

Уходящий 2016 год запомнится изобилием ярких новостей о прикладных применениях машинного обучения практически повсеместно. Словно родителям, наблюдающим за первыми неловкими шагами чада, нам с Вами довелось стать свидетелями первых робких попыток слабого искусственного интеллекта читать, писать романы и… даже делать трейлеры к фильмам! Подводя итоги этого насыщенного года, сотрудники Phobos рады добавить в копилку необычных применений машинного обучения приложение в управление проектами.
Когда мир зачарованно наблюдал за победами систем искусственного интеллекта в логических играх и первыми когнитивными успехами сетей гугла в 15 году, наш коллектив уже интересовало приложение существующих технологий для победы в играх управленческих. Сейчас машина ставит мат гроссмейстеру. Значит, однажды, поставит мат неэффективности управления коллективом. Более года тому назад мы решили, что готовы работать, чтобы этот момент приблизить.Тогда мы ещё не понимали к чему это приведет.
Данный материал расскажет о вехах в решении данной задачи практически с нуля:
- Постановка задачи;
- Формализация модели;
- Определение входных и выходных данных;
- Обучение и валидация;
- Тестирование.
Постановка задачи. Рождение «скайнета»
Цель статьи — понятная для человека презентация общей картины решения, включающей ее архитектуру, основного используемого ПО, а также описание наиболее интересных из нестандартных решений не теряя общей картины системы.
В случае наличия спроса будем рады опубликовать более детальные описания по интересующим этапам в отдельные статьи.
Задача отделу машинного обучения нашим руководителем, Алексеем Спасским, была поставлена конкретная — реализовать систему автоматической максимизации эффективности коллектива. Ребята прозвали ее «скайнет».
Нужно было реализовать «виртуального менеджера», умеющего распределять задачи в нашей системе трекинга YouTrack и реагировать на их статус, тип, приоритет и срок. Да так, чтобы эффективность сотрудников возрастала.
Основным методом решения мы выбрали Q-learning относящийся к классу алгоритмов обучения с подкреплением. При таком подходе, интеллектуальному агенту (в данном случае нашему менеджеру «скайнету») необходимо, взаимодействуя с незнакомой ему средой, научится выполнять действия, которые принесут наибольшее вознаграждение обратной связью от среды. Именно таким методом обучают интеллектуальных агентов играть в простые игры лучше человека. Агент совершает действия: сперва хаотичные, на каждом шаге в ответ на действия получает новое состояние среды и числовую оценку действий — кнут, если очки меньше нуля, и пряник, если больше. Делая численные выводы из наград и наказаний, агент учится выбирать действия наиболее вероятно приводящие к самым награждаемым состояниям среды. Одними из интересных успехов применения данного метода была игра в нарды наравне с человеком и пилотирование модели вертолёта.
Моделью генерирующей предсказания действий агента (его мозгом) был выбран многослойный перцептрон или fully connected feed-forward artificial neural network. Почему именно Q-learning на базе deep learning? Это лучшее, что мы смогли найти для решения многопараметрической задачи в игровой постановке.
Формализация модели. Первый виртуальный менеджер
Искушенный читатель, вероятно, уже заметил, что многое из сказанного намеренно упрощенно. Давайте упростим ещё больше для понимания нашей модели.
Итак, на вход «мозга» из искусственных нейронов нашего менеджера «скайнет» мы подаём статистику из системы трекинга по его проекту и исполнителям. Он бьётся в экстазе осознания и на выходе говорит как бы он в данной ситуации поступил с тасками проекта. Теперь нам надо дать числовую оценку его действиям, чтобы методом обратного распространения ошибки, по всем слоям своего многослойного персептрона он смог сделать выводы где был немного не прав. В случае игры, числовая оценка действиям или цепочкам действий агента — игровые очки, которые исчисляются голами, монетками или попаданиями в мишень. В нашем случае для оценки необходимо иметь формализованную бизнес-логику. Другими словами, неплохо было бы иметь «абсолютную формулу безупречного управления» для машинного обучения победителя управляющих игр. Её у нас тогда не было. Но была и есть мудрость наших руководителей, которую мы формализовали в полуэмпирической модели. На формализацию бизнес-процессов и разработку соответствующих метрик ушли месяцы обсуждений. В ней мы хотели выразить именно объективный подход к управлению лишенный любой предвзятости и эмоциональных искажений свойственных всем людям без исключения. Обратите внимание, что при формализации бизнес-логики, психологические управленческие модели не учитывались.
Отбросив философию резюмируем, что мы бы хотели, чтобы наш алгоритм умел находить минимум неэффективности в пространстве управляющих действий для каждого из сотрудников. Но, мало создать формулу неэффективности, нужно ещё найти её минимум.
Обучение модели реализовали посредством mini-batch gradient descent. Не редкость, что в машинном обучении функция потерь (в нашем случае — функция неэффективности) может иметь много локальных минимумов. В какой именно забредет градиентный спуск в поисках дна в итоге определит «стиль управления» нашего менеджера «скайнета», или специфику взаимодействия интеллектуального агента со средой.
Некоторая логика была заложена в модель в более явном виде. К примеру, благодаря нашему менеджеру Лёше для расстановки приоритетов задач использовался метод Эйзенхауэра. Важность и срочность задачи мы учили определять другой модуль системы на основе многослойного перцептрона обученного с учителем. Обучение происходило на данных размеченных менеджерами. Срочные и важные задачи имеют первый приоритет, несрочные и неважные — последний. Мы заложили некоторый порог приоритета, после которого система пишет сообщения в чат. Используя telegram api, она информирует о критических задачах.
Определение входных и выходных данных. Игра на деньги
Основной язык реализации — python. Фреймворк для реализации машинного обучения — TensorFlow, который со временем стал поддерживать не только реализацию сетей, но и Q-learning и serving. Входные данные мы получали и отправляли посредством YouTrack REST API, youtrack-rest-python-library, а также api мессенджеров и почтовиков для которых тоже нашлись библиотеки на python.
В результате, на вход:
- Была установлена система трекинга YouTrack. Дисциплина по отчётам о проделанных задачах ужесточена — теперь отчитываться нужно было о каждом таске, каждой мелочи. Нам нужна была полная статистика. Также ответственные за исполнение задач теперь должны были выставлять оценки исполнителям. Считалась каждая минута просроченных задач или задач на опережение. Время исполнения задачи — весьма влиятельный параметр в оценке эффективности;
- Получали данные о создании спринтов на неделю;
- Время работы сотрудников измеряли по активности рабочих сессиях на машинах.
На выходе:
- Управляющие сигналы в систему постановки тасков: назначение и переназначение задач из уже созданных исполнителю; назначение/переназначение ответственного; установка дедлайнов; создание спринтов на неделю.
Одним из важных управляющих действий был коэффициент корректировки зарплаты на который в конце месяца умножается базовый оклад. Падение коэффициента ниже наперёд заданного порога означало увольнение. В данном случае отправлялось уведомление; - Сообщения особой важности при помощи api telegram транслировались в общий чат. «Важность» задач является одним из ключевых параметров связанным с эффективностью.

Обучение и валидация. Интеллектуальный агент под прикрытием
Каждый проект — отдельная игровая среда взаимодействия с другими агентами (живыми исполнителями проекта). Чтобы обучить интеллектуального агента играть в игру надо понимать в какое именно новое игровое состояние переведут нас действия агента. В случае, если мы обучаем робота — мы можем смоделировать его механику и обучать на матмодели. Но, мы то хотим учить играть с коллективом, а человека, не то что коллектив, пока никому удовлетворительно смоделировать не удавалось, иначе бы… Поэтому учить в нашем случае можно было только на реальном взаимодействии с не виртуальной средой. Но, чтобы исключить «квантовые эффекты» — изменение наблюдаемого под влиянием наблюдателя, агент получал на обучение случайные таски и никто не знал заранее искусственный или естественный интеллект сейчас ведёт его задачу. Эдакий тайный санта.
Другими словами, агент должен знать как человеки ведут себя в естественной среде, иначе не избежать обмана. Первым делом они могут сказать, что задача на день, а делов на 30 минут. Оценка времени задачи в отличие от «срочности» и «важности» в отдельном модуле не производилась. Валидация проводилась также на случайной выборке задач с измерением метрик эффективности, затем задачи снова выбирались случайно и значение эффективности усредняется по всем выборкам.
Тестирование. Сомнительный эксперимент
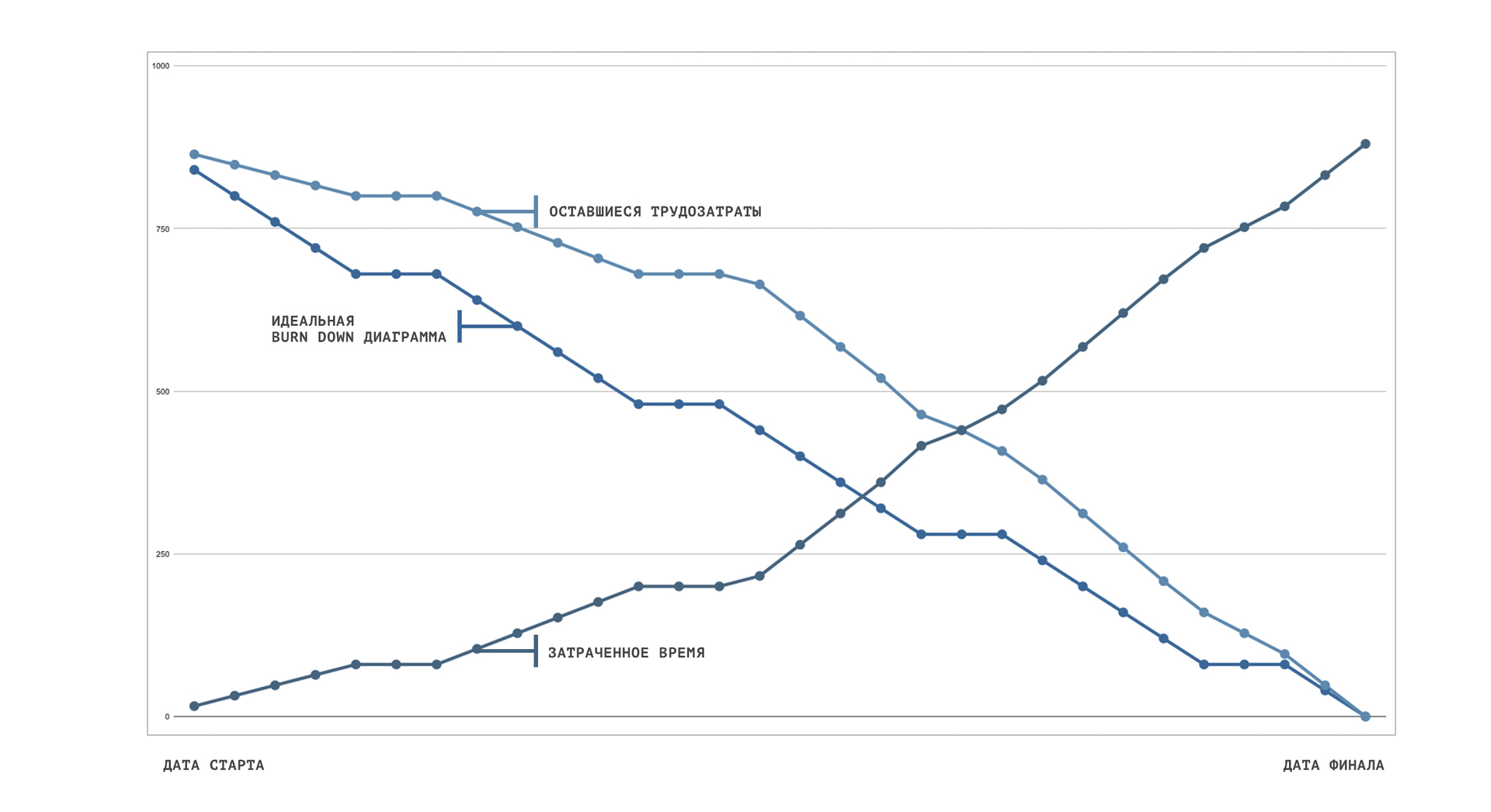
Однажды утром мы проснулись с осознанием того, что месяц нами будет управлять специально обученный нами же большой брат. Наша работа будет управлять нашей работой. Отзывы испытуемых и результаты тестирования найдёте в статье «Как мы на месяц перевели команду под управление искусственного интеллекта». Выводы о своевременности и успешности эксперимента в целом предлагаем читателям сделать самостоятельно. На графике представлены результаты тестирования в часах.
Комментарии (7)

Dum_spiro_spero
21.01.2017 00:23+1Выводы о своевременности и успешности эксперимента в целом предлагаем читателям сделать самостоятельно
… а кто убийца читатель может сообразить сам, на основании всех улик собранных Шерлоком…
Самое интересное — это как раз результаты и их трактовка в психологическом аспекте.
funca
22.01.2017 14:03+2месяц нами будет управлять специально обученный нами же большой брат
Судя по графику они сначала вдвоем фигачили таски по 8 часов в сутки. На второй неделе стали работать по 9. Потом, в понедельник, менеджерский интеллект прикинул, что прошло полмесяца, а работы эта зондер-команда сделала заметно меньше половины и для повышения мотивации одного уволил. Но потом видимо посчитал, что оставшиеся 650 часов до конца месяца в одного не выработать ну хоть ты тресни. Поэтому на следующий день нанял еще двоих, и перевел всех на казарменное положение. Поэтому до конца месяца они уже работали без выходных по 14 часов и все успели.
Hellsy22
21.01.2017 05:43Чтобы сделать выводы об успешности эксперимента, нужно знать чем конкретно занимается компания и кем именно управляет ИИ. Потому как если речь идет о небольших задачах, не требующих высокой квалификации, то ваш подход может дать прирост эффективности… пока биологический ИИ не нащупает максимально эффективные формальные способы удовлетворения требований.
В случае же средних и крупных проектов, требующих высококвалифицированных специалистов, боюсь, подобные требования к отчетности и фокусы с зарплатой могут очень дорого обойтись компании в среднесрочной перспективе и стать фатальными в долгосрочной. К примеру, я не отправил бы вам резюме ни при каких обстоятельствах, поскольку, согласно моему опыту, нет ничего более отвратительного, беспомощного и контрпродуктивного, чем избыточный контроль.
funca
22.01.2017 13:11+1Скайнет задумывался несомненно как более гуманная штуковина, потому, что он управлял роботами, а не человеками. А вот то, что вы тут описали в 2032 году, вероятно, будет назваться АСГУ и для повышения эффективности коллектива немного постреляет ядерными ракетами. Ей там как раз 16 исполнится. :)


Marsikus
Как хорошо такие эксперименты подходят к названию вашей компании.