
Для ясности теоретического понимания нет лучшего пути, чем учиться на своих собственных ошибках, на собственном горьком опыте. (Фридрих Энгельс)
Всем привет!
Несколько недель назад мне в линкедине написал коллега и сообщил, что в моем проекте на гитхабе не совсем верно работает хеш-таблица.
Мне прислали тесты и фикс, и действительно создавалась ситуация, где система "зависала". При расследовании проблемы я понял, что допустил несколько ошибок при верификации. На Хабре тема верификации RTL-кода не слишком подробна расписана, поэтому я и решил написать статью.
Из статьи вы узнаете:
- как можно организовать хеш-таблицу на FPGA.
- на чём была построена верификация.
- какие ошибки я допустил (они привели к тому, что бага не была замечена раньше).
- как это всё можно исправить.
Добро пожаловать под кат!
Кратко о проекте
Цели и предпосылки
Цели, которые я ставил перед началом проекта:
- если заявляется, что хеш-таблица на N элементов, то гарантированно поместится там любых N элементов.
- таблица сама разрешает коллизии, ограничения на количество элементов в корзине нет (но не больше размера хеш-таблицы, разумеется).
- таблица позволяет производить операции добавления, поиска и удаления по ключу
- если при поиске не возникает коллизий, то таблица готова принимать задания для поиска каждый такт (максимальная производительность).
- по поводу ресурсов и тактовой частоты я не беспокоюсь.
Внутренее устройство
Я хочу получить максимальную производительность, поэтому организовываю конвейер:

Вход (
ht_cmd):typedef enum logic [1:0] {
OP_SEARCH,
OP_INSERT,
OP_DELETE
} ht_opcode_t;
typedef struct packed {
logic [KEY_WIDTH-1:0] key;
logic [VALUE_WIDTH-1:0] value;
ht_opcode_t opcode;
} ht_command_t;Выход (
ht_res):typedef enum int unsigned {
SEARCH_FOUND,
SEARCH_NOT_SUCCESS_NO_ENTRY,
INSERT_SUCCESS,
INSERT_SUCCESS_SAME_KEY,
INSERT_NOT_SUCCESS_TABLE_IS_FULL,
DELETE_SUCCESS,
DELETE_NOT_SUCCESS_NO_ENTRY
} ht_rescode_t;
typedef struct packed {
ht_command_t cmd;
ht_rescode_t rescode;
logic [BUCKET_WIDTH-1:0] bucket;
// valid only for opcode = OP_SEARCH
logic [VALUE_WIDTH-1:0] found_value;
} ht_result_t;Примечание:
На самом деле в
ht_result_t нас волнует только rescode и found_value, но чуть забегая вперед — без других полей было бы сложнее верифицировать. Всё равно, если в железе они не будут использоваться, то синтезатор их вырежет и ресурсы они не займут.Что и где расположено:
- Все данные (
key,value) хранятся в памятиdata_table. - Рядом с данными хранится информация для организации связанного списка (
next_ptr,next_ptr_val). - Номер ячейки, где находится начало связанного списка для корзины, хранится в
head_table. empty_ptr_storageхранит номера пустых строчек вdata_table.
Слово в
head_table:typedef struct packed {
logic [HEAD_PTR_WIDTH-1:0] ptr;
logic ptr_val;
} head_ram_data_t;Слово в
data_table:typedef struct packed {
logic [KEY_WIDTH-1:0] key;
logic [VALUE_WIDTH-1:0] value;
logic [HEAD_PTR_WIDTH-1:0] next_ptr;
logic next_ptr_val;
} ram_data_t;Алгоритм работы:
calc_hashиспользуетkeyдля расчета хеша (его значение и будет номером корзины (bucket_num)).- используем
bucket_numкак адрес дляhead_table: получаем указатель на начало связанного списка для корзины. - мультиплексор распределяет задание в нужный модуль (
data_table_search,data_table_insert,data_table_delete) (ориентируясь наopcode). - модули, которые получают соответствующие задания (
task) на исполнение (найти, вставить, удалить) и читают/пишут изdata_table(бегают по связанному списку). Формируют результатht_res.
Интересные нюансы:
- память
data_tableимеет задержку на чтение в два такта, поэтому для того, чтобы каждый такт производить поиск, сделаны несколько (пять) параллельных модулей, задания между которыми распределяются round-robin'ом. - для убыстрения поиска свободной ячейки предусмотрен
empty_ptr_storage. На момент написания статьи он реализован очень нерационально: векторомempty_ptr_mask(его длина — количество ячеек таблицыdata_table), который хранится на регистрах. А поиск пустого элемента происходит "перебором" за ноль тактов (на комбинационке). С точки зрения ресурсов и частоты — это не самое лучшее решение.
Выглядит это так (кликните для увеличения):

Что я сделал для того, чтобы избежать ошибок/упростить отладку
Перед тем, как начать делать хеш-таблицу, я понимал, что проект непростой, поэтому заранее предусмотрел некоторые вещи, которые ускорили разработку и упростили отладку.
SystemVerilog & Coding Style
В качестве HDL-языка использовался SystemVerilog и корпоративный кодинг стайл.
Он позволяет удобно описывать структуры (см. выше) и создавать свои типы данных, например для описания FSM:
enum int unsigned {
IDLE_S,
NO_VALID_HEAD_PTR_S,
READ_HEAD_S,
GO_ON_CHAIN_S,
KEY_MATCH_S,
ON_TAIL_WITHOUT_MATCH_S
} state, next_state;Потоковый интерфейс (Avalon-ST)
При разработке конвейера нужно хорошо понимать когда он будет останавливаться.
Можно напридумывать много чего, но лучше всего использовать уже готовые, разработанные интерфейсы.
На работе я пишу под FPGA компании Altera, поэтому я лучше знаком с интерфейсами, которые они предлагают/продвигают. В этом проекте я использовал семейство Avalon.
Команды это просто поток данных (одно слово — одна команда), поэтому я использовал стандарт
Avalon-Streaming (Avalon-ST) (сигналы data, ready, valid).Вот так выглядит транзакция на
Avalon-ST при readyLatency = 0 (взято из стандарта):
На этой картинке видно, что сигнал ready, которым управляет слейв, затыкает транзакцию и передачу данных.
Dummy hash
Когда я прикидывал как я буду делать эту хеш-таблицу, я понимал, что самое сложное будет в её верификации. Очевидно, что самые интересные нюансы проявляются тогда, когда ты пытаешься добавить в цепочку, где уже есть данные, либо удаляешь из длинной цепочки и так далее.
Это значит, что когда подается воздействие на систему, то нужно иметь возможность по заранее заданному номеру корзины легко генерировать ключ (
key).С настоящими хеш-функциями это проблематично, поэтому предусмотрено значение параметра
HASH_TYPE равное "dummy hash".Если выбран этот тип хэша, то номер корзины — это просто старшие
BUCKET_WIDTH бит от ключа.Следовательно, когда
key = 0x92123456, а BUCKET_WIDTH равен 8, то bucket_num = 0x92.Это позволит легко составить необходимое воздейстие для генерации тех или иных граничных случаев.
Логирование в симуляции
Иногда разработчики отлаживают свои RTL-модули прямо на железе (читай, платах) с использованием SignalTap или ChipScope. Такой подход не всегда самый быстрый и продуктивный — требуется пересборка всего проекта (от 10 минут до нескольких часов) (а иногда не один раз), плата под рукой, отладчик, генерация входных воздействий и т.д.
Для ускорения разработки используются специальные симуляторы, такие как ModelSim, VCS, Icarus Verilog и др. Они позволяют отслеживать значения всех (либо выбранных) сигналов/переменных во время отладки путем построения временных диаграмм (времянок). На просмотр этих диаграмм может уходить огромное количество времени при дебаге.
Решение:
Логировать все действия, что происходят, для быстрого просмотра глазами.
Для этого в
data_table_insert, data_table_delete, data_table_search я добавил функции, которые печатают в лог:function void print( string s );
$display("%08t: %m: %s", $time, s);
endfunctionФормат
display похож на printf (можно %d, %f и пр. использовать):%08t— выведет время симуляции (будет удобно потом прыгнуть в нужный момент времени).%m— напечатает модуль (иерархическое имя), где это произошло. (Внимание: это не требует аргументов!)%s— печать строчки
Логируем переходы FSM:
function void print_state_transition( );
string msg;
if( next_state != state )
begin
$sformat( msg, "%s -> %s", state, next_state );
print( msg );
end
endfunctionПечатаем прием нового задания:
function string pdata2str( input ht_pdata_t pdata );
string s;
$sformat( s, "opcode = %s key = 0x%x value = 0x%x head_ptr = 0x%x head_ptr_val = 0x%x",
pdata.cmd.opcode, pdata.cmd.key, pdata.cmd.value, pdata.head_ptr, pdata.head_ptr_val );
return s;
endfunction
function void print_new_task( ht_pdata_t pdata );
print( pdata2str( pdata ) );
endfunctionИ так далее...
Для симуляции я использую ModelSim. В его логе, который отображается на экране (и по умолчанию попадет в файл
transcript) возникают такие строчки:1465: top_tb.dut.d_tbl.sea_eng.g_s_eng[3].search.print: opcode = OP_SEARCH key = 0x04000000 value = 0x0000 head_ptr = 0x000 head_ptr_val = 0x0
1465: top_tb.dut.d_tbl.sea_eng.g_s_eng[3].search.print: IDLE_S -> NO_VALID_HEAD_PTR_S
1475: top_tb.dut.d_tbl.sea_eng.g_s_eng[3].search.print: RES: key = 0x04000000 value = 0x0000 rescode = SEARCH_NOT_SUCCESS_NO_ENTRY
1475: top_tb.dut.d_tbl.sea_eng.g_s_eng[3].search.print: NO_VALID_HEAD_PTR_S -> IDLE_S
1475: ht_tb.print: IN_MONITOR: key = 0x04000000 value = 0x0000 rescode = SEARCH_NOT_SUCCESS_NO_ENTRY
1485: top_tb.dut.d_tbl.del_eng.print: opcode = OP_DELETE key = 0x04111111 value = 0x0000 head_ptr = 0x000 head_ptr_val = 0x0
1485: top_tb.dut.d_tbl.del_eng.print: IDLE_S -> NO_VALID_HEAD_PTR_S
1495: top_tb.dut.d_tbl.del_eng.print: RES: key = 0x04111111 value = 0x0000 rescode = DELETE_NOT_SUCCESS_NO_ENTRY
1495: top_tb.dut.d_tbl.del_eng.print: NO_VALID_HEAD_PTR_S -> IDLE_S
1495: ht_tb.print: IN_MONITOR: key = 0x04111111 value = 0x0000 rescode = DELETE_NOT_SUCCESS_NO_ENTRY
1505: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x04000000 value = 0xb95f head_ptr = 0x000 head_ptr_val = 0x0
1505: top_tb.dut.d_tbl.ins_eng.print: IDLE_S -> NO_HEAD_PTR_WR_HEAD_PTR_S
1515: top_tb.dut.h_tbl.print: addr = 0x04 wr_data.ptr = 0x003 wr_data.ptr_val = 0x1
1515: top_tb.dut.d_tbl.ins_eng.print: NO_HEAD_PTR_WR_HEAD_PTR_S -> NO_HEAD_PTR_WR_DATA_S
1525: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x003 key = 0x04000000 value = 0xb95f next_ptr = 0x000, next_ptr_val = 0x0
1525: top_tb.dut.d_tbl.ins_eng.print: RES: key = 0x04000000 value = 0xb95f rescode = INSERT_SUCCESS
1525: top_tb.dut.d_tbl.ins_eng.print: NO_HEAD_PTR_WR_DATA_S -> IDLE_SТакой текстовый лог легко grep'ать, либо побегать поиском (например, в vim'e).
Логи сэкономили огромное количество времени: при подаче простых примеров я знал, что в каком порядке должно писаться и просто смотрел в лог. Если происходила ошибка, то переходил к анализу кода, а не временных диаграмм.
Всем советую в качестве челенджа попробовать в течение недели отлаживать RTL-код без времянок (выйти из зоны комфорта).
Верификация
Если обратиться к хорошей литературе, например, SystemVerilog for Verification, то в качестве хорошего, правильного тестбенча там приводится следующая схема:

В этой статье забирать хлеб у Chris Spear я не собираюсь, поэтому о том что обозначают все эти компоненты подробно рассказывать не буду.
Схема моего тестбенча:

top_tb
Топовый модуль.
DUT (Device/Design Under Test)
Наш подопытный — экземпляр модуля
hash_table_top.ht_driver
- содержит mailbox
gen2drv, который предназначен для команд, которые будут отправлены вDUT. - как только в этой очереди появляется команда, то она будет отправлен в
DUT. - после отправки команды в
DUT, она копируется вht_scoreboard.
Для того, чтобы положить команду в этот mailbox используется иерархический доступ:
task send_to_dut_c( input ht_command_t c );
// using hierarchial access to put command in mailbox
env.drv.gen2drv.put( c );
endtask tests
Для проверки работоспособности были написаны три теста/входных воздействия.
Макросы для упрощения работы:
`define CMD( _OP, _KEY, _VALUE ) cmds.push_back( '{ opcode : _OP, key : _KEY, value : _VALUE } );
`define CMD_SEARCH( _KEY ) `CMD( OP_SEARCH, _KEY, 0 )
`define CMD_INSERT( _KEY, _VALUE ) `CMD( OP_INSERT, _KEY, _VALUE )
`define CMD_INSERT_RAND( _KEY ) `CMD_INSERT( _KEY, $urandom() )
`define CMD_DELETE( _KEY ) `CMD( OP_DELETE, _KEY, 0 )Пример теста:
task test_01( );
ht_command_t cmds[$];
$display("%m:");
`CMD_INSERT( 32'h01_00_00_00, 16'h1234 )
`CMD_INSERT( 32'h01_00_10_00, 16'h1235 )
`CMD_INSERT_RAND( 32'h01_00_00_00 )
`CMD_INSERT_RAND( 32'h01_00_00_01 )
`CMD_DELETE ( 32'h01_00_00_00 )
`CMD_INSERT_RAND( 32'h01_00_00_02 )
`CMD_SEARCH( 32'h01_00_00_00 )
`CMD_SEARCH( 32'h01_00_00_01 )
`CMD_SEARCH( 32'h01_00_00_01 )
`CMD_SEARCH( 32'h01_00_00_03 )
foreach( cmds[i] )
begin
send_to_dut_c( cmds[i] );
end
endtaskht_monitor
- следит за выходным интерфейсом
ht_res. - как только там есть результат, то выцепляет его и отправляет в
ht_scoreboard.
ht_scoreboard
Проверяет корректность работы DUT'a.
В себе содержит:
- два
mailbox, куда кладут команды и результатht_driverиht_monitorсоответственно. - референсная модель хеш-таблицы
ref_hash_table.
Алгоритм работы:
- как только пришел результат
ht_res, то вынимаются из очереди он и соответствующий ему запрос. Здесь нам на руку то, что на каждую команду будет ответ. - вызывается функция
check, которая скармливает команду в референсную модель и сравнивает результаты от DUT'a и референсной модели. - если совпадения нет, то с помощью
$errorбудет распечатано об этом сообщение в лог, а в GUI ModelSim'a появится красная стрелочка в том момент времени, когда это произошло.
Coverage
Итак, уже есть система (если хотите, фреймворк), которая позволяет отправлять различные входные воздейстия, а так же анализировать корректность реакции DUT. Для того, чтобы убедиться, что багов нет, необходимо покрыть "все возможные" варианты.
Для оценки покрытия в языке SystemVerilog введены такие объекты как covergroup и coverpoint. С их помощью можно описать те точки, где мы хотим сэмплировать, а так же какую статистику собирать.
covergroup cg();
option.per_instance = 1;
CMDOP: coverpoint result_locked.cmd.opcode;
CMDRES: coverpoint result_locked.rescode;
BUCKOCUP: coverpoint bucket_occup[ result_locked.bucket ] {
bins zero = { 0 };
bins one = { 1 };
bins two = { 2 };
bins three = { 3 };
bins four = { 4 };
bins other = { [5:$] };
}
CMDOP_BUCKOCUP: cross CMDOP, BUCKOCUP;
CMDRES_BUCKOCUP: cross CMDRES, BUCKOCUP {
// we should ignore SEARCH_FOUND, INSERT_SUCCESS_SAME_KEY, DELETE_SUCCESS
// when in bucket was zero elements, because it's not real situation
ignore_bins not_real = binsof( CMDRES ) intersect{ SEARCH_FOUND, INSERT_SUCCESS_SAME_KEY, DELETE_SUCCESS } &&
binsof( BUCKOCUP ) intersect{ 0 };
}
endgroupПояснение:
CMDOPиCMDRESследят за тем, какие были операцииht_cmdи результатыht_res.- массив
bucket_occupхранит количество элементов, которые были в корзине в момент операции. CMDOP_BUCKOCUP— "скрещивает" команды с количеством элементов в корзине: получаем события была команда X, а в корзине, к которой относилсяkey, где было Y элементов.CMDRES_BUCKOCUP— "скрещивает" результат с количество элементов в корзине.
После окончания симуляции в консоли ModelSim'a можно получить отчет:
coverage save 1.ucdb
vcover report 1.ucdb -verbose -cvgОтчёт:
COVERGROUP COVERAGE:
----------------------------------------------------------------------------------------------------
Covergroup Metric Goal/ Status
At Least
----------------------------------------------------------------------------------------------------
TYPE /top_tb/dut/resm/cg 94.0% 100 Uncovered
Coverpoint cg::CMDOP 100.0% 100 Covered
Coverpoint cg::CMDRES 85.7% 100 Uncovered
Coverpoint cg::BUCKOCUP 100.0% 100 Covered
Cross cg::CMDOP_BUCKOCUP 100.0% 100 Covered
Cross cg::CMDRES_BUCKOCUP 84.6% 100 Uncovered
Covergroup instance \/top_tb/dut/resm/cg1 94.0% 100 Uncovered
Coverpoint CMDOP 100.0% 100 Covered
covered/total bins: 3 3
missing/total bins: 0 3
bin auto[OP_SEARCH] 21 1 Covered
bin auto[OP_INSERT] 21 1 Covered
bin auto[OP_DELETE] 18 1 Covered
Coverpoint CMDRES 85.7% 100 Uncovered
covered/total bins: 6 7
missing/total bins: 1 7
bin auto[SEARCH_FOUND] 12 1 Covered
bin auto[SEARCH_NOT_SUCCESS_NO_ENTRY] 9 1 Covered
bin auto[INSERT_SUCCESS] 14 1 Covered
bin auto[INSERT_SUCCESS_SAME_KEY] 7 1 Covered
bin auto[INSERT_NOT_SUCCESS_TABLE_IS_FULL] 0 1 ZERO
bin auto[DELETE_SUCCESS] 11 1 Covered
bin auto[DELETE_NOT_SUCCESS_NO_ENTRY] 7 1 Covered
Coverpoint BUCKOCUP 100.0% 100 Covered
covered/total bins: 6 6
missing/total bins: 0 6
bin zero 7 1 Covered
bin one 13 1 Covered
bin two 9 1 Covered
bin three 12 1 Covered
bin four 8 1 Covered
bin other 11 1 Covered
Cross CMDOP_BUCKOCUP 100.0% 100 Covered
covered/total bins: 18 18
missing/total bins: 0 18
bin <auto[OP_SEARCH],zero> 1 1 Covered
bin <auto[OP_INSERT],zero> 5 1 Covered
bin <auto[OP_SEARCH],one> 5 1 Covered
...
Cross CMDRES_BUCKOCUP 84.6% 100 Uncovered
covered/total bins: 33 39
missing/total bins: 6 39
bin <auto[SEARCH_NOT_SUCCESS_NO_ENTRY],zero>
1 1 Covered
bin <auto[INSERT_SUCCESS],zero> 5 1 Covered
bin <auto[DELETE_NOT_SUCCESS_NO_ENTRY],zero>
1 1 Covered
...Все возможные перекрещивания получены автоматически — ничего дополнительного мы не писали.
После трех тестов видно, что:
- команд на вставку
OP_INSERTбыло 21, а на удаление 18 - всего один раз пытались искать, когда в корзине не было элементов
- ни разу не было события
INSERT_NOT_SUCCESS_TABLE_IS_FULL
В итоге
- есть система, которая проверяет правильно ли работает DUT, сравнивая её выход с референсной моделью.
- есть небольшой набор тестов, которые генерируют входные воздействия.
- есть обратная связь о качестве тестов (coverage).
- заранее упростили дебаг и симуляцию, используя "dummy hash" и логирование.
В чем заключалась бага
Оказалось, если подать такое воздействие:
`CMD_INSERT_RAND( 32'h05_00_00_00 )
`CMD_INSERT_RAND( 32'h05_00_00_01 )
`CMD_DELETE ( 32'h05_00_00_01 )
`CMD_INSERT_RAND( 32'h05_00_00_02 )
`CMD_INSERT_RAND( 32'h05_00_00_03 )то это приведёт к тому, что при вставке ключа
0x05000003 модуль data_table_insert "зависал":- постоянно читает из адреса 0x001
- состояние FSM
stateвисит вGO_ON_CHAIN_S(и из него больше никогда не выйдет)
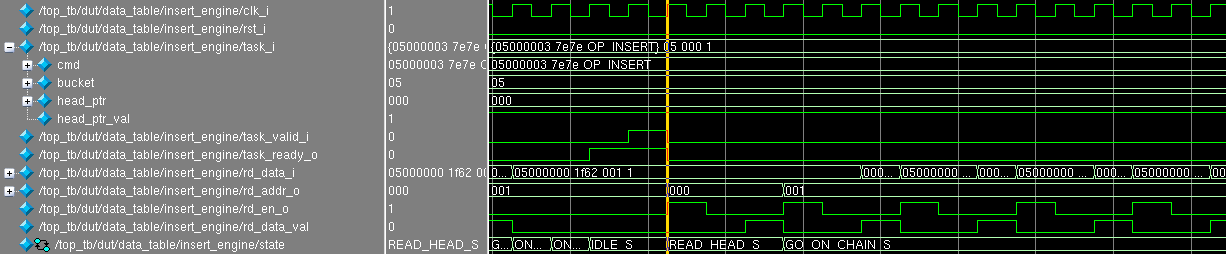
(кликните для увеличения)
В логе возникли сообщения:
385: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000003 value = 0x7e7e head_ptr = 0x000 head_ptr_val = 0x1
385: top_tb.dut.d_tbl.ins_eng.print: IDLE_S -> READ_HEAD_S
415: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
415: top_tb.dut.d_tbl.ins_eng.print: READ_HEAD_S -> GO_ON_CHAIN_S
445: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
475: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
505: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
535: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
...Отмотаем немного лог и проанализируем его. Я привёл только те строчки, которые нам интересны (что читалось и писалось в таблицу
data_table): 75: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000000 value = 0x1f62 head_ptr = 0x000 head_ptr_val = 0x0
95: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x000, next_ptr_val = 0x0
115: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000001 value = 0x3ff2 head_ptr = 0x000 head_ptr_val = 0x1
145: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x000, next_ptr_val = 0x0
155: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x001 key = 0x05000001 value = 0x3ff2 next_ptr = 0x000, next_ptr_val = 0x0
165: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
185: top_tb.dut.d_tbl.del_eng.print: opcode = OP_DELETE key = 0x05000001 value = 0x0000 head_ptr = 0x000 head_ptr_val = 0x1
215: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
245: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x001 key = 0x05000001 value = 0x3ff2 next_ptr = 0x000, next_ptr_val = 0x0
255: top_tb.dut.d_tbl.del_eng.print: WR: addr = 0x001 key = 0x05000001 value = 0x3ff2 next_ptr = 0x000, next_ptr_val = 0x0
265: top_tb.dut.d_tbl.del_eng.print: WR: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x000, next_ptr_val = 0x0
285: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000002 value = 0x5429 head_ptr = 0x000 head_ptr_val = 0x1
315: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
345: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x000, next_ptr_val = 0x0
355: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x001 key = 0x05000002 value = 0x5429 next_ptr = 0x000, next_ptr_val = 0x0
365: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
385: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000003 value = 0x7e7e head_ptr = 0x000 head_ptr_val = 0x1
415: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
445: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
475: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
505: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1Можно заметить, что в момент времени 255-265 нс произошли странные события: сначала в
addr = 0x001 записали одно значение, а затем другое. Это приводит к тому, что таблица
data_table содержит некорректные данные:- ячейка 0x000 указывает, что в ячейке 0x001 есть продолжение цепочки (
next_ptr = 0x001,next_ptr_val = 0x1) - в ячейке 0x001 хранится ключ 0x00000000. Он никак не может быть в корзине 0x05, т.к. в симуляции используется
dummy hash.
При добавлении ключа 0x05000002 происходит интересная ситуация: снова происходит запись два раза в одну ячейку 0x001.
- запись на 355 нс записывает новое значение, т.к. модуль
empty_ptr_storageвыдал, что 0x001 пустует (нам повезло, что сейчас алгоритм работы этого модуля такой, что он отдает самый маленький адрес, который считается пустым) - запись на 365 нс обновляет ячейку, которая предыдущая в цепочке, и по мнению модуля это 0x001. В итоге 0x001 теперь указывает на 0x001.
При попытке добавления ключа 0x05000003 происходит зацикливание при проходе по цепочке. Начиная с 445 нс мы будем бесконечно бегать по цепочке и читать один и тот же адрес.
В чём оказалась ошибка
Очевидно, что ошибку вносит модуль, который удалял данные (
data_table_delete). В момент 255 нс он должен был в ячейке 0x000 флаг
next_ptr_val сделать равным нулю, а в момент 265 нс записать в 0x001 записать все нули. Так предполагалось по коду этого модуля, но этого, как видим, не произошло. Дело в том, что надо было отдельно сохранить
rd_addr и rd_data, которые мы прочитали с конца цепочки, а так мы использовали значения, с которыми только что работали.Такие ошибки (лишняя задержка на один такт, перезаписанные данные не вовремя и пр.) весьма типичны в RTL-коде. Интереса они особого не представляют, поэтому я это не особо расписываю в статье.
Какие ошибки были допущены (при разработке)
Ведение проекта "неидеально"
Дело в том, что я не довёл проект до логического конца, который я себе представлял. Почему — сейчас уже не вспомню.
Например, в
README в проекта не указано того, где и как использовался/тестировался этот модуль.Сравните две фразы:
- этот проект используется в продакшене в 100G коммутаторе.
- этот проект писался по приколу на нескольких выходных за
банками пиватоматным соком.
Если бы я явно указал, что этот модуль я написал просто так на выходных и никуда его не встраивал, то, возможно, сторонние разработчики не использовали мой модуль и съэкономили бы себе время (правда, тогда бы я не узнал, что у меня есть бага, а вы бы не прочитали эту статью).
Когда я начал разбираться где проблема в коде, я расстроился, когда увидел, что проблема есть с переменной
prev_rd_addr. Блок, где присваивают её значение, выглядит вот так:always_ff @( posedge clk_i or posedge rst_i )
if( rst_i )
prev_rd_addr <= '0;
else
if( rd_en_o ) //FIXME
prev_rd_addr <= rd_addr;FIXME без пояснения — это плохо. Лишние пять минут описания проблемы всегда окупятся в будущем.*Выводы:
- если что-то выкладываете в опенсорс, указывайте явно как и где оно тестировалось на железе (если тестировалось). Если оно не тестировалось, то напишите об этом явно.
- если ведете проект в одиночку, просите кого-то (возможно со стороны, например на electronix.ru) отревьюить код. Возможно, он даст кое-какие советы, замечания.
- даже если есть проблемы, которые вы не смогли решить (например, было вам лень), то явно указывайте это в файле типа,
KNOWN_PROBLEMS/KNOWN_BUGS
Coverage
Легко заметить, что те точки, на которое смотрит покрытие, не дает полной картины:
- не учитывается "история": как шли запросы друг за другом и к каким корзинам они относились.
- не учитывается в какой части цепочки остановился поиск, либо было удалены данные (в начале/середине/конце).
Исправляем:
Вводим тип
ht_chain_state_t, который будет показывать, где мы остановились при операции:typedef enum int unsigned {
NO_CHAIN,
IN_HEAD,
IN_MIDDLE,
IN_TAIL,
IN_TAIL_NO_MATCH
} ht_chain_state_t;
// добавляем его в ht_result_t
...
// only for verification
ht_chain_state_t chain_state;
} ht_result_t;В соотстветвующих модулях добавляем анализ. Для
data_table_delete это выглядит так:ht_chain_state_t chain_state;
always_ff @( posedge clk_i or posedge rst_i )
if( rst_i )
chain_state <= NO_CHAIN;
else
if( state != next_state )
begin
case( next_state )
NO_VALID_HEAD_PTR_S : chain_state <= NO_CHAIN;
IN_TAIL_WITHOUT_MATCH_S : chain_state <= IN_TAIL_NO_MATCH;
KEY_MATCH_IN_HEAD_S : chain_state <= IN_HEAD;
KEY_MATCH_IN_MIDDLE_S : chain_state <= IN_MIDDLE;
KEY_MATCH_IN_TAIL_S : chain_state <= IN_TAIL;
// no default: just keep old value
endcase
end
// кладем в результат, чтобы проанализировать в ```ht_res_monitor```
assign result_o.chain_state = chain_state;Изменения в
ht_res_monitor:
// история результатов
ht_result_t result_history [HISTORY_DELAY:1];
always_ff @( posedge clk_i )
begin
if( result_locked_val )
begin
result_history[1] <= result_locked;
for( int i = 2; i <= HISTORY_DELAY; i++ )
begin
result_history[i] <= result_history[i-1];
end
end
end
// 1 в маске обозначает, что корзины (bucket) совпали в истории
logic [HISTORY_DELAY:1] bucket_hist_mask;
always_comb
begin
for( int i = 1; i <= HISTORY_DELAY; i++ )
bucket_hist_mask[i] = ( result_history[i].bucket == result_locked.bucket );
endДобавляем в covergroup:
...
CMDOP_D1: coverpoint result_history[1].cmd.opcode;
CMDOP_D2: coverpoint result_history[2].cmd.opcode;
CMDRES_D1: coverpoint result_history[1].rescode;
CMDRES_D2: coverpoint result_history[2].rescode;
CHAIN: coverpoint result_locked.chain_state;
BUCK_HIST_MASK: coverpoint bucket_hist_mask;
CMDOP_HISTORY_D2: cross CMDOP_D2, CMDOP_D1, CMDOP, BUCK_HIST_MASK;
CMDRES_HISTORY_D2: cross CMDRES_D2, CMDRES_D1, CMDRES, BUCK_HIST_MASK {
ignore_bins not_check_now = binsof( CMDRES ) intersect{ INSERT_NOT_SUCCESS_TABLE_IS_FULL } ||
binsof( CMDRES_D1 ) intersect{ INSERT_NOT_SUCCESS_TABLE_IS_FULL } ||
binsof( CMDRES_D2 ) intersect{ INSERT_NOT_SUCCESS_TABLE_IS_FULL };
}
CMDOP_CHAIN: cross CMDOP, CHAIN {
ignore_bins insert_in_middle = binsof( CMDOP ) intersect { OP_INSERT } &&
binsof( CHAIN ) intersect { IN_MIDDLE };
ignore_bins insert_in_tail_no_match = binsof( CMDOP ) intersect { OP_INSERT } &&
binsof( CHAIN ) intersect { IN_TAIL_NO_MATCH };
}Для того, чтобы стало ясно что будет анализироваться приведу пример bin для
CMDOP_HISTORY_D2:bin <auto[OP_DELETE],auto[OP_SEARCH],auto[OP_SEARCH],auto['b10]>Произойдет попадание, если:
- сейчас команда
OP_SEARCH, - прошлая команда была
OP_SEARCHв корзину, отличную от текущей - позапрошлая команда была
OP_DELETEв корзину, которая совпадает с текущей
До всех фиксов у меня были написаны руками три простых теста. Запустим их:
Coverpoint cg::CMDOP 100.0% 100 Covered
Coverpoint cg::CMDRES 85.7% 100 Uncovered
Coverpoint cg::CMDOP_D1 100.0% 100 Covered
Coverpoint cg::CMDOP_D2 100.0% 100 Covered
Coverpoint cg::CMDRES_D1 85.7% 100 Uncovered
Coverpoint cg::CMDRES_D2 85.7% 100 Uncovered
Coverpoint cg::CHAIN 100.0% 100 Covered
Coverpoint cg::BUCK_HIST_MASK 100.0% 100 Covered
Coverpoint cg::BUCKOCUP 100.0% 100 Covered
Cross cg::CMDOP_BUCKOCUP 100.0% 100 Covered
Cross cg::CMDRES_BUCKOCUP 84.6% 100 Uncovered
Cross cg::CMDOP_HISTORY_D2 18.5% 100 Uncovered
covered/total bins: 20 108
missing/total bins: 88 108
Cross cg::CMDRES_HISTORY_D2 3.1% 100 Uncovered
covered/total bins: 27 864
missing/total bins: 837 864
Cross cg::CMDOP_CHAIN 84.6% 100 Uncovered (остальной лог я убрал, т.к. он очень большой)
Как видим, у точек с
HISTORY отвратительное покрытие (18.5% и 3.1%). Три теста, написанные руками, не смогли дать нужного разнообразия.Почему я анализирую только три последних результата, включая текущее?
Это число взято наугад. Разумеется, чем больше, тем лучше, но и чем больше получается вариантов, тем больше тестов нужно будет для 100% покрытия.
Где здесь грань и какое самое оптимальное число для анализа — я не знаю. Наверно, это значение должно равнятся задержке модуля в количестве команд в худшем случае (порядка 5 или 6 специально это число я не считал).
Выводы:
- coverage ваш друг и союзник. Без лишних затрат он смотрит на те точки, которые вы указали и подсчитывает статистику. Можно автоматически сделать сочетания между различными переменными и проверить, что во всех возможных комбинациях эти переменные появляются.
- чем в больших ситуациях побывает модуль, тем больше вероятность нахождения ошибки.
- если вам доступен RTL, который тестируете (белый ящик), то подумайте какие граничные ситуации там бывают. Предусмотрите это в bin'ах для анализа.
Нет рандомизированного теста
При верификации сложных и больших систем необходимо убедится, что покрываются или почти все варианты.
Вручную сложно сделать все варианты. Выход — рандомизированное тестирование. Но просто генерировать случайные данные на входе, не самая лучшая идея: есть методика Constrained Random Verification.
Да, мы подаем случайные значения, но они чем-то ограничены, либо подчиняются какому-то простому (или не очень) закону, для воспроизведения того, что вам надо.
Сделаем функцию, которая дает нам случайный ключ в нужном диапазоне корзин и значения ключей:
function bit [KEY_WIDTH-1:0] gen_rand_key( int min_bucket_num = 0,
int max_bucket_num = ( 2**BUCKET_WIDTH - 1 ),
int max_key_value = ( 2**( KEY_WIDTH - BUCKET_WIDTH ) - 1 ) );
bit [BUCKET_WIDTH-1:0] bucket_num;
bit [KEY_WIDTH-1:0] gen_key;
if( hash_table::HASH_TYPE != "dummy" )
begin
$display("%m: hash_type = %s not supported here!", hash_table::HASH_TYPE );
$fatal();
end
bucket_num = $urandom_range( max_bucket_num, min_bucket_num );
gen_key = $urandom_range( max_key_value, 0 );
// replace high bits by bucket_num (is needs in dummy hash)
gen_key[ KEY_WIDTH - 1 : KEY_WIDTH - BUCKET_WIDTH ] = bucket_num;
return gen_key;
endfunctionТеперь сгенерируем случайные транзакции для корзин
[0;15] и значений ключей [0;7].// testing small amount of buckets with random commands
task test_05( );
ht_command_t cmds[$];
$display("%m:");
for( int c = 0; c < 5000; c++ )
begin
`CMD_SEARCH ( gen_rand_key( 0, 15, 7 ) )
`CMD_INSERT_RAND ( gen_rand_key( 0, 15, 7 ) )
`CMD_DELETE ( gen_rand_key( 0, 15, 7 ) )
end
// взболтать, но не смешивать :)
cmds.shuffle( );
foreach( cmds[i] )
begin
send_to_dut_c( cmds[i] );
end
endtaskКак видим даже это не даёт полного покрытия:
Cross cg::CMDOP_HISTORY_D2 98.1% 100 Uncovered
covered/total bins: 106 108
missing/total bins: 2 108
Cross cg::CMDRES_HISTORY_D2 81.1% 100 Uncovered
covered/total bins: 701 864
missing/total bins: 163 864Если посмотреть, какие bin'ы не покрылись, то станет ясно, что нужен отдельный тест на одну корзину:
// testing only one bucket with random commands
task test_06( );
ht_command_t cmds[$];
$display("%m:");
for( int c = 0; c < 1000; c++ )
begin
`CMD_SEARCH ( gen_rand_key( 0, 0, 7 ) )
`CMD_INSERT_RAND( gen_rand_key( 0, 0, 7 ) )
`CMD_DELETE ( gen_rand_key( 0, 0, 7 ) )
end
cmds.shuffle( );
foreach( cmds[i] )
begin
send_to_dut_c( cmds[i] );
end
endtaskРезультат:
Cross cg::CMDOP_HISTORY_D2 100.0% 100 Covered
covered/total bins: 108 108
missing/total bins: 0 108
Cross cg::CMDRES_HISTORY_D2 99.1% 100 Uncovered
covered/total bins: 857 864
missing/total bins: 7 864 Дополнительно добавил тест, который вставляет огромное количество данных (для того, чтобы создать
rescode=INSERT_NOT_SUCCESS_TABLE_IS_FULL)Примечание:
- конечно, вот такая случайная генерация и shuffle, не самая красивая идея. Действенная и простая в реализации, но не красивая. В SystemVerilog есть специальная конструкция constraint блок: с его помощью можно создавать осмысленные транзакции с нужными ограничениями.
Выводы:
- не забывайте про рандомизированное тестирование. Не подавайте просто случайные данные, лучше предусмотреть несколько тестов, где происходит рандомизация разных параметров.
Нет отслеживания проблем в "реальном" времени
Нюанс этого проекта был в том, что если причина ошибки от следствии может быть отделено огромным симуляционным временем.
При возникновении ошибки (а её детектирование происходит по выходу
ht_res), придется "отматывать" время симуляции, логи и т. д. При больших и сложных системах это может быть трудоёмким процессом.Наша задача как разработчиков (и верификаторов) — найти ошибку как можно ближе по времени и месту (модулю) в котором она расположена.
В этом проекте есть несколько хранилищ:
head_tabledata_tableempty_ptr_storage
Эта бага приводила к тому, что в какой-то из моментов времени данные в таблице становились некорректными.
Если мы сразу же (с точки зрения симуляции) это выясним, то багу будет проще исправить/дебажить.
Выведем правила, которым должны подчиняться данные в таблицах:
head_table:- в нём не могут быть два одинаковых указателя с
ptr_val - указатель с
ptr_valне может указывать на ячейку, которая помечена как empty
data_table:keyдолжно принадлежать этой цепочке/корзине- цепочка не должна образовывать кольцо
next_ptr_valне должен указывать на ячейку, которая помечена как пустая- не должно быть ячеек, на которые никто не ведет (ни от
head_table, ни от какой-либо цепочки) - не должно быть чтений ячеек, которые помечена как пустая
empty_ptr_storage:- модули
data_table_*не должны просить очистить ячейку, если она уже пустая - модуль не имеет права отдавать то, что ячейка пустая, если она такой не является (не была очищена ранее).
Комментарий к любому моменту времени:
- есть небольшой нюанс, что в какой-то момент времени таблица всё-таки может быть неконсистентна. (Например при вставке, требуется модификация двух ячеек — после первой записи данные не консистентны). Проверять таблицу мы будем тогда, когда в неё не пишут.
Был написан
tables_monitor, который в себе содержит референсные модели head_table, data_table, empty_ptr.Так же там написана функция, которая обходит таблицы и проверяет на те условия, которые мы описали ранее. Файл полностью можно глянуть тут.
Откатим фикс для воспроизведения баги и посмотрим лог:
...
1195: top_tb.dut.d_tbl.del_eng.print: opcode = OP_DELETE key = 0x01000000 value = 0x0000 head_ptr = 0x001 head_ptr_val = 0x1
1195: top_tb.dut.d_tbl.del_eng.print: IDLE_S -> READ_HEAD_S
1225: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x001 key = 0x01001000 value = 0x1235 next_ptr = 0x002 next_ptr_val = 0x1
1225: top_tb.dut.d_tbl.del_eng.print: READ_HEAD_S -> GO_ON_CHAIN_S
1255: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x002 key = 0x01000001 value = 0x3ff2 next_ptr = 0x000 next_ptr_val = 0x1
1285: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x000 key = 0x01000002 value = 0x5429 next_ptr = 0x004 next_ptr_val = 0x1
1315: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x004 key = 0x01000000 value = 0x1cc0 next_ptr = 0x000 next_ptr_val = 0x0
1315: top_tb.dut.d_tbl.del_eng.print: GO_ON_CHAIN_S -> KEY_MATCH_IN_TAIL_S
1325: top_tb.dut.d_tbl.del_eng.print: WR: addr = 0x004 key = 0x01000000 value = 0x1cc0 next_ptr = 0x000 next_ptr_val = 0x0
1325: top_tb.dut.d_tbl.del_eng.print: KEY_MATCH_IN_TAIL_S -> CLEAR_RAM_AND_PTR_S
1335: top_tb.dut.d_tbl.del_eng.print: WR: addr = 0x004 key = 0x00000000 value = 0x0000 next_ptr = 0x000 next_ptr_val = 0x0
1335: top_tb.dut.d_tbl.del_eng.print: RES: key = 0x01000000 value = 0x0000 rescode = DELETE_SUCCESS chain_state = IN_TAIL
1335: top_tb.dut.d_tbl.del_eng.print: CLEAR_RAM_AND_PTR_S -> IDLE_S
1335: ht_tb.print: IN_MONITOR: key = 0x01000000 value = 0x0000 rescode = DELETE_SUCCESS chain_state = IN_TAIL
1335: top_tb.dut.d_tbl.empty_ptr_storage.print: add_empty_ptr: 0x004
** Error: ERROR: addr = 0x004. This addr is empty, but ptr is val
Time: 1340 ns Scope: top_tb.tm.check_one_addr File: ../tb/tables_monitor.sv Line: 119
** Error: ERROR: addr = 0x004 key=0x00000000 don't match bucket_num = 0x01
Time: 1340 ns Scope: top_tb.tm.check_one_addr File: ../tb/tables_monitor.sv Line: 127Оказалось, что ошибка детектируется уже на тех трех ручных тестах (без участия рандомизированных)!
Обход ячеек показал:
- есть указание на адрес 0x004, хотя референсная модель считает, что эта ячейка пустая, т.к. на 1335 нс её освободили.
- в ячейке 0x004 лежит
key = 0x00000000, который не может принадлежать корзине 0x01 (т.к. используется dummy hash).
Выводы:
- подумайте, какие ситуации не должны происходить при корректной работе. Напишите правила и проверяйте на это! Любое отклонение от нормы явно говорит о неверном (или неожидаемом) поведении.
- очень часто проверки встраивают в интерфейсы общения между модулями. Тогда лучше использовать такую конструкцию как assertion.
Заключение
Дураки говорят, что они учатся на собственном опыте, я предпочитаю учиться на опыте других. (Отто фон Бисмарк)
В этой статье я рассказал из чего может состоять простой тестбенч для верификации простых IP-ядер для ASIC/FPGA в разрезе проекта хеш-таблицы.
Исходники:
Главной своей ошибкой я считаю то, что не доделал до конца проект в своё время. План по верификации у меня был, и там были отмечены часть идей, которые мы и реализовали в этой статье.
Надеюсь, статья была интересна начинающим RTL-разработчикам, которые хотят улучшить свои тестбенчи.
Делитесь в комментариях, какой болезненный опыт был у вас при верификации RTL-кода :)
Спасибо за внимание! Буду рад вопросам и замечаниям в комментариях или в личной почте.
P.S.:
Это мой первый пост
Подскажите, пожалуйста:
- почему не подсвечивается адекватно код, хотя я ему указал
systemverilog? GitHub Flavored Markdown вроде как должен знать это... - почему тэг
spoilerприводит к тому, что весь дальнейший текст не распознается как markdown?
Комментарии (9)
valeriyk
26.02.2016 00:41Вообще в больших проектах то, что ты наваял, верифицирует другой человек. Поэтому у нас, например, ни один синьор стафф архитект ничего никаким UVM-ом не верифицирует, а пишет сам себе какие-то маленькие тестбенчи, после чего шлет специально обученому индусу, который уже облепляет модуль всякими Verification IP и дальше по тестплану гоняет его и шлет гневные письма дизайнеру, когда все в очередной раз сломалось.

Master_Dante
26.02.2016 03:56-8Простите но что это за язык на котором вы писали? Конструкции вроде begin — end и C+ конструкции в одном флаконе смущают. Как правило, когда речь идет об алгоритмах, указывают язык и платформу. Спасибо за то, что сегодня я узнал новую аббревиатуру FPGA.

Sevlyar
26.02.2016 06:13+5как можно организовать хеш-таблицу на FPGA
В качестве HDL-языка использовался SystemVerilog и корпоративный кодинг стайл.
Master_Dante
27.02.2016 12:09-2Обычно язык указывается до листингов… Делали ли вы замер производительности? В C# Dictionary делает миллион вставок за ~45 микросекунд(core i7 920). Мне интересно как быстро это делает FPGA?

Des333
27.02.2016 13:27- Вы задаёте вопрос не автору статьи.
- Если не затруднит, можно ссылку на описание измерений с C#? Честно говоря, не очень верится.

ishevchuk
27.02.2016 19:24+2Замера производительности я не делал.
Я модуль писал для себя, чтобы размять руки в свободное время, и в продакшене не планировал использовать.
Цели обогнать какие-то готовые библиотеки (С, C#, Java) я не ставил, потому что области применения немного разные ;)
Статья рассказывает о подходе к написанию RTL-кода и его верификации. Производительность в этом плане уходит на второй план.
По поводу производительности:
- Зависит от чипа (цены на них от 30$ до 20к$). Не на порядок, но в 3-7 раз точно.
- Сейчас неоптимимально сделан модуль empty_ptr_storage, и из-за этого просадится частота.
- Мне важно было сделать так, что если нет коллизий, то модуль готов принимать задание на поиск каждый такт. Грубо говоря, если тактовая частота модуля будет 100 МГц, то он сможет делать 100 миллионов поисков в секунду.
- Я сделал, что в одной ячейке data_table хранится только одно слово. Если происходят коллизии, то это слишком стопит операции. Если в одной ячейке разместить сразу четыре ключа, то тогда если в цепочке четыре ключа или меньше, можно сравнения делать в параллель и не делать дополнительных чтений.
У меня еще есть пара идей, что надо доделать и в проекте. Когда это сделаю, то может сделаю какое-то измерение производительности.
Про C#:
45 мкс = 45000 нc -> 0.045 нс = 45 ps на одну вставку. Если взять тактовую частоту 2.66 ГГц (я посмотрел на сайте Интела), что составляет период 376 ps, то как-то не верится, что можно сделать ~8 вставок за один такт :)
nerudo
26.02.2016 10:34[Ехидно] Вот, даже у обычных людей вызывает вопросы c++ с бегинами и ендами! ;-)
valeriyk
Бесплатный альтеровский модельсим каверыдж ведь не считает?
Вообще нужно студентов учить разработке на FPGA вот так:
nerudo
Красиво, но абсолютно бессмысленно. 5 только за счет дикого везения кто-то получит. Даже для опытных разработчиков задача непростая.