
Всякую ли поисковую функцию выполняет Яндекс или Google? К сожалению, пока нет. Существуют такие типы поиска, при которых никакая выдача не будет считаться правильной. И дело даже не в релевантности, а в том, что нужен другой поиск — помимо привычного нам всем. Под катом вы найдете расшифровку лекции о разведочном поиске, а также большинство слайдов.
Друзья, мы все здесь собрались для того, чтобы сделать мир лучше, а людей умнее. Что мешает людям становиться умнее? Я бы сказал, что психологические, технологические барьеры между людьми и знанием. Мой доклад про то, как современные информационные технологии, наверное, в ближайшем будущем позволят рушить эти барьеры, которые всё ещё остаются.
Здесь я пытаюсь ввести новую моду — чтобы, когда презентация потом в интернете размещается, впервые ее открывший человек понял, о чем она.
Идея такая: почему я декларирую, что мы хотим сделать людей умнее? Тут наверняка есть скептики, которые скажут: «Ха-ха-ха, человека не изменишь». Но я скептикам напомню, что когда-то люди не умели ни читать, ни писать, а знания распространялись исключительно устным способом, обрастали легендами и мифами, забывались, модифицировались до неузнаваемости и т. д. Но потом люди придумали, что нужно писать книги, печатать книги. Это произошло, когда европейские священники поняли: когда они читают проповеди, из года в год одно и то же, народ все равно не запоминает, не понимает, воспринимает как-то неправильно. И что нужно всех научить грамоте.
Дальше было еще несколько информационных революций. В конце концов появился интернет, поисковые системы, и знание стало ближе к людям. Но кажется, что все равно чего-то не хватает. Все равно я от моих коллег-ученых, людей знания, время от времени слышу жалобу, что я начал вести исследование, прочитал кучу литературы, а через полгода, три, пять лет вдруг обнаружил: всё, что я сделал, уже опубликовано 10 лет назад. Как же так? Ты годами занимался своей работой и не сумел найти то, что кто-то сделал до тебя. Как это возможно при современных поисковых возможностях? Оказывается, все-таки этот барьер между человеком и знаниями существует. Сейчас я сказал про технологический барьер. Если чисто про психологический — троечники никогда не любили отличников, и это понятно, и с этим мы сейчас с вами не поборемся. Но рушить технологические барьеры очень хочется.
Поэтому возникают новые парадигмы информационного поиска, о которых сегодня хотелось бы с вами поговорить.

Начнем мы с того, что примерно 10 лет назад стали появляться, активно обсуждаться новые парадигмы концепции информационного поиска.
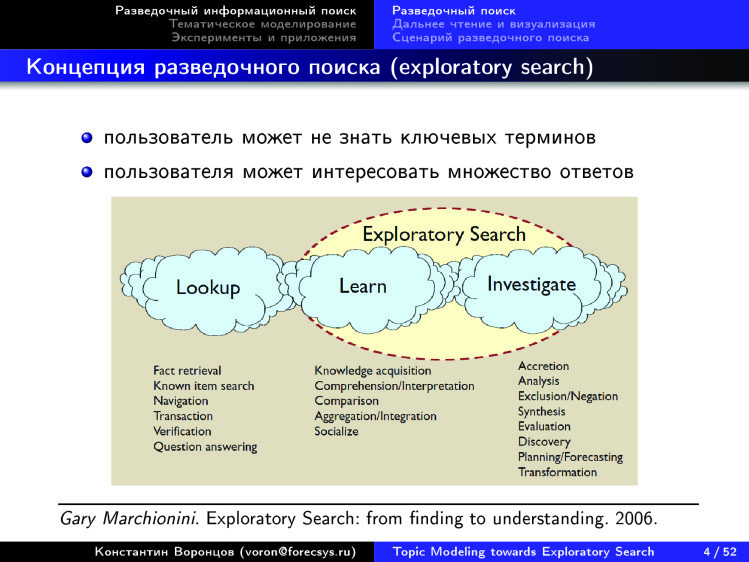
В частности такое выражение — Exploratory Search. Как перевести это на русский? Я перевожу это как «разведочный поиск», некоторые переводят как «исследовательский поиск». Если посмотреть на эту диаграмму, то слева поисковые потребности, к которым мы привыкли. И современные поисковые системы, которые хорошо ищут по ключевым словам, решают задачу найти ближайшую аптеку, где есть лекарство и где оно самое дешевое. Или найти что-то конкретное, и вы знаете, как это обозначить словами. Но если вы хотите разобраться в новой для вас предметной области — у вас будут проблемы. Я, специалист по анализу данных, недавно стал разбираться в электрокардиографии. Я совершенно не медик: ни в кардиографии, ни в электрокардиографии ничего не смыслю. Мне нужно быстро понять структуру этой предметной области. Узнать, что именно читать в первую очередь, чтобы выяснить, где она находится на стыке с тем, что я хорошо знаю. С тем, где я профессионал.
И такие информационные потребности возникают всё чаще и чаще у людей всё более широкого спектра профессий. Мы уже не говорим только о студентах, преподавателях, ученых, исследователях. Это маркетологи, врачи, юристы, журналисты — кто угодно. Всё больше людей начинают что-то самостоятельно искать в интернете, пополнять свои знания. Вопрос — как делать это максимально эффективно?
Мы начинаем использовать поисковые системы для самообразования — чтобы что-то исследовать, узнавать что-то новое. И тут мы понимаем, что нам их не хватает, потому что они недостаточно эффективно покрывают эти потребности.
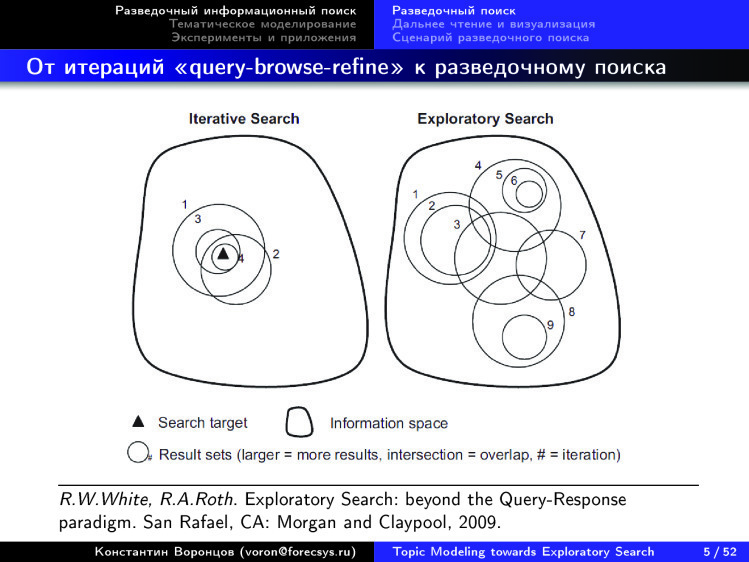
Проблема состоит в том, что когда мы ищем по ключевым словам, мы должны достаточно точно знать, что мы ищем. И мы должны предполагать, что существует правильный ответ. Эти две предпосылки — ровно не такие, когда мы в новой для нас предметной области. С одной стороны, мы не очень хорошо понимаем, что именно мы ищем. Мы сами хотим разобраться. Мы еще не владеем терминологией, единственное, что мы можем — задавать в поисковой строке какие-то выражения, слова. И результаты поиска всегда как-то привязаны к указанным словам. Когда мы узнаем новые слова, то понимаем: на самом деле надо было искать именно это, а не то, что мы искали до сих пор. Но нужно много десятков таких прозрений в итерационном процессе, чтобы более-менее начать ориентироваться. И все равно: вы можете заниматься этим годами, но чего-то важного не найти.
Вопрос: как предоставить ответ на поисковый запрос в таком виде, чтобы человек сразу увидел перед собой дорожную карту предметной области, чтобы он понял, из чего она состоит и куда ему дальше следовать внутри.
Так что существуют различия между тем, чего бы мы хотели — а мы бы хотели картину предметной области, — и привычным итеративным поиском. Мы привыкли query-browse-refine, то есть дал запрос, посмотрел ответ, улучшил запрос и так итеративно много раз.
Вот примерно десятилетней или даже большей давности парадигмы, которые возникают. Чем information seeking отличается от information retrieval? Последнее — область информационного поиска, то, чем занимается Яндекс. А information seeking — это немножко смещенный акцент, это не наука про весь информационный поиск, а наука про то, как пользователи себя ведут, когда что-то ищут, как устроен этот итерационный разведочный процесс, когда пользователь в процессе поиска узнает, что же ему на самом деле надо.
Есть такая мантра из области этого information seeking — что сначала вы должны получить общую картину, потом воспользоваться средствами масштабирования и фильтрации, углубиться внутрь, увидеть картину более широко, что-то из нее выбрать и потом — углубиться до самых деталей.
Почему я выделил кусочек этой мантры красным? Очень часто, когда рассказывают о каких-то новых способах визуализации больших объемов информации, показывают большую картинку, граф. И у многих уже идиосинкразия на такие картинки. Их слишком часто и много показывают, но не объясняют, что с ними делать дальше.
Идеологи information seeking это объяснили. Не надо забывать, что есть не только первый этап, когда вы overview дали. Также дайте пользователю способ сделать зум, углубиться, отфильтровать и добраться до самого контента. Когда эта технология целиком реализована и она интерактивная, то она начинает работать. А если вы ограничились первым этапом — тогда, конечно, кроме красивой картинки вы ничего не видите.
Также возникло понятие close reading. Это то, к чему мы привыкли, — линейное чтение текста. Мы чего-то конспектируем, подчеркиваем, выделяем фломастерами и т. д. Пристальное чтение.
Вот другая концепция, которую предложил 10 лет назад Франко Моретти, итальянский социолог литературы. Он задался вопросом, почему в мировой литературе 99,9% никем не читается, и как понять, о чем вся эта литература. Если он такие вопросы задает по отношению к художественной литературе, то тем более они справедливы для научной литературы, для знания. Каким образом можно всё охватить, сделать overview?

Есть много разных попыток представить большие объемы научного знания в виде каких-то карт. Конечно, предполагается, что потом будут возможности масштабирования.
Вот например, карты медицинских знаний. Эта карта мне не очень нравится — здесь явно есть некая географическая метафора. Есть нечто вроде стран, которые как-то называются, а другим шрифтом и другим цветом что-то вроде городов подписано. Можно идти дальше, придумывать смысл для дорог, рек и т. д. Но кажется, что все это перегружено. Вы смотрите на это и понимаете, что вам неудобно. Почему? Давайте будем пробовать осознавать.

Вот еще один способ визуализации. Мне он нравится больше, он более понятен. Это наша с вами область — data science, data mining, какие-то слова здесь появились, которые уже хорошо видны, в отличие от предыдущего слайда.
Мне здесь кое-что не нравится. Когда крупная клеточка разбивается на более мелкие, это иерархическая структура знания — и очень хорошо, что она появилась и что вы можете так углубляться в клеточки. Они указанным фрактальным образом будут дробиться на всё более мелкие, пока вы где-то не дойдете до текста. Это как раз здорово, это хорошая идея. Но мне не очень нравится принцип, что такое дробление крупных на мелкие чисто визуально, графически, строится от того, что более крупная клеточка должна быть в середине, а более мелкие — вокруг нее. Исчезает двумерная топология. Мы представляем некую проекцию, некую карту на плоскости, на экране, поэтому близость там должна быть как-то семантически нагружена. А здесь получается, что мы только представили иерархию.

Вот еще один пример, уже поближе. И таких примеров в интернете можно найти много. Много кто пытается строить карты всей науки по самым разным коллекциям. Есть просто коллекции статей, есть коллекции аннотаций, есть коллекции, где учитываются ссылки между статьями, то есть информация цитирования. Есть коллекции, в которых имеется информация о том, как пользователи скачивали и читали те или иные статьи. Вообще, эти типы информации можно использовать, чтобы строить такие карты науки.
Если присмотреться к этой карте, сразу бросается в глаза, что всё почему-то расположилось по кругу. Вот экономика, вот computer science, математика, сельское хозяйство, физика, химия, медицина, биология, фармакология, neuroscience, психология — дальше всё как-то к гуманитарному циклу свелось. Подметили, есть цикл: точные, естественные, гуманитарные. Цикл замкнулся. И топология такой картины знания не двумерная, как кажется здесь на картинке. Речь идет об окружности, одномерной структуре. Да, она замкнута в кольцо, но это интересное наблюдение.

А вот очень похожая картинка. Она сделана совершенно другими людьми и средствами, на совершенно других коллекциях, но мы снова видим те же области: computer science, математику, инженерию, физику, химию, геологию, биологию, биотехнологию, молекулярную биологию, brain, медицину, здравоохранение, гуманитарку, социалку — и снова они замыкаются на компьютерные методы исследования. Опять окружность возникает.
Если вы посмотрите, в интернете много таких картинок. Больше половины из них почему-то представляют из себя такие окружности.
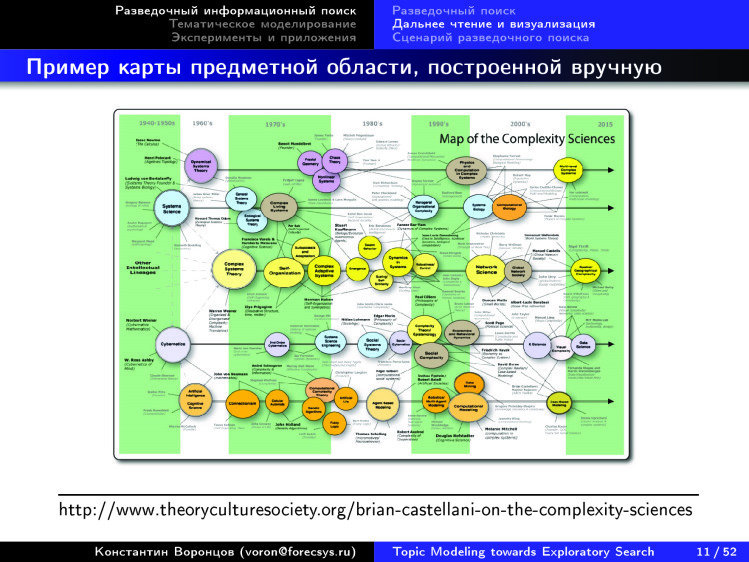
Вот другое представление — но, к сожалению, не автоматически построенное, а вручную. Есть такой специалист по теории сложности, Брайан Кастеллани, который из года в год обновляет эту карту теории в науке о сложности. Он выделяет основные направления и раскладывает их по годам. В отличие от предыдущих карт, появилась двумерность. Есть горизонтальная ось, которая соответствует времени, и вертикальная ось, соответствующая темам. Можно разглядеть эти темы, примерно пять линеек, показывающих, как это возникает в computer science и кибернетике. Где-то в конце это доходит до анализа данных, появились новые кружочки.
Выделенные темы идут горизонтально, и можно проследить, как тема развивалась. А стрелочками показано, каковы основные работы и фамилии ученых, которые внесли основной вклад. Человек трудился, рисовал эту картинку. Возникает вопрос: а можно ли эти картинки рисовать по любой области науки чисто автоматически? Взяли мы все эти десятки миллионов научных публикаций, выделили каким-то образом, дали запрос. Например, теория сложности, по которой 10 опорных работ, — это наш поисковый запрос. И мы хотим на выходе такую картинку. Тогда людям будет проще разбираться с новыми для них областями знаний. Примерно к этому мы хотели бы прийти.
Кстати, картинки, которые, например, раскладывают во времени новостные потоки, тоже очень красиво научились строить. Технологии визуализации готовы, много наработок есть.
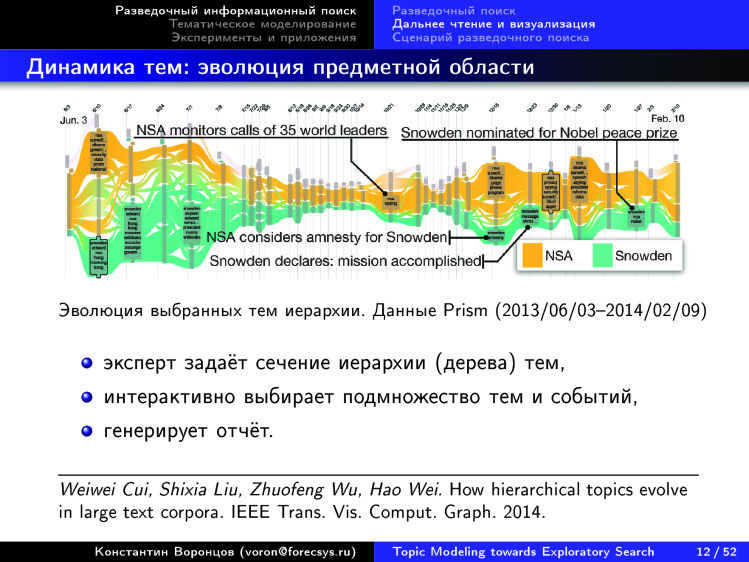
Например, возмем проект Rose River. Вот как они визуализируют поток новостей, связанный со Сноуденом. 2013-2014 годы. Что они делают для того, чтобы строить такие картинки по любому подмножеству новостного потока? сначала задать некое сечение иерархии тем, методов, автоматически по коллекции новостей построить некую иерархию, показать другому эксперту. Тот говорит: здесь, пожалуйста, сделайте отсечение на верхнем уровне, эти темы меня не очень сильно интересуют. А здесь, про Сноудена, — пожалуйста, поподробнее, здесь нужно охватить более низкий уровень иерархии.
Эксперт задал такой фильтр, а дальше ему система показывает автоматически такую картинку, показывает, как темы развивались во времени, как они пересекались, сливались, возникали, затухали. Все отображается в виде красивой картины, где темы текут рекой. Дальше эту картину можно интерактивно менять, по новой генерировать и т. д. В принципе, это именно то, что называется distant reading. Мы хотим разобраться в том, как структурно устроена эта область. В данном случае есть новостной поток, касающийся конкретных тем, и есть возможность углубиться, потому что можно подправить каждую тему, войти в подтему и дойти до конкретных новостей, прочитать их. Указанная система примерно такая, но он тоже устроена следующим образом: горизонтальная ось — время, вертикальная — какие-то темы, выбранные экспертом.
В достаточно удобных средствах визуализации мы снова видим, что две оси интерпретируемы, в отличие от карт, которые были показаны в самом начале.
Средств визуализации больших текстовых коллекций придумано уже очень много. Год назад, когда я выступал с докладом об этом на Data Fest, их было 170. Теперь я посмотрел — уже 330. За год их число удвоилось. Люди вкладывают очень много усилий, чтобы придумать удобные способы визуализации больших объемов текстов. Этим можно пользоваться.

Давайте пофантазируем о том, как же все-таки должен быть устроен разведочный поиск. Чего мы хотим? Мы не можем задавать запросы в виде коротких словосочетаний. Мы не знаем, что ищем. А от чего же мы отталкиваемся тогда? Если подумать, то, как правило, у нас есть на руках какой-то большой текст, какая-то коллекция текста. Может, мы даже сами в нем еще не разобрались. Есть некая статья. Нам ее только что скинул коллега, мы ни в чем еще не разобрались, не знаем, как эта статья позиционируется внутри нужной нам области науки. Сначала мы это хотим увидеть. Поэтому запросом является текст сколь угодно длинный — большая коллекция может быть. И мы хотим понять, к каким темам относится запрос, что по ним известно еще, помимо нашего документа. Хотим понять, какова тематическая структура этой предметной области, какие области являются для нее смежными и что вообще читать в первую очередь. Это спектр запросов, поисковых потребностей пользователя, который занимается самообразованием, пытается расширить свои знания в той или иной области.
Хотелось бы, чтобы такая возможность была в любом приложении, где есть некий текст. Хотелось бы понять, на какие темы этот текст, и использовать его как запрос — чтобы тут же получить картину с визуализацией данной предметной области. Такая вот мечта о разведочном поиске. Мы даже не идем ни в какой Google или Яндекс набивать что-то в поисковую строку. Нам даже этого не надо делать. Такой способ поиска всегда должен быть под рукой, везде, где есть сколь угодно длинный текст. Такая вот мечта.
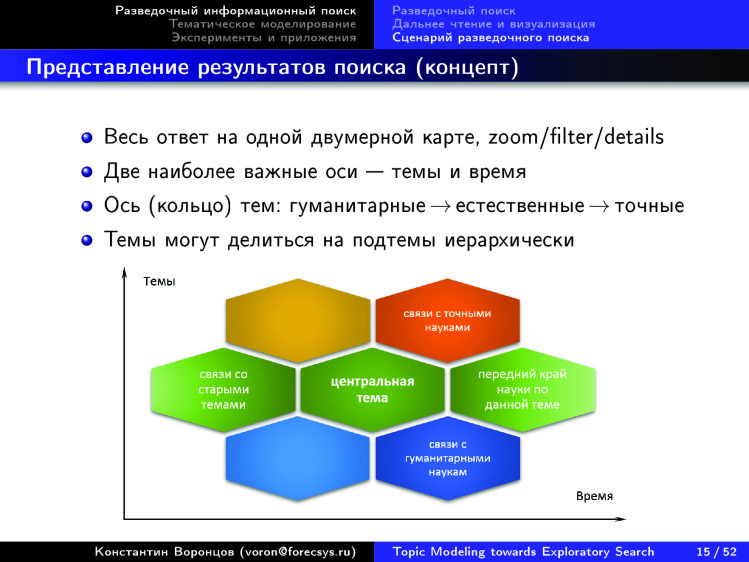
Здесь представлен некий концепт. Понятно, что многие в мире идут к этой мечте разными путями. Кто-то, как я и моя научная группа, — с точки зрения математики, кто-то с точки зрения технологий. Как бы мы хотели, чтобы это было устроено? Мы уже поняли, что очень здорово визуализировать информацию в двух осях: время-тематика. Очень здорово, если есть возможность тематику дробить на подтемы, иметь достаточно большое дерево. Причем желательно, чтобы оно строилось автоматически — чтобы там не было никаких УДК, состоящих из 80 тыс. пунктов, придуманных сообществом из десятков тысяч экспертов на протяжении более ста лет. Эта человечески поддерживаемая структура постоянно устаревает. Такого нам не надо. Нам надо с помощью информационных технологий сделать так, чтобы подобные структуры строились на лету, автоматически, по тому контенту, который есть в интернете.
Еще мы подметили замечательную особенность: есть цикл по окружности — гуманитарные, естественные, точные науки. Мы хотим это кольцо где-то как-то разорвать, отобразить по вертикальной оси и работать с таким представлением, когда мы выделили некую центральную тему, справа от которой мы можем понять, что по ней последнее, слева — что было до, а верх и низ — связи со смежными областями знаний.
Как нам идти к этой мечте?

На самом деле, уже много чего готово. Технологическая цепочка, которая здесь мыслится, состоит из многих известных и готовых технологий, которые отработаны в современных поисковых системах. Есть Яндекс, Google, много чего еще. Умеем делать интернет-краулинг, фильтрацию контента — это важно, потому что нам нужна система поиска по знанию, а не коммерческая информация, которой тьма. Не нужны котики, лайки и т. д. Нам нужно выделить знание. Такие технологии тоже есть.
Тематическое моделирование. Как по коллекции научных документов построить множество тем? Это важный вопрос.
Как искать? Идея проста до гениальности. Мы умеем искать по словам документы, это называется инвертированным индексом. А если у нас поиск по смыслу, по тематике, то что мы должны сделать? Мы должны понять, данный документ запроса — он на какие темы? Документ может быть безумно длинным, но число тем в нем может быть не очень большим. Если мы умеем представлять любой документ в виде набора тем — может быть, с весами, определяющими, насколько каждая тема в нем представлена, — то дальше возникает ровно та же ситуация, которая была у нас раньше с обычным поиском по словам. Мы по словам искали документы, этим занимался инвертированный индекс. А теперь мы по темам ищем документы. У нас как любой запрос, так и любой документ теперь представлены не словами, а темами. А технология остается — опять-таки, инвертированный индекс.
Дальше нужно уметь решать задачи ранжирования, визуализировать, потому что есть 330 уже готовых средств визуализации. Дальше — уметь делать персонализацию. Почему? С чем связана эта идея? Как устроен поисковый запрос человека, который, например, хочет иметь под рукой некую картину тех областей знаний, с которыми он сталкивается, будь то ученый, строитель, журналист, маркетолог — неважно. Он просто копит какие-то отрывочки, какие-то текстики, они где-то у него сложены, в каких-то папочках. Эта папочка как раз и является поисковым запросом. Более того, постоянно действующим. Более того, персонализированным. Потому что он или его рабочая группа этот запрос разделяет. Для них постоянно можно организовать поток пополнения информации из интернета по данной тематике. Это, фактически, не что иное, как персонализация, рекомендательная система.
Почему я выделил красным тематическое моделирование? Я о нем хочу поговорить дальше. Это математическая основа данной технологии, ключевое звено.
А монетизация — самая основная проблема. Почему такого сервиса до сих пор нет, если все технологии готовы? Потому что никто еще не придумал, как его монетизировать. Умники, интеллектуальная элита общества, которая потенциально будет этим средством пользоваться, — ну не кликает она на рекламу, не нужна она таким людям. Или надо придумать, какую рекламу им давать, чтобы они таки на нее кликали. Это тоже некий челлендж, который пока препятствует реализации этих замечательных идей.

Итак, про тематическое моделирование. Интуитивно мы воспринимаем тему как некую специальную терминологию предметной области, как набор терминов, которые совместно встречаются в некотором достаточно узком подмножестве документов. Это можно формализовать на языке частотности слов или условных вероятностей. Для нас тема — распределение вероятностей над словарем слов. В математической теме одни слова более частые, а в биологической — другие. Понятно, что тема — такое условное распределение.
Когда мы так определили темы, которых намного меньше, чем слов, мы можем восстанавливать тематические профили документов — условное распределение тем в них. А тематическая модель должна по исходной коллекции, то есть по распределению частот слов в документах восстанавливать эти красные распределения.

В основе здесь лежит представление о вероятностном процессе порождения слов в коллекции. Процесс устроен так: мы берем распределение тем в документе, генерируем из него тему для данной позиции слова, а потом, зная тему, генерируем распределение конкретного слова, записываем туда. Вот модель мешка слов. Она предполагает, что нам для понимания тематики документа не важен порядок слов в нем. Кстати, от этого драконовского предположения легко отказаться. В тематическом моделировании есть специальные методы, которые идут дальше и отказываются от него, но тем не менее, данная модель в целом остается верной.
В такой модели нам дано то, что слева, а справа нужно искать распределения.

В этом состоит анализ данных. На входе у нас коллекция документов, которые состоят из слов заданного словаря. Нам известны частоты слов, а хочется найти параметр данной вероятностной модели. Если присмотреться, перед нами не что иное, как матричное разложение. Вот предложение нашей исходной матрицы, «слова — документы», в виде произведения двух матриц: «слова на темы» и «темы на документы».
Но беда в том, что данное распределение не однозначно определено. Те, кто проходил линейную алгебру, знают, что сюда можно встроить линейное преобразование и обратное к нему и получить другое решение, которое ничем не будет отличаться по аппроксимационной способности этих исходных данных распределения слов в документах.
Нужно придумывать разумные дополнительные ограничения на эти матрицы. Матрица ? — распределение слов в темах, ? — распределение тем в документах.

Тут много чего напридумано, и главное — у нас есть много требований к этим матрицам. Мы знаем, что чтобы построить нашу мечту, наш разведочный поиск, мы должны по оси Х изображать, как темы развиваются во времени, а по оси Y изображать иерархию тем. Нам их надо восстанавливать. На все это будут смотреть люди, поэтому нужно, чтобы темы казались интерпретируемыми сами собой.
Для улучшения интерпретируемости очень помогает уметь объединять слова в словосочетания — термины предметных областей. Если вы видите термин «машина опорных векторов», значит, скорее всего, данный текст про машинное обучение. Если вы рассматриваете указнные три слова отдельно, то такой текст может быть про что угодно из инженерных областей. Много всяких разных требований. Мультиязычность, например: мы хотим задавать запрос на одном языке, а ответ получать на другом. Кроме того, мы хотим, чтобы эта технология быстро работала, чтобы она была линейно масштабируема по длине коллекции, чтобы мы ее могли на кластерах распараллеливать и т. д.

Тематическое моделирование — область, которая развивается примерно с 1999 года, когда Томас Хоффман придумал модель вероятностного латентного семантического анализа. Затем модель Дэвида Блея, латентное размещение Дирихле, поместила эту задачу в контекст байесовского обучения. И дальше тематическое моделирование развивалось практически на 100% внутри этого контекста. Я какие-то основные вехи здесь отметил. Вообще тематических моделей напридумано несколько сотен, а может, даже тысяч за эти чуть более чем 15 лет. На данном слайде можно надолго задержаться, но я не буду.

Байесовское обучение. Можно пытаться объяснять, почему все сообщество тематического моделирования плотно село именно на эту парадигму машинного обучения, но она порождает некие проблемы. В первую очередь, в основе байесовского вывода лежит схема, что мы задаем априорное распределение на наши параметры модели, на наши матрицы ? и ?, добавляем туда данные и получаем апостериорные распределения. Этот переход нетривиален — приходится выполнять нетривиальную математику и каждое ограничение на матрицах ? и ?, к сожалению, требует уникальной математической работы, что несколько препятствует созданию из этого универсальной гибкой технологии.
Трудно комбинировать модели. Если есть хорошая модель про иерархию, про учет динамики времени, про учет N-грамм, еще про что-то, а мы хотим их объединить в байесовском подходе, то у нас будут большие проблемы. Получатся очень громоздкие выкладки — трудно сделать из этого какой-то софт, который любые модели позволял бы подстегивать вместе. Еще надо как-то понимать модели. Для понимания придумали пользоваться плоской нотацией, графическими моделями.

А мы придумали способ, как избежать этих усложнений, как очень легко можно комбинировать разные модели, и, главное — как строить модели с требуемыми свойствами.

Подход вот какой. Мы каждую из сотен моделей, известных в литературе, умеем представлять в виде некоторого регуляризатора, некоторого дополнительного функционала к основной задаче. А основная задача — она на максимум правдоподобия.
Если мы хотим от нашей модели чего-то еще, мы можем представить наши дополнительные пожелания в виде какой-то добавки к критерию. Кстати, это очень хорошо вписывается в байесовский подход — речь идет про логарифм априорных распределений на параметры ? и ?.
Но если дальше мы хотим скомбинировать несколько таких априорных распределений, то в байесовском подходе у нас возникают технические сложности. А вот если отказаться от байесовской интерпретации, воспринимать это как постановку оптимизационной задачи и тупо в лоб известными математическими техниками попытаться ее решить, то мы приходим к системе уравнений, которая легко решается методом простой итерации. Она легко распараллеливается и вообще выглядит приятно. Главное — она обобщает огромное количество уже известных моделей, да еще и позволяет их друг с другом стыковать путем такого простого суммирования критериев, которые мы вынимаем из отдельных моделей и суммируем с весами.

Правда, возникает вопрос, как находить эти веса, но об этом чуть позже.
Мы имеем дело с документами как с некими контейнерами, содержащими не только слова. Они еще много чего могут содержать: метки авторов, времени, ссылок на другие документы, информацию о том, что какой-то пользователь зашел в документ, скачал его, лайкнул, дизлайкнул и т. д. Все это тоже хочется как-то учитывать. И оказывается, учитывается оно очень легко.

Если документ содержит в себе не только слова, но и элементы каких-то других модальностей, давайте для каждой модальности выпишем правдоподобие. Затем возьмем взвешенную сумму этих правдоподобий, будем оптимизировать — оказывается, это тоже на наш итерационный процесс не сильно влияет, не сильно его усложняет. По-прежнему можно выписать систему уравнений и решать ее. А главное, она очень универсальна, она покрывает огромное количество уже известных моделей и их комбинации.

Таким образом можно сделать технологию. Мы ее сделали — уже три года существует проект с открытым кодом BigARTM, который реализует довольно эффективное распараллеливание этого регуляризованного ЕМ-алгоритма на ядрах. На кластерах — пока нет. До сих пор не было под рукой настолько большой коллекции, чтобы ее нужно было распараллеливать на кластерах. Как только появится — сделаем.
К проекту можно подсоединяться, использовать: ограничений на коммерческое использование нет. Мы охотно консультируем, у нас уже есть несколько десятков коллег, которые работают с этим софтом.

Здесь я поясняю, чем этот софт отличается от байесовского подхода. В байесовском подходе вы вынуждены математическую модель индивидуально строить под каждую совокупность требований, которые к вам поступили из прикладной задачи. Получается, что вам в команде нужен математик, который сделает формализацию, сделает байесовский вывод, несколько дней потратит на то, чтобы написать модель, потом сделает исследовательскую реализацию в MATLAB, ее прогонит, и все это — работа, индивидуальная для каждого приложения.
Наш софт — он унифицирует эти промежуточные шаги и делает промышленный код на С++, который работает быстро, за три года мы его вылизали достаточно неплохо. Другими словами, неформализуемым остается анализ требований и внедрение, а это именно то, что и должно быть. Надо думать о прикладной задаче, а не как построить байесовскую модель. Не надо её строить, всё гораздо проще можно сделать.

Есть интерфейс в Python, есть масса готовых примеров того, как решаются задачи тематизации для разных коллекций.
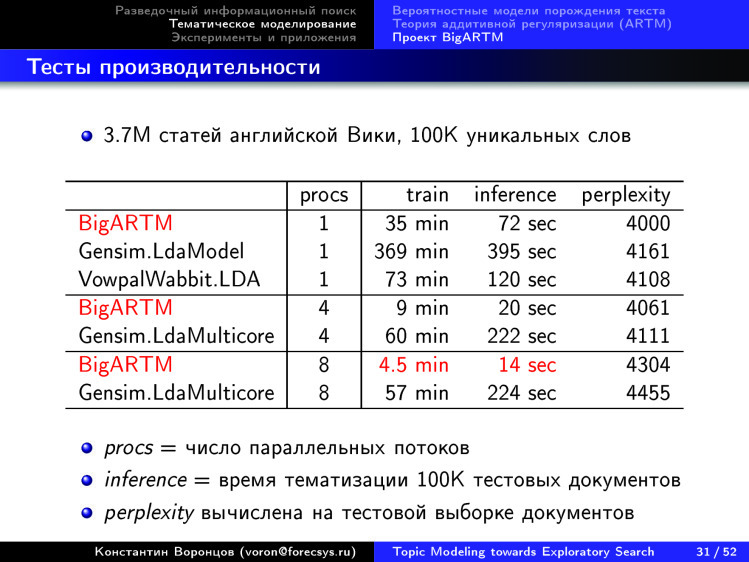
Тут мы показываем, что мы впереди ближайших конкурентов по скорости. Коллекция из 3,7 млн документов из Википедии у нас за 4,5 минуты оттематизировалась. После этого за 14 секунд еще 10 тыс. документов протематизировались — и перед нами довольно устаревшие данные, сейчас это еще в несколько раз быстрее.
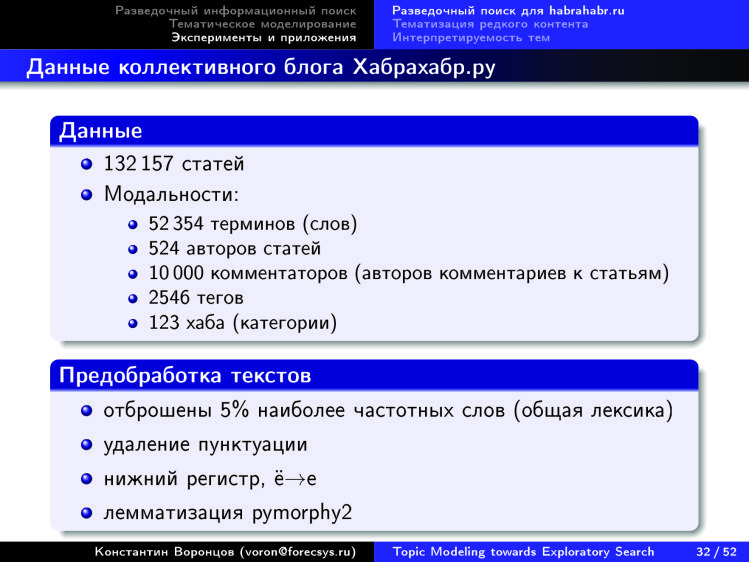
Хотел бы рассказать об одном эксперименте, который мы ставили, чтобы подойти к этой задаче — задаче о том, как построить тематический разведочный поиск.
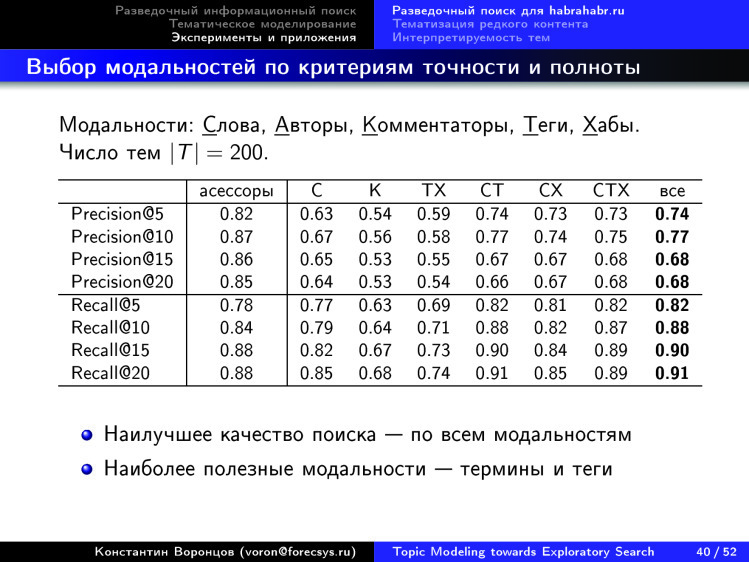
Мы взяли коллекцию Хабрахабра — эту работу делала моя студентка Настя Янина, она работает в Яндексе. Коллекция тоже была мультимодальной, в ней были не только слова, а еще информация об авторах статей, людях, которые комментируют, теги, хабы и т. д.
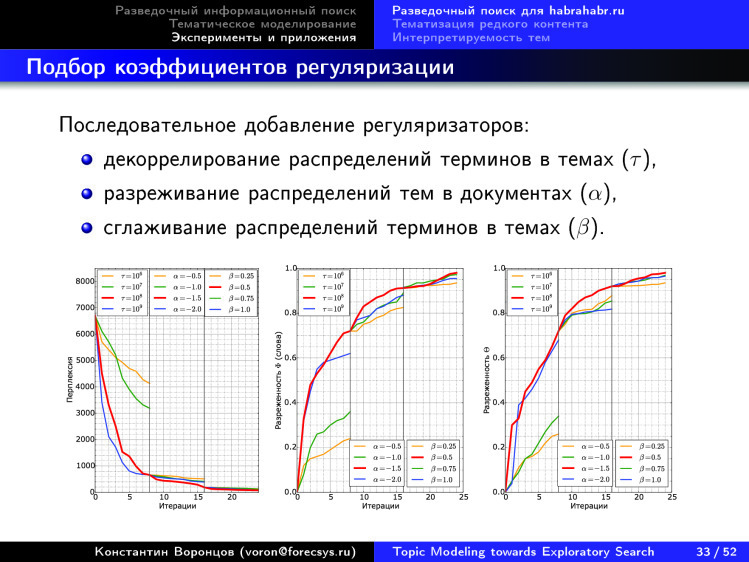
Здесь показана некая универсальная технология того, как подбирать те самые коэффициенты регуляризации в регуляризаторах. Поэтапно для каждого регуляризатора подбирается коэффициент, и мы по совокупности критериев видим, что некие показатели улучшаются.

Дальше мы делаем тематический поиск, вводим косинусную меру близости между тематическими векторами документа и запроса и по этой мере близости ранжируем документы — выдаем первые топ-k документов.

Дальше возникает вопрос, как измерить качество этого поиска.
Мы придумали такую методологию, при которой мы используем асессоров, придумали такие запросы. Сейчас, в первом эксперименте, их было 25 вручную составленных, модель такая: начальник информационной службы дает своему подчиненному задание разобраться за один час в той или иной теме по сайту, на Хабре. И человек сначала должен указанную работу сделать руками. Как правило, на эту тему уходит от получаса до часа у разных людей.
Потом этому же асессору предъявляется результат тематического поиска, и его просят отметить, какие были из автоматически найденных документов релевантны и какие нет.

Вот пример одного из запросов. Как устроен запрос? Это примерно страница текста А4. Еще есть комментарии для асессоров — с критериями релевантности и нерелевантности.

Вот примеры заголовков запросов, которые мы использовали. Понятно, что тут что-то в тематике Хабра. При этом ни один запрос не может быть просто выполнен обычной поисковой системой. Не хватает вам набрать просто [3D принтеры] и узнать что-то о 3D принтерах вменяемое — вы получите огромное количество выдач.

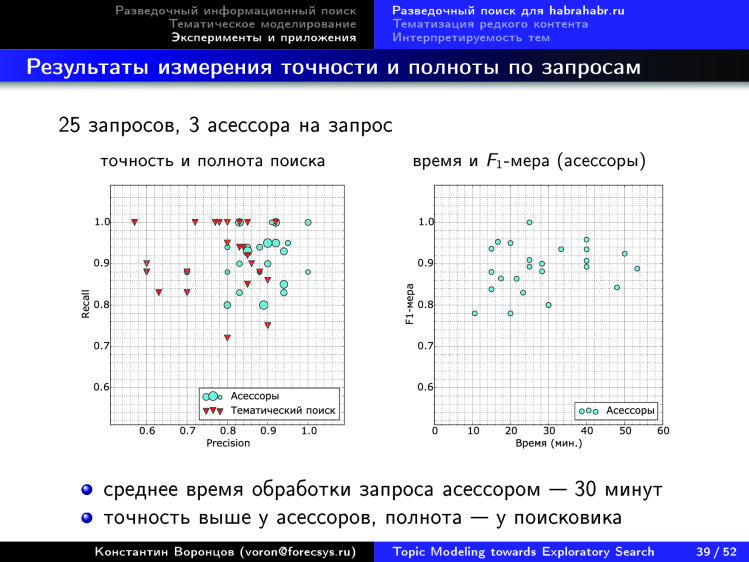
Дальше мы используем обычные стандартные критерии точности и полноты. Поскольку у нас есть асессоры, разметившие эту коллекцию, то вот как выглядят эти 25 запросов.
Перейду сразу к финальному результату.
Оказалось, что асессоры довольно точно и полно находят контент, а тематическая модель обладает лучшей полнотой, особенно если мы ее построим по всем пяти модальностям в этой задаче и еще проанализируем число тем. Хотя ее точность, может быть, чуть меньше.
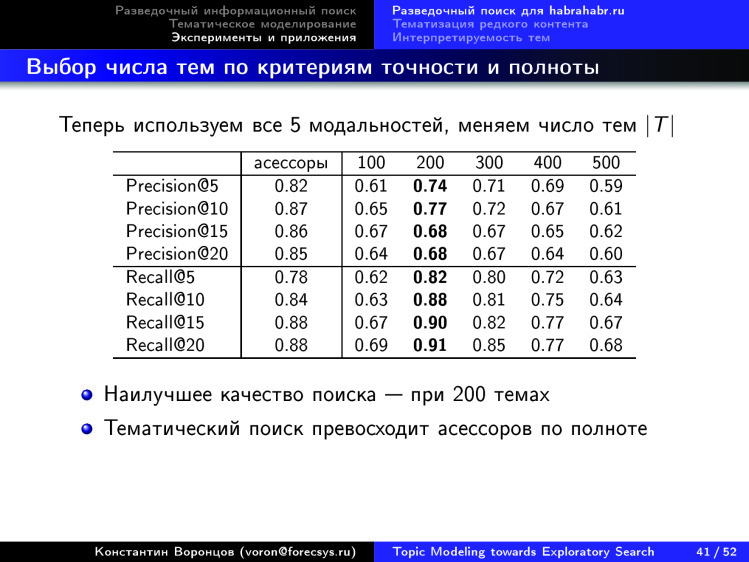
Вот, удалось обнаружить оптимум по 200 темам. Это интересно, потому что во многих задачах оптимум по числу тем не удается обнаружить, чем больше тем берем — тем лучше. Но когда мы используем критерий качества поиска, оказывается, все-таки существует оптимальное число тем.

На этом остановлюсь. Я еще заготовил несколько рассказов, но не успеваю. В презентации они останутся, если у вас будут вопросы, мне можно написать письмо. Спасибо за внимание.
Комментарии (8)

Saffron
23.10.2016 19:41+4Пятнадцать лет назад, ещё до всяческих умных алгоримтов, запросто находил информацию в интернете. Основной секрет — надо искать в два-три шага. Например, сначала найти достойное доверие сообщество, почитать его, узнать термины, искать дальше. Это особенно хорошо работало, когда можно было вбить ключевые слова в поисковик и увидеть страницы, их содержащие. К сожалению, в наше время такой поиск больше не работает — поисковик отдаёт тебе то, что как он думает, ты ищешь, а не то, что ты конкретно указал в запросе.

dcc0
23.10.2016 20:54Я и раньше находил и сейчас нахожу то — что мне надо. Мое субъективное мнение: существующего поиска достаточно для осуществления практически любой научной и образовательной деятельности.
Куда более остро стоят вопросы сохранности информации, в сети много изменений, пропадают сайты, изображения и т.д.
Here_and_Now
24.10.2016 00:14Я бы заплатил уже за функцию поисковика, которая позволит помечять коммерческий буллшит, тексты, которые я уже читал (не содержат нового знания) и тексты, которые мне как раз могут быть интересны.
А если это ещё и визуализировать так круто, как рассказал автор доклада, то цена может быть в 10 раз выше.
Почему этого ещё нет? Думаю потому, что более-менее нормальные результаты получаются на базах научных знаний, которые имеют строгие правила оформления + многие дополнительные параметры документы описаны отдельно. Если взять более коммерческую, а не академическую задачу (а таких людей большинсво), то данные надо будет собирать по сотням блогов, форумов и книг. Отделять действительно полезные статьи от рекламных поверхностных материалов. Вычитывать их. В общем получится каша, хуже чем после 3-4 уточнений с человеческим мозгом.
Как думаете?chersanya
24.10.2016 02:23Конечно, лучше (=проще получить хороший результат) работает на научных датасетах — мы с Воронцовым строили, например, тематические модели конференций, arxiv'а. Однако вне науки тоже можно пробовать, для начала что-то более-менее адекватное — например, как написано в статье, дамп хабра. Но и это, как я понимаю, уже в некоторым смысле пройденный этап — сейчас анализируют методами тематического моделирования к примеру данные из соц сетей. При этом, кстати, можно учитывать не только непосредственно текст, но и например геолокацию, пользователя, дату и т.п. — и всё в рамках ARTM :) И библиотека bigartm сейчас, насколько я знаю, почти всё это поддерживает — можно пробовать самим на своих данных.
Here_and_Now
24.10.2016 11:05Тогда не совсем понятна проблема с монетизацией. Если система помогает искать знания, то «интеллектуальная элита» способна заплатить пару долларов в месяц за такой сервис.
Вообще напоминает идею Semantic web, но с оговоркой, что никто размечать контент не будет, потому надо всё делать самим)
Очень жду такую систему. У самого были мысли, что подобный сервис был бы интересен, но навыков недостаточно) Пишите ещё об улучшении поиска информации и образования!

markhor
24.10.2016 11:13Очень нужна ссылка на статью и код Насти Яниной! Комбинирование регуляризаторов и подбор весов — это самое сложное и самое крутое, полезное в ARTM, а документации нифига нет про это. См. мою статью — про это жалуюсь. Банально как в CLI задавать декорреляцию — без чтения кода непонятно.
stokker
Странный вопрос о монетизации… В этой сфере, кто первый — того и тапки.
stokker
И кстати, это не камень в огород Википедии?