

Чем сложнее программный продукт, чем больше он взаимодействует со сторонними системами (часто не менее сложными), тем выше вероятность сбоев в работе. Тестирование помогает найти большинство багов перед выкатыванием релиза, но иногда что-то может проскользнуть. И чтобы быстро получать подробную информацию о факте сбоя и сопутствующих условиях, в наших продуктах широко используется система отчётов. О её устройстве мы хотим сегодня рассказать.
Обычно приложения падают из-за багов или непредсказуемых действий пользователей. Чтобы понять причину падения, нужно собрать разную информацию: в каком окружении работает приложение, что сделал пользователь. В общем, данные, которые могут помочь нам решить проблему. Для этого используется система отправки отчётов о работе приложения и о фактах сбоев.

Кроме расследования причин сбоев, мы используем отчёты и для анализа поведения пользователей. Для этого мы примерно раз в три месяца инициируем анонимный сбор статистики использования наших приложений. Мы смотрим, какие функции используются чаще всего и в каких ситуациях, возникают ли у пользователей затруднения. Это помогает нам корректировать планы по развитию продуктов. Возьмём, например, Parallels Desktop. Нам интересно, сколько пользователей запускают одну виртуальную машину, две, четыре и так далее. Если у большинства одна ВМ, то очевидно, что не имеет смысла сильно оптимизировать интерфейс для использования нескольких виртуалок, и так далее.
Подробности реализации
Отчёты отправляются как автоматически при падении приложения, так и по инициативе пользователей. В них включаются логи приложения, крэш-дампы, дампы памяти, информация о конфигурации машины, иногда ещё какая-нибудь служебная информация. Всё это упаковывается в файл tar.gz, размер которого колеблется от единиц до сотен мегабайт, и отправляется на наш сервер. Здесь файл подвергается первичной обработке, в него добавляется служебная информация — IP-адрес отправителя и временная метка, — а затем файл заливается в MongoDB.
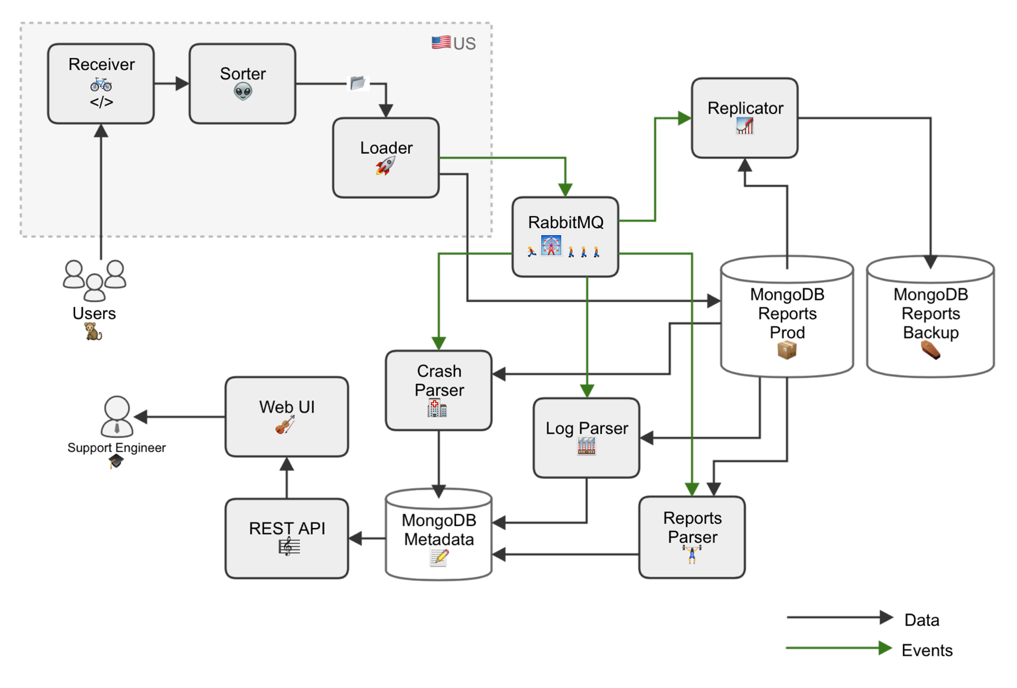
Дальше есть два варианта развития событий:
• Разработчики могут вручную проанализировать XML-файлы, логи и конфигурацию, чтобы понять, в каком окружении работает приложение и что делал пользователь
• Отчёт может быть автоматически классифицирован и включён в общую статистику
Классификация делается так: написанные на Python парсеры получают от RabbitMQ ID отчётов, залитых в MongoDB, извлекают из них state-trace, и по неким правилам присваивают текстовую метку — сигнатуру. Парсеры извлекают из XML файлов необходимые данные и складывают их в виде отдельных документов с проиндексированными полями.
Также у нас есть специальные парсеры, каждый из которых обрабатывает конкретные виды крэш-отчётов. Они проходятся по каждому отчёту и смотрят, есть ли там интересующие их файлы. Например, один парсер ищет только Mac-отчёты, другой — только Windows, и так далее. Затем они точно так же строят сигнатуру. Компоненты системы отчётов развёртываются с помощью Chef.
Общая статистика по отчётам в реальном времени отображается на специальной веб-странице, где можно сортировать данные по сигнатурам и отдельным полям. Например, по версии Mac OS, гостевой ОС и версии продукта. Это помогает быстро понять, какую проблему нужно решать в первую очередь, если количество каких-то сигнатур вдруг начинает резко расти, например, после очередного обновления.
Серверный парк
В среднем мы обрабатываем около 400 000 отчётов в месяц, 100 гигабайт. За 10 лет у нас накопилось более 50 млн разнообразных отчетов. Серверы, принимающие отчёты, расположены в США, потому что там находится большинство наших пользователей. Но хранение, обработка и анализ данных выполняются в России. Раньше иногда случалось, что отчёты поступали быстрее, чем мы успевали обработать и передать через океан. Сейчас мы уже протестировали и начали внедрять систему, использующую очереди и микросервисы для парсинга. Количество микросервисов можно менять в зависимости от текущей нагрузки, так что единственным ограничением может стать только пропускная способность канала.
Сколько серверов обслуживают нашу систему отчётов:

При необходимости любую из подсистем можно масштабировать, подстраиваясь под растущую нагрузку.

Отчёты — это не только источник подробной информации о сбоях, но и система «раннего предупреждения». Зачастую пользователи обращаются в поддержку не сразу, а лишь столкнувшись с какой-то проблемой несколько раз. Но благодаря автоматическим отчётам быстро увидим рост количества сбоев и сразу начнём решать проблему. Часто мы фиксим баг ещё до того, как в поддержку пойдёт волна обращений.
Поделиться с друзьями
Комментарии (4)

tkutru
08.12.2016 12:37Если не секрет, сколько ядер, сколько памяти на серверах? Насколько активно используется?


{kind=link}
3aicheg
Знакомьтесь, это друг упоротого лиса — укуренный пёс.