
Есть два отличных пакета для работы с данными в R —
Здесь можно найти руководство и краткое описание
В первой части: начало работы с данными, выбор, удаление и переименование столбцов.
Чтобы выбрать из данных некоторые строки, нужно использовать глагол
Чтобы упорядочить строки, нужно использовать глагол
Давайте отсортируем по State по возрастанию и End_Date по убыванию.
В
Для получения обобщенной статистики можно использовать функцию
Можно также получить обобщенную статистику по отдельным частям данных. В

Также можно использовать более чем одно условие группировки.
И

Средние затраты на случай, по штатам
Средние затраты на случай, по штатам
Мы рассмотрели, как можно осуществлять одни и те же операции с помощью пакетов
Код, использующийся в этой статье, доступен на GitHub.
dplyr и data.table. У каждого пакета свои сильные стороны. dplyr элегантнее и похож на естественный язык, в то время как data.table лаконичный, с его помощью многое можно сделать всего в одну строку. Более того, в некоторых случаях data.table быстрее (сравнительный анализ доступен здесь), и это может определить выбор, если есть ограничения по памяти или производительности. Сравнение dplyr и data.table можно также почитать на Stack Overflow и Quora.Здесь можно найти руководство и краткое описание
data.table, а здесь — для dplyr. Также можно почитать обучающие материалы по dplyr на DataScience+.В первой части: начало работы с данными, выбор, удаление и переименование столбцов.
Выбрать определенные строки из данных
Чтобы выбрать из данных некоторые строки, нужно использовать глагол
filter из dplyr вместе с условиями, которые могут содержать регулярные выражения. В data.table нужны только условия.Фильтровать по одной переменной
from_dplyr = filter(hospital_spending,State=='CA') # выбрать строки для Калифорнии
from_data_table = hospital_spending_DT[State=='CA']
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
dropped attributes
Фильтровать по нескольким переменным
from_dplyr = filter(hospital_spending,State=='CA' & Claim.Type!="Hospice")
from_data_table = hospital_spending_DT[State=='CA' & Claim.Type!="Hospice"]
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
dropped attributes
from_dplyr = filter(hospital_spending,State %in% c('CA','MA',"TX"))
from_data_table = hospital_spending_DT[State %in% c('CA','MA',"TX")]
unique(from_dplyr$State)
CA MA TX
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
dropped attributes
Упорядочить данные
Чтобы упорядочить строки, нужно использовать глагол
arrange в dplyr. Это можно сделать по одной или нескольким переменным. Для сортировки по убыванию используют desc(), как в примерах. Примеры сортировки по убыванию и возрастанию очевидны. Давайте отсортируем данные по одной переменной. По возрастанию
from_dplyr = arrange(hospital_spending, State)
from_data_table = setorder(hospital_spending_DT, State)
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
dropped attributes
По убыванию
from_dplyr = arrange(hospital_spending, desc(State))
from_data_table = setorder(hospital_spending_DT, -State)
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
dropped attributes
Сортировка по нескольким переменным
Давайте отсортируем по State по возрастанию и End_Date по убыванию.
from_dplyr = arrange(hospital_spending, State,desc(End_Date))
from_data_table = setorder(hospital_spending_DT, State,-End_Date)
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
dropped attributes
Добавить/удалить столбец(цы)
В
dplyr для добавления столбцов используется функция mutate(). В data.table можно добавить или изменить столбец по ссылке, в одну строку, используя :=.from_dplyr = mutate(hospital_spending, diff=Avg.Spending.Per.Episode..State. - Avg.Spending.Per.Episode..Nation.)
from_data_table = copy(hospital_spending_DT)
from_data_table = from_data_table[,diff := Avg.Spending.Per.Episode..State. - Avg.Spending.Per.Episode..Nation.]
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
sorted
renamed rows
dropped row names
dropped attributes
from_dplyr = mutate(hospital_spending, diff1=Avg.Spending.Per.Episode..State. - Avg.Spending.Per.Episode..Nation.,diff2=End_Date-Start_Date)
from_data_table = copy(hospital_spending_DT)
from_data_table = from_data_table[,c("diff1","diff2") := list(Avg.Spending.Per.Episode..State. - Avg.Spending.Per.Episode..Nation.,diff2=End_Date-Start_Date)]
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
dropped attributes
Получить обобщенную информацию о столбцах
Для получения обобщенной статистики можно использовать функцию
summarize() из dplyr.summarize(hospital_spending,mean=mean(Avg.Spending.Per.Episode..Nation.))
mean 8.772727
hospital_spending_DT[,.(mean=mean(Avg.Spending.Per.Episode..Nation.))]
mean 8.772727
summarize(hospital_spending,mean=mean(Avg.Spending.Per.Episode..Nation.),
maximum=max(Avg.Spending.Per.Episode..Nation.),
minimum=min(Avg.Spending.Per.Episode..Nation.),
median=median(Avg.Spending.Per.Episode..Nation.))
mean maximum minimum median
8.77 19 1 8.5
hospital_spending_DT[,.(mean=mean(Avg.Spending.Per.Episode..Nation.),
maximum=max(Avg.Spending.Per.Episode..Nation.),
minimum=min(Avg.Spending.Per.Episode..Nation.),
median=median(Avg.Spending.Per.Episode..Nation.))]
mean maximum minimum median
8.77 19 1 8.5
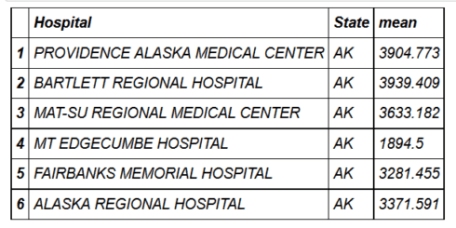
Можно также получить обобщенную статистику по отдельным частям данных. В
dplyr есть функция group_by(), а в data.table просто используется by.head(hospital_spending_DT[,.(mean=mean(Avg.Spending.Per.Episode..Hospital.)),by=.(Hospital)])
mygroup= group_by(hospital_spending,Hospital)
from_dplyr = summarize(mygroup,mean=mean(Avg.Spending.Per.Episode..Hospital.))
from_data_table=hospital_spending_DT[,.(mean=mean(Avg.Spending.Per.Episode..Hospital.)), by=.(Hospital)]
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
sorted
renamed rows
dropped row names
dropped attributes
Также можно использовать более чем одно условие группировки.
head(hospital_spending_DT[,.(mean=mean(Avg.Spending.Per.Episode..Hospital.)),
by=.(Hospital,State)])
mygroup= group_by(hospital_spending,Hospital,State)
from_dplyr = summarize(mygroup,mean=mean(Avg.Spending.Per.Episode..Hospital.))
from_data_table=hospital_spending_DT[,.(mean=mean(Avg.Spending.Per.Episode..Hospital.)), by=.(Hospital,State)]
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
sorted
renamed rows
dropped row names
dropped attributes
Последовательное соединение
И
dplyr, и data.table позволяют строить цепочки функций. В dplyr можно использовать конвейеры из пакета magrittr с помощью %>%. %>% передает результат одной функции в качестве первого аргумента следующей за ней. В data.table для построения цепочек используют %>% или [.from_dplyr=hospital_spending%>%group_by(Hospital,State)%>%summarize(mean=mean(Avg.Spending.Per.Episode..Hospital.))
from_data_table=hospital_spending_DT[,.(mean=mean(Avg.Spending.Per.Episode..Hospital.)), by=.(Hospital,State)]
compare(from_dplyr,from_data_table, allowAll=TRUE)
TRUE
sorted
renamed rows
dropped row names
dropped attributes
hospital_spending%>%group_by(State)%>%summarize(mean=mean(Avg.Spending.Per.Episode..Hospital.))%>%
arrange(desc(mean))%>%head(10)%>%
mutate(State = factor(State,levels = State[order(mean,decreasing =TRUE)]))%>%
ggplot(aes(x=State,y=mean))+geom_bar(stat='identity',color='darkred',fill='skyblue')+
xlab("")+ggtitle('Average Spending Per Episode by State')+
ylab('Average')+ coord_cartesian(ylim = c(3800, 4000))
Средние затраты на случай, по штатам
hospital_spending_DT[,.(mean=mean(Avg.Spending.Per.Episode..Hospital.)),
by=.(State)][order(-mean)][1:10]%>%
mutate(State = factor(State,levels = State[order(mean,decreasing =TRUE)]))%>%
ggplot(aes(x=State,y=mean))+geom_bar(stat='identity',color='darkred',fill='skyblue')+
xlab("")+ggtitle('Average Spending Per Episode by State')+
ylab('Average')+ coord_cartesian(ylim = c(3800, 4000))
Средние затраты на случай, по штатам
Заключение
Мы рассмотрели, как можно осуществлять одни и те же операции с помощью пакетов
data.table и dplyr. Каждый пакет имеет свои преимущества.Код, использующийся в этой статье, доступен на GitHub.
Поделиться с друзьями