
Под катом — расшифровка лекции и часть слайдов Сергея.
В последние годы мы наблюдали череду крупных побед либо по мере сил принимали в них участие. Эти победы выражены в том, что множество важных задач машинного обучения беспрецедентно точно решаются с использованием нейросетей. В результате возникло очень много шума далеко за пределами научного сообщества, и очень многие люди обратили внимание на область глубокого обучения.
Такое внимание может быть весьма полезным с точки зрения финансирования исследований, каких-то стартапов. Но еще оно стимулирует рост ожиданий, часть из которых откровенно малоадекватны, и вокруг глубокого обучения надувается пузырь.
Мой тезис заключается в следующем: сегодня глубокое обучение в том виде, в котором оно преподносится нам журналистами или некоторыми не очень добросовестными или не очень разбирающимися в теме экспертами, — современный миф. Сегодня я хочу его деконструировать, поговорить о том, что в нем действительно реально, что работает, что маловероятно работает, какие выводы мы можем извлечь — или, по крайней мере, какие выводы извлек я — и что может прийти на смену глубокому обучению.
Нам преподносят миф, имеющий много общего с другими известными мифами. Например, в нем есть история о темном времени, когда истинное светлое знание практически утеряно, хранится всего несколькими посвященными, а в мире царит хаос.
Еще в этом мифе есть свои герои, совершающие великие эпические подвиги.

В этом мифе есть и сами великие подвиги — они потом остаются в истории и рассказываются друг другу из уст в уста.

И еще в этом мифе есть табу, великий запрет. Нарушив его, можно высвободить какие-то мощные, неподконтрольные человечеству силы.
Наконец, у этого мифа есть свои последователи, которые предпочли служение культу вместо объективной реальности.

Давайте поговорим о том, что такое глубокое обучение в массовом сознании. Во-первых — совершенно новая технология, аналогов которой раньше не было.
Во-вторых — попытка воспроизвести принципы работы человеческого мозга или даже превзойти их.
И наконец, это универсальный магический черный ящик, который можно скачать, вставить куда-то между усилиями и профитом и который сам заработает так, что все станет гораздо лучше.
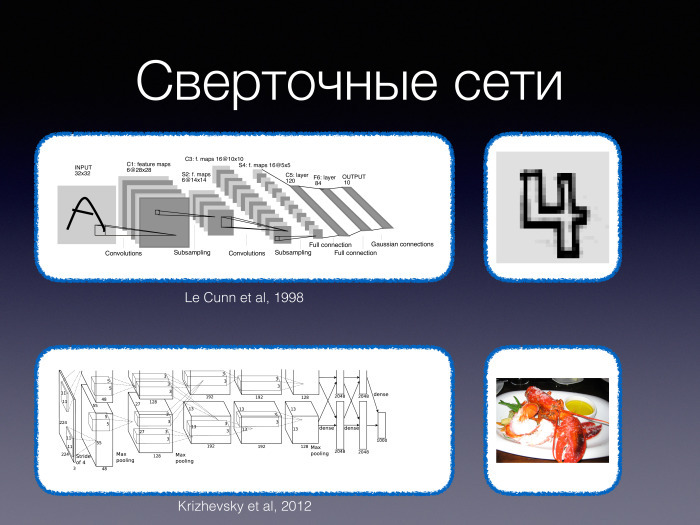
Давайте поговорим про новизну. Есть такой пример, что многие успехи глубокого обучения — связанные прежде всего с задачами компьютерного зрения, да и все остальные — начались с исторической работы 2012 года, когда два аспиранта и один научный руководитель обучили большую сверточную сеть и с большим отрывом победили в конкурсе распознавания изображений ImageNet. Многие разговоры о том, что это наше будущее, начались именно с указанной работы. И многие люди стали воспринимать обсуждаемую технологию как что-то совершенно новое — в то время как первые статьи о сверточных сетях датируются серединой 90-х годов. Конечно, тогда они были гораздо меньше, и изображения, с которыми они работали, были гораздо проще, но тем не менее.

Другой хороший пример — рекуррентные сети. Известная модель seq to seq, sequence to sequence learning, позволяет, например, осуществлять машинный перевод или строить диалоговые системы. Она тоже наделала много шума. Когда я читал примеры философских диалогов с этой системой, у меня холодок пробежал по спине, потому что пример из статьи имеет какой-то смысл. И снова многие заговорили, что мы приближаемся к какому-то искусственному интеллекту, и тоже возникло ощущение, что речь идет о чем-то совершенно новом.
Это действительно была новая модель, новая нейросетевая архитектура, и результат, по сути, уникальный. Однако можно заметить, что составляющие этой сети, которые отвечают за распознавание, скажем, входного вопроса и за генерацию ответа, представляют собой довольно давно известную рекуррентную архитектуру, и известна она как long short-term memory или LSTM. Предложена она была аж в 1997 году — почти 20 лет назад.
И вот, совсем свежий прорыв, развеявший все сомнения о том, ждет ли нас сильный искусственный интеллект. Речь идет про гибкий нетворк, систему от компании Google DeepMind, которая на сырых кадрах из эмулятора игр Atari смогла научиться в них играть, причем лучше, чем отдельные люди. Это, понятно, тоже наделало много шума.
Интересно, что это исторический результат, но также верно и другое: часть этой системы, отвечающая непосредственно за интеллект, за принятие решений, за принципы Q-learning, была предложена аж в 1989 году в диссертации, по-моему, Кристофера Уоткинса.

Что же изменилось за эти 20 лет? Почему когда-то нейросети были технологией-аутсайдером, каждый шутил и издевался над исследователями в этой области, а теперь всё немножко наоборот?
В первую очередь, компьютеры стали быстрее и дешевле, а технологии параллельных вычислений — включая вычисления на графических ускорителях — появились и стали мейнстримом. Это во многом сделало возможным обучение больших моделей.
Стало больше данных. Упомянутый конкурс ImageNet и набор данных для него состоит из 14 миллионов размеченных объектов в 21 тысяче категорий. Объекты размечены людьми. Хотя этот дата-сет создавался только для одной задачи, для классификации изображений, благодаря ему появились такие классные приложения, как Prisma, перенос стилей, и наверняка еще извлечен не весь потенциал. Был необходим качественный переход в наличии обучающих данных.
Наконец, банально накопился какой-то опыт в области машинного обучения. Например, появились работы о том, как такие сети правильно обучать и инициализировать; появилось больше понимания того, как они на самом деле устроены и работают.

Давайте посмотрим, насколько нейросети — черный магический ящик. Предположим, вам нужно решить задачу сортировки всех массивов вещественных чисел из четырех элементов. Представьте универсальный аппроксиматор, универсальную черную сеть, способную справляться с такими задачами, — вашу любимую архитектуру.
Теперь представьте, что эта же архитектура решает задачи определения ранга матрицы по ее тепловой карте, которую вы получили с помощью вашего любимого инструмента анализа данных — MATLAB или какой-нибудь библиотеки на языке Python. Не знаю, как вам кажется, а мне кажется очень маловероятным, что одна и та же нейросетевая архитектура будет эффективно решать много разных задач, одинаково эффективно анализировать самые разные типы данных и вообще работать в самых разных режимах.
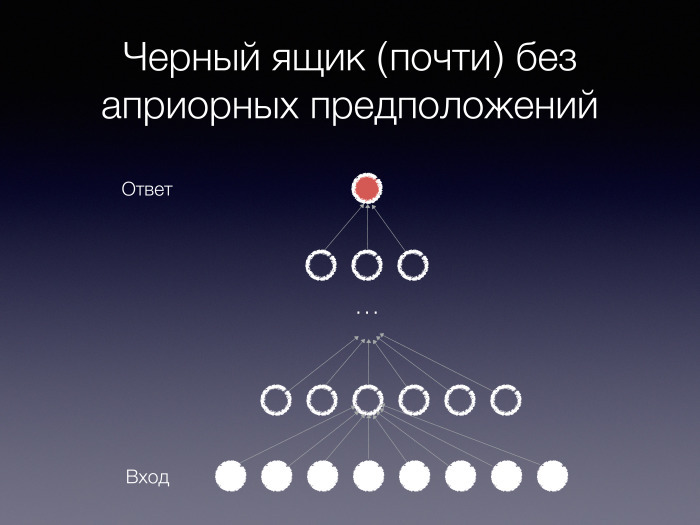
На самом деле действительно есть такой черный ящик — его называют многослойным перцептроном. Это простейшая нейросетевая архитектура, использующая очень мало априорных предположений о задаче, которую предстоит решать. Она устроена просто как несколько слоев нейронов. Каждый нейрон принимает входы со всех нейронов предыдущего слоя, выполняет над ними некоторые преобразования и передает их по аналогичному принципу дальше, наверх. В конце мы вычисляем ответ.
Известно, что такая архитектура теоретически является универсальным аппроксиматором для непрерывных функций. Есть много разных универсальных аппроксиматоров, не только многослойные перцептроны. Есть разные классы функций, в которых они всё могут аппроксимировать. И есть такой факт.
Интересно, что на практике выясняется: такие универсальные черные ящики, в первую очередь, избыточно параметризованы, то есть эта связанность каждого нейрона с каждым нейроном из предыдущего слоя глубоко избыточна. Часть этих связей если и не вредят, то совершенно точно лишние. По весам отдельных нейронов можно предсказать веса других нейронов.
Кроме того, мы ожидаем, что чем глубже этот ящик, тем лучше он работает. В теории, наверное, оно так и есть, но на практике часто оказывается, что его выразительная способность может падать с увеличением глубины, числа слоев.
Как ни странно, именно такой черный ящик относительно редко используется в практических приложениях.

Скажем, для задач компьютерного зрения часто используют сверточные сети. И там совсем не такой черный ящик. В них используется гораздо больше априорного знания о решаемой задаче, априорных предположений — давайте посмотрим на примере, каких именно.
Для начала мы хотим обеспечить себе инвариантность относительно небольших смещений и поворотов изображения. Мы хотим, чтобы подобное не влияло на результат классификации. Добиваемся мы этого, например, с помощью операции пулинга. Мы частично снимаем указанный вопрос.
Кроме того, есть мощное априорное знание о том, что нам нужно переиспользовать параметры. Когда мы выполняем операцию свертки, мы применяем один и тот же фильтр, одни и те же веса, к разным участкам изображения. Такой механизм мы, конечно, могли бы выучить в многослойном перцептроне, но, видимо, до сих пор это мало кому удавалось, если удавалось вообще. И здесь мы накладываем очень сильные ограничения, вносим в нашу модель очень много структур.
Наконец, мы предполагаем, что наше изображение имеет некоторую иерархическую природу и что уровни этой иерархии устроены примерно одинаково.
Согласитесь: все это нельзя назвать черным ящиком, где мы строим минимальное количество предположений. Мы вносим очень много априорного знания.
А вот пример сверточной сети, которая показывает одни из лучших на данный момент результатов в конкурсе ImageNet. Это Inception-ResNet. Блок, отмеченный красным, на самом деле выглядит так. Следующий блок выглядит так, и следующий.
Inception-ResNet имеет очень сложную структуру. Не вполне понятно, зачем здесь нужны такие асимметрии, такая сложная связность между элементами сети. И здесь мы используем еще больше априорного знания уже даже не только о решаемой задаче, но и о методе обучения, который мы используем, чтобы эту сеть настроить. Здесь мы прокидываем короткие связи между слоями. Они минуют несколько слоев сети, чтобы градиенты лучше распространились в обход промежуточного количества слоев. Здесь мы используем так называемый принцип остаточного обучения — предполагаем, что каждый следующий слой не просто изменяет вход предыдущего, а пытается скорректировать, исправить ошибки, допущенные до него. Здесь очень много априорных предположений.
Иными словами, более эффективная нейросетевая архитектура использует более верные априорные предположения, лучше обходится с информацией о решаемых задачах.
В глубоком обучении произошел уровень повышения абстракции априорных предположений. Если раньше мы кодировали признаки вручную, то теперь мы примерно знаем, как должны быть устроены интересные нам признаки, а выучатся они сами. Но у нас по-прежнему нет черного ящика, который решит за нас всё.
Общая тенденция выражается в следующем: мы хотим иметь обучаемые черные ящики, о которых мы мало что понимаем. Только это не один большой черный ящик, а много маленьких — сцепленных между собой и работающих в связке. Хороший пример — модель для image captioning, для генерации описания. Там в связке работает достаточно сложная сверточная сеть и рекуррентная сеть, генерирующая слова. еще там есть механизм памяти — много черных ящиков, которые мы настраиваем так, чтобы они работали вместе.

Также существует интересный тезис, что нейросети работают лучше, чем человек. Для части задач это так. На том же конкурсе ImageNet есть несколько категорий, где у нейросетей точность выше, чем у некоторых людей.
Но нейросети способны и ошибаться. Приведу пример ошибки нейросети. Приложением Google Photos выполнялась автоматическая классификация, и некоторые чернокожие люди на фотографии были опознаны как гориллы. Не очень хочется на этом примере спекулировать — есть много причин, почему такое могло произойти, и они совсем необязательно имеют отношение к глубокому обучению, к нейросетям.
Но есть еще такой пример направленной атаки, когда к изображению панды добавляется некоторый специальный, незаметный для человеческого глаза шум, заставляющий продвинутую хорошую нейросеть определять изображение как гиббона, причем с очень большим уровнем уверенности.
Не то чтобы указанные примеры должны продемонстрировать какую-то беспомощность нейросетей в сравнении с человеческим интеллектом. Просто и в компьютерном зрении — где, казалось бы, решены если не все задачи, то многие — есть над чем поработать даже в достаточно базовых задачах.

В глубоком обучении действительно здорово, что можно обучать большие и очень большие модели на больших объемах данных. Это возможно благодаря использованию аппарата стохастической градиентной оптимизации. Если нашу задачу можно представить как минимизацию матожидания некоторой функции — где у нас есть какая-то совершенная величина ? и норма параметров ?, — то мы хотим найти наилучшие параметры при всех возможных значениях ?. И такая стохастичность, такое матожидание, может возникнуть в разных ситуациях — например, когда мы усредняем по всей обучающей выборке. Иными словами, случайная величина отвечает за выбор объекта из выборки. И если мы усредним по всем объектам, это будет всё равно что пройтись по всем объектам, посчитать функцию потери, а затем усреднить.
Или ? может быть каким-нибудь внутренним шумом либо неопределенностью. Например, в генеративных моделях, о которых говорилось сегодня, используется этот принцип. Там есть некоторый случайный шум, который потом превращается, скажем, в фотографию человеческого лица. Вот тоже пример такой стохастичности.
Очень здорово, что от функции f почти ничего не зависит. У нас есть универсальный метод минимизации таких функций, так называемый стохастический градиентный спуск, о котором многие слышали и который не требует от нас расчета всего этого большого матожидания. Достаточно значения функции или ее градиента в какой-то одной случайной точке по случайной величине.
Использование градиентных методов оптимизации позволяет нам декомпозировать всю нашу систему машинного обучения на подобные составляющие: на модель, на функцию потерь, на оптимизатор — который является очень важным элементом успеха нашего обучения. Разные методы оптимизации могут давать радикально разную скорость сходимости и радикально разное качество после какого-нибудь количества итераций.
Интересно, что это несколько напоминает модель model-view controller, которая иногда встречается в программировании. Может, отсюда что-то следует.

Когда мы зафиксировали функции потерь и оптимизатор, мы можем сконцентрироваться только на нашей модели. Мы можем отдать ее голодным аспирантам, студентам или инженерам и сказать, что мы хотим 95-процентного качества. И они могут, используя свои знания, свои творческие способности, комбинировать, композировать разные модели из разных кусков, пробовать, изменять модель в едином фреймворке градиентной оптимизации. И в конце концов они могут побороть порог требуемого значения.
Как люди строят нейросети в современном мире? Если сеть не требует особого подхода, то достаточно взять какую-нибудь простую существующую библиотеку вроде keras, как в данном примере, определить структуру нейросети, после чего будет автоматически построен вычислительный граф для обучения данной модели. Есть сама модель, поступают данные, автоматически считаются градиенты от функции потерь. Есть оптимизатор — он обновляет веса сети. Все это может работать на разных устройствах, не обязательно на вашем компьютере. Оно даже может работать на нескольких компьютерах параллельно. Речь идет об отличной абстракции. Она заставляет задаться вопросом — а вообще, так ли нам теперь необходима метафора нейронных сетей?
Если мы знаем, что хотим использовать стохастический градиентный спуск или какие-то другие градиентные методы для настройки весов, то зачем нам проводить параллели с какими-то якобы нейронами в нашей голове? Я не готов подробно говорить об этом — не знаю, как работает наш головной мозг. Но мне кажется, что эти метафоры во многом вредны и не всегда соответствуют реальному положению вещей.
Вместе с тем отказ от параллели с реальными нейронными сетями может дать нам больше, чем кажется. Если мы перейдем от термина «нейронная сеть» к термину «дифференцируемая функция», то мы сильно расширим базис функций, из которых можно строить новые модели. И, может, их выразительная мощность только повысится.

Есть очень много инициатив, где пытаются совершить такой переход. Это заслуживает отдельного доклада. Но я бы хотел донести несколько вещей, которые кажутся мне весьма полезными и которые исследователям в области глубокого обучения стоит почерпнуть из смежных дисциплин, связанных с программированием.
В первую очередь предположим, что мы либо знаем, что функция, которую мы оптимизируем, должна быть, скажем, дифференцируемой или гладкой, либо накладываем какие-то другие ограничения. Также мы, предположим, знаем, что указанное свойство сохраняется относительно замкнутых операций — композиции, сложения, еще чего-то. При этих условиях мы можем в языке программирования с продвинутой системой типов проверять дифференцируемость, гладкость, еще какие-то свойства полностью стохастически на этапе компиляции.
Наконец, мне очень нравится идея встраивания маленьких «черных ящиков», дифференцируемых функций, в обычные языки программирования. Если вы вдруг забыли, как вычисляется площадь квадрата в зависимости от его диаметра, вы можете сказать: у меня нет нужной функции, вместо нее есть некая нейросеть, все это будет на привычном вам языке программирования, а в конце будут несколько примеров того, каким должен быть выход у программы целиком. Речь идет обо всей вашей программе и обо всем, что из нее можно продифференцировать. Значит, внутри программы мы в том числе можем обучить такой маленький черный ящик.
еще есть инициативы по созданию дифференцируемых структур данных — каких-то привычных нам структур вроде стека, очереди или двусторонней очереди. Но решения относительно алгоритмических паттернов, которые используют эти структуры данных, тоже дифференцируемы.
То есть если вы вдруг хотите всех победить на Topcoder и как-нибудь догадались, что в вашей задаче нужно использовать стек, но точно не знаете, как именно, — может, вы сумеете вынести управление стеком в отдельную функцию. Ее можно обучить по каким-то тестам. Это мне кажется совершенно замечательным.
И вообще, есть очень много параллелей с функциональным программированием, заслуживающих пристального внимания. Приглашаю всех пройти по ссылке и прочитать подробнее.
Если мы разобрались, что, возможно, глубокое обучение — не серебряная пуля и все равно там есть к чему стремиться и куда развиваться, то давайте поговорим о другом. Что может прийти на смену нейросетям и парадигме дифференцируемого программирования в целом?
Это нечто должно обладать, как мне кажется, тремя свойствами. Для начала, оно должно позволять строить мощные выразительные модели — потому что немощные и невыразительные у нас уже были, теперь нам нужны мощные.
Кроме того, она должна позволять строить их модульно, композиционно, собирать из разных кусков более сложные модели и тем самым иметь низкий порог вхождения. Цель — чтобы какой-то отдельный кусок можно было дать отдельному человеку и он за короткое время мог его реализовать.
Также должна быть возможность универсально обучать нужные модели на больших данных.

У меня нет времени поговорить про одного из кандидатов, способых со временем заменить глубокое обучение. Дмитрий Петрович сделал небольшой ввод. Это может быть вероятностное программирование, это могут быть вероятностные модели, в которых мы будем автоматически выполнять вывод. Гипотетически они обладают всеми тремя свойствами, кроме одного: сейчас нет способа придумать универсальный и быстрый алгоритм обучения для произвольно сложной вероятностной модели. Возможно, с использованием того же нейробайесовского подхода удастся это сделать.
Одну минуту поговорю о роли больших данных. Давайте на секунду забудем про ImageNet. Вспомним два примера: DQN и AlphaGo. Интересно то, что указанные системы обучались на симулированных данных. В случае с DQN использовались снимки из эмулятора компьютерных игр, запуск которого гораздо дешевле, чем, например, запуск робота в реальном мире. Если 10 млн виртуальных обучающих объектов мы собрать можем, то собрать 10 млн реальных обучающих объектов гораздо сложнее, особенно если речь идет о состоянии какой-то физической системы.
И AlphaGo помимо размеченного (неразборчиво — прим. ред.) использовала 30 млн позиций, полученных в ходе игры системы с самой собой. Это очень важные идеи, поскольку именно они позволили собрать эффективную обучающую выборку и обучить настолько сложную модель.
Следующий прорыв может стоить дорого. В следующей предметной области, которая будет «решена» нейросетями, тоже должно быть много обучающих выборок. Если вы хотите построить очень совершенного чат-бота, вам где-то надо найти обучающую выборку. И возможно, вам придется вложить много денег в ее разметку.

В заключение хотел бы сказать, что глубокое обучение работает, я совсем не отказываюсь это признавать — было бы очень странно отказываться. Просто в успехе нейросетей есть много составляющих, и о них тоже надо помнить. Надо критически подходить к тому, что в них реально работает, а что является каким-то маркетингом и пиаром.
И нейросети — не конец эволюции методов машинного обучения, а только какой-то ее этап. Имеет смысл инвестировать свои усилия и интерес в альтернативные подходы. Спасибо за внимание.
Комментарии (43)

Keresto
20.11.2016 19:57Небольшой вопрос от студента-профана, начавшего изучение НС и имеющего желание на основе данных вещей написать научную работу (естественно, имеется математическая база).
Вспоминая ту новость про выигрыш команды в конкурсе по написанию бота для DOOM, который должен был уметь ориентироваться на новых картах, успешно сражаться и собирать вещи: авторы сказали, что использовали несколько нейронных сетей.
Ну а вопрос, собственно, именно про целесообразность такого подхода: как уже известно, сети с большим количеством слоёв (на примере многослойного перцептрона) часто ошибаются, а с малым количеством могут банально не «понять» способ решения задачи. А если подобрать некое оптимальное значение количества слоёв, а затем использовать множество нейронных сетей с малым количеством выходов, но которые были бы специализированы на чём-то одном, а затем уже отдельные выводы шли как входные данные некоей новой обобщающей НС.
В принципе, идея на поверхности лежит, есть ли исследования реализаций?
napa3um
20.11.2016 20:55+4Вы как раз и обрисовали современное положение вещей (озвученное и в статье): лидеры ИИ-гонки из нейросетей строят специализированные на конкретных (под-)задачах «чёрные ящички», которые объединяются инженерами (с их опытом и интуициями относительно прикладной задачи) в различные архитектуры, которые к биологическим нейросетям уже как бы и не имеют никакого отношения, это всего лишь чисто математические инструменты, «минимизаторы целевых функций», присыпанные кучей ручных эвристик и настроек. «Само» оно всё ещё не работает, главным архитектором решения остаётся человек, и отобрать у него эту роль, построив «универсальный чёрный ящик», до сих пор не удалось.

xuexi
20.11.2016 21:14+2Хорошо, что хайп спадает. А то последнее время из-за маркетоидной лажи трудно было найти информацию по существу дела. К этой статье можно порекомендовать недавний сжатый классификатор нейросетей (тыц, тыц)
Кстати, не является ли докладчик родственником Олегу Бартунову, который PostgreSQL?


BelBES
20.11.2016 23:11+2Упомянутый конкурс ImageNet и набор данных для него состоит из 14 миллионов размеченных объектов в 21 тысяче категорий.
А когда ImageNet успел настолько подрасти? Вроде бы он как был ~1.2M картинок из 1000 классов, так и сейчас продолжает оставаться таких же размеров.
supersonic_snail
21.11.2016 20:46+2То, что вы называете ImageNet-ом — это ILSVRC2012, сабсет настоящего ImageNet-а.
А сам ImageNet — иерархическая база знаний, а-ля wordnet для картинок. Отсюда и название.BelBES
21.11.2016 22:03Спасибо за замечание. Как-то никогда не задумывался, что этот датасет настолько огромен.
BelBES
21.11.2016 22:14Кстати, а есть работы, где тренируются на полном датасете? В статьях вроде бы все пользуются этим самым 1000-классовым сабсетом, да и большинство статей у меня с этим датасетом воспроизводился.
supersonic_snail
21.11.2016 22:45Я ни разу не видел, да и не думаю, что есть — слишком уж здоровый.
К тому же уже столько работ на ilsvrc2012, что что-то новое на большем количестве данных будет не совсем честно сравнивать с существующими работами.BelBES
21.11.2016 23:11Тут было бы интересно посмотреть не в плане сравнения с уже имеющимися методами, а в целом понять: можно ли получить существенный буст качества методом "грубой силы". Типа потренировать тот-же ResNet-1001 на полном датасете, а потом приляпать его к Faster-RCNN и посмотреть, можно ли получить таким методом state of the art.
supersonic_snail
21.11.2016 23:40+1Мне думается, что переход от 1кк к 10кк картинок не даст принципиального улучшения. Конечно, будет определенный прирост качества, но не такой как при переходе с 10к на 1кк картинок. Хотя я запросто могу быть неправ — очень тяжко предугадать поведение сетей не поставив эксперимента, так что я бы хотел увидеть статью, в которой обучают на полном imagenet-е.
crea7or
21.11.2016 03:18+2Для интересующихся настоящими нейросетями предлагаю посмотреть курс Химия Мозга Вячеслава Дубинина ( МФК МГУ ). Эти 12 лекций по 1,5 часа типа бегом по основному функционалу мозга. Ну хотя бы первые 5 надо осилить, чтобы понять, что такое настоящая нейросеть, как она работает и примерно к чему надо стремиться.
Alexey_mosc
21.11.2016 12:20Слушать интересно. Детали тоже полезные, особенно, если не ас в глубинном обучении. Но сам посыл он не нов. Об этом уже говорилось и подмечалось. Теория и первые разработки уже давно есть, а на рынок технология вышла недавно из-за роста мощностей.

SADKO
21.11.2016 12:29+1Посыл не нов, но мало кто верит, как не странно…
… и вот уже новое поколение пускается во все тяжкие, начиная почему-то с разу с больших задач, хотя куда логичней изучать свойства и подходы на элементарных примерах, когда и эксперимент-то не всегда нужен, всё тупо математически выводитсяAlexey_mosc
21.11.2016 13:47Соглашусь. И лучше начать с самого легкого метода. Например, сделать линейную аппроксимацию процесса. При кажущейся примитивности, такие модели показывают хорошую устойчивость с точки зрения воспроизводимости результата на новых данных, ибо они underfit (недоученные). А глубокие сети это апофеоз технологий — несколько видов регуляризвации, самописные функции потери, генерация входных признаков, стохастические методы сходимости… Короче, весь этот паровоз должен быть оправдан.
an24
21.11.2016 13:15Если вы хотите построить очень совершенного чат-бота, вам где-то надо найти обучающую выборку. И возможно, вам придется вложить много денег в ее разметку.
Мне казалось, что как раз глубокие сети(точнее методы их обучения) и не требуют большого количества размеченных данных.
Dark_Daiver
21.11.2016 17:24+1Как раз наоборот, для Deep Learning важно чтобы данных было много. Иначе велик шанс получить переобученную модель.
an24
21.11.2016 18:52+1Не совсем так. С помощью RBM или Autoencoder'ом глубокую сеть обучают без учителя на большом объеме НЕ размеченных данных. Потом сеть тюнингуется с помощью небольшого объема размеченных данных.
Dark_Daiver
21.11.2016 19:08Виноват, не понял что в вашем сообщении акцент на разметке.
Если честно, то мне казалось, что предобучение в основном использовалось чтобы ускорить обучение (и сейчас так уже делают редко).
А есть ли какие-нить бенчмарки которые бы сравнивали качество предобученных моделей + тюннинг и моделей обученных «честно»?supersonic_snail
21.11.2016 21:11+2Предобучение на неразмеченных данных практически не используется — в основном люди берут сеть, обученную на imagenet-е и тюнят ее для своих задач.
То, о чем вы спрашиваете, живет под именем semi-supervised learning, и работает в общем-то довольно таки неплохо — на том же mnist-е имея 100 размеченных картинок и все остальное неразмеченное, можно получить около 1% ошибки [1]. Для сравнения — лучшие результаты с 50000 размеченных картинок это 0.5-0.3%. Для больших сетей не используется — слишком уж накладно по вычислениям.
[1] https://arxiv.org/abs/1606.03498, таблица 1.an24
21.11.2016 21:43в основном люди берут сеть, обученную на imagenet-е и тюнят ее для своих задач
Так это и есть предобученная сеть.supersonic_snail
21.11.2016 22:50+1Сеть, обученная на imagenet-е, обучена с учетелем (supervised). Вы выше писали про обученные без учителя (unsupervised) сети для инициализации, что уже практически сошло на нет. Самое близкое — semi-supervised.
an24
21.11.2016 21:34Сверхглубокие сети обратным распространением ошибки (это вы, видимо, называете «честным» способом) вообще не обучить из-за эффекта затухания градиента.
Dark_Daiver
21.11.2016 21:36+1Ну, а чем еще их учат то? Backprop (т.е. получение градиента) и разные варианты SGD. С затуханием борются с использованием незатухающих ф-ий (ReLU) и штук типа Batch Normalization, если я не ошибаюсь, конечно.
Тот же ResNet (в том числе и его версию из 1000 слоев), вполне обучили.
Под «честным», я имею ввиду обучение на всех размеченных данных без предобученияan24
21.11.2016 22:07-1Размеченные данные данные нужны для обучения «с учителем». Все современные сети предобучают алгоритмами «без учителя». Все они являются различными комбинациями ограниченной машины Больцмана (RBM) и/или Autoencoder'а (есть весьма затейливые комбинации).
Насколько я понимаю, ReLU помогает против паралича сети. От затухания градиента не помогает. Методы увеличивающие learning rate тоже не про это (это про Batch Normalization)
Про ResNet знаю очень мало.
Мне кажется, что будущее как раз за обучением с минимумом размеченных данных, т.е. без учителя.
BelBES
21.11.2016 22:20Про ResNet знаю очень мало.
Там вся идея в том, чтобы как можно дальше по сети пропихивать "остатки" полезного синала, тем самым увеличивая общую глубину сети, получая более сложные иерархические фичи.
Dark_Daiver
21.11.2016 22:34Мне нравится думать, что ResNet это такой себе каскад, в котором мы обучаем одновременно все этапы, а не только текущий
Dark_Daiver
21.11.2016 22:21Как я понимаю, еще используют хитрую инициализацию
http://www.jmlr.org/proceedings/papers/v28/sutskever13.pdf
Статью я сам пока не осилил, но
>More recently, Martens (2010)… is capable of training DNNs from certain random initializations without the use of pre-training, and can achieve lower errors for the various auto-encoding tasks considered by Hinton & Salakhutdinov (2006).
an24
22.11.2016 05:29В целом интересно. Хотя в данной фразе есть фактическая ошибка. Если речь идет про основополагающую статья Хинтона «Reducing the Dimensionality of
Data with Neural Networks», то в ней для предобучения использовалась RBM, а не AE.
BelBES
21.11.2016 22:09в том числе и его версию из 1000 слоев
А разве обучили? Насколько я помню из оригинальной статьи, авторы её попробовали тренировать, а потом сказали, что в ImageNet картинок мало, поэтому сетка недотренировалась.
Dark_Daiver
21.11.2016 22:17Я абсолютно не спец в Deep Learning, поэтому могу не совсем верно использовать термины
Отсюда https://arxiv.org/pdf/1512.03385v1.pdf
>Our method shows no optimization difficulty
В пункте про обучение 1к сетки
>The testing result of this 1202-layer network is worse than that of our 110-layer network, although both have similar training error. We argue that this is because of overfitting.
Ну я это понял как обучить смогли, но получили оверфит из-за слишком сложной модели при малом числе данных.
Если переобученную сеть нельзя считать за обученную сеть, то тогда я неправ.
Пример с этой сеткой я привел для того, чтобы показать, что проблема затухающих градиентов для сверхглубоких сетей может и не стоять, при правильно подобранной архитектуре.BelBES
21.11.2016 22:22Ну да, что-то такое, "фокус не удался", но в целом идея тащит, в достаточно больших сетях куда втыкаешь Residual connections — дает буст :-)
BelBES
21.11.2016 22:06Хм, про RBM'ы последние пару-тройку лет что-то вообще не слышно в вижене (последнее что я слышал — это как на RBM'ах делали инвариантные к повороту фичи). В основном сейчас исопльзуют предтренированные на ImageNet сети, а потом уже да, файнтюнят, но там тоже датасеты не вот чтобы очень маленькие для тюнинга.
supersonic_snail
21.11.2016 22:47Все верно. RBM ушел из моды с появлением denoising autoencoder-а. И вообще все ушло из моды с появлением AlexNet-а.
an24
22.11.2016 05:41-1Совершенно верно, — RBM мало кто использует, хотя Хинтон по-прежнему считает, что у машины Больцмана есть потенциал. Разряженный энкодер очень популярен.
AlexNet это обычная CNN из 8 уровней. Сделана учеником Хинтона. Алгоритм обучения, к сожалению, не совсем ясен. Вот кто делал CNN тот знает, что на 8 уровнях back prop работает плохо.BelBES
22.11.2016 08:49Вы легко можете повторить эксперимент с тренировкой AlexNet с нуля, для этой сети вообще никакой магии и подбора параметров у солвера не требуется, чтобы получить статейные значения.
SADKO
Истину глаголет! Всё было ране, ничего не ново, кроме возросших вычислительных возможностей позволяющих играться в чёрные ящики не утруждаясь поиском смысла происходящего и даже достигать каких-то результатов :-)
Хочется добавить лишь один нюанс, когда заходит речь о научных публикациях, мне всегда вспоминаются Гарри Марковиц, обладатель Нобелевской премии за экономическую теорию портфелей, на столько простую и очевидную, но никем ранее не озвученную из чисто шкурных соображений…
… так же и с нейро сетями вообще и глубокими в частности, имейте ввиду что задачка классификации картиночек, сложна и прикольна, но классификация состояний рынков куда проще и в хозяйстве полезней, ибо получить какой-либо прок от классификации картиночек в одиночку тяжело, один в поле не воин, чего не скажешь про биржевые баталии :-) so получив какой-либо значимый результат, вольный исследователь имеет веские причины о нём принципиально промолчать.
r66qq3Ek
Скажем так, от «классификации состояний рынков» общественной пользы тоже не ахти. Там и так достаточно страждущих что-то поклассифицировать и попредсказывать.