
 Привет, Хабр! Меня зовут Марко Кевац, я системный программист Badoo в команде «Платформа», и я очень люблю Go. Если сложить эти две вещи, то вы поймёте, насколько я люблю ассемблер в Go.
Привет, Хабр! Меня зовут Марко Кевац, я системный программист Badoo в команде «Платформа», и я очень люблю Go. Если сложить эти две вещи, то вы поймёте, насколько я люблю ассемблер в Go. Совсем недавно мы рассказывали на Хабре о том, на каких конференциях побывали. Одной из них была GopherCon 2016, где практически всем запомнился доклад Роба «Командира» Пайка про Go-шный ассемблер. Представляю вам перевод его доклада, оформленный в виде статьи. Я постарался дать в тексте как можно больше ссылок на релевантные статьи в «Википедии».
Ассемблер? Это что-то древнее, как мамонт!

Роб Пайк выступает на GopherCon 2016
Спасибо! Это самая воодушевлённая реакция на доклад о языке ассемблера за многие годы. Вы можете спросить: зачем нам вообще говорить об ассемблере? Причина есть, но о ней позже. Также вы можете спросить, какой интерес может представлять язык ассемблера. Давайте вернёмся в 1970 год и заглянем в руководство IBM: «Важнее всего понять следующую особенность языка ассемблера: он позволяет программисту использовать все функции компьютера System/360, как если бы он программировал на уровне машинных кодов System/360».
Во многих отношениях эти слова устарели, но основная идея по-прежнему верна: ассемблер – это способ взаимодействия с компьютером на самом базовом уровне. На самом деле, язык ассемблера необходим даже сегодня. Было время, когда в распоряжении программиста был только ассемблер.
Потом появились так называемые языки высокого уровня, например, Фортран и Кобол, которые медленно, но верно вытесняли ассемблер. Какое-то время даже язык С по сравнению с ассемблером считался высокоуровневым. Но потребность в ассемблере сохраняется и сегодня — из-за того уровня доступа к компьютеру, который он предоставляет.
Ассемблер необходим для начальной загрузки среды, для работы стеков, для переключения контекста. В Go, кстати, переключение между горутинами тоже реализовано на ассемблере. Есть ещё вопрос производительности: иногда можно вручную написать код, который работает эффективнее, чем результат работы компилятора. Например, существенная часть пакета math/big стандартной библиотеки Go написана на ассемблере, потому что базовые процедуры этой библиотеки гораздо более эффективны, если вы обходите компилятор и реализуете что-то лучше, чем сделал бы он. Иногда ассемблер нужен для работы с новыми и необычными функциями устройств или с возможностями, недоступными для более высокоуровневых языков — например, новыми криптографическими инструкциями современных процессоров.
Но для меня самое важное в языке ассемблера заключается в том, что его терминами многие люди мыслят о компьютере. Язык ассемблера даёт представление о наборах инструкций, принципах работы компьютера. Даже если вы не программируете на ассемблере — и я надеюсь, что здесь таких нет, — вам стоит иметь представление об ассемблере, просто чтобы понимать, как работает компьютер. Однако я не буду уделять слишком много внимания самому языку ассемблера, и это соответствует идее моего доклада.
Много разных и хороших ассемблеров
Многие из вас не очень хорошо знакомы с языком ассемблера. Поэтому я приведу ряд примеров, стараясь придерживаться хронологического порядка.
IBM System/360
1 PRINT NOGEN
2 STOCK1 START 0
3 BEGIN BALR 11,0
4 USING *,11
5 MVC NEWOH,OLDOH
6 AP NEWOH,RECPT
7 AP NEWOH,ISSUE
8 EOJ
11 OLDOH DC PL4'9'
12 RECPT DC PL4'4'
13 ISSUE DC PL4'6'
14 NEWOH DS PL4
15 END BEGINЭто ассемблер IBM System/360. Именно про этот компьютер была цитата в начале. Не обращайте внимания на смысл, просто взгляните.
А это – чтобы показать общую картину.
Apollo 11 Guidance Computer
# TO ENTER A JOB REQUEST REQUIRING NO VAC AREA:
COUNT 02/EXEC
NOVAC INHINT
AD FAKEPRET # LOC(MPAC +6) - LOC(QPRET)
TS NEWPRIO # PRIORITY OF NEW JOB + NOVAC C(FIXLOC)
EXTEND
INDEX Q # Q WILL BE UNDISTURBED THROUGHOUT.
DCA 0 # 2CADR OF JOB ENTERED.
DXCH NEWLOC
CAF EXECBANK
XCH FBANK
TS EXECTEM1
TCF NOVAC2 # ENTER EXECUTIVE BANK.Это – ассемблерный код для бортового управляющего компьютера корабля «Аполлон-11». Все его программы были написаны полностью на ассемблере. Ассемблер помог нам добраться до Луны.
PDP-10
TITLE COUNT
A=1 ;Define a name for an accumulator.
START: MOVSI A,-100 ;initialize loop counter.
;A contains -100,,0
LOOP: HRRZM A,TABLE(A) ;Use right half of A to index.
AOBJN A,LOOP ;Add 1 to both halves (-77,,1 -76,,2 etc.)
;Jump if still negative.
.VALUE ;Halt program.
TABLE: BLOCK 100 ;Assemble space to fill up.
END START ;End the assembly.Это ассемблер для PDP-10, и он весьма подробно прокомментирован, если сравнивать с другими примерами.
PDP-11
/ a3 -- pdp-11 assembler pass 1
assem:
jsr pc,readop
jsr pc,checkeos
br ealoop
tst ifflg
beq 3f
cmp r4,$200
blos assem
cmpb (r4),$21 /if
bne 2f
inc ifflg
2:
cmpb (r4),$22 /endif
bne assem
dec ifflg
br assemЭто фрагмент для PDP-11. Более того, это кусок кода для ассемблера в Unix v6 — который, разумеется, написан на ассемблере. Язык С стал использоваться позже.
Motorola 68000
strtolower public
link a6,#0 ;Set up stack frame
movea 8(a6),a0 ;A0 = src, from stack
movea 12(a6),a1 ;A1 = dst, from stack
loop move.b (a0)+,d0 ;Load D0 from (src)
cmpi #'A',d0 ;If D0 < 'A',
blo copy ;skip
cmpi #'Z',d0 ;If D0 > 'Z',
bhi copy ;skip
addi #'a'-'A',d0 ;D0 = lowercase(D0)
copy move.b d0,(a1)+ ;Store D0 to (dst)
bne loop ;Repeat while D0 <> NUL
unlk a6 ;Restore stack frame
rts ;Return
end
Cray-1
ident slice
V6 0 ; initialize S
A4 S0 ; initialize *x
A5 S1 ; initialize *y
A3 S2 ; initialize i
loop S0 A3
JSZ exit ; if S0 == 0 goto exit
VL A3 ; set vector length
V11 ,A4,1 ; load slice of x[i], stride 1
V12 ,A5,1 ; load slice of y[i], stride 1
V13 V11 *F V12 ; slice of x[i] * y[i]
V6 V6 +F V13 ; partial sum
A14 VL ; get vector length of this iteration
A4 A4 + A14 ; *x = *x + VL
A5 A5 + A14 ; *y = *y + VL
A3 A3 - A14 ; i = i - VL
J loop
exitЭто ассемблер для Motorola 68000, а это — для Cray-1. Этот пример мне нравится, он из диссертации Роберта Грисемеера (Robert Griesemer). Напоминает о том, как всё начиналось.

Роберт Грисемеер выступает на GopherCon 2015
Вы можете заметить, что всё это разные языки, но в чём-то они похожи: у них есть общая, очень чёткая, структура.
Инструкции
subroutine header
label:
instruction operand... ; comment
...Операнды
register
literal constant
address
register indirection (register as address)
...Программы на ассемблере обычно записываются в столбик: слева – метки, потом инструкции, операнды и, наконец, справа – комментарии. В роли операндов обычно выступают регистры, константы или адреса памяти, но синтаксически для разных архитектур они довольно похожи. Есть и исключения. Пример Cray выделяется на общем фоне: команда сложения записывается в виде символа +, как в арифметическом выражении. Но смысл везде один и тот же: вот это команда сложения, а это – регистры. То есть всё это в действительности одно и то же.
Другими словами, даже давным-давно, даже в мои времена, процессоры были примерно такими же, как сейчас. Есть контрпримеры, но большая часть процессоров (и уж точно все процессоры, на которых работает Go), по сути, остались прежними, если не обращать внимания на детали. Если не углубляться в подробности, то можно прийти к интересному выводу: для всех этих компьютеров можно составить общую грамматику. Для понимания этого факта потребовалось около 30 лет.
Гениальная идея Кена

Слева направо: Роберт Грисемеер, Роб Пайк, Кен Томпсон
Примерно в середине 1980-х годов Кен Томпсон (Ken Thompson) и я начали думать над разработкой, которая потом превратилась в Plan 9. Кен написал новый компилятор С, который лёг в основу компилятора С в инструментах Go и использовался до недавнего времени. Это было на компьютере с симметричной многопроцессорной архитектурой компании Sequent, в котором использовались процессоры National 32000. По-моему, это был первый 32-разрядный микропроцессор, доступный в широкой продаже в виде интегральной микросхемы. Но Кен сделал одну интересную штуку — её некоторые тогда не поняли, но потом она оказалась очень важной. Это вообще характерная особенность Кена.
Компилятор не генерировал машинные инструкции — он выдавал нечто вроде псевдокода. А потом вторая программа (по сути, линкер) принимала результат работы компилятора и преобразовывала эти псевдоинструкции в настоящие инструкции.
Инструкция наподобие
MOVW $0, varмогла стать просто
XORW R1, R1
STORE R1, varПриведу абстрактный пример. Есть, например, инструкция MOVW, которая помещает ноль в переменную. Выданный линкером код, который будет выполняться на компьютере, может состоять, например, из инструкций XORW, для которой в качестве обоих операндов указан один и тот же регистр (то есть она обнуляет значение регистра), и STORE, которая помещает значение этого регистра в переменную. Не беспокойтесь насчёт деталей: суть здесь в том, что инструкции, которые выполняет компьютер, могут не совсем соответствовать тому, что мы вводим в ассемблер.
Этот процесс составления реальных инструкций на основе псевдоинструкций мы называем выбором инструкций. Отличный пример псевдоинструкции — инструкция возвращения из функции, которую Кен назвал RET. Она так и называется уже 30 лет, но её реализация зависит от того, на каком компьютере она выполняется. В руководствах к некоторым компьютерам её так и называют RET, но в других это может быть переход по адресу, который содержится в регистре, или перенаправление на адрес в специальном регистре, или что-нибудь совсем другое.
Поэтому ассемблер можно считать способом записи псевдоинструкций, которые генерирует компилятор. В мире Plan 9, в отличие от большей части других архитектур, компилятор не запускает ассемблер – данные передаются непосредственно в линкер.
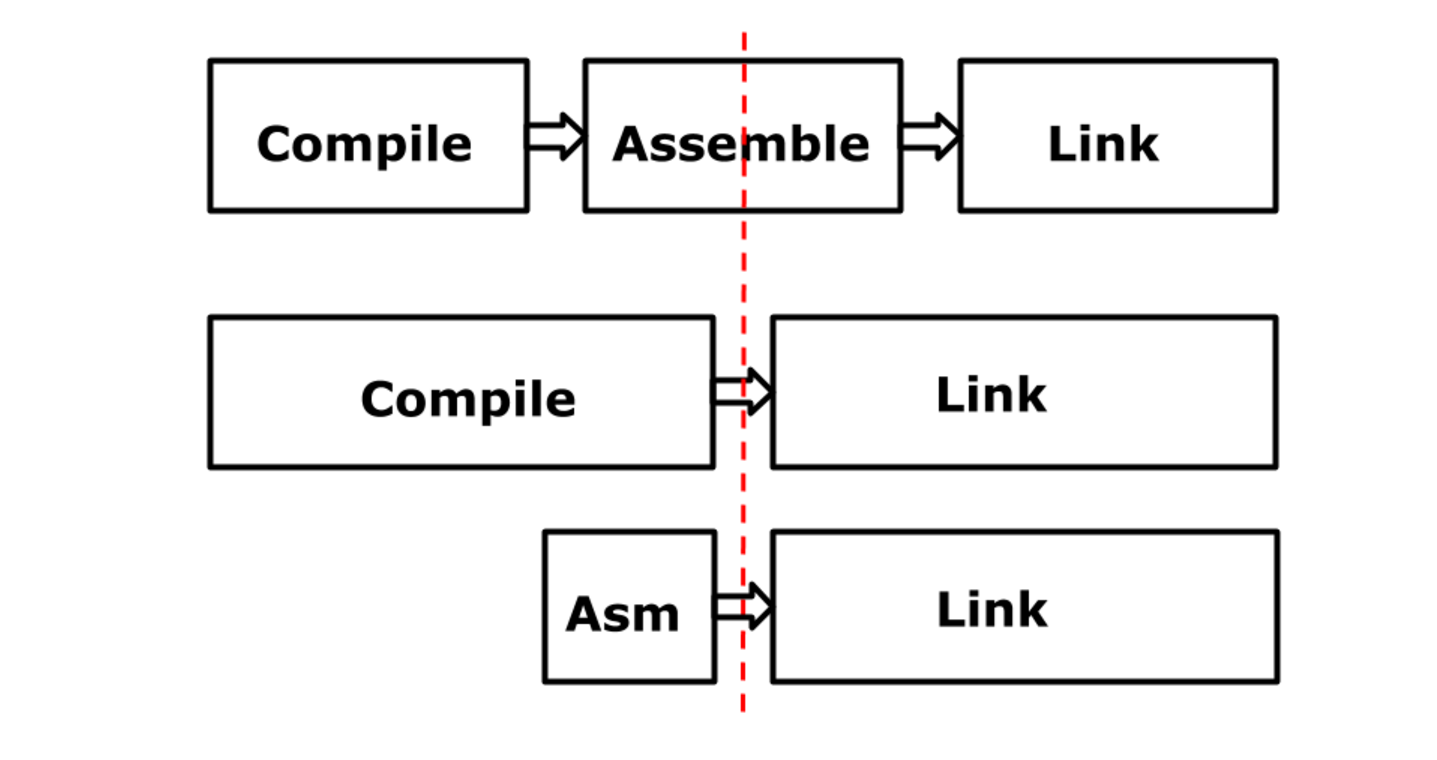
В результате процесс выглядит приблизительно так. Верхняя строчка примерно соответствует традиционным архитектурам. По-моему, GCC и сегодня работает так же. Это компилятор, он принимает высокоуровневый код и преобразует его в код на языке ассемблера. Ассемблер генерирует реальные инструкции, а линкер связывает отдельные части, создавая бинарник. Две нижние строки показывают, как обстоит дело в Plan 9. Здесь ассемблер, по сути, разделили пополам: одна половина осталась в компиляторе, а вторая – стала частью линкера. Стрелки, пересекающие красную черту, — это потоки псевдоинструкций в двоичном представлении. Ассемблер в Plan 9 служит одной цели: он предоставляет вам возможность записывать в текстовом виде инструкции, преобразующиеся в псевдоинструкции, которые обрабатывает линкер.
Ассемблер Go
Такая ситуация сохранялась много поколений. И ассемблеры Plan 9 ей соответствовали: это были отдельные программы на С с грамматикой Yacc, своей для каждой архитектуры. Они образовывали своеобразный набор или пакет, но это были отдельные, независимо написанные, программы. У них был общий код, но не совсем… В общем, всё было сложно. А потом начал появляться Go… когда это было… в 2007 году мы начали… в эту кучу программ со смешными именами добавились ещё компиляторы Go — 8g и 6g. И в них использовалась та же модель. Они соответствуют средней строчке на диаграмме. И то, как было реализовано это разделение, давало множество преимуществ для внутреннего устройства Go, но сегодня я не успею подробно об этом рассказать.

Расс Кокс выступает на GopherCon 2015
В Go 1.3 мы захотели избавиться от всего кода на С и реализовать всё исключительно на Go. Это потребовало бы времени. Но в выпуске Go 1.3 мы запустили этот процесс. Началось всё с того, что Расс (Russ Cox) взял большой кусок линкера и отделил его. Так появилась библиотека liblink, и большую её часть занимал так называемый алгоритм выбора инструкций. Сейчас эта библиотека называется obj, но тогда она называлась liblink. Компилятор использовал эту библиотеку liblink, чтобы преобразовывать псевдоинструкции в настоящие инструкции. В пользу такого решения было несколько аргументов.
Самый важный из них — ускорение процесса сборки. Даже несмотря на то, что компилятор теперь проделывает больше работы — сейчас он выбирает инструкции, тогда как раньше этим занимался линкер. Благодаря такому устройству, он проделывает это только один раз для каждой библиотеки. Раньше, если вам нужно было скомпоновать пакет fmt, например, выбор инструкций для Printf выполнялся бы каждый раз заново. Очевидно, это глупо. Теперь мы делаем это один раз, и компоновщику не приходится этим заниматься. В результате компилятор работает медленнее, но сборка в целом ускоряется. Ассемблер может быть устроен так же и может использовать библиотеку obj.
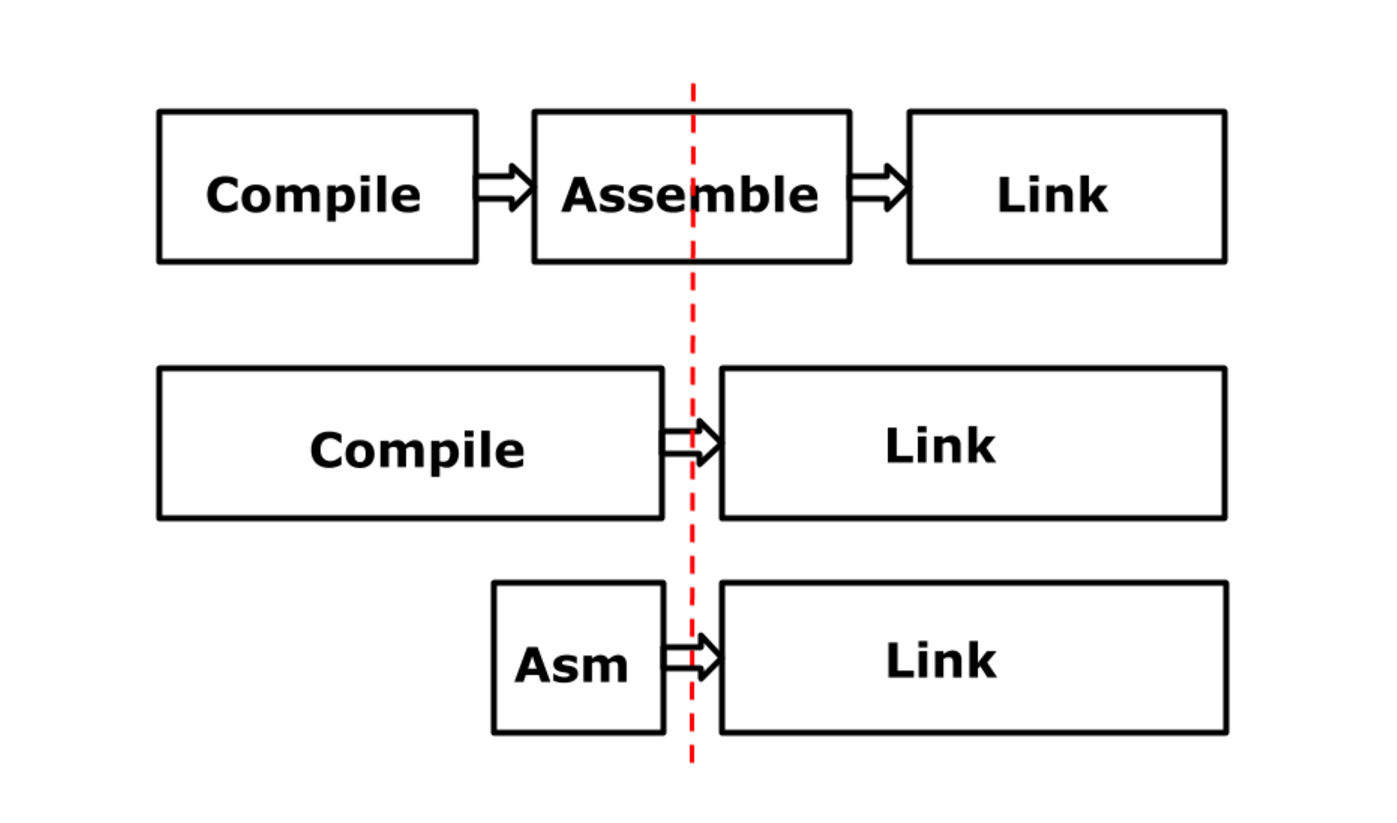
Самая важная особенность этого этапа была в том, что для пользователя ничего не изменилось: входной язык остался прежним, вывод остался прежним, это всё тот же двоичный файл, только детали другие. Вот общая схема старой архитектуры, я её уже показывал: компилятор, ассемблер, линкер. В мире Plan 9 линкером управляет компилятор или ассемблер.
Старая архитектура:
Новая архитектура:
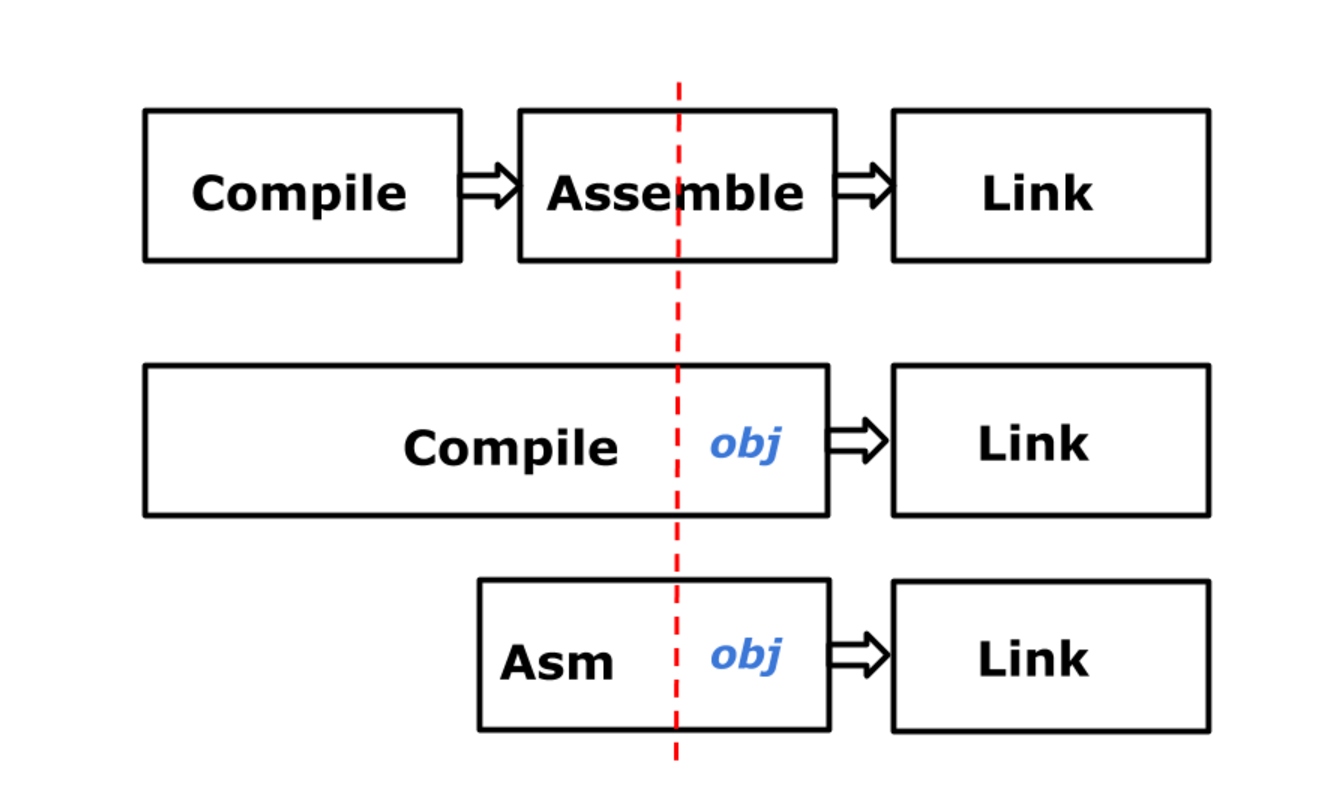
В версии 1.3 мы перешли на вот такое устройство. Как видите, теперь у нас получился намного более традиционный линкер: он получает реальные инструкции, потому что библиотека obj, которая выполняет выбор инструкций, перестала быть частью компоновщика и стала последним этапом компилятора и ассемблера. То есть теперь ассемблер и компилятор больше соответствуют старой схеме, если включить ассемблер в процесс.
Этот новый ассемблер Go — странная штука. Ничего похожего просто не существует. Что он делает? Он преобразует текстовые описания псевдоинструкций в реальные инструкции для линкера. В 1.5 мы сделали большой шаг — избавились от С. Для этого мы проделали большую подготовительную работу в 1.3 и 1.4, и теперь эта задача, наконец, решена. Расс написал транслятор, который преобразовывал старые исходники компиляторов Go (и, кстати, линкеров), написанные на С, в программы на Go.
Старая библиотека liblink была встроена в набор библиотек, который в совокупности мы здесь называем obj. В результате есть штука, которая называется obj, это портируемая часть, и подкаталоги с машиннозависимыми частями, которые хранят сведения об особенностях каждой архитектуры. Этой работе посвящено несколько докладов: это сама по себе интересная история. Два года назад Расс выступил на GopherCon с докладом, но он уже довольно устарел. В действительности мы поступили совсем не так, как он тогда рассказал. А потом на GopherFest 2015 я представил более общий, но более точный обзор изменений в версии 1.5.
GOOS=darwin GOARCH=arm go tool compile prog.goТак вот. Раньше компиляторы назывались 6g, 8g и другими странными именами. Теперь это одна программа под названием compile. Вы запускаете инструмент compile и настраиваете его, устанавливая значения стандартных переменных среды GOOS (произносится «goose», как «гусь») и GOARCH (произносится «gorch», как «пьяный похотливый парень в баре») — именно так их названия произносятся официально. Для линкера мы сделали то же самое. Есть инструмент link, вы устанавливаете значения GOOS и GOARCH – и можете компилировать свою программу. Вы можете задаться вопросом: «Как один компилятор может поддерживать все эти архитектуры? Мы-то знаем, что кроссплатформенная компиляция — это очень, очень сложно». На самом деле, нет. Вам просто нужно заранее всё подготовить. Обратите внимание вот на что: здесь есть только один входной язык — Go. С точки зрения компилятора результат работы тоже один — псевдоинструкции в двоичной форме, которые передаются в библиотеку obj. То есть нам нужно только настроить библиотеку obj, задав значения переменных на момент запуска инструмента. Скоро вы узнаете, как это делается.
Что касается ассемблера, мы выполняли машинное транслирование ассемблеров с языка С на Go, но это не идеальное решение, мне оно не нравилось. Я предложил написать на Go с нуля единственную программу, которая бы заменила их все, — asm. Настройка опять же выполнялась бы исключительно через GOOS и GOARCH. Вы можете заметить, что язык ассемблера и Go — не одно и то же. У каждого процессора есть свой набор инструкций, свой набор регистров, это не единый язык вывода. Что с этим делать? Но на самом деле, они, по сути, одинаковы. Смотрите.
package add
func add(a, b int) int {
return a + b
}Вот пример простой программы, которая складывает два целых числа и возвращает сумму. Я не буду показывать псевдоинструкции, которые выдаёт компилятор, если вы воспользуетесь флагом -S, чтобы просмотреть код на ассемблере. Ещё я убрал немало лишнего — если вы воспользуетесь этим способом, вы тоже увидите много ненужного, но на этом этапе компилятор выдаёт именно такие псевдоинструкции.
32-bit x86 (386)
TEXT add(SB), $0-12
MOVL a+4(FP), BX
ADDL b+8(FP), BX
MOVL BX, 12(FP)
RET
64-bit x86 (amd64)
TEXT add(SB), $0-24
MOVQ b+16(FP), AX
MOVQ a+8(FP), CX
ADDQ CX, AX
MOVQ AX, 24(FP)
RET
32-bit arm
TEXT add(SB), $-4-12
MOVW a(FP), R0
MOVW b+4(FP), R1
ADD R1, R0
MOVW R0, 8(FP)
RET
64-bit arm (arm64)
TEXT add(SB), $-8-24
MOVD a(FP), R0
MOVD b+8(FP), R1
ADD R1, R0
MOVD R0, 16(FP)
RET
S390 (s390x)
TEXT add(SB), $0-24
MOVD a(FP), R1
MOVD b+8(FP), R2
ADD R2, R1, R1
MOVD R1, 16(FP)
RETВот вариант для 32-разрядной архитектуры. Не задумывайтесь о деталях – просто взгляните на картину в целом. Вот результат для 64-разрядной архитектуры x86, её ещё называют AMD64, вот – для 32-разрядной архитектуры ARM, для 64-разрядной архитектуры ARM, а вот – для архитектуры IBM System/390; для нас они новые, но для всех остальных явно нет.
64-bit MIPS (mips64)
TEXT add(SB), $-8-24
MOVV a(FP), R1
MOVV b+8(FP), R2
ADDVU R2, R1
MOVV R1, 16(FP)
RET
64-bit Power (ppc64le)
TEXT add(SB), $0-24
MOVD a(FP), R2
MOVD b+8(FP), R3
ADD R3, R2
MOVD R2, 16(FP)
RETВот код для 64-разрядной архитектуры MIPS, вот – для 64-разрядной архитектуры POWER. Вы можете заметить, что они похожи. Причина в том, что они, по сути, являются одним и тем же языком. Отчасти потому, что они так устроены: по сути дела, мы 30 лет использовали ассемблер National 32000, меняя только лишь железо, на котором он использовался. Но ещё и потому, что некоторые из них действительно идентичны. Это просто инструкции, регистры, операнды, константные значения, метки — всё одно и то же. Единственное важное отличие заключается в том, что у инструкций и регистров разные имена. Ещё иногда отличаются смещения, но это зависит от размера машинного слова.
Всё это сводится к ассемблеру National 32000, который написал Кен. Это язык ассемблера National 32000, каким его себе представляет Кен, адаптированный для современного PowerPC. Таким образом, у нас есть всё необходимое — общий язык ввода, библиотека obj в бэкэнде – и мы можем писать на ассемблере. При таком подходе возникает проблема: если взять руководство National или PowerPC и взглянуть на язык ассемблера, то окажется, что он выглядит не так. У него другой синтаксис, иногда другие имена инструкций, потому что на каком-то уровне это фактически псевдоинструкции. На самом деле, это неважно.
Непосвящённого человека внешний вид ассемблера Go — все эти заглавные буквы и странные штуки — может серьёзно смутить. Но поскольку для всех этих компьютеров у нас есть общий язык ассемблера, мы можем получить замечательный результат, о котором речь пойдёт ниже. Поэтому мы считаем, что это оправданный компромисс и достигнуть его не очень сложно. Стоит научиться программировать на 68000 и на ассемблере Кена – и вы автоматически сможете писать программы для PowerPC. Какая разница?
Как же это работает? Ассемблер версии 1.5 я считаю идеалом ассемблера. Дайте ему любой компьютер – и он транслирует ассемблер для него. Это новая программа, написанная полностью на Go. В ней есть общие лексический и синтаксический анализаторы, которые просто принимают ваш входной код, всё что вы ему дадите, и преобразуют инструкции в структуры данных, описывающие инструкции в двоичной форме, а потом передают результат новой библиотеке obj, в которой содержится информация о конкретных платформах.
Большая часть кода, который лежит в основе ассемблера, полностью портируема, она не содержит ничего, никакой интересной информации об архитектурах, но там есть таблица со сведениями об именах регистров. Ещё есть несколько вещей, которые связаны с работой операндов, но там это довольно просто. И всё это настраивается при запуске программы в соответствии со значением переменной GOARCH. GOOS используется в очень, очень редких случаях, в которые мы не будем углубляться, – основные характеристики определяет GOARCH. Ещё есть внутренний пакет для ассемблера, который называется arch, он создаёт эти таблицы на лету, динамически извлекая их из библиотеки obj. А вот фрагмент настоящего кода.
import (
"cmd/internal/obj"
"cmd/internal/obj/x86"
)
func archX86(linkArch *obj.LinkArch) *Arch {
register := make(map[string]int16)
// Create maps for easy lookup of instruction names etc.
for i, s := range x86.Register {
register[s] = int16(i + x86.REG_AL)
}
instructions := make(map[string]obj.As)
for i, s := range obj.Anames {
instructions[s] = x86.As(i)
}
return &Arch{
Instructions: instructions,
Register: register,
...
}
}Он немного упрощён, но суть передаёт. Это arch, внутренний пакет ассемблера. Это процедура, которая настраивает весь ассемблер для архитектуры x86. Этот код используется и в 32-, и в 64-разрядной архитектуре, они с этой точки зрения идентичны. А потом мы просто запускаем цикл… Цикл, перебирающий имена регистров из библиотеки obj, определённой в пакете x86 для процедур obj. И мы просто настраиваем карту, которая сопоставляет имена регистров и двоичный код в соответствии с данными из obj. А потом делаем то же самое для инструкций.
Эти коды на самом деле не являются кодами инструкций, вы не найдёте их в руководстве. Это буквально алфавитный перечень всех вещей — повторю, что это лишь псевдоинструкции, а не настоящие команды. Но сейчас мы знаем все имена всех регистров и все инструкции. И описание архитектуры, которое мы вернём, содержит только эти две карты. Вот имена инструкций, которые вы знаете, вот имена регистров, которые вы знаете, и ещё немного вещей, которые я не упомянул, но там всё довольно просто. Это вся необходимая информация для того, чтобы преобразовывать язык ассемблера в инструкции для этих компьютеров. На самом деле, парсер просто проводит сопоставление строк, чтобы найти нужные инструкции. Вы в столбце 1, он содержит слово, это инструкция, ищем её в таблице инструкций. Это довольно просто.
ADDW AX, BX
&obj.Prog{
As: arch.Instructions["ADDW"],
From: obj.Addr{Reg: arch.Register["AX"]},
To: obj.Addr{Reg: arch.Register["BX"]},
...
}Вот пример. Это инструкция «добавить слово» (ADDW) для процессора 386, которую вы можете использовать в реальном коде или обнаружить в выводе компилятора. Она выглядит так: ADDW AX, BX. Ассемблер знает, что в первом столбце содержится инструкция. Всё, что он делает, — проводит поиск по списку инструкций, который содержится в структуре для архитектуры, индексирует карту по ADDW и получает код. Он помещает его в величину с именем A — странное название, но уж какое есть. Далее идут источник и приёмник, два операнда. То же самое — ищем регистр AX, ищем регистр BX. На самом деле, всё немного сложнее, но смысл такой: вы просто ищете слова, которые подаются на вход, помещаете их в структуру данных и передаёте библиотеке obj. Суть в том, что это просто обработка текста. Всё, что делает ассемблер, — обрабатывает текст. Он ничего не знает о семантике архитектуры этих устройств.
Ещё он должен выполнить проверки, убедиться, что результат лексически и синтаксически корректен. Это легко осуществляется стандартными методами анализа. То есть ассемблер анализирует, например, операнды, на своём ли они месте… Там есть несколько ухищрений и некрасивых специальных случаев, потому что в некоторых компьютерах используются странные режимы операндов, которых нет в других, но и их достаточно просто применить. Это не проблема.
Самое важное здесь то, что все семантические проверки выполняет библиотека obj. Базовое правило здесь такое: если структура, которая описывает инструкцию, передаётся в библиотеку obj, и та обрабатывает её без ошибок, причина в том, что библиотека obj знает, как преобразовать её в инструкцию для физического компьютера. Поэтому если код парсится, а библиотека obj его обрабатывает, то всё готово. Это вся идея.
Она, очевидно, безумна, но работает, и мы можем доказать это на практике. Тестирование мы проводили так. Помните, у нас были старые ассемблеры, они были написаны на С, и мы буквально брали программы… я написал ассемблер и библиотеку obj для него, мы объединили их, а потом взяли программу и собирали её с помощью старого ассемблера и нового. И мы повторяли это снова и снова, пока новый ассемблер не выдал то же, что и старый, с точностью до мельчайших частей. А потом мы взяли следующую программу. К тому времени, как мы обработали весь стандартный пакет, у нас был рабочий ассемблер. Вот, в общем-то, и всё. Такое A/B-тестирование — превосходный способ проводить подобные проверки. Оно сработало просто отлично.
Вначале я провёл его для 386, потом – для AMD64. Для каждой архитектуры был ряд особых случаев, но со временем ситуация улучшалась. К тому моменту, как мы добрались до PowerPC, добавление в ассемблер поддержки этой новой архитектуры заняло пару часов – настолько это было просто. Самой удивительной и, на мой взгляд, самой интересной особенностью этой работы было то, что при написании ассемблера с поддержкой этих четырёх архитектур я не заглянул ни в одно руководство к аппаратной платформе. Эта задача сводится исключительно к обработке текста на основе того факта, что вся нужная информация хранится в библиотеке obj, поэтому мне просто незачем всё это знать.
По-моему, это довольно круто. Так вот, в итоге у нас теперь есть одна программа на Go, которая заменяет кучу разных программ на С и Yacc. Поддерживать одну программу намного проще, чем несколько. Исправлять ошибки в одной программе тоже гораздо проще. Программа написана на Go, поэтому её можно должным образом тестировать, что хорошо. Она зависит от библиотеки, от которой зависит всё, то есть правильность обеспечивается почти автоматически, и это отлично. Я преувеличил, но в целом это так. И у нас есть новый ассемблер, который практически идеально совместим со всеми старыми. Области несовместимости по большей части соответствуют различиям между ассемблерами и небольшим особенностям работы разных штук. Но сейчас всё полностью унифицировано. Мы создали действительно универсальный язык ассемблера для всех этих платформ. И портируемость обеспечивается очень просто.
Я показал, кажется, все архитектуры, которые он сейчас поддерживает, когда мы просматривали те примеры функции сложения, и многие из них были созданы людьми из open-source-сообщества. Если вы зайдёте в репозиторий Git и взглянете на коммиты, которые добавляют эти новые архитектуры, то увидите, что объём информации, необходимый для поддержки нового компьютера, в действительности очень небольшой. Это здорово. По-моему, это говорит в пользу выбранного подхода. Мне приятно видеть, с какой лёгкостью open-source-сообщество добавляет новые архитектуры.
Как я говорил, ассемблер настраивается путём загрузки, по сути, таблиц, известных библиотеке obj и представляющих архитектуру компьютера. Таблицы ведь можно генерировать? Мне не нравится писать таблицы от руки. На самом деле, не совсем так, но… дизассемблеры — я рассказываю не про них, но их использует инструмент pprof, и некоторые другие компоненты — по-моему, их все, или, по крайней мере, значительную их часть, создал Расс одним тоскливым днём. Он тогда написал программу, обрабатывающую описание инструкций в формате PDF и преобразующую его в битовые шаблоны, которые нужны для кодирования инструкций. У нас есть описание компьютера, которое компьютер может прочитать, — почему бы не прочитать его компьютером? В результате дизассемблеры были сгенерированы на компьютере. В другом направлении всё это не так просто, там есть свои особенности. Прежде всего такое преобразование должно быть абсолютно точным. Если дизассемблер ошибётся, это не страшно.
Отсутствие ошибок — это приятно, но особые случаи не очень важны. А вот в другом направлении результат должен быть абсолютно точным. Поэтому такая задача намного сложнее. Но Расс работает над ней. Я надеялся, что к сегодняшнему дню она будет решена, но пока не удалось. Однако я надеюсь, что к концу года вы сможете дать нам PDF с описанием инструкций новой архитектуры, мы нажмём на кнопку – и вернём вам рабочий ассемблер. Цель здесь именно такая.
Это значит, что у нас есть ассемблер, большей частью сгенерированный на компьютере, по крайней мере, после завершения предварительной ручной работы.
Заключение
В заключение скажу вот что. Язык ассемблера везде по сути одинаков, несмотря на то, что некоторые утверждают обратное. И в области портируемости мы дошли до того, что именно таким его надо считать. На основе этих идей мы можем создать подлинно общий язык ассемблера, который позволит говорить с компьютером на самом базовом уровне, но не учить для этого каждый раз новый синтаксис и не осваивать новый инструмент. Если у вас есть такая единая среда, с которой аккуратным и прозрачным образом взаимодействуют компилятор и линкер, писать на ассемблере намного проще. Этого можно добиться путём динамической загрузки таблиц, автоматически составленных на основе пары переменных среды. Они необходимы — печально, но это так. И однажды — надеюсь, ещё в этом году — мы сможем создавать эти таблицы для архитектур автоматически. Как видите, мы взяли язык ассемблера, который часто относят к наименее портируемым вещам, и создали для него портируемое решение.
Это и есть путь Go. Спасибо.
Комментарии (33)
Vjatcheslav3345
21.12.2016 14:35А в компиляторы С можно перенести новую архитектуру ассемблера?

mkevac
21.12.2016 14:39Теоретически, думаю, безусловно можно. Таким же способом, как делается (собираются делать) для Go. Но я не слышал о том, что кто-то это делает.

Varim
21.12.2016 15:14Статья понравилась, спасибо.
Интересно в чем принципиальная разница между GO ASM, .NET CIL, JVM кодом и LLVM кодом, помимо регистровой/стековой направленности?
Дело в удобстве? В том смысле «это сделано не нами», а у нас мы легко и быстро поправим генерацию под любой CPU?
Duduka
21.12.2016 17:21JVM, NET, LLVM объектные файлы, после генерации кода компилятором, проходят(могут) этап оптимизации, что упрощает разработку компиляторов, в отличии от описанного случая, в котором все CPU подгоняются под одну «гребенку», а компилятор — «один на всех, и за ценной не постоим», очень прозорливое решение, позволяющие не заботится поддержке зоопарка, например тех же x86 с их таймингами, разным количеством исполнительных блоков. Куда интереснее вопрос, был ли в NS32000 SIMD и графический сопроцессор?!
Varim
21.12.2016 17:36+1x86 с их таймингами, разным количеством исполнительных блоков
Зачем тайминги в ассемблере, ни разу завязку на тайминги не видел, это же не real time OS и если не параллельное исполнение команд, то какая разница сколько исполнительных блоков…
qw1
21.12.2016 23:19Есть несколько способов достичь одного результата.
Компилятор должен выбрать, что быстрее — инструкция сдвига влево на N разрядов, илиadd eax,eax, повторённый N раз, или конструкции типаlea eax, [eax*8].
Причём на разных процессорах в пределах линейки x86 предпочительные инструкции разные, отсюда и проблема зоопарка.Varim
22.12.2016 03:38Спасибо.
«Есть несколько способов достичь одного результата.» — мне казалось это количество тактов инструкции.
Тайминг это наверное все же реальное время.
Duduka наверно имел ввиду количество тактов.Duduka
22.12.2016 12:09+1Все куда печальнее, выбор инструкций зависит не только от количества тактов (большинство регистровых инструкций выполняются за один такт или меньше, часто — несколько инструкций исполняется одновременно), но от распараллеливаемости потока инструкций (блок исполнения в последних моделях имеет достаточную свободу в последовательности исполнения, а не только спаривание, как в MMX), и раскрутка цикла не всегда приводит к росту производительности (инструкции из предыдущей итерации или инициализации процедуры, цикла могут останавливать исполнение). Так же бутылочным горлышком являются кэши(и необходимость их прогрева, и трюка с предвыборкой в кэш, увеличивающий затраты по тактам, но дающие выигрыш по таймингам на некоторых архитектурах или проигрышу на других), а тайминги выборки из ОЗУ от процессора практически не зависят (вернее сам процессор подстраивается), поэтому на топовых чипсетах с топовой памятью в режимах с минимальными циклами управления, даже слабенький по частоте процессор показывал приемлемый результат на коде интенсивно работающем с ОЗУ, в то время как топовый на «устаревшей» ОЗУ работал как с половинной частотой, недогружая конвеер команд и забивая шину доступом к ОЗУ. Как результат, используется трюк — перевычисление значений, лишь бы не лезть в память можно тратить такты.
Поэтому, выбор только по тактам приемлемых последовательностей инструкций, подставляемых компилятором, после i8086, представляется «неумным», в топовых компиляторах предоставляются ключи выбора типа процессора, и системы SIMD команд, меняющих генерируемый код(оптимизируется под конкретное устройство), в котором (по идее) все последствия учтены, что не факт, например компиляторы MS достаточно долго были заточены на генерацию кода под i386, и на пентиумах исполнялись очень-очень не оптимально, из-за не учета спаривания инструкций и предсказания переходов (и ядра выходили с оптимизацией под i386, но это не факт, что очень плохо, например gentoo-пользователи оптимизировали всю OS тотально, и получали несколько процентов прироста или никакого, сам компилятор накладывал ограничения — падал или генерировал некорректный код). В общем, интел создал систему «интегральных костылей», а компиляторы должны по сложности приближаться к искусственному интеллекту(или не должен,… как выше в топике описан), чтобы один «костыль» не блокировал другой.

rkfg
21.12.2016 15:49+7Хмм… всё это хорошо, конечно, но такой код вряд ли будет высокопроизводительным. По сути, универсальный ассемблер — это «наибольший общий делитель» всех архитектур. Но каждая платформа имеет свои особенности, а x86/amd64, в частности, большое количество дополнительных инструкций, позволяющих в разы ускорить вычисления. Взять хотя бы эту статью. Как я понял, Go никак не стремится использовать эти расширения, т.к. они не кроссплатформенны.

mekegi
21.12.2016 20:41+1rkfg
21.12.2016 21:24+3Здесь говорится о более компактном и эффективном коде, но я не вижу ничего касающегося платформозависимых оптимизаций. Полагаю, что компактность и эффективность опять же относится к общим для всех платформ оптимизациям (это хорошо, конечно). Потому что находить возможности для применения векторных инструкций, судя по приведённой мной ссылке на статью, не так-то просто. А если это делается, то смысл уже этой статьи ускользает от меня.
Скажем, если на какой-то платформе отсутствует инструкция умножения или деления (например, на микроконтроллерах), то либо придётся делать для этой платформы хак в виде сложений/сдвигов, либо делать хак в виде одной инструкции умножения для платформ, где оно есть, либо везде использовать сложения/сдвиги. И судя по вот этой статье будет применяться именно последний вариант.
creker
21.12.2016 23:39+1Оптимизации для конкретных архитектур есть. В том числе использование наборов инструкций, которых нет у других. Например, AES написан с помощью соответствующий инструкций под x86. Для других архитектур реализация уже на обычном Go
rkfg
22.12.2016 00:08+2Есть ещё вопрос производительности: иногда можно вручную написать код, который работает эффективнее, чем результат работы компилятора. Например, существенная часть пакета math/big стандартной библиотеки Go написана на ассемблере, потому что базовые процедуры этой библиотеки гораздо более эффективны, если вы обходите компилятор и реализуете что-то лучше, чем сделал бы он. Иногда ассемблер нужен для работы с новыми и необычными функциями устройств или с возможностями, недоступными для более высокоуровневых языков — например, новыми криптографическими инструкциями современных процессоров.
Вы имеете в виду вот это? Тут нет ничего удивительного, конечно же, стандартную библиотеку оптимизируют вручную для разных архитектур, если есть такая возможность. Но речь шла о компиляторе, который компилирует пользовательский код. В этом случае он тоже сумеет автоматически, без помощи разработчика, использовать расширенный набор инструкций, присущий целевой платформе?
creker
22.12.2016 00:16Рантайм компилируется ровно тем же самым компилятором, который и для пользовательского кода. Поэтому тут разницы никакой.
Я говорил вот про этот пакет https://github.com/golang/go/tree/master/src/crypto/aes Как видите, для оптимизации под конкретные архитектуры используется соответствующий постфикс. Похожий подход используется в Go во многих местах. _test.go файлы означают тесты и компилируют отдельно от остального кода. Помимо архитектур в постфиксе можно указать операционную систему, чтобы использовать их уникальные особенности. Например вот так https://github.com/golang/go/tree/master/src/osrkfg
22.12.2016 00:24+5Это и есть ручная оптимизация — под каждую платформу код пишется на ассемблере с учётом особенностей этой платформы. Я же говорил про оптимизацию компилятором, как это делает GCC или clang. AES вряд ли соптимизирует, это уж слишком мощное распознавание должно быть, но SSE/AVX применяются автоматически, разработчик же продолжает писать на C или C++, никак не вникая в ассемблер и не подсказывая компилятору. Т.к. эти векторные инструкции (вроде как) недоступны, например, на ARM, там GCC скомпилирует код без них, используя стандартные возможности. Я полагаю, что Go так не умеет, и только об этом и говорил. А использовать интринсики или напрямую ассемблерный код, конечно, можно во многих языках и компиляторах, но это неинтересно в рамках данной темы.
creker
22.12.2016 00:47+1Да, не так понял. Насчет этого уже не знаю точно, но заглянул в компилятор. Судя по этому https://github.com/golang/go/blob/master/src/cmd/compile/internal/ssa/gen/AMD64Ops.go, поддержка SSE по крайней мере есть. Регистры и инструкции упоминаются. Вот в ARM уже NEON инструкций и регистров не видно.

Solopov
21.12.2016 22:30+1Кусок на asm ibm360 вызвал ностальгию, на yем лабы в универе делал. Правда это уже было после pdp-11, z80,, masm, tasm и т.д.
Fortop
21.12.2016 23:36+1Кто вник в детали сильнее?
Чем их "изобретение" отличается от классических
https://en.m.wikipedia.org/wiki/Object_filemkevac
21.12.2016 23:56Ммм… Например тем что в object file машинный код уже, а статья про более ранний этап «универсального» ассемблера.
Fortop
22.12.2016 00:09+1Это очевидно.
Но чем некий машинный код (который почти ассемблер) отличается от некоего «универсального» ассемблера (читай ассемблера некой виртуальной машины)…
Вот это мне не очевидно.
И на LLVM чуть ниже сосласлись совершенно справедливо.
В общем пока мне идеология непонятна. Написали потому что «захотелось» такое же, но с перламутровыми пуговицами (на Го).creker
22.12.2016 00:27-1Отчасти да. Go старается не зависеть от других и в этом его огромный плюс. Это цельный набор инструментов полностью на Go, который берется из одного репозитория и компилируется за считанные секунды. Да, можно было LLVM взять и много чего еще, но все это значит зависеть и поддерживать огромные проекты, которые развиваются самостоятельно, а Go все таки хочется развивать разработчикам самостоятельно и, по сути, в изоляции. LLVM скорее всего дал был Go намного лучший оптимизатор (хотя и комплектный сейчас развивается вполне хорошо), но цена этого была для команды слишком высока. У них даже был C компилятор изначально, но и его они полностью перенесли на Go. Они потеряли в производительности, но цели были совсем другие. Об этом, кстати, тоже был отдельный доклад.
vagran
21.12.2016 23:39+4Не совсем понимаю, зачем нужно было городить свои ассемблеры, если уже есть готовое и проверенное решение в виде LLVM IR.
creker
21.12.2016 23:49+1Тем, что им с самого начала не хотелось тащить в проект огромный LLVM. Им нужен был простой тулчей полностью на Go, а LLVM это, как минимум, головная боль со сборкой, модификацией и поддержкой такого огромного проекта. Все таки рантайм Go имеет много своих особенностей, о которых нужно знать компилятору, и просто допилить фронтеэнд и взять все остальное готовое не получилось бы в любом случае. Ну и весь Go собирается за считанные секунды, чего не скажешь об LLVM. Это тоже было очень важно. Теперь, оглядываясь назад на это решение, вряд ли многие программисты на Go скажут, что это было ошибкой. По крайней мере, ни разу не видел даже намеков на какие-то предложения попробовать приладить что-то другое.
mkevac
21.12.2016 23:54+1Два из трех изначальных разработчиков Go имели за собой огромный багаж накопленного. И ассемблеры и компиляторы. И идеи как их развивать.
Возможно Go на LLVM работал бы даже лучше, но мы этого не узнаем…

imanushin
22.12.2016 19:56-3Как минимум — фатальный недостаток.
К тому же в свое решение вносить изменения намного легче, плюс улучшая его ты помогаешь именно себе, а не всем (что выгодно корпорации).
Это та же причина, почему Microsoft .Net имеет свой runtime, вместо того, чтобы переиспользовать от Java в свое время.
mkevac
В тему доклада новость свежайшая: intel выложили machine readable описание инструкций для X86. Russ Cox уже потирает ручки.
sleeply4cat
а что это?
mkevac
В докладе выше говорится о том что скоро можно будет давать PDF описание архитектуры и утилита сама сделает ассемблер для нее. Для этого требуется парсить более-менее человеческий язык и всякие таблички из PDF. А тут вот Intel выложила описание, которое с самого начала предназначено для чтения программой.