все доступные на данный момент подходы и алгоритмы.
CFGScale
Этот параметр определят на сколько сильно SD "старается" сгенерить то, что вам нужно.
Стандартное значение = 7.
Если мы понижаем CFGScale, картинка становится менее сатурированной, а сюжет - более расплывчатым. Если повышаем - цветность повышается, некоторые детали становятся более нарочитыми, появляется "пережжённость" изображения.
В основном этот параметр не изменяется, так как это не приводит к качественно лучшим результатам. Крутят его тогда, когда отдельно взятый Checkpoint генерит слишком насыщенные картинки, либо при использовании изотерических семплеров (LCM) или extension'ов.
Img2Img
SD позволяет генерить изображение на основе других изображений. Для этого предусмотрен отдельный режим img2img.
На вход, помимо промпта подаётся изображение. И в зависимости от силы перерисовки denoising strength, изображение меняется в нужную сторону.
Диапазоны изменения (для изображений 512x512 ± 50%) :
0.0 - 0.2- Изменяются самые мелкие детали0.2 - 0.4- Меняется качество "рисовки", и среднемелкие детали0-4 - 0.5- Крупные изменения с сохранением всех основных концепций оригинальной картинки0-5 - 0.65- Работа на тему, с сохранением композиции0.65 - 1.0- Что-то отдалённо напоминающее оригинальное изображение
При других разрешениях этот диапазон меняется. Чем больше разрешение исходной картинки, тем меньше будет влияние Denois'a.
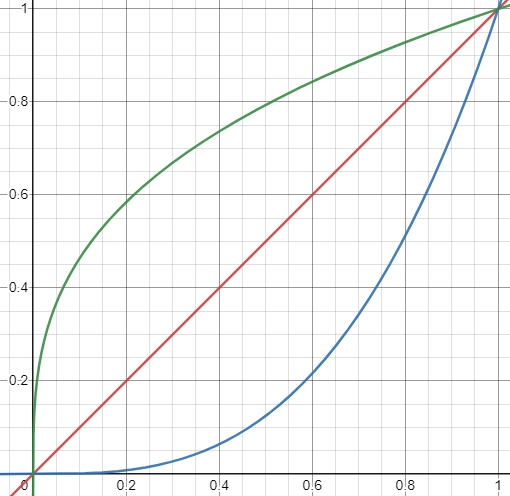
Красное: 512x512
Зелёное < 512
Синее > 512
По этому при перерисовке больших изображений имеет смысл сильнее задирать Denoising Strength.
Inpaint
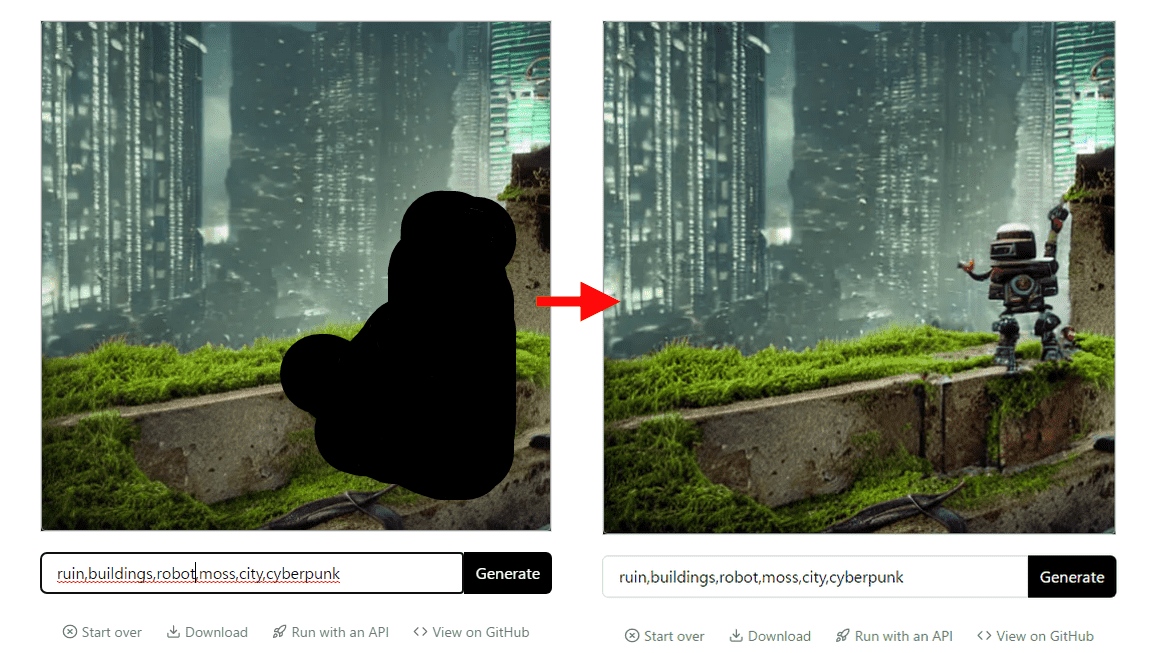
При генерации в img2img можно ограничить область действия SD.
Это нужно в тех случаях, когда необходимо:
изменить лицо
перерисовать одежду
добавить элементов окружения в нужное место
починить анатомию
изменить текстуру предмета
детализировать глаза
...
Only Masked vs Whole Picture
Inpaint может работать в 2 режимах:
Only Masked - перерисовывает только те пиксели, что попадают в маску. Это бывает полезно для увеличения детализации на отдельном участке большого изображения. Так как перерисовывается только часть изображения, мы можем работать над крупными картинками (например 3072x1546), ограничивая разрешение SD небольшим квадратиком в который помещается маска (например 600x300).
Whole Picture - перерисовывает картинку целиком.
Scripts
В txt2img и img2img, предусмотрен ряд специальных режимов работы, которые дают хорошие результаты в рамках отдельно взятых задач.
Loopback

Когда нужно сгенерить качественно другое изображение, но композиция, поза и суть должны остаться оригинальными, можно попробовать применить скрипт Loopback.
Логика его работы проста:
Пропустить изображение через img2img
Повторить несколько раз, подавая на вход предыдущий результат
За счёт того что проходов много, а Denoising Strength низкий, детали на каждом последующем шаге меняются незначительно. Так как это происходит большое кол-во раз, конечный результат довольно сильно откланяется от изначального изображения. В лучшую сторону, но остаётся похожим на то что было.
Так же можно установить изменение Denoising'а на каждом последующем шаге, чтобы на первом проходе он был высоким (0.4-0.6) и с каждой последующим шагом становился всё меньше. Это позволяет получать более проработанные и менее искажённые результаты, так как на каждом последующем шаге размер деталей над которыми работает SD, становится всё меньше и меньше.
XYZ Plot

Для того чтобы лучше понять как влияют изменения параметров, prompt'a и всего остального, можно воспользоваться скприптом XYZ plot.
Мы, через запятую, перечислим что необходимо изменить, и затем SD в автоматическом режиме создаёт изображение на котором отчётливо видны изменения.
Этот инструмент экономит кучу времени, так как всё происходит автоматически, и ты не путаешься в куче картинок лежащих в папке.
SDUpcale

Самый крутой апскейлер в плане качества, но не точности - апскейлер основанный на основе StableDiffusion'а.
Тут важно понимать, что в отличие от обычного апскейла, SD перерисовывает ваше изображение, добавляя в него деталей. Это приводит к потере достоверности, но эстетически такие изображения выглядят сильно лучше, чем любой другой алгоритм апскейла (esrgan, ldsr, topaz, ...).
Работает он следующим образом:
Исходная картинка прогоняется через традиционный апскейлер
Делится на небольшие области-tile'ы (например 1024x1024) с небольшим перекрытием соседних
Каждый tile прогоняется через SD с нашим промптом, параметрами, lora'ми и выбранным checkpoint'ом
Результаты склеиваются в одно большое изображение
Стоит отметить, что Denoising Strength не стоит сильно задирать иначе получится что-то вроде:

Хорошее значение: 0.3.
Extension'ы
Помимо коробочных функций, в webui от Automatic1111 можно добавлять различные расширения (плагины).
Каждое расширение представляет собой отдельно живущий git репозиторий, которые можно склонировать в папку /sd-webui/extensions.
Либо установить из интерфейса самого webui через менеджер расширений:
Расширения можно устанавливать по ссылке. Так же имеется список, поддерживаемый Automatic1111'ом во вкладке Available.
После установки расширения, webui необходимо перезагрузить. Сделать это можно нажав кнопку Apply and restart UI или перезапустив .bat файл.
CADS
https://github.com/v0xie/sd-webui-cads

Для того чтобы в значительной степени повысить вариативность получаемых результатов, существует расширение CADS. Оно рандомизирует промежуточные стадии формирования изображения, сбивая SD от сваливания в локальный минимум гиперпространства.
В результате работы Extension'а вы будете получать более разнообразные изображения, но не всегда более качественные. Поэтому это инструмент для более эффективного начального поиска интересных результатов, нежели универсальный инструмент который "просто делает лучше".
Kohya Highres.fix
https://github.com/wcde/sd-webui-kohya-hiresfix

HighRes Fix в исполнении Kohya'и.
Основное отличие от стандартного HighRes Fix'a:
Изображение генерируется за 1 проход
Изображение генерируется в большом размере
Extension влияет на промежуточные стадии генерации
Итого:
-
Плюсы:
Пропускается стадия базовой генерации и апскейла
Результат может оказаться интереснее, т.к. генерация происходит при большом разрешении
-
Минусы:
Генерятся сразу большие изображения, а это плохо сказывается на времени итерации.
ADetailer
https://github.com/Bing-su/adetailer

ADetaler это расширение, которое позволяет добавить стадию постпроцессинга готового изображения.
Принцип работы:
Сгенерить изображение
Определить на изображении области интереса (лицо, рука, одежа, ...)
Перерисовать (img2img) эту область с более высоким разрешением.
За счёт Adetailer'а в основном:
дорабатывают лица и руки
применяется lora нужного персонажа, чтобы получалось стабильное лицо
меняется макияж
...
Dynamic Prompts
https://github.com/adieyal/sd-dynamic-prompts.git

Когда мы итерируемся, работая над тем или иным персонажем / lora, часто хочется увидеть как он будет выглядеть в других контекстах, одеждах, окружениях и жанрах.
Вручную это реализуется за счёт того, что мы каждый раз меняем промпт. Но это утомительно и неудобно. Как альтернативу, можно попробовать использовать XYZ plot, но это не так удобно.
Для этого есть специальный инструмент - Dynamic Prompts.
Он добавляет 3 основных функции: комбинации, wildcard'ы, подсказки.
Комбинации
Комбинации - это специальное расширение синтаксиса промпта, позволяющее определить список понятий, которые будут применяться по кругу на каждой следующей генерации.
beautiful girl, {green|light red|orange} dress, walking in park
Здесь нас интересуют фигурные скобочки. Внутри может находиться несколько понятий разделённых символом | .
Если мы сгенерим 6 изображений, у нас будет 6 девочек гуляющих в парке: у 2 будет зелёное платье, ещё у двух - светло-красное, и у оставшихся 2 - оранжевое.
WildCard'ы
Для того чтобы каждый раз не писать в Prompt'е длинные портянки с комбинациями, лучше сохранить или скачать их в виде специальных файлов с этими понятиями, а в промпт добавлять по имени файла:
Beautiful model woman
posing in bay area
__fem_portraits/fashion_outfit_image__
Тут вместо __fem_portraits/fashion_outfit_image__ будет подставляться строка за строкой из одноимённого файла лежащего в папке: /sd-webui/extensions/sd-dynamic-prompts/wildcards/....
В файле записаны добавки к промпту:
Подсказки
Это расширение добавляет интерфейс подсказок. Он позволяет проще ориентироваться в коллекции WildCard'ов и узнавать силу токенов.
Pixelization
https://github.com/AUTOMATIC1111/stable-diffusion-webui-pixelization

Для генерации Pixel Art'a можно попробовать поискать checkpoint'ы или lora.
Но более качественного результата можно добиться используя расширение, содержащего внутри себя небольшую нейросеть, которая перерисовывает ваше изображение в стиле pixelart'a.
Основное отличие этого расширения от банального уменьшения разрешения оригинальной картинки заключается в том, что оно сохраняет контуры и перерабатывает детали, сохраняя при этом оригинальную эстетику.
ControlNet
GitHub - Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
ControlNet - это попытка глубоко забраться в мозги SD и склонить его в генерацию того что нужно. Используя для этого различные хитрости и приёмы формирования исходного шума и влияния на промежуточные стадии генерации.
Так как основной принцип заключается в том, чтобы повлиять на процесс генерации, внедрив туда некоторые изменения, существует большое множество различных режимов работы ControlNet'а, для каждого из которых предусмотрены свои собственные модели.
Модели и Препроцессоры
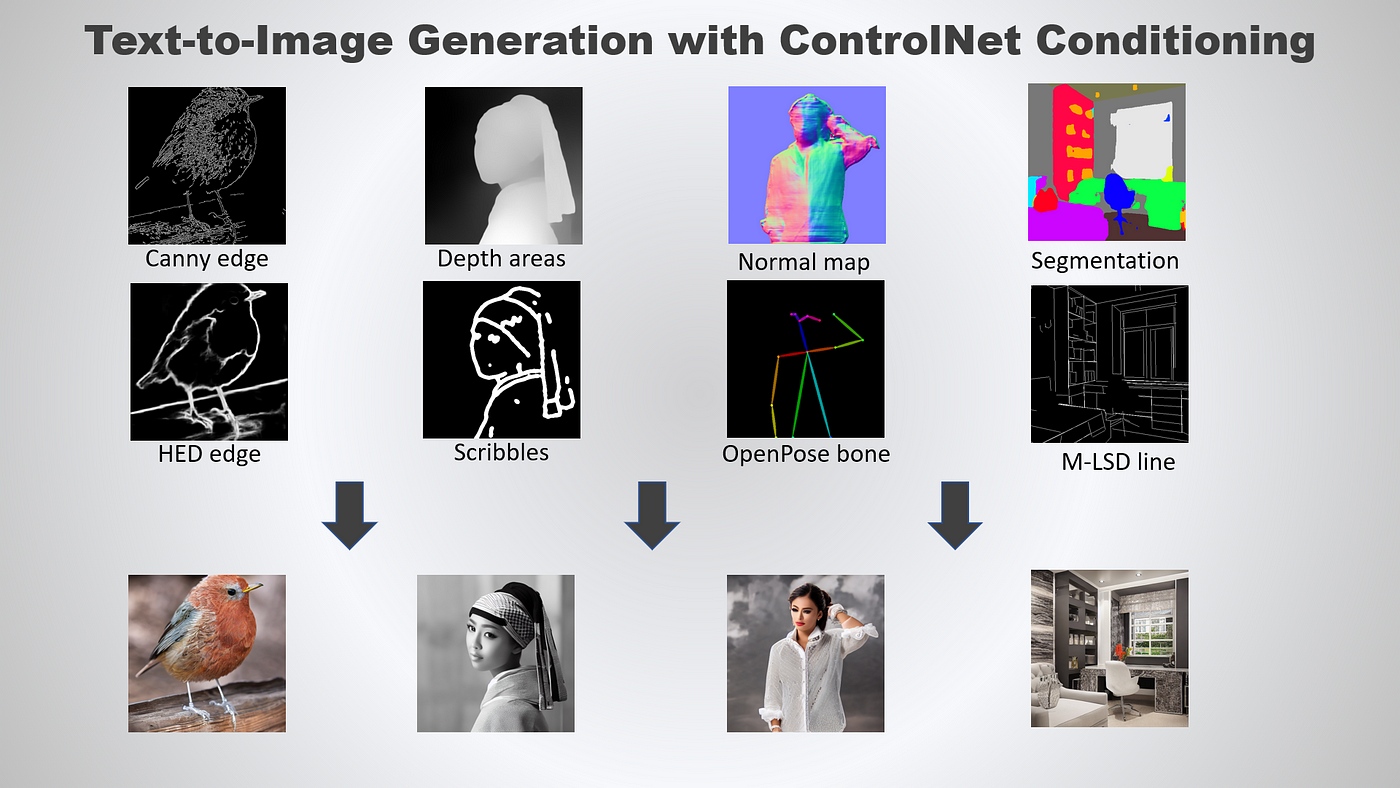
ControlNet влияет на SD за счёт специальных моделей. Модели работают по-разному, но большинство из них принимают на вход изображение-референс, которое используется для генерации финального изображения.
Референс может быть нарисован от руки, либо сгенерён с помощью препроцессора.
Препроцессор - алгоритм обрабатывающий входное изображение, преобразующий его в вид понятный для модели ControlNet'a.
Модели бывают самые разные и работают на разных принципах, что позволяет генерить изображения на основе:
Контуров (canny, scrible, hed, lineart, mlsd)
Глубины (depth)
Нормалей (normals)
Сегментации (sebmentation)
Позы (openpose)
Исходной палитры (recolor)
...
Скачать основной набор моделей для ControlNet можно тут:
https://civitai.com/models/38784/controlnet-11-models
IP Adapter
Особенно хочется отметить "магическую" модель IPAdapter, которая использует исходное изображение для генерации подсказки уровня промпта. Благодаря этому, результат начинает быть похожим на исходное изображение, при этом суть изображаемого может очень сильно измениться.

Модели лежат тут: https://huggingface.co/h94/IP-Adapter
Upscaling
В основном, исходные генерации получаются весьма небольшими. Для проработки деталей и увеличения разрешения, изображения подвергаются апскейлингу. При этом пиксели не просто растягиваются, на их основе генерятся новые, а общая детализация изображения растёт.
Коробочные алгоритмы
В webui от Automatic1111, встроены реализации самых разных апскейлеров.
Практически применимым однако является только один - esrgan.
Все остальные имеют либо более скверное качество картинки, либо генерация может занимать десятки минут (LDSR).
Для esrgan'a существует большое кол-во чекпоинтов. На практике хорошо себя показали следующие:
NMKD Siax ("CX") - 200k | Stable Diffusion Upscaler | Civitai
4x-Ultrasharp - 4x-UltraSharp v1.0 | Stable Diffusion Upscaler | Civitai
Помимо этих моделей есть ещё куча других. Посмотреть можно тут: https://openmodeldb.info/
Topaz Photo AI
Коммерческий продукт от компании Topaz. В среднем имеет хорошее качество увеличения как на графике, так и на фотореалистичных изображениях.
Главное отключить все улучшайзеры, которые борются с компрессией и блюром. Результаты работы SD и так являются околоидеальными, с точки зрения артефактов сжатия, поэтому любые попытки их "улучшить" будут только портить конечное изображение.
Построение рабочего Pipeline'а
Самое важное, что просто необходимо понимать, чтобы не разочароваться в SD - это то, что SD - профессиональный инструмент, который даёт вам полный контроль над происходящим. И если у вас что-то не получается, это проблема скилла, а не инструмента. Вы же не будете злиться на пианино за то, что не умеете на нём играть, когда сели за него впервые.
Нужно набраться терпения, привыкнуть ко всем инструментам, понять их сильные и слабые стороны, после чего придёт понимание того, что можно, а чего нельзя. Однако и без того можно с уверенностью сказать, что кнопка Generate ≠ Сделать красиво.
Ну, а чтобы упростить первые попытки, я предлагаю следующую тактику работы с SD, которая позволит добиться внятных и интересных результатов.
Итеративный процесс
Для того чтобы сгенерить хорошее, годное изображение, нужно делать это итеративно. Разбивая свой процесс на стадии.
Для начала, было бы не плохо понять, знает ли выбранный Checkpoint все нужные токены. Может получиться так, что вы напишете большой детальный промпт, а половины описанного не будет. Поэтому перед тем как делать что-то сложное, нужно для начала выяснить, "понимают ли вас по ту сторону".
Так например, если вы соберётесь создать одноглазого пирата с повязкой и эполетами, держащего в левой руке топор, могут возникнуть некоторые трудности...
В этом случае стоит обзавестись соответствующими Lora'ми, или подобрать другие токены.
Далее, с простым неперегруженным промптом, и парочкой WildCard'ов можно посмотреть "общую картину" и найти интересный для себя сеттинг. На этом этапе нам все равно на мелкие детали, мы ищем общее настроение и композицию.
В конце концов мы находим "ту самую" картинку, и начинаем работать над отдельными деталями. Предварительно апскейлим, чтобы по меньшей стороне изображение было минимум 1200 пикселей.
Далее мы переходим в img2img, чтобы начинать Inpaint'ить отдельные элементы изображения, подбирая под каждую деталь свой собственный промпт.
После доработки деталей в SD, изображение можно ещё сильнее заапскейлить, чтобы его размер был уже пригодным для печати (3000px+).
Завершающей стадией работы над изображением, как правило, является переход из WebUI в графический редактор, где уже ювелирно исправляются мелкие косяки. Дорабатываются цвета изображения, применяются различные постэффекты (плёнка, grain, ...).
Таким образом, мы от простого промпта, путём постепенного увеличения разрешения и локализации вносимых изменений, приходим к изображению с высоким разрешением и большим количеством деталей.
Чтобы гарантированно ничего не получилось:
Напишите супер длинный и взаимоисключающий промпт, с кучей разбалансированных токенов и лор; влупите разрешение 2048x1536. И требуйте от инструмента невозможного. Fail гарантирован.
Не нужно зацикливаться
Если на одном из начальных этапов блуждания по латентному пространству, вы увидели "самую замечательную картинку в своей жизни", но она при этом очень кривая - не нужно пытаться её дорабатывать. Просто оставьте её как референс. В латентном пространстве бесконечное множество похожих картинок, но с меньшим количеством артефактов, их просто нужно дождаться.
Так же можно попробовать сгенерить вариации той же самой картинки, включив Seed Variation. Результаты будут похожие, и в зависимости от силы Variation'а может повезти, и вы найдёте более удачный вариант в окрестностях латентного гиперпространства.

И в целом не бойтесь выкидывать то что вы делаете, если оно вам не нравится. У вас в распоряжении инструмент, который может создать бесконечное кол-во красивых изображений. И то что вам понравилось сейчас - не уникально!
Иногда проще брать толпой
Если лень заниматься первыми стадиями поиска, добавьте WildCard, включите CADSи поставьте генериться 200 изображений. Затем по турнирной схеме выберете одно лучшее.

Prompt Engeneering
Промпт - минипрограмма, которую нужно уметь писать.
Вам придётся изучать предметную область, чтобы отыскивать те самые слова, которые будут генерить именно то что нужно. Ключ к хорошей, качественной генерации - лаконичный, заряженный понятиями prompt.
Не пытайтесь копировать длинные портянки от "красивых картинок" с civit-ai. Пользы от этого не много, так как изменить в этом промпте вы всё равно ничего не сможете.
Читайте блоги, каналы и статьи нейрохудожников, экспериментируйте, погружайтесь в предметную область и тогда результаты не будут посредственными.
Крутость кроется в комбинациях
В первом пункте описана "каноническая" комбинация действий. Однако, возможна далеко не только она.
Пайплайн можно построить и из другого набора инструментов и действий. Главное разобраться и понять какие есть возможности и пределы у инструментов. И использовать их вместе, выстраивая цепочку операций. В этом случае будут получаться качественные и необычные изображения.
Сложность комбинации прямо пропорциональна необычности итоговой картинки. Комбинации нужно уметь строить или находить в интернете (civit, reddit, twitter, ...).
Набор прикольных комбинаций можно почитать тут:
Самые распространённые проблемы генерации
Как вкатываться разобрались, осталось понять какие очевидные проблемы нас подстерегают и как с ними бороться.
Double face

Когда такое происходит, главная причина - слишком большое разрешение генерации. Не жадничайте, уменьшите его до ±50% разрешения базовой модели и генерите дальше.
Вывернутая макушка головы
Схематически выглядит это так:
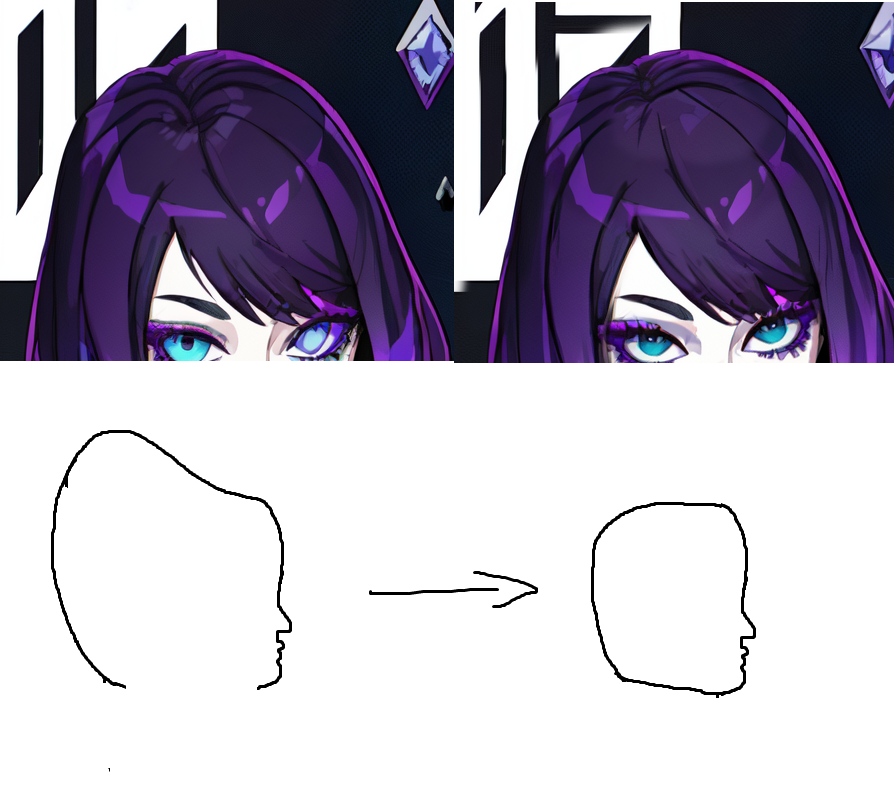
По какой-то причине все Checkpoint'ы SD склонны выворачивать на зрителя все шарообразные объекты, и головы, в том числе.
По этому если вы видите "воздухозаборник" или "выемку" на голове, знайте - это прикол SD. Который легко чинится в графическом редакторе.
Лишние конечности, кривые руки и прочая кривая анатомия
В этом месте латентного пространства видимо находится горка или впадина, из-за чего картинка искажается. Самый простой и правильный способ этой гипер-горки избежать - продолжать генерить дальше.
Если на картинке что-то конкретно не так с анатомией, в других менее заметных местах скорее всего тоже будет что-то не так. И заметите вы это только когда поправите руки. По этому не зацикливайтесь и идите дальше.
"Скучный" результат
Ожидания не всегда совпадают с реальностью и картинка получается слишком уж скучной и бесхитростной?
Это может случаться из-за того что:
Промпт слишком простой
Промпт слишком сложный
Чекпоинт не знает то, что вы от него просите
Не тот чекпоинт что вам нужен
Вы слишком уверены в своем промпте, но видимо в этот раз с ним что-то не так. Проведите исследование предметной области и найдите более походящие термины.
Я хочу красное платье и зелёные волосы!!!
А получаются красные волосы, зелёная водолазка и красная юбка...
Ни чего сверхъестественного в этом нет. SD не понимает терминов, он их даже не видит. На вход ему поступают цифры, и он ищет в латентном пространстве ближайшие соответствия. Потом из этого латентного пространства генерится финальная картинка. Это вероятностный процесс, в ходе которого могут возникать смысловые ошибки разной степени тяжести.
Увы, избежать этого никак не получится, и отдельно взятая плохая генерация будет такой. Но вероятностно, большая часть других генераций будет с тем что вам нужно. В крайнем случае всегда можно пойти в img2img Inpaint и перерисовать неугодную часть исходного изображения.
Конец
Этого должно хватить, чтобы стартануть в мир генерации изображений с помощью StableDiffusion.
Читайте разных авторов, смотрите youtube, экспериментируйте! И у вас всё обязательно получится.
Я оставлю тут пару, по моему мнению, полезных и интересных ссылок на YouTube и TG. И вы тоже делитесь информацией в комментариях.
Комментарии (21)

Aniro
29.12.2023 23:08+7Я бы сказал - неплохой стартовый обзор, на хабре подобного вроде еще не было.
Но есть некоторые неточности, щас буду душнить:
Просто пишите через запятую набор понятий.
Вредный совет. Это так только для моделей обученных на изображениях описанных тэгами (AnythingV3 и наследники, но тогда надо и про clip skip рассказать) Базовая модель и многие файнтюны (особенно SDXL) обучались на нормальных человеческих описаниях, соответсвенно их лучше понимают.
Все модели обучаются на наборе изображений фиксированного размера (512x512 или 1024x1024). Наименьшее кол-во проблем будет именно с этими "опорными" разрешениями.
Неправда. Только базовые модели первой версии 0.9-1.5 обучались на фиксированном разрешении 512х512. Большинство файнтюнов первой версии обучались на различных разрешениях, вплоть до 768х768 и у них значительно меньше проблем с нестандартными (в разумных переделах) разрешениями.
SDXL сразу обучалась на множестве вариантов разрешений, она официально поддерживала несколько вариантов с самого начала:

... другие интересные инструменты, которые имеют скорее экспериментальный характер. К их числу я бы отнёс ComfyUI
Кхм... интересные у вас представления об "экспереметальном характере", учитывая что самые интересные работы делаются именно в комфи и насколько я знаю профессионалы зарабатывающие обработкой картинок и видео в SD тоже пользуются им. Видимо поэтому в обзоре не упомянут ни AnimeDiff, ни SVD ?
Euler A- гладкий идеализированный результат (50+ шагов для хорошего качества)
Про сэмплеры которые "медленные или странные" это вы конечно тоже загнули, но это в общем вкусовщина. Стоит упомянуть что самые "странные" это как раз "A" сэмплеры. С ними генерация за 20 шагов может очень сильно отличаться от генерации за 19 при одном и том же сиде, что исключает их использование в некоторых сценариях. Ancestral сэмплеры предназначены для ускорения генерации, так что 50 шагов для эйлера-А это явный перебор, в отличии от простого Эйлера разницы в качестве не будет после примерно тридцатого шага, дальше вы уже просто по разному генерируете шум)
Еще можно наверное было упомянть SD Turbo и LCMЯ хочу красное платье и зелёные волосы!!! А получаются красные волосы, зелёная водолазка и красная юбка...
Увы, избежать этого никак не получится
Да ладно... BREAK, regional prompter, etc... в зависимости от задачи что-то да подойдет

JakErdy Автор
29.12.2023 23:08В общем и целом согласен. Спасибо что потратили время на уточнение моих неточностей.
Я в некоторых моментах сознательно допускал неточности чтобы донести "качественую" характеристеку и не зарываться при этом в детали. В процессе работы с инструментом пытливый человек всё-равно будет пробовать разные подходы, и обнаружит для себя более эффективные и действенные методы. Я постарался дать отправную точку, чтобы глаза не разбегались.
Единственное что хотелось бы уточнить - про экспериментальность ComfyUI. Да безусловно, возможностей влезть в процесс inferenca там больше и как следствие, контроля над происходящим. Но начинать я бы с него всё-же не стал, так как нужно иметь большой багаж знаний и хорошо понимать что происходит внутри SD чтобы иметь возможность своими руками собрать нужный граф. И в разряд экспериментальных он в моём представлении попадает именно потому что в нём реализуют самые сложные и нетривиальные workflow. Для 95% задач не требуется слишком сложного начального этапа. Да и постобработка, что после ComfyUI, что после Automatic1111 в большинстве сулчаев необходима.


Astus
29.12.2023 23:08+3nvidia rtx 3xxx +
Двухтысячники вполне подходят под минимальные комфортные требования.

Kekovsky
29.12.2023 23:08+2Запускаю на 1070'й, но иногда падает скорость, т.к. начинает в подкачку уходить, с целью отожрать доп. RAM. Однако, вылетов не наблюдаю, так или иначе она дорисовывает всё, даже больше разрешения, единственное - медленно.
JakErdy Автор
29.12.2023 23:08+3По мимо самого gpu на производительность так же сильно влияет объём памяти. И
Опять таки, что считать комфортным каждый определяет для себя сам, и тут нужно понимать какой предполагается сценарий использования. Если в рекреационных целях, раз в неделю погенерить аниме или каких-то весёлых картинок, тут да, не так важно в целом. Но если рассматривать SD как один из инструментов применивых в работе, то тут же чем быстрее, тем лучше.
2 серия нвидий и правда сравнима по скорости с 3 сериией на генерации мелких изображений. Но тут ещё нужно брать во внимание объём памяти у самой видеокарты. Если её будет недостаточно, то скорость генерации будет падать в разы из-за свопинга. И происходить это будет на последних этапах работы над изображением, когда разрешение уже относительно высокое (1500px+). Так же будет проблематично использовать XL модели, так как у них требования к памяти ещё выше.
В моей практике, для создания чего-то интересного обычно приходится запускать процесс генерации десятки а то и сотни раз (начальный процесс, плюс все последующие доработки), и если бы генерация занимала не 5-10-15 секунд, а скажем 1-2 минуты, пользоваться этим для полезных практических применений было бы затруднительно.
По этому я бы ориентировался скорее на объём памяти (8гб ок, но лучше 12), если SD применяется в качестве инструмента для работы. 3060 с 12гб не сильно ударит по карману, и даст хороший экспириенс в плане времени иттерации.
PS. Товарищи с THG сделали сравнение разных видеокарт на генерации маленького изображения. Получилось следующее:

Но опять таки, это маленькие изображения, если бы сравнение проводилось на больших (этап доработки), были бы совсем другие результаты.
Astus
29.12.2023 23:08Это всё понятно, я сам использую SD в работе с её самого появления на своей 2080 Ti, в PS она мне успешно заменила Адобовский Firefly.
Тем не менее, "nvidia rtx 3xxx" - это в т.ч. весьма распространённые восьмигиговые бюджетные 3050 и "народные" 3060, которых, если судить по Вашему графику, обгоняет старая восьмигиговая 2060S.


bdaring
29.12.2023 23:08+2Спасибо, хорошая обзорная статья, действительно полезная как стартовая точка.
Чего как мне кажется не хватает, так это практических примеров. Кроме простого констатирования о сложности генерирования "одноглазого пирата с повязкой и эполетами, держащего в левой руке топор", хотелось бы увидеть как его все же можно получить, используя описываемый инструментарий.JakErdy Автор
29.12.2023 23:08Ох, боюсь это тема для отдельной статьи...
bdaring
29.12.2023 23:08+1C удовольствием бы почитал подобную статью!

Alexey2005
29.12.2023 23:08+3Проще всего многократной перерисовкой (inpainting). Генерируем около изображений 20 пирата, выбираем наиболее близкое к желаемому. Далее начинаем перегенерировать область за областью. Сперва выделяем лицо, требуем сделать повязку. Потом область возле руки, создавая топор. Кстати, для топора скорее всего потребуется найти подходящую LoRA, потому что SD из рук вон плохо создаёт инструменты. Мне ещё не встречалось такой модели, которая могла бы прямо из коробки создать, скажем, механика с отвёрткой в руках. Или с гаечным ключом.
После серии перерисовок получается готовое изображение, на которое уже можно накладывать текст или иные эффекты.
Пример того, как это работает:
Исходный скетч (лучшее из серии в 30 штук)

Финальный фрейм комикса после пары часов перерисовок


LF69ssop
29.12.2023 23:08Мне ещё не встречалось такой модели, которая могла бы прямо из коробки
создать, скажем, механика с отвёрткой в руках. Или с гаечным ключом.Это вы еще, вероятно, человека со сноубордом не пробовали генерить.
У всех без исключения моделей очень странное представление о том что такое сноуборд и как он крепится к человеку.



timonin
29.12.2023 23:08Информации много, это плюс, не вся она точная и актуальная, это минус, но об этом уже писали.
Про фокус мнение странное, там есть все настройки, они в дебаг меню просто, как первый интерфейс фокус как раз самое оно, потом а1111, потом комфи)

Shapic
29.12.2023 23:08+ Ещё Ruined Fooocus имеется. Но фокус ограничен sdxl. В базовом виде он не может в turbosdxl на текущий момент, только LCM, где страдает качество.
Но у фокуса на текущий момент есть суперпреимущество: inpaint. Полноценный. Пока нет инпейнт модели для контролнета и инпейнт чекпоинтов - в большинстве случаев вне исправить (лицо/зрачки/пальцы) это превращается в боль и перерисовку через img2img с потерей деталей.

NinjaNickName
29.12.2023 23:08Спасибо за статью! Как раз собираюсь пощупать SD, подскажите пжл, если знаете, имеет смысл ставить SD на WSL ? Это даст какой-то прирост в плане производительности\удобства\возможностей или можно не заморачиваться и ставить прямо в винду?
JakErdy Автор
29.12.2023 23:08Прироста точно не будет, так как драйвер для видеокарты у вас всё равно будет виндовый. По мимо этого WSL требует для своей работы дополнительной оперативной памяти. И если у вас в системе не 20гб+ ram, это будет ощутимо при работе с XL моделями, в особенности в моменты их загрузки в память.
SD устанавливается в одну папку, и не особо мусорит в системе т.к. все зависимости устанавливаются в venv. Так же будет проще с загрузкой моделей, каждый чекпоинт весит 2гб+ (для 1.5) и 6гб+ (для XL), и его может быть накладно копировать в файловую систему WSL. Либо придётся сразу загружать из терминала с помощью того же wget'a.
В общем явных преимуществ нет, а вот неудобств вероятно добавится.


Asterris
29.12.2023 23:08Стоит упомянуть что самые "странные" это как раз "A" сэмплеры. С ними генерация за 20 шагов может очень сильно отличаться от генерации за 19 при одном и том же сиде, что исключает их использование в некоторых сценариях
Ancestral-сэмплеры не странные. Они просто добавляют в генерацию немного шума на каждом шаге. Это позволяет чуть ускорить генерацию, но по определению не позволяет получить стабильно воспроизводимый результат с одними и теми же входными параметрами.



yumupdate
29.12.2023 23:08+1Что же вы ничего не рассказали про TensorRT ?
https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT
Даёт ощутимый прирост в скорости.
Но как всегда есть но :)
JakErdy Автор
29.12.2023 23:08Не рассказал, потому что текущий вариант реализации плохо применим на практике.
TensorRT штука интересная, потому что позволяет в 2+ раз ускорять генерацию изображений. Как Proof of Concept норм, но у неё слишком много минусов чтобы рекомендовать её:
Для каждого чекпоинта приходится создавать отдельную модель которая занимает 1гб+
Модели-ускорители создаются под конкретное разрешение
Не работают Lora. А чтобы заработали их нужно смерджить с чекпоинтом, что долго, не удобно, занимент много места. А учитывая то что Lora часто не одна, и хочется покрутить её вес в промпте, это прям совсем для любителей.
Довольно проблематично установить
В текущей реализации оно подходит разве что для чат-ботов, которые аватарки генерят, где пайплайн максимально фиксирован, а машинное время дорогое. Для ручной генерации изображений, да и тем более новичкам, оно точно не нужно.
RigidStyle
Занимательная статья в свободное время, но не раскрывает ни инструментарий, ни применение. Просто навалено всего из разряда "что бы нарисовать сову, вам нужен карандаш и понимание совы, рисуется сова очень просто, только нужно научиться ее рисовать, сесть и нарисовать, попутно разобравшись что такое сова и карандаш, и как рисовать сову".
Из полезного - перечисление основного инструментария (плагинов).