
Пара часов из жизни математика-программиста или читаем википедию
Для начала в качестве эпиграфа цитирую rocknrollnerd:
— Здравствуйте, меня зовут %username%, и втайне раскрываю суммы из сигма-нотации на листочке, чтобы понять, что там происходит.
— Привет, %username%!
Итак, как я и говорил в своей прошлой статье, у меня есть студенты, которые панически боятся математики, но в качестве хобби ковыряются паяльником и сейчас хотят собрать тележку-сигвей. Собрать-то собрали, а вот держать равновесие она не хочет. Они думали использовать ПИД-регулятор, да вот только не сумели подобрать коэффициенты, чтобы оно хорошо работало. Пришли ко мне за советом. А я ни бум-бум вообще в теории управления, никогда и близко не подходил. Но зато когда-то на хабре я видел статью, которая говорила про то, что линейно-квадратичный регулятор помог автору, а пид не помог.
Если ПИД я ещё себе худо-бедно на пальцах представляю (вот моя статья, которую с какого-то перепугу перенесли на гиктаймс), то про другие способы управления я даже и не слышал толком. Итак, моя задача — это представить себе (и объяснить студентам, а заодно и вам), что такое линейно-квадратичный регулятор. Пока что работы с железом не будет, я просто покажу, как я работаю с литературой, ведь именно это и составляет львиную долю моей работы.
Раз уж пошёл эксгибиционизм про мою работу, то вот вам моё рабочее место (кликабельно):


Используемые источники
Итак, первое, что я делаю, иду в википедию. Русская википедия жестока и беспощадна, поэтому читаем только английский текст. Он тоже отвратителен, но всё же не настолько. Итак, читаем. Из всех вводных кирпичей текста только одна фраза меня заинтересовала:
The theory of optimal control is concerned with operating a dynamic system at minimum cost. The case where the system dynamics are described by a set of linear differential equations and the cost is described by a quadratic function is called the LQ problem.
В переводе на русский они говорят, что моделируют некую динамическую систему дифференциальными уравнениями (о ужас), и выбирают непосредственно управление, минимизируя какую-то квадратичную функцию (о! я чувствую приближение наименьших квадратов). Так, хорошо. Пытаемся читать дальше:
Finite-horizon, continuous-time LQR,
[серия ужасных формул]
Пропускаем, ну его в болото такое читать, кроме того, явно будет противно руками считать непрерывные функции.
Infinite-horizon, continuous-time LQR,
[серия ещё более ужасных формул]
Час от часу не легче, ещё и несобственные интегралы пошли, пропускаем, вдруг дальше что интересного найдём.
Finite-horizon, discrete-time LQR
О, это я люблю. У нас дискретная система, смотрим её состояние через некие промежутки (некие промежутки в первом прочтении всегда равны одной секунде) времени. Производные из уравнения ушли, т.к. они теперь могут быть приближены как (x_{k+1}-x_{l})/1 секунду. Теперь неплохо было бы понять, что такое x_k.
Одномерный пример
Фейнман писал, как именно он читал все уравнения, что ему приходилось:
Actually, there was a certain amount of genuine quality to my guesses. I had a scheme, which I still use today when somebody is explaining
something that I'm trying to understand: I keep making up examples. For instance, the mathematicians would come in with a terrific theorem, and they're all excited. As they're telling me the conditions of the theorem, I construct something which fits all the conditions. You know, you have a set (one ball) — disjoint (two balls). Then the balls turn colors, grow hairs, or whatever, in my head as they put more conditions on. Finally they state the theorem, which is some dumb thing about the ball which isn't true for my hairy green ball thing, so I say, «False!»
Ну а мы что, круче Фейнмана? Лично я нет. Поэтому давайте так. Имеется автомобиль, едущий с некой начальной скоростью. Задача его разогнать до некой финальной скорости, при этом единственное, на что мы можем влиять, это на педаль газа, сиречь на ускорение автомобиля.
Давайте представим, автомобиль идеален и движется по такому закону:

x_k — это скорость автомобиля в секунду k, u_k — это положение педали газа, которое мы захотим, можно её интерпретировать как ускорение в секунду k. Итого, мы стартуем с некой скорости x_0, и затем проводим вот такое численное интегрирование (во какие слова пошли). Отметьте, что я не складываю м/с и м/с^2, u_k умножается на одну секунду интервала между измерениями. По умолчанию у меня все коэффициенты либо ноль, либо один.
Итак, чтобы понять, что происходит, я пишу вот такой код (я пишу очень много одноразового кода, который выкидываю сразу после написания). Привожу листинг здесь на всякий случай, как обычно, я использую OpenNL для решения больших разреженных линейных систем уравнений.
#include <iostream>
#include "OpenNL_psm.h"
int main() {
const int N = 60;
const double xN = 2.3;
const double x0 = .5;
const double hard_penalty = 100.;
nlNewContext();
nlSolverParameteri(NL_NB_VARIABLES, N*2);
nlSolverParameteri(NL_LEAST_SQUARES, NL_TRUE);
nlBegin(NL_SYSTEM);
nlBegin(NL_MATRIX);
nlBegin(NL_ROW); // x0 = x0
nlCoefficient(0, 1);
nlRightHandSide(x0);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
nlBegin(NL_ROW); // xN = xN
nlCoefficient((N-1)*2, 1);
nlRightHandSide(xN);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
nlBegin(NL_ROW); // uN = 0, for convenience, normally uN is not defined
nlCoefficient((N-1)*2+1, 1);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
for (int i=0; i<N-1; i++) {
nlBegin(NL_ROW); // x{i+1} = xi + ui
nlCoefficient((i+1)*2 , -1);
nlCoefficient((i )*2 , 1);
nlCoefficient((i )*2+1, 1);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
}
for (int i=0; i<N; i++) {
nlBegin(NL_ROW); // xi = xN, soft
nlCoefficient(i*2, 1);
nlRightHandSide(xN);
nlEnd(NL_ROW);
}
nlEnd(NL_MATRIX);
nlEnd(NL_SYSTEM);
nlSolve();
for (int i=0; i<N; i++) {
std::cout << nlGetVariable(i*2) << " " << nlGetVariable(i*2+1) << std::endl;
}
nlDeleteContext(nlGetCurrent());
return 0;
}
Итак, давайте разбираться, что я делаю. Для начала я говорю N=60, на всё отвожу 60 секунд. Затем говорю, что финальная скорость должна быть 2.3 метра в секунду, а начальная полметра в секунду, это выставлено от балды. Переменных у меня будет 60*2 — 60 значений скорости и 60 значений ускорения (строго говоря, ускорения должно быть 59, но мне проще сказать, что их 60, а последнее должно быть равно строго нулю).
Итого, у меня 2*N переменных (N=60), чётные переменные (я начинаю считать с нуля, как и всякий нормальный программист) — это скорость, а нечётные — это ускорение. Задаю начальную и конечную скорость вот этими строчками:
По факту, я сказал, что хочу, чтобы начальная скорость была равна x0 (.5m/s), а конечная — xN (2.3m/s).
nlBegin(NL_ROW); // x0 = x0
nlCoefficient(0, 1);
nlRightHandSide(x0);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
nlBegin(NL_ROW); // xN = xN
nlCoefficient((N-1)*2, 1);
nlRightHandSide(xN);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
Мы знаем, что x{i+1} = xi + ui, поэтому давайте добавим N-1 такое уравнение в нашу систему:
for (int i=0; i<N-1; i++) {
nlBegin(NL_ROW); // x{i+1} = xi + ui
nlCoefficient((i+1)*2 , -1);
nlCoefficient((i )*2 , 1);
nlCoefficient((i )*2+1, 1);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
}
Итак, мы добавили всё жёсткие ограничения в систему, а что именно, собственно, мы можем хотеть оптимизировать? Давайте просто для начала скажем, что мы хотим, чтобы x_i как можно скорее достиг финальной скорости xN:
for (int i=0; i<N; i++) {
nlBegin(NL_ROW); // xi = xN, soft
nlCoefficient(i*2, 1);
nlRightHandSide(xN);
nlEnd(NL_ROW);
}
Ну вот наша система готова, жёсткие правила перехода между состояниями заданы, квадратичная функция качества системы тоже, давайте потрясём коробочку и посмотрим, что наименьшие квадраты нам дадут в качестве решения x_i, u_i (красная линия — это скорость, зелёная — ускорение):
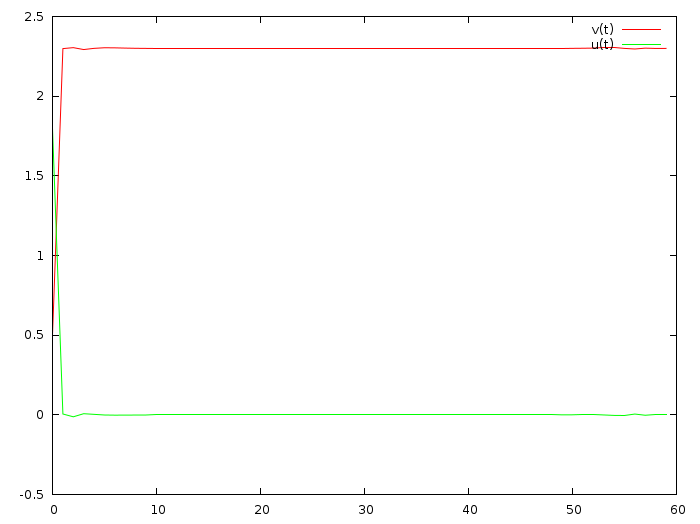
Ооокей, мы действительно ускорились с полуметра в секунду до двух метров запятая трёх в секунду, но уж больно большое ускорение наша система выдала (что логично, т.к. мы потребовали сойтись как можно скорее).
А давайте изменим (вот коммит) целевую функцию, вместо наискорейшей сходимости попросим как можно меньшее ускорение:
for (int i=0; i<N; i++) {
nlBegin(NL_ROW); // ui = 0, soft
nlCoefficient(i*2+1, 1);
nlEnd(NL_ROW);
}
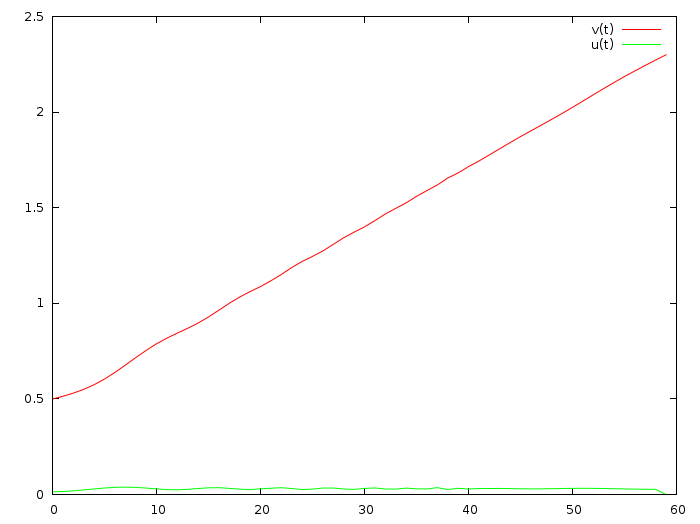
Мда, теперь машина ускоряется на два метра в секунду за целую минуту. Ок, давайте и быструю сходимость к финальной скорости, и маленькое ускорение попробуем (вот коммит)?
for (int i=0; i<N; i++) {
nlBegin(NL_ROW); // ui = 0, soft
nlCoefficient(i*2+1, 1);
nlEnd(NL_ROW);
nlBegin(NL_ROW); // xi = xN, soft
nlCoefficient(i*2, 1);
nlRightHandSide(xN);
nlEnd(NL_ROW);
}
Ага, супер, теперь становится красиво:
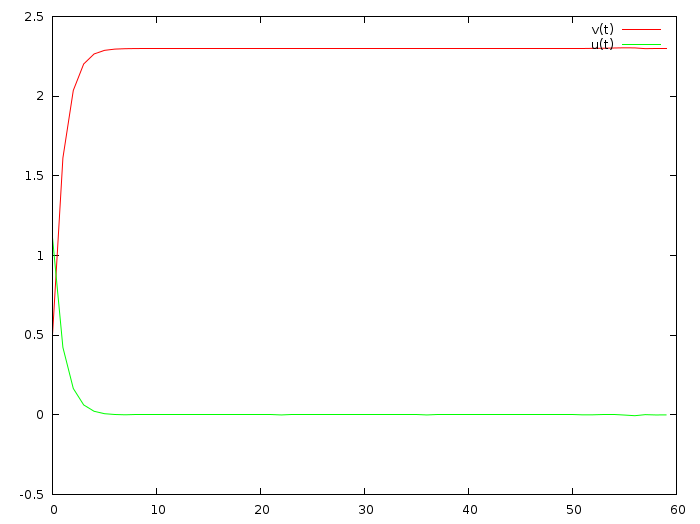
Итак, быстрая сходимость и ограничение величины управления — это конкурирующие цели, понятно. Обратите внимание, на данный момент я остановился на первой строчке параграфа википедии, дальше идут страшные формулы, я их не понимаю. Зачастую чтение статей сводится к поиску ключевых слов и полному выводу всех результатов, используя тот матаппарат, которым лично я владею.
Итак, что мы имеем на данный момент? То, что имея начальное состояние системы + имея конечное состояние системы + количество секунд, мы можем найти идеальное управление u_i. Это хорошо, только к сигвею слабо применимо. Чёрт, как же они делают-то? Так, читаем следующий текст в википедии:
with a performance index defined as
the optimal control sequence minimizing the performance index is given by
where [ААА, ЧТО ТАМ ДАЛЬШЕ ТАКОЕ?!]

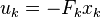
Так. Я не понимаю что после знака равно в формуле «J = ...», но это явно квадратичная функция, что мы попробовали. Типа, скорейшей сходимости к цели плюс наименьшими затратами, это мы позже посмотрим ближе, сейчас мне достаточно моего понимания.
u_k = -F x_k. Оп-па. Они говорят, что для нашего одномерного примера в любой момент времени оптимальное ускорение — это некая константа -F, помноженная на текущую скорость? Ну-ка, ну-ка. А ведь и правда, зелёный и красный графики подозрительно друг на друга похожи!
Давайте-ка попробуем написать настоящие уравнения для нашего 1D примера.
Итак, у нас есть функция качества управления:
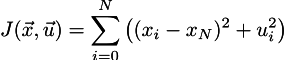
Мы хотим её минимизировать, при этом соблюдая ограничения на связь между соседними значениями скорости нашей машины:
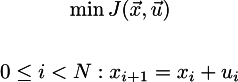
Стоп-стоп-стоп, а какого хрена в википедии стоит x_k^T Q x_k? Ведь это же простой x_k^2 в нашем случае, а у нас (x_k-x_N)^2?! Ёлки, да ведь они предполагают, что финальное состояние, в которое мы хотим попасть, это нулевой вектор!!! КАКОГО [CENSORED] ОБ ЭТОМ НА ВСЕЙ СТРАНИЦЕ ВИКИПЕДИИ НИ СЛОВА?!
Окей, дышим глубоко, успокаиваемся. Теперь я все x_i в формулировке J выражу через u_i, чтобы не иметь ограничений. Теперь у меня переменными будет являться только вектор управления. Итак, мы хотим минимизировать функцию J, которая записывается вот так:
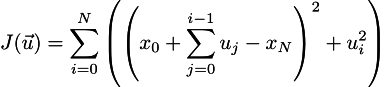
Зашибись. А теперь давайте раскрывать скобки (см. эпиграф):
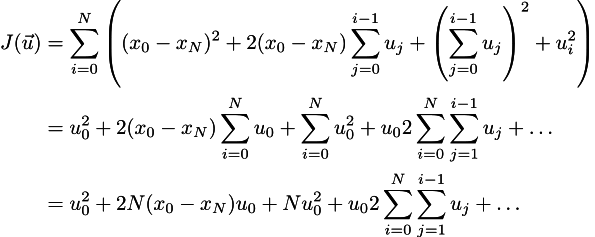
Многоточие здесь означает всякую муть, которая от u_0 не зависит. Так как мы ищем минимум, то чтобы его найти, нужно приравнять нулю все частные производные, но для начала меня интересует частная производная по u_0:
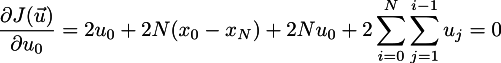
Итого мы получаем, что оптимальное управление будет оптимально только тогда, когда u_0 имеет вот такое выражение:
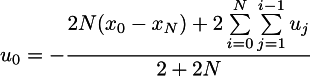
Обратите внимание, что в это выражение входят и другие неизвестные u_i, но есть одно «но». Прикол в том, что я не хочу, чтобы машина ускорялась всю минуту на всего два метра в секунду. Минуту я ей дал просто как заведомо достаточное время. А могу и час дать. Член, зависящий от u_i, если грубо, то это вся работа по ускорению, от N она не зависит. Поэтому если N достаточно большой, то оптимальный u_0 линейно зависит только от того, насколько x0 далёк от конечного положения!
То есть, управление должно выглядеть следующим образом: мы моделируем систему, находим магический коэффициент, линейно связывающий u_i и x_i, записываем его, а затем в нашем роботе просто делаем линейный пропорциональный регулятор, используя найденный магический коэффициент!
Если быть предельно честным, то до вот этого момента я кода, конечно, не писал, всё вышеозначенное я проделал в уме и чуть-чуть на бумажке. Но это не отменяет факта, что одноразового кода я пишу действительно много.
2D пример
В качестве интуиции это прекрасно, а вот первый код, который я действительно написал:
#include <iostream>
#include <vector>
#include "OpenNL_psm.h"
int main() {
const int N = 60;
const double x0 = 3.1;
const double v0 = .5;
const double hard_penalty = 100.;
const double rho = 16.;
nlNewContext();
nlSolverParameteri(NL_NB_VARIABLES, N*3);
nlSolverParameteri(NL_LEAST_SQUARES, NL_TRUE);
nlBegin(NL_SYSTEM);
nlBegin(NL_MATRIX);
nlBegin(NL_ROW);
nlCoefficient(0, 1); // x0 = 3.1
nlRightHandSide(x0);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
nlBegin(NL_ROW);
nlCoefficient(1, 1); // v0 = .5
nlRightHandSide(v0);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
nlBegin(NL_ROW);
nlCoefficient((N-1)*3, 1); // xN = 0
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
nlBegin(NL_ROW);
nlCoefficient((N-1)*3+1, 1); // vN = 0
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
nlBegin(NL_ROW); // uN = 0, for convenience, normally uN is not defined
nlCoefficient((N-1)*3+2, 1);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
for (int i=0; i<N-1; i++) {
nlBegin(NL_ROW); // x{N+1} = xN + vN
nlCoefficient((i+1)*3 , -1);
nlCoefficient((i )*3 , 1);
nlCoefficient((i )*3+1, 1);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
nlBegin(NL_ROW); // v{N+1} = vN + uN
nlCoefficient((i+1)*3+1, -1);
nlCoefficient((i )*3+1, 1);
nlCoefficient((i )*3+2, 1);
nlScaleRow(hard_penalty);
nlEnd(NL_ROW);
}
for (int i=0; i<N; i++) {
nlBegin(NL_ROW); // xi = 0, soft
nlCoefficient(i*3, 1);
nlEnd(NL_ROW);
nlBegin(NL_ROW); // vi = 0, soft
nlCoefficient(i*3+1, 1);
nlEnd(NL_ROW);
nlBegin(NL_ROW); // ui = 0, soft
nlCoefficient(i*3+2, 1);
nlScaleRow(rho);
nlEnd(NL_ROW);
}
nlEnd(NL_MATRIX);
nlEnd(NL_SYSTEM);
nlSolve();
std::vector<double> solution;
for (int i=0; i<3*N; i++) {
solution.push_back(nlGetVariable(i));
}
nlDeleteContext(nlGetCurrent());
for (int i=0; i<N; i++) {
for (int j=0; j<3; j++) {
std::cout << solution[i*3+j] << " ";
}
std::cout << std::endl;
}
return 0;
}
Здесь всё то же самое, только переменных системы теперь две: не только скорость, но и координата машины.
Итак, дана начальная позиция + начальная скорость (x0, v0), мне нужно достичь конечной позиции (0,0), остановиться в начале координат.
Переход из одного момента в следующий осуществляется как x_{k+1} = x_k + v_k, а v_{k+1} = v_k + u_k.
Я достаточно прокомментировал предыдущий код, этот не должен вызвать трудностей. Вот результат работы:
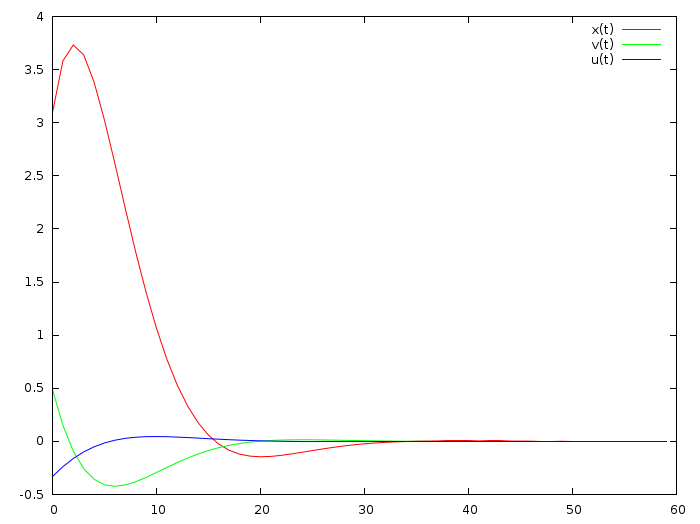
Красная линия — координата, зелёная — скорость, а синяя — это непосредственно положение «педали газа». Исходя из предыдущего, предполагается, что синяя кривая — это взвешенная сумма красной и зелёной. Хм, так ли это? Давайте попробуем посчитать!
То есть, теоретически, нам нужно найти два числа a и b, такие, что u_i = a*x_i + b*v_i. А это есть не что иное, как линейная регрессия, что мы делали в прошлой статье! Вот код.
В нём я сначала считаю кривые, что на картинке выше, а затем ищу такие a и b, что синяя кривая = a*красная + b*зелёная.
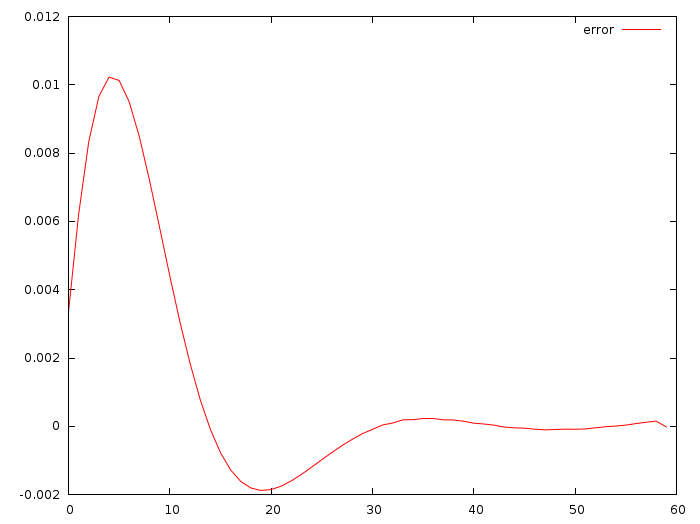
Вот разница между настоящими u_i и теми, что я получил, складывая зелёную и красную прямую:
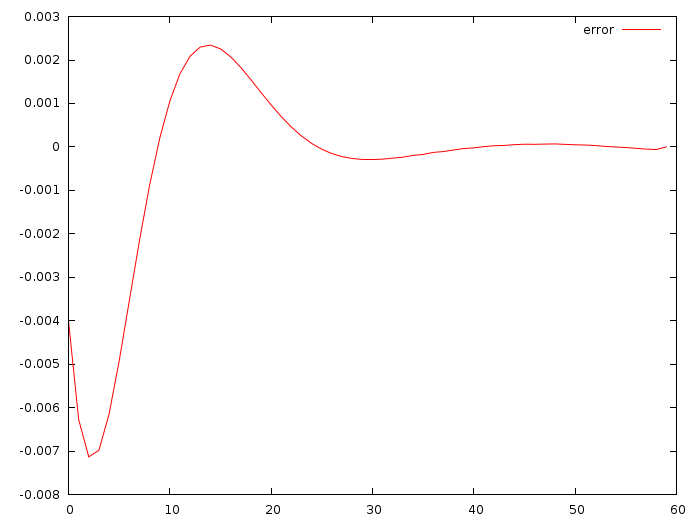
Отклонение порядка одной сотой метра за секунду за секунду! Круто!!! Тот коммит, что я привёл, даёт a=-0.0513868, b=-0.347324. Отклонение действительно небольшое, но ведь это нормально, начальные данные-то я не менял.
А теперь давайте кардинально изменим начальное положение и скорость машины, оставив магические числа a и b из предыдущих вычислений.
Вот разница между настоящим оптимальным решением и тем, что мы получаем наитупейшей процедурой, давайте-ка я её ещё раз приведу полностью:
double xi = x0;
double vi = v0;
for (int i=0; i<N; i++) {
double ui = xi*a + vi*b;
xi = xi + vi;
vi = vi + ui;
std::cout << (ui-solution[i*3+2]) << std::endl;
}
И никаких дифференциальных уравнений Риккати, которые нам предлагала википедия. Возможно, что и про них мне придётся почитать, но это будет потом, когда припечёт. А пока что простые квадратичные функции меня устраивают более чем полностью.
Сухой остаток
Итого: чтобы это использовать, будут две основных трудности:
а) найти хорошие матрицы перехода A и B, это нужно будет записывать кинематические уравнения, так как, конечно, там всё будет зависеть от масс объектов и прочего
б) найти хорошие коэффициенты компромисса между целями наискорейшего схождения к цели, но при этом ещё и не делая сверхусилий.
Если а и б сделать, то метод выглядит многообещающим. Единственное, что он требует полного знания состояния системы, что не всегда получается. Например, положение сигвея мы не знаем, можем только догадываться о нём, исходя из данных датчиков типа гироскопа и акселерометра. Ну да это про это я расскажу своим студентам в следующий раз.
Итак, я хотел добиться трёх целей:
а) понять, что такое lqr
б) объяснить то, что понял, студентам и вам
в) показать вам и моим студентам, что я (как и большинство людей) ни хрена не понимаю в математических текстах, что печально, но совсем не катастрофично. Ищем ключевые слова, за которые зацепиться, выкидываем излишние, ненужные нам методы и абстракции, и пытаемся это впихнуть в рамки наших текущих знаний.
Надеюсь, мне удалось. Ещё раз, я совсем не специалист в теории управления, я её в глаза не видел, если у вас есть что дополнить и поправить, не стесняйтесь.
Enjoy!
Комментарии (82)
ProLimit
21.02.2016 21:42+2Долго вникал в LQR но нифига не понял, чем он лучше PID контроллера, если критерий оптимальности все равно с потолка берется. Что такое minimum cost? А если мы от розетки питаемся и электричества не жалко, а нужен наилучший результат следования цели, то этот метод бесполезен?
Ещё интересно, применим ли он если полного знания о динамике системы нет? Например, на сигвей стал малыш 15кг или дядя в 120кг. Динамика же меняется в разы.
haqreu
21.02.2016 23:43Я не специалист, подождем других комментариев, но насколько я понимаю, то критерий оптимальности не берется с потолка, это желание получить максимально быструю сходимость, но не выходя за физические ограничения управления. Грубо говоря, мы ставим только критерий скорости, и добавляем щепотку ограничений на контроль, покуда не впишется в рамки. То есть, оно серия ведет настолько хорошо, насколько мы написали физику. С пид все чуток противнее. Но использовать надо тот метод, который решает задачу.
С изменением массы я сильно подозреваю, что можно сделать адаптирующуюся модель...ProLimit
22.02.2016 01:11Физика это хорошо, только модель очень условно описывает реальный процесс, все тонкости железной реализации учесть сложно. А если динамика ещё и меняться может, то регулятору проще рассматривать процесс как черный ящик, а не строить контроллер только на аналитических моделях. Как я понял, LQR, описанный в википедии, строит контроллер именно аналитически, без сбора реальных данных и подстройки "по месту"?
Мне (как практически нулевому математику) PID контроллер интуитивно понятен и нравится с одной стороны простотой, с другой стороны большим объемом теоретических исследований и их практических применений, в том числе и по автонастройке под разные критерии. Но и познакомиться с другими алгоритмами тоже интересно, а вдруг они лучше PID?
У вас в итоге получился обычный PD контроллер, но как-то совсем с другой стороны :)
Адаптация контроллера в процессе работы, это на мой взгляд уже высшее исскуство математической магии :) Особенно адаптация под изменяющиеся условия без прерыани работы, т.е. без возможности провести специальные эксперименты по сбору доп. данныхhaqreu
22.02.2016 09:42Насколько я бегло посмотрел, то контроллеров люди настроили вагон и маленькую тележку, самотюнингующихся и нет. В каких-то применениях у кого-то работают лучше одни, у кого-то другие, особенно если применения разные :)
Тот ЛКР, что описан в википедии, это именно аналитическое решение, без реальных данных. Мы записали физику, потрясли коробочку, вот вам коэффициенты.
У вас в итоге получился обычный PD контроллер, но как-то совсем с другой стороны :)
Не PD, а просто P, если уж вы про это. И я даже про это прямо написал :)
Разница между P регулятором и этим LQR в том, что P регулятор (ещё раз, я говорю про беглое гугление, возможно, что где-то не так) не смешивает между собой разные компоненты вектора состояний.
Arastas
22.02.2016 11:47Это, на самом деле, вопрос терминологии, как договоримся обзываться. Формально, Ваша P составляющая по скорости является D составляющей по положению, так что можно сказать, что Ваш регулятор эквивалентен некоторому PD.
К вопросу о "смешивании". Если P-регулятор скалярный, то он действительно берет один сигнал (как правило, ошибку, рассогласование) и формирует управление как некоторый k умножить на сигнал. Если же P-регулятор векторный, то берется вектор сигналов и скалярно умножается на вектор коэффициентов, получается скалярное управление. И то и то может называться P-регулятором.
ProLimit
22.02.2016 12:55Ну у вас же 2 коэффициента a и b: один на расстояние — аналог Kp, другой при производной — аналог Kd:
u = Kpx + Kddx
Похоже что и в общем нелинейном случае если кол-во пременных состояния не более трех, управление сводится к PID, Если больше, то к одной из его каскадных версий или версии с 2-мя степенями свободы. И в этом случае LQR полезен тем что аналитически найдет коэффициенты под заданный критерий.Arastas
22.02.2016 13:18Не понял, почему же закон управления для произвольной нелинейной системы третьего порядка должен обязательно иметь форму pid? Там есть и другие варианты.
ProLimit
22.02.2016 13:48Из соображения что матрица F в выражении u_k = -Fx_k — константа, а x_k — вектор состоящий из x, dx, d2x в разных комбинациях. После перемножения и группировок получим все те же константы при x, dx, d2x что очень похоже на PID.
Но это только мое предположение, не судите строго :)Arastas
22.02.2016 13:56Формально, d2x уже не соответствует классическому скалярному PID. А в общем случае нелинейной системы нет оснований считать, что измеряемые состояния являются линейной комбинацией скоростей/ускорений.
Но это так, общие рассуждения, а на практике по различным оценкам порядка 90% используемых регуляторов — PID.
Arastas
22.02.2016 11:50LQR можно аналитически обобщить на произвольную размерность и на системы с несколькими входами и несколькими выходами.
Ни LQR ни классический PID не адаптивны, т.е. не подстраиваются под изменения параметров системы. Но могут быть достаточно робастны, т.е. сохранять работоспособность при изменении параметров.

Mrrl
22.02.2016 08:47Не очень понятно, каким образом уравнение uk = — Fk xk, где F зависит от времени (через уравнение Риккати) превратилось в uk = — F xk с постоянной матрицей F.
haqreu
22.02.2016 09:50Если вы про общий случай, то для начала нужно в целевой функции выразить x через u, используя дополнение Шура, а затем брать в руки динамическое программирование или его аналоги, и искать зависимость u_0 от x_0 и от u_i. А затем показать, что зависимость от u_i бесконечно мала при удаляющемся горизонте.
Я же это показал только на одномерном примере, получив такую зависимость через приравнивание к нулю частной производной по u_0:

Вот смотрите, мы даём всё больше и больше времени для стабилизации нашей системы (N -> бесконечность). Для приведения в конечное состояние у нас есть вполне себе конечная работа, которую нужно проделать, это и есть сумма наших u_i. Но делим-то мы эту работу на всё большее и большее время, в итоге она растворится в том, что от времени не зависит.Mrrl
22.02.2016 10:02Так тогда можно было сразу брать пункт про "бесконечный горизонт". Там и F от индекса не зависит, и явная формула для неё приведена.
haqreu
22.02.2016 10:06Да, зависимость от времени уходит только в бесконечном горизонте. Только интуицию трудно строить на бесконечностях. А если вы про явную формулу:
 , где
, где
 , а внутри
, а внутри
 ,
,
то она мне неинтересна. Она настолько страшная, что я сходу не понимаю, откуда она взялась, а верить на слово формулам я разучился уже давно.
То есть, я разобрался потом. Но её использовать в реальной жизни я всё равно не захочу. Мне линейной регрессии хватит за глаза, так как за всю жизнь мне придётся построить только пару регуляторов.
haqreu
22.02.2016 11:19Поясню на всякий случай про слепое использование формул. В формулах бывают опечатки; я сам не способен написать ни одной правильной формулы. Все формулы, что я пишу, неверные. То забыл единицу добавить, то знак потерял, то ещё что.
Но когда я начинаю их программировать, то я способен из неправильной формулы восстановить правильную, так как у меня за каждым значком стоит какой-то смысл. Например, совсем недавно у меня студент на экзамене в какой-то задачке получил отрицательную комнатную температуру. В кельвинах.
И ведь у него ничего не почесалось, потому что он, как прилежный ученик, применил какие-то формулы. А смысла в них не вложил, и поэтому проверить свой ответ не смог. Поэтому я стараюсь не использовать никакие уравнения/формулы, которые я хотя бы на интуитивном уровне не понимаю. Да, я не вывожу абсолютно все результаты, которые использую, но я стараюсь понять, откуда они пришли.Mrrl
22.02.2016 11:33+1В формулах бывают опечатки; я сам не способен написать ни одной правильной формулы.
Тогда понятно. Потому что у меня получилось, что в вашей формуле для u_0 (у которой в знаменателе 2+2N) вместо x_n должен быть x_0 (тем более, n никак не определяется), перед двойной суммой должна быть двойка, а внутренняя сумма (по j) должна идти не от 0, а от 1 (а то u_0 получается и слева, и справа). Впрочем, насколько я понял, у вас эта двойная сумма всё равно не вычисляется?haqreu
22.02.2016 11:37О, спасибо большое за поправки, дойду до компа, исправлю.
Внутренняя сумма от единицы, да, справа, конечно же, (x0-xN), а не (xn-xN). И двойку потерял тоже, да. На бумажке у меня правильно, а вот в латехе налажал.
haqreu
22.02.2016 11:48Поправил, если ваши браузеры закэшили картинки, то вот так должны выглядеть формулы:



Mrrl
22.02.2016 11:55И, кстати, чтобы "из неправильной формулы восстановить правильную, так как за каждым значком стоит какой-то смысл", нужен довольно высокий уровень понимания математики. Надо продраться через все эти формулы, понять, что за координатами есть формализм векторов, за ними матрицы и тензоры, являющиеся самостоятельными объектами, дальше не знаю, что — оно зависит от направления; сейчас я, например, предпочитаю думать в терминах инвариантов и законов сохранения. Но при необходимости могу вернуться и к формулам.
И можно ли объяснить интуитивный уровень тем, кто панически боится формул изначально — что-то сомневаюсь. "В геометрии нет царских путей", в математике в целом, вероятно, тоже.haqreu
22.02.2016 12:03Я не очень понимаю, что такое царский путь, но основное сообщение, которое я пытаюсь донести до своих студентов, это то, что никто не знает всей математики. Никто не знает всей физики. Ни истории и политики тоже. Нужно не бояться брать чужие утверждения и проецировать их на базу своих знаний. И зачастую за страшными математическими значками открываются вполне простые, понятные, интуитивные вещи.
Arastas
22.02.2016 11:58Ёлки, да ведь они предполагают, что финальное состояние, в которое мы хотим попасть, это нулевой вектор!!! КАКОГО [CENSORED] ОБ ЭТОМ НА ВСЕЙ СТРАНИЦЕ ВИКИПЕДИИ НИ СЛОВА?!
Видимо, это одно из тех общепринятых знаний, что зачем о нём писать, и так ведь все знают. :)
Для линейных систем, если явно не оговорено иного, всегда рассматривается задача перевода системы в нулевое положение равновесия. Потому что для линейных систем задача перевода из одного положения в другое эквивалентна задаче перевода из ненулевого начального состояния в нулевое.
Отдельно рассматривается задача слежения, т.е. когда желаемое положение не константа, а некоторая траектория.haqreu
22.02.2016 12:00Ага, правильно. Это очевидно всем, кто прослушал первую лекцию по теории управления. Но я-то не слушал, я просто пошёл поглядеть в википедию, что такое ЛКР. И в других источниках (я их перекопал десятка три) про это очень редко упоминают.
Ведь натурально отсутствие одной только фразы замедлило понимание на заметное время :(
datacompboy
22.02.2016 20:51+1Может стоит пойти и сделать правку ?*
haqreu
22.02.2016 21:00Я не чувствую себя в силе править статьи, которые не понимаю полностью. Я стараюсь написать как можно более доходчиво на этой площадке.
datacompboy
22.02.2016 22:49Добавление комментария о целевой точке (и вытекающих из этого различий в понимании) вполне возможно, имхо. Это же просто уточнение постановки задачи.
haqreu
22.02.2016 23:40Сделайте, пожалуйста?
datacompboy
23.02.2016 11:49Так. Пошел в википедию и прочитал, что там написано, цитирую:
Note that u_N is not defined, since x is driven to its final state xN by A x{N-1} + B u_{N-1}.
Так что нет, x_N не похоже на нулёвость.
VaalKIA
28.02.2016 10:03Тоже не знаю про лекцию, но на мой взгляд что суть вот в чём: Предположим, что у нас есть плита и кастрюля, надо нагреть кастрюлю до 100 градусов за минимальное время, ну так нет ничего проще, врубаем конфорку на полную мощность, следим за температурой кастрюли и — вот они 100 градусов, выключаем. Но в реальности, в этот момент начнётся как раз самое интересное, температура не остановится а продолжит расти, а всё потому, что тепло от нагревательного элемента доходит не сразу, а сам он при включении на полную может и 500 показать. Поэтому надо расширить аналитику и говорить уже не о мгновенной температуре, а о скорости её изменения, то есть в момент, когда надо отключить, должна не просто быть температура 100. а ещё и скорость её изменения ноль, вот и получаем этот самый вектор.
Это уже статья пятая на хабре, где упоминается PID, но первая, после которой мне захотелось разобраться что же это действительно такое и тема, оказалась очень интересной.

dimview
22.02.2016 19:37Судя по красной линии мы проскочили мимо цели, развернулись и поехали обратно. Это не всегда хорошо. В радиотехнике называется звон или эффект Гиббса.
haqreu
22.02.2016 19:42+1Ну это зависит от приложения. Обратный маятник, сильно подозреваю, иначе и не сделать.

Spin7ion
24.02.2016 13:00Зависит от того какие матрицы штрафа у вас или как вы выбрали коэффициенты PID
haqreu
24.02.2016 14:00Мне кажется, что без перерегулирования нормальный обратный маятник не сделать.
Spin7ion
24.02.2016 14:07Насколько мне известно перерегулирование это один из признаков неоптимальности управления и с ним даже борятся, например в гиростабилизированных подвесах и коптерах
haqreu
24.02.2016 14:10Я не про вертолёты говорил, вроде… Это всё сильно зависит от приложения. Оптимальность — опасное слово, оно слишком обманывает. Оптимальность согласно какому критерию?
Spin7ion
24.02.2016 14:31Согласно критерию минимизации квадратичного функционала:

Ведь, разве, если мы перерегулируем, то второй подинтегральный член не будет минимален?haqreu
24.02.2016 14:35Зависит. Не забывайте, что сумма многих маленьких квадратов предпочтительнее малого количества, но больших. Поэтому квадратичный функционал предпочтёт упасть как можно скорее к нулю, даже если это будет ценой (небольших) колебаний около нуля.
Arastas
24.02.2016 14:551) Этот функционал может дать перерегулирование, а может и нет, смотря какие матрицы выбраны. Вообще, на сколько я помню, для любого вектора обратных связей существуют такие матрицы Q, R, что этот вектор оптимален для этого функционала.
2) Перерегулирование может быть плохо, а может и хорошо, в малых количествах. Например, классические настройки на оптимум предполагают малое перерегулирование, до 5%, так как это заметно сокращает общее время переходного процесса.haqreu
24.02.2016 15:58Давайте отделять разные вопросы.
1) Управление с перерегулированием не означает того, что мы не нашли минимума целевой функции J, Spin7ion спрашивал об этом, как я понял
2) Я плохо вижу определение перерегулирования в случае векторных величин, возможно, что мы говорим о разных вещах. Я умею сравнивать векторы между собой, но уж больно в специфических контекстах.
3) Представим тележку с палкой сверху, которую надо балансировать. Если тележка не перейдёт через целевую точку, то палку от падения не остановить, см. инерция и проч. То есть, на бумаге можно, на практике нет.Arastas
24.02.2016 16:061) Согласен. Я как раз хотел сказать, что минимум функционала J может достигаться и на траекториях с перерегулированием.
2) Перергулирование определяется для скалярных траекторий, как правило, для выходного сигнала, в Вашем случае — для положения.
3) Если в этом примере нас интересует стабилизация палки, то и перерегулирование логично смотреть в траектории палки, а не в движении тележки.haqreu
24.02.2016 16:11Ну вот смотрите, система cart-pole. Забудем про всякие скорости-ускорения, целевой вектор двухмерный, ноль координат и палка вверх. Я и палку хочу выровнять, и тележку на место поставить.
Что такое перерегулирование в этом случае? Отдельно тележка перескочит через цель, чтобы выровнять палку. Палка, возможно, через цель не перескочит, кто его знает. Хотя перескочит, ну да не суть.
Поэтому уже для примера, который я в статье привёл, надо сначала определить, что такое перерегулирование, а потом уже говорить, исходя из общих понятий.Arastas
24.02.2016 16:56Вообще, перергулирование имеет достаточно конкретное определение и находится по переходному процессу, т.е. реакции на единичное ступенчатое воздействие при нулевых начальных условиях. Однако, так как для нелинейных систем переходный процесс не масштабируем, то часто на практике перерегулирование находится по конкретной траектории. Которая всё равно имеет вид перехода из одного постоянного положения в другое. В Вашем примере будет отдельно траектория палки и отдельно тележки, по каждой траектории можно что-то считать.
Кстати, когда говорят про перевернутый маятник, то обычно задачи вывода тележки в точку нет, есть задача стабилизации палки.
Arastas
24.02.2016 14:56Теоретически, не вижу причин, почему обратный маятник не может быть стабилизирован без перерегулирования. Хватало бы быстродействия и точности измерений и оценки параметров.
splav_asv
22.02.2016 22:25+1Если интересует время установления, часто так получается быстрее. Однократный переход через целевое значение и выход на полку с обратной стороны в ТАУ вполне нормальное явление. Называется перерегулирование — https://ru.wikipedia.org/wiki/Перерегулирование

nickolaym
02.03.2016 11:42Где нормальное, а где ненормальное.
При управлении автомобилем это называется "торможение двигателем: сперва бампером, потом радиатором, и наконец, двигателем".
dateless
23.02.2016 00:13Не в тему, но очень хочется: где вы приобритали такие боксы с алюминевым прифилем?
haqreu
23.02.2016 00:23Покупал сам алюминиевый профиль, плексиглас и тп, резал, собирал. Ничего готового там нет, я на все грабли стараюсь наступить сам. Один — это закрытый плексигласом куб для шумо- и пылезащиты окружающего пространства от небольшого чпу фрезера, все четыре стороны распахиваются на петлях для облегчения доступа и уборки.
У меня нет отдельно фотографии кожуха, только такая:
Скрытый текст

knagaev
24.02.2016 12:50Прокомментируйте, пожалуйста, графики, где показаны результаты работы.
Насколько я понял, сначала управляющее воздействие было направлено в сторону, противоположную координате цели?
Потом оно поменялось на "правильное", и потом ещё раз на "неправильное" для гашения скорости.
Если так, то почему не поехали сразу в "правильную" сторону?haqreu
24.02.2016 14:03Вы про какую именно картинку?
knagaev
24.02.2016 15:17Извините, я наверно не очень хорошо "идентифицировал".
Которая идёт сразу после строки "Я достаточно прокомментировал предыдущий код, этот не должен вызвать трудностей. Вот результат работы:"haqreu
24.02.2016 16:02В самый начальный момент времени машина находилась в трёх метрах от цели, при этом от цели удалялась со скоростью полметра в секунду.
Развернуть сразу я её не могу, у неё есть инерция. Управление (синяя кривая) сначало отрицательное, машина притягивалась к цели (ноль координат, останов). Примерно на третьей секунде машина повернула к цели, но продолжала притягиваться к цели. Секунде эдак на седьмой она начала от цели отталкиваться, но по инерции всё равно на пятнадцатой секунде перескочила через цель, дальше оно поколебалось чутка и стабилизировалось.knagaev
24.02.2016 16:05Всё понятно, спасибо.
Я просто по инерции (каламбурчик) после первых примеров подумал, что начальное состояние в покое.
Вот что-то мозги завернулись при попытке представить как всё это было.
Spin7ion
24.02.2016 13:23Стоп-стоп-стоп, а какого хрена в википедии стоит x_k^T Q x_k? Ведь это же простой x_k^2 в нашем случае, а у нас (x_k-x_N)^2?! Ёлки, да ведь они предполагают, что финальное состояние, в которое мы хотим попасть, это нулевой вектор!!! КАКОГО [CENSORED] ОБ ЭТОМ НА ВСЕЙ СТРАНИЦЕ ВИКИПЕДИИ НИ СЛОВА?!
В теории управления вводят невязку ( e=x_t-x, где x_t желаемое положение, а x — текущее ), о которой вы говорите.
В линейно-квадратичном регуляторе Q это матрица штрафа за отклонение от нуля, а R — матрица штрафа за использование управления. Если я правильно понял вашу статью, то в вашем случае эти матрицы являются единичными и, как следствие, это может являться причиной перерегулирования.
Кроме того, вы упомянули, что хотите делать балансера. Как я понимаю балансер может стоять условно бесконечное время (N огромно), если это так, то как вы собираетесь высчитать u_0 при N->+inf?
Возможно вам и вашим студентам будет полезна моя статья, в конце есть ссылка на более математическую ее версию. Есть так же много книг В.Н. Афанасьева, которые можно найти на сайте ВШЭ, где он описывает в том числе и LQR.haqreu
24.02.2016 14:02Понятно как буду делать — посчитаю статическую матрицу отклика на компе и вколочу коэффициенты в балансир.
Целые книги по теории управления читать лишь для того, чтобы сделать сигвей — это стрельба из пушки по воробьям, мне это ни к чему, спасибо.
И подскажите, пожалуйста, зачем вы дали ссылку на вашу статью, учитывая, что я её же и процитировал в первом же параграфе моей?Spin7ion
24.02.2016 14:10Понятно как буду делать — посчитаю статическую матрицу отклика на компе и вколочу коэффициенты в балансир.
Не могли бы вы подробнее описать алгоритм действий, к сожалению, я не очень понял идею?
И подскажите, пожалуйста, зачем вы дали ссылку на вашу статью, учитывая, что я её же и процитировал в первом же параграфе моей?
Был невнимателен, приношу свои извиненияhaqreu
24.02.2016 14:19Насколько я понял, то:
0) для начала я буду делать систему без скрытых переменных, а только с полностью известным вектором состояния, где я всё могу точно измерить
1) линеаризую физику, записываю систему x_{k+1} = A x_k + B u_k
2) выбираю большое время, пишу простейший МНК как в статье, получаю красивые графики
3) при помощи второй задачи МНК ищу постоянную такую матрицу F, что u_k = -F (x_k — 0), — 0 здесь просто показать, что я хочу достить нулевого вектора
4) вколачиваю постоянную матрицу F в робота
5) в каждый момент времени, имея измеренное состояние робота x, выбираю управление u = -F (x — 0)Arastas
24.02.2016 15:00Можно еще добавить 3.5 — сравнить полученную матрицу F с той, что считается аналитически по матрицам A, B и критерию оптимальности.
haqreu
24.02.2016 16:13Когда вы говорите про аналитическое решение, вы имеете в виду решение уравнения Риккати или просто взять начальное положение, потрясти коробочку, и посмотреть, насколько полученные траектории отличаются от тех, что я получил бы, используя матрицу F? Типа того, что я сделал с самым последним графиком.
Arastas
24.02.2016 16:20Я имею ввиду сравнить Ваш вектор F с тем, который получится путем аналитического синтеза, т.е. решения уравнения Риккати.
haqreu
24.02.2016 16:31А, можно. Если понять, что такое уравнение Риккати ;)
Ладно, я, конечно, придуриваюсь, и сумею его посчитать, но ведь натурально неохота вникать, куда как проще просто потрясти коробочку с линейной регрессией. А результаты должны получиться одинаковыми. Если всё же дойду до настоящих железок, то сделаю, наверное, сравнение.Arastas
24.02.2016 17:01Ну давайте попробуем Ваш пример из статьи посмотреть. Как я понимаю, система описывается в виде
x{k+1}=Ax{k}+Bu{k}, где A=[1 1; 0 1]; B=[0;1], правильно? Не могу сейчас в коде найти, какие у Вас матрицы Q, R, N, как Вы J считаете?haqreu
24.02.2016 17:09Q единичная, R = 256 (матрица 1x1), N нулевая. A и B такие, да.
Матрица F получилась [-0.0513868, -0.347324].Arastas
24.02.2016 17:15+1Расчёт с помощью Matlab dlqr дает F=-[0.052 0.354]:
A=[1 1;0 1]; B=[0;1]; Q=eye(2); R=256; F=-dlqr(A,B,Q,R)
Достаточно близко, на мой взгляд.haqreu
24.02.2016 17:21Угу, логично, что результат должен быть одним и тем же. Чтобы было ещё ближе, мне надо количество шагов взять не 60, а хотя бы 6000. Спасибо большое за проверку!
Arastas
24.02.2016 14:58Как правило, балансир предполагает, что мы стоим в положении равновесия, т.е. u=0. Или же мы можем сделать эту точку точкой равновесия за счет постоянного управления, тогда эта постоянная составляющая в модели отклонений не учитывается.
Spin7ion
24.02.2016 14:45Есть еще такой вопрос.
Как я вижу у вас получилось управление, коэффициент которого зависит от вашей начальной точки. Что будет в случае, если робот окажется в другой точке? Гарантируется ли тогда управление?
Заметьте, что в вычислении коэффициентов обычном LQR не участвует x_0:
 — управление, где
— управление, где
 , где P — решение уравнения Риккати:
, где P — решение уравнения Риккати:

haqreu
24.02.2016 15:54В моей процедуре подсчёта да, я использую начальную точку, но результат должен быть тем же, что и при решении уравнения Риккати. Гарантий нет никаких ни в том случае, ни в другом. Например, лежащий на земле сигвей не встанет. Гарантии есть только для малого отклонения от финальной точки.
haqreu
24.02.2016 17:24Посмотрите подсчёт Arastas, он посчитал именно аналитически, результат сходится с тем, что посчитал я численно.
MichaelBorisov
29.02.2016 15:13+2Регулятор в теории управления — это система стабилизации состояния. Вы же рассмотрели задачу не стабилизации, а перевода системы из одного состояния в другое. Конечно, хороший регулятор справится и с этим, но это решение далеко не оптимальное. Оптимальное программное управление (а именно его вы ищете для рассматриваемой задачи) — это по сути дела задача на вариационное исчисление: найти такие функции u(t), которые минимизируют функционал (время работы системы, расход энергии и пр.). Но в нашем случае методы классического вариационного исчисления неприменимы по следующим причинам:
1) В классическом вар. исчислении нет возможности учесть ограничения на управление (максимальное и минимальное ускорения)
2) Классическое вариационное исчисление отыскивает решение в виде непрерывных функций, а оптимальное управление при ограничениях часто оказывается кусочно-постоянной, т.е. разрывной функцией.
В этой ситуации задача на оптимальное программное управление решается исходя из принципа максимума Понтрягина. Для линейных систем с максимальным быстродействием найдены более-менее общие решения, которые являются кусочно-постоянными: управление всегда находится на одной из границ допустимого интервала. Тем самым на практике нужно лишь находить моменты времени, в которые управление переключается с одной границы на другую.
Что же касается регулятора — то его есть смысл задействовать для стабилизации траектории (которая будет иметь случайные отклонения от идеальной) и конечного положения. Применение регулятора по назначению — это устранение малых отклонений состояния объекта управления от желаемого.MichaelBorisov
29.02.2016 15:35+2Для иллюстрации к вашей задаче управления автомобилем: если стоит задача максимально быстро разогнать его до некоторой скорости — то оптимальным по быстродействию управлением будет выжать полный газ до тех пор, пока автомобиль не разгонится, а потом полностью отпустить газ. Это и обеспечит разгон до заданной скорости за минимальное время, при этом ограничение на управление (максимальное ускорение) будет соблюдено. После этого можно уже включить регулятор для стабилизации скорости.
Более интересно рассмотреть другую задачу: автомобиль может ускоряться (влево или вправо) или тормозить с заданным максимальным ускорением. Он находится в пункте А и имеет скорость v0. Задача — привести его в пункт B и остановить там за кратчайшее время.
Очевидно, что оптимальное программное управление в этом случае будет кусочно-постоянным. Возможны 4 случая:
1) если мы изначально стояли в пункте А, то надо сначала выжать полный газ, пока не проедем ровно половину пути, а потом максимально тормозить вплоть до прибытия в пункт B.
2) Если мы изначально двигались влево, а пункт B находится справа — то надо сначала максимально тормозить, а после полной остановки применить ту же стратегию, как для случая 1)
3) Если мы изначально двигались вправо с такой скоростью, что успеем затормозить до прибытия в пункт B — то надо сначала ускоряться до той точки, из которой мы сможем затормозить, а потом тормозить, как в случае 1).
4) Если мы изначально двигались вправо с такой скоростью, что не сможем затормозить до пункта B — то сразу начинаем максимально тормозить, проскакиваем пункт B, а после полной остановки применяем решение для случая 1)
Таким образом, у нас управление во время действия объекта всегда находится на одной из допустимых границ, и максимально происходит одно переключение с одной границы на другую. При этом переход между торможением и разгоном не считается за переключение, если направление ускорения при этом не меняется. В этой задаче удобно представить себе ракетный автомобиль, у которого спереди и сзади установлены реактивные двигатели, дающие заданное ускорение вплоть до максимального. Тогда очевидно, что переход между торможением и разгоном не приводят к переключению двигателей, если при этом не меняется направление ускорения.nickolaym
02.03.2016 12:00Если время дискретное, то момент "пора тормозить" может оказаться между квантами. Придётся начать торможение несколько заранее, чтобы не проскочить финиш. Тогда у нас появится запас по управляющему воздействию, вот тут-то регулятор и пригодится, наверное?
PapaBubaDiop
Хорошее чтиво. На мой взгляд надо уменьшить число восклицательных знаков и поменять красное с зелёным, начиная с первого рисунка.
haqreu
Спасибо, про восклицательные знаки согласен, а вот по цвета не понял...
PapaBubaDiop
Кое-где цвета перепутаны. Зелёная линия на самом деле ускорение, а красная — скорость.
haqreu
Да, в самом первом примере были перепутаны, спасибо, поправил. Но в тексте, не в картинках, в картинках подписи были правильными. Первая переменная красная, вторая зелёная, третья синяя. RGB.