
 Идея написать популярно про большие числа пришла во время чтения этой статьи. Речь в ней шла о числах-гигантах, имеющих хоть какой-то физический смысл. И заканчивается она упоминанием числа Грэма. Того числа, которое будет точкой отсчета сегодняшней статьи. Чтобы представить себе масштабы бедствия я настоятельно рекомендую предварительно прочитать вот эту статью, в которое объясняется о числе Грэма на пальцахTM — там автор очень красочно и последовательно рассказывает о границах восприятия, в которые мы себя зажимаем, когда говорим о больших числах.
Идея написать популярно про большие числа пришла во время чтения этой статьи. Речь в ней шла о числах-гигантах, имеющих хоть какой-то физический смысл. И заканчивается она упоминанием числа Грэма. Того числа, которое будет точкой отсчета сегодняшней статьи. Чтобы представить себе масштабы бедствия я настоятельно рекомендую предварительно прочитать вот эту статью, в которое объясняется о числе Грэма на пальцахTM — там автор очень красочно и последовательно рассказывает о границах восприятия, в которые мы себя зажимаем, когда говорим о больших числах.
Для начала необходимо прояснить, что когда мы говорим о больших числах (даже не БОЛЬШИХ, а просто больших), то как правило имеем ввиду не последовательность цифр, образующих это число, а способ (или метод), с помощью которого данное число получается. Конечно, мы можем написать секстиллион как 1000000000000000000000, но все же привычнее видеть 1021. В данном случае способом описания числа будет операция возведение в степень (которая выглядит как запись числа верхним индексом справа). Использование подобных способов позволяет сократить запись числа, оставляя лишь способ его образования (чего, разумеется, вполне достаточно для совершения математических действий над ним). Так мы логически подошли к тому, что все разговоры в БОЛЬШИХ числах сводятся к поиску максимально компактной записи максимально большого числа. Итак, «шо же придумали эти математики».
Все мы знаем три основные арифметические операции: сложение (a+b), умножение (a ? b), возведение в степень (ab). Никогда не задумывались, что все эти операции последовательно вытекают одна из другой? А если так:



Обобщенно эти операции называются гипероператорами. Для сложения, умножения и возведения в степень — 1-го, 2-го и 3-го порядка соответственно. Продолжение этого ряда на более высокие порядки напрашивается само собой: гипероператором 4 порядка (тетрацией) называют последовательное возведение в степень:
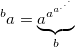
А вот для гипероператоров более высоких порядков использовать такую систему обозначений уже не получится — уж больно громоздкими и запутанными будут степенные башни. Поэтому для обозначение больших чисел используются другие системы нотаций.
Одной из наиболее распространенных является стрелочная нотация Дональда Кнута, предложенная в 1976 году. Принцип записи чисел вытекает из последовательности гипероператоров и по большому счету представляет собой явное указание порядка гипероператора. Обычное возведение в степень (гипероператор 3 порядка) обозначается одной стрелкой: a^b, тетрация — двумя стрелками a^^b и так далее. Вот как вычисляется тетрация:
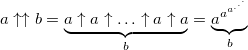
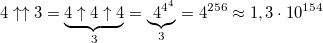
Изменив всего одну цифру мы получаем гигантский рост значения числа:
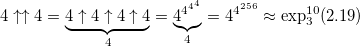 — в этом числе более, чем 10153 цифр.
— в этом числе более, чем 10153 цифр.Добавив еще одну стрелку мы получаем гипероператор 4 порядка — пентацию:
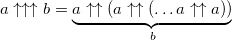
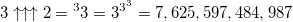
Изменение одной цифры здесь приводит к столь большому росту значения, что эпитеты можно и не подбирать:
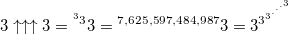 — высота степенной башни составляет 7,625,597,484,987 элементов…
— высота степенной башни составляет 7,625,597,484,987 элементов…(это число назвается тритри, и оно нам еще пригодится)
Чтобы не рисовать много стрелок, используется сокращенная запись: a^nb для обозначения a^^...^b с n стрелок.
Тут нужно быть крайне аккуратным в оценках скорости роста функции по мере увеличения порядка гипероператора (вы явно ошибётесь в меньшую сторону) — если три не пентировать, а гексировать в три (ну просто увеличить n на единицу), то мы должны 3 два раза пентировать по три, то есть 3 пентировать в три 7,625,597,484,987 раз… (но не расслабляйтесь, всё это только начало, самое начало).
Кстати, вы уже догадались, каково самое слабое место стрелочной нотации Кнута? Да, именно n — количество стрелок. А что, если оно столь велико, что обычное число уже не в состоянии его передать? Короткое отступление: если три, пентированное в два, поддается хоть какому-то пониманию, то уже три, пентированное в три, ни представить, ни осознать невозможно. Даже не заикаясь о следующих порядках гипероператоров. Это область чистой незамутненной абстрактной математики и, чёрт возьми, it's fucking awesome!
Решением проблемы нотации Кнута являются цепочки Конвея. Они используются тогда, когда для записи числа даже стрелочная нотация Кнута становится слишком громоздкой. Помните про число Грэма, которое упоминалось в самом начале? Обозначить его стрелками Кнута просто невозможно. Определение цепочки и её взаимосвязь со стрелочками Кнута:


Вроде бы всё одно и то же. Но проблема «количества стрелочек» в цепочках Конвея решается легко и изящно: добавлением еще одной стрелки. А каждая стрелка обращает всю предыдущую цепочку на себя. Попробуем разобраться на примере: возьмем тетрацию 3 > 3 > 2 (что это такое: берем первые два числа и проделываем операцию возведения в степень три раза), добавим справа > 2.
3 > 3 > 2 > 2 = 3 > 3 > ( 3 > 3 > 1 > 2) > 1 = 3 > 3 > (3 > 3) = 3 > 3 > 27
Добавив всего однy стрелочку мы сразу перешли к гипероператору 27 порядка. И число Грэма, никак не представляемое в стрелочной нотации Кнута, цепочками Конвея записывается очень лаконично: 3 > 3 > 64 > 2. А ведь можно продолжать добавлять стрелочки и переходить ко всё более невообразимым порядкам чисел.
Ха! Но разве это правильно, рисовать столько стрелок? Да и слишком уж ме-е-едленно растут числа… В общем, Джонатан Бауэрс ввел массивную нотацию (array notation), которая в своей максимально расширенной форме называется BEAF (Bowers Exploding Array Function, взрывная массивная функция Бауэрса, игра слов с английским beaf — говядина. Надо отметить, что Бауэрс даже в своих научных трудах отличается особым чувством юмора). Запись ее очень проста и напоминает уже рассмотренные нотации: 3^^^3 = 3 > 3 > 3 = {3,3,3}. Используется также другая система массивной нотации, когда последний элемент, обозначающий порядок гипероператора, переносится в середину записи, т.е. {3,3,2} = 3 {2} 3 (логика такая — берем две цифры по краям и делаем с ними то, что указано в середине).
На данном этапе никаких отличий массивной нотации от цепочек Конвея нет. Но добавление четвертого элемента массива имеет принципиально другой смысл, а именно — количество скобочек: {3,3,3} = {3,3,3,1}, {3,3,3,2} = {{3,3,3}}.
{a,b,1,2} = a {{1}} b = a { a { a....a { a { a } a } a… a } a } a, где b — количество a, расходящихся от центра.
Для наглядности посмотрим, что происходит при изменении элемента внутри центральных скобочек «всего на единицу»:
{3,3,1,2} = 3 {{1}} 3 = 3 {3 {3} 3} 3 = {3, 3, {3, 3, 3}} = {3, 3, тритри}
{3,3,2,2} = 3 {{2}} 3 = 3 {{1}} 3 {{1}} 3 = {3, {3, 3, тритри}, 1, 2} = 3 {3 {3… 3 {3 {3} 3} 3… 3} 3} 3, где количесто троек, расходящихся от центра к краям, равно {3,3, тритри}.
В сравнение с цепочками Конвея взрывной рост числа происходит на этап раньше — если у Конвея лишь четвертое число обращает все предыдущие операции на себя, то у Бауэрса — уже третье. Яркий пример с рассмотренными выше числами:
у Конвея третья единица «съедает» остаток цепочки 3 > 3 > 1 > 2 = 3 > 3 = 27, то у Бауэрса она как раз «работает» на дальнейший его рост: {3,3,1,2} = {3,3, тритри}.
Кстати, это был всего лишь массив из 4 элементов. Добавим безумия? Просто увеличивать количество элементов массива через запятую, следуя уже сформулированным правилам работы с ними — это неинтересно. Поэтому Бауэрс придумывает видоизмененные «скобки» для того, чтобы хоть минимально наглядно «представить» числа в массивной нотации. Четвертое число в массиве еще остается с фигурными скобками, а дальше начинается форменное безобразие: пятое — квадратные скобки, повернутые на 90 градусов, шестое — кольца вокруг предыдущей конструкции, седьмое — обратные угловые скобки, восьмое — как трехмерные квадратные… Короче, проще это показать:

(еще на подобные картинки можно посмотреть здесь)
Вы думаете, что Бауэрс на этом остановился? Как бы не так. Ну вот что, ЧТО еще можно придумать в записи массивов? А можно обратить внимание, что там есть запятые… Которые пусть обозначают элементы одномерного массива. А если поставить между числами (1), то это переход на следующую строку, (2) — переход на следующую плоскость.
Квадрат из троек («дутритри») записывается как {3,3,3(1)3,3,3(1)3,3,3}.
Куб из троек («диментри») — {3,3,3(1)3,3,3(1)3,3,3(2)3,3,3(1)3,3,3(1)3,3,3(2)3,3,3(1)3,3,3(1)3,3,3}.
Вот так незатейливо мы перешли от плоскостных массивов к объемным (и заметьте, это всего лишь запись некого числа, которая из-за своих масштабов потребовала выйти из плоскости просто в своем написании!). Разумеется, дальше мы вводим новые обозначения для четырехмерных, пятимерных «объектов» (простите, называть эти монструозные контрукции числами уже сложно). Например, & означает «массив из»: {10,100,2} & 10. То есть {10,100,2}-массив десяток, или же 10^^100-массив десяток. Ну то есть нужно 100 раз возвести десять в десятую степень, построить решетку с таким количеством ячеек (причем она будет находиться в стозмерении, то есть измерении измерений измерений… измерений (слово повторено сто раз)), затем заполнить все ячейки десятками — и только тогда можно приниматься решать этот массив.
Думаете хотя бы на этом всё? Неа. Обозначим «легион» прямым слэшем (/). В массиве {a,b,c,.../2} двойка находится во втором легионе. Сначала мы должны решить первый легион (слева от косой черты), а затем взять такое количество элементов в цепочке «массив из… массив из… массив из...», которое получилось при решении: {3,3 / 2} = 3 & 3 & 3 = {3,3,3} & 3. А вот если взять {3,3,3 / 3} = {3 & 3 & 3 / 2}. На этот раз тритри — это не количество элементов в массиве, а количество элементов в цепочке 3 & 3 &… & 3 & 3.
Еще одно расширение Бауэрс сделал добавив символ @ (a@b обозначает «легионный массив размера a из b») и обратный слэш \ (лугион). Ну тут уже всё понятно: {a,b \ 2} = a @ a @ a… a @ a @ a (где а повторяется b раз).
Понятно, что процесс придумывания новых наименований для каких-то операций не может быть бесконечным (за легионами и лугионами идут лагионы, лэгионы и лигионы, но очевидно, что это ничто, учитывая наш размах), поэтому Бауэрс сделал проще — определил L как прогрессию из легионов, лугионов, лагионов, лэгионов и лигионов: L1, L2, L3… И далее число опередляется индексами.
Например для «вычисления» (смешно, конечно, говорить о вычислениях на таких масштабах) {L100,10}10,10 нужно взять сотый член в прогрессии «легионы, лугионы, лагионы...» и составить из него массив в 10 измерениях. Затем нужно убирать по одному члену, каждый раз добавляя цепочку из «10 % 10 %… %10» (где % — L100-гионный массив из на то количество десяток, которое получилось на предыдущем этапе. И только после того, как все сотые члены (а также L99, L98 и иже с ними, вплоть до \ и /) закончатся, мы сможем, собственно, начать решать первый массив в сумасшедшей прогрессии массивов.
Кстати, для 340 больших чисел Бауэрс ввел собственные наименования, многие из которых по своей безумности полностью соответствуют алгоритмам расчета. Встречайте, МЕАМЕАМЕАЛОККАПУВА УМПА: {{L100,10}10,10 & L,10}10,10.
Примечание для нердов:
Разумеется, Бауэрс определил строгий набор правил совершения операций над массивами.
Определения:
— первый запись в массиве называется «базой» (base) — b;
— вторая запись в массиве называется «начальной» (prime) — p;
— первая неединичная запись после начальной называется «пилотом» («pilot»);
— запись массива, которая следует сразу за пилотом называется «вторым пилотом». Она не существует, если пилот является первой записью в своем ряду;
— структура — это часть массива, которая состоит из групп меньшей размерности. Это может быть запись (Х0), ряд (Х1), плоскость (Х2), область (Х3) и т.д., не говоря уже о структурах большей размерности (Х5, Х6 и т.д.) и тетрационных структурах, например, X^^3. Можно также продолжить пентационными, гексационными и т.п. структурами.
— «предыдущей записью» (previous entry) называется запись, которая образуется перед пилотом, но в том же ряду, что и остальные предыдущие записи. «Предыдущим рядом» называется ряд, который появляется перед пилотным рядом, но в той же плоскости, что и все остальные предыдущие ряды и т.д.
— «начальный блок» (prime block) структуры S вычисляется заменой всех вхождений Х на p. Например, если S = Х3, то начальным блоком будет p3 или куб со стороной длины p. Начальным блоком Хх-структуры будет pp, p-гиперкуб с длиной стороны p.
— «самолёт» включает в себя пилота, все предыдущие записи, а также начальный блок всех предыдущих структур;
— «пассажиры» — это записи в самолете, которые не являются пилотом или вторым пилотом;
— значение массива записывается как v(A), где А — это массив.
Правила вычисления:
1. Если p = 1, v(A) = b
2. Если нет пилота, то v(A) = bp
3. Если первое и второе не применяется, то:
— пилот уменьшается на 1;
— второй пилот принимает значение оригинального массива с начальным значением, уменьшенным на 1;
— каждый пассажир становится b;
— остальная часть массива не изменяется
Все примеры, описанные выше, подчиняются этим незатейливым правилам.
Как уже говорилось выше, BEAF по своей мощи значительно превосходит цепочки Конвея, не говоря уже о нотации Кнута… Интересно, что дальше?
А дальше мы вступаем на поле скорее философии, нежели собственно математики. Все описанные выше нотации представляют собой вычислимые функции или функции, которые могут быть реализованы на машине Тьюринга.
Во второй части мы рассмотрим невычислимые функции: задачу усердных бобров, сигма-функцию Радо ?(n), число Райо, BIG FOOT и другие, а также рассмотрим быстрорастущую иерархию, чтобы понять, есть ли предел этому математическому безумию.
Использованные материалы:
1. Главный сайт по гугологии: http://googology.wikia.com/wiki/Googology_Wiki
2. Бесконечноскрёбы Джонатана Бауэрса
3. Exploding Array Function
Комментарии (34)


Zagrebelion
22.01.2016 11:20+3У числа Грэма есть смысл — верхняя граница решения какой-то там задачи про куб.
А в чём смысл этой МЕАМЕАМЕАЛОККАПУВАУМПы?
Kamalesh
22.01.2016 12:19А в чём смысл этой МЕАМЕАМЕАЛОККАПУВАУМПы?
Практического смысла — никакого. По большому счету вся гугология — это развлечение математиков на тему: «Кто придумает наиболее быстрорастущую функцию». Ну а если ты что-то крутое придумал — надо это обозвать.
PavelSandovin
22.01.2016 15:17Это сейчас — никакого. Появится задача, где такие числа всплывут — а аппарат для них уже готов.
olekl
22.01.2016 12:39Жду вторую часть!
Kamalesh
22.01.2016 12:46+1Будет! Она мне чуть сложнее дается в плане перевода, потому что используется специальная математическая терминология — раз, а зачастую — собственные изобретения математиков, для которых в принципе нет устоявшегося перевода — два. И три — надо еще отличить одно от другого…

Zardos
22.01.2016 13:28+1По поводу самой быстро-растущей функции. Почему бы вместо троек, десяток (в записях вроде "{3,3,3 / 3}" и "{{L100,10}10,10 & L,10}10,10") не брать самые большие числа, полученные на предыдущем шаге, обозначенные новыми символами?
Например, на первом шаге взяли произвольное достаточно большое число и дали определение оператору, которое позволяет с ним сделать что-то еще большее. На втором шаге берем полученное на первом в качестве операнда и придумываем новый оператор, позволяющий вырастить это число еще больше. Чтоб символы и скобочки не исчерпывались фантазией, пусть это будут какие-нибудь N1, N2,… — для создания новых символов для чисел и O1, O2,… — для создания новых символов для операторов.Kamalesh
23.01.2016 06:19… и получаем обычные рекурсивные функции. Ограничения которых упираются в длину используемого «алфавита». Поэтому математики придумали гораздо более быстрорастущие функции. Про это и будет вторая часть.
Zardos
23.01.2016 19:55-2а так я и говорю, что ограничение в виде длины алфавита легко обходится, если использовать один символ и числовые индексы для создания неограниченного числа символов. А также однажды выбранную скобочку со своими индексами, чтоб не привязываться к ограничению на рисунок новх скобочек. Операторы на каждом этапе новые, максимально растущие по сравнению с предыдущими шагами — так что это не рекурсия.
Kamalesh
23.01.2016 07:29Ну и, кстати, на «соревнованиях» по придумыванию самых больших чисел условие ставится, как правило такое — получить самое большое число, которое может быть записано не более чем N знаками.

KvanTTT
23.01.2016 14:26По поводу записи вспомнились порядковые числа, как способ пересчета бесконечностей:

Zenitchik
22.01.2016 16:21Сбился на цепочках Конвея.
Можете подробнее объяснить, как от четырёхстрелочной операции перейти к рекурсивным трёхстрелочным?Kamalesh
23.01.2016 07:26+1Общий механизм расчета цепочек Конвея таков (рассмотрим на примере цепочки из поста):
1. Одна стрелка — это возведение в степень (p > q = pq).
2. Единица после стрелки убирает остальную часть цепочки: (X > p > 1 = X > p, так же X > 1 > p = X, где в общем случае X — любая подцепочка).
3. Раскрытие цепочек производится с конца по следующей формуле: X > p > q = X > (X > (p-1) > q) > (q-1).
На примере из поста:
3 > 3 > 2 > 2, здесь X = 3 > 3, p = 2, q = 2, раскрываем цепочку по формуле:
3 > 3 > 2 > 2 = 3 > 3 > ( 3 > 3 > (2-1) > 2) > (2-1)
Части цепочек после единиц отсекаем: 3 > 3 > (3 > 3)
Поскольку 3 > 3 = 33 = 27, то получаем цепочку с 3 элементами: 3 > 3 > 27

grokinn
22.01.2016 17:44Интересно конечно ли число способов компактной записи чисел? Если оно конечно, то существует число, которое можно компактно записать только лишь использовав все частицы вселенной, следовательно это будет самое большие число, которое только можно сформулировать. Или такого числа не существует?
Zenitchik
22.01.2016 18:23Видите ли, в чём дело… Каждый из указанных способов записи позволяет компактно описывать только определённый класс чисел. Числа ±1 — уже недоступны этому методу, придётся городить выражение.
Не вижу причины, почему было бы невозможно разработать форму записи, пригодную для компактной записи класса чисел, содержащего заданное сколь угодно большое число.

nickolaym
22.01.2016 18:31Пусть у нас есть какая-то супер-пупер-нотация, неважно, как интерпретируемая.
Но смысл этой нотации — отображать строку текста (допустимую для языка нотации, разумеется) на конечное число.
Если у нас есть алфавит мощностью L и мы ограничены длиной строк N (оба значения, естественно, не превосходят количество частиц во вселенной), то получаем множество строк мощностью LN. Самое главное, что это множество конечное.
А теперь, внимание, фокус! Если каждой строке соответствует некоторое конечное число, то для конечного множества этих всех чисел мы можем найти максимум. И этот максимум тоже будет конечным.nickolaym
22.01.2016 18:44+1Хитрость здесь в том, что мы вынесли за скобки описание нотации.
Если на неё мы тратим 0 символов (передаём её устно), — то мы всегда можем для любого наперёд заданного числа сказать, что «X» означает это число, «Y» означает X+1, а другие числа нас вообще не интересуют. У кого есть запасная вселенная, сможет на досуге родить десятичную запись числа Y.
Если же нам нужно рядом с компактной записью числа разместить компактную запись нотации (т.е. алгоритма вычисления — или порождения десятичной записи), то всё становится интереснее!
И тут мы упрёмся в проблему остановки.
Например, вот такая запись:
алгоритм: «прочитать десятичное значение n, выдать n-ное исключение из последовательности Коллаца (т.е. число, которое не сведётся к 1)»
даже для n=1 неизвестно, будет ли найдено такое число…
Mixim333
23.01.2016 11:51+3Как-то в студенческие годы решил посмотреть, какой максимум имеет тип BigInteger(https://msdn.microsoft.com/ru-ru/library/system.numerics.biginteger%28v=vs.110%29.aspx) в C#: на своем домашнем ПК с Core i7 и 16Гб оперативной памяти я написал маленькую программу: инициализация двух чисел типа BigInteger значением в районе миллиарда и их перемножения (b=b*a) в цикле while true — прошел примерно час, приложение сожрало около 2Гб оперативки, но так и продолжало работать, хотя скорость сократилась на порядок. Я плюнул, действительно поверил, что BigInteger «Представляет произвольно большое целое число со знаком» и больше таких экспериментов не проводил. Да, кстати, вычисления выполнялись не в Windows под .NET Framework, а в Linux под Mono.
mayorovp
23.01.2016 17:13Вместо эксперимента можно было бы посмотреть его внутреннюю структуру. Это же массив целых чисел (разрядов) произвольного размера. А один массив на C# может хоть всю доступную память сожрать, независимо от количества доступной памяти.
ls1
Если я правильно понял, float point (IEEE 754) в современных компьютерах это по сути реализация первой стрелочки Кнута. Интересно, следует ли ждать расширение формата хотя бы до второй стрелочки (на аппаратном уровне)?
gbg
Числа с плавающим разделителем — уж точно одной только степенью не выражаются. Так как это A*2^X, а также хитрые соглашения о +0, -0, NaN и Inf
Практической потребности в реализации чего-то большего, чем long double (80 бит с плавающей точкой) на данный момент нет — для инженерных задач с лихвой хватает возможностей double, а то и float.
Практика показывает, что такие задачи поддаются перемасштабированию, что позволяет втолкать их в рамки double.
Главная трудность в хранении огромных чисел — их размер.
Если делать размер плавающим, нужно перетряхивать всю вычислительную архитектуру (процессор сам себе выделяет память под результат — ничего себе, новости)
Если делать размер фиксированным, получим пустую трату памяти, слишком неэкономично, даже при нынешних терабайтах оперативки на кластерах.
Так что GMP — наше все.
ls1
CodeRush
Ради школьников тратить §20M на RnD и $10M на отладку получившейся «аппаратной поддержки второй стрелки» никто не будет, извините. Пусть эти школьники спокойно пьют свое пиво.
ls1
Ok, в следущий раз буду ставить смайл и ссылку на анекдот, на который был намёк
mayorovp
Нет, не стоит. Арифметика с плавающей точкой построена на операциях переноса точки влево и вправо:
m x 2 ^ n = (2m) x 2 ^ (n-1) = (m/2) x 2 ^ (n+1)
Но для стрелочки второго порядка изменение показателя на 1 уже попросту не влезет в разрядную сетку:
2 ^^ (k+1) / 2 ^^ k = 2 ^ ( 2 ^^ k — 2 ^^ (k-1) )
Как следствие, при высоких k числа высших порядков будут просто поглощать числа низших порядков при попытках выполнения арифметических операций. Это так сильно упрощает все «алгоритмы» — что поддержка этих алгоритмов на уровне процессора становится просто ненужной.
mtivkov
Учитывая, что количество планковских объемов в наблюдаемой Вселенной — всего-то порядка 10^185 и просуществует Вселенная до испарения последних черных дыр порядка 10^144 хрононов, то для решения вопросов современной физики, и любых нематематических проблем, достаточно реализации в компьютерах вычислений по первой стрелке Кнута.
mammuthus
Или не просуществует.