

Фейсбук автоматически маркирует людей на ваших фотографиях, которых вы отметили когда-то ранее. Я не могу определиться для себя, полезно это или жутковато!
Эта технология называется распознавание лиц. Алгоритмы Фейсбука могут распознавать лица ваших друзей после того, как вы отметили их лишь пару-тройку раз. Это — удивительная технология: Фейсбук в состоянии распознавать лица с точностью 98% — практически так же, как и человек!
Рассмотрим, как работает современное распознавание лиц! Однако просто распознавать ваших друзей было бы слишком легко. Мы можем подойти к границе этой технологии, чтобы решить более сложную задачу — попробуем отличить Уилла Феррелла (известный актёр) от Чеда Смита (известный рок-музыкант)!

Один из этих людей — Уилл Феррелл. Другой — Чед Смит. Клянусь — это разные люди!
Как использовать обучение машины при очень сложной проблеме
До сих пор в частях 1, 2 и 3 мы использовали обучение машины для решения изолированных проблем, имеющих только один шаг — оценка стоимости дома, создание новых данных на базе существующих и определение, содержит ли изображение некоторый объект. Все эти проблемы могут быть решены выбором одного алгоритма обучения машины, вводом данных и получением результата.
Но распознавание лиц представляет собой фактически последовательность нескольких связанных проблем:
1. Во-первых, необходимо рассмотреть изображение и найти на нём все лица.
2. Во-вторых, необходимо сосредоточиться на каждом лице и определить, что, несмотря на неестественный поворот лица или неважное освещение, это — один и тот же человек.
3. В-третьих, надо выделить уникальные характеристики лица, которые можно использовать для отличия его от других людей — например, размер глаз, удлинённость лица и т.п.
4. В завершение необходимо сравнить эти уникальные характеристики лица с характеристиками других известных вам людей, чтобы определить имя человека.
Мозг человека проделывает всё это автоматически и мгновенно. Фактически, люди чрезвычайно хорошо распознают лица и, в конечном итоге, видят лица в повседневных предметах:

Компьютеры неспособны к такого рода высокому уровню обобщения (как минимум, пока …), поэтому приходится учить их каждому шагу в этом процессе отдельно.
Необходимо построить конвейер, на котором мы будем находить решение на каждом шаге процесса распознавания лица отдельно и передавать результат текущего шага на следующий. Другими словами, мы соединим в одну цепь несколько алгоритмов обучения машины:

Как может работать базовый процесс распознавания лиц
Распознавание лиц — шаг за шагом
Давайте решать эту проблему последовательно. На каждом шаге мы будем узнавать о новом алгоритме обучения машины. Я не собираюсь разъяснять каждый отдельный алгоритм полностью, чтобы не превратить эту статью в книгу, но вы узнаете основные идеи, заключающиеся в каждом из алгоритмов, и узнаете, как можно создать свою собственную систему распознавания лиц в Python, используя OpenFace и dlib.
Шаг 1. Нахождение всех лиц
Первым шагом на нашем конвейере является обнаружение лиц. Совершенно очевидно, что необходимо выделить все лица на фотографии, прежде чем пытаться распознавать их!
Если вы использовали в последние 10 лет какую-либо фотографию, то вы, вероятно, видели, как действует обнаружение лиц:
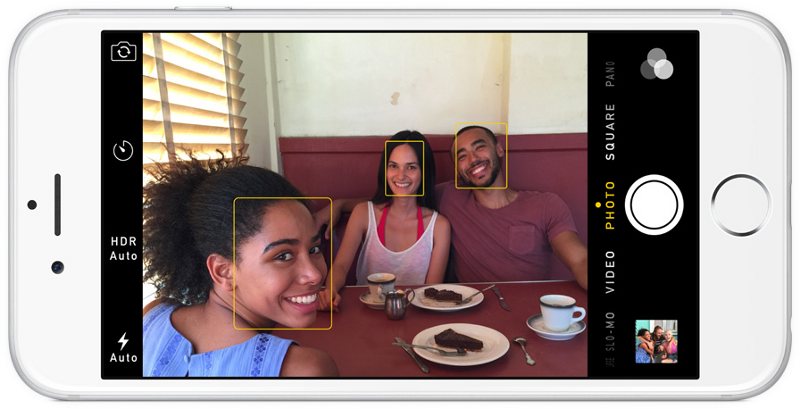
Обнаружение лиц — великое дело для фотокамер. Если камера может автоматически обнаруживать лица, то можно быть уверенным, что все лица окажутся в фокусе, прежде чем будет сделан снимок. Но мы будем использовать это для другой цели — нахождение областей изображения, которые надо передать на следующий этап нашего конвейера.
Обнаружение лица стало господствующей тенденцией в начале 2000-х годов, когда Пол Виола и Майкл Джонс изобрели способ обнаруживать лица, который был достаточно быстрым, чтобы работать на дешёвых камерах. Однако сейчас существуют намного более надёжные решения. Мы собираемся использовать метод, открытый в 2005 году, — гистограмма направленных градиентов (коротко, HOG).
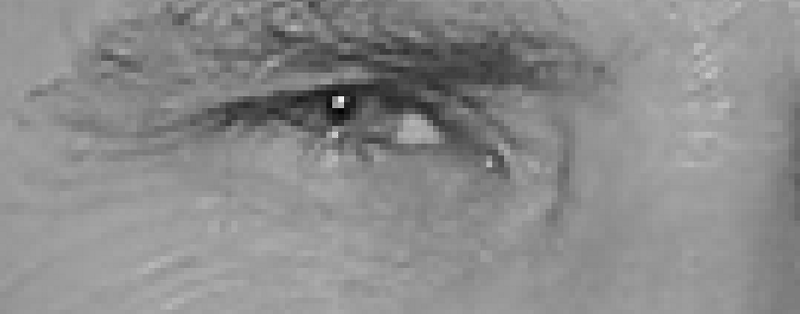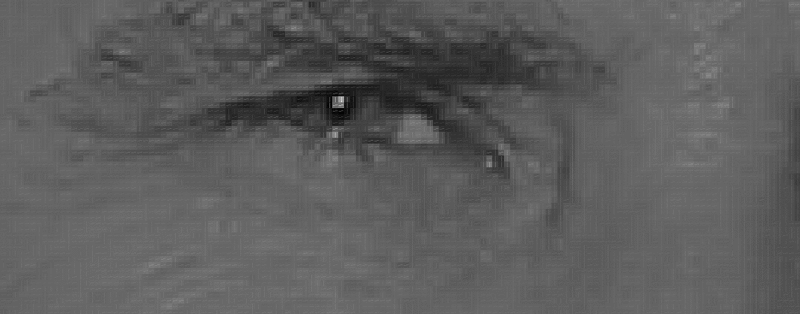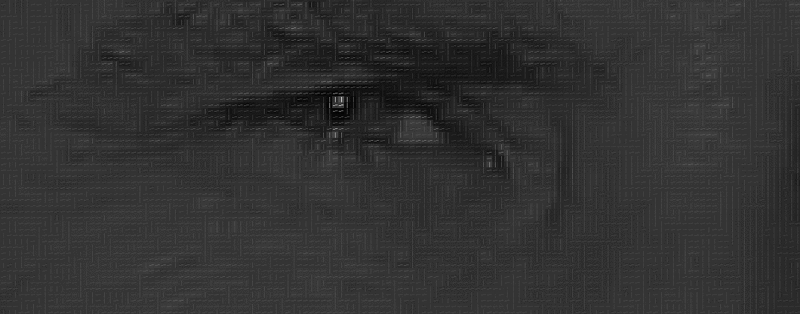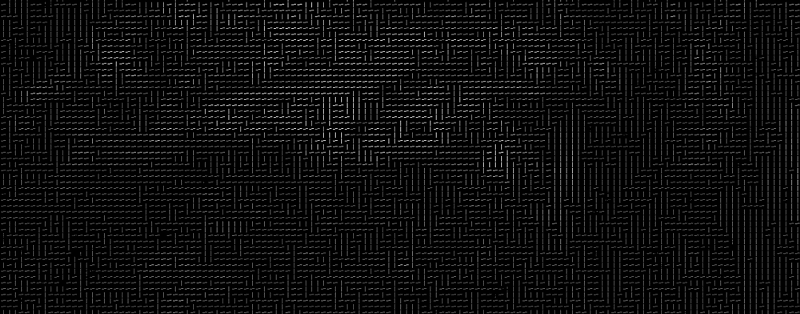
Для обнаружения лиц на изображении мы сделаем наше изображение чёрно-белым, т.к. данные о цвете не нужны для обнаружения лиц:

Затем мы рассмотрим каждый отдельный пиксель на нашем изображении последовательно. Для каждого отдельного пикселя следует рассмотреть его непосредственное окружение:

Нашей целью является выделить, насколько тёмным является текущий пиксель по сравнению с пикселями, прямо примыкающими к нему. Затем проведём стрелку, показывающую направление, в котором изображение становится темнее:

При рассмотрении этого одного пикселя и его ближайших соседей видно, что изображение темнеет вверх вправо.
Если повторить этот процесс для каждого отдельного пикселя на изображении, то, в конечном итоге, каждый пиксель будет заменён стрелкой. Эти стрелки называют градиентом, и они показывают поток от света к темноте по всему изображению:
Может показаться, что результатом является нечто случайное, но есть очень хорошая причина для замены пикселей градиентами. Когда мы анализируем пиксели непосредственно, то у тёмных и светлых изображений одного и того же человека будут сильно различающиеся значения интенсивности пикселей. Но если рассматривать только направление изменения яркости, то как тёмное, так и светлое изображения будут иметь совершенно одинаковое представление. Это значительно облегчает решение проблемы!
Но сохранение градиента для каждого отдельного пикселя даёт нам способ, несущий слишком много подробностей. Мы, в конечном счёте, не видим леса из-за деревьев. Было бы лучше, если бы мы могли просто видеть основной поток светлого/тёмного на более высоком уровне, рассматривая таким образом базовую структуру изображения.
Для этого разбиваем изображение на небольшие квадраты 16х16 пикселей в каждом. В каждом квадрате следует подсчитать, сколько градиентных стрелок показывает в каждом главном направлении (т.е. сколько стрелок направлено вверх, вверх-вправо, вправо и т.д.). Затем рассматриваемый квадрат на изображении заменяют стрелкой с направлением, преобладающим в этом квадрате.
В конечном результате мы превращаем исходное изображение в очень простое представление, которое показывает базовую структуру лица в простой форме:

Исходное изображение преобразовано в HOG-представление, демонстрирующее основные характеристики изображения независимо от его яркости.
Чтобы обнаружить лица на этом HOG-изображении, всё, что требуется от нас, это найти такой участок изображения, который наиболее похож на известную HOG-структуру, полученную из группы лиц, использованной для обучения:

Используя этот метод, можно легко находить лица на любом изображении:

Если есть желание выполнить этот этап самостоятельно, используя Python и dlib, то имеется программа, показывающая, как создавать и просматривать HOG-представления изображений.
Шаг 2. Расположение и отображение лиц
Итак, мы выделили лица на нашем изображении. Но теперь появляется проблема: одно и то же лицо, рассматриваемое с разных направлений, выглядит для компьютера совершенно по-разному:

Люди могут легко увидеть, что оба изображения относятся к актёру Уиллу Ферреллу, но компьютеры будут рассматривать их как лица двух разных людей.
Чтобы учесть это, попробуем преобразовывать каждое изображение так, чтобы глаза и губы всегда находились на одном и том же месте изображения. Сравнение лиц на дальнейших шагах будет значительно упрощено.
Для этого используем алгоритм, называемый «оценка антропометрических точек». Есть много способов сделать это, но мы собираемся использовать подход, предложенный в 2014 году Вахидом Кэземи и Джозефином Салливаном.
Основная идея в том, что выделяется 68 специфических точек (меток), имеющихся на каждом лице, — выступающая часть подбородка, внешний край каждого глаза, внутренний край каждой брови и т.п. Затем происходит настройка алгоритма обучения машины на поиск этих 68 специфических точек на каждом лице:

68 антропометрических точек мы располагаем на каждом лице
Ниже показан результат расположения 68 антропометрических точек на нашем тестовом изображении:

СОВЕТ ПРОФЕССИОНАЛА НОВИЧКУ: этот же метод можно использовать для ввода вашей собственной версии 3D-фильтров лица реального времени в Snapchat!
Теперь, когда мы знаем, где находятся глаза и рот, мы будем просто вращать, масштабировать и сдвигать изображение так, чтобы глаза и рот оказались отцентрованы как можно лучше. Мы не будем вводить какие-либо необычные 3D-деформации, поскольку они могут исказить изображение. Мы будет делать только базовые преобразования изображения, такие как вращение и масштабирование, которые сохраняют параллельность линий (т.н. аффинные преобразования):

Теперь независимо от того, как повёрнуто лицо, мы можем отцентровать глаза и рот так, чтобы они были примерно в одном положении на изображении. Это сделает точность нашего следующего шага намного выше.
Если у вас есть желание попытаться выполнить этот шаг самостоятельно, используя Python и dlib, то имеется программа для нахождения антропометрических точек и программа для преобразования изображения на основе этих точек.
Шаг 3. Кодирование лиц
Теперь мы подошли к сути проблемы — само различение лиц. Здесь-то и начинается самое интересное!
Простейшим подходом к распознаванию лиц является прямое сравнение неизвестного лица, обнаруженного на шаге 2, со всеми уже отмаркированными лицами. Если мы найдём уже отмаркированное лицо, очень похожее на наше неизвестное, то это будет означать, что мы имеем дело с одним и тем же человеком. Похоже, очень хорошая идея, не так ли?
На самом деле при таком подходе возникает огромная проблема. Такой сайт как Фейсбук с миллиардами пользователей и триллионами фотографий не может достаточно циклично просматривать каждое ранее отмаркированное лицо, сравнивая его с каждой новой загруженной картинкой. Это потребовало бы слишком много времени. Необходимо распознавать лица за миллисекунды, а не за часы.
Нам требуется научиться извлекать некоторые базовые характеристики из каждого лица. Затем мы могли бы получить такие характеристики с неизвестного лица и сравнить с характеристиками известными лиц. Например, можно обмерить каждое ухо, определить расстояние между глазами, длину носа и т.д. Если вы когда-либо смотрели телесериал о работе сотрудников криминалистической лаборатории Лас-Вегаса («C.S.I.: место преступления»), то вы знаете, о чём идёт речь:

Как в кино! Так похоже на правду!
Самый надёжный метод обмерить лицо
Хорошо, но какие характеристики надо получить с каждого лица, чтобы построить базу данных известных лиц? Размеры уха? Длина носа? Цвет глаз? Что-нибудь ещё?
Оказывается, что характеристики, представляющиеся очевидными для нас, людей, (например, цвет глаз) не имеют смысла для компьютера, анализирующего отдельные пиксели на изображении. Исследователи обнаружили, что наиболее адекватным подходом является дать возможность компьютеру самому определить характеристики, которые надо собрать. Глубинное обучение позволяет лучше, чем это могут сделать люди, определить части лица, важные для его распознавания.
Решение состоит в том, чтобы обучить глубокую свёрточную нейронную сеть (именно это мы делали в выпуске 3). Но вместо обучения сети распознаванию графических объектов, как мы это делали последний раз, мы теперь собираемся научить её создавать 128 характеристик для каждого лица.
Процесс обучения действует при рассмотрении 3-х изображений лица одновременно:
1. Загрузите обучающее изображение лица известного человека
2. Загрузите другое изображение лица того же человека
3. Загрузите изображение лица какого-то другого человека
Затем алгоритм рассматривает характеристики, которые он в данный момент создаёт для каждого из указанных трёх изображений. Он слегка корректирует нейронную сеть так, чтобы характеристики, созданные ею для изображений 1 и 2, оказались немного ближе друг к другу, а для изображений 2 и 3 — немного дальше.
Единый «строенный» шаг обучения:

После повтора этого шага миллионы раз для миллионов изображений тысяч разных людей нейронная сеть оказывается в состоянии надёжно создавать 128 характеристик для каждого человека. Любые десять различных изображений одного и того же человека дадут примерно одинаковые характеристики.
Специалисты по обучению машин называют эти 128 характеристик каждого лица набором характеристик (признаков). Идея сведения сложных исходных данных, таких как, например, изображение, к списку генерируемых компьютером чисел оказалась чрезвычайно перспективной в обучении машин (в частности, для переводов). Такой подход для лиц, который мы используем, был предложен в 2015 году исследователями из Гугл, но существует много аналогичных подходов.
Кодировка нашего изображения лица
Процесс обучения свёрточной нейронной сети с целью вывода наборов характеристик лица требует большого объёма данных и большой производительности компьютера. Даже на дорогой видеокарте NVidia Telsa требуется примерно 24 часа непрерывного обучения для получения хорошей точности.
Но если сеть обучена, то можно создавать характеристики для любого лица, даже для того, которое ни разу не видели раньше! Таким образом, этот шаг требуется сделать лишь один раз. К счастью для нас, добрые люди на OpenFace уже сделали это и предоставили доступ к нескольким прошедшим обучение сетям, которые мы можем сразу же использовать. Спасибо Брендону Амосу и команде!
В результате всё, что требуется от нас самих, это провести наши изображения лиц через их предварительно обученную сеть и получить 128 характеристик для каждого лица. Ниже представлены характеристики для нашего тестового изображения:

Но какие конкретно части лица эти 128 чисел описывают? Оказывается, что мы не имеем ни малейшего представления об этом. Однако на самом деле это не имеет значения для нас. Нас должно заботить лишь то, чтобы сеть выдавала примерно одни и те же числа, анализируя два различных изображения одного и того же человека.
Если есть желание попробовать выполнить этот шаг самостоятельно, то OpenFace предоставляет Lua-скрипт, создающий наборы характеристик всех изображений в папке и записывающий их в csv-файл. Можно запустить его так, как показано.
Шаг 4. Нахождение имени человека после кодировки лица
Последний шаг является фактически самым лёгким во всём этом процессе. От нас требуется лишь найти человека в нашей базе данных известных лиц, имеющего характеристики, наиболее близкие к характеристикам нашего тестового изображения.
Это можно сделать, используя любой базовый алгоритм классификации обучения машин. Какие-либо особые приёмы глубинного обучения не требуются. Мы будем использовать простой линейный SVM-классификатор, но могут быть применены и многие другие алгоритмы классификации.
От нас потребуется только обучить классификатор, который сможет взять характеристики нового тестового изображения и сообщить, какое известное лицо имеет наилучшее соответствие. Работа такого классификатора занимает миллисекунды. Результатом работы классификатора является имя человека!
Опробуем нашу систему. Прежде всего я обучил классификатор, используя наборы характеристики от примерно 20 изображений Уилла Феррелла, Чеда Смита и Джимми Фэлона:

О, эти восхитительные картинки для обучения!
Затем я прогнал классификатор на каждом кадре знаменитого видеоролика на Youtube, где на шоу Джимми Фэлона Уилл Феррелл и Чед Смит прикидываются друг другом:

Сработало! И смотрите, как великолепно это сработало для лиц с самых разных направлений — даже в профиль!
Самостоятельное выполнение всего процесса
Рассмотрим требуемые шаги:
1. Обработайте картинку, используя HOG-алгоритм, чтобы создать упрощённую версию изображения. На этом упрощённом изображении найдите тот участок, который более всего похож на созданное HOG-представление лица.
2. Определите положение лица, установив главные антропометрические точки на нём. После позиционирования этих антропометрических точек используйте их для преобразования изображения с целью центровки глаз и рта.
3. Пропустите отцентрованное изображение лица через нейронную сеть, обученную определению характеристик лица. Сохраните полученные 128 характеристик.
4. Просмотрев все лица, характеристики которых были сняты раньше, определите человека, характеристики лица которого наиболее близки к полученным. Дело сделано!
Теперь, когда вы знаете, как всё это работает, просмотрите инструкции с самого начала до конца, как провести весь процесс распознавания лица на вашем собственном компьютере, используя OpenFace:
Прежде чем начать
Убедитесь, что Python, OpenFace и dlib у вас установлены. Их можно установить вручную или использовать предварительно сконфигурированное контейнерное изображение, в котором это всё уже установлено:
docker pull bamos/openface
docker run -p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash
cd /root/openfaceСовет профессионала новичку: если вы используете Docker на OSX, то можно сделать папку OSX/Users/ видимой внутри контейнерного изображения, как показано ниже:
docker run -v /Users:/host/Users -p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash
cd /root/openfaceЗатем можно выйти на все ваши OSX-файлы внутри контейнерного изображения на /host/Users/…
ls /host/Users/Шаг 1
Создайте папку с названием
./training-images/ в папке openface.mkdir training-imagesШаг 2
Создайте подпапку для каждого человека, которого надо распознать. Например:
mkdir ./training-images/will-ferrell/
mkdir ./training-images/chad-smith/
mkdir ./training-images/jimmy-fallon/Шаг 3
Скопируйте все изображения каждого человека в соответствующие подпапки. Убедитесь, что на каждом изображении имеется только одно лицо. Не требуется обрезать изображение вокруг лица. OpenFace сделает это автоматически.
Шаг 4
Выполните скрипты openface из корневого директория openface:
Сначала должны быть выполнены обнаружение положения и выравнивание:
./util/align-dlib.py ./training-images/ align outerEyesAndNose ./aligned-images/ --size 96В результате будет создана новая подпапка
./aligned-images/ с обрезанной и выровненной версией каждого из ваших тестовых изображений.Затем создайте представления из выровненных изображений:
./batch-represent/main.lua -outDir ./generated-embeddings/ -data ./aligned-images/Подпапка
./generated-embeddings/ будет содержать csv-файл с наборами характеристик для каждого изображения.Проведите обучение вашей модели обнаружения лица:
./demos/classifier.py train ./generated-embeddings/Будет создан новый файл с именем
./generated-embeddings/classifier.pk. Этот файл содержит SVM-модель, которая будет использоваться для распознавания новых лиц.С этого момента у вас появляется работающий распознаватель лиц!
Шаг 5. Распознаём лица!
Возьмите новую картинку с неизвестным лицом. Пропустите её через скрипт классификатора, типа нижеследующего:
./demos/classifier.py infer ./generated-embeddings/classifier.pkl your_test_image.jpgВы должны получить примерно такое предупреждение:
=== /test-images/will-ferrel-1.jpg ===
Predict will-ferrell with 0.73 confidence.Здесь, если пожелаете, можете настроить python-скрипт
./demos/classifier.py.Важные замечания:
• Если результаты неудовлетворительные, то попытайтесь добавить ещё несколько изображений для каждого человека на шаге 3 (особенно изображения с разных направлений).
• Данный скрипт будет всегда выдавать предупреждение, даже если он не знает это лицо. При реальном использовании необходимо проверить степень уверенности и убрать предупреждения с низким значением степени уверенности, поскольку они, скорее всего, неправильные.
Комментарии (22)


astill
28.07.2016 16:19+1Но какие конкретно части лица эти 128 чисел описывают? Оказывается, что мы не имеем ни малейшего представления об этом.
После этой фразы я подумал о skynet. А если серьезно, по какому принципу она создает 128 характеристик? Где об этом можно прочитать подробнее?
DirectX
28.07.2016 22:40Ну очень условно: вот есть 68 особых точек, заданных своими координатами. Самое простое, с чего можно начать — к примеру измерить между ними расстояния. По сути получится полный граф, рёбрам которого можно присвоить значение расстояний. Если у нас есть n=68 точек, то значит имеется n(n-1)/2 = 2278 возможных расстояний между точками — столько же возможных параметров. Суть алгоритма обучения — оставить из 2 тысяч только 128, но самых характерных.
NindzyA_RulS
29.07.2016 08:27Для этого нужно обрезать голову сети — так мы получим карты фильтров. Эти фильтры показывают области, вносящие наибольший вклад в определение класса входного изображения. Если теперь эти фильтры применить к конкретному изображению — «засветим» характерные черты конкретного человека.

Deosis
29.07.2016 08:30А кто-нибудь пробовал по этим признакам восстановить лицо?
Уже есть подходы (Deep learning например) восстановления изображения из признаков.
Если построить анимацию изменения одного признака, то есть шанс увидеть, за что отвечает данный признак.
Где на хабре видел подобную статью с птицей.
staticlab
29.07.2016 11:31Можете попробовать почитать Parkhi et al. Deep face recognition.
Вкратце — тренируется специальная свёрточная нейронная сеть. Нейросеть из начального набора параметров генерирует числовой вектор (n=128). Соответственно, она натаскивается так, чтобы для разных лиц эти векторы были как можно более разными. В конечном итоге получается некая «формула», которая для искомого лица выдаёт 128-вектор. Но зависимость между исходными данными и результатом может быть очень сложной, хотя это можно исследовать и попытаться выявить закономерности.

daiver19
28.07.2016 16:20Но вместо обучения сети распознаванию графических объектов, как мы это делали последний раз, мы теперь собираемся научить её создавать 128 характеристик для каждого лица.
Получается же embedding, верно? Только вместо традиционного словаря сверточная сеть?

EmachinesDIMA
28.07.2016 17:19-1ОГОгошеньки!!! Огромнейшее СПАСИБО!!! Интереснейшая статья и, к тому же, пошаговая инструкция.
Начну сегодня же! хоте нет, сперва один проект закончу, а после и начну!
Idot
28.07.2016 21:46+1По хорошему, лицо надо бы различать как трёхмерный объект, а не как плоскую маску.

{kind=link}

ZlodeiBaal
28.07.2016 23:48+31) Ну, разница HOG и Haar минимальна на лицах. HOG неплохо выигрывает на тушках, но на лицах этого нет.
2) То что вы называете «оценка антропометрических точек» это называется «активные модели внешнего вида» (AAM) и появились они не в 2014, а в 1998 году — https://habrahabr.ru/post/155759/
3) Классификатор на 3 лица неинтересно обучать. Вот обучите на 25, например. А распознавайте этих же трёх. И тогда люди начнут ой как путаться;) А трёх человек даже eigenface распознает.
Хотя да, есть сейчас модели которые куда лучше распознают, но не эта. И всё равно точность ограничена.NindzyA_RulS
29.07.2016 09:10Kazemi et al. предложили именно способ автоматического нахождения антропометрических точек (лэндмарков) на произвольном изображении, причем очень быстрый. Тогда как AAM / ASM — способ сопоставления лиц на основе лэндмарков.
Update: по опыту коммерческого применения, Haar чаще фолтит (просто не умеем его готовить?), даже на фронтальных, но и повороты отрабатывает, и засветы и пр. мусор. Тогда как HOG не пропускает (корректно отрабатывает) фронтальные вообще, а на поворотных, засвченных и т.п. — хуже.ZlodeiBaal
29.07.2016 11:10Эмм. Нет же. AAM ASM это не способ составления. Это способ натянуть модель формы на объект — https://en.wikipedia.org/wiki/Active_shape_model
Я не спорю, что более современные методы работают получше. Но идея идёт именно из работ 1995-1998 года.

BelBES
02.08.2016 11:171) Ну, разница HOG и Haar минимальна на лицах. HOG неплохо выигрывает на тушках, но на лицах этого нет.
Крутые пацаны сейчас вообще используют всякие ICF, ну или Deep Learning
3) Классификатор на 3 лица неинтересно обучать. Вот обучите на 25, например. А распознавайте этих же трёх. И тогда люди начнут ой как путаться;) А трёх человек даже eigenface распознает.
Так вроде бы Зисерман и Ко своими триплетами обучали сетку на 1000 уникальных людей… да и findface как-то работает.
ZlodeiBaal
02.08.2016 11:20Так вроде бы Зисерман и Ко своими триплетами обучали сетку на 1000 уникальных людей… да и findface как-то работает.
Да. Но там и не вектора на 128фич на выходе свёрточной сети. Тут всё же старое и простое решение используется.

modernstyle
02.08.2016 12:40Реквевстирую такое сравнение для Натали Портман и Киры Найтли — вот где нейронная сеть даст сбой!
andybelo
02.08.2016 13:39Такое распознавание легко обходится. вот: https://nplus1.ru/news/2016/07/25/adversarial
Речь идет о изображениях-обманках (adversarial examples), которые можно сделать на основе любой исходной картинки. Для человека такие изображения почти не отличимы от оригинала, однако в них внесены некоторые изменения, которые существенно усложняют их распознавание нейросетью. Потенциально, такие изображения можно использовать для обхода автоматических фильтров спама, систем распознавания лиц или для подделки биометрии.
maaGames
На мой взгляд Чед Смит и Уилл Фаррелл вообще не похожи друг на друга. Разные носы, разные уши, разные подбородки, носогубный треугольник. Только брови и глаза слегка похожи.
Но вот что нейронная сеть их различает — это жутко круто.
Расистский вопрос: Градиенты корректно строятся на сильно чёрной коже или вы испортили шутку про «невидимых» негров на определителе лиц?
Второй вопрос: Если в HOG структуре для каждого квадрата 16*16 указывается направление градиента, то почему там не одна стрелка, а «пучок»?