
Обучение — сложный процесс, который становится еще труднее, когда нету подходящего материала. И в начале моего обучения, я пытался найти какие-то туториалы. Но все что я находил были частичные гайди, которые носили поверхностных характер и не давали целостного представления о построении архитектуры. А документация по библиотекам не особо помогла при понимании некоторых функций:
Rx.Observable.prototype.flatMapLatest(selector, [thisArg])
Projects each element of an observable sequence into a new sequence of observable sequences by incorporating the element's index and then transforms an observable sequence of observable sequences into an observable sequence producing values only from the most recent observable sequence.
Святая Корова!
Я прочитал две книги, первая из которых всего лишь описывала общую картину, в то время, как вторая описывала использование конкретной библиотеки. Окончание обучения реактивному программированию было сложно — приходилось разбираться с ним в процессе работы. В Futurice я применил его в реальном проекте при поддержки некоторых своих коллег.
Самой сложной частью процесса обучения оказалось научить свой мозг работать в «реактивном» стиле, имея старые императивные привычки и стойкие шаблоны разработки. К сожалению я не нашел уроков в интернете, которые описывали бы этот аспект и я подумал, что мир заслуживает несколько слов о том, как думать в реактивном стиле. В общем, можем начинать. А документация библиотек может помочь продолжить полет после моей статьи. Я надеюсь, что я вам помогу.
Что такое Реактивное Программирование?
В интернете существует много плохих объяснений и определений реактивного программирования. Например Википедия как всегда все обобщает и теоретизирует, а Stackoverflow содержит каноничные ответы, которые не подходят новичку. Reactive Manifesto звучит, как одна из тех вещей, которые нужно показывать своему проектному менеджеру или бизнес аналитику своей компании. А Rx terminology «Rx = Observables + LINQ + Schedulers» настолько тяжел и майкрософтный, что большинству из нас остается только возмущаться. Слоганы вроде «реактивный» и «распространение изменений» не объясняют ничего конкретного, что отличало б типичный подход MV*, который уже встроен в ваш язык. Конечно же представления из моего фреймворка реагируют на модели. Конечно же распространение изменений. Если б это было не так — то мы б не увидели работу программы.
Ну что ж, давайте расставим точки над i.
Реактивное программирование — это программирование с асинхронными потоками(streams) данных.
В общем говоря, здесь нету ничего нового. Шины событий или типичные события нажатий на кнопки — это все реальные примеры асинхронных событийных потоков, которые вы можете слушать и выполнять некоторые побочные действия. По сути — реактивность эксплуатирует эту идею на стероидах. Вам предоставляется возможность создавать потоки чего-либо, не только события нажатий. Потоки легковесные и используются повсеместно: переменные, пользовательский ввод, свойства, кеш, структуры данных и многое многое другое. Например, лента Твитера может быть потоком данных наравне с чередой событий пользовательского интерфейса. То есть можно слушать поток и реагировать на события в нем.
Более того, вы получаете прекрасный набор инструментов и функций для сочетания, которые позволяют создавать и фильтровать каждый из этих потоков. Вот где «функциональная» магия дает о себе знать. Потоки могут быть использованы как входные параметры друг друга. Даже множественный поток может быть использован как входной аргумент другого потока. Вы можете объединять несколько потоков. Вы можете фильтровать один поток, чтобы потом получить другой, который содержит только актуальные данные. Вы можете объединять данные с одного потока с данными другого, чтобы получить еще один.
Так вот, если потоки — это центральная идея Реактивности, давайте более пристально рассмотрим их, начнем с знакомого нам событийного потока «нажатия на кнопку».
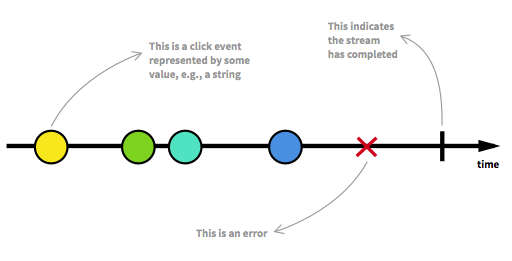
Поток — это последовательность, состоящая из постоянных событий, отсортированных по времени. В нем может быть три типа сообщений: значения (данные некоторого типа), ошибки и сигнал о завершении работы. Рассмотрим то, что сигнал о завершении имеет место для экземпляра объекта во время нажатия кнопки закрытия.
Мы получаем эти cгенерированные события асинхронно, всегда. Согласно идеологии реактивного программирования существуют три вида функций: те, которые должны выполняться, когда некоторые конкретные данные будут отправлены, функции обработки ошибок и другие функции с сигналами о завершении работы программы. Иногда последнее два пункта можно опустить и сосредоточится на определении функций для обработки значений. Слушать(listening) поток означает подписаться(subscribing) на него. То есть функции, которые мы определили это наблюдатели(observers). А поток является субъектом который наблюдают. Такой подход называется Observer Design Pattern.
Альтернативным способом представить вышеупомянутую диаграмму является ASCII графика, которую мы будем использовать в некоторых разделах этого туториала:--a---b-c---d---X---|-> a, b, c, d are emitted values X is an error | is the 'completed' signal ---> is the timeline
Чтобы не дать вам заскучать давайте разберем что-то новое, например создадим поток событий, преобразовав изначальный поток событий нажатий.
Первое что мы сделаем — добавим счетчик, который будет индикатором нажатий кнопки. В большинстве Реактивных библиотек каждый поток имеет много встроенных функций, таких как объединение, фильтр, сканер и так дальше. Когда вы вызываете одну из этих функций, таких как clickStream.map(f), она возвращает новый поток, который базируется на родительском(на clickStream). Дочерний поток никаким образом не затрагивает и не модифицирует своего родителя. Это свойство называется постоянностью(immutability) и является неотъемлемой частью реактивных потоков, так само как блинчики нельзя себе представить без сиропа. Это разрешает нам объединять функции(например — clickStream.map(f).scan(g)):
clickStream: ---c----c--c----c------c-->
vvvvv map(c becomes 1) vvvv
---1----1--1----1------1-->
vvvvvvvvv scan(+) vvvvvvvvv
counterStream: ---1----2--3----4------5-->
Функция map(f) создает новый поток, в котором с помощью функции f заменяться каждое новое событие. В нашем случае мы привязываем единицу к каждом нажатию на кнопку. Функция scan(g) агрегирует все предыдущие значение в потоке, возвращая значение x = g(accumulated, current). После этого counterStream посылает общее количество нажатий.
Для того, чтобы показать реальную силу Реактивного подхода, давайте просто скажем, что вы хотите получить поток, который будет вызывать двойное нажатие. Для того, чтобы сделать все более интересным, давайте скажем, что мы хотим чтобы новый поток рассматривал тройные нажатия как двойные, или, в общем, как мультинажатия(два или больше). Сделайте глубокий вдох и представьте что вы моли бы сделать то же самое в традиционной императивной манере. Я держу пари, что это звучит довольно мерзко и включает в себя переменные для сохранения некоторых состояний и временных интервалов.
То-есть, в Реактивном программирование все очень просто. По сути логика сосредоточена в 4 строчках кода
. Но давайте не будем обращать внимание на код, пока что. Размышление над диаграмой — лучший способ для понимания и построение потоков, без разницы, являетесь ли вы экспертом или только начинаете.

Серые прямоугольники являются функциями трансформации одного потока в другой. Первое, что мы сделали — аккумулировали клики в список. Всякий раз, когда 250 миллисекунд задержки события проходят (вот почему buffer(stream.throttle(250ms)), генерируется событие. Не переживайте насчет понимания деталей этого момента. Мы только разбираемся с Реактивностью. Результатом является поток списка, где к каждому элементу была применена функция map(), чтобы присоединить к каждому списку его длину. И наконец мы игнорируем число 1, используя функцию filter(x >= 2). Это все — всего 3 операции для того что бы создать наш целевой поток. Мы можем подписать на него листенер, который будет реагировать в точности так, как мы захотим.
Я надеюсь, что вы получили наслаждение от красоты этого подхода. Этот пример — всего лишь верхушка айсберга: вы можете применять те же операции к разным типам потоков данных, например к потокам ответа API. Ну и к тому же впереди еще огромное количество других функций.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (11)

xGromMx
21.03.2016 13:57+1ИМХО не надо. Лучший вариант понять это все — это написать с чистого листа и понять как это работает (как это сделал я давно) Если общественности надо, то я мог постараться рассказать о Rx в статьях, в которых мы бы писали свой Rx с пустого файла и рассмотрели такие темы как lazy evaluation, continuation monads и много чего еще интересного в плане функционального и реактивного программирования. Писать конечно я смогу не часто, но зато обещаю стабильность :D В любом случае, чтобы понять лучше написать и разобрать все самому и понять весь контракт и правила обработки. В Rx5 подход немного поменялся в частности появились новые способы создания новых операторов путем лифтинга ну еще немного изменений, но основной принцип подхода остался.

webmasterx
21.03.2016 14:49+1Если соберетесь, сделайте хорошие и законченные примеры близкие к реальной жизни. Именно этим страдают большинство статей, которые я повстречал.
xGromMx
21.03.2016 15:00Ну вот один из таких примеров в котором показано преимущество fp и rp https://jsfiddle.net/xgrommx/a9m50xev/

TheShock
21.03.2016 15:34Простите, преимущество над чем? Я правильно понимаю бизнес-задачу?
- Есть N элементов
- При клике на один из них — он становится единственным активным
- При клике с контрол или шифт один элемент добавляется к списку активных
- При клике на активный — все деактивируются
- При клике на активный с контрол или шифт — один деактивируется
Всё?
TheShock
21.03.2016 21:08+2Ну вот один из таких примеров в котором показано преимущество fp и rp jsfiddle.net/xgrommx/a9m50xev
Вы вот утверждаете, что тут показано преимущество. Но в чём преимущество?
Вот тот же код в императивном стиле: https://jsfiddle.net/0co58hr8/3/
Он, конечно, не так модно выглядит, нету клёвых pipe и кучи смайликов, но он короче, он доступнее для понимания, никаких непонятных библиотек.
А ещё в нем нету странного багаSTR:
- Click on [1]
- Ctrl+Click on [6]
- Ctrl+Click on [6]
- See: Active only [1]
- Shift+Click on [3]
Expected:
Active are [1],[2],[3]
Actual:
Active are [1],[3],[4],[5],[6]

technont64
21.03.2016 16:36Даже этой статьи хватило чтобы в голове щелкнуло, и появилось впечатление понимания :)
У меня стойкое ощущение, что реактивность крайне схожа с достаточно старым подходом — рассматривать все как поток данных.
В таком виде появляются плюшки в виде Map-Reduce, разделения логики от данных, становится гораздо проще раскидать обработку по разным потокам.
Чем-то похоже на Entity-System (https://habrahabr.ru/post/197920/)
А любителям нырнуть поглубже могу посоветовать эту онлайн-книгу:
www.dataorienteddesign.com/dodmain
webmasterx
читал это как раз вчера, но полной ясности так и не принесло
burjui
Может быть, вам и многим другим непонятно из-за того, что нигде не объясняют самой сути: чтто Observable, по сути, является Iterable, вывернутым наизнанку относительно управления потоком данных: Iterable — это модель pull (сами просим данные), а Observable — push (данные летят в нас).
Мне кажется, после этого видео Эрика Мейера, создателя Rx, не должно остаться вопросов:
https://www.youtube.com/watch?v=sTSQlYX5DU0
xGromMx
Согласимся =)