

Четыре примера работы программы, код которой опубликован в открытом доступе. Слева показаны исходные изображения, справа — результат автоматической обработки
Многие задачи в обработке изображений, компьютерной графике и компьютерном зрении можно свести к задаче «трансляции» одного изображения (на входе) в другое (на выходе). Так же как один и тот же текст можно представить на английском или русском языке, так и изображение можно представить в RGB-цветах, в градиентах, в виде карты границ объектов, карты семантических меток и т.д. По образцу систем автоматического перевода текстов, разработчики из лаборатории Berkeley AI Research (BAIR) Калифорнийского университета в Беркли создали приложение для автоматической трансляции изображений из одного представления в другое. Например, из чёрно-белого наброска в полноцветную картинку.
Неосведомлённому человеку работа такой программы покажется магией, но в основе её лежит программная модель условных генеративных состязательных сетей (conditional generative adversarial networks, cGAN) — разновидности известного типа генеративных состязательных сетей (generative adversarial networks, GAN).
Авторы научной работы пишут, что большинство проблем, которые возникают при трансляции изображений, связаны с трансляцией или «многие к одному» (компьютерное зрение — трансляция фотографий в семантические карты, сегменты, границы объектов и т.д.), или «один ко многим» (компьютерная графика — трансляция меток или входных данных от пользователя в реалистичных изображения). Традиционно каждая из этих задач выполняется отдельным специализированным приложением. В своей работе авторы попытались создать единый универсальный фреймворк для всех таких проблем. И у них получилось.
Для трансляции изображений великолепно подходят свёрточные нейросети, обученные минимизировать функцию потерь, то есть меру расхождения между истинным значением оцениваемого параметра и оценкой параметра. Хотя само обучение происходит автоматически, всё-таки для эффективной минимизации функции потерь требуется значительная ручная работа. Другими словами, нам по-прежнему нужно объяснить и показать нейросети, что конкретно нужно минимизировать. И здесь кроется много подводных камней, которые отрицательно сказываются на результате, если мы работаем с функцией потерь на низком уровне типа «минимизировать евклидово расстояние между предсказанными и настоящими пикселями» — это приведёт к генерации смазанных изображений.

Влияние различных функций потери на результат
Намного проще было бы ставить нейросети высокоуровневые задачи типа «сгенерировать изображение, неотличимое от реальности», а затем автоматически обучить нейросеть для минимизации функции потерь, которая наилучшим образом выполняет поставленную задачу. Именно так работают генеративные состязательные сети (GAN) — одно из самых перспективных направлений в разработке нейросетей на сегодняшний день. Сеть GAN обучает функцию потерь, задачей которой является классифицировать изображение как «настоящее» или «поддельное», одновременно тренируя генеративную модель, чтобы минимизировать эту функцию. Здесь никак не могут получиться размытые изображения на выходе, потому что они не пройдут проверку классификации как «настоящие».
Разработчики использовали для поставленной задачи условные генеративные состязательные сети (cGAN), то есть GAN с условным параметром. Так же как GAN усваивает генеративную модель данных, cGAN усваивает генеративную модель по определённому условию, что делает её пригодной для трансляции изображений «один в один».

Трансляция разметки Cityscapes в реалистичные фотографии. Слева разметка, в центре оригинал, а справа сгенерированное изображение
В последние два года описано множество применений GAN и хорошо изучена теоретическая основа их работы. Но во всех этих работах GAN используется только для специализированных задач (например, генерация пугающих изображений или генерация порнокартинок). Не совсем понятно было, каким образом GAN подходит для эффективной трансляции изображений «один в один». Основная цель данной работы — продемонстрировать, что такая нейросеть способна выполнять большой перечень разнообразных задач, показывая вполне приемлемый результат.
Например, очень неплохо смотрится раскраска чёрно-белых карандашных набросков (левая колонка), на основе которых нейросеть генерирует фотореалистичные изображения (правая колонка). В некоторых случаях результат работы нейросети кажется даже реалистичнее, чем настоящая фотография (центральная колонка, для сравнения).

Трансляция карандашных набросков в реалистичные фотографии. Слева карандашный рисунок, в центре оригинал, а справа сгенерированное изображение


Трансляция карандашных набросков в реалистичные фотографии
Как и в других генеративных сетях, в этой GAN нейросети воюют между собой. Одна из них (генератор) пытается создать фальшивое изображение, чтобы обмануть другую (дискриминатор). Со временем генератор обучается всё лучше обманывать дискриминатор, то есть генерирвоать более реалистичные изображения. В отличие от обычных GAN, в Pix2Pix одновременно и дискриминатор, и генератор имеют доступ к исходному изображению.
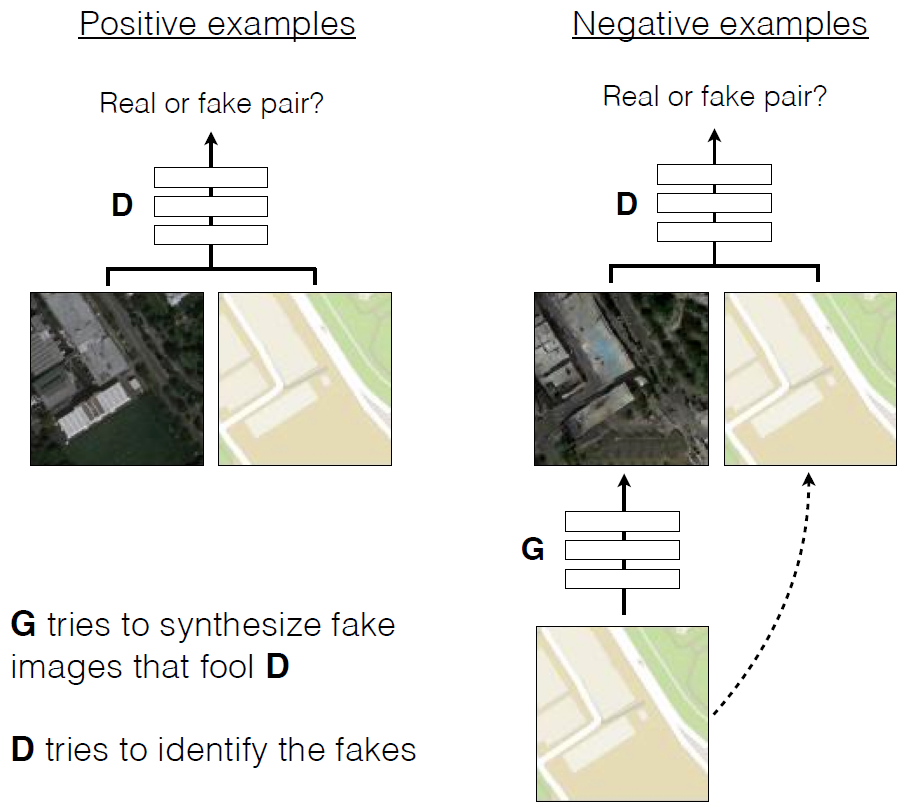
Обучение cGAN предсказывать фотографии аэрофотосъёмки по картам местности

Примеры работы cGAN по трансляции фотографий аэрофотосъёмки в карты местности и наоборот
Научная статья опубликована в открытом доступе, исходный код Pix2pix — на GitHub. Авторы предлагают всем желающим испытать программу.
Комментарии (44)

gionet
22.11.2016 19:42+4Скормить бы ей детские рисунки или каракули, которые люди рисуют во время телефонного разговора

igorek_uk
22.11.2016 21:14+6Получится что-то типа такого:
artist turns 6-year-old son's doodles into absurdly anatomically-incorrect animals
telmo pieper reincarnates his childhood doodles as digital drawings






Alexmaru
22.11.2016 20:36+1Пора собирать GUI ко всем этим вариантам, что тут показывали за последние пол-года.

pudovMaxim
22.11.2016 22:55Кстати о гуи. Неплохая мысль — нарисовать на листочке от руки формочки, прогнать через нейросеть и получить готовый комплект GUI.

pOmelchenko
22.11.2016 23:39+1и код обработчика…
pudovMaxim
23.11.2016 10:06А почему и нет. Стандартные кнопки, вроде закрыть, логин, свернуть, громкость и подобные реализовать достаточно просто.

RusikR2D2
22.11.2016 21:16Получается альтернатива CG для фильмов? графика будет совсем реалистичной при минимуме затрат. Эдакий компьютерный мультик на входе, а на выходе реалистичное кино. Наверняка, можно и без актеров обходиться.
deslambada
23.11.2016 11:11+1Да! Я мечтаю когда скачаешь обученную нейросеть по созданию CG фильмов, задашь ей в настройках критерии сюжета (типа маленькая девочка спасается в мире зомби апокалипсиса, или вообще в качестве сюжета можно закинуть книгу целиком), задаёшь количество драмы, триллера. Прописываешь какие-нибудь особенности и нажимаешь создать. комп подумает и к вечеру у тебя будет уникальный CG фильм, по качеству как «аватар» и «варкрафт»! Или мульт.
Хм… ещё было бы круто создавать таким образом целые игры! Типа создай мне похожее на скайрим или ведьмака, только чтобы люди там играли в блэкджек и текстуры покачественней.

imm
23.11.2016 11:35+1да и без зрителей — дискриминатор посмотрит и критическую статью напишет, рейтинг imdb выставит

zim32
22.11.2016 21:29+4Осталось написать нейросеть которая сможет генерировать нейросеть по наброску и дело в шляпе
Так глядишь скоро в художественных школах вместо композиции начнуть преподавать питонdeslambada
23.11.2016 11:23-1худ. школы не будут популярны, если в открытом доступе будет ИИ, который нарисует всё что угодно, достаточно сделать детский набросок за пару минут (ну и может настрить несколько настроек)
I-Brand
22.11.2016 22:09+1Пробовал на этой программе раскрашивать военные фото, ориентировочно 42-45 год. Что сказать, тональность меняется, цвета я бы сказал приближены к тем, которые могли бы быть в реальности. Но как по мне очень блекло все.
equand
24.11.2016 13:49+1Проблема статистического алгоритма, нужно обучать, а все просто закидывают «true this, false that»
jazator
22.11.2016 22:14Отдать ей удава и слона Маленьго принца. И вот тогда!
«Но все они отвечали мне: „Это шляпа“. И я уже не говорил с ними ни об удавах, ни о джунглях, ни о звездах...»

funca
22.11.2016 23:08+1Это абстракционизм наоборот. Интересно, что сеть думает про квадрат Малевича? :)

Dmitry_Dor
23.11.2016 12:50Ну, тут все просто 8-)

a5b
25.11.2016 08:32Почти: http://www.vz.ru/news/2015/11/12/777744.html "Они расшифровали надпись на «Черном квадрате», которую считают авторской.… Вся фраза, по мнению музейщиков, звучит как «Битва негров в темной пещере».… картину Малевича можно считать чем-то вроде заочного диалога художника с автором полотна, написанного в 1882 году французским писателем и эксцентриком Альфонсом Алле. Его полностью черная картина называется «Битва негров в темной пещере глубокой ночью»."

aydahar
23.11.2016 08:02+1Блин, когда же появятся готовые оффлайновые программы с обученными нейросетями для всего этого?!
Хочу плагин к фотошопу в виде этой Pix2pix.TheRexx
23.11.2016 11:11Не совсем оффлайн, вдруг кто прошел мимо темы — Колоризатор от японских мастеров
maxpsyhos
23.11.2016 09:46+4Интересно, а как оно справится с НАСТОЯЩИМИ карандашными набросками, а не оттрассированными с таких же фотографий, на которых сеть учили?

slavius
23.11.2016 11:11Все просто — если в обучении были правильные изображения — будет правильный выхлоп.
Если-бы сеть учили на «котиках» — было-бы интересно посмотреть на стену и сумку.
К примеру стена леопардовых диванов в обучении;)






MikeLP
Хороший генератор уровней