
Перевод поста Джона Маклуна (Jon McLoone) "10 Tips for Writing Fast Mathematica Code".
Выражаю огромную благодарность Кириллу Гузенко KirillGuzenko за помощь в переводе.
Пост Джона Маклуна рассказывает о распространенных приемах ускорения кода, написанного на языке Wolfram Language. Для тех, кто заинтересуется этим вопросом мы рекомендуем ознакомиться с видео «Оптимизация кода в Wolfram Mathematica», из которого вы подробно и на множестве интересных примеров узнаете о приемах оптимизации кода, как рассмотренных в статье (но более детально), так и других.
Когда люди говорят мне, что Mathematica недостаточно быстро работает, обычно я прошу посмотреть код и часто обнаруживаю, что проблема не в производительности Mathematica, а в её не оптимальном использовании. Я хотел бы поделиться списком тех вещей, на которые я обращаю внимание в первую очередь при попытке оптимизировать код в Mathematica.
Самая распространённая ошибка, которую я замечаю, когда разбираюсь с медленным кодом — задание слишком высокой точности для данной задачи. Да, неуместное использование точной символьной арифметики — самый распространенный случай.
У большинства вычислительных программных систем нет такого понятия, как точная арифметика — для них 1/3 это то же самое, что и 0,33333333333333. Это различие может играть большую роль, когда вы сталкиваетесь со сложными и неустойчивыми задачами, однако для большинства задач числа с плавающей точкой вполне удовлетворяют нуждам, и что важно — вычисления с ними проходят значительно быстрее. В Mathematica любое число с точкой и с менее чем 16 цифрами автоматически обрабатывается с машинной точностью, потому всегда следует использовать десятичную точку, если в данной задаче скорость важнее точности (например, ввести треть как 1./3.). Вот простой пример, где работа с числами с плавающей точкой проходит почти в 50,6 раза быстрее, чем при работе с точными числами, которые лишь затем будут переведены в числа с плавающей точкой. И в этом случае получается такой же результат.
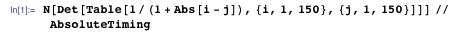
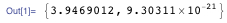


То же самое можно сказать и для символьных вычислений. Если для вас не принципиальна символьная форма ответа и устойчивость в этой задаче не играет особой роли, то постарайтесь как можно раньше перейти к форме числа с плавающей точкой. Например, решая это полиномиальное уравнение в символьном виде, перед тем, как подставить значения, Mathematica строит промежуточное символьное решение на пять страниц.


Но если сперва выполнить подстановку, то Solve будет использовать значительно более быстрые численные методы.


При работе со списками данных следует быть последовательным в использовании действительных чисел. Всего лишь одно точное значение в наборе данных переведёт его в более гибкую, но менее эффективную форму.




Функция Compile принимает код Mathematica и позволяет предварительно задавать типы (действительный, комплексный и т. д.) и структуры (значение, список, матрица и т. д.) входных аргументов. Это лишает части гибкости языка Mathematica, но освобождает от необходимости беспокоиться о том, «Что же делать, если аргумент в символьной форме?» и других подобных вещах. Mathematica может оптимизировать программу и создать байт-код для его запуска на своей виртуальной машине (возможна также компиляция в C — см. ниже). Не всё можно скомпилировать, и очень простой код может и не получить никаких преимуществ, однако сложный и низкоуровневый вычислительный код может получить действительно большое ускорение.
Вот пример:




Использование Compile вместо Function даёт ускорение более чем в 80 раз.



Но мы можем пойти дальше, сообщая Compile о возможности распараллеливания этого кода, получая ещё лучший результат.



На моей двухъядерной машине я получил результат в 150 раз быстрее, чем в изначальном случае; прирост скорости будет ещё заметнее с большим количеством ядер.
Однако следует помнить, что многие функции в Mathematica, такие как Table, Plot, NIntegrate и ещё некоторые автоматически компилируют свои аргументы, так что вы не увидите каких-либо улучшений при использовании Compile для вашего кода.
Кроме того, если ваш код компилируется, то вы также можете использовать опцию CompilationTarget -> «C» для генерации кода на C, что автоматически вызовет компилятор C для компиляции в DLL и отправки ссылки на него в Mathematica. Мы имеем дополнительные издержки на этапе компиляции, но DLL выполняется непосредственно в процессоре, а не в виртуальной машине Mathematica, так что результаты могут быть еще быстрее (в нашем случае, в 450 раз быстрее, чем изначальный код).



Mathematica содержит много функций. Больше, чем обычный человек сможет выучить за один присест (последняя версия Mathematica 10.2 содержит уже более 5000 функций). Так что не удивительно, что я часто вижу код, где кто-то реализовывает какие-то операции, не зная, что Mathematica уже умеет их осуществлять. И это не только пустая трата времени на изобретение велосипеда; наши ребята основательно потрудились, создав и наиболее эффективно реализовав лучшие алгоритмы для различных типов входных данных, так что встроенные функции работают действительно быстро.
Если вы найдете что-то похожее, но не совсем то, то вам следует проверить параметры и необязательные аргументы — часто они обобщают функции и охватывают многие специальные и более отдалённые приложения.
Вот пример. Если у меня есть список из миллиона матриц 2х2, который я хочу превратить в список из миллиона одномерных списков из 4 элементов, то по идее самый простой способ будет использовать Map на функцию Flatten, применённую к списку.



Но Flatten знает, как самой решить эту задачу, если вы укажете, что уровни 2 и 3 структуры данных должны быть объединены, а уровень 1 чтобы не затрагивался. Указание подобных деталей может быть несколько неудобным, однако используя только одну Flatten, наш код будет выполнен в 4 раза быстрее, чем в случае, когда мы будем заново изобретать встроенные в функцию возможности.


Так что не забывайте заглянуть в справку перед тем, как вводить какой-то свой функционал.
Mathematica прощает некоторые виды ошибок в коде, и всё будет спокойно работать, если вы вдруг забыли инициализировать переменную в нужный момент, и не нужно заботиться о рекурсии или неожиданных типах данных. И это здорово, когда вам нужно просто по-быстрому получить ответ. Однако подобный код с ошибками не позволит вам получить оптимальное решение.
Workbench помогает сразу несколькими способами. Во-первых, он позволяет лучше отлаживать и организовывать крупные проекты, а когда всё ясно и организованно, то значительно проще писать хороший код. Но ключевой особенностью в данном контексте является профайлер, который позволяет увидеть, какие строки кода используется в определённые моменты времени, сколько раз они были вызваны.
Рассмотрим в качестве примера подобный, ужасно неоптимальный (с точки зрения вычислений) способ получения чисел Фибоначчи. Если вы не задумывались о последствиях двойной рекурсии, то, вероятно, несколько удивитесь 22-м секундам для оценки fib[35] (примерно столько же времени потребуется встроенной функции для расчета всех 208 987 639 цифр Fibonacci[1000000000] [см. пункт 3]).

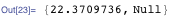
Выполнение кода в Profiler показывает причину. Главное правило вызывается 9 227 464 раз, а значение fib[1] запрашивается 18 454 929 раз.
Увидеть код таким, каким он является в действительности — может стать настоящим откровением.
Это хороший совет для программирования на любом языке. Вот как это можно реализовать в Mathematica:

Она сохраняет результат вызова f для любого аргумента, так что если функция будет вызвана для уже вызванного ранее аргумента, то Mathematica не потребуется вычислять его снова. Тут мы отдаем память, взамен получая скорость, и, конечно, если количество возможных аргументов функции огромно, а вероятность повторного вызова функции с тем же аргументом весьма мала, то так делать не стоит. Но если множество возможных аргументов невелико, то это действительно может помочь. Вот этот код спасает программу, которую я использовал для иллюстрации совета 3. Нужно заменить первое правило на это:
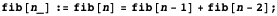
И код начинает работать несравнимо быстро, и для вычисления fib [35] главное правило должно быть вызвано лишь 33 раза. Запоминание предыдущих результатов предотвращает необходимость неоднократно рекурсивно спускаться к fib[1].
Всё большее число операций в Mathematica автоматически распаралливаются на локальные ядра (особенно задачи линейной алгебры, обработки изображений, статистики), и, как мы уже видели, по запросу могут быть реализованы через Compile. Но для других операций, которые вы хотите распараллелить на удаленном оборудовании, вы можете использовать встроенные конструкции для распараллеливания.
Для этого есть набор инструментов, однако в случае принципиально монопоточных задач использование одних лишь ParallelTable, ParallelMap и ParallelTry может увеличить время вычислений. Каждая из функций автоматически решает задачи коммуникации, управления и сбора результатов. Существует некоторые дополнительные издержки в отправке задачи и получении результата, то есть получая выигрыш во времени в одном, мы теряем время в другом. Mathematica поставляется с определенным максимальным количеством доступных вычислительных ядер (зависит от лицензии), и вы можете масштабировать их с gridMathematica, если у вас есть доступ к дополнительным ядрам. В этом примере ParallelTable дает мне двойную производительность, поскольку выполняется на моей двухъядерной машине. Большее количество процессоров дадут больший прирост.




Всё, что может сделать Mathematica, может быть распараллелено. Например, вы можете отправить наборы параллельных задач удалённым устройствам, каждое из которых компилирует и работает в C или на GPU.
С помощью GPU некоторые задачи могут в параллельном режиме решаться значительно быстрее. Не считая случая, когда для решения ваших задач требуются уже оптимизированные под CUDA функции, вам потребуется проделать небольшую работу, однако инструменты CUDALink и OpenCLLink автоматизируют для вас большое количество всякой рутины.
Из-за гибкости структур данных в Mathematica, AppendTo не может знать, что вы будете добавлять число, потому что вы можете точно так же добавлять документ, звук или изображение. В результате AppendTo необходимо создать новую копию всех данных, реструктуризованную для размещения прилагаемой информации. По мере накопления данных работа будет осуществляться всё медленнее (а конструкция data=Append[data,value] эквивалентна AppendTo).
Вместо этого используйте Sow и Reap. Sow передаёт значения, которые вы хотите собрать, а Reap собирает их и создаёт объект данных в конце. Следующие примеры эквивалентны:



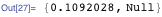
Block (локализация значения переменной), With (замена переменных во фрагменте кода на их конкретные значения с последующим вычислением всего кода) и Module (локализация имен переменных) представляют собой ограничивающие конструкции, которые имеют несколько различные свойства. По моему опыту, Block и Module взаимозаменяемы, по крайней мере в 95% случаев, с которыми я сталкиваюсь, но Block, как правило, работает быстрее, а в некоторых случаях With (фактически Block с переменными, доступными лишь для чтения) ещё быстрее.


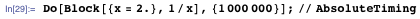
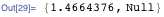
Шаблонные выражения — это здорово. Многие задачи с их помощью легко решаются. Однако шаблоны — это не всегда быстро, особенно такие нечёткие, как BlankNullSequence (обычно записывается как "___"), которые могут долго и упорно осуществлять поиск шаблонов в данных, которых там явно не может быть. Если скорость выполнения принципиальна, используйте чёткие модели, или вообще откажитесь от шаблонов.
В качестве примера приведу изящный способ осуществить сортировку пузырьком в одну строчку кода через шаблоны:

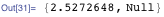
В теории всё аккуратно, но слишком медленно по сравнению с процедурным подходом, который я изучал, когда только начинал программировать:


Конечно, в этом случае следует использовать встроенную функцию Sort (см. совет 3), которая работает наиболее быстро.


Одна из самых сильных сторон Mathematica — возможность решать задачи по-разному. Это позволяет писать код так, как вы мыслите, а не переосмысливать проблему под стиль языка программирования. Тем не менее, концептуальная простота не всегда есть то же, что и вычислительная эффективность. Иногда простая для понимания идея порождает больше работы, чем это необходимо.
Но другой момент заключается в том, что из-за всяких специальных оптимизаций и умных алгоритмов, которые автоматически применяются в Mathematica, часто трудно становится предсказать, какой из путей следует выбрать. Например, вот два способа расчёта факториала, но второй более чем в 10 раз быстрее.




Почему? Вы могли бы предположить, что Do медленнее прокручивает циклы, или все эти присваивания Set к temp занимают время, или ещё что-то не так с первой реализацией, но настоящая причина, вероятно, окажется довольно неожиданной. Times (оператор умножения) знает хитрый трюк с бинарным разбиением, который может использоваться, когда у вас есть большое количество целочисленных аргументов. Рекурсивное разделение аргументов на два меньших произведения (1 * 2 *… * 32767) * (32768 *… * 65536) работает быстрее, чем обработка всех аргументов — от первого до последнего. Количество умножений получается таким же, однако однако меньшее количество из них включают большие числа, потому в среднем алгоритм осуществляется быстрее. Есть много другого скрытого волшебства в Mathematica, и с каждой версией его всё больше.
Конечно лучший вариант в данном случае — использовать встроенную функцию (опять-таки совет 3):


Mathematica способна обеспечить превосходную вычислительную производительность, а также высокую скорость и точность, но не всегда одновременно. Надеюсь, что эти советы помогут вам сбалансировать зачастую противоречивые требования быстрого программирования, быстрого исполнения и точных результатов.
Все тайминги приводятся для 7 64-разрядной Windows PC, с 2,66 ГГц Intel Core 2 Duo и 6 Гб оперативной памяти.
Помимо этого краткого поста Джона Маклуна, мы рекомендуем вам ознакомиться с двумя видео, приведенными ниже.
Выражаю огромную благодарность Кириллу Гузенко KirillGuzenko за помощь в переводе.
Пост Джона Маклуна рассказывает о распространенных приемах ускорения кода, написанного на языке Wolfram Language. Для тех, кто заинтересуется этим вопросом мы рекомендуем ознакомиться с видео «Оптимизация кода в Wolfram Mathematica», из которого вы подробно и на множестве интересных примеров узнаете о приемах оптимизации кода, как рассмотренных в статье (но более детально), так и других.
Когда люди говорят мне, что Mathematica недостаточно быстро работает, обычно я прошу посмотреть код и часто обнаруживаю, что проблема не в производительности Mathematica, а в её не оптимальном использовании. Я хотел бы поделиться списком тех вещей, на которые я обращаю внимание в первую очередь при попытке оптимизировать код в Mathematica.
1. Используйте числа с плавающей точкой, и переходите к ним на как можно более ранней стадии.
Самая распространённая ошибка, которую я замечаю, когда разбираюсь с медленным кодом — задание слишком высокой точности для данной задачи. Да, неуместное использование точной символьной арифметики — самый распространенный случай.
У большинства вычислительных программных систем нет такого понятия, как точная арифметика — для них 1/3 это то же самое, что и 0,33333333333333. Это различие может играть большую роль, когда вы сталкиваетесь со сложными и неустойчивыми задачами, однако для большинства задач числа с плавающей точкой вполне удовлетворяют нуждам, и что важно — вычисления с ними проходят значительно быстрее. В Mathematica любое число с точкой и с менее чем 16 цифрами автоматически обрабатывается с машинной точностью, потому всегда следует использовать десятичную точку, если в данной задаче скорость важнее точности (например, ввести треть как 1./3.). Вот простой пример, где работа с числами с плавающей точкой проходит почти в 50,6 раза быстрее, чем при работе с точными числами, которые лишь затем будут переведены в числа с плавающей точкой. И в этом случае получается такой же результат.
То же самое можно сказать и для символьных вычислений. Если для вас не принципиальна символьная форма ответа и устойчивость в этой задаче не играет особой роли, то постарайтесь как можно раньше перейти к форме числа с плавающей точкой. Например, решая это полиномиальное уравнение в символьном виде, перед тем, как подставить значения, Mathematica строит промежуточное символьное решение на пять страниц.
Но если сперва выполнить подстановку, то Solve будет использовать значительно более быстрые численные методы.
При работе со списками данных следует быть последовательным в использовании действительных чисел. Всего лишь одно точное значение в наборе данных переведёт его в более гибкую, но менее эффективную форму.
2. Используйте Compile...
Функция Compile принимает код Mathematica и позволяет предварительно задавать типы (действительный, комплексный и т. д.) и структуры (значение, список, матрица и т. д.) входных аргументов. Это лишает части гибкости языка Mathematica, но освобождает от необходимости беспокоиться о том, «Что же делать, если аргумент в символьной форме?» и других подобных вещах. Mathematica может оптимизировать программу и создать байт-код для его запуска на своей виртуальной машине (возможна также компиляция в C — см. ниже). Не всё можно скомпилировать, и очень простой код может и не получить никаких преимуществ, однако сложный и низкоуровневый вычислительный код может получить действительно большое ускорение.
Вот пример:
Использование Compile вместо Function даёт ускорение более чем в 80 раз.
Но мы можем пойти дальше, сообщая Compile о возможности распараллеливания этого кода, получая ещё лучший результат.
На моей двухъядерной машине я получил результат в 150 раз быстрее, чем в изначальном случае; прирост скорости будет ещё заметнее с большим количеством ядер.
Однако следует помнить, что многие функции в Mathematica, такие как Table, Plot, NIntegrate и ещё некоторые автоматически компилируют свои аргументы, так что вы не увидите каких-либо улучшений при использовании Compile для вашего кода.
2.5.… и используйте Compile для генерации кода на C.
Кроме того, если ваш код компилируется, то вы также можете использовать опцию CompilationTarget -> «C» для генерации кода на C, что автоматически вызовет компилятор C для компиляции в DLL и отправки ссылки на него в Mathematica. Мы имеем дополнительные издержки на этапе компиляции, но DLL выполняется непосредственно в процессоре, а не в виртуальной машине Mathematica, так что результаты могут быть еще быстрее (в нашем случае, в 450 раз быстрее, чем изначальный код).
3. Используйте встроенные функции.
Mathematica содержит много функций. Больше, чем обычный человек сможет выучить за один присест (последняя версия Mathematica 10.2 содержит уже более 5000 функций). Так что не удивительно, что я часто вижу код, где кто-то реализовывает какие-то операции, не зная, что Mathematica уже умеет их осуществлять. И это не только пустая трата времени на изобретение велосипеда; наши ребята основательно потрудились, создав и наиболее эффективно реализовав лучшие алгоритмы для различных типов входных данных, так что встроенные функции работают действительно быстро.
Если вы найдете что-то похожее, но не совсем то, то вам следует проверить параметры и необязательные аргументы — часто они обобщают функции и охватывают многие специальные и более отдалённые приложения.
Вот пример. Если у меня есть список из миллиона матриц 2х2, который я хочу превратить в список из миллиона одномерных списков из 4 элементов, то по идее самый простой способ будет использовать Map на функцию Flatten, применённую к списку.
Но Flatten знает, как самой решить эту задачу, если вы укажете, что уровни 2 и 3 структуры данных должны быть объединены, а уровень 1 чтобы не затрагивался. Указание подобных деталей может быть несколько неудобным, однако используя только одну Flatten, наш код будет выполнен в 4 раза быстрее, чем в случае, когда мы будем заново изобретать встроенные в функцию возможности.
Так что не забывайте заглянуть в справку перед тем, как вводить какой-то свой функционал.
4. Используйте Wolfram Workbench.
Mathematica прощает некоторые виды ошибок в коде, и всё будет спокойно работать, если вы вдруг забыли инициализировать переменную в нужный момент, и не нужно заботиться о рекурсии или неожиданных типах данных. И это здорово, когда вам нужно просто по-быстрому получить ответ. Однако подобный код с ошибками не позволит вам получить оптимальное решение.
Workbench помогает сразу несколькими способами. Во-первых, он позволяет лучше отлаживать и организовывать крупные проекты, а когда всё ясно и организованно, то значительно проще писать хороший код. Но ключевой особенностью в данном контексте является профайлер, который позволяет увидеть, какие строки кода используется в определённые моменты времени, сколько раз они были вызваны.
Рассмотрим в качестве примера подобный, ужасно неоптимальный (с точки зрения вычислений) способ получения чисел Фибоначчи. Если вы не задумывались о последствиях двойной рекурсии, то, вероятно, несколько удивитесь 22-м секундам для оценки fib[35] (примерно столько же времени потребуется встроенной функции для расчета всех 208 987 639 цифр Fibonacci[1000000000] [см. пункт 3]).
Выполнение кода в Profiler показывает причину. Главное правило вызывается 9 227 464 раз, а значение fib[1] запрашивается 18 454 929 раз.
Увидеть код таким, каким он является в действительности — может стать настоящим откровением.
5. Запоминайте значения, которые вам понадобятся в дальнейшем.
Это хороший совет для программирования на любом языке. Вот как это можно реализовать в Mathematica:
Она сохраняет результат вызова f для любого аргумента, так что если функция будет вызвана для уже вызванного ранее аргумента, то Mathematica не потребуется вычислять его снова. Тут мы отдаем память, взамен получая скорость, и, конечно, если количество возможных аргументов функции огромно, а вероятность повторного вызова функции с тем же аргументом весьма мала, то так делать не стоит. Но если множество возможных аргументов невелико, то это действительно может помочь. Вот этот код спасает программу, которую я использовал для иллюстрации совета 3. Нужно заменить первое правило на это:
И код начинает работать несравнимо быстро, и для вычисления fib [35] главное правило должно быть вызвано лишь 33 раза. Запоминание предыдущих результатов предотвращает необходимость неоднократно рекурсивно спускаться к fib[1].
6. Распараллеливайте код.
Всё большее число операций в Mathematica автоматически распаралливаются на локальные ядра (особенно задачи линейной алгебры, обработки изображений, статистики), и, как мы уже видели, по запросу могут быть реализованы через Compile. Но для других операций, которые вы хотите распараллелить на удаленном оборудовании, вы можете использовать встроенные конструкции для распараллеливания.
Для этого есть набор инструментов, однако в случае принципиально монопоточных задач использование одних лишь ParallelTable, ParallelMap и ParallelTry может увеличить время вычислений. Каждая из функций автоматически решает задачи коммуникации, управления и сбора результатов. Существует некоторые дополнительные издержки в отправке задачи и получении результата, то есть получая выигрыш во времени в одном, мы теряем время в другом. Mathematica поставляется с определенным максимальным количеством доступных вычислительных ядер (зависит от лицензии), и вы можете масштабировать их с gridMathematica, если у вас есть доступ к дополнительным ядрам. В этом примере ParallelTable дает мне двойную производительность, поскольку выполняется на моей двухъядерной машине. Большее количество процессоров дадут больший прирост.
Всё, что может сделать Mathematica, может быть распараллелено. Например, вы можете отправить наборы параллельных задач удалённым устройствам, каждое из которых компилирует и работает в C или на GPU.
6.5. Подумайте об использовании CUDALink и OpenCLLink.
С помощью GPU некоторые задачи могут в параллельном режиме решаться значительно быстрее. Не считая случая, когда для решения ваших задач требуются уже оптимизированные под CUDA функции, вам потребуется проделать небольшую работу, однако инструменты CUDALink и OpenCLLink автоматизируют для вас большое количество всякой рутины.
7. Используйте Sow и Reap для накопления больших объемов данных (но не AppendTo).
Из-за гибкости структур данных в Mathematica, AppendTo не может знать, что вы будете добавлять число, потому что вы можете точно так же добавлять документ, звук или изображение. В результате AppendTo необходимо создать новую копию всех данных, реструктуризованную для размещения прилагаемой информации. По мере накопления данных работа будет осуществляться всё медленнее (а конструкция data=Append[data,value] эквивалентна AppendTo).
Вместо этого используйте Sow и Reap. Sow передаёт значения, которые вы хотите собрать, а Reap собирает их и создаёт объект данных в конце. Следующие примеры эквивалентны:
8. Используйте Block и With вместо Module.
Block (локализация значения переменной), With (замена переменных во фрагменте кода на их конкретные значения с последующим вычислением всего кода) и Module (локализация имен переменных) представляют собой ограничивающие конструкции, которые имеют несколько различные свойства. По моему опыту, Block и Module взаимозаменяемы, по крайней мере в 95% случаев, с которыми я сталкиваюсь, но Block, как правило, работает быстрее, а в некоторых случаях With (фактически Block с переменными, доступными лишь для чтения) ещё быстрее.
9. Не перебарщивайте с шаблонами.
Шаблонные выражения — это здорово. Многие задачи с их помощью легко решаются. Однако шаблоны — это не всегда быстро, особенно такие нечёткие, как BlankNullSequence (обычно записывается как "___"), которые могут долго и упорно осуществлять поиск шаблонов в данных, которых там явно не может быть. Если скорость выполнения принципиальна, используйте чёткие модели, или вообще откажитесь от шаблонов.
В качестве примера приведу изящный способ осуществить сортировку пузырьком в одну строчку кода через шаблоны:
В теории всё аккуратно, но слишком медленно по сравнению с процедурным подходом, который я изучал, когда только начинал программировать:
Конечно, в этом случае следует использовать встроенную функцию Sort (см. совет 3), которая работает наиболее быстро.
10. Используйте разные подходы.
Одна из самых сильных сторон Mathematica — возможность решать задачи по-разному. Это позволяет писать код так, как вы мыслите, а не переосмысливать проблему под стиль языка программирования. Тем не менее, концептуальная простота не всегда есть то же, что и вычислительная эффективность. Иногда простая для понимания идея порождает больше работы, чем это необходимо.
Но другой момент заключается в том, что из-за всяких специальных оптимизаций и умных алгоритмов, которые автоматически применяются в Mathematica, часто трудно становится предсказать, какой из путей следует выбрать. Например, вот два способа расчёта факториала, но второй более чем в 10 раз быстрее.
Почему? Вы могли бы предположить, что Do медленнее прокручивает циклы, или все эти присваивания Set к temp занимают время, или ещё что-то не так с первой реализацией, но настоящая причина, вероятно, окажется довольно неожиданной. Times (оператор умножения) знает хитрый трюк с бинарным разбиением, который может использоваться, когда у вас есть большое количество целочисленных аргументов. Рекурсивное разделение аргументов на два меньших произведения (1 * 2 *… * 32767) * (32768 *… * 65536) работает быстрее, чем обработка всех аргументов — от первого до последнего. Количество умножений получается таким же, однако однако меньшее количество из них включают большие числа, потому в среднем алгоритм осуществляется быстрее. Есть много другого скрытого волшебства в Mathematica, и с каждой версией его всё больше.
Конечно лучший вариант в данном случае — использовать встроенную функцию (опять-таки совет 3):
Mathematica способна обеспечить превосходную вычислительную производительность, а также высокую скорость и точность, но не всегда одновременно. Надеюсь, что эти советы помогут вам сбалансировать зачастую противоречивые требования быстрого программирования, быстрого исполнения и точных результатов.
Все тайминги приводятся для 7 64-разрядной Windows PC, с 2,66 ГГц Intel Core 2 Duo и 6 Гб оперативной памяти.
Помимо этого краткого поста Джона Маклуна, мы рекомендуем вам ознакомиться с двумя видео, приведенными ниже.
Разработка больших приложений в Mathematica
Распространенные ошибки и заблуждения начинающих пользователей Mathematica
LeonidShifrin
Хочу отметить: почти все советы Джона очень хороши, кроме совета 8, в той его части, что касается Block. Использовать Block для локализации переменных — опасная и в целом вредная практика, так как Block реализует динамическое, а не лексическое связывание. Block — более специальная конструкция, полезная и мощная, но требующая полного понимания, зачем и почему он используется.
Вот доп. ссылки на эту тему
mathematica.stackexchange.com/questions/559/what-are-the-use-cases-for-different-scoping-constructs/569#569
mathematica.stackexchange.com/questions/11579/what-are-some-advanced-uses-for-block/11585#11585
LeonidShifrin
В дополнение к предыдущему комментарию: это высказывание «По моему опыту, Block и Module взаимозаменяемы, по крайней мере в 95% случаев, с которыми я сталкиваюсь, но Block, как правило, работает быстрее, а в некоторых случаях With (фактически Block с переменными, доступными лишь для чтения) ещё быстрее.» просто неверно.
Во-первых, Block и Module *не* взаимозаменяемы. Это принципиально разные конструкции с очень различной семантикой. Замена одной на другую приведет в общем случае к существенной разнице в том, как будет выполняться код. Тот факт, что во многих случаях Block будет *вроде бы* работать в 95% случаев, делает ситуацию только хуже, так как создает обширное поле для совершенно неочевидных и трудно-уловимых багов.
Во-вторых, описание With как «Block с переменными, доступными лишь для чтения» весьма далеко от реальности. Если With к чему-то и близок по сематнике, так это к правилам трансформации выражений (Rule, RuleDelayed), но никак не к Block.
Эти ошибки вполне простительны для Джона (являющегося сугубым практиком, чьи примеры остроумного применения Mathematica в самых разных областях вызывают только восхищение, и достигшего в этом больших высот), но их необходимо отметить, чтобы не создавать неправильного понимания и вредных привычек у начинающих пользователей.