
Группа исследователей из Университета Торонто опубликовало работу, посвященную использованию FPGA для повышения эффективности обработки событий при алгоритмической торговле на бирже. Мы представляем вашему вниманию основные моменты этого документа.
Введение
В настоящий момент высокочастотная торговля доминирует на финансовых рынках (по разным данным, доля сделок, совершенных с помощью алгоритмов, сейчас составляет около 70%). Соответственно, постоянно растет и важность оптимизации процессов исполнения заявок и обработки транзакций и возникающих на рынке событий — конкуренция столь сильна, что все решают микросекунды.
Успешные стратегии могут приносить своим создателям прибыль, играя даже на микроскопических различиях цен связанных активов на разных биржевых площадках — к примеру, если акция какой-то компании торгуется на Нью-Йоркской бирже по цене $40,05, а в Торонто — по $40,04, то алгоритм должен купить в акцию в Канаде и продать ее в США. Каждая выигранная миллисекунда здесь может повлечь за собой миллионные прибыли на горизонте года.
Алгоритмическую торговлю можно смоделировать в виде платформы обработки событий, в которой финансовые новости и рыночные данные рассматриваются в качестве событий, вроде [stock = ABX, TSXask = 40.04, NYSEask = 40.05], а инвестиционные стратегии формулируются финансовыми институтами или инвесторами в виде подписок: [stock = ABX, TSXask 6= NYSEask] или [stock = ABX, TSXask ? 40.04].
Таким образом, масштабируемая платформа обработки событий должна уметь эффективно находить все инвестиционные стратегии (подписки), которые соответствуют входящим событиям — и таких событий могут быть миллионы в секунду.
Зачем использовать FPGA
Наиболее ресурсоемким аспектом процесса обработки событий является сопоставление (matching). Алгоритм принимает входное событие (поток котировок, рыночные события) и набор подписок (т.е. инвестиционных стратегий) и возвращает подписки, для которых найдены совпадения с рыночными событиями.
Справляться с требованиями по эффективности обработки данных в сетях с постоянно увеличивающейся пропускной способностью — нетривиальная задача. Одновременно с увеличением пропускной способности растут и объёмы обрабатываемых данных. При этом, построение не чрезмерно дорогих систем для работы в такой ситуации также непросто в виду того, что существующие технологии создания процессоров подходят к своему пределу и их производительность не растет так быстро, как это было раньше.
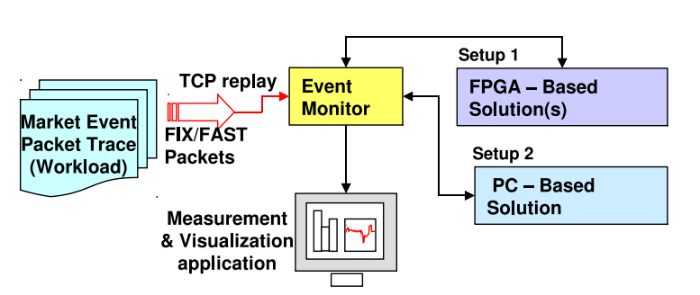
Популярные серверы часто не справляются с обработкой рыночных данных на нужной скорости. В результате трейдеры и финансовые организации сталкиваются с необходимостью повышения производительности своей инфраструктуры. Ускорить работу алгоритмов можно не только с помощью покупки дополнительных серверов, но и использования FPGA.
Софт-подход к обработке
Возможность аппаратного реконфигурирования позволяет FPGA использовать Soft-микропроцессоры, которые имеют несколько важных преимуществ. Их проще программировать (это означает возможность использования C вместо Verilog, который требует специализированных знаний), они могут быть портированы для разных FPGA, их можно кастомизировать, кроме того их можно использовать для взаимодействия с другими частями системы.
В текущем примере FPGA располагается на сетевой карте NetFPGA и связывается с хост-машиной через DMA на PCI-интерфейсе. У FPGA есть программируемые пины, которые обеспечивают прямое соединение с памятью и сетевыми интерфейсами — в обычном сервере с ними можно взаимодействовать только через интерфейс сетевой карты.
Для экспериментов было создано решение, основанное на Soft-микропроцессорах, работающее на NetFPGA, а также базисный вариант для работы с PC — обе реализации использовали одну и ту же стратегию матчинга.
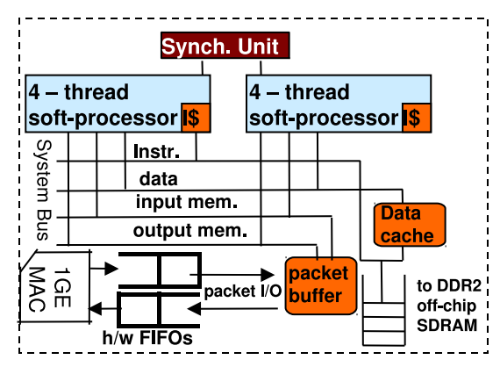
Реализация Soft-микропроцессора
Для повышения пропускной способности приложения обработки событий был выбран NetThreads, который имеет два однозадачных, пятиступенчатых, многопоточных процессоров.
В едином ядре инструкции из четырех «железных» потоков обрабатываются похожим на round-robin способом — это позволяет осуществлять вычисления даже при необходимости ожидания памяти. Подобная система хорошо подходит для обработки событий: Soft-процессоры не страдают от перегрузок операционной системы, чему подвержены обычные компьютеры, они могут получать и обрабатывать пакеты параллельно, при минимальных затратах ресурсов, а также у них есть доступ к таймеру с более высоким разрешением (гораздо большим чем на PC) для обработки таймаутов и планирования операций.
Благодаря отсутствию в NetThreads операционной системы пакеты рассматриваются в качестве буферов символов в памяти и доступны сразу же после их полного получения процессором (пропускается шаг с копированием в приложение в пространстве пользователя).
Только «железо»
Второй использованный подход подразумевал создание исключительно аппаратного решения: все нужные шаги осуществляют «кастомные» железные компоненты, в том числе они используются для парсинга рыночных событий и их матчинга с соответствующими стратегиями. Этот метод позволяет добиться наибольшей производительности, однако он также является и наиболее сложным.
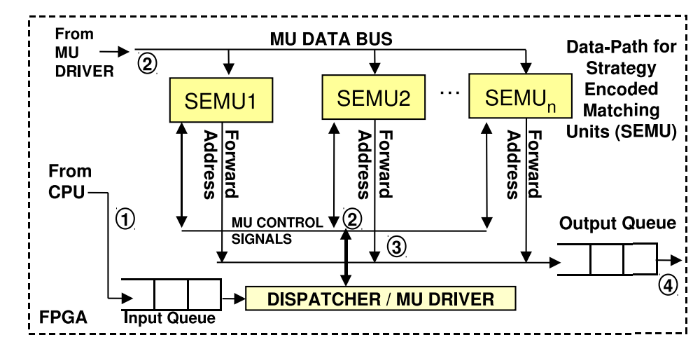
Гибридный подход
Из-за сложности использования только аппаратных средств для поддержки динамических стратегий и форматов событий можно применять и гибридный подход, объединяющий плюсы двух описанных выше схем. Поскольку обычно FPGA программируются на низкоуровневых языках, то поддерживать работу созданных таким образом коммуникационных протоколов довольно трудно.
Этой проблемы можно избежать, если запустить Soft-микропроцессор для реализации обработки пакетов с помощью софта. После парсинга входящих пакетов с рыночными данными, Soft-микропроцессор передает их железу.
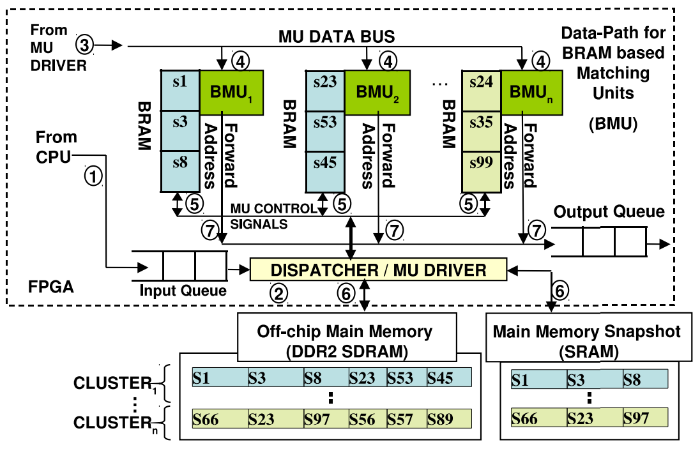
Заключение
В результате применения различных подходов — использование PC в качестве базового варианта, софт-подход, только «железо» и гибридный метод — исследователям удалось собрать данные по эффективности каждого из представленных методов для обработки рыночных событий.
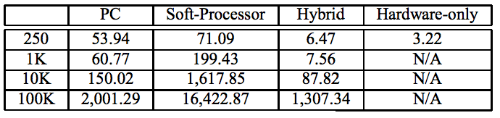
Нагрузка в ходе экспериментов изменялась с 250 до 100 тыс. анализируемых инвестиционных стратегий. В результате использование гибридного подхода позволило опередить другие методы на два и более порядка (результаты представлены в таблице выше).
Комментарии (9)

gbg
15.01.2016 14:03+2Все прекрасно, но на картинке у вас LV2444A — операционный усилитель. Аналоговая микросхема, не имеющая ничего общего с FPGA. Кого вы хотите обмануть?

lol_wat
15.01.2016 14:46+4Кого вы хотите обмануть?
Обмануть, картинкой до ката… Мдаgbg
15.01.2016 14:51+1А просто хитрый автор поста изволил картинку убрать (ну, нагуглилась у него какая попала микросхема, никого же не интересует, что это аналоговый прибор даже, а не цифровой), и теперь я выгляжу слегка идиотом.

alexlash
15.01.2016 14:56+2Вот как раз поэтому и стоит такие комменты писать в личку — это же простая неточность или ошибка, после исправления которой коммент становится непонятным новым читателям
gbg
15.01.2016 14:58+2Нужно отличать техническую ошибку вроде опечатки или даже убитой орфографии, от некомпетентности. Влепить аналоговую микросхему в качестве иллюстрации к такой статье — это расписаться в таковой некомпетентности.
lol_wat
15.01.2016 16:41+2Отличать-то можно что угодно, но суть в том, что ваш коммент теперь нерелевантен ситуации — ошибки, которая в нем описана нет. И зачем он тут тогда? Такие вещи решаются через личку, для того она и нужна здесь

Kroid
Если физически две биржи находятся в разных местах, то наш сервер будет стоять где-то между ними. Имеет ли смысл тогда бороться за каждый такт, если скорость получения/отправки ордера будет на несколько порядков меньше, чем самые медленные вычисления на том же PC?
webmascon
то есть алгоритм сначала должен узнать, а потом купить. но на это уйдет время. и когда ордер отправленный алгоритмом прибежит в Торонто там будет уже другая цена. а ордер прибежавший в Нью-йорк будет исполнен. и получится ваш алгоритм купил а продать не смог. или продал голым шортом, а перекупить не успел.