

Фрагмент 32?32 пикселя оригинального изображения, сжатого разными методами. Иллюстрация: Google
Разработчики из компании Google поделились очередными достижениями в применении нейросетей для практических задач. 18 августа они опубликовали на arXiv научную статью «Сжатие полноразмерных изображений с помощью рекуррентных нейронных сетей» ("Full Resolution Image Compression with Recurrent Neural Networks"). В статье описан инновационный метод сжатия фотографий с помощью нейросети, показан процесс её обучения и примеры её работы.
Разработчики информируют, что это первая нейросеть в мире, которая на большинстве битрейтов сжимает фотографии лучше JPEG, при помощи энтропийного кодирования или без его помощи.
Нейросеть для сжатия изображений Google сделана на базе свободной библиотеки машинного обучения TensorFlow. Для обучения использовались два набора данных: 1) готовый набор изображений 32?32 пикселя; 2) 6 млн фотографий из интернет-базы Kodak размером 1280?720 пикселей.
Каждое изображение 1280?720 из второй базы разбили на фрагменты 32?32 пикселя. Затем система выделяла 100 образцов с наименее эффективным сжатием, по сравнению с PNG. Идея в том, что это самые «сложные» для сжатия области изображения — именно на них нужно обучать нейросеть, а сжатие остальных областей будет гораздо проще. Этот «сложный» набор данных в таблице ниже представлен как «Набор данных с высокой энтропией».
Исследователи из Google испытали несколько вариантов архитектуры. Каждая из моделей включала в себя кодер и декодер на рекуррентной нейросети, модуль бинаризации и нейросеть для энтропийного кодирования. В научной работе сравнивается эффективность нескольких типов нейросетей, а также представлены новые гибридные типы нейросетей GRU и ResNet.
Для сравнения эффективности сжатия использовались стандартные метрики для алгоритмов с потерей качества — Multi-Scale Structural Similarity (MS-SSIM, представлен в 2003 году) и более современный Peak Signal to Noise Ratio — Human Visual System (PSNR-HVS, 2011 год). Метрика MS-SSIM применялась для каждого из RGB-каналов в отдельности, результаты усреднялись. В метрике PSNR-HVS изначально учтена информация о цвете.
MS-SSIM даёт оценку по шкале от 0 до 1, а PSNR-HVS измеряется в децибеллах. В обоих случаях более высокое значение означает лучшее сходство сжатого изображения и оригинала. Для ранжирования моделей использовалась суммарная оценка, вычисленная как площадь изображения под кривой соотношения степени искажения и количества данных (area under the rate-distortion curve, AUC) суммарно по всем уровням сжатия (bpp, бит на пиксель).
Все модели прошли обучение примерно в 1 000 000 шагов. Энтропийное кодирование не использовалось. Реальный показатель AUC будет гораздо выше при использовании энтропийного кодирования. Но даже без него все модели показали результат по MS-SSIM и PSNR-HVS лучше, чем JPEG.
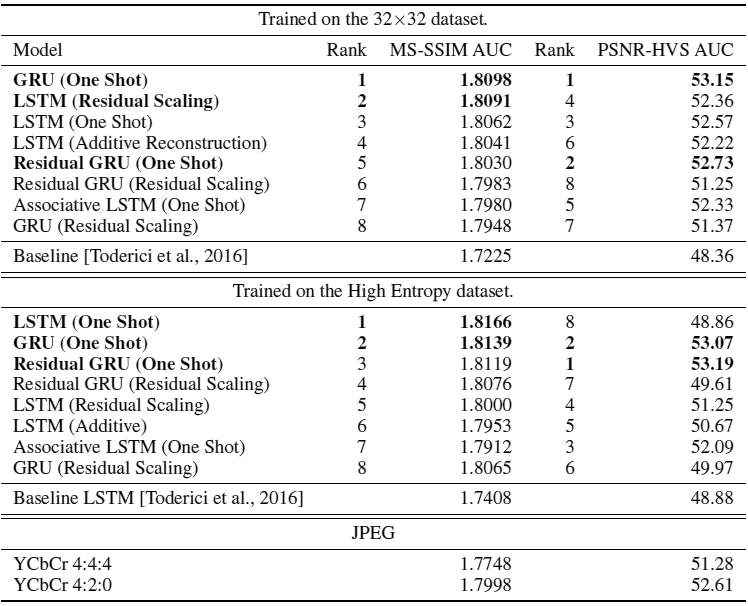
На диаграммах внизу видно, что все варианты нейросети работают более эффективно при использовании дополнительного слоя энтропийного кодирования. На относительно небольших изображениях 1280?720 выигрыш небольшой: между 5% на 2 bpp и 32% на 0,25 bpp. Преимущество станет намного более заметно только на действительно больших фотографиях. В модели Baseline LSTM экономия составила от 25% на 2 bpp до 57% на 0,25 bpp.
На первой диаграмме показана кривая соотношения степени искажения и количества данных (rate-distortion curve), по оси ординат отложены показатели метрики MS-SSIM, которые изменяются в зависимости от уровня компрессии — показателя бит на пиксель, отложенного по оси абсцисс. Штриховые линии соответствуют эффективности до применения энтропийного кодирования, сплошные линии — после применения энтропийного кодирования. Слева — две лучшие модели, обученные на наборе данных изображений 32?32 пикселя. Справа — две лучшие модели, обученные на наборе данных с высокой энтропией, то есть на реальных фотографиях, которые исследователи Google разбили на фрагменты 32?32 и выделили самые трудносжимаемые участки.
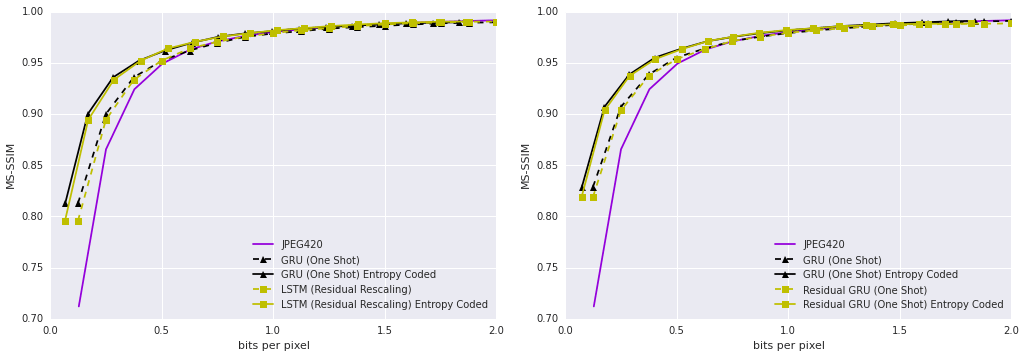
На следующих диаграммах то же самое для метрики PSNR-HVS.
Нейросеть всё ещё нуждается в доработке: некоторые результаты её работы выглядят не совсем привычно для человеческого глаза. Авторы научной работы признают, что статистика эффективности по RD-кривой не всегда соответствует субъективному восприятию на глаз: «Визуальная система человеческого зрения более чувствительна к определённым типам искажения, чем к другим», — пишут они.
Тем не менее, этот проект — важный шаг к разработке более эффективных алгоритмов, которые помогут ещё более качественно сжимать изображения. Разработчики уверены, что можно ещё больше повысить эффективность на больших изображениях, если использовать трюки, позаимствованные у видеокодеков, как это делает WebP, созданный на основе свободного видеокодека VP8. Это такие методы как повторное использование фрагментов, закодированных ранее. Кроме того, они планируют провести совместное обучение энтропийного кодировщика (BinaryRNN) и кодировщика по месту (patch-based) на больших изображениях, чтобы найти оптимальный баланс между эффективностью кодировщика по месту и прогностической мощностью энтропийного кодировщика.
Несколько примеров, как работает нейросеть Google в нынешнем состоянии, на сжатии реальных изображений. Как упоминалось выше, человеческий глаз более чувствителен к определённым типам искажений и менее чувствителен к другим. Поэтому даже картинка, получившая высокую оценку MS-SSIM и PSNR-HVS, иногда может выглядеть не так хорошо, как получившая низкую оценку. Это уже изъяны существующих метрик (или человеческого зрения).
Оригинальное изображение, разделённое на фрагменты 32?32 пикселя. Иллюстрация: Google

Фрагмент 32?32 пикселя оригинального изображения, сжатого разными методами. Иллюстрация: Google

Оригинальное изображение, разделённое на фрагменты 32?32 пикселя. Иллюстрация: Google

Фрагмент 32?32 пикселя оригинального изображения, сжатого разными методами. Иллюстрация: Google
TensorFlow — высокомасштабируемая система машинного обучения, способная работать как на простом смартфоне, так и на тысячах узлов в центрах обработки данных. Google использует TensorFlow для всего спектра наших задач, от распознавания речи и перевода текстов Google Translate до автоответчика в Inbox и поиска в Google Photos. Эта библиотека «быстрее, умнее и гибче, чем наша старая система, так что её намного проще приспособить к новым продуктам и исследованиям», говорила компания Google в ноябре 2015 года, когда выложила библиотеку TensorFlow во всеобщее пользование под свободной лицензией Apache 2.0.
Комментарии (20)

force
25.08.2016 13:31+2Хм… а почему сравнивали JPEG, а не какой-нить JPEG2000 или ещё что-нить из новенького? Тот же JPEG2000 даёт гораздо лучшее изображение, а артефакты гораздо приятнее для глаза.

mychaelo
25.08.2016 17:42+2Как ни забавно, наилучших результатов в сжатии картинок добиваются даже не wavelet-кодеки типа JP2K, а натравленный на одиночный кадр H265.

pda0
25.08.2016 13:59Может целесообразнее использовать нейронные сети для ускорения фрактального сжатия? Там основная проблема в поиске похожих блоков без учёта афинных преобразований. Вроде нейронные сети как раз сильны в поиске шаблонов?

RomanArzumanyan
25.08.2016 14:27Из занудства: может, стоит всё-таки писать RD-кривая вместо «скорость-искажение»? Скорости там вообще ни в каком виде нет.

rfvnhy
25.08.2016 19:35В начале 2000хх (примерно 1999-2003) натыкался на программку фрактального сжатия картинок.
Огромнейший минус был один — без нее открыть фото потом было невозможно.
Помнится 400кб картинку без особых потерь сжимали до как бы не 10кб, на экране разницы особо заметно не было.
Ну и второй — «разжимала» она ее потом до 4Мб что ли… (для jpg)
Иначе были огромные потери качества.
Т.е. сжимала нормально, но обратно… Уже тогда я понял что держать коллекцию картинок в формате непонятного ПО смысла нет, поэтому наигравшись забросил.




{kind=link}
vangelfeld
25.08.2016 20:02Шутка про Крысолов.
Всё-таки за прототип Холли нужно было взять Гугл, а не Мелкомягких

RolexStrider
25.08.2016 21:23+3Некогда (еще в конце 90-х, примерно одновременно с рождением mp3) подобный трюк попытались проделать японцы (то ли Yamaha, то ли еще круче кто-то). Формат VQF придумали. А суть, как я понял, была такая: «А давайте проанализируем много-много музыки, разобъем на небольшие фреймы, и из самых часто встречающихся сделаем что-то типа словаря. Ну и писать в файл будем ссылку на этот „словарный сэмпл“, плюс сжатую (с потерями) дельту от него. „Словарь“ вышел небольшой — около 2 Мб, ЕМНИП. Звучало недурно, и что характерно, на тот момент декодирование было менее ресурсоемко чем для mp3. Но… Не взлетело. А мне вот запомнилось. Красота идеи. И да, плеер еще такой был, который в это умел. Я это к чему: история — она же по спирали, может у Google получится.
kJofol GUI - девяностые, на минуточку!
BelerafonL
Да, сразу видна работа нейросети. Сложный объект в виде номера комнаты размазался и замылился, как нечто инородное и нетипичное для фотографий. А косые линии под разными углами передаются отлично. Возможно, в библиотеку обучения нужно добавить побольше текстов, чтобы нейросеть лучше узнавала их не пыталась смазывать.
Revertis
Поддерживаю!
JPEG сжал нормально, номер оказался читабельным, а нейросеть смылила всё, даже непонятно, что это номер.
Cool-Z
А ведь это уже не та же самая картинка с огрехами компрессии, а другая, просто очень похожая. А вообще, конечно, очень круто.
Mad__Max
Где же это он читаемый у JPEG? Разве что на максимальном битрейте (2 бита на пиксель — последняя строчка) но на нем он и у нейросети тоже такой же «условно читаемыей», по крайней мере у первых 2х вариантов (без энтропии).
Revertis
Не знаю, мой парсер находит там цифры, может когнитивные способности поднатасканы чуть более ваших, не знаю…
Mad__Max
Издеваетесь что-ли? Вот тут вот видите цифры не «подглядывая» в оригинал?

Если и ведите, то разве что «видите» в кавычках — их мозг по памяти дорисовывает. Любит он такие штуки выкидывать и часто «видишь», то чего глаза на самом деле не видят.
Чтобы от таких «глюков» избавиться — нужно слепой тест проводить: показывать картинку людям не видевшим оригинала и спрашивать, что они там видят.
Victor_koly
Как и JPEG, это сжатие не очень подходит для мелких особенностей. Особенно странно выглядела бы попытка взять цифры толщиной 1 пиксель на фоне.
З.Ы. Нашел свои образцы ч/б картинок — с цифрами все нормально.