
На них приходится четверо инженеров по инфраструктуре (опсов, админов, то есть нас) — мы чаще всего были нужны для того, чтобы устанавливать софт на стенды, перезагружать машины (первая надежда разработчика: не работает — попроси инженера перезагрузить), накатывать схемы БД и так далее.

Разработчики пишут код, который сливается в репозиторий. Из него Jenkins рождает сборки, которые выкладывает на шару. Развёртывание системы с нуля первый раз у меня заняло 4 часа 15 минут по таймеру. Для каждого из порядка десяти компонентов (скрипты разных БД, Tomcat-овские приложения и т. д.) в нужном порядке надо было взять файл с шары, разобраться, где и в скольких экземплярах его нужно развернуть, поправить настройки, указать, где ему искать другие компоненты системы, связать всех со всеми и ничего не перепутать.
Пальцы закровоточили — начал скриптовать. Началось с одного маленького скрипта.
Что было
Система состоит из довольно большого числа компонентов: 6 разных приложений на Томкате, каждое из которых в нескольких экземплярах на разных серверах, кластер DSE = Cassandra + Solr + Spark, скрипты создания объектов в них, загрузка начальных данных, миграции схем Oracle, PostgreSQL, кластер RabbitMQ, балансировщики нагрузки, куча внешних систем и так далее.
Стенды тоже в основном состоят из нескольких разных серверов. Приложения на всех стендах распределены по-разному (например, где-то одно из томкатовских приложений развёрнуто в единственном варианте, а где-то в нескольких и прячется за балансировщиком, где-то один экземпляр Оракла, где-то несколько, и т. д.).
Итого, развернуть такую систему — много серверов и много компонентов с разными и часто меняющимися конфигами, в которых они желают иметь информацию друг о друге, расположении баз данных, внешних систем и т. д. и т. п. Таким образом, развернуть всё, где нужно, ничего не забыть, не перепутать и правильно сконфигурировать — задача не совсем тривиальная. Мест, где можно сделать ошибку, много, и процесс требует внимания и концентрации. Сначала я скриптовал маленькие части, доставлявшие наибольшее число проблем. Освободившееся время тратил на следующие по злобности моменты, объединение и обобщение.
В итоге получилось, что для каждого кусочка системы был готов один shell-скрипт, который делал всё — от копирования дистрибутива из jenkins-а до правки конфигов и развёртывания приложения или выполнения обработанных скриптов на базе данных. В общем, начиналось всё, как классический админский велосипед: те же скрипты, которые пишут почти все для себя из кирпичиков. Разница в том, что мы решили сделать эти части взаимозаменяемыми и сразу (ладно, через месяц, а не сразу) задумались о структуре. В итоге это сначала стало системой скриптов, где всё довольно гибко конфигурируется (снаружи), а потом появился ещё и web-GUI.
У меня для каждого стенда и для каждого компонента системы уже были готовы скрипты, выполняющие нужные действия. Но появлялись новые стенды, имеющиеся изменялись, разработка системы двигалась семимильными шагами, и отражать все изменения в скриптах было всё сложнее.
Тогда я описал структуру стенда и все изменяющиеся от стенда к стенду части в конфигурационных файлах, а скрипты обобщил так, что они для работы съедали имя стенда, находили его конфиг и оттуда получали необходимую для работы информацию.
То есть теперь одни и те же скрипты работали на всех стендах, особенности которых были вынесены в конфиг. Так реагировать на изменения стало довольно просто.

Конфиг — это просто страшноватый текстовый файл, в котором содержится список переменных и их, собственно, значений. Скрипты просто source-ят этот файл и получают все настройки в переменных окружения (на самом деле сейчас стало немного сложнее, но именно немного).
#BUTTON_DESC=DSE 4.7JDBC thin<br>Двебуквы
# include "defaults.include"
BUILD_DIRS="data-facade/release-1.5.0:DATA_FACADE,SOMEAPP process-runner/release-1.5.0:PROCESS_RUNNER integration-services/release-1.5.0:INTEGRATION scripts/release-1.5.0:CASS_DDL,ORA_DDL,SOLR_SCHEMA fast-ui/release-1.5.0:FAST_UI cache-manager/release-1.5.0:CACHE_MANAGER"
DSE_HOSTS="xxxdevb.lab.croc.ru xxxdevc.lab.croc.ru xxxdevd.lab.croc.ru xxxdeve.lab.croc.ru"
CASSANDRA_CONNECTION_HOSTS="xxxdevb.lab.croc.ru xxxdevc.lab.croc.ru xxxdevd.lab.croc.ru xxxdeve.lab.croc.ru"
CASS_DDL_NODE="xxxdeve.lab.croc.ru"
SOLR_URL="http://xxxdeve.lab.croc.ru:8983/solr"
ORA_DATABASES="xxxdevg.lab.croc.ru:1521/test"
ORA_CONN_STRING="jdbc:oracle:thin:@xxxdevg.lab.croc.ru:1521/test"
ORA_OPSTORE_PW="###"
ORACLE_HOSTS="DEVG"
DEVG_ADDR="xxxdevg.lab.croc.ru"
DEVG_INSTANCES="TEST"
DEVG_TEST_SID="test"
PG_SERVER="xxxdeva.lab.croc.ru"
DATA_FACADE_HOSTS="xxxdevb.lab.croc.ru"
SOMEAPP_HOSTS="xxxdevb.lab.croc.ru"
PROCESS_RUNNER_HOSTS="xxxdeva.lab.croc.ru"
PP_PROXY_PROCESS_RUNNER_URL="http://xxxdeva.lab.croc.ru:8080/xxx-process-runner"
XX_API_URL="http://#.#.#.#/###/api/"
CASS_DDL_ADD_BOM="yes"
CASS_DDL_TEST_SEED="yes"
KEYSPACE=xxx
REPLICATION_STRATEGY="{'class':'NetworkTopologyStrategy', 'Solr':3}"
CATALINA_HOME=/usr/share/apache-tomcat-8.0.23
CASS_DDL_DISTR_NAME="cass-ddl.zip"
SOLR_DISTR_NAME="solr-schema.zip"
DATA_FACADE_TARGET_WAR_NAME="data-facade.war"
SOMEAPP_DISTR_PATTERN='rest-api-someapp-*-SNAPSHOT.war'
SOMEAPP_TARGET_WAR_NAME="someapp.war"
PROCESS_RUNNER_TARGET_WAR_NAME='xxx-process-runner.war'
PROCESS_RUNNER_DISTR_PATTERN='resources/distr/xxx-process-runner.war'
PROCESS_RUNNER_RESOURCES_DISTR_DIR="resources"
CASS_REQ_FETCHSIZE=100
CASS_REQ_BATCHSIZE=10
CASS_REQ_MAX_LOCAL=2
CASS_REQ_MAX_REMOTE=2
CASS_REQ_CONSISTENCY_LEVEL="LOCAL_QUORUM"
INTEGRATION_AD_SEARCH_NAME="OU=TOGS, DC=testxxxx,DC=local;OU=GMC,DC=testxxxx,DC=local;OU=CA,DC=testxxxx,DC=local"
INTEGRATION_LDAP_PROVIDER_ADDRESS="#.#.#.#"
INTEGRATION_LDAP_PROVIDER_PORT="389"
INTEGRATION_LDAP_SECURITY_PRINCIPAL='testxxxx\\\\lanadmin'
INTEGRATION_LDAP_SECURITY_CREDENTIALS='СЕКРЕТЖИ!'
INTEGRATION_AD_ROOT_DEPARTMENT="DC=testxxxx,DC=local"
SSTABLELOADER_OPTS=""
CASS_REQ_QUEUESIZE=1
OSR_URL=http://#.#.#.#/SPEXX
QUEUE_HOST="xxxdevg.lab.croc.ru"
QUEUE_API_HOST="http://xxxdevg.lab.croc.ru:%s/api/"
QUEUE_ENABLE="true"
TOMCAT_HOSTS="DEVA DEVB"
DEVA_ADDR="xxxdeva.lab.croc.ru"
DEVA_CATALINA_HOMES="CH1"
DEVA_CH1_APPS="PROCESS_RUNNER"
DEVB_ADDR="xxxdevb.lab.croc.ru"
DEVB_CATALINA_HOMES="CH1"
DEVB_CH1_APPS="DATA_FACADE SOMEAPP FAST_UI CACHE_MANAGER"
CACHE_MANAGER_URL=http://xxxdevb.lab.croc.ru:8080/cache-manager/Чтобы сделать более удобным ещё и управление конфигами стендов, позже добавил инклуды — пачки логически связанных настроек, записанных в отдельных файлах, которые можно скопом подключать к конфигам или другим инклудам. Например, настройки, связанные с AD, записаны в 5 разных переменных, а сервера AD всего два, для каждого из них сделан инклуд с этими 5 настройками. Чтобы быстро переключать стенды, между ними достаточно подключить нужный инклуд. Чтобы отразить какое-то изменение, произошедшее на сервере, надо поправить настройки в одном файле, и все нацеленные на него стенды узнают об этом.
Эта структура скриптов позже обросла свистоперделками, но в основном сохранилась.

Действия обычно выполняются пачкой — смысл имеет последовательность действий, например: на тестовом стенде сохрани НСИ, пересоздай схему в Оракле, загрузи НСИ обратно. Если предыдущий компонент отвалился с ошибкой, вероятно, надобность в следующих отпала. Чтобы было удобнее, сделан скрипт-запускалка:
./run.sh "test" "save-nsi ora-ddl-init load-nsi"Скрипт run.sh уходит пересоздавать схему с сохранением НСИ на тестовом стенде, а инженер — пить чай.
GUI
Стало казаться, что инженер в процессе развёртывания системы нужен только для перевода слов из человеческого («разверни мне первое, второе и компот») в имена скриптов в последовательности.
Команда не очень любит unix-овую консоль, поэтому к идее запускать скрипты без инженеров отнеслись скептически. Но лень толкнула предпринять ещё одну попытку — сделал страничку из cgi скрипта на Питоне, на которой нехитрым образом можно было выбрать из списка конфиг и натыкать мышкой последовательность компонентов. Грубо говоря, просто графическую кнопку, которую можно нажать вместо консольной команды. Ей стали пользоваться.
Идея прижилась, туда стали добавляться и другие рутинные инженерные действия, перезапуск отдельных компонентов и серверов в целом, выгрузка-загрузка-сохранение информации из разных БД, управление балансировкой, включение «балета» на время даунтаймов и т. д. Прижилось и кодововое имя «Кнопка».
Это творение моих кривых рук потихоньку переделал, теперь она работает на python + flask и умеет делать всё без перезагрузки страницы: обновлять список стендов и их состояние, обновлять хвосты логов, запускать компоненты и пристреливать их, если шалят.
Коллега Андрей применил дизайнерскую магию и из месива моих чёрно-белых div-ов сделал красиво оформленную страничку.
Слева — список стендов, там выбираем стенд, с которым нужно что-то сделать. Это название стенда, которое инженеры раньше передавали в скрипт.
./run.sh "dev-letters" "save-nsi ora-ddl-init load-nsi"Тыкаем в название нужного стенда, справа открываются детали.

dev-letters — это название. Ниже — краткое описание стенда от инженеров (из коммента, первой строчки конфига). Ссылки «посмотреть логи» и развёрнутые версии софтов, затем — указание, из какой ветки будут браться сборки для этого стенда. И возможность изменить эту ветку:
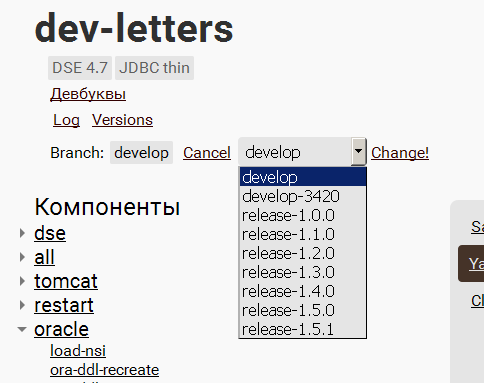
Все заскриптованные действия со стендами распределены по категориям и подписаны «Компоненты». Это названия действий, которые инженеры раньше передавали скриптам:
./run.sh "dev-letters" "save-nsi ora-ddl-init load-nsi"Когда из списка выбирается компонент-действие, он попадает в правую часть страницы:

Здесь из них формируется очередь выполнения: распределяем их в нужном порядке (или добавляем в нужной последовательности). Например, на скрине будет выполнено: выгрузить nsi, пересоздать схему в Оракловой БД, загрузить nsi обратно.
Чтобы не набирать часто используемые последовательности, можно сохранять их в Комбо и запускать на выполнение в несколько кликов, минуя поиск нужных компонентов в списке.
Ещё ниже — пользовательские комментарии к стенду. Есть возможность оставить весточку коллегам о том, что стенд захвачен для проведения очень важных работ, чтобы его пока никто не трогал.

Последний комментарий отображается в списке стендов, чтобы легче было получить общую картину по стендам и выбрать, где можно поработать.
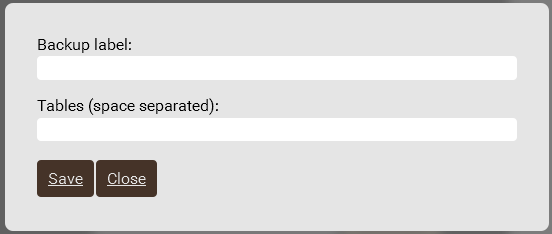
Есть обмен данными между стендами, в частности, между Кассандрами. Можно нажать кнопочку Save data, придумать имя для архива и список таблиц, тогда данные будут заботливо сохранены. Затем можно выбрать другой стенд и загрузить их туда кнопочкой Load data, выбрав нужный архив из списка имеющихся.

Пользователи аутентифицируются через корпоративный AD. Есть простенький контроль доступа: роли, которые можно распределять пользователям, и привилегии для разных стендов, которые можно распределять ролям. Это чтобы никто из пока неопытных коллег не запустил деструктивные компоненты (пересоздание БД, например) на важных стендах.
Обо всех действиях через кнопку специально обученный единорог пишет в командный Slack. Так что все знают, что где происходит.

Также единорог сообщает, если скрипты отвалились с ошибкой, чтобы пользователь о том, что 3-часовая заливка бэкапа срубилась после 10 минут работы, узнал сразу же, а не через 3 часа (к тому же ему не нужно будет постоянно смотреть за процессом).

Чтобы, не дожидаясь нотификаций заботливого единорога, узнать, как там идёт процесс, есть логи выполнения скриптов.

Чтобы видеть, что там сейчас на стенде развёрнуто из нашего софта, Кнопка при деплое компонентов системы записывает, откуда был взят дистрибутив, который использовался для этого. Что удалось записать, можно посмотреть и сделать вывод, что там сейчас развёрнуто на стенде.

Есть ещё скрипт, который раз в день проходит по всем конфигам стендов, заходит на все задействованные сервера и смотрит, что там работает из компонентов системы, какие версии системных и наших софтов установлены, что запущено, что нет, когда последний раз были обращения к томкатам и т. д.
Всё это собирается в таблицу excel и отдаётся пользователям, чтобы можно было проанализировать, как используются стенды, как распределить их между разработчиками, где добавить/забрать железок.

Есть у нас один стенд, к которому доступ по соображениям безопасности закрыт на физическом уровне, но там всё равно должна работать наша система. Для этого в списке есть специальный стенд.
С ним всё, как и с остальными стендами, только когда в очередь выполнения набираются компоненты, происходит другой процесс. Скрипты копируют сами себя, отрезают ненужные части (типа странички, привилегий и конфигураций стендов разработки), создают рядом скрипт вызова всех указанных в очереди компонентов. Затем добавляют к этому всему дистрибутивы компонентов, собирают полученное в архив и выкладывают на шару.
То есть для всех стендов оно само подключается, куда ему надо, и делает нужные вещи. А для того, где подключиться нельзя, пакует себя в чемодан, из которого по приезде на место вылезает и делает своё дело. Получается такое «отложенное выполнение»: формируются скрипты, которые нужно отнести за стенку, запустить ./run_all.sh, и начнёт происходить всё то же самое, что и с остальными стендами.
Вишенка на торте — вверху, как видите, техническая информация, в частности, дежурный инженер, его телефон, гертруда, чтобы разработчик видел, что страница реально обновилась, и всякие мелкие полезности:
Сколько времени экономит
Чтобы попытаться понять, приносит ли нам этот наш чудесный велосипед какую-то пользу, попробовал тут прикинуть время, которое Кнопка выигрывает инженерам.
Если взять типовой сценарий, который выполняется чаще других: изменилась структура БД, нужно накатить миграции и обновить (допустим, одно) приложение, затронутое обновлением, то это займёт примерно минут 30–40 в случае одного сервера.
В зависимости от количества серверов с таким приложением изменится и число операций копирования приложения на сервер и исправления кучи параметров в конфигах (+ схемы Касандры, Оракла и Солара).
Кнопка это делает самостоятельно, без промедлений и участия пользователя, нужно только выбрать желаемые шаги. Но стоит ли это всё потраченных усилий, если это нужно сделать один раз в году. Сколько действий запускается в день?
Чтобы ответить на этот вопрос, я попробовал грубо проанализировать логи запусков. Судя по первым записям в логах, мы запустили эту версию Кнопки в работу около 1 февраля 2016-го. На 10 ноября 2016-го прошло 185 дней, из них, грубо говоря, 185*5/7 = 132 рабочих дня.
Количество запусков:
[dpotapov@dpotapovl logs]$ (sum=0; for f in *.log ; do sum=$(expr $sum + $(grep "requested run" "$f" | wc -l)) ; done ; echo $sum)22192219/132=16.8106 запусков в день.
Но каждый запуск — это целая последовательность компонентов: посчитаем, сколько их было всего:
for f in *.log ; do
grep "requested run" $f |sed 's/^.*\[\(.*\)\].*$/\1/' | while read l ; do
for w in $l ; do
echo "$w" | sed 's/,$//'
done
done done > /tmp/requests.list
cat /tmp/requests.list | wc –l
[dpotapov@dpotapovl logs]$ cat /tmp/requests.list | wc –l
64426442/132=48.8030 компонентов в день.
Сложно точно посчитать, сколько руками мы разворачивали бы каждый компонент, но думаю, можно пальцем в небо оценить в 20 минут. Если так, то руками сделать то, что Кнопка делает в среднем за день, будет 48*20/60 = 16 часов. 16 часов работы инженера — без ошибок, косяков, залипаний в интернетах, обедов и болтовни с коллегами.
Можно ещё добавить, что Кнопка на всех стендах работает одновременно, когда это нужно пользователю. Разные пользователи на разных стендах друг другу не мешают. В случае инженера сюда следует ещё добавить время, которое упускает пользователь-заказчик, пока ждёт в очереди у инженера.
Это уже девопс?
С одной стороны — нет, потому что рутового доступа на продуктивы у наших разработчиков нет. Они не готовы его получить, потому что вместе с доступом нужно принять ответственность, а там довольно сложная инфраструктура — Инфинибэнд, Спарки, вот это всё — очень легко выстрелить себе в ногу.
С другой стороны, у нас кто-угодно-опс, потому что любой участник команды может накатить сборку на стенды, куда у него есть доступ.
Сборки на продуктив, например, чаще всего накатывает лидер группы тестирования.
Почему не докер или не другое готовое решение?
Изначально задача была, как «научиться хотя бы руками собрать всю эту кучу софтов вместе и заставить работать». В процессе этого «научиться» часть заскриптовали, потом ещё и ещё, и получился такой велосипед.
Начиналось как малая автоматизация. Надо было выполнить кучу скриптов БД из директории — сделал скрипт, который обходит директорию и запускает всё в ней. Потом подумалось, что круто было бы насильно конвертировать каждый скрипт в UTF, добавили эту процедуру туда же. Потом стали дописывать директивы в каждый скрипт, чтобы выставлять уровень консистентности, с которым выполнять скрипт. Потом стали из них каждого скрипта удалять пустые строки, когда поменяли версию клиента БД, и он на это плевался. И так далее.
У нас почти не было чёткого рубежа, до которого это было сборищем такой мелкой автоматизации, а после стало системой. Оно как-то само выросло, мелкими шажками. Поэтому и вопрос о том, что наверняка есть какой-то готовый продукт, встал только когда наша поделка уже решала задачу. Тогда уже получалось, что нам надо заменить что-то, что работает и закрывает вопрос на что-то, что придётся изучить и заточить под свои нужды (неизвестно какого калибра напильником).
Резюме
Вот так у нас и получился пульт управления всем сразу: в несколько кликов можно переключать заставку обслуживания, мигрировать схемы баз данных, перестраивать индексы, устанавливать новые сборки сразу с нужными настройками под стенд и без остановки работы пользователей (за счёт последовательного вывода из балансировки) — любой версии на любой стенд, перекачивать данные между стендами, смотреть за состоянием стендов и историй изменений на них.
Скрипты под капотом устроены так, что адаптировать или доработать их довольно просто, так что и другие проекты потихоньку начинают адаптировать Кнопку под себя или писать свой велосипед на основе тех же идей.
Трудно сказать, лучшим ли способом мы это всё устроили (наверняка ведь нет), но работать — работает.
Получилось сэкономить примерно 16 рабочих часов админа в день — это целых два землекопа. Так что меня теперь трое из ларца, одинаковых с лица. Если вдруг есть вопросы не для комментариев, моя почта — dpotapov@croc.ru.
Комментарии (65)
oxidmod
27.12.2016 11:50+2может сморожу глупость, но нельзя ли приспособить всякие ansible и иже с ними?

dbax
27.12.2016 12:04А у ansible есть хорошая веб-морда?
Главный вопрос в этом.ybalt
27.12.2016 12:36+2Есть Ansible Tower, но он триальный, до 10 хостов, только поиграться.
Я использую Jenkins с плагином для Ansible, выглядит очень неплохо, наглядно и деплоиться в один клик.

Suvitruf
27.12.2016 13:23+2Ansible Semaphore? Я, правда, всё равно по старинке все плейбуки в блокнотике пишу.

LoadRunner
27.12.2016 11:55и всякие мелкие полезности
А есть где-то весь список забавных фразочек из шапки?
SystemXFiles
27.12.2016 12:35+5Вот, пожалуйста =)
Цитаты из Кнопки- Глаз страуса больше, чем его мозг, %username%.
- Мне нужна твоя одежда и мотоцикл, %username%.
- В наборе детских кубиков буквы «Х», «Й» и «У» всегда находятся на одном кубике, %username%.
- Сегодня вас ждёт приятная неожиданность, %username%!
- Хорошая погода, не правда ли, %username%?
- Попытка — первый шаг к провалу, %username%.
- Продолжайте кликать, %username%! Во имя всего святого, продолжайте кликать!
- Шоколад ни в чем не виноват, %username%.
- Береги коленки, %username%!
- Bite my shiny metal ass, %username%
- Попасть сюда сложно, %username%. Выход не могут найти даже старожилы.
- Тут никого нет, %username%! Никого! Никого, кроме тебя!
- Вы не дождетесь новых приветствий, %username%.
- Люди в тюрьме меньше времени сидят, чем вы работаете на этом проекте, %username%.
- Если руки золотые, то не важно откуда они растут, %username%.
- Вгрущить — это то, что наша система умеет делать лучше всего, %username%.
- Проект развивает мелкую моторику рук и тренирует глаза. Все время надо прищелкивать, %username%!
- Косячим — так косячим, чиним — так чиним, %username%!
- Что-то пошло не так, %username%.
- Надо прибить план гвоздями, %username%
- Машина едет, а мы строим дорогу перед ней, %username%.
- Мы с одного конца печём батон, который с другого конца едят, %username%.
- Буквы нужны для проверки двух теорий, %username%.
- Прилетело НЛО и унесло ваши отчеты, %username%.
- <table_name> — это изюм нашего хранилища, %username%.
- Что сделать, чтобы оно не висло, %username%?
- Мы написали ошибку ПО 1000 лет тому назад, %username%.
- Про проект или хорошо, или никак, %username%.
- Ну какой инженер может спокойно пройти мимо забитого на 100% диска, %username%?
- <Название_системы> не сдается, %username%!
- Не найдены микроданные — это нормально, %username%.
- Эксперименты, инновации, ПСИ, %username%!
- <Название_системы>ик болеет, %username%.
- Солар на буквах ушёл в запой, %username%.
- По срочности: это нежно до завтра до утра понять, %username%.
- На <Название_формы> можно только смотреть… это созерцательная форма, %username%.
- Сортировка строк в Кассандре происходит с божьей помощью, %username%.
- Непоправимое улучшение было выполнено, %username%.
- Костыли в шкафу, %username%.
- Процесс разборок запущен, %username%.
- У нас что с Каччандрой, %username%?
- Я тоже позвонил Андрею, %username%.
- Ничего ведь просто так не бывает — есть причина, есть следствие, %username%.
- Ушки пчелы, перья жабы, кровь тухлого абрикоса и немного времени решат твою задачу, %username%.
- У нас в проекте аналитики ходят с мылом, веревкой и загадочно улыбаются, %username%.
- Если ты не тестировщик, %username%, не ломай тест. Это должны делать профессионалы.
- Конвейеру похер-мороз, %username%. Он еще и не такие шаги обработает.
- Оказалось не все так ужасно, %username%.
- У Кассандры одна извилина, %username%.
- Запрещать разработчикам разрабатывать без ФС — это ограничивать их свободу творчества, %username%.
- С первой виртуалкой какой-то огурец мозга, %username%.
- Не стоит делать /usr/share/apache-tomcat-8.0.23/bin/startup.sh от рута, %username%. Это нарушает пространственно-временной континуум.
- Не знаю что это, %username%, но в хозяйстве явный прибыток.
- Салават не хочет получить лососями, %username%. Он не овнер!
- Если ошибка в программе может произойти, она произойдет, %username%.
- Здесь могла бы быть ваша реклама, %username%. Но, увы, её тут нет.
- Для хорошего программиста он слишком часто копировал чужой код, %username%.
- Бугагагашенька, %username%.
- Спокойной ночи, в случае апокалипсиса — удачи, %username%.
- Только начнёшь работать, обязательно кто-нибудь разбудит, %username%.
- %username%, помни правило простое. Работаешь сидя, отдыхай — стоя!
time2rfc
27.12.2016 13:06+1это изумительно, так понравилась статья и подход, что даже полез смотреть вакансии на сайт

Termux
28.12.2016 19:08+1Я был на собеседовании в КРОКе.
Мне они сразу сказали, что проект срочный
и придётся оставаться в офисе до "после 23:00".
Т.е. заведомо нанимали меньше народа,
чтобы каждый работал не только за себя,
но и за того парня.
navion
30.12.2016 17:05За 10 лет ничего не менялось… Меня тогда собеседовал инженер в несвежей рубашке с мешками под глазами, как будто работал всю ночь.
Termux
31.12.2016 19:00Такое, к сожалению, много где бывает —
везде, где плохо организована работа
или не хватает кадров, например
«слишком быстрый рост»
но в КРОКе на это шли сознательно —
нужно было двух (трёх?) человек,
а искали — одного.
ybalt
27.12.2016 11:56+1А почему не использовали какие-нибудь provisioning tool типа Chef, Puppet или Ansible?
iaon
27.12.2016 13:06Сильно зависит от workflow. Когда нужно готовить хост с нуля они подходят очень хорошо. Но если надо менять кирпичик в уже построеном доме, то все становится очень печально… Т.е. сделать можно, но никакой эстетики.
ybalt
27.12.2016 15:22+1Есть проблема с самим Ansible — его позиционируют почему-то исключительно как средство для поднятия и настройки хостов.
На самом деле он прекрасно вписывается в текущую инфраструктуру, если грамотно использовать его возможности, а не только модуль command или shell. Я использую Ansible как для provisioning, так и для деплоя и для тестов.iaon
27.12.2016 15:47Текущая инфраструктура бывает разной. Когда для того чтобы задеплоить компонент нужно несколько других остановить, причем на разных хостах. Потом поднять это дело в нужной последовательности и с проверками. А еще неплохо как-нибудь совместимость версий компонентов отследить… Тут приходит боль :)
Мне понравилось такое на XL deploy делать, но он сильно платный.ybalt
27.12.2016 17:42Вот то, что вы описали, Ансибл решает очень даже замечательно. Ну кроме совместимости версий, я тут немного не понял кейс.
iaon
27.12.2016 19:47Совместимости читай зависимости. Если компонент А требует версию компонента Б, то не давать ставить А. Но это уже детали.
Мне уже стало интересно как у вас все реализовано :)
Вот смотрите есть у нас DB, backend, frontend. И они зависят друг от друга по нисходящей. Миграция DB ведет к рестарту backend, а затем frontend. Апдейт версии backend влечет рестарт frontend. Получаем у нас есть три возможных артифакта и 7 вариантов деплоя.
И как реализовать деплой не плодя плэйбук на каждый случай? Я представляю что это можно решить через группы. И/или расписать все шаги и на каждом шаге проверять условия. Но мне кажется, что поддержка такого будет не слаще чем скриптов. Помним что пример абстрактный, и компонентов у нас на самом деле несколько десятков.
ybalt
27.12.2016 20:13+2В ансибле есть понятие handlers — это таски, вызываемые при срабатывании каких-либо условий через notify. Это один вариант. Есть еще таски, включаемые по флагу, например onchange
Применимо к вашему примеру, плей будет выглядеть примерно так:
— hosts: db
tasks:
— name: restart db
service: name=db state=restart
tags:
— restartdb
notify:
— restart be
— restart fe
— hosts: be
tasks:
— name: restart be
service: name=be state=restart
tags:
— restartdb
notify:
— restart fe
— hosts: fe
tasks:
— name: restart fe
service: name=fe state=restart
tags:
— restartfe
— handlers:
— name: restart be
service: name=be state=restarted
— name: restart fe
service: name=fe state=restarted
В этом плейбуке при запуске задачи restartdb будут рестартнуты в самом конце backend и frontend
Причем эти хендлеры будут вызваны в конце всех тасков.
У меня экосистема приложений это десяток микросервисов, которые обслуживаются через один небольшой плейбук, я по сути просто указываю тэг микросервиса, а прописанные зависимости автоматом запускают нужные задачи по его деплою — например, редеплой основного приложения влечет изменения в балансировщике и оповещение зависимых сервисов о том, что нужно сделать рестарт.iaon
28.12.2016 13:24Спасибо за развернутый ответ. Не очень, конечно, хорошо то что все стартанет в конце. Попробую при случае. Хэндлеры использовал внутри хост группы, а получается что и глобально можно.
А по хорошему, конечно, порядок старта это зло, нужно максимально избегать на этапе проектирования.
varnav
27.12.2016 16:27+1Да ну нет же! Не знаю как в чефе-паппете, но в Ансибле прицип «desired state», очень он хорошо меняет кирпичик, просто замечательно.

gunya
29.12.2016 21:04В любой системе управления конфигурациями используется desired state.
Но в ansible desired state не такой строгий, как в puppet.

meatlink
27.12.2016 13:09+1Да, наверняка можно было бы использовать эти инструменты. Но так получилось, что сначала мы подумали, что справимся своими силами, а одновременно с пониманием, что руками тут делать многовато, появлялись скрипты. В итоге, когда полностью осознали ситуацию, скрипты уже были готовы и работали.
ybalt
27.12.2016 15:28Да, знакомая ситуация, у меня тоже начиналось все со скриптов. Но ввиду того, что человекоресурсы были сильно ограничены, то с ростом сложности и размера скриптов их поддержка превращалась в ад. Кроме того, в скриптах нет никакой вменяемой страховки от множественного срабатывания, кроме самописных, нет возможности восстановить процесс с нужной точки после падения и большая проблема вычищать промежуточные результаты при аварии.
Помог переезд полностью на Ansible, со скурпулезным подходом к действиям — никаких прямых вызовов shell, только через модули и состояния. Ошибки практически исчезли и само исполнение задач стало безопасным и идемпотентным.
Это исключительно мой опыт, возможно, набор скриптов в некоторых случаях более действенен.Termux
28.12.2016 19:01+1В крайнем случае
для сценариев shell тоже есть
1) фрэймворки
2) библиотеки
3) соглашения по исползованию (coding conventions)
4) пакетирование
…
тысячи их
N) PROFIT!!!
мне хочется выгнать вон из профессии ссаными тряпками всех,
кто в 2015 пишет так,
как будто на дворе 1995 г.
хуже сырого говнокода на баше
может быть только говнокод на PERL
ну реально
дюди прочитали самую тупую и неудачную книжку
(или вообще никакой)
и плодят уродство, с которым потом
нормальным доведётся страдать
и ещё за это
получают неплохие зарплаты
как после этого нормально относиться
к КРОКу и подобным конторам?!
https://github.com/alebcay/awesome-shell
https://github.com/awesome-lists/awesome-bash
https://c9.io/nopolitica/awesome-shell
Вот честно, — я бы избавился от такого Дениса
под любым предлогом!
Я был в конторах, где десятки таких «гениев»
годами (если не десятилетиями) копили
тонны такого говнокода и говноинфрастуктуры
и я бы не согласился разгребать ЭТО
ни за какие деньги
потому что здоровье дороже
и нервов не хватит.
Плохо что у нас такие КРОКи — «короли госзаказа»
у буржуев на западе
подобная контора (а у них там всё так)
дожила бы ровно до первого грамотного аудита.meatlink
29.12.2016 14:46Скажите, но как вы составили себе представление о коде, чтобы дать такую резкую оценку?
Относительно кода, возможно, в посте недостаточно подчеркнул, но я выносил общий код в библиотеки, использовал coding conventions…
Про какую книжку, кстати, Вы говорите? Я любитель юниксов, командной строки и всего такого, много лет пользуюсь шеллом и довольно много материала изучил по этой теме.Termux
29.12.2016 18:32Закрытый код == говно. В том числе и из-за невозможности оценить
(или «заценить», глянув беглым взглядом на количество «звёздочек»,
количество контрибуторов и дату коммита).
Сейчас для баша все «coding conventions»
заканчиваются "… а лучше напишите playbook или возьмите готовый".
книжки есть просто «хорошие по башу», типа TLCL
The.Linux.Command.Line.2012.William.E.Shotts.Jr.A.Complete.Introduction.ePub
https://sourceforge.net/projects/linuxcommand/files/TLCL/16.07/TLCL-16.07.pdf/download
но на память ни одной по «продуктивному башу» не помню.
И этот факт — ещё одно подтверждение того,
инструментарий поменялся (с 1995),
Ansible действительно проще
1) во вхождении (старте)
2) в поддержке/использовании
3)
это не более «модный», а более эффективный инструмент на сегодня.
Ваши (и мои тоже) знания действительно устарели
и unix-shell-scripting-background может как помогать,
так и мешать
например, я работал с bash-профи, который использовал
Puppet просто как средство доставки файлов .sh и .tgz
т.е. не в парадигме инструмента (bad practice, даже worse)
в его версиях скриптов невозможно было разобраться в принципе
— версионирования, тестирования и т.п. не было как такового
я их отличал только по MD5 hash-у,
что довольно тяжело при полутора тысячах узлов
человек выстроил инфраструктуру, замкнутую на него самого
— все окружающие страдали.meatlink
29.12.2016 20:55+1Очень похоже на классическое — «не читал, но осуждаю».
Все же я считаю, что шелл скрипты вы ругаете необоснованно, каждому инструменту свое место.
Вот, к примеру, задача из недавних.
Мне приходят холодные копии оракловых БД, моя задача — поднять пришедшую БД на сервере solaris на рамдисках заданного размера, проследить, чтобы размер табличных пространств был не менее указанного.
Если меньше — добить табличные пространства файлами, если файлы не помещаются на существующие рамдиски, насоздавать их еще и таки добить файлами на них.
Пересоздать транзакционные журналы в нужной конфигурации и поменять рад настроек в самой БД.
Автоматизация этой задачи — чуть более 300 строк шелл скрипта, который работает с любой БД, любой структуры.
Есть более удобное решение?
С книжкой знаком, благодарю.Termux
30.12.2016 09:50shell script-ы вы ругаете необоснованно,
каждому инструменту свое место.
я ругаю не shell script-ы, а построение на них инфраструктуры.
Вот, к примеру, задача из недавних.
Вы спроектируете роли, задачи, состояния,
короче сделаете свой Ансибль
из
чуть более 300 строк шелл скрипта
а затем с вами что-то случится (найдёте более интересную и высокооплачиваемую работу)
и поддерживать ваш баш никто не сможет.
Он будет падать при любом изменении
и его выкинут, лишь бы не трогать.
Потому что трогать никто не захочет.
Свойства самого баша таковы, что любая программа,
состоящая из более, чем 10 строк,
становится абсолютно нечитаемой.
а если в .sh-скрипте из 30 строк кода нет 50 строк комментариев
— поддерживать такой код через месяц не сможете даже вы сами.
За 300 строчек я сразу увольняю.
Если сотрудник просит 2 недели на поиски работы
— он эти 2 недели переписывает свой bash в современный язык
и покрывает тестами вида
«произвольно выбираем случайный узел и гасим его».
iaon
30.12.2016 14:47Вы, как я вижу, сильно пострадали от баша. Я тоже на самом деле :)
Я однозначно согласен с вами про то что построение инфраструктуры на shell это дорога
в ад. Например в случае с init скриптами этим адом оказался systemd (шутка)
Но все же вы утрируете, 10 строк если не использовать монструозные конвееры это так себе скрипт. В него даже толком не запихать необходимых проверок.
Для себя я вполне допускаю использовать баш в следующих случаях
— стартап скрипты
— простейшие развертывания (удалить, разархивировать, скопировать)
— крон-джобы
Помним что случае разные бывают, не всегда инфраструктура полностью подконтрольна, не везде есть python и пр.
meatlink
30.12.2016 15:07Простыню в 300 строк читать конечно невозможно. Но изливать простыню или нормально структурировать и заботиться о читабельности кода — это ведь выбор автора, а не «свойства баша». Баш предоставляет все средста для реализации обоих подходов.
Вот например книга https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882
В ней конечно речь идет о более «взрослых» языках, но многие идеи можно применять и для написания шелл скриптов.
Нечитабельную простыню можно и на «современном языке» писать с успехом.Termux
30.12.2016 19:06Баш предоставляет все средста для реализации обоих подходов.
Нечитабельную простыню можно и на «современном языке» писать с успехом.
+1
фреймворки — для слабаков!
melchermax
27.12.2016 13:06Интересно, а сколько инженеро-часов было потрачено на создание мегакнопки? Ваяли в рабочее время или дома?
meatlink
27.12.2016 13:13Сначала недели 2-3 почти только этим и занимался.Но тогда еще не было понятно, как собрать систему из кусков. Передо мной стояла задача пройти по всем командам разработчиков, который пишут свои куски, взять у них их часть системы и разобраться, как это все собирать вместе. Записать полученные знания в инструкции итд.
В ходе этого дела, я заскриптовал самые сложные части, чтобы упростить инструкции, жизнь себе и другим инженерам. Когда эти сложные части были заскриптованы — освободившееся благодаря им время частично тратил на улучшение, занимался проектом каждый рабочий день примерно часа по 2-3.

thunderspb
27.12.2016 16:00+3у меня не пальцы, а глаза закровоточили…
Ansible для настройки/деплоя
Jenkins — с правильным подходом позволяет и красивые выпадающие списки с версиями делать (nexus + parametrized build pluginx + groovy scriptler для вытаскивания доступных версий из нексуса)
Если сильно хочется, то есть еще Rundeck с плагинами, собсно оно для этого и предназначено: «Job Scheduler and Runbook Automation». А к Женькинсу есть плагин, который шедулит запуски в рандеке при успешном билде.
mail.ru вообще деплоится самописными скриптами на перле ;)

romangoward
28.12.2016 00:27Прям классика из серии "Кратко о том, почему не стоит работать в ...".
К парням, которые пытались в силу знаний и умений, но хоть как-то решить текучку — вопросов нет: работает и ладно.
А вот чем занимались тим лид и пм по внутренним разработкам? Если их не было, то почему? В крупнейшем интеграторе не хватает специалистов по катанию серверов на оленях? А если были, то почему поделка на уровне фриланса за 3$/час?
Termux
28.12.2016 08:51-1Если бы я был TCO (тех.диром) в КРОКе — я бы ПОДЫСКИВАЛ ЗАМЕНУ
Денису, пишущему велосипеды на shell-скриптах в 2015 г.iaon
28.12.2016 13:30-1Во-первых CTO, а не TCO.
Во-вторых директора интересуют факты работает/не работает и в срок/не в срок. Остальное детали.Termux
28.12.2016 18:48-1да, верно
описался
Во-вторых директора интересуют факты работает/не работает и в срок/не в срок.
вот поэтому у меня и ассоциируются
почти все интеграторы со словосочетанием
«безумно дорогое говно»
и всё что я эксплуатировал после КРОКа и ему подобных контор
было настолькор адски кривым и неюзабельным
(зачастую просто ничего не работало — банально пилили бабки),
что часто возникало желание найти авторов и…
SveChu
29.12.2016 17:50+1А вы к компании КРОК так плохо относились до собеседования или уже после так стали?
Termux
29.12.2016 18:39+2Я ничего не знал о компании КРОК до прихода туда.
На собеседовании я понял, что при достаточно высоких требованиях
рабочий день будет ненормированным
т.е. это было сознательное решение — выжать из человека всё
затем я уже столкнулся с проектами
и «внедрениями» этой компании
и чем дальше — тем хуже.
«Кнопка» — очередной минус,
гвоздь в крышку гроба
a_zaporozhan
29.12.2016 14:08Менеджеров, помимо раобтает/не работает, много чего еще интересовать должно — риски, например, в виде воспроизводимости результата после того как на месте Дениса окажется Петя, или вероятности найти такого Петю, который уже почти в 2017 году спит и видит как бы овладеть чужим велосипедом на shell-скриптах.
iaon
30.12.2016 13:57Вы со своей колокольни судите. Вы на такую позицию не пойдете, я на такую позицию не пойду. Но на самом деле найти человека на shell скриптинг проще чем готового ansible/chef/puppet специалиста. И стоить он будет дешевле.
Изначально мой тезис был про то что CTO не увольняет конкретного исполнителя за говнокод на баше. Увольнять тут скорее нужно лида, архитектора, продакт оунера или кто там у них. В моей практике было полно случаев когда я говорил что так делать нельзя, это нарушение процесса, сейчас может ничего страшного не случится, но мы огребем в конце концов. Но мидл-менеджмент наваливался кучкой и приходилось делать.
Suvitruf
30.12.2016 21:37+1Вообще-то нет. Директор на то и директор, что смотрит на месяца, а то и годы вперёд. Если директор смотрит на ежеминутные результаты и не заглядывает наперёд, то из такой компании лучше валить.
Я не знаю, что там за баш скрипты в кроке, но это один геморрой. И дело не в том, что это нагромождение костылей, как правило, и т.п. Главная проблема таких скриптов в том, что они не идемпотентны.
В случае того же Ansible я уверен, что запуская плейбук, у меня никаких проблем не возникнет. Плюс, в таких системах уже куча готовых модулей, чтоб не велосипедить на баш скриптах это всё.





ksenobayt
Делал что-то похожее на менее масштабном проекте. Удалось обойтись без своих велосипедов, хватило функционала TeamCity, который и дёргал всю гирлянду скриптов или конкретные из них. Вы не думали о нём, к слову?
dbax
или rundeck
ksenobayt
Да даже Дженкинс можно тот же было привинтить.
rauch
Поделитесь опытом — как, а, главное, зачем?
Т.е. на каждый мердж в мастер:
И это на каждый пуш в мастер, я правильно понимаю?
ksenobayt
Как настроите — так будет. Совершенно необязательно после каждого пуша или мерджа сразу же запускать всё это на сборку или деплой — триггеры штука гибкая, и могут работать как вам заблагорассудится. ТС — крайне мощная штука.
К примеру, у меня была гора планов сборки приложения, в зависимости от конкретного объекта, в которую были вложены разные ветки (dev, stable, и так далее). Те, в свою очередь, могли собираться или по временным триггерам (те же ночники), так и после N коммитов, или же вовсе лишь вручную.
Персонально у меня автоматом, как правило, собирался только next-release, стейбл же собирался либо вручную, либо по воскресеньям в ночь на пнд. Деплой можно было к конкретно взятому билду подвесить автоматом после сборки, либо же выполнить вручную.
В общем, всё можно сделать достаточно гибко. Никакого оверхеда и сборки после каждого коммита не было. Что же касается самих скриптов — я предпочитал создавать темплейты из скрипта, распиленного на степы, и потом создавать из них конкретные билды, лишь подменяя параметры в зависимости от стенда. Единократно требовалось бросить ключи на тачку с агента, и после этого всё было в практически однокнопочном режиме.
v_sadist
Вот ДА!
Надо было сделать некий интерфейс для разрабов, чтобы те могли создавать и копировать схемы оракла из прода в дев. Чем писать свой велосипед — сделал несколько джобов, которые читали вводные данные и запускали скрипты.
ksenobayt
Собственно, да. Таким же образом, учитывая то, что все тачки на объектах были типовыми, собранными из OVF-шаблонов, можно было организовать и работу с удалёнкой: к примеру, тостировщик мог не напрягаясь зайти в ТС, ткнуть одну кнопку, и стянуть на нужный стенд свежую оракловую базу (можно было взять как горячую, так и ночной бэкап) с определённого объекта, если он был заведён к нам по VPN.
Всё, полчаса-час ожидания — и можно сидеть и проверять зарепорченный баг. А я могу сходить попить чаю, вместо того, чтоб сидеть тридцать минут в консоли и стучать в клавиатуру, как заведённый щелкунчик.