

Привет. Меня зовут Марко, и я системный программист в Badoo. Я очень люблю досконально разбираться в том, как работают те или иные вещи, и тонкости работы разделяемых библиотек в Linux не исключение. Я представляю вам перевод именно такого разбора. Приятного чтения.
Я уже описывал необходимость специальной обработки разделяемых библиотек во время загрузки их в адресное пространство процесса. Если кратко, то, когда линкер создает разделяемую библиотеку, он заранее не знает, в каком месте в памяти она будет загружена. Из-за этого делать ссылки на данные и код внутри библиотеки проблематично: непонятно, как создавать ссылку, чтобы она указывала в правильное место после того, как библиотека будет загружена.
В Linux и в ELF существует два главных способа решить эту проблему:
- Релокация во время загрузки (load-time relocation).
- Код, не зависящий от адреса (position-independent code (PIC)).
Релокацию во время загрузки мы уже рассмотрели. А сейчас рассмотрим второй подход – PIC.
Изначально я планировал рассказывать и о x86, и о x64 (также известной как x86-64), но статья всё росла и росла, и я решил, что нужно быть более практичным. Так что в этой статье я расскажу только о x86, а о x64 речь пойдёт в другой (я надеюсь, гораздо более короткой). Я взял более старую архитектуру x86, так как в отличие от x64 она разрабатывалась без учета PIC, и реализация PIC в ней чуть более сложная.
Проблемы релокации во время загрузки
Как мы увидели в предыдущей статье, релокация во время загрузки – очень простой и прямолинейный метод. И он работает. Но PIC гораздо более популярен на данный момент и является рекомендуемым способом создания разделяемых библиотек. Почему, спросите вы?
У релокации есть несколько проблем: она занимает время и секция text (содержащая машинный код) уже не подходит для разделения между процессами.
Поговорим сначала про проблему производительности. Если библиотека была слинкована с информацией о символах, требующих релокации, то сама релокация при загрузке займёт некоторое время. Вы можете подумать, что это время не должно быть продолжительным, ведь загрузчику не нужно пробегать по всему исходному коду – достаточно пройтись по этим самым символам. Но в случае если какая-то сложная программа загружает несколько больших библиотек, то оверхед очень быстро накапливается – и в результате мы получаем вполне заметную задержку при старте программы.
Ну, и несколько слов про проблему невозможности расшарить text-секцию. Она несколько серьёзнее. Одна из главных задач существования разделяемых библиотек – сэкономить на памяти. Некоторые библиотеки используются несколькими приложениями одновременно. Если text-секция (где находится машинный код) может быть загружена в память только один раз (и затем добавлена в другие процессы с помощью mmap), то можно сэкономить довольно большое количество оперативной памяти. Но это невозможно при использовании релокации, так как text-секция должна быть изменена во время загрузки, чтобы подставить правильные указатели для конкретного процесса. Получается, для каждого процесса, использующего библиотеку, приходится держать полную копию этой библиотеки в памяти [1]. Никакого разделения не происходит.
Более того, держать text-секцию с правами на запись (а она должна быть с правами на запись, чтобы загрузчик мог подкорректировать ссылки) – плохо с точки зрения безопасности. Сделать эксплоит в этом случае гораздо легче.
Как мы увидим далее, PIC практически полностью решает эти проблемы.
Введение
Идея, которая стоит за PIC, очень проста – добавление в код промежуточного слоя для всех ссылок на глобальные объекты и функции. Если по-умному использовать некоторые артефакты процессов линковки и загрузки, можно сделать раздел text действительно не зависящим от адреса, куда его положат; мы сможем отобразить сегмент с помощью mmap на самые разные адреса в адресном пространстве процесса, и нам не понадобится изменять в нём ни один бит. В следующих нескольких разделах я покажу, как можно этого достичь.
Ключевая идея №1. Смещение между секциями text и data
Одна из ключевых идей, на которых основывается PIC, – смещение между секциями text и data, размер которого известен линкеру во время линковки. Когда линкер объединяет несколько объектных файлов, он собирает их секции вместе (к примеру, все секции text объединяются в одну большую секцию text). Таким образом, линкеру известны и размеры секций, и их относительное расположение.
Например, сразу за секцией text может следовать секция data, и в этом случае смещение от любой инструкции из секции text до начала секции data будет равняться размеру секции text минус смещение до данной инструкции от начала секции text. И все эти размеры и смещения известны линкеру.
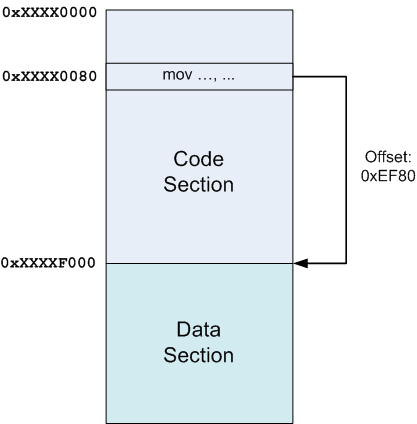
На диаграмме выше секция code была загружена по некоторому адресу (неизвестному нам на момент линковки) 0xXXXX0000 (иксы буквально означают «всё равно, что там»), а секция data – сразу после нее по адресу 0xXXXXF000. В этом случае, если какая-то инструкция по смещению 0x80 в секции code захочет указать на что-то в секции data, линкер знает относительное смещение (0xEF80 в данном случае) и может добавить его в инструкцию.
Заметьте, что ничего не изменится, если другая секция будет замаплена между секциями code и data или если секция data будет расположена до секции code. Поскольку линкер знает размеры всех секций и решает, куда их положить, идея остаётся неизменной.
Ключевая идея №2. Делаем так, чтобы смещение относительно IP работало на x86
Всё, о чём было рассказано выше, работает, если мы вообще можем воспользоваться относительными смещениями. Ведь ссылки на данные (например, как в инструкции MOV) на x86 требуют абсолютные адреса. Так что же нам делать?
Если у нас есть относительный адрес, а нужен абсолютный, нам не хватает значения указателя команд, или счётчика команд (instruction pointer – IP). Ведь по определению относительный адрес относителен по отношению к IP. На x86 не существует инструкции для получения IP, но мы можем воспользоваться простой хитростью. Вот небольшой ассемблерный псевдокод, который её демонстрирует:
call TMPLABEL
TMPLABEL:
pop ebxЧто здесь происходит:
- Процессор выполняет инструкцию call TMPLABEL, которая сохраняет адрес следующей инструкции на стеке (pop ebx), а затем прыгает на лейбл.
- Поскольку инструкцией у лейбла является pop ebx, она выполняется следующей. Эта инструкция вытаскивает значение со стека в ebx. Но это и есть адрес самой инструкции. Так что ebx, по сути, теперь содержит значение IP.
Глобальная таблица смещений (GOT)
Теперь у нас есть всё, чтобы, наконец, рассказать о том, как реализована не зависящая от позиции адресация на x86. А реализована она с помощью глобальной таблицы смещений (global offset table или GOT).
GOT – это просто таблица с адресами, которая находится в секции data. Предположим, что какая-то инструкция в секции code хочет обратиться к переменной. Вместо того, чтобы обратится к ней через абсолютный адрес (который потребует релокации), она обращается к записи в GOT. Поскольку GOT имеет строго определённое место в секции data, и линкер знает о нём, это обращение тоже является относительным. А запись в GOT уже содержит абсолютный адрес переменной:
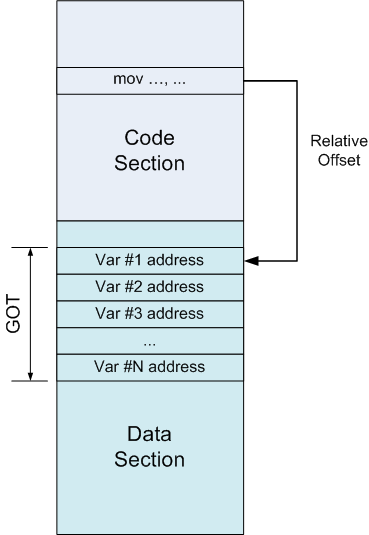
В псевдоассемблере это будет выглядеть как замена абсолютной адресации.
// Положим значение переменной в edx
mov edx, [ADDR_OF_VAR]на адресацию через регистр и небольшую прокладку:
Каким-то образом найдём адрес GOT и положим его в ebx:
lea ebx, ADDR_OF_GOT
Предположим, адрес переменной (ADDR_OF_VAR) находится по смещению 0x10 в GOT. В этом случае следующая инструкция положит ADDR_OF_VAR в edx:
mov edx, DWORD PTR [ebx + 0x10]
Наконец, обратимся к переменной и положим её значение в edx:
mov edx, DWORD PTR [edx]
Таким образом мы избавились от релокации в секции code путём перенаправления обращений через GOT. Но мы также создали релокацию в секции data. Почему? Потому что GOT в любом случае должна содержать абсолютный адрес переменной, чтобы вышеописанная схема работала. Так где же профит?
А профита, оказывается, много. Релокация в data-секции сопряжена с гораздо меньшим количеством проблем, чем релокация в секции code. Этому есть две причины, соответствующие двум проблемам, возникающим при релокации во время загрузки.
- Релокации в секции code необходимы для каждого обращения к переменной, тогда как релокации в GOT – всего лишь для каждой переменной. Обращений к переменным обычно заметно больше, чем переменных, так что это более эффективно.
- Секция data уже доступна для записи и не расшарена между процессами, так что релокации в ней ничему не вредят. А вот тот факт, что в секции code больше не будет релокаций, позволяет сделать эту секцию доступной только для чтения и расшарить её между процессами.
PIC с обращениями через GOT (пример)
Сейчас я покажу полноценный пример, который демонстрирует механику PIC:
int myglob = 42;
int ml_func(int a, int b)
{
return myglob + a + b;
}Этот блок кода будет скомпилирован в разделяемую библиотеку (используя флаги -fpic и -shared) libmlpic_dataonly.so.
Давайте посмотрим, что сгенерировал компилятор, фокусируясь на функции ml_func:
0000043c <ml_func>:
43c: 55 push ebp
43d: 89 e5 mov ebp,esp
43f: e8 16 00 00 00 call 45a <__i686.get_pc_thunk.cx>
444: 81 c1 b0 1b 00 00 add ecx,0x1bb0
44a: 8b 81 f0 ff ff ff mov eax,DWORD PTR [ecx-0x10]
450: 8b 00 mov eax,DWORD PTR [eax]
452: 03 45 08 add eax,DWORD PTR [ebp+0x8]
455: 03 45 0c add eax,DWORD PTR [ebp+0xc]
458: 5d pop ebp
459: c3 ret
0000045a <__i686.get_pc_thunk.cx>:
45a: 8b 0c 24 mov ecx,DWORD PTR [esp]
45d: c3 retЯ буду указывать на адрес инструкций (самое левое число в выводе). Этот адрес – это смещение от того адреса, на который была замаплена библиотека.
- На 43f адрес следующей инструкции кладётся в ecx тем самым способом, который был описан выше в разделе «Ключевая идея №2».
- На 444 известное смещение от инструкции до GOT кладётся в ecx. Таким образом, ecx теперь служит указателем на GOT.
- На 44a берётся значение из [ecx — 0x10], являющееся записью из GOT, и кладётся в eax. Это адрес переменной myglob.
- На 450 мы уже берём значение myglob и кладём в eax.
- Далее параметры a и b прибавляются к myglob, и значение возвращается (таким образом, что мы оставляем его в eax).
Также с помощью readelf -S можно узнать, куда линкер положил GOT:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
<snip>
[19] .got PROGBITS 00001fe4 000fe4 000010 04 WA 0 0 4
[20] .got.plt PROGBITS 00001ff4 000ff4 000014 04 WA 0 0 4
<snip>Давайте достанем калькулятор и проверим компилятор. Ищем myglob. Как я уже упоминал выше, вызов __i686.get_pc_thunk.cx кладёт адрес следующей инструкции в ecx. Это 0x444 [2]. Следующая инструкция прибавляет к нему 0x1bb0 – и в результате в ecx мы получим 0x1ff4. Наконец, чтобы получить элемент GOT, который содержит адрес myglob, делаем [ecx — 0x10]. Элемент, таким образом, имеет адрес 0x1fe4, и это первый элемент в GOT, согласно заголовку секции.
Почему там ещё одна секция, имя которой начинается с .got, я расскажу позже [3]. Заметьте, что компилятор решил положить в ecx адрес после GOT, а затем использовать отрицательное смещение. Это нормально, если в конечном итоге всё сходится. И пока что всё сходится.
Но есть одна вещь, которой нам пока не хватает. Как именно адрес myglob оказывается в элементе GOT по адресу 0x1fe4? Вспомните, что я упоминал релокацию, так что давайте её найдём:
> readelf -r libmlpic_dataonly.so
Relocation section '.rel.dyn' at offset 0x2dc contains 5 entries:
Offset Info Type Sym.Value Sym. Name
00002008 00000008 R_386_RELATIVE
00001fe4 00000406 R_386_GLOB_DAT 0000200c myglob
<snip>Вот она, релокация для myglob, указывающая на адрес 0x1fe4, как мы и ожидали. Релокация имеет тип R_386_GLOB_DAT, который просто говорит загрузчику: «Положи реальное значение симпола (то есть его адрес) по данному смещению». Теперь всё понятно. Осталось только посмотреть как, это всё выглядит при загрузке библиотеки. Мы можем это сделать, создав простой бинарник (driver), который линкуется к libmlpic_dataonly.so и вызывает ml_func, и запустив его через gdb.
> gdb driver
[...] skipping output
(gdb) set environment LD_LIBRARY_PATH=.
(gdb) break ml_func
[...]
(gdb) run
Starting program: [...]pic_tests/driver
Breakpoint 1, ml_func (a=1, b=1) at ml_reloc_dataonly.c:5
5 return myglob + a + b;
(gdb) set disassembly-flavor intel
(gdb) disas ml_func
Dump of assembler code for function ml_func:
0x0013143c <+0>: push ebp
0x0013143d <+1>: mov ebp,esp
0x0013143f <+3>: call 0x13145a <__i686.get_pc_thunk.cx>
0x00131444 <+8>: add ecx,0x1bb0
=> 0x0013144a <+14>: mov eax,DWORD PTR [ecx-0x10]
0x00131450 <+20>: mov eax,DWORD PTR [eax]
0x00131452 <+22>: add eax,DWORD PTR [ebp+0x8]
0x00131455 <+25>: add eax,DWORD PTR [ebp+0xc]
0x00131458 <+28>: pop ebp
0x00131459 <+29>: ret
End of assembler dump.
(gdb) i registers
eax 0x1 1
ecx 0x132ff4 1257460
[...] skipping outputДебаггер вошёл в ml_func и остановился на IP 0x0013144a [4]. Мы видим, что ecx имеет значение 0x132ff4 (адрес инструкции плюс 0x1bb0). Заметьте, что в данный момент, во время работы, это всё абсолютные адреса – библиотека уже загружена в адресное пространство процесса.
Так, элемент GOT с myglob должен быть на [ecx — 0x10]. Давайте проверим:
(gdb) x 0x132fe4
0x132fe4: 0x0013300cТо есть мы ожидаем что 0x0013300c – это адрес myglob. Проверяем:
(gdb) p &myglob
$1 = (int *) 0x13300cТак и есть!
Вызов функций в PIC
Итак, мы увидели, как работает PIC для адресов на данные. Но что насчёт функций? Теоретически тот же самый способ будет работать и для функций. Вместо того, чтобы call содержал адрес функции, пусть он содержит адрес элемента из GOT, а элемент уже будет заполнен при загрузке.
Но вызов функций в PIC работает не так, в реальности всё несколько сложнее. Прежде чем я объясню, как именно, в двух словах расскажу о мотивации выбора такого механизма.
Оптимизация: «ленивый» байндинг
Когда разделяемая библиотека использует какую-либо функцию, реальный адрес этой функции ещё не известен. Определение реального адреса называется байндинг (binding), и это то, что загрузчик делает, когда загружает разделяемую библиотеку в адресное пространство процесса. Байндинг не тривиален, так как загрузчику нужно искать символы функций в специальных таблицах [5].
Таким образом, определение реального адреса каждой функции занимает какое-то время (не так много времени, но так как вызовов функций может быть значительно больше, чем данных, длительность этого процесса увеличивается). Более того, в большинстве случаев это делается зря, так как при обычном запуске программы будет вызвана лишь малая часть функций (подумайте, как много вызовов требуются только при возникновении ошибок или каких-то специальных условий).
Чтобы ускорить этот процесс, и была придумана хитрая схема «ленивого» байндинга. «Ленивая» — это общий термин оптимизаций в IT, когда какая-либо работа откладывается до самого последнего момента. Смысл этой оптимизации в том, чтобы не делать лишнюю работу, которая может быть и не нужна. Примерами такой «ленивой» оптимизации являются механизм copy-on-write и «ленивые» вычисления.
«Ленивая» схема реализована путём добавления ещё одного уровня адресации – PLT.
Procedure Linkage Table (PLT)
PLT – это часть секции text в бинарнике, состоящая из набора элементов (один элемент на одну внешнюю функцию, которую вызывает библиотека). Каждый элемент в PLT – это небольшой кусок выполняемого машинного кода. Вместо вызова функции напрямую вызывается кусок кода из PLT, который уже сам вызывает функцию. Такой подход часто называют «трамплином». Каждый элемент из PLT имеет собственный элемент в GOT, который содержит реальное смещение для функции. После того как загрузчик определит её, конечно.
На первый взгляд всё довольно запутанно, но я надеюсь, что скоро всё станет более понятно – в следующих разделах я расскажу о деталях с диаграммами.
Как я уже упоминал, PLT позволяет делать «ленивое» определение адресов функций. В тот момент, когда разделяемая библиотека впервые загружена, реальные адреса функций ещё не определены:
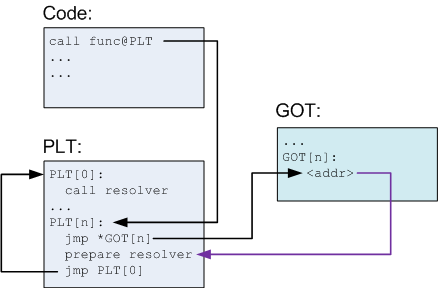
Объяснение:
- В коде вызывается функция func. Компилятор переводит этот вызов в вызов func@plt, который является одним из элементов PLT.
- PLT состоит из специального первого элемента, за которым следуют несколько идентично структурированных элементов, один для каждой функции.
- Все элементы PLT, кроме первого, содержат следующие части:
• прыжок по адресу, который указан в соответствующем элементе из GOT;
• подготовка аргументов для метода «определения»;
• вызов метода «определения», который находится в первом элементе PLT. - Первый элемент PLT – вызов метода «определения», который находится в коде самого загрузчика [6]. Этот метод определяет реальный адрес функции (подробнее об этом – ниже).
- Перед тем как реальный адрес функции будет определён, N-ный элемент GOT просто указывает на адрес после прыжка. Именно поэтому стрелка на диаграмме выделена другим цветом – это не реальный прыжок, а просто указатель.
Что происходит после того, как func вызвана первый раз:
- Вызывается PLT[n] – и происходит прыжок по адресу из GOT[n].
- Этот адрес указывает обратно на PLT[n], на место, где происходит подготовка аргументов для метода «определения».
- Метод вызывается.
- Метод определяет реальный адрес функции func, кладёт его в GOT[n] и вызывает func.
После первого раза диаграмма выглядит немного по-другому:

Заметьте, что GOT[n] теперь указывает на реальную func [7] вместо того чтобы указывать обратно в PLT. Так что когда функция вызывается повторно, происходит следующее:
- Вызывается PLT[n] и происходит прыжок по адресу из GOT[n].
- GOT[n] указывает на func, так что func просто вызывается.
Другими словами, func теперь попросту вызывается без использования метода «определения» и без лишнего прыжка. Этот механизм позволяет делать «ленивое» определение адресов функций и не делать никакого определения для тех функций, которые не вызываются.
Обратите внимание, библиотека при этом абсолютно не зависит от адреса, по которому она будет загружена, ведь единственное место, где используется абсолютный адрес, – это GOT, а она находится в секции data и будет релоцирована во время загрузки загрузчиком. Даже PLT не зависит от адреса загрузки, так что она может находиться в секции text, доступной только для чтения.
Я не углубляюсь в детали работы метода «определения», но это и не так важно. Метод – это просто кусок низкоуровневого кода в загрузчике, который делает своё дело. Аргументы, которые готовятся перед вызовом метода, дают ему знать, адрес какой функции необходимо определить и куда следует поместить результат.
PIC с вызовом функции через PLT и GOT (пример)
Ну, и для того чтобы подкрепить теорию практикой, рассмотрим пример, который демонстрирует вызов функции с помощью вышеописанного метода.
Вот код разделяемой библиотеки:
int myglob = 42;
int ml_util_func(int a)
{
return a + 1;
}
int ml_func(int a, int b)
{
int c = b + ml_util_func(a);
myglob += c;
return b + myglob;
}Этот код будет скомпилирован в libmlpic.so, и мы сфокусируемся на вызове ml_util_func из ml_func. Дизассемблируем ml_func:
00000477 <ml_func>:
477: 55 push ebp
478: 89 e5 mov ebp,esp
47a: 53 push ebx
47b: 83 ec 24 sub esp,0x24
47e: e8 e4 ff ff ff call 467 <__i686.get_pc_thunk.bx>
483: 81 c3 71 1b 00 00 add ebx,0x1b71
489: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
48c: 89 04 24 mov DWORD PTR [esp],eax
48f: e8 0c ff ff ff call 3a0 <ml_util_func@plt>
<... snip more code>Интересная часть – вызов ml_util_func@plt. Заметьте также, что адрес GOT находится в ebx. Вот как выглядит ml_util_func@plt (находится в секции .plt с правами на выполнение):
000003a0 <ml_util_func@plt>:
3a0: ff a3 14 00 00 00 jmp DWORD PTR [ebx+0x14]
3a6: 68 10 00 00 00 push 0x10
3ab: e9 c0 ff ff ff jmp 370 <_init+0x30>Вспомните, что каждый элемент PLT состоит из трёх частей:
- Прыжок по адресу из GOT (это прыжок на [ebx+0x14]).
- Подготовка аргументов для метода «определения».
- Вызов метода «определения».
Метод «определения» (элемент 0 в PLT) находится по адресу 0x370, но он нас сейчас не интересует. Гораздо интересно посмотреть, что содержит GOT. Для этого нам снова понадобится калькулятор.
Трюк для получения текущего IP в ml_func был сделан по адресу 0x483, и к нему мы прибавили 0x1b71. Так что GOT находится по адресу 0x1ff4. Мы можем увидеть, что там, с помощью readelf [8]:
> readelf -x .got.plt libmlpic.so
Hex dump of section '.got.plt':
0x00001ff4 241f0000 00000000 00000000 86030000 $...............
0x00002004 96030000 a6030000 ........Запись в GOT для ml_util_func@plt, похоже, находится по смещению +0x14, или 0x2008. Судя по выводу выше, слово по этому адресу имеет значение 0x3a6, а это адрес push-инструкции в ml_util_func@plt.
Чтобы помочь загрузчику сделать своё дело, в GOT добавлена запись с адресом места в GOT, куда нужно записать адрес ml_util_func:
> readelf -r libmlpic.so
[...] snip output
Relocation section '.rel.plt' at offset 0x328 contains 3 entries:
Offset Info Type Sym.Value Sym. Name
00002000 00000107 R_386_JUMP_SLOT 00000000 __cxa_finalize
00002004 00000207 R_386_JUMP_SLOT 00000000 __gmon_start__
00002008 00000707 R_386_JUMP_SLOT 0000046c ml_util_funcПоследняя строчка означает, что загрузчику нужно положить адрес символа ml_util_func в 0x2008 (а это, в свою очередь, элемент GOT для данной функции).
Было бы классно увидеть, как происходит эта модификация в GOT. Для этого воспользуемся GDB ещё раз.
> gdb driver
[...] skipping output
(gdb) set environment LD_LIBRARY_PATH=.
(gdb) break ml_func
Breakpoint 1 at 0x80483c0
(gdb) run
Starting program: /pic_tests/driver
Breakpoint 1, ml_func (a=1, b=1) at ml_main.c:10
10 int c = b + ml_util_func(a);
(gdb)Мы сейчас находимся перед первым вызовом ml_util_func. Вспомните, что адрес GOT находится в ebx. Посмотрим, что там:
(gdb) i registers ebx
ebx 0x132ff4Смещение для нужного нам элемента находится по адресу [ebx+0x14]:
(gdb) x/w 0x133008
0x133008: 0x001313a6Да, заканчивается на 0x3a6. Выглядит правильно. Теперь давайте шагнём до вызова ml_util_func и посмотрим ещё раз:
(gdb) step
ml_util_func (a=1) at ml_main.c:5
5 return a + 1;
(gdb) x/w 0x133008
0x133008: 0x0013146cЗначение по адресу 0x133008 поменялось. Получается, что 0x0013146c – реальный адрес ml_util_func, который был положен туда загрузчиком:
(gdb) p &ml_util_func
$1 = (int (*)(int)) 0x13146c <ml_util_func>Как мы и ожидали.
Управляем определением адреса загрузчиком
Сейчас самое время упомянуть о том, что процесс «ленивого» определения адреса, который осуществляется загрузчиком, может быть настроен несколькими переменными окружения (а также соответствующими аргументами для линкера ld). Иногда эти настройки могут быть полезны для дебаггинга или каких-то специальных требований к производительности.
Переменная LD_BIND_NOW, когда она определена, говорит загрузчику определять все адреса при старте, а не «лениво». Её работу можно проверить, посмотрев вывод gdb для примера выше в том случае, когда она задана. Мы увидим, что элемент из GOT для ml_util_func содержит реальный адрес функции ещё до первого вызова функции.
Напротив, LD_BIND_NOT говорит загрузчику не обновлять GOT никогда. То есть каждый вызов функции в этом случае будет идти через метод «определения».
Загрузчик настраивается и некоторыми другими флагами. Я рекомендую изучить man ld.so. Там много интересной информации.
Стоимость PIC
Мы начали разговор с проблемы релокации во время работы и решения этой проблемы PIC. Но сам PIC, увы, тоже не без проблем. Одна из них – стоимость лишней косвенной адресации. Это лишнее обращение к памяти при каждом обращении к глобальной переменной или функции. «Масштаб бедствия» зависит от компилятора, процессорной архитектуры и собственно приложения.
Другая, менее очевидная, проблема – использование дополнительных регистров для реализации PIC. Чтобы не определять адрес GOT слишком часто, компилятору имеет смысл сгенерировать код, который будет хранить адрес в регистре (например, ebx). Но это значит, что целый регистр уходит только на GOT. Для RISC-архитектур, у которых обычно много регистров общего пользования, это не такая уж большая проблема, чего не скажешь об архитектурах типа x86, у которых мало доступных регистров. Использование PIC означает на один регистр меньше, а значит, нужно будет делать больше обращений к памяти.
Заключение
Теперь вы знаете, что такое код, не зависящий от адреса, и как он помогает создавать разделяемые библиотеки с разделяемой, доступной только для чтения, секцией text.
У PIC есть плюсы и минусы по сравнению с релокацией во время работы, и результат будет зависеть от множества факторов (в частности, от архитектуры процессора, на котором будет работать программа).
Однако, несмотря на недостатки, PIC становится всё более популярным подходом. Некоторые неIntel-архитектуры, такие как SPARC64, требуют обязательного использования PIC для разделяемых библиотек, а многие другие (например, ARM) – имеют IP-зависимую адресацию, чтобы сделать PIC более эффективным. И то, и другое верно для наследницы x86 – x64.
Мы не фокусировались на проблемах производительности и архитектурах процессора. Моя задача была в том, чтобы рассказать, как работает PIC. Если объяснение было недостаточно «прозрачным», дайте мне знать в комментариях – и я постараюсь дать больше информации.


Halt
Все хорошо, только записи в PLT традиционно называют «трамплином» а не «батутом».
mkevac
Вы правы! Спасибо!