

Скачать пост в виде документа Mathematica, который содержит весь код использованный в статье, вместе с дополнительными файлами, можно здесь (архив, ~147 МБ).
Анализ социальных сетей и всевозможных медиа-ресурсов является сейчас довольно популярным направлением и тем удивительнее для меня было обнаружить, что на Хабрахабре, по сути, нет статей, которые содержали бы анализ большого количества информации (постов, ключевых слов, комментариев и пр.), накопленного на нем за довольно большой период работы.
Надеюсь, что этот пост сможет заинтересовать многих участников Хабрахабра. Я буду рад предложениям и идеям возможных дальнейших направлений развития этого поста, а также любым замечаниям и рекомендациям.
В посте будут рассматриваться статьи, относящиеся к хабам, всего в анализе участвовало 62000 статей из 264 хабов. Статьи, написанные только для корпоративных блогов компаний в посте не рассматривались, а также не рассматривались посты, не попавшие в группу «интересные».
Ввиду того, что база данных, построенная в посте, формировалась за некоторое время до публикации, а именно 26 апреля 2015 г., посты, опубликованные на Хабрахабре после этой даты (а также, возможно, новые хабы) в данном посте не рассматривались.
Оглавление
Импорт списка хабов
Импорт ссылок на все статьи Хабрахабра
Импорт всех статей Хабрахабра
Функции извлечения конкретнных данных из символьного XML представления поста
Создание базы данных постов Хабрахабра с помощью Dataset
Результаты обработки данных
— Краткий анализ хабов
— Граф связей хабов на Хабрахабре
— Количество статей в зависимости от времени
— Количество изображений (видео), используемых в постах в зависимости от времени
— Облака ключевых слов Хабрахабра и отдельных хабов
— Сайты, на которые ссылаются в статьях на Хабрахабре
— Коды, которые приводят в статьях на Хабрахабре
— Частота встречи слов
— Рейтинг и числа просмотров постов, а также вероятность достижения их определенных значений
— Зависимость рейтинга и числа просмотров поста от времени публикации
— Зависимость рейтинга поста от его объема
Заключение
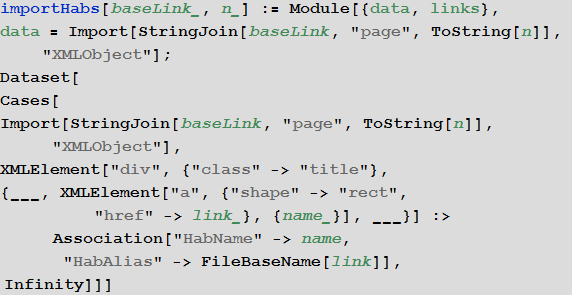
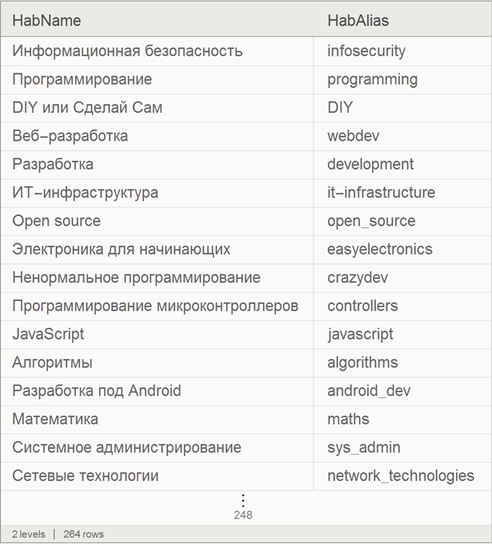
Импорт списка хабов
Импортируем список хабов и представим их в виде встроенного формата баз данных Dataset для удобства дальнейшей работы.
Импорт ссылок на все статьи Хабрахабра
Функция импорта ссылки с n-й страницы некоторого хаба:
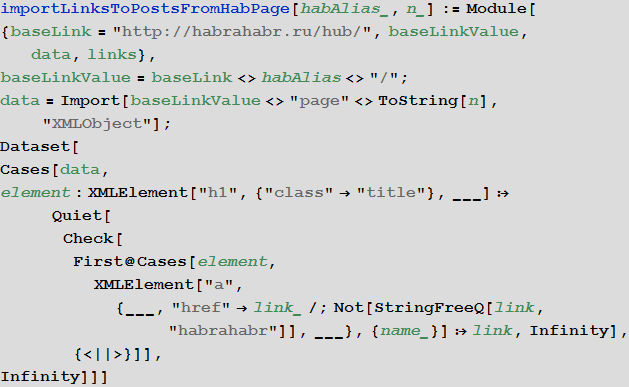
Функция импорта ссылок на все статьи, находящиеся в некотором хабе:

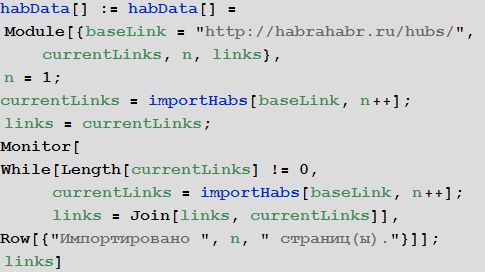
Функция импорта ссылок на все посты из всех хабов (кроме корпоративных блогов):
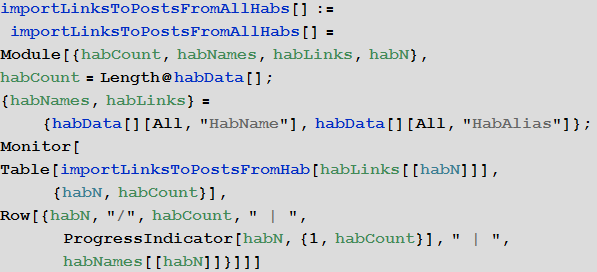
Импорт с сохранением в бинарный дамп-файл Wolfram Language (для последующего мгновенного использования) ссылок на все посты из всех хабов:
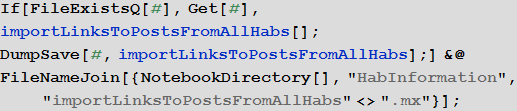
Импорт всех статей Хабрахабра
Всего в базе ссылок на посты:
При этом, среди них довольно много дублей, что связано с тем, что один и тот же пост часто относится к разным хабам. Всего дублирующихся постов ~30,6%, что видно из кода ниже.

Создадим список, состоящий из уникальных ссылок на посты:

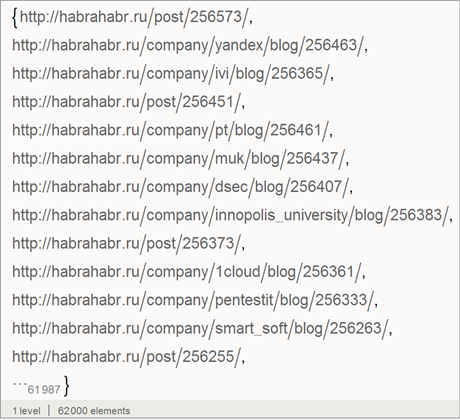
Всего мы имеем 62000 ссылок, которые соответствуют такому же количеству статей.
Создадим функцию, отвечающую за импорт HTML кода веб-страницы (поста) в виде символьного XML объекта (XMLObject) по ссылке на эту страницу, которая на выходе создает серийный пакет .mx языка Wolfram Language.
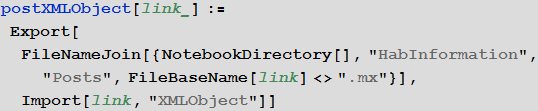
Запустим загрузку всех постов:

После окончания загрузки мы получим 62000 файлов на жестком диске:
Функции извлечения конкретных данных из символьного XML представления поста
После того, как мы подгрузили все посты с Хабрахабра в формате символьных XML объектов, нам потребуется извлечь из них интересющую нас информацию. Для этого мы создадим ряд функций, представленных ниже.
Заголовок поста

Список хабов, в которых опубликован пост

Дата и время публикации поста в формате абсолютного времени (для удобства дальнейшей работы).

Рейтинг поста

Количество просмотров поста

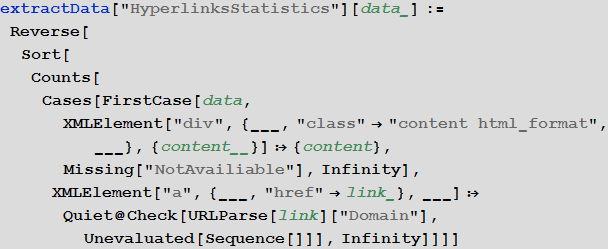
Статистика гиперссылок, приведенных в посте
Количество изображений, использованных в посте

Количество комментариев к посту

Количество видео, вставленных в пост

Текст поста в стандартизованной форме (устранены абзацы, все буквы сделаны прописными)
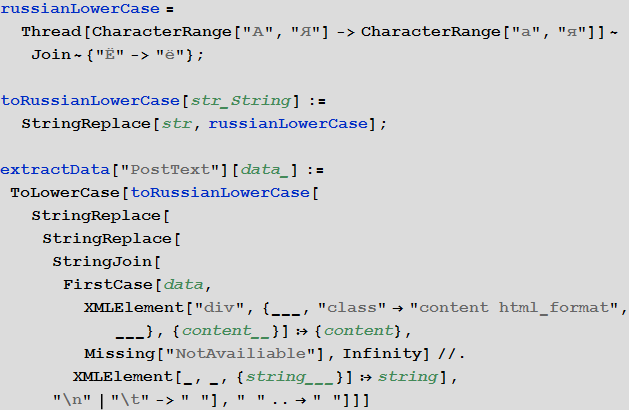
Статистика кодов, приведенных в посте

Ключевые слова

Создание базы данных постов Хабрахабра с помощью Dataset
В ряде случаев, доступ к постам закрыт по разным причинам. При этом, если перейти по соответствующей ссылки, можно увидеть страницу такого рода:

Создадим функцию, отсеивающую такие страницы:

Теперь подгрузим пути до всех файлов .mx, в которых хранятся посты:

И удалим закрытые:
Всего было удалено около 0,5% постов, являющихся закрытыми:
Создадим функцию, которая будет создавать строку базы данных о постах Хабрахабра, которую мы получим ниже. Мы сделаем это с помощью созданных ранее функций, а также функции Association.

Наконец, сформируем с помощью функции Dataset базу данных постов Хабрахабра:
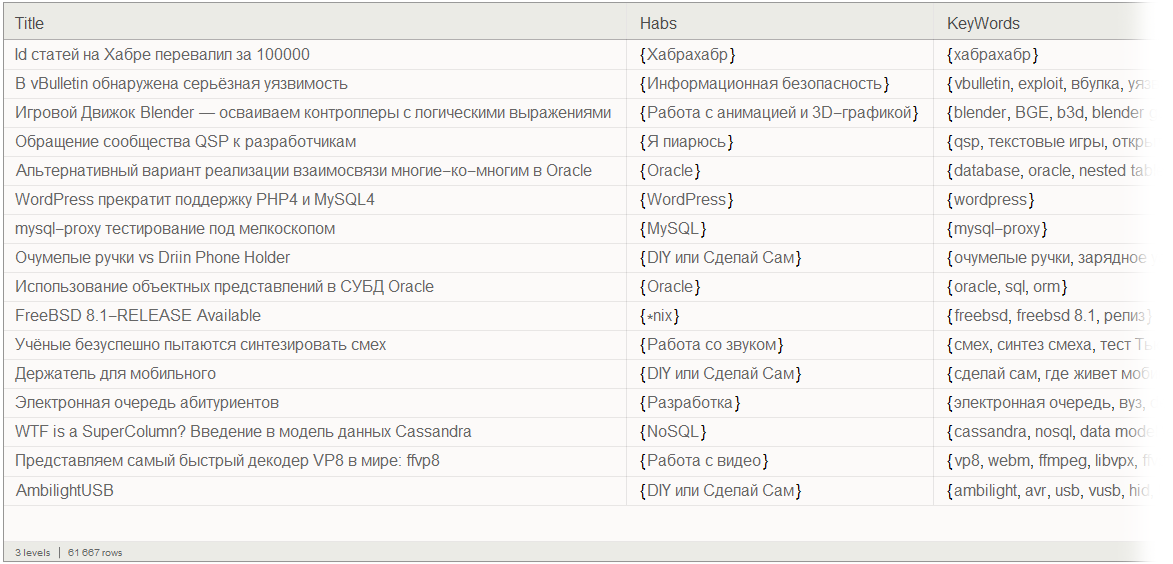
Результаты обработки данных
Краткий анализ хабов
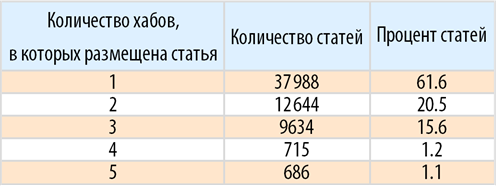
Найдем распределение количества хабов, в которых размещена статья:

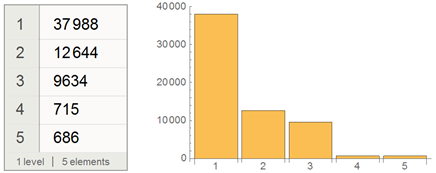
Представим этот фрагмент Dataset в виде таблицы:

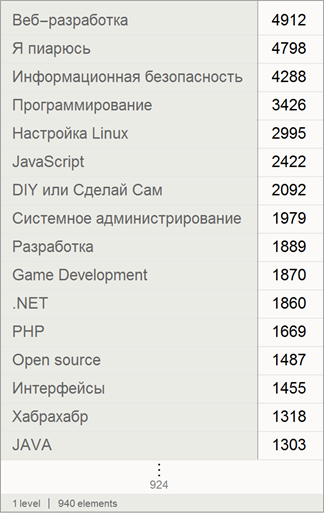
Найдем самые большие Хабы по количеству статей:
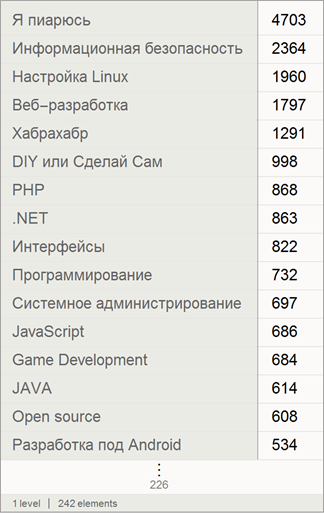
Если рассмотреть только уникальные статьи (относящиеся только к одному хабу, то картина несколько изменится):

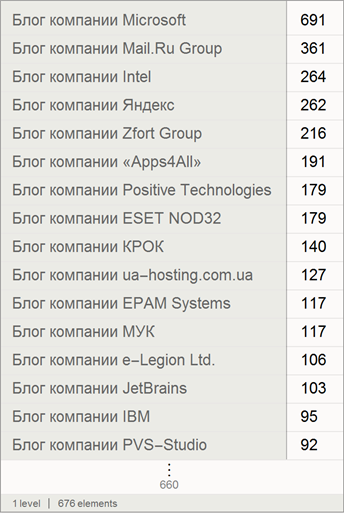
Также, найдем количество постов компаний (здесь не учитываются посты, написанные компанией только для своего блога):

Граф связей хабов на Хабрахабре
Создадим функцию, вычисляющую меру схожести двух хабов по спискам постов, которые в них опубликованы, на основе коэффициента Сёренсена:
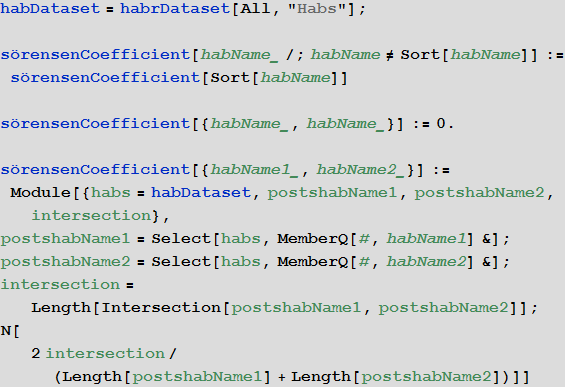
Создадим список всех возможных пар хабов (хабы компаний мы не рассматриваем):
Вычислим для каждой пары хабов их коэффициент сходства:

Создадим списки, задающие ребра графа и их веса:
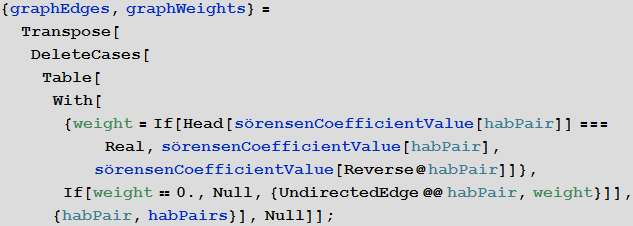
Для раскраски создадим функцию, нормирующую полученные значения коэффициента сходства на отрезок [0; 1]:
Зададим цвет, толщину и прозрачность ребер в зависимости от коэффициента сходства. Чем больше вес ребра, тем оно толще и краснее. Чем его вес меньше, тем оно прозрачнее и тоньше.

Полученный граф интерактивен, при наведении на каждую из вершин можно увидеть ее название.
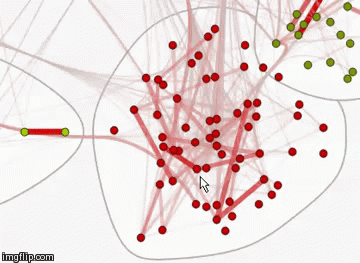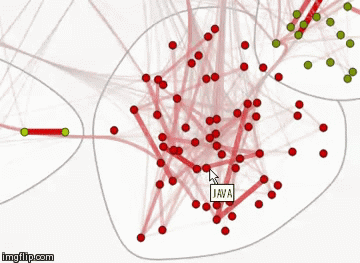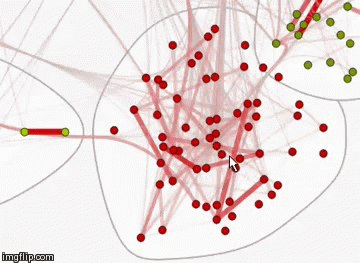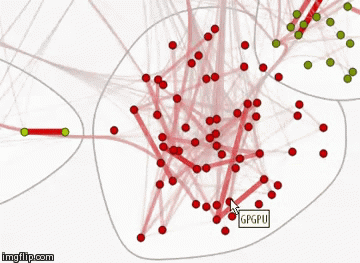

Можно также изменить стиль этого графа, отобразив названия вершин. Посмотреть этот граф в натуральном размере можно по ссылке (изображение, 12 МБ).
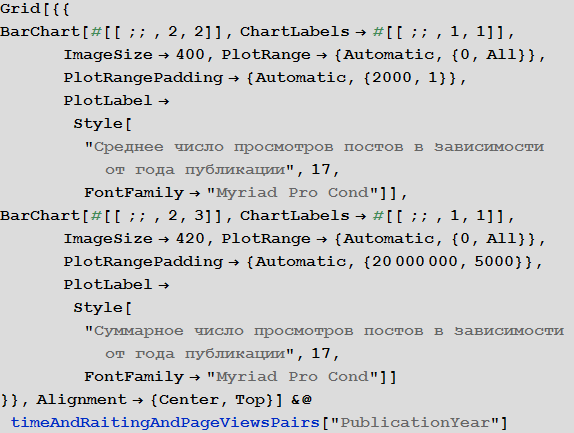
Количество статей в зависимости от времени
Создадим функцию, визуализации количества опубликованных статей как на всем Хабрахабре, так и в некотором хабе:
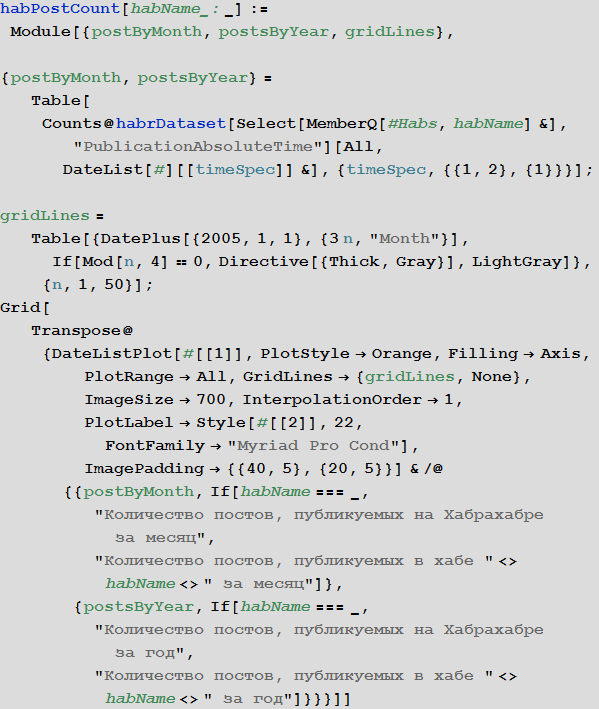
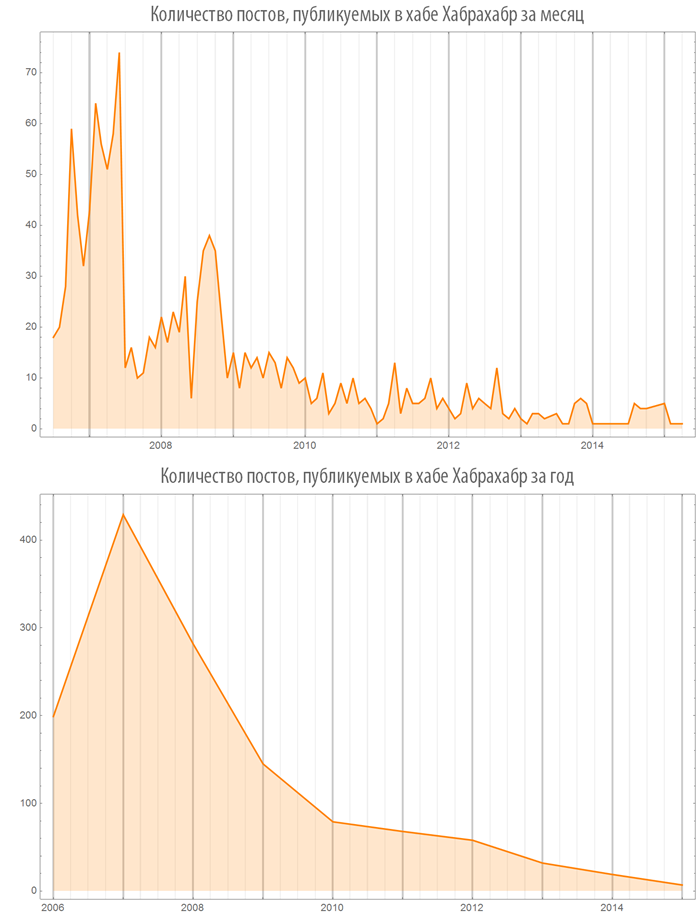
Посмотрим на результаты ее работы. Из полученных графиков видно, что в настоящий момент, по-видимому, наблюдается выход количества публикуемых в год на Хабрахабре постов на плато, приближаясь к значению 11000 постов в год.
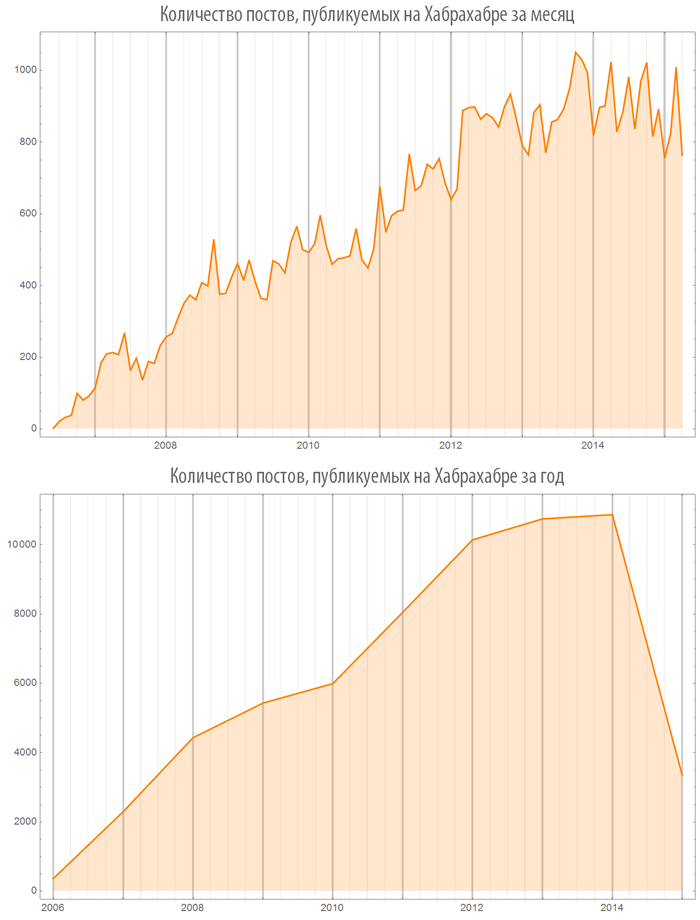
Начиная с 2012 года наблюдается стремительный рост публикаций в хабе “Математика”:
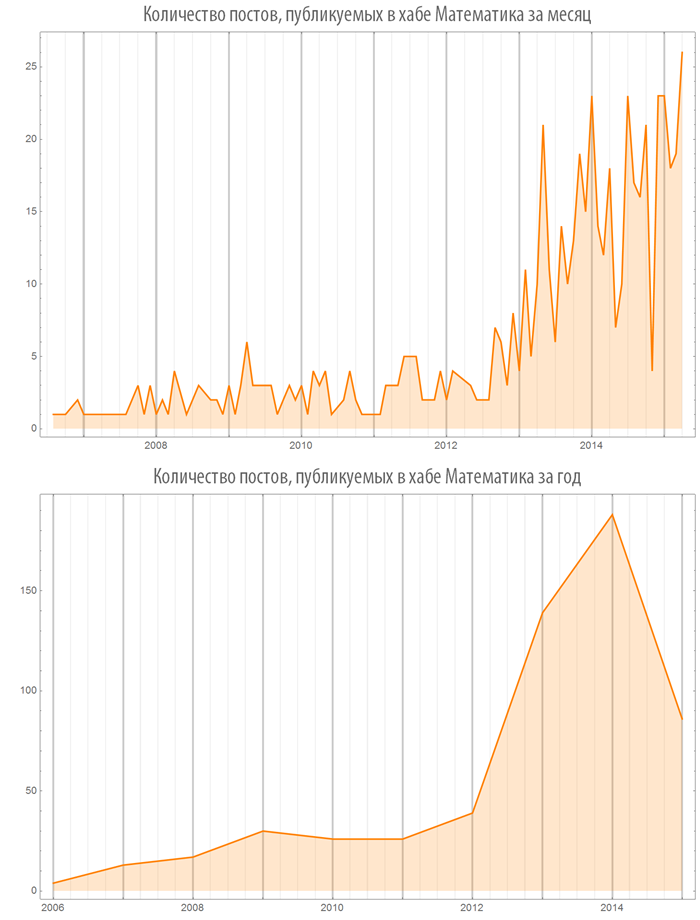
С 2011 года можно наблюдать затухание интереса к Flash:
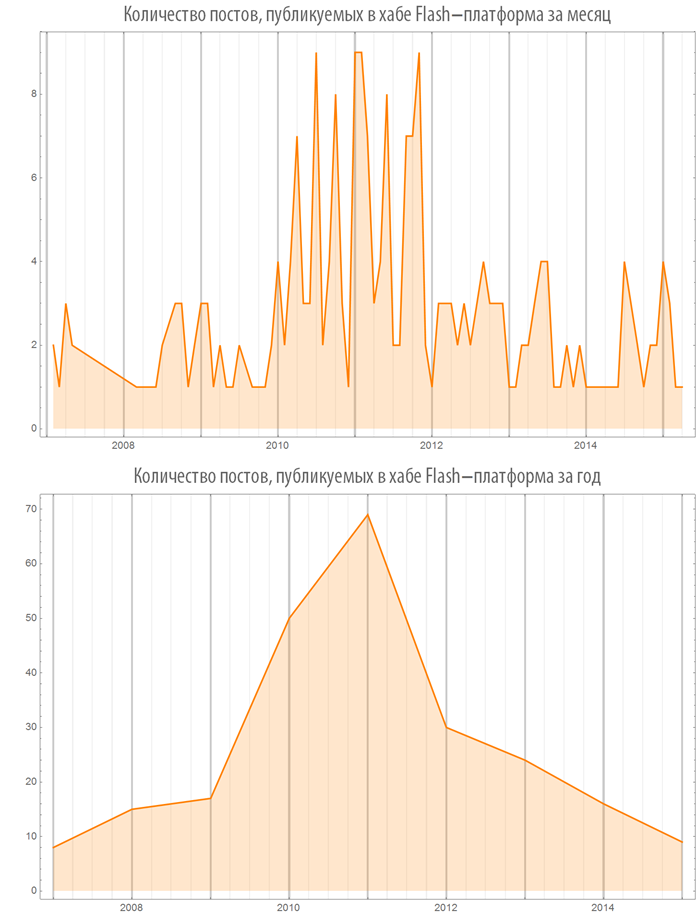
В то же время, с 2010 года хаб “Game Development” растет просто как на дрожжах:
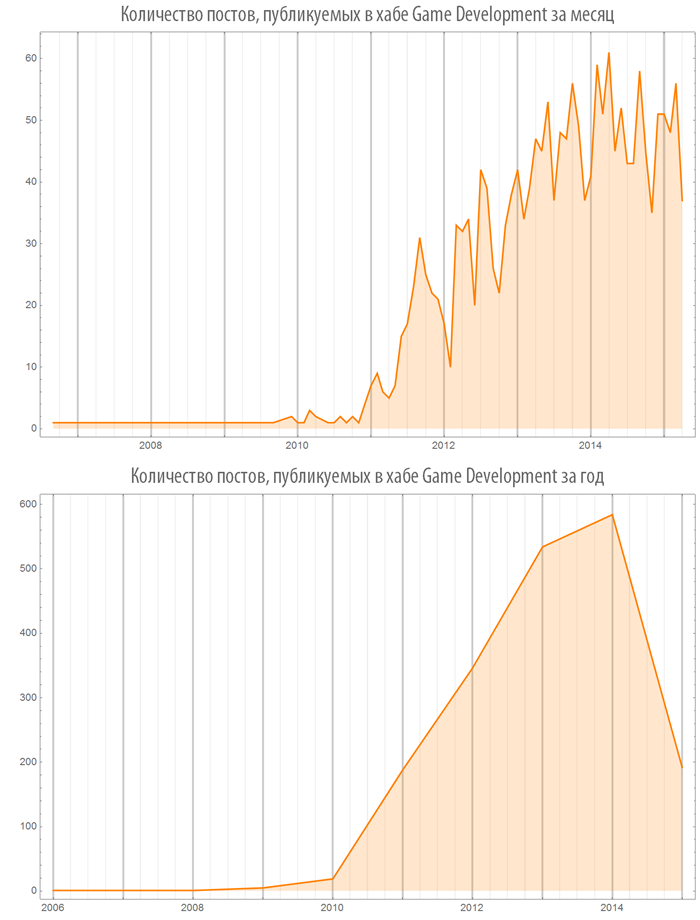
Что интересно, в хаб “Хабрахабр” поступает все меньше статей.
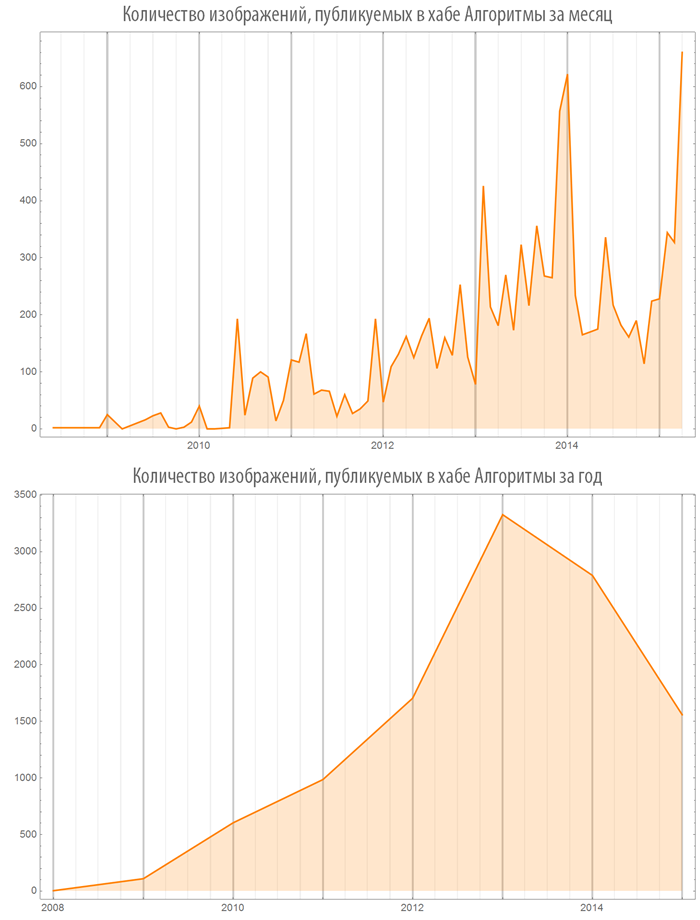
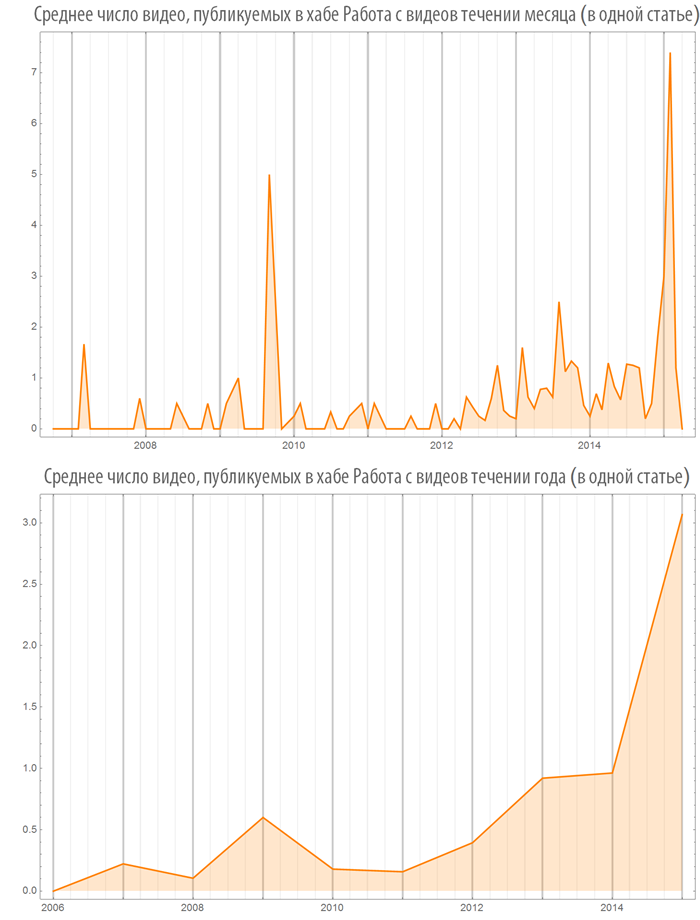
Количество изображений (видео), используемых в постах в зависимости от времени
Создадим функцию, визуализации количества изображений (или видео), в опубликованных постах, как на всем Хабрахабре, так и в некотором хабе:

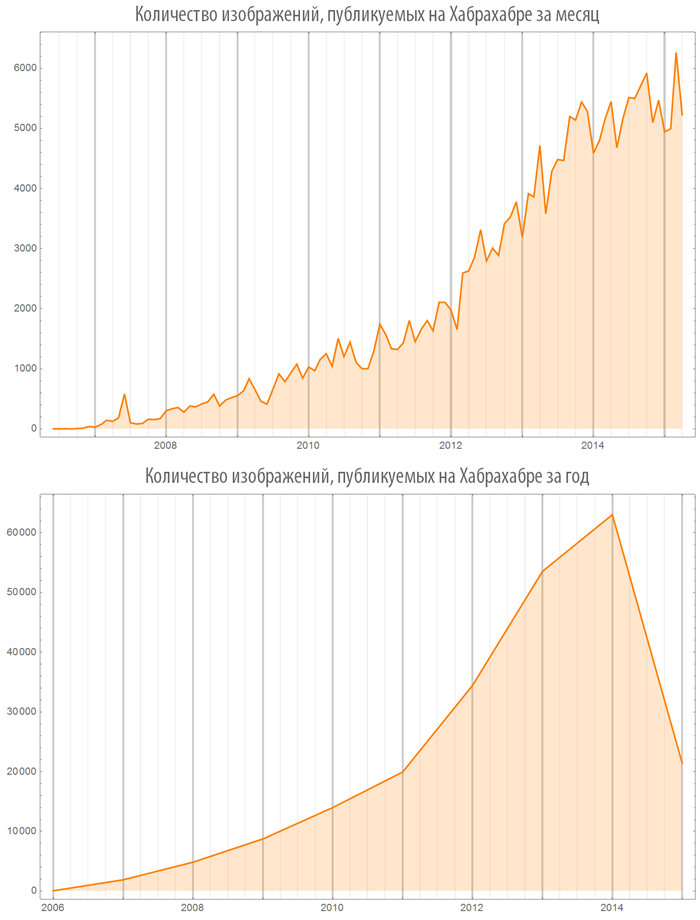
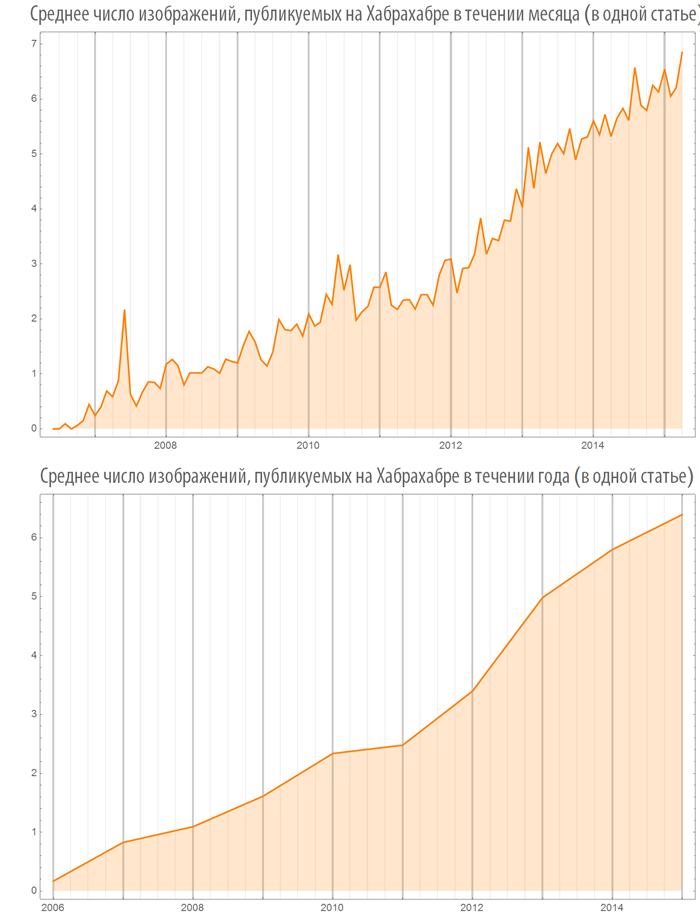
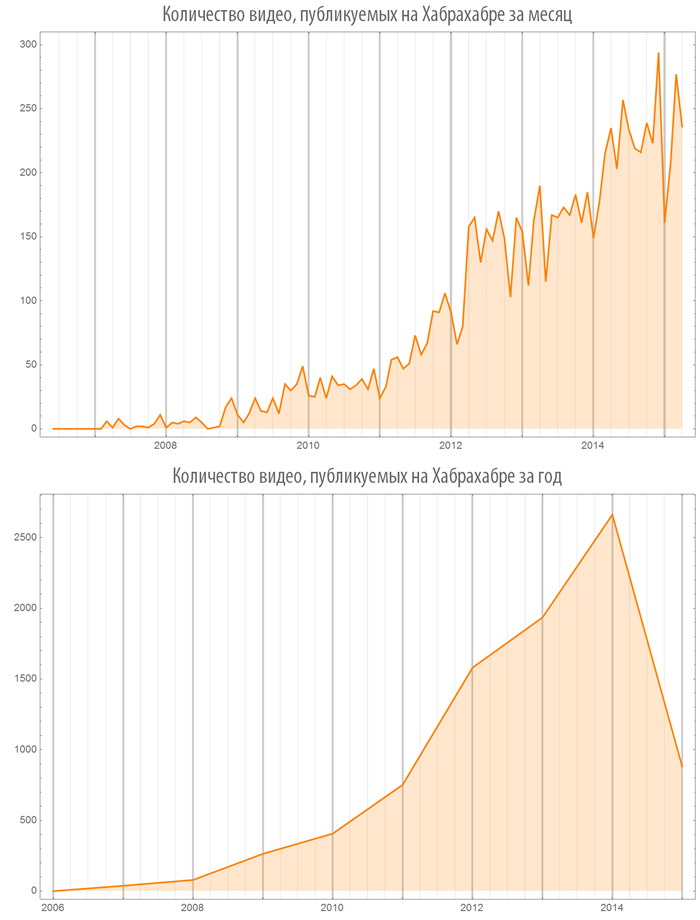
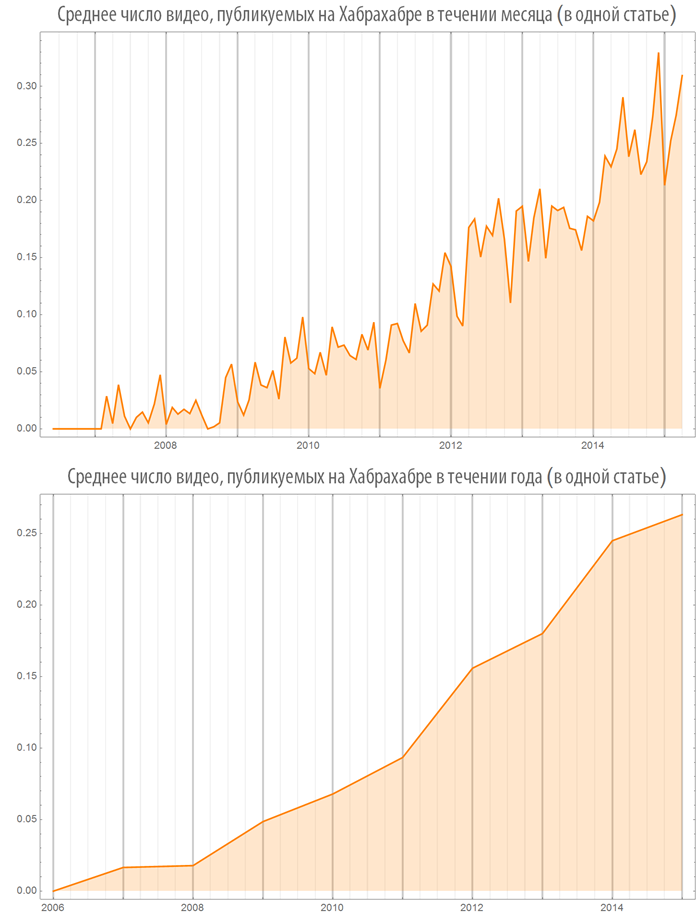
Посмотрим на некоторые хабы:
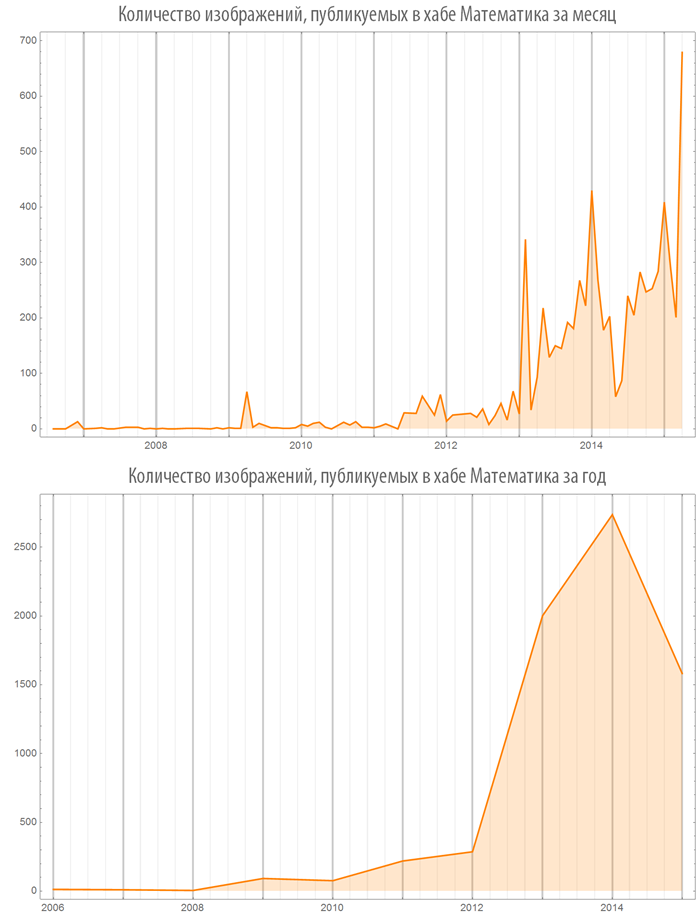
Облака ключевых слов Хабрахабра и отдельных хабов
Найдем список количеств употребления ключевых слов среди всех анализируемых постов на Хабрахабре:
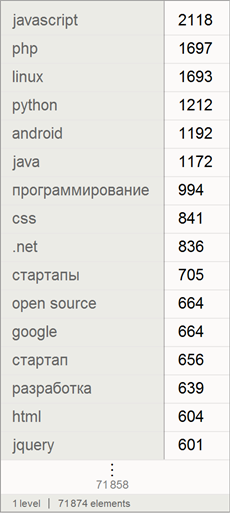
Выберем 150 наиболее распространенных среди них:

Создадим из них облако слов, в котором размер слова (или словосочетания) прямо пропорционален количеству его указаний:

Мы также можем создать из некоторой строки маску:


и сделать на ее основе облако слов, содержащее уже 750 самых распространненных ключевых слов (словосочетаний):


Можно также сделать облако слов в любой форме:

Теперь создадим функцию, которая будет визуализировать облака самых популярных ключевых слов некоторого хаба (по умолчанию будет использоваться 100 слов):
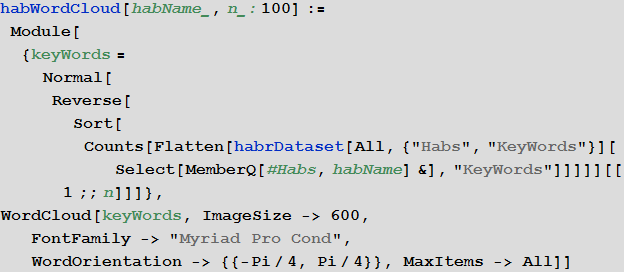
100 ключевых слова хаба “Математика”:

30 ключевых слов хаба “Математика”:

Ключевые слова хаба “Программирование”:
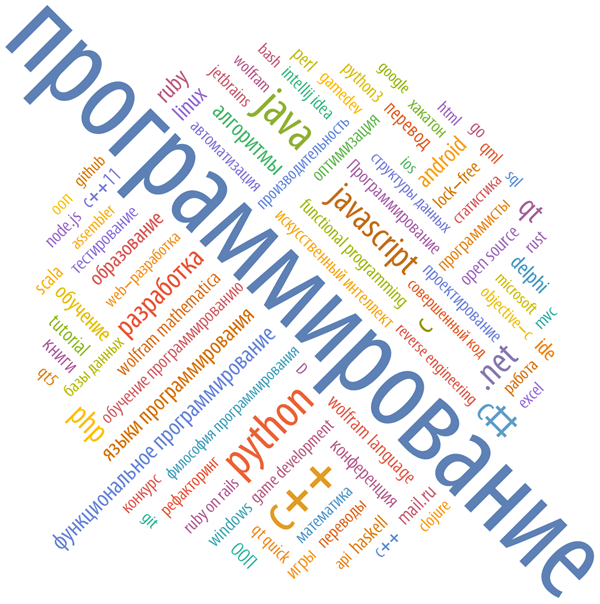
Ключевые слова хаба “JAVA”:

200 ключевых слов хаба “Open source”:

Сайты, на которые ссылаются в статьях на Хабрахабре
Создадим функцию, которая будет показывать сайты, на которые чаще всего ссылаются как на Хабрахабре вообще, так и в некотором хабе:

Найдем сайты, на которые чаще всего ссылаются на Хабрахабре:

Картина становится яснее, если убрать главный источник ссылок — сам Хабрахабр.

Найдем сайты, на которые чаще всего ссылаются в хабе “Математика” (при этом мы везде удалим сам Хабрахабр, так как на него всюду ссылаются, что очевидно, чаще всего):
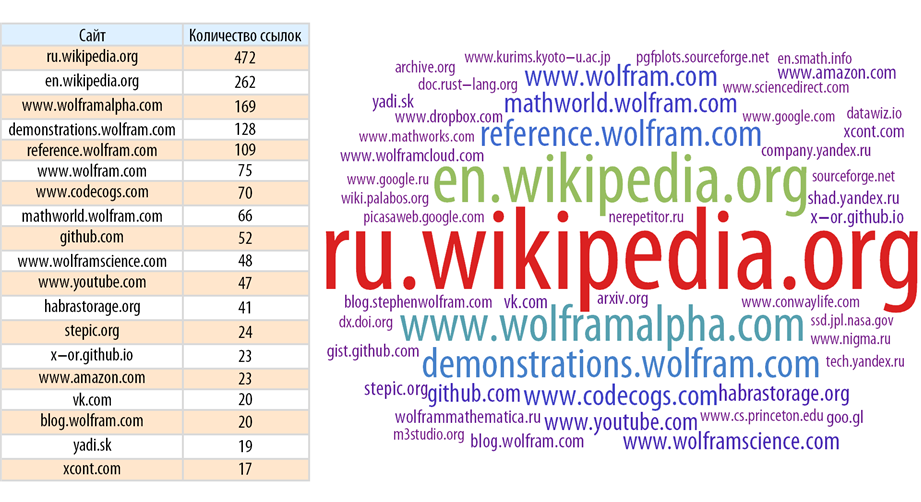
Теперь посмотрим, скажем, на хаб “Разработка под iOS”:

А вот хаб “.NET”:

Коды, которые приводят в статьях на Хабрахабре
Найдем долю статей, в которых нет вставок кода (здесь возможна серьезная погрешность, так как не всегда код вставляется авторами с помощью специального тэга — скажем, в этом посте он вставлен в виде изображений).
Создадим функцию, которая будет показывать статистику языков вставок кода в посты, как на Хабрахабре вообще, так и в некотором хабе. При этом, если автор не указал код, то такой фрагмент будет помечен названием “SomeCode”. Также, здесь мы не производим обработку названий языков, указанных авторами.
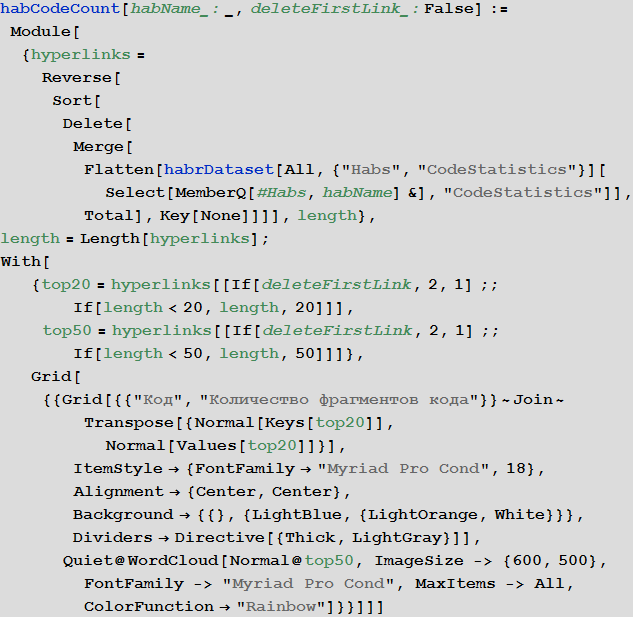
Найдем распределение языков вставок кода для всего Хабрахабра:

Картина станет более ясной, если удалить вставки, у которых не указан язык программирования:

Посмотрим теперь на самые популярные языки программирования вставок кода в хабе “Алгоритмы”:

Хабе “Программирование”:

Хаб “Веб-разработка”:

Хаб “Настройка Linux”:

Хаб “Поисковые машины и технологии”:

Частота встречи слов
Сервис Яндекса “Подбор слов” очень полезен, если вы хотите написать, скажем, статью, которая будет интересна широкой аудитории. Этот сервис позволяет посмотреть частоту поисковых запросов слов. На основе подгруженной информации о статьях Хабрахабра можно сделать некий аналог этого сервиса, выдающий частоту встречи слов (их групп или регулярных выражений) в тексте статей. Это позволяет проследить интерес аудитории к той или иной теме.
Итак, создадим функцию, которая будет выдавать такого рода частоту встречаемости слов:

Теперь можно посмотреть разные вещи, скажем, можно сравнить, какое название ресурса “Хабрахабр” или “Хабр” чаще употребляется на Хабрахабре:
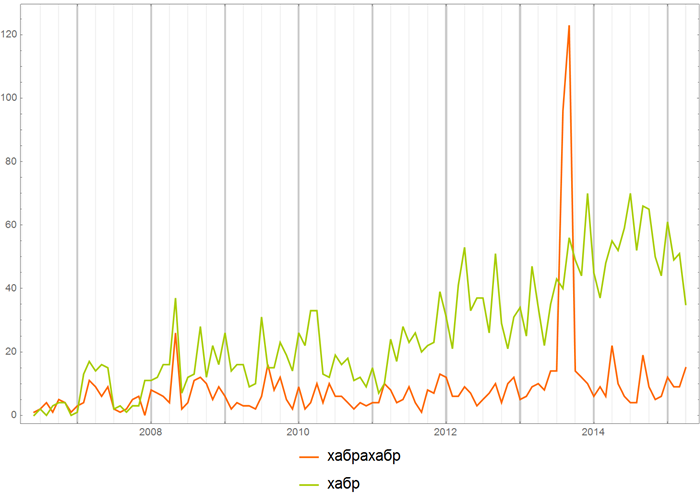
Или же можно сравнить частоту употребления названий различных языков программирования всюду на Хабрахабе:

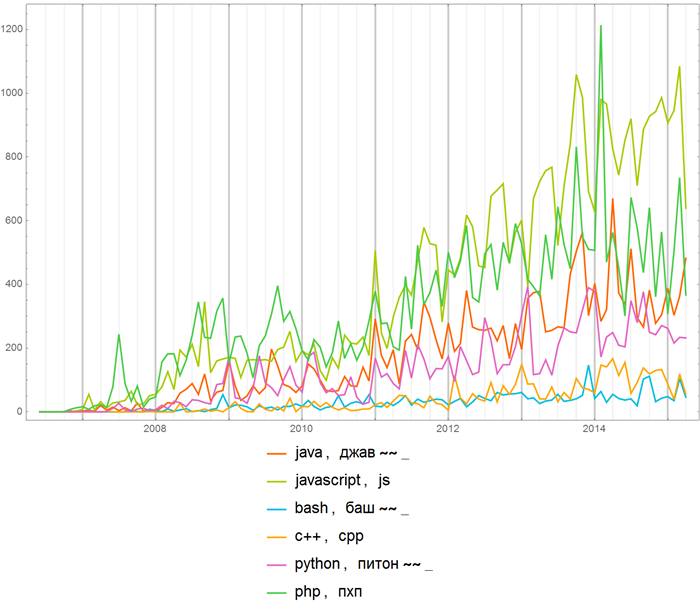
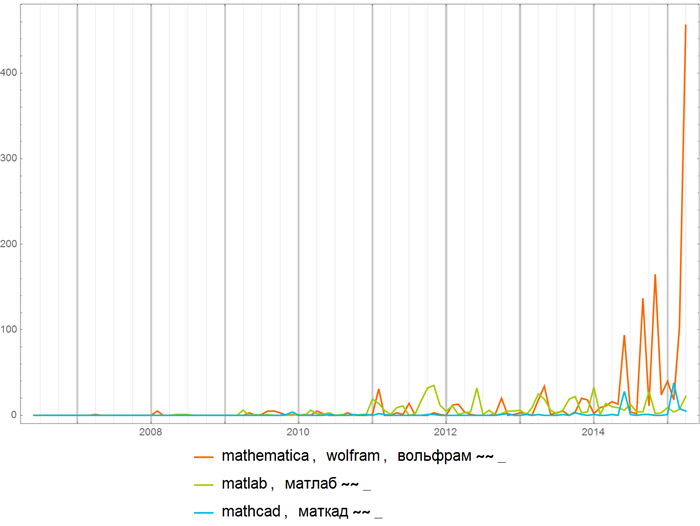
Сравним частоту упоминаний математических пакетов (выражения вида “строка”~~_ (они использовались и в предыдущем примере) позволяют задавать коллекции строк с разными окончаниями, скажем, выражение “вольфрам”~~_ задаст коллекцию строк “вольфрам”, “вольфраму”, “вольфраме” и пр.):

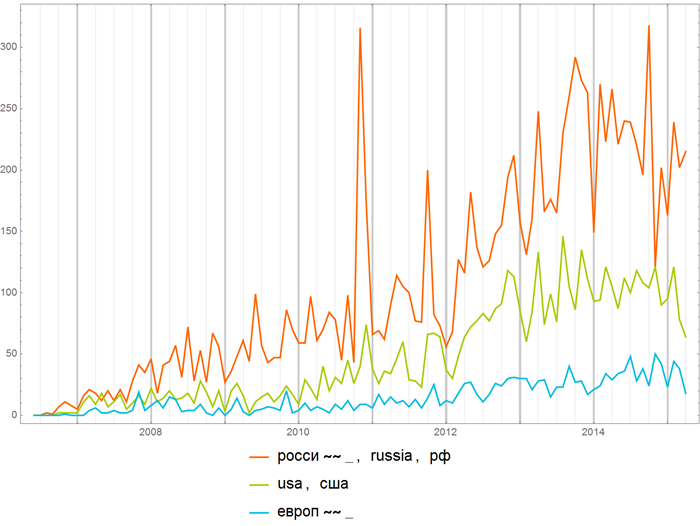
Можно, конечно, интересоваться разными вещами, скажем, узнать частоту встреч слов группы “Россия”, “США” и “Европа”:
Или же можно наблюдать постепенное угасание (заморозку) интереса к какой-то технологии:
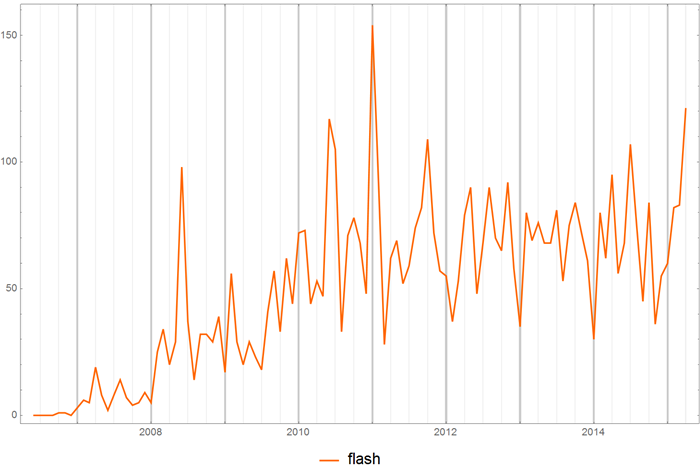
Или рождение новой:
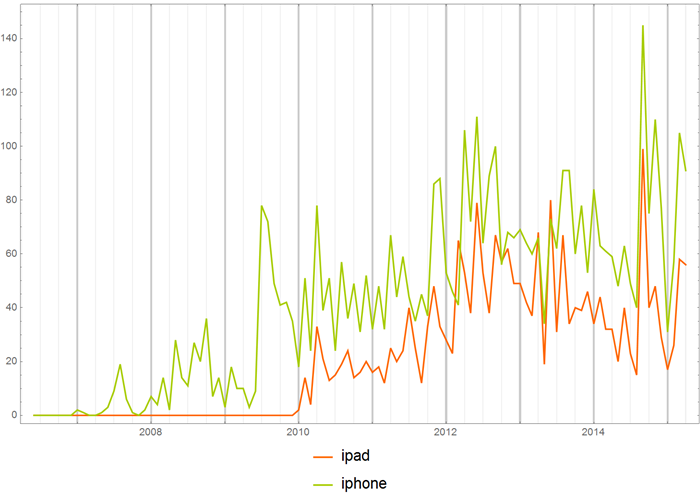
Также можно смотреть на частоту употребления слов в отдельных хабах. Скажем, частота употребления слов “iOS” и “Аndroid” в хабе “Разработка под iOS”.
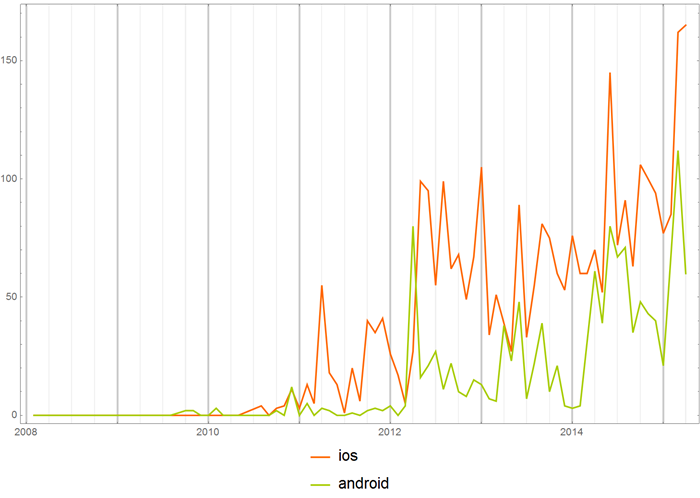
Или те же слова, но в хабе “Разработка под Android”.
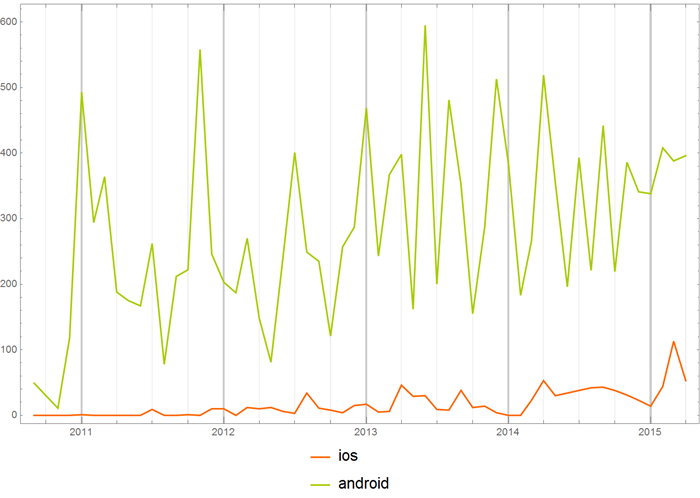
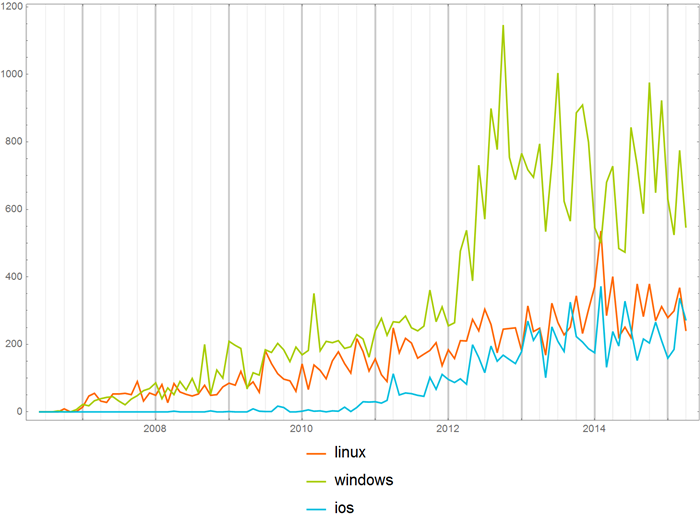
Можно сравнить частоту употребления названий операционных систем в хабе “Open source”:
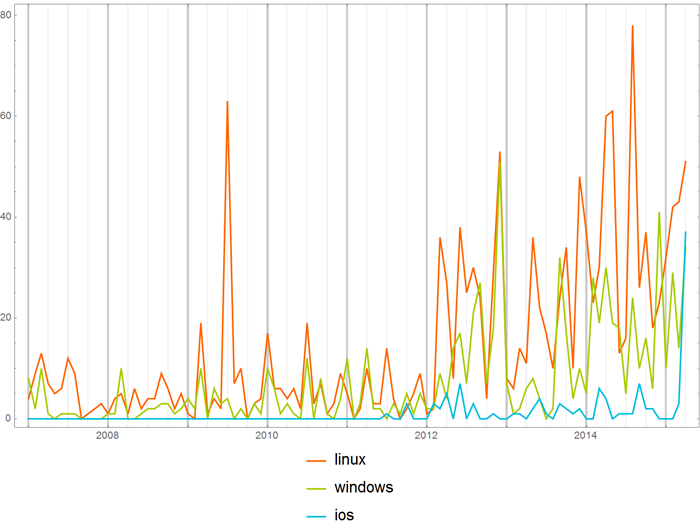
с Хабрахабром в целом:
Рейтинг и числа просмотров постов, а также вероятность достижения их определенных значений
Выделим пары рейтинг поста + числа просмотров поста:


Построим их распределение на плоскости в обычном и логарифмическом масштабах:
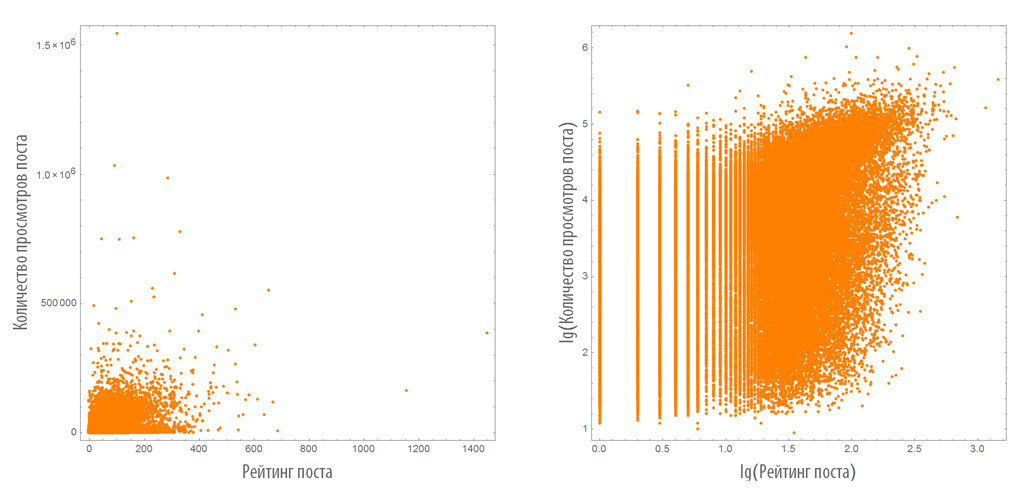
Недостатком этих графиков является то, что они не отражают плотности распределения точек на них.
Построим двумерную и трехмерную плотность распределения рассматриваемых пар:


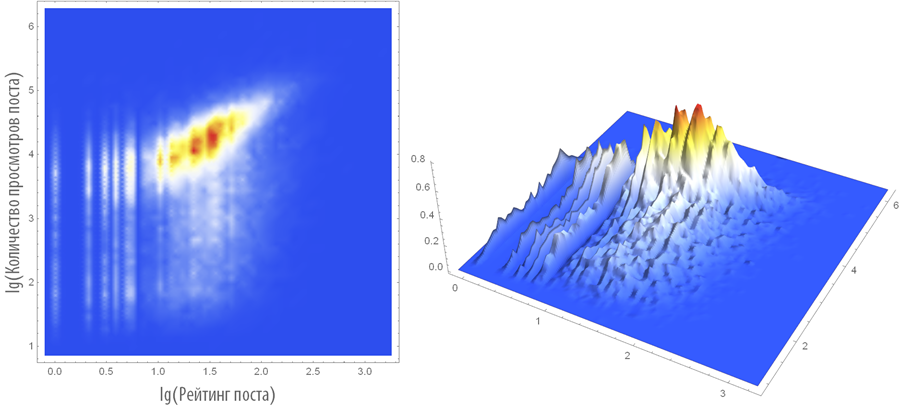
Средний рейтинг поста на Хабрахабре равен 34.5, а среднее количество просмотров 14237.3
Однако, это не статистическая характеристика. Построим распределение пар (создадим распределение двумерной случайной величины):


Найдем математическое ожидание:
А также среднеквадратическое отклонение:
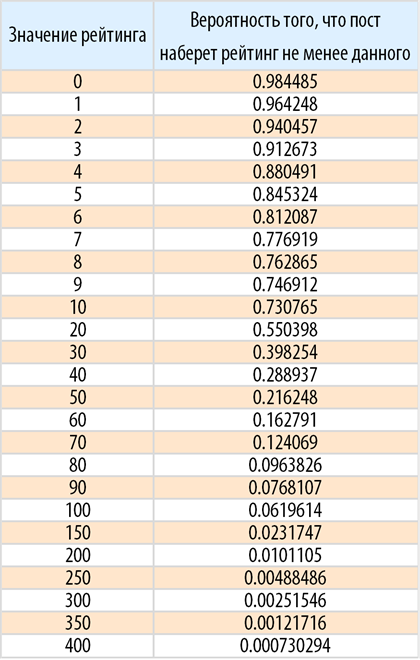
Также можно найти вероятность, например, того, что пост наберет определенный рейтинг:

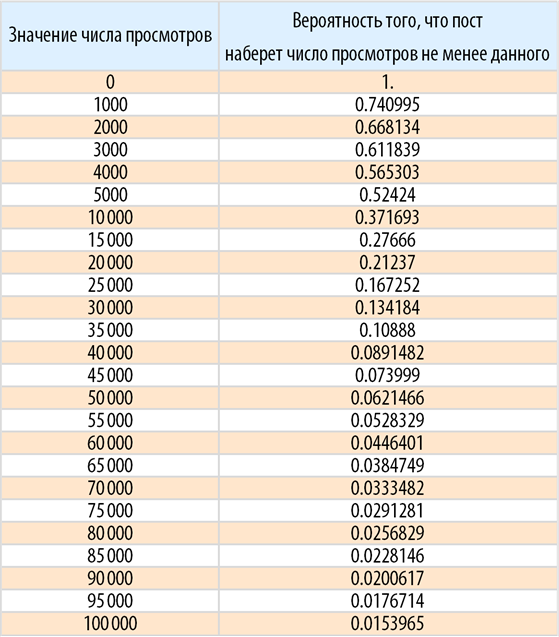
Найдем теперь вероятность, того, что пост наберет определенное число просмотров:

Зависимость рейтинга и числа просмотров поста от времени публикации
Из кода ниже видно, что за все время на Хабре все статьи набрали суммарный рейтинг порядка 2,1 млн., а суммарное количество их просмотров приближается к 1 млрд.:

Выделим тройки время публикации поста + рейтинг поста + количество просмотров поста:
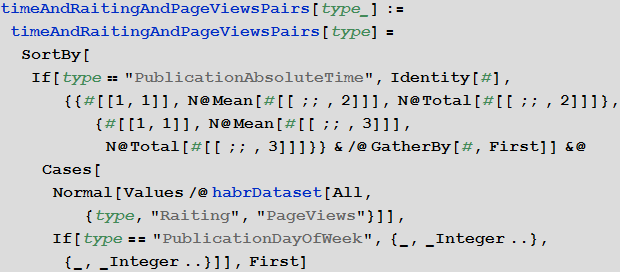
Изучим поведение рейтинга постов в зависимости от времени публикации:
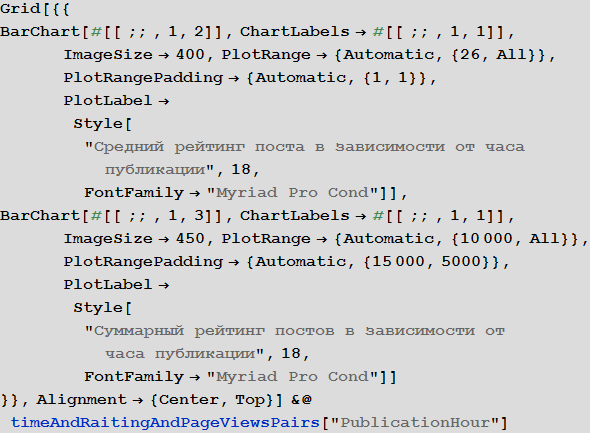
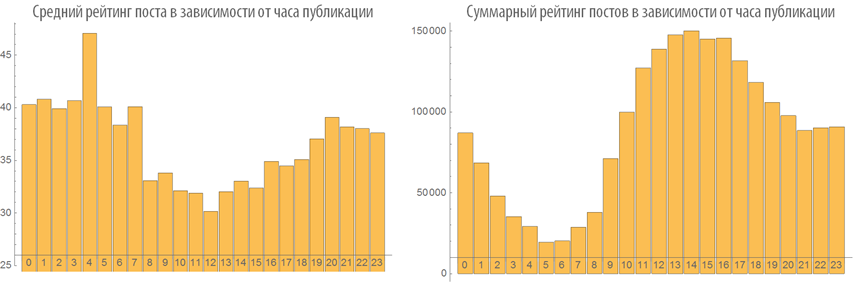
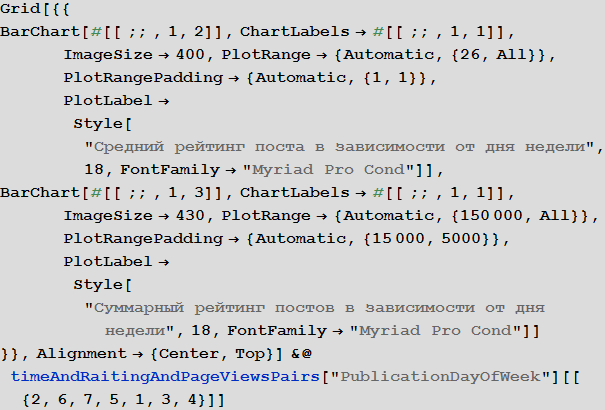
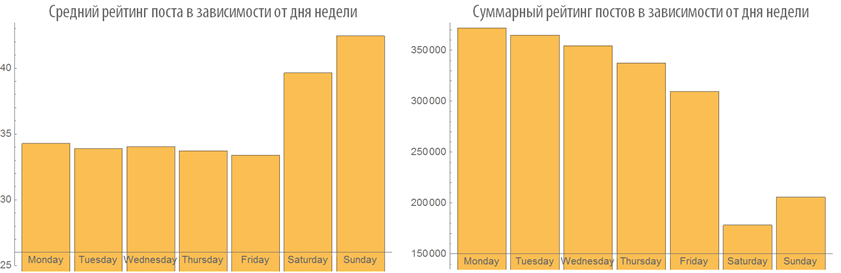
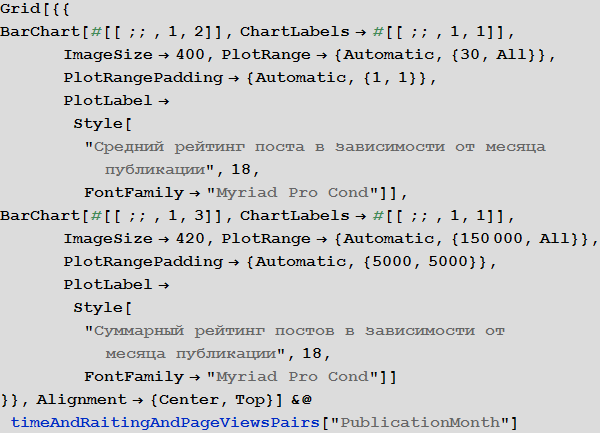
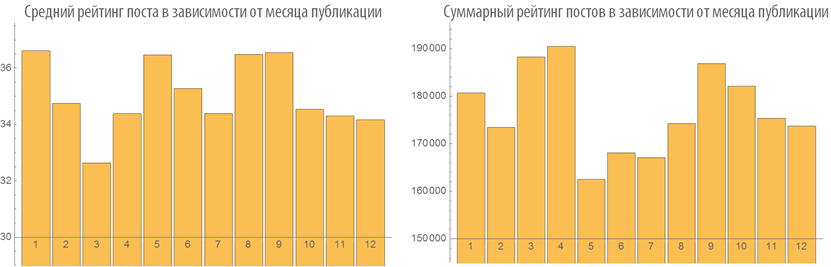
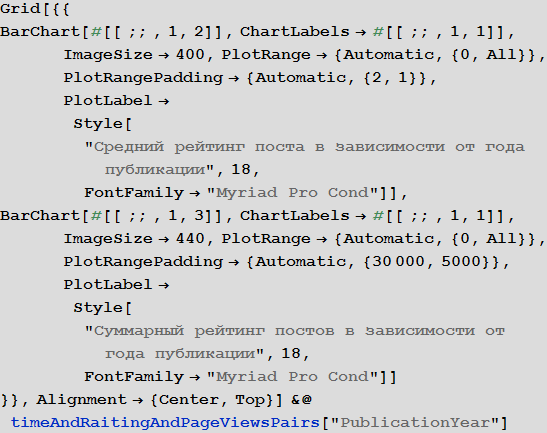
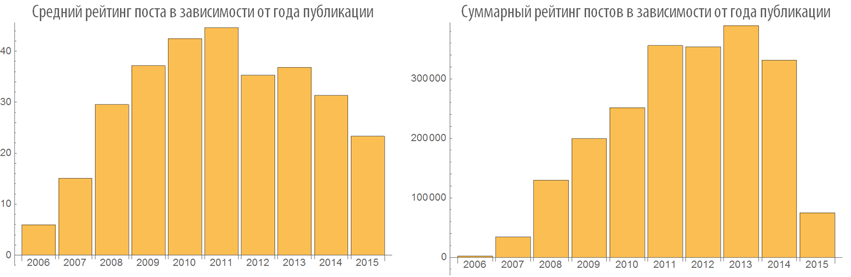
Изучим число просмотров постов в зависимости от времени публикации:
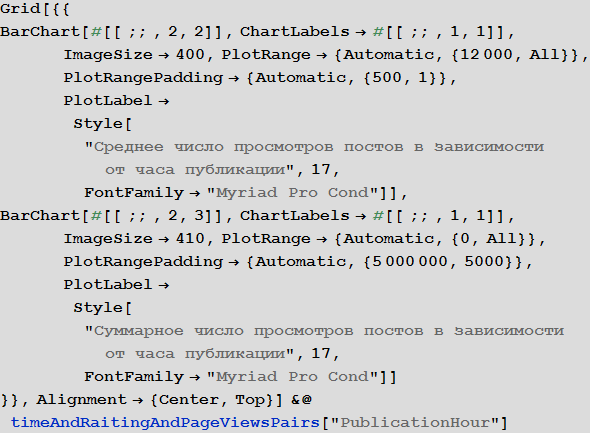
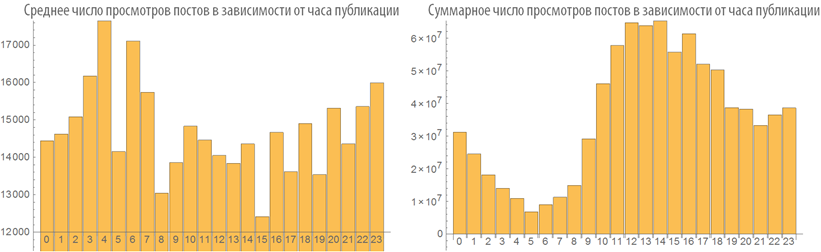

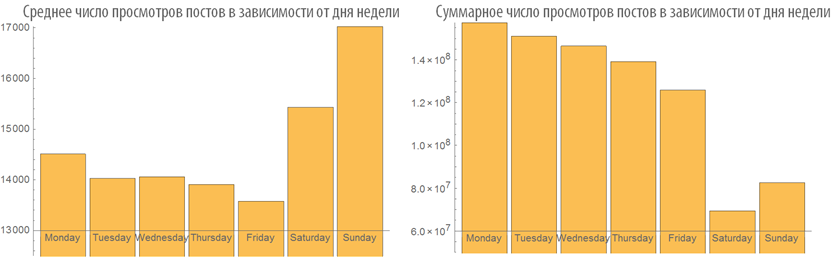

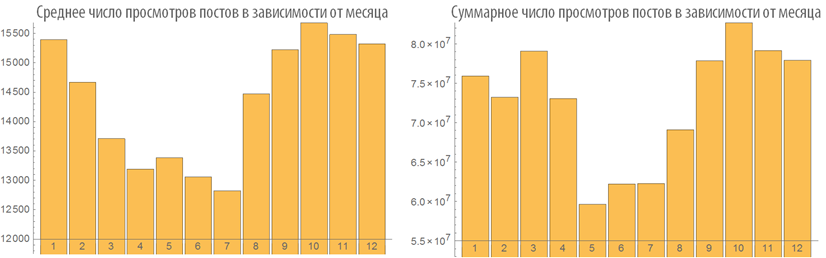
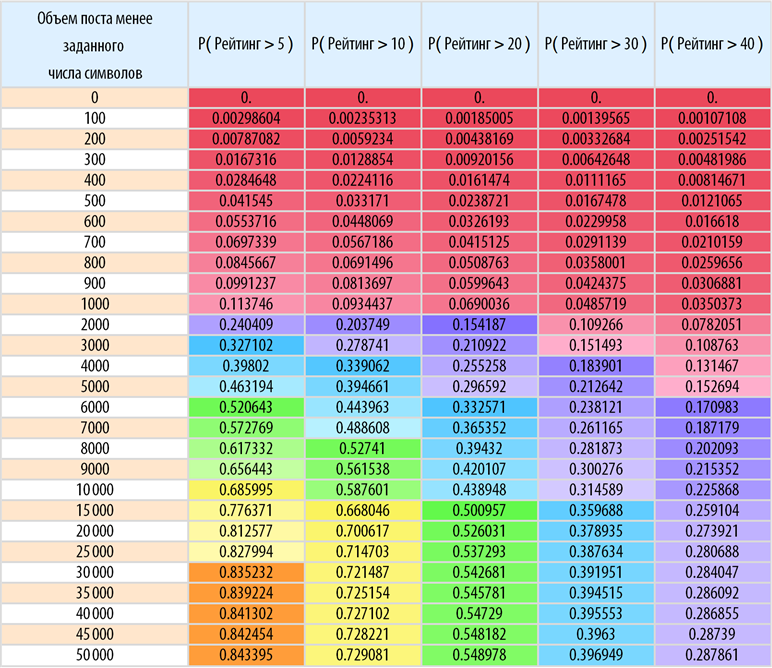
Зависимость рейтинга поста от его объема
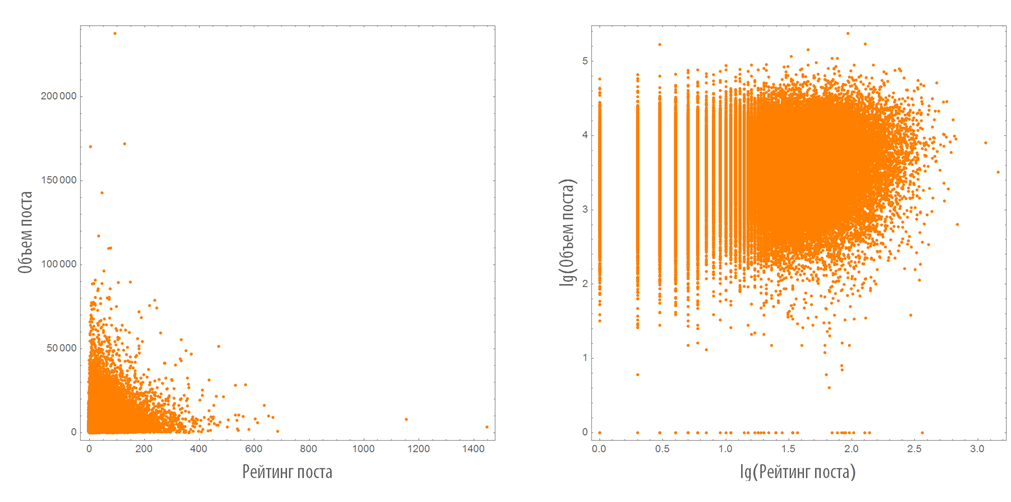
Выделим пары вида длина поста + рейтинг поста (длина поста — мы будем ее называть далее объемом поста — врассчитывается как общее числов символов в посте):
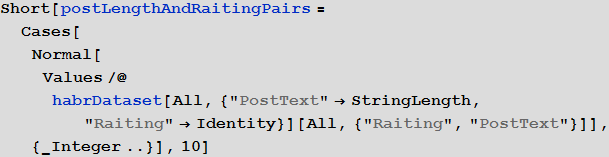

Построим их распределение на плоскости в обычном и логарифмическом масштабах:
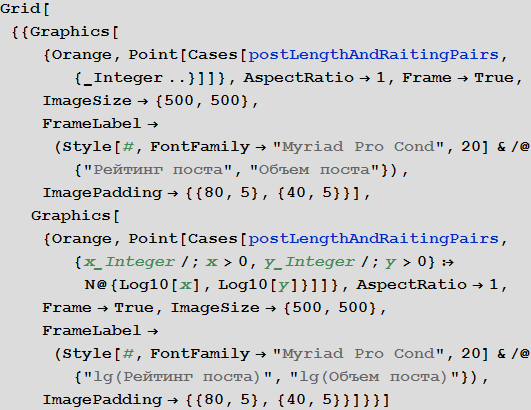
Построим двумерную и трехмерную плотность распределения рассматриваемых пар:
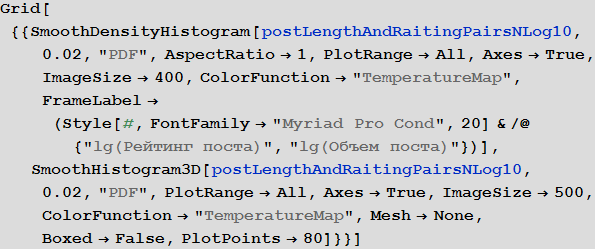
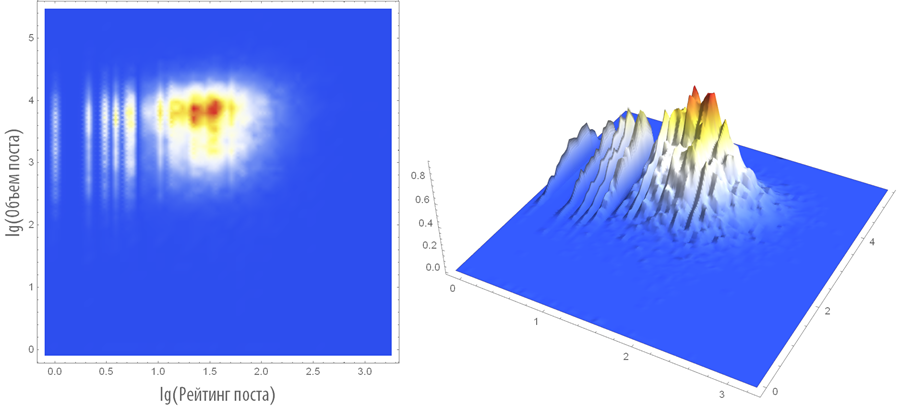
Средний объем поста на Хабрахабре равен 5989 символов.
Как и раньше, построим распределение рассматриваемых пар (создадим распределение двумерной случайной величины):


Найдем вероятность того, что пост с объемом не превышающим заданное количество символов наберет рейтинг не менее заданного:

Заключение
Надеюсь, что проведенный анализ смог заинтересовать вас, а также будет вам полезен. Безусловно, на основе полученной базы данных можно провести еще массу всевозможных исследований, скажем, ответить на такие вопросы: будет ли данный пост популярен (предсказание уровня популярности)? что влияет на количество комментариев? как найти оптимальную тему для поста? и многое другое. Но это уже темы для будущих постов.
Обновление от 3:21 30 апреля: благодаря вниманию Power, скорректированы рассчитанные значения, связанные с рейтингом постов. По сравнению с ранее вычисленными значениями, отличия оказались довольно незначительными. Однако, восстановлена цельность всей цепочки алгоритмов, за счет устранения бага в функции extractData[«Raiting»].
Комментарии (58)
Aclz
29.04.2015 18:57+2А можно тезисно, какую действительно полезную сообществу информацию удалось выудить из всего этого?

valemak
29.04.2015 19:05+2Меня в этой информационной свалке заинтересовали только графики, иллюстрирующие когда лучше размещать публикацию, чтобы получить больше плюсов. Но выводы из них весьма подозрительные…

dyadyaSerezha
30.04.2015 13:38+2Солидарен с вопросов. Не увидел практически ничего реального полезного, кроме математики ради математики.

Boomburum
29.04.2015 19:00+12Объём этой статьи составляет 21500 символов (код поста – 60 тысяч) – ну, математика, не подведи исследователей! :)
p.s. Очень круто, спасибо!
OsipovRoman Автор
29.04.2015 22:41+5Вероятность набрать при это более 40 «лайков» равна около 0.28, что не плохо. Пост это количество на данный момент уже набрал)
valemak
29.04.2015 19:03+2Ещё кажется очень подозрительным высокая плюсуемость субботне-воскресных публикаций. На самом деле, это наихудшие дни в плане рейтинга — маленькая посещаемость из-за чего мало оценок.

Frolenarzt
29.04.2015 21:59+2Уже много раз это обсуждалось.
В выходные плюсуют больше, потому что конкуренции меньше.

thelongrunsmoke
29.04.2015 19:57+2Картина становится яснее, если убрать главный источник ссылок — сам Хабрахабр.
Повторяется дважды, второй раз в облаках с языками.
Mingun
29.04.2015 20:04+1Да не только это, весь блок с графиками оптимального времени публикации задвоен (впрочем, это легко можно не заметить :)).
OsipovRoman Автор
29.04.2015 22:39В нем просто две группы графиков — одна коллекция по рейтингу, другая по числу просмотров. Визуально, да, они похожи.

Power
30.04.2015 01:54Да, во второй раз там должно быть что-то вроде «Посмотрим на самые популярные языки программирования вставок кода в хабе “Алгоритмы”:»

Lerg
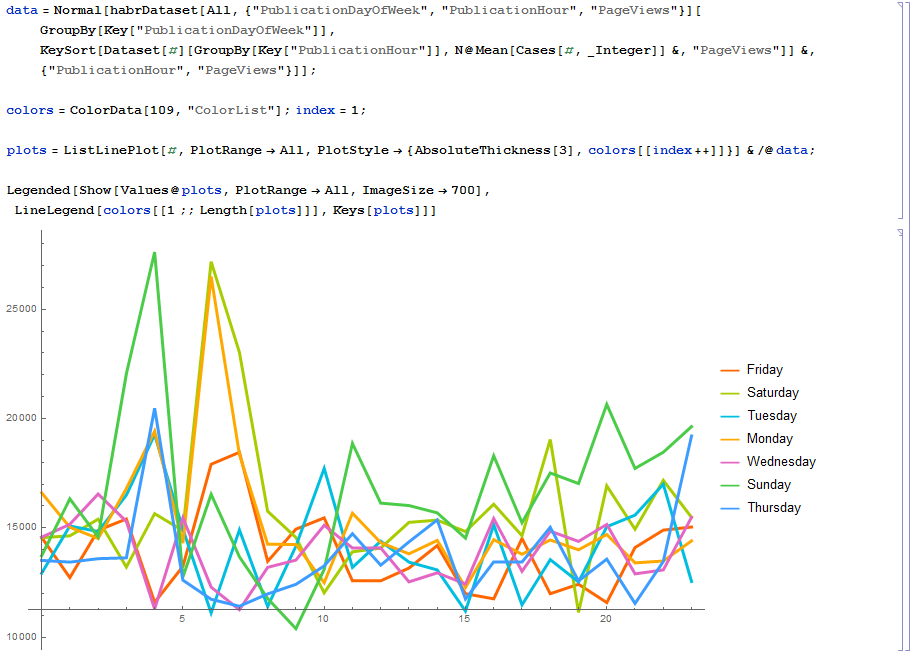
29.04.2015 20:59+5Постройте, пожалуйста, график среднего рейтинга поста в зависимости от дня недели и времени одновременно. Т.е. в начале графика понедельник с 0 до 23, затем вторник с 0 до 23 и в конце воскресенье с 0 до 23. Всего 24 * 7 точек. Спасибо.
OsipovRoman Автор
29.04.2015 23:07+4Вот результат:
Код для копированияdata=Normal[habrDataset[All,{"PublicationDayOfWeek","PublicationHour","PageViews"}][GroupBy[Key["PublicationDayOfWeek"]],KeySort[Dataset[#][GroupBy[Key["PublicationHour"]],N@Mean[Cases[#,_Integer]]&,"PageViews"]]&,{"PublicationHour","PageViews"}]]; colors=ColorData[109,"ColorList"];index=1; plots=ListLinePlot[#,PlotRange->All,PlotStyle->{AbsoluteThickness[3],colors[[index++]]}]&/@data; Legended[Show[Values@plots,PlotRange->All,ImageSize->700],LineLegend[colors[[1;;Length[plots]]],Keys[plots]]]Lerg
29.04.2015 23:25Спасибо! Очень интересны пики в 4 и 6 часов.
Моя гипотеза в том, что 4, 5, 6 часов по Москве — самое неудобное время для авторов статей, то есть до 3..4 часов ночи люди ещё могут посидеть, дописать и выложить статью, но как только время доходит до 5 часов, человек ложится спать и оставляет статью на потом.
Из-за этого в этом промежутке очень мало данных для полноценного анализа. Может быть идеальным временем публикации будет 5 часов в субботу, воскресенье или понедельник, но мы просто не имеем достаточно хороших статей, чтобы подтвердить эту гипотезу.

Himura
29.04.2015 21:05+4Ого, потрясающе фундаментальная работа! Судя по данным, технологии Wolfram наконец-то набирают популярность! Прекрасное исследование, огромное спасибо!

opckSheff
29.04.2015 21:27+3Отлично. Спасибо за публикацию. На самом деле, можно было бы разделить на несколько частей, объем действительно гигантский, аж колесико мышки перегревается и глаза разбегаются.
А по теме — очень интересно, наконец научился полноценно работать с dataset'ами.
Power
30.04.2015 01:51+2А почему у вас получилось, что рейтинг постов не бывает отрицательным? Не ошибка ли это извлечения рейтинга? (Имейте в виду, Хабр вместо минуса перед числом использует тире (ndash).)
OsipovRoman Автор
30.04.2015 02:03Таких постов не так много. Рейтинг -1 у 669 постов, -2 у 113, -3 у 89 и -4 у 85. Меньше нет. В базе они есть.
Power
30.04.2015 02:32+1Вы, похоже, ходили по страницам вида
http://habrahabr.ru/hub/{hubname}/page{N}/, а надо было поhttp://habrahabr.ru/hub/{hubname}/all/page{N}/.
Первое — это «Интересное. Записи, получившие положительную оценку (рейтинг ?-4) пользователей», а второе — «Всё подряд. Все записи хаба (в хронологическом порядке)» (см. справку).OsipovRoman Автор
30.04.2015 02:59Что-ж, в будущем можно будет написать апдейт с учетом не только «интересных» хабов, но и с очень плохим рейтингом. Благо доля их также не очень велика.
OsipovRoman Автор
30.04.2015 02:54Но, вообще, вы правы. Из-за этого символа, который на первый взгляд и внутри Wolfram Language отображается как минус, я не заметил эту неточность. Сейчас поправлю все что относится к этому. Благо изменения будут всюду лишь в сотых, а на графиках их вообще заметить будет невозможно.
OsipovRoman Автор
30.04.2015 03:19Благодарю за замеченную неточность. Поправил результаты. Отличия, как и думал, получились крайне малые.

MilkyWay
30.04.2015 02:31А есть ли у вас статистика по переводам (и помнится был формат топик-ссылка в прошлом)? Интересно сколько контента создано только для хабра
OsipovRoman Автор
30.04.2015 03:57+3На данный момент нет, но вот теперь, добавил. В целом, даже не знаю, почему мне не пришла в голову мысль вставить это сразу)

Код для копированияextractData["TranslationQ"][data_]:=If[ FreeQ[data,XMLElement["span",{"class"->"flag flag_translation"},{"перевод"}]],"Original","Translation"]MilkyWay
30.04.2015 04:38+1Благодарю! Ждем статьи о гиктаймсе :)
OsipovRoman Автор
30.04.2015 10:36+1Что интересно, сделать клон этой статьи для GeekTimes и Мегамозга не сложно, нужно просто сделать другую базу и поставить на счет. Все произойдет в почти автоматическом режиме.

chiffa_ua
30.04.2015 02:40+2Офигенно интересно! Спасибо.
Насчёт анализа вероятностей, а лотерею просчитать можешь? ;)opckSheff
30.04.2015 11:59На самом деле, просчитать шанс выиграть в лотерею может любой человек, знакомый с азами теории вероятности. Даже без помощи Wolfram Language, с бумажкой и ручкой. Хотя так, конечно, удобнее. )

Vorchun
30.04.2015 10:43Статистика «только уникальные статьи (относящиеся только к одному хабу)»
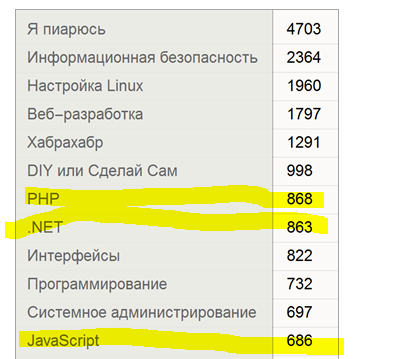
Немного удивлен порядком. Ведь можно говорить как о тренде и популярности? JS неожиданно ниже.OsipovRoman Автор
30.04.2015 11:04+2С одной стороны да, с другой ясно, что Javascript очень связан с другими хабами, куда, почти автоматом, также добавляют пост при публикации. Так что да, «монохабных» постов в нем получается меньше.
Вот с какими хабами тесно связан хаб Javascript

Код для копированияhabs= Association@KeyValueMap[#1<>" ("<>ToString[#2]<>")"->#2&,KeySelect[Drop[Normal[Reverse@Sort[Counts[Flatten[habrDataset[Select[And[MemberQ[#Habs,"JavaScript"]]&],"Habs"]]]]],1],Not[StringMatchQ[#,"Блог"~~__]]&]]; Quiet[WordCloud[habs,ImageSize->800,MaxItems->All]]
pasha_golub
30.04.2015 12:39Если ставить хаб JavaScript, то многие сразу лепят HTML. Так что всё в норме
OsipovRoman Автор
30.04.2015 12:45Чаще всего «лепят» хаб «Веб разработка», как видно из облака слов выше. В 4 с лишним раза чаще, чем «HTML».
pasha_golub
30.04.2015 12:56Именно так! Когда я писал комментарий, этих данных еще не было. Воспользовался встроенным телепатором. Полагаю, что очень рядом получилось :)
Rondo
30.04.2015 11:56+1Грандиозная работа, большое спасибо за неё!
Несколько графиков немного сбивают с толку: «Количество %object_name%, публикуемых в %hab_name% за год» — почему-то у всех завален правый край.
Я конечно понимаю, что 2015 год ещё не закончился и значение за этот год меньше, но ведь можно было или экстраполировать по данным за первые 4 месяца на весь год, или просто урезать график по ширине до первых 4 месяцев 2015 года.OsipovRoman Автор
30.04.2015 12:03Согласен, но это скорее дело вкуса. Я думаю, что все читатели поняли, что в 2015 году меньше только по причине того, что прошло еще только 4 месяца. Экстраполяция потребовала бы довольно много дополнительных объяснений, построения доп. моделей, выяснения их состоятельности и пр.
opckSheff
30.04.2015 12:07Хабрахабр изменчив, словно живой организм. Экстраполировать, пожалуй, совсем некорректно. ) И вариант «ужать» тоже нежизнеспособен, поскольку для построения уходящего вверх и вправо, как вам хочется, графика экстраполировать все равно придется. Дело в том, что значения графика между отметками на оси абсцисс — это не «количество %object_name%, публикуемых в %hab_name% за месяц», это просто линии, соединяющие точки.
Rondo
30.04.2015 19:24Кстати, лучше тогда делать гистограмму, а не график, если тут линии между точками не несут особого смысла.
DISaccount
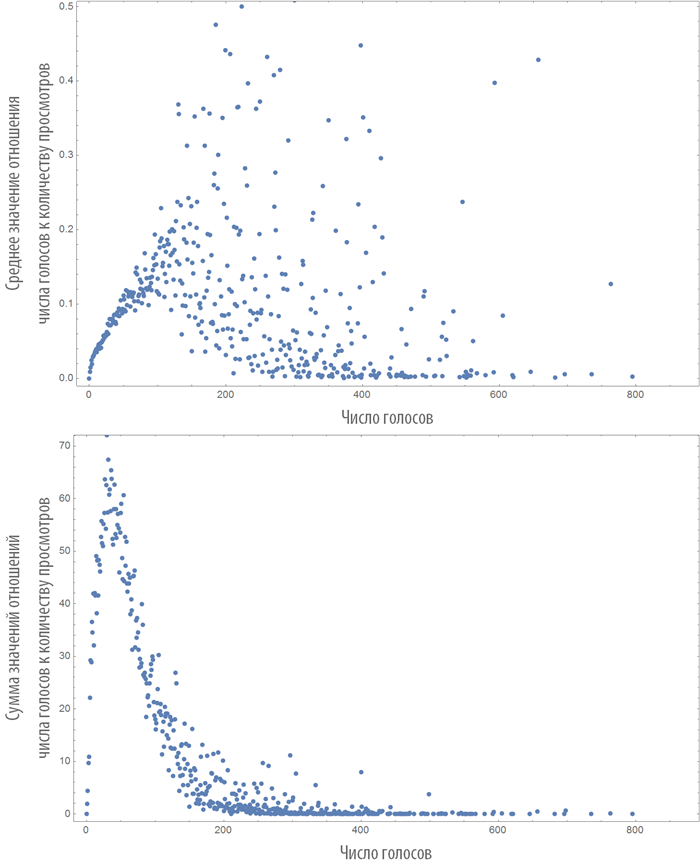
30.04.2015 12:36У меня есть предположение, что случайная величина — отношение числа голосов (не рейтинга!) за статью к числу ее просмотров подчинена распределению Пуассона. Могли бы Вы привести этот график (ось абсцисс — число голосов, ось ординат — отношение)?
OsipovRoman Автор
01.05.2015 12:53+1Вот то, что вы просили:
DISaccount
05.05.2015 13:22Спасибо! Кажется гипотеза правдоподобна.
PS: Вы как настоящий трудящийся, в день трудящихся не поленились потрудиться!

antonpv
30.04.2015 14:22+1Эпичный пост, однозначно плюс! Всегда было интересно, как делают облачка и фигуры из слов, а тут еще и математически :)

Tiberius
30.04.2015 19:26+1Классная статья!
К сожалению, познакомился с Mathematica лишь недавно, но сразу на курсе лекций был поражён тем, что умеет данный программный пакет, если знать, как с ним обращаться. Хотел про него для Хабра написать, но моих знаний определённо не хватит даже на 1 процентик от данной статьи)))
И ещё раз спасибо!

RomanPyr
06.05.2015 12:48+1А можете сравнить частоту слов: яв~~ и джав~~?
OsipovRoman Автор
07.05.2015 06:24+1
RomanPyr
07.05.2015 11:45Благодарю. Давно об этом мечтал.











{kind=link}
valemak
Неожиданным оказалась то, что самые плюсуемые статьи — созданные в 4 утра по Москве. Хотя, при дальнейшем размышлении, кажется что это вполне логично — опубликованное глубокой ночью (время московское) прочитывается в начале рабочего дня жителями России, начиная с Владивостока и далее по территории страны, по мере наступления рабочего дня в соответствии с часовым поясом. При этом ещё много часов подряд публикация остаётся на первых страницах — большинство авторов (которые находятся в пределах часовых поясов европейской части России) ещё спят. И даже когда в самой Москве начинается рабочий день, статья ещё в числе самых верхних на странице.
Но тогда непонятно обрушение на следующем, 5-м часу. Разница с 4-мя часами утра, по идее, должна быть не такой резкой.
Я же надеюсь, что если статьи с Хабры собирались несколькими пауками, то их IP были из одного часового пояса?
OsipovRoman Автор
Статьи собирались только с моего отдельного локального компьютера, так что время одно.
godlin
У меня есть подозрение, что это происходит именно потому, что новых написанных статей в 4 утра очень мало. Т.е. внимание читающих распределяется неким образом между новыми статьями, и количество новых статей в это время падает сильнее, чем количество читающих.