
Напомним общую схему системы:
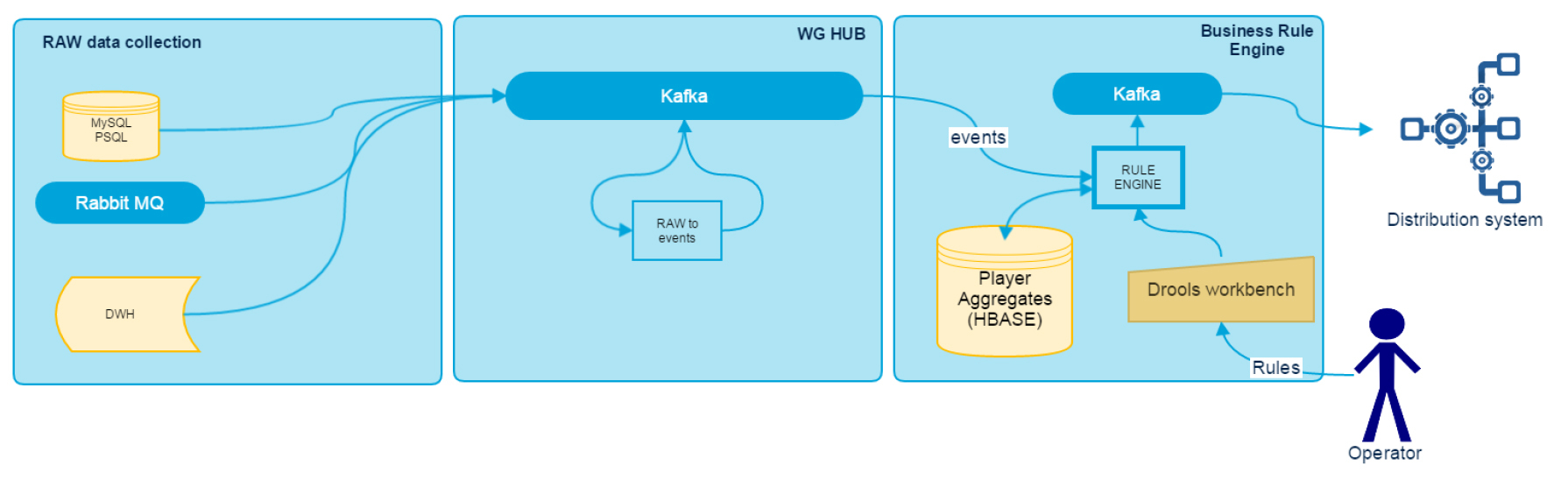
Блок RAW Data Collection описан в первой статье и представляет собой набор из standalone-адаптеров.
В основе следующих двух лежит параллельная потоковая обработка данных. В качестве фреймворка используется Spark Streaming. Почему именно он? Было решено, что стоит использовать единый дистрибутив Hadoop – Cloudera, который из коробки включает в себя Spark, HBase и Kafka. К тому же в компании на тот момент уже имелась экспертиза по Spark.
Raw Data Transformer
На вход подсистемы WG Hub мы получаем массу информации от различных источников данных, однако не вся она готова к прямому использованию и требует некоторой трансформации. Для преобразования сырых данных используется модуль RDT (Raw Data Transformer), в котором собрана вся бизнеc-логика по интеграции источников данных. На выходе мы получаем уже стандартизированное сообщение, которое представляет собой некоторое именованное событие с набором атрибутов. Оно записывается в Kafka в виде сериализованного Java-объекта. На входе RDT обрабатывает количество topic равное количеству источников данных, на выходе же получаем один topic с потоком различных событий, партиционированый по идентификатору игрока. Это гарантирует, что при последующей обработке данные конкретного игрока обрабатываются только одним executor, закреплённым за партицией (при использовании Spark Streaming directStream).
Главный недостаток этого модуля – необходимость правки кода и редеплоя в случае изменения структуры входных данных. Сейчас мы прорабатываем варианты использования в преобразованиях некоего метаязыка, чтобы сделать модуль более гибким и вносить изменения в логику без необходимости написания кода.
Rule Engine
Основной задачей этого модуля является предоставление конечному пользователю возможности создавать в системе правила, которые, реагируя на события в шине данных и имея у себя в распоряжении некоторые накопленные исторические данные об игроке, на основании заданной пользователем логики будут выдавать нотификации в конечную систему. Основу для Rule Engine выбирали достаточно долго, пока не остановились на Drools. Почему именно он:
- это Java, что подразумевает меньше проблем с интеграцией
- в комплекте есть не самое удобное, но всё же GUI для создания правил
- компонент KieScanner, позволяющий обновлять правила без рестарта приложения
- возможность использования Drools в виде библиотеки без необходимости устанавливать дополнительные сервисы
- достаточно большое сообщество
В качестве хранилища исторической информации по игроку используется HBase. NoSQL-хранилище тут отлично подходит, т. к. вся обработка ведётся по идентификатору игрока, а HBase хорошо справляется с балансировкой нагрузки и шардингом данных между регионами. Лучший отклик мы получаем, если почти все данные умещаются в blockCache.
Схематично работа BRE выглядит следующим образом:

Drools распространяет правила как собранный JAR-файл, поэтому на первом этапе мы установили локальный Maven и настроили проект в Workbench на деплой в репозиторий через секцию distributionManagement в pom.xml.
При старте Spark-приложения в каждом executor запускается отдельный процесс Drools KieScanner, который периодически проверяет в Maven артефакт с правилами. Версия для проверки артефакта установлена в LATEST, что позволяет в случае появления новых правил подгрузить их в текущий запущенный код.
При поступлении новых событий в Kafka, BRE принимает пачку в обработку и для каждого игрока из HBase вычитывает блок исторических данных. Далее события вместе с данными игрока передаются в Drools StatelessKieSession, где они проверяются на соответствие текущим загруженным правилам. В результате список сработавших правил записывается в Kafka. Именно на его основании формируются подсказки и предложения пользователю в игровом клиенте.
DDRRE: оптимизируем и совершенствуем
Сериализация исторических данных для хранения в HBase. На первых этапах реализации мы использовали Jackson JSON, в результате чего один и тот же POJO использовался в двух местах (в workbench при написании правил и в Jackson). Это очень сильно ограничивало нас в оптимизации формата хранения и заставляло использовать слишком сложные аннотации Jackson. Тогда мы решили отделить бизнес-описание объекта от объекта хранения. В качестве последнего используется класс, сгенерированный по protobuf-схеме. В результате POJO, используемый в workbench, имеет человекочитаемую структуру, ясные наименования и является как бы «прокси» к protobuf-объекту.
Оптимизация запросов в HBase. Во время тестовой эксплуатации сервиса было замечено, что в силу специфики игры, в пачку обработки часто попадают несколько событий от одного и того же аккаунта. Так как обращение к HBase является самой ресурсоемкой операцией, мы решили предварительно группировать аккаунты в пачке по идентификатору и вычитывать исторические данные один раз на всю группу. Данная оптимизация позволила уменьшить запросы к HBase в 3-5 раз.
Оптимизации Data Locality. В нашем кластере машины совмещают в себе одновременно Kafka, HBase и Spark. Так как процесс обработки начинается с чтения Kafka, то и locality ведётся по лидеру читаемой партиции. Однако если рассмотреть весь процесс обработки, то становится ясно, что объем данных, читаемый из HBase, значительно превышает объем данных входящих событий. Следовательно, и пересылка этих данных по сети отнимает больше ресурсов. Для оптимизации процесса после чтения данных из Kafka мы добавили дополнительный shuffle, который перегруппировывает данные по HBase region и по нему же выставляет locality. В результате мы получили значительное сокращение сетевого трафика, а также выигрыш в производительности, за счёт того что каждый отдельный Spark task обращается лишь к одному конкретному HBase region, а не ко всем, как было ранее.
Оптимизация ресурсов, используемых Spark. В борьбе за время обработки мы также уменьшили spark.locality.wait, так как при большем количестве обрабатываемых партиций и меньшем количестве executor, ожидание locality было намного больше, чем время обработки.
В текущей версии модуль справляется с поставленным задачами, однако места для оптимизации ещё много.
В планах по расширению DDRRE создание Rule as a service – специальной системы, при помощи которой станет возможно вызывать срабатывание правил не за счет внутриигрового события, а по запросу от внешнего сервиса через API. Это позволит отвечать на запросы вида: «Какой рейтинг у данного игрока?», «К какому сегменту относится?», «Какой товар для него лучше подходит?» и т. п.
Комментарии (6)

aml
22.01.2016 20:44А порядок обработки сообщений из очереди роли не играет? Сколько вокеров разгребают сообщения из очереди? Что будет, если несколько воркеров выгребут события, относящиеся к одному пользователю, и будут их одновременно молотить? Как запись синхронизируется?

mephius
22.01.2016 21:28+1События одного пользователя гарантированно попадают в один и тот же партишн кафки, соотвественно никак не могут одновременно обрабатываться разными воркерами.

igor_suhorukov
25.01.2016 00:11Основа drools — язык mvel достаточно ограниченый в возможностях и сложный в отладке. Как вы решили проблему с отладкой правил?

Wargaming
28.01.2016 16:17Отладка правил происходит после их введения в препродакшене, уже на реальных данных. Валидность оценивается по откликам, срабатыванию и т. п. Поэтому в нашем случае главное четко понимать какова цель введения того или иного правила.
Melz
Вам бы систему, которая запрещает выкатывать патчи (с багами) 30 декабря, но это так, к слову ;)
Собственно вопрос по вашему примеру из прошлой статьи
> Свои первые 100 боев он с мучениями и проблемами отыграл на ПТ САУ. Процент побед низкий, удовольствия от игры мало.
> В такой ситуации мы предлагаем ему несколько обучающих материалов,
> которые помогут ознакомиться с стратегией ведения боя на ПТ САУ.
Каким образом вы будете нивелировать влияние других систем ВГ на принятие решений? В частности, как будет вести себя система, если окажется что игрока в такую ситуацию поставил матчмейкер? Дедлока не будет?
У вас же нет ММ по скиллу, а рейтинги так себе работают при меленьком количестве информации. А ММ будет «тянуть» игрока к 50%.
Wargaming
Мы оцениваем влияние нашего взаимодействия исходя из разницы поведения однородных групп игроков. Для каждого офера мы выбираем целевые и контрольные группы пользователей. С одними взаимодействуем, с другими – нет. Отличия в их поведении и есть влияние наших коммуникаций.
Также нужно понимать, что для каждой отдельной коммуникации алгоритм оценки отличается.