

Как-то в конторе появилась мысль, что надо бы продумать как нам распараллелить работу над одни микриком, так чтобы команды не пересекались друг с другом. Есть некоторые api, над которыми работают несколько команд. Каждая работает над своей фичей локально и пишет тесты, а вот при деплое на стэнд получается столпотворение потому, что нужно изменения слить в одну ветку аля develop и её закинуть на тест. При этом могут быть конфликты при мерже кода или измениться проперти, которые не совместимы между разными ветка.
Мобильный банк сейчас обслуживает 450+ микриков. Над которыми работают более 90 команд. Так как у нас в проекте нет code ownership, то каждая команда вносит изменения в нужные им микрики. Чтобы избежать различного рода сложностей, которые приводят к увеличению времени time to market, нужно было развести разработку отдельных команд так, чтобы они не влияли друг на друга и могли работать параллельно.
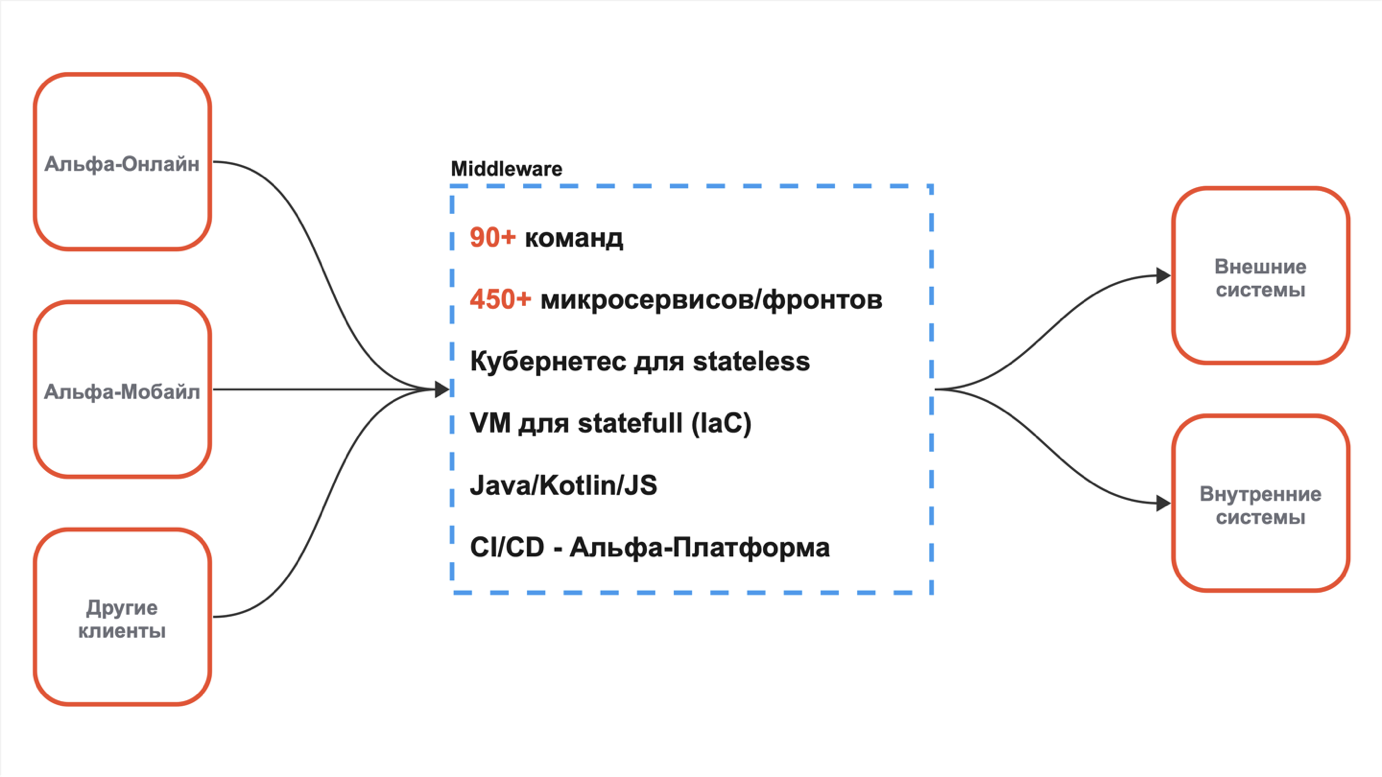
Проблема
Наш тестовый стэнд довольно жирный и создавать рядышком ещё и дев стэнд не хотелось. Так как это ещё одна статья в бюджете, плюс его надо поддерживать, что тоже требует много сил. Из-за постоянных изменений тест стэнд периодически плохо себя чувствовал, что напрямую влияет на бизнес-процессы.
При этом мы живём в K8S вместе с Istio. В статье «Практическая магия Istio при построении архитектуры крупных микросервисных систем» коллеги уже писали про Istio и почему выбран именно он. Можно ознакомиться для понимания, что это за зверь такой.
Главное, что у Istio есть мощный механизм маршрутизации запросов, который может помочь нам сделать параллельную разработку и тестирование более безопасным.
Как было сделано
Рассматривали несколько вариантов, такие как организация очереди, отдельный релизный кластер или кластер (namespace) для каждой команды. Но с таким большим количеством команд потребуется огромное количество ресурсов, а также возрастает сложность деплоя и поддержки.
Остановились мы на одном решении, которое назвали Feature Branches. Частично это решение у нас уже применялось для фронтов, которые разрабатывали web. Его надо было доработать и масштабировать для разработки под Andriod, iOS, а также для бэка.
Прежде чем перейдём к техническим подробностям немного терминологии:
Feature instance: экземпляр сервиса, для которого настроены правила маршрутизации.
Feature name: имя фичи, признак для маршрутизации в feature instance.
Feature branch: набор feature instance, объединённый одним feature name.
Master branch: ветка по умолчанию, набор релизных версий.
Реализация решения может быть разная, но мы используем Кубер и Istio. В Istio есть отдельные ресурсы, которые отвечают за маршрутизацию — VirtualService (VS) и DestinationRule (DR). Для каждой фичи создаётся свой DR, а VS маршрутизирует трафик между ними. Например, DR для demo-api для мастер ветки выглядит так:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
...
spec:
host: demo-api.default.svc.cluster.local
subsets:
- labels:
app.kubernetes.io/instance: demo-api
name: default
Здесь указан дефолтный subset, который ведёт на задеплоенный master branch.
При этом для фичи DR:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
...
spec:
host: demo-api.default.svc.cluster.local
subsets:
- labels:
app.kubernetes.io/instance: demo-api.feature-31337
name: feature-31337
Имя фичи у нас задано в subset, а так же попадает в label через точку. VS и DR работают в паре. Для нашего сервиса VS будет выглядеть так:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
...
spec:
hosts:
- demo-api.default.svc.cluster.local
http:
- match:
- headers:
X-FEATURE-NAME:
exact: feature-31337
route:
- destination:
host: demo-api.default.svc.cluster.local
subset: feature-31337
- route:
- destination:
host: demo-api.default.svc.cluster.local
subset: default
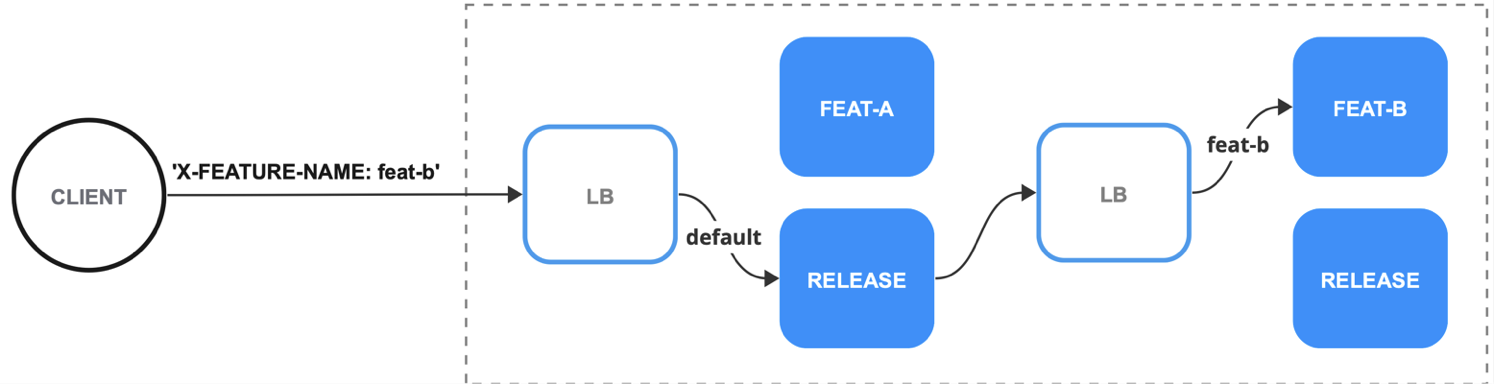
Получается следующая картина. Чтобы понять, куда перенаправить запрос, Istio сначала смотрит в VS, а потом на основе правил матчинга выбирает нужный subset, который задан в DR и ведёт в нужный сервис.

И вот мы подошли к тому, на основе чего происходит маршрутизация HTTP запросов, а именно, учитывается наличие HTTP хедера X-FEATURE-NAME. Так как в VS в секции match проверяется наличие этого хедера в запросе на точное (exact) совпадение его значения с feature-31337, то запрос полетит в под с лэйблом app.kubernetes.io/instance: demo-api.feature-31337.
Сервисы можно объединить в цепочку если задеплоить их с одним feature name. При этом, если в цепочке вызовов в сервисе нет заданной фичи, то запрос полетит в дефолтный subset потому, что не сработает ни одна секция матчинга в VS.
Такая конфигурация Istio присутствует не только для каждого бэка, но также и для микрофронта. Фронты не используют запросы с хедером X-FEATURE-NAME напрямую. У них есть возможность деплоить фичи под выделенным урлом. Например, feature-31337.demo.net.
Таким урлом удобно делиться с тестировщиками или дизайнерами, чтобы показать свои текущие наработки. В данном случае запрос прилетает в сервис с настроенным Spring Cloud Gateway. GW парсит урл и находит там имя фичи, которое затем проставляет в хедер X-FEATURE-NAME и перенаправляет запрос в нужный микрофронт:
spring:
cloud:
gateway:
routes:
- id: ignored
uri: http://demo-ui
order: 1
predicates:
- Host={branch}.demo.net
- Path=/demo-ui/**
filters:
- SetRequestHeader=X-FEATURE-NAME, {branch}
- RewritePath=/demo-ui/(?<segment>.*), /$\\{segment}
Вот так устроены и работают фича ветки.
Процесс деплоя веток тоже автоматизирован. В банке используется самописная платформа CI/CD, которая, помимо прочего, деплоит артефакты на тест среду. Платформа интегрирована с Bitbucket посредством хуков. То есть она знает, когда произошел пуш в репозиторий.
После получения эвента о пуше Платформа просматривает коммит месадж в поисках ключевых слов, а если находит сообщение (deploy_feature), то запускает флоу сборки артефакта и деплоя его в K8S на тестовую среду. При этом разработчику нет необходимости отслеживать состоянии сборки и деплоя фичи, так как специально обученный бот нотифицирует его в мессенджер об удачной или упавшей сборке.
Подытожим коротенечко, что у нас получилось:
№1. Реализации фича веток основывается на правилах маршрутизации, предоставляемых Istio.
№2. Что бы feature instance заработал нужно:
Создать DestinationRule, который содержит subset для выбора сервиса по лэйблу.
Создать VirtualService, который на основе HTTP хедера перенаправит запрос в нужный subset.
№3. Для обращения к feature instance, нужно:
На бэке использовать заголовок X-FEATURE-NAME в запросах.
На фронте можно использовать выделенный урл по типу
feature-31337.demo.net, если заранее сконфигурировать Spring Cloud Gateway как было показано выше.
Вывод
После внедрения фича веток больше нет необходимости создавать общую ветку в Git и деплоить её в мастер ветку, что значительно повысило удобство разработки и стабильность тест среды.
Прямой деплой в мастер ветку запрещен, а её обновление происходит только в случае раскатки артефакта на прод, так как деплой и тестирование на тест среде — это обязательный шаг.
Команды быстро адаптировались под новый рабочий флоу и начали плодить feature instance сотнями. Чтобы не завалить кластер, под них были выделены отдельные ноды, а так же написана джоба, которая занимается очисткой фича веток. Она также задеплоена в кластер Куба и запускается по крону.
Немного цифр. Как я говорил выше, сейчас на проекте работает 90+ команд. При этом общее количество фича веток превышает 300 единиц. Также среди разрабов проводился опрос про удобство работы/использования фича веток. Одним из вопросов просили поставить субъективную оценку по пятибальной шкале. Средняя оценка получилась 4.3 что даже очень хорошо. В опросе приняло участие более половины инженеров.
После внедрения фича веток работы тестовая среда стала работать намного стабильней. У нас всегда есть сред релизных версий артефактов, которые протестированы и работают стабильно. То есть теперь команда смело может деплоить снапшотную версию артефакта не боясь сломать смежные сервисы. Если происходит какая-то ошибка, то она случается только в этой снапшотной версии, что позволяет её локализовать.
Так же снапшотные ветки позволяют дебажить сервис удалённо, опять же, потому, что смежные api задеты не будут.
Есть и ложка дёгтя в нашем решении. С внедрением фича веток повысилась нагрузка на Jenkins, которому стали собирать больше снапшотных артефактов. Также этот подход не решает полностью проблему с внешними системами, плюс немного повысилась сложность разработки.
В данный момент механизм фича веток реализован только для api-х, но при этом у нас ещё есть базы, очереди и кэши, которые пока не разведены. Есть задачки. Будем думать как это сделать красиво и при этом, чтобы было удобно пользоваться.
Комментарии (7)

BcTpe4HbIu
15.03.2024 11:55+1Но если базы, кэши и очереди не разделены, то получается все эти фичаветки используют общие базы, кэши и очереди? А как быть с миграциями, изменениями контрактов в очередях и всем таким?

AliveSubstance Автор
15.03.2024 11:55С очередями пока самое сложное. Явного какого-то способа не нашли. Есть возможность поднять отдельную кафку и натравить на неё микрик.
С базами пока решили что если схема меняется, то происходит полное копирование данных в этой же базе, но в другую схему, там делаются правки и потом миграцией заливаются в основную. Это с SQL. С многой не много проще получается потому что коллекции можно создать автоматом.
Если нужен отдельный кеш, то он разводится по имени мапы.
Но, к сожалению, эти все действия нужно совершать в ручную.


ideological
15.03.2024 11:55>Есть некоторые api, над которыми работают несколько команд. Каждая работает над своей фичей локально и пишет тесты, а вот при деплое на стэнд получается столпотворение потому, что нужно изменения слить в одну ветку аля develop и её закинуть на тест.
Наверное проще чтобы каждая команда делала свои фичи в отдельном проекте на отдельных роутах. А уже кто-то выше вызывал те что нужны.
Проще убрать пересечение чем разруливать его.
AliveSubstance Автор
15.03.2024 11:55Тогда сложно будет подружить фронт и бэк. Если фронтовый и бэковый микрик задеплоить с одинаковой фичей, например feature-31337, то можно будет вызывать feature-31337.demo.net и попасть в фича ветку фронта и бэка.
chemtech
Спасибо за пост. Вопрос про мониторинг istio. У istio метрики с наибольшим количеством серий это: istio_request_bytes_bucket, istio_request_duration_milliseconds_bucket, istio_response_bytes_bucket. Уменьшали ли вы их кардинальность? Если да, то как?
AliveSubstance Автор
Пожалуйста) С метриками отдельно ни чего не делали. Используем дефолтнын дашборды от истио, но надо будет посмотреть на них внимательней. Сложностей они каких-то не создают потому что хранятся мало времени на тесте, а на проде фича веток нет