
Растущее количество угроз вынуждает разработчиков средств анализа защищенности постоянно усовершенствовать свои решения. Сейчас на рынке ИБ представлен широкий выбор сканеров безопасности от различных производителей, которые разнятся по своей эффективности. Это делает невозможным выпуск новых версий сканеров без конкурентного анализа подобных продуктов.
Компания Positive Technologies разработала собственную методологию конкурентного анализа для тестирования и сравнения сканеров по объективным критериям, таким как типы и количество найденных уязвимостей, полнота сканирования различных целей. Кроме того, была сформирована база данных конкурентного анализа (DBCA — Database of Competitive Analysis), в которой собраны уникальные уязвимости, найденные в процессе ручных проверок и автоматического сканирования синтетических целей, реальных сайтов, CMS, веб-приложений и прочих информационных систем сканерами безопасности (WebEngine – встроенный в PT AF и PT AI, Acunetix, AppScan и др.). DBCA используется для сравнения результатов сканирования новыми версиями сканеров Positive Technologies с результатами сторонних сканеров и отсеивания ложных срабатываний (false positive).
Однако наполнение DBCA требует месяцев ручного труда высококвалифицированных инженеров-тестировщиков. Процессы настройки окружений и сканирования занимают много времени, порой недели. Еще дольше происходит процесс валидации найденных уязвимостей. Так, над заполнением текущей базы работали три инженера отдела QA в течение года. В связи с этим возникла необходимость ускорения и автоматизации работ.
Решением стало использование математического аппарата нейронных сетей (НС) и нечетких измерительных шкал. Об этом мы подробно писали в предыдущей статье «Сканеры безопасности: автоматическая валидация уязвимостей с помощью нечетких множеств и нейронных сетей». Теоретические исследования вошли в основу практического эксперимента, поставленного инженерами Positive Technologies: Тимуром Гильмуллиным, Владимиром Софиным, Артемом Юшковским.
Была решена формальная задача по преобразованию DBCA в базу знаний, путем использования НС (в качестве решающего правила) и нечетких измерительных шкал (для лингвистической оценки результатов классификации в понятной человеку форме). Практически DBCA была дополнена правилами и механизмами отсеивания ложных срабатываний, заранее отсортированных по степени уверенности в их наличии, оцененных на нечеткой измерительной шкале. Это позволило ускорить работу инженеров-тестировщиков по анализу результатов сканирования и отсеиванию ложных срабатываний.
Ретроспектива, критерий приемки и основные результаты
После завершения работ по первичному заполнению DBCA уязвимостями, база содержала несколько десятков тысяч уязвимостей. Из них инженеры-тестировщики в течение года классифицировали лишь около половины. Результаты нашего анализа показали, что они выполняли до 70% лишних действий по отсеиванию ложных срабатываний от всего объема работ.
При регулярном проведении работ по конкурентному анализу использование автоматической системы для валидации уязвимостей дает огромный прирост производительности и повышает эффективность ручного труда — можно сократить до 70% объема требуемых работ! Кроме того, применение автоматической системы освободит инженеров для других приоритетных задач, что позволит увеличить число сканеров, участвующих в конкурентном анализе, и количество сканируемых CMS.
Со стороны тестирования были получены следующие критерии приемки и требования эффективности:
- Основной критерий: после внедрения автоматической системы для валидации уязвимостей количество ложных отказов (false reject) не должно превышать 10% от общего числа обработанных уязвимостей.
- Новый алгоритм подтверждения уязвимостей увеличит количество подтвержденных уязвимостей (confirmed) и уменьшит количество незначительно отличающихся от эталонных уязвимостей (semi-confirmed) как минимум на 5—10%.
- Новый алгоритм подтверждения уязвимостей даст меньше ошибок, чем простой алгоритм, который уже имеется у инженеров по тестированию, как минимум на 10%.
- Автоматическая система валидации уязвимостей будет внедрена в процесс конкурентного анализа.
В ходе эксперимента инженерами были разработаны:
- Матрица кодирования уязвимостей. Это правила преобразования данных об уязвимостях и представления их свойств в виде числового или нечеткого вектора. Такая матрица уникальна для каждой конкретной предметной области и решаемой задачи.
- Программные скрипты для получения данных из DBCA, представленные в формате XML.
- Программные скрипты для кодирования полученных данных об уязвимостях в виде числовых или нечетких векторов (хранимых в текстовых файлах определенного формата), согласно матрице кодирования. Эти файлы используются при обучении нейросети.
- Обученная нейронная сеть для задачи классификации уязвимостей с возможностями дообучения и переобучения, в формате XML программы FuzzyClassificator.
- Адаптированные для решения поставленной задачи скрипты FuzzyClassificator, реализующие все этапы работы с нейросетью, включая ее создание, обучение и этап классификации обученной нейросетью.
- Механизмы для управления всеми процессами валидации уязвимостей на базе системы непрерывной интеграции TeamCity.
Функциональная схема классификации уязвимостей
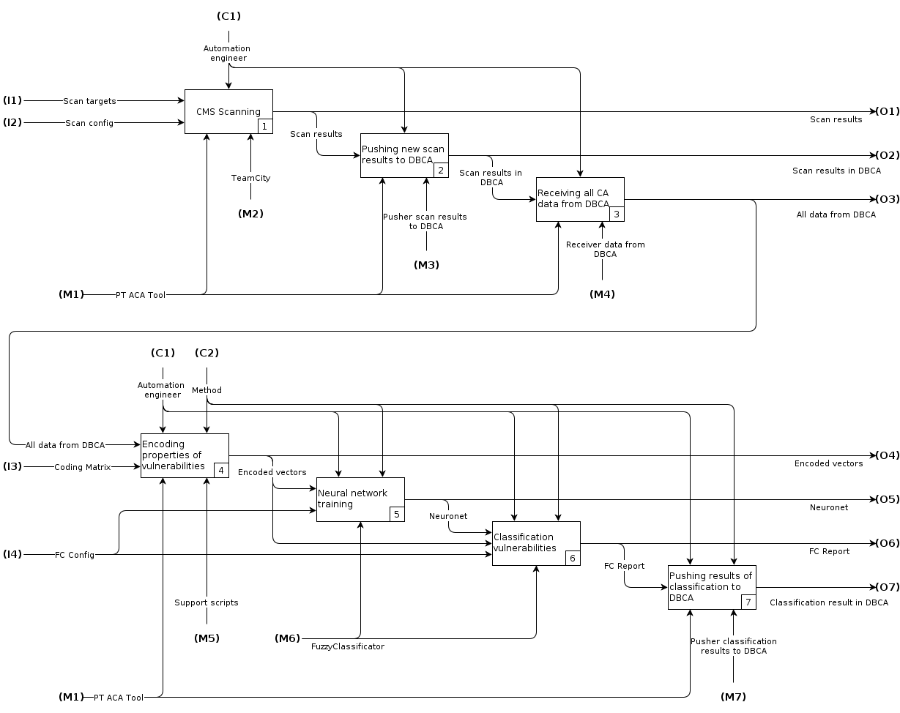
Весь комплекс автоматизации процессов для классификации уязвимостей был описан функциональной IDEF0-схемой.
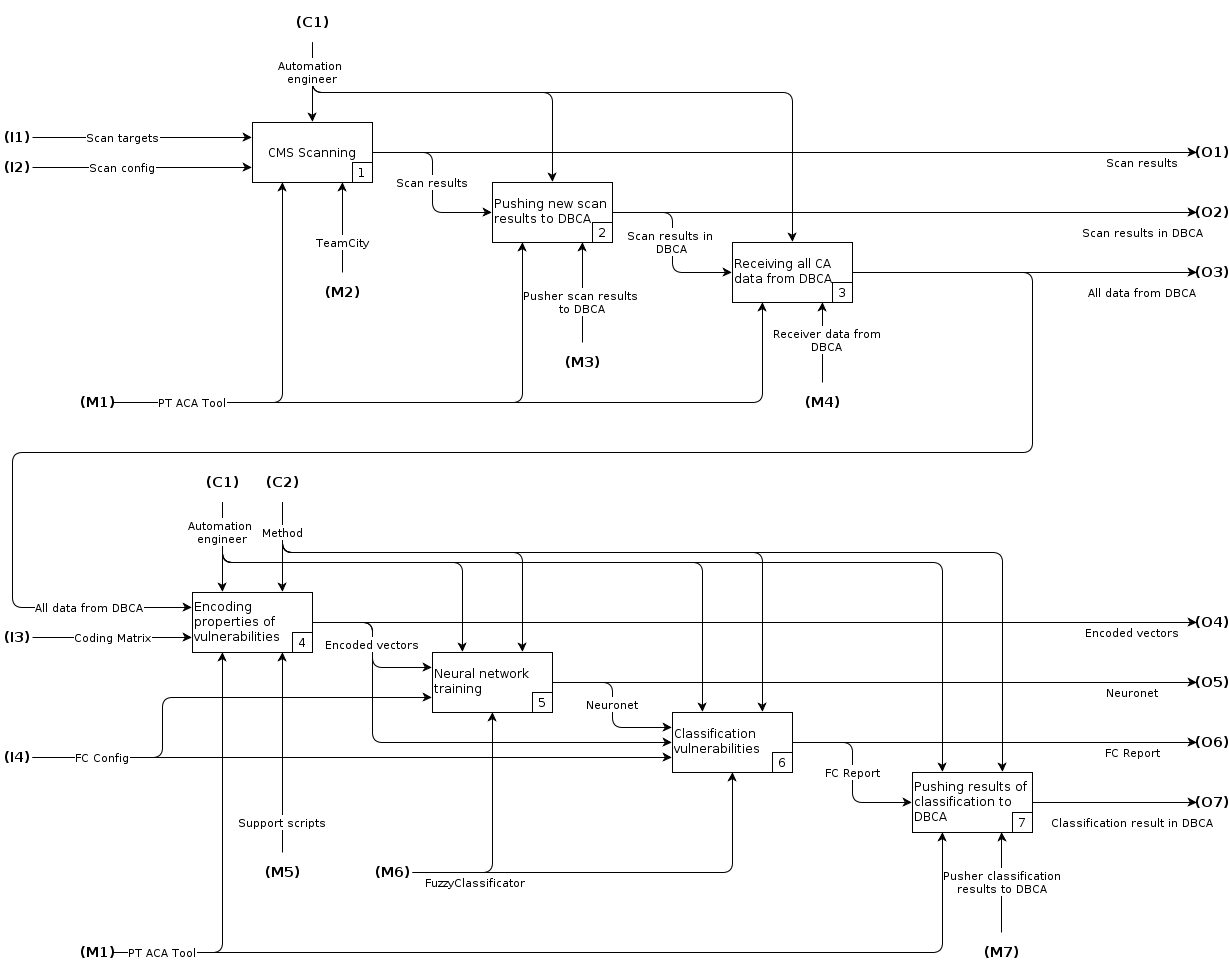
Рис. 1 Функциональная IDEF0-схема
На схеме отражены основные этапы классификации уязвимостей:
- Сканирование CMS.
- Занесение результатов в DBCA.
- Получение всех данных из DBCA, включая ранее найденные уязвимости и результаты текущего сканирования.
- Кодирование уязвимостей в числовые векторы в формате, понимаемом программой FuzzyClassificator.
- Обучение НС при помощи FuzzyClassificator на раннее найденных уязвимостях.
- Получение результатов классификации новых уязвимостей, найденных в текущей итерации сканирования.
- Публикация результатов в DBCA.
Подробные описания всех элементов функциональной схемы приведены под спойлером
Элементы функциональной схемы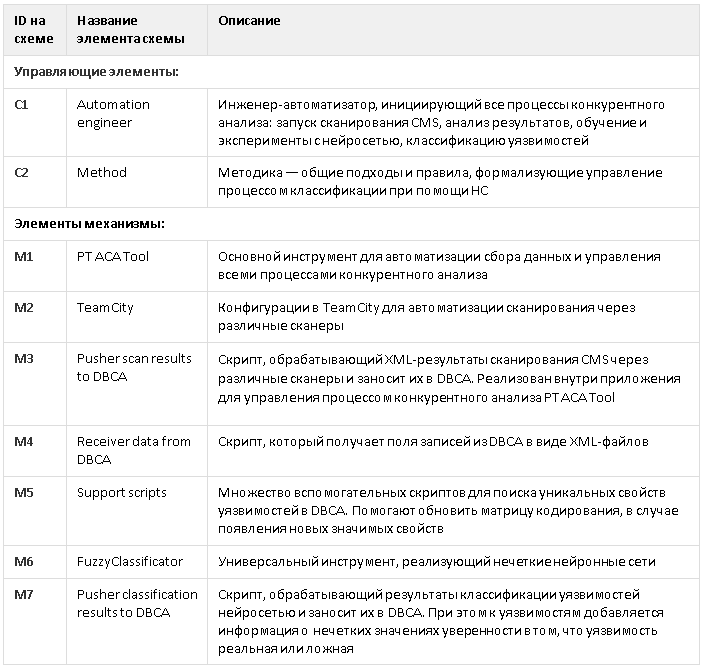

В качестве измерительных шкал для оценки свойств информационных систем была использована универсальная нечеткая измерительная шкала (рис. 2).
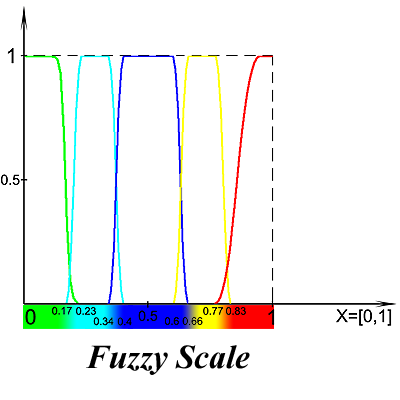
Рис. 2. Распределение уровней по нечеткой универсальной шкале
Нечеткая шкала (FuzzyScale) — это набор упорядоченных нечетких переменных, представленных в виде лингвистических переменных, описывающих некоторые свойства объекта:
FuzzyScale = {Min, Low, Med, High, Max}Здесь:
- Min — это нечеткое значение, означающее минимальную степень уверенности в чем-либо;
- Low — это чуть большее значение степени уверенности;
- Med — это средняя степень уверенности;
- High — это более высокая степень уверенности;
- Max — это нечеткий уровень, означающий максимальную степень уверенности в чем-либо.
По сравнению с другими используемыми алгоритмами валидации уязвимостей, в основе которых лежит четкая измерительная шкала, такой подход помогает решить проблему приоритизации уязвимостей на более понятной человеку шкале, состоящей из уровней, что значительно сокращает их дальнейший разбор.
Матрица кодирования свойств уязвимостей и формат ее хранения
Любой способ классификации уязвимостей предполагает кодирование, поэтому одним из важных этапов классификации уязвимостей было кодирование входных данных. В качестве основного элемента мы использовали матрицу кодирования свойств уязвимостей (Coding Matrix). Она применяется для преобразования уязвимостей, полученных из базы TFS в формате XML, в текстовый DAT-файл специального формата, подаваемого на вход нейросети программы FuzzyClassificator. После построения матрицы написать скрипты (support scripts) для кодирования при помощи матрицы не составляет никакого труда. Подробнее читайте в блоге (Кодирование входных данных).
Для более эффективного обучения нейросети требовалось подобрать оптимальную матрицу, которая описывает способ кодирования наиболее значимых свойств уязвимостей, подаваемых на входы нейросети. Матрица была реализована при помощи простого JSON-файла.
Coding Matrix json-format:
{
"<PROPERTY_NAME_1>": {
"values": {
"unknown": 0,
"<value_1>": 1,
"<value_2>": 2,
...,
<value_N>: N
},
"comment": "Произвольный комментарий к свойству, например способ получения его значения. PROPERTY_NAME - уникальное имя отдельного свойства уязвимости"
},
...,
"<PROPERTY_NAME_M>": {
"values": {
"unknown": 0,
"<value_1>": 1,
"<value_2>": 2,
...,
<value_K>: K
},
"comment": "Каждое свойство содержит уникальное имя и набор всех возможных значений, которые кодируются по порядку: 0 (неизвестное значение), 1, 2, ..."
},
"<PROPERTY_NAME_X>": {
"values": {
"unknown": 0,
"exists": 1
},
"comment": "Так должно выглядеть кодирование тех свойств, о которых достаточно знать только то, что они существуют (exists = 1) или не существуют (unknown = 0) у конкретной уязвимости"
}
}
Автоматизация процесса классификации уязвимостей в TeamCity
Для удобства инженеров-тестировщиков весь процесс, представленный на функциональной схеме, был автоматизирован в системе интеграции TeamCity. Часть конфигурации, приведенная на рис. 3, иллюстрирует точку входа для реализации блоков 4, 5, 6 (7) функциональной схемы.
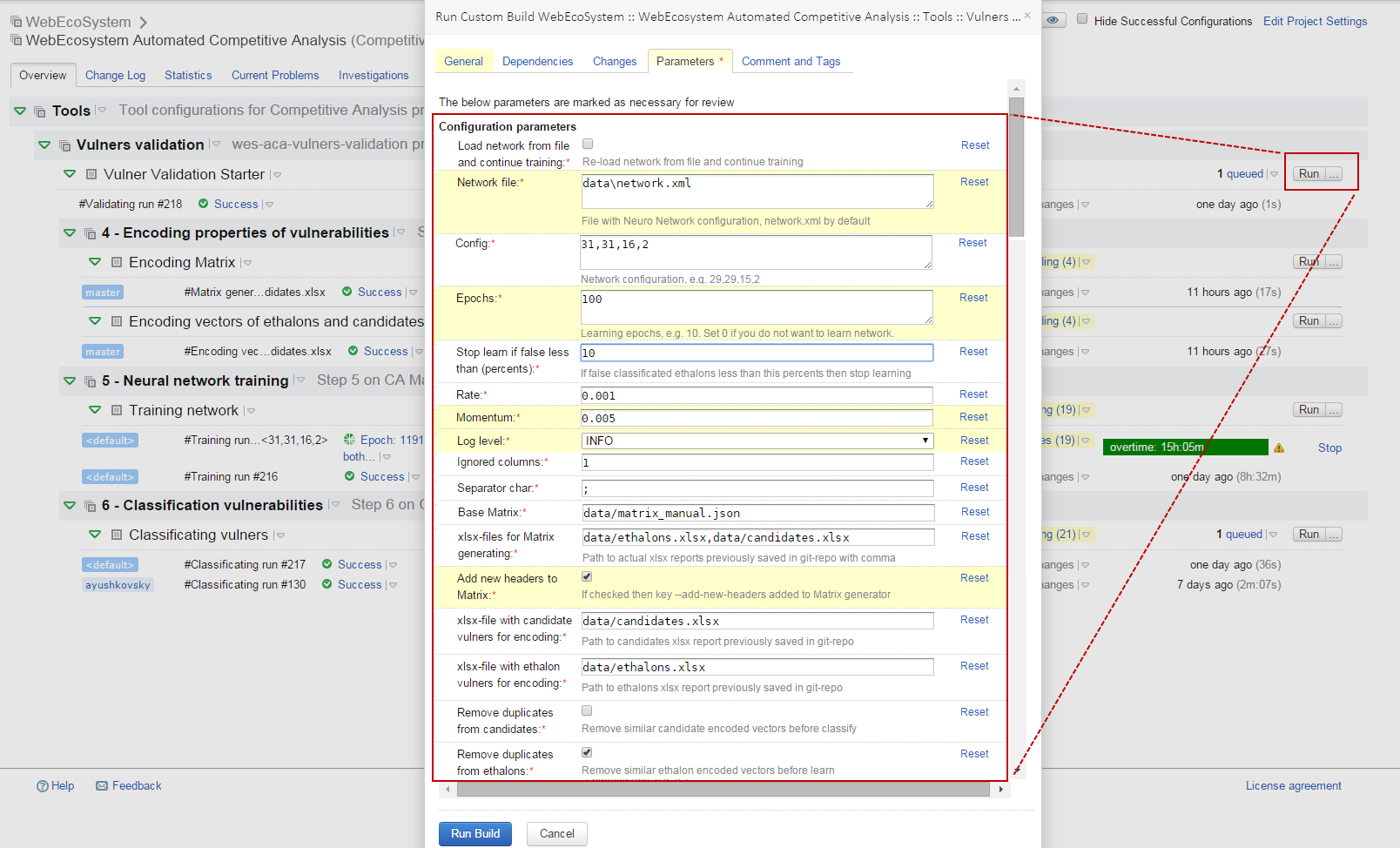
Рис. 3. Конфигурация в TeamCity, которая запускает процесс классификации уязвимостей
После завершения процесса анализа уязвимостей TeamCity выдает текстовые файлы с отчетами по классификации уязвимостей-кандидатов и статистику с оценкой качества обучения нейросети на эталонах.
Кроме того, до получения итоговых результатов можно оценивать качество обучения нейросети по ошибкам, которые она выдает на эталонных векторах. Процесс обучения проходит в удобном для инженера формате: вся необходимая информация выводится в конфигурации Training network (см. рис. 4) в реальном времени.

Рис. 4. Вывод промежуточных результатов по качеству обучения нейросетей
Параметры на рис. 4 отражают основные показатели обучения на эталонных векторах:
- Epoch — текущая эпоха обучения (или последняя по окончании обучения);
- False — общее число ошибочно классифицированных эталонных уязвимостей (правила подсчета статистики при обучении приведены ниже);
- Best — количество ошибочно классифицированных эталонных уязвимостей для лучшей нейросети в этом обучении.
Примеры отчетов
Для удобства интерпретации результатов статистика во всех отчетах разбита на отдельные блоки, т. е. на выходе инженер-тестировщик получает понятный и подробный отчет. Под спойлером представлены пояснения по каждому блоку.
Блоки отчета
В заголовке отчета Overview:
В таблице Main statistics:
В таблице Neural network quality statistics (for ethalon vectors only):
В таблице Classification Result:
• Neuronet — используемая сеть;
• Input file with encoded vectors — файл со входными данными для обучения или классификации (в зависимости от отчета);
• Network configuration — конфигурация нейронной сети;
• Report legend — описание нечетких уровней, использующихся для оценки принадлежности уязвимости к классам подтвержденных или неподтвержденных уязвимостей.
В таблице Main statistics:
• Total classificated vectors' count — количество обработанных уязвимостей при классификации;
• Allocation table of sorted by levels vectors' count — таблица распределения количества векторов уязвимостей по различным нечетким уровням.
В таблице Neural network quality statistics (for ethalon vectors only):
• False classificated vectors' count — количество ошибочно классифицированных векторов уязвимостей при обучении на эталонах, согласно правилам подсчета статистики по качеству обучения нейросети (неполное совпадение засчитывается как верный результат);
- a) False confirmed vectors' count — количество векторов уязвимостей, у которых с эталоном не совпал только уровень Level Confirm,
- b) False rejected vectors' count — количество векторов уязвимостей, у которых с эталоном не совпал только уровень Level Reject,
- c) Both of false confirmed and rejected vectors' count — количество векторов уязвимостей, у которых с эталоном не совпали одновременно оба уровня Level Confirm и Level Reject;
• Allocation table of sorted by levels false classificated vectors — количество ошибок классификации сгруппированных по различным нечетким уровням.
В таблице Classification Result:
• TFSID — ссылка на уязвимость в DBCA;
• Level Confirm — результат классификации уязвимости нейросетью, показывающий степень уверенности в том, что уязвимость подтверждается;
• Level Reject — результат классификации уязвимости нейросетью, показывающий степень уверенности в том, что уязвимость не подтверждается;
• Interpreting as — как интерпретировать результат композиции двух уровней (Level Confirm, Level Reject), четкий итоговый результат классификации:
- Confirmed — нейросеть считает, что уязвимость скорее подтверждается,
- Rejected — нейросеть считает, что уязвимость скорее отвергнута,
- ERROR — ошибка классификации, которая означает, что нейросеть не может однозначно классифицировать уязвимость и требуется ее ручная валидация.

Рис. 5. Пример отчета по классификации уязвимостей-эталонов, содержащий статистику по качеству обучения нейросети
На рис. 5 представлен пример отчета по классификации уязвимостей-эталонов. Данные, полученные нейросетью после обучения (блок Classification Result), сравниваются с эталоном и выдается результат — True или False (засчитать ответ как правильный или как ложный). По итогам классификации подсчитывается число ошибочно классифицированных уязвимостей при обучении на эталонах, согласно правилу подсчета статистики по качеству обучения нейросети. Это правило мы свели в табл. 1, где указали уровни, которые можно считать правильным результатом при классификации, исходя из практических соображений.
Табл. 1. Интерпретация ответов нейросети при обучении
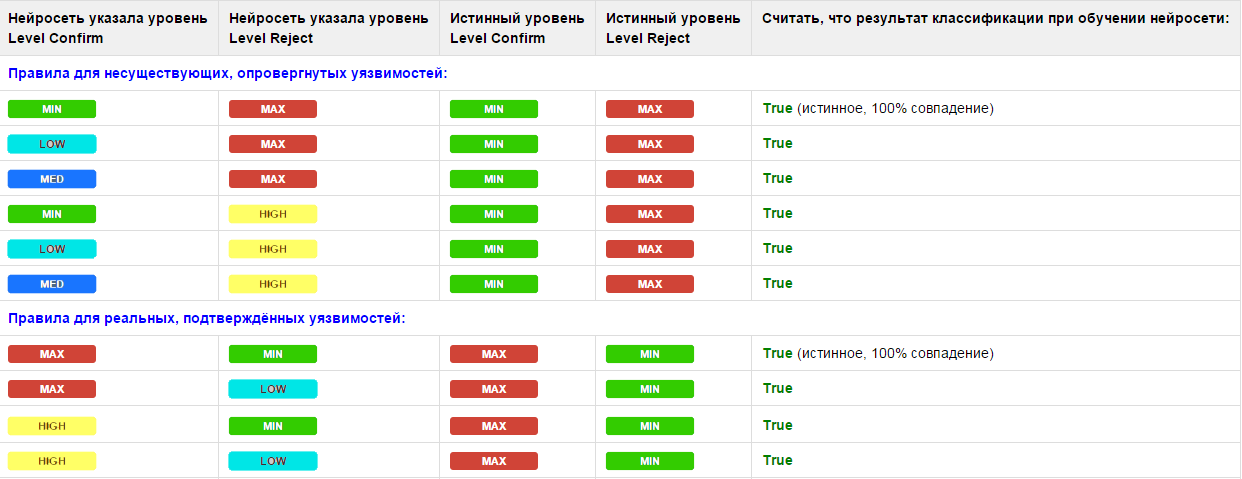
В ходе исследования мы пришли к выводу, что требовать от нейросети стопроцентного совпадения уровней при классификации уязвимостей невозможно, так как некоторые уровни близки по значению друг к другу. К примеру, человек, получив в результате классификации Level Reject = High вместо Max, зачтет такую уязвимость как опровергнутую. Поэтому, если результат, выданный нейросетью, «близок» к истинному значению (High вместо Max и Low/Med вместо Min), то мы считаем его правильным при обучении True (weak), если значения полностью совпадают, то True (strong). Отметим, что правила для реальных уязвимостей строже, чем для ложных, так как выявление реальных уязвимостей является более приоритетной задачей. Все остальные варианты, не указанные в таблице, считаются ложным ответом (False).
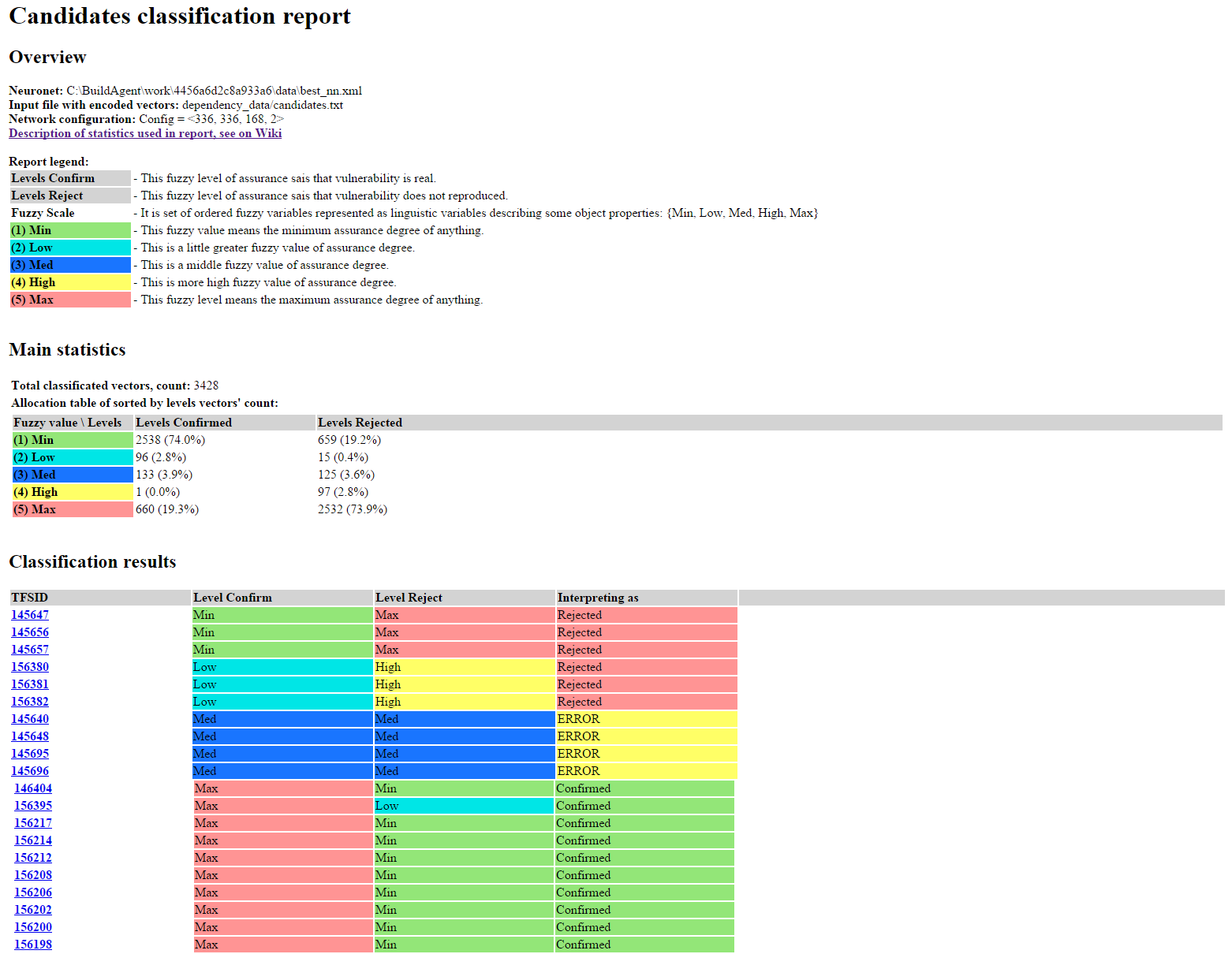
Рис. 6. Пример отчета по классификации уязвимостей-кандидатов, содержащий значения нечетких уровней и их интерпретацию
Аналогично отчету по классификации уязвимостей-эталонов выглядит отчет с результатами классификации по кандидатам. Нейросеть выдает ответ, как интерпретировать нечеткие уровни Level Confirm и Level Reject по каждой уязвимости: Confirmed, Rejected или ERROR, согласно правилам однозначной интерпретации результатов нечеткой классификации уязвимостей (см. табл. 2).
Табл. 2. Правила однозначной интерпретации результатов нечеткой классификации уязвимостей

Использование правил позволяет дать четкий ответ в понятной человеку форме: уязвимость подтверждена, опровергнута или получен неоднозначный результат классификации — ошибка. В случае ошибки требуется ручная классификация. По аналогии с правилами табл. 1, уязвимости-кандидаты нужно считать отвергнутыми, если по результатам классификации нечеткий уровень Level Reject будет высоким (Max, High), а нечеткий уровень Level Confirm средним или низким (Med, Low, Min). Соответственно уязвимость будет подтверждена при противоположных результатах. Правила для подтвержденных уязвимостей также более строгие.
Результаты исследования
Работа с нейросетью включала в себя несколько этапов — обучение на эталонах и разбор уязвимостей в рабочем режиме на новых результатах сканирования.
Так, в ходе эксперимента обучалось одновременно несколько нейросетей, но с различными конфигурациями. На данный момент по результатам обучения в TeamCity получена наилучшая нейросеть со следующей конфигурацией:
Config = <336, 336, 168, 2>. Ее обучение происходило в течение 1155 эпох на 11004 эталонных векторах уязвимостей. При этом нейросеть, согласно правилам интерпретации ответов (см. табл. 1), в режиме обучения ошибочно классифицировала всего 555 (5.0%) векторов.Разбор уязвимостей в рабочем режиме состоял из двух этапов. Первый этап включал в себя ручной разбор данных сканирования и классификацию уязвимостей. На втором этапе разобранные уязвимости были предложены нейросети, которая ранее на них не обучалась, для анализа (одновременно и в качестве кандидатов для разбора уязвимостей, и в качестве эталонов).
В рабочем режиме, при классификации ранее неизвестных уязвимостей, нейросеть выдала следующие результаты: из 2998 проанализированных уязвимостей ошибочно классифицировала 595 (19.8%).
На данный момент удовлетворены все формальные требования со стороны отдела тестирования, и мы продолжаем работать над улучшением результатов классификации: оптимизируем параметры нейросети, отсеиваем «плохие» свойства из матрицы кодирования.
Полноценное использование всех преимуществ автоматической классификации уязвимостей при помощи нейросетей ожидается в начале 2016 года. Однако уже сейчас результаты разбора уязвимостей автоматически проставляются для уязвимостей в DBCA.
На рис. 7 приведен пример типичной записи об уязвимости из DBCA, для которой нейросеть сделала правильное предположение, что эту уязвимость, найденную сканером PT AI, нужно опровергнуть как ложное срабатывание. Об этом говорят значения полей: «Level Confirm: 5 – Min», «Level Reject: 1 — Max», «Notes: Interpreting as: Reject». Аналогичным образом проставляются результаты для всех остальных уязвимостей.
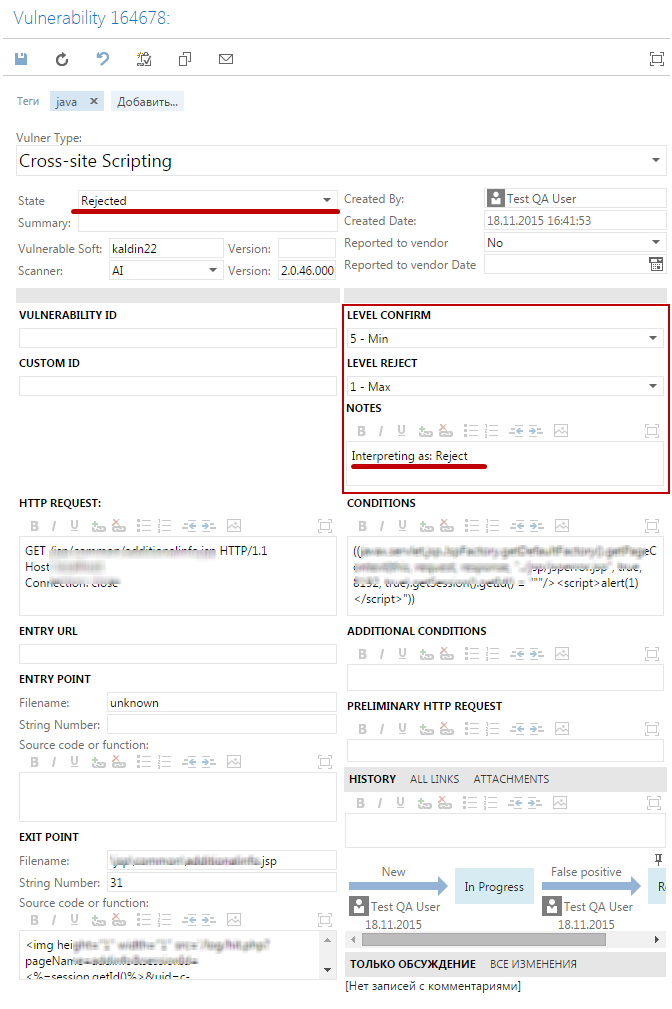
Рис. 7. Запись в DBCA с результатами нейросетевой классификации
Выражаю благодарность своим коллегам: QA-инженерам Positive Technologies Владимиру Софину и Артему Юшковскому за помощь в практической реализации некоторых инструментов и огромный вклад в проведение многочисленных экспериментов, а также доценту кафедры математического анализа, алгебры и геометрии, к. пед. н. Казанского (Приволжского) федерального университета Мансуру Гильмуллину за помощь в подготовке теоретической базы для исследований и экспериментов.
Автор: Тимур Гильмуллин, к. т. н., DevOps-инженер Positive Technologies.