
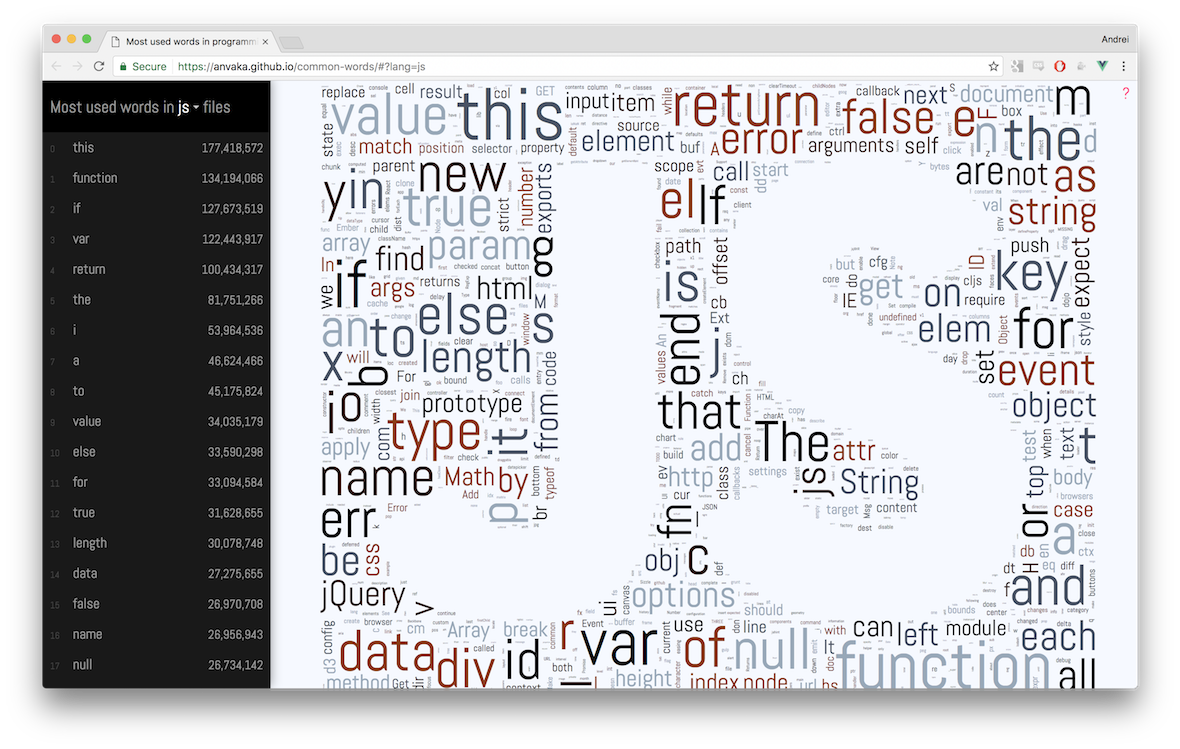
Сайт находится здесь, а его исходники можно почитать на гитхабе.
Под катом описано в деталях о том как собирались данные, как строился сайт и как укладывались облака. И немножко наблюдений.
Приятного чтения!
Наблюдения
- Самым популярным текстом во всех языках программирования был текст из лицензий. Среди всех языков Java здесь победила. Из 966 самых популярных слов, 127 были о лицензии:

Наверное, культура добавления лицензий в каждый .java файл гораздо сильнее чем в других языках. Вы видели официальный hello world?
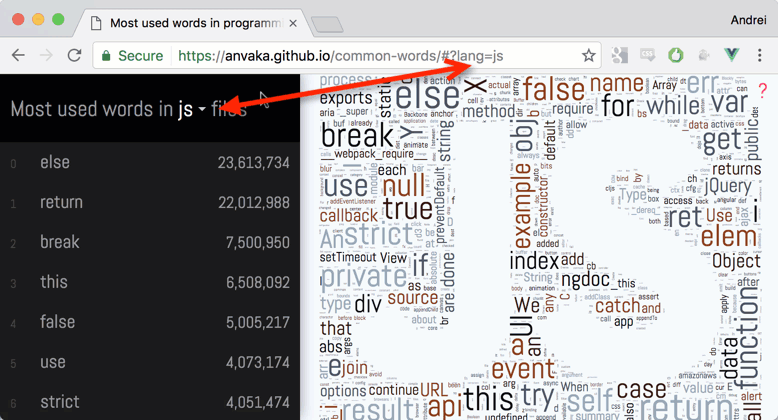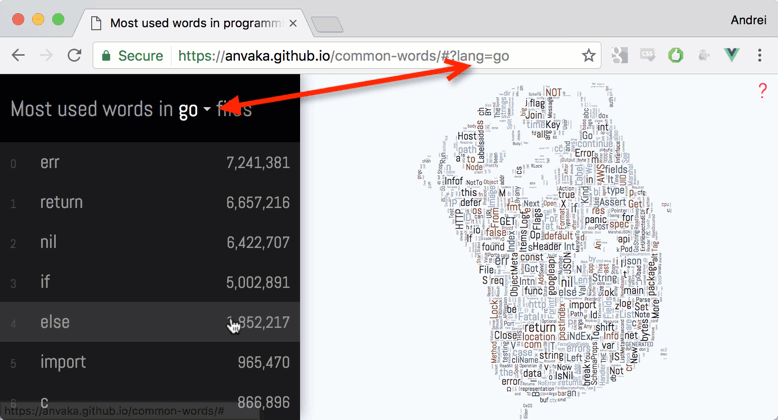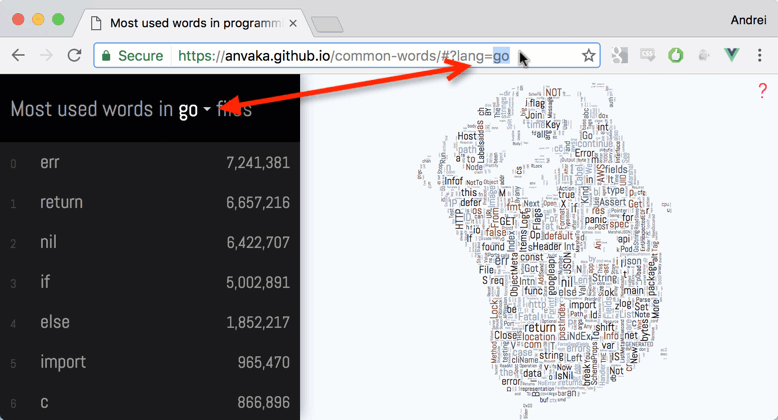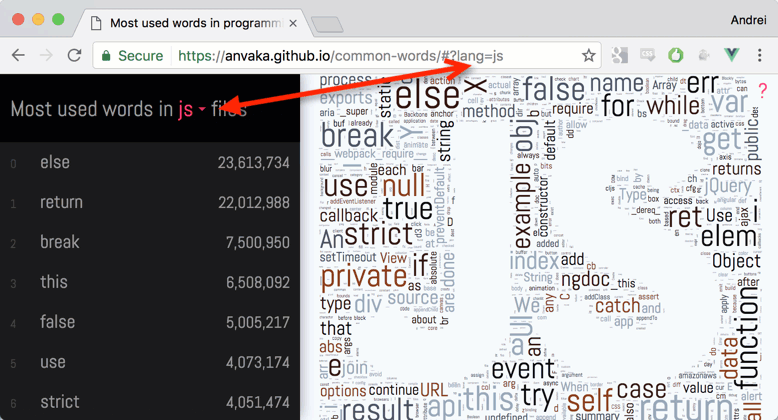
Lua— единственный язык программирования в котором нецензурное слово вошло в топ. Можете найти?
- В Go самым популярным словом оказалось
err. В этом языке нет исключений?
Как?
Данные я собирал с помощью BigQuery. Google, совместно с GitHub'ом, выложили полный снимок исходников в публичный дата сет github_repos. Индекс был построен в конце 2016 года.
При построении облаков я накладываю некоторые ограничения на данные:
- Максимальная длина строки со словом не должна превышать 120 символов. Это помогает избавиться от сгенерированного кода (например, в минифицированном javascript'е).
- Пунктуация (
, ; : .), операторы (+ - * ...) и числа игнорируются. Например, строкаa + b + 42будет посчитана как два словаaиb - Поскольку текст лицензий перегружал визуализации, я убрал все строки в которых есть слова-маркеры, специфичные для лицензий (например,
license,noninfringementи так далее...) - Регистр слов учитывается.
Thisиthisсчитаются двумя разными словами.
Как собирались данные?
BigQuery — потрясающая платформа. Содержимое всех файлов из гитхаба хранится прямым текстом в таблицах.
| Файл | Содержимое |
|---|---|
| File 1.h | // File 1 content\n#ifndef FOO\n#define FOO... |
| File 2.h | // File 2 content\n#ifndef BAR\n#define BAR... |
BigQuery позволяет написать обычный SQL запрос и выполнить его с изумительной скоростью.
Сначала я решил разбить содержимое всех файлов на слова, и потом использовать
GROUP BY чтобы посчитать их. | Слово | Сколько раз встретил |
|---|---|
| File | 2 |
| content | 2 |
| ... | ... |
К сожалению, такой подход вырывает слово из контекста. Мне же очень хотелось показывать слова с примерами как они используются:

Как же быть? Вместо простого разбиения на слова я создал промежуточную таблицу, где файлы разбиты построчно:
| Строка | Сколько раз встретил строку |
|---|---|
| // File 1 content | 1 |
| #ifndef FOO | 1 |
| #ifndef FOO | 1 |
| ... | ... |
Такое промежуточное хранение позволяет сократить размер обрабатываемых данных с ~2TB до ~12GB.
Теперь, чтобы получить самые популярные слова из этой таблицы, мы можем разбить каждую строку на индивидуальные слова, но при этом сохранить изначальную строку:
| Строка | Слово |
|---|---|
| // File 1 content | File |
| // File 1 content | content |
| #ifndef FOO | ifndef |
| #define FOO | FOO |
| ... | ... |
Казалось бы, практически ничего не изменилось. Но, в такой интерпретации мы можем использовать оконные функции чтобы получить топ 10 строк по каждому слову (
SELECT ... OVER (PARTITION BY ...) — как в этом вопросе на StackOverflow).Текущий код запроса можно найти здесь: extract_words.sql.
Кстати... Мой SQL находится на весьма начальном уровне. Потому если вы, дорогой читатель, обнаружите ошибку, или знаете более подходящий способ — пожалуйста, дайте мне знать.
Как рисовать облако тегов?
В основе всех известных мне отрисовщиков тегов лежит такой алгоритм:
Для каждого слова `w`:
Шаг 1. Попробовать нарисовать`w` в случайной точке (x, y)
Шаг 2. Если слово пересекает любое другое слово - повторить Шаг 1.Этот код может выполняться бесконечно, потому мы либо прекращаем пытаться после нескольких итераций, либо уменьшаем размер шрифта до тех пор пока слово не поместится.
Для простоты, слова можно рассматривать как прямоугольники. Мы пытаемся разместить все прямоугольники на экране так, чтобы ни один прямоугольник не пересекал занятые пиксели на экране.
Самой ресурсоёмкой частью этого алгоритма является проверка пересечений. Особенно в конце, когда все свободное пространство в основном уже занято, найти новую область куда можно вставить слово становится очень сложно (а иногда и не возможно).
Разные имплементации пытаются ускорить эту часть алгоритма индексированием занятого пространства
- Некоторые используют Summed area table. Это специальная структура данных, которая позволяет за время
O(1)сказать или пересекает новый прямоугольник что-то на экране. К сожалению, структуру нужно обновлять после изменений на экране, что дает посредственную производительность.
- Я видел кое-кто использовал разновидности R-деревьев, чтобы индексировать занятое пространство. В таком подходе поиск пересечений работает медленнее, чем с Summed Area Tables, но зато поддержание индекса работает быстрее. Однако же реализация R-деревьев — не самая тривиальная задача.
Я хотел попробовать что-то другое. Вместо индексирования занятого пространства, я хотел иметь индекс свободной области. Чтобы можно сразу выбрать большой прямоугольник в котором гарантированно найдется место для нового поступления.
Для индекса я воспользовался квад-деревом. Каждый промежуточный узел дерева хранит информацию о том, сколько в нем свободных/занятых пикселей. Так можно мгновенно отметать квадранты, в которых недостаточно свободных пикселей.
Проще всего это видеть на картинке. Вот квад-дерево логотипа JS:

Белые пустые прямоугольники — это свободное пространство. Если нужно добавить новый прямоугольник который меньше чем любой из этих пустых прямоугольников — мы можем смело его там рисовать.
Этот подход дает неплохие результаты, но может привести к визуальным артифактам. Ведь ни один новый прямоугольник не может находится на пересечении квадрантов:

Более того, что если ни один из свободных квадрантов не обладает достаточным размером? А при этом если смежные квадранты объединить, то места достаточно?
Объединение свободных квадрантов и был мой следующий шаг. Я просто «расширяю» квады влево/вправо от цели. Это немножко замедляет время построения, но уменьшает артефакты и дает лучше результаты:

Кстати... Мой код укладчика не доступен вместе с сайтом. Он был написан на скорую руку и его сложно использовать в других контекстах. Если вам нужен хороший укладчик, посмотрите на
amueller/word_cloud
Как был сделан сайт?
Отрисовка текста
В целом я был доволен скоростью постройки облака тегов. Но в контексте моего сайта этой скорости было не достаточно.
Я использовал SVG чтобы рисовать слова на экране. Сама отрисовка стольких текстовых SVG элементов может легко заблокировать UI поток на несколько секунд. Куда уж тут еще позиции считать для облака тегов?
К счастью, можно убрать укладчик в оффлайн. Вместо того чтобы считать позиции слов на лету, когда браузер открывает страницу, я решил посчитать позиции один раз, сохранить их в файл, и потом рисовать по статике. Это нам позволяет сфокусировать на оптимизации UI потока.
Чтобы не блокировать браузер на длительные промежутки времени, нужно разбить всю работу на маленькие кусочки, и выполнять ее асинхронно. На одной итерации цикла событий мы добавляем N слов и выходим из функции, чтобы браузер смог обработать другие события. На следующей итерации мы добавляем еще слов, и так далее.
Для этих целей я написал anvaka/rafor. Эта библиотека представляет собой адаптивный, асинхронный цикл `for` на основе
requestAnimationFrame(). Все итерации выполняются на разных этапах цикла событий, и тем самым снижается нагрузка на UI поток. Начальная загрузка сайта выглядит более плавной.Навигация и зум
С помощью мышки, клавиатуры или touch-screen'a вы можете приближать, удалять карту и двигать ее по экрану точно так же, как это делает Google Maps. Все это делается при помощи библиотеки panzoom.
Модель приложения
Я использую vue.js для UI. Она простая в использовании и быстрая в работе. Особенно здорово иметь vue-компоненты в отдельных файлах — не приходится часто переключаться между js/разметкой/стилями. Hot-reload делает разработку особенно приятной.
Состояние приложения хранится в одном объекте appState. Когда вы выбираете язык программирования — слова и их контекст загружаются асинхронно.
Для обмена событиями между компонентами я использую свою мини-библиотеку ngraph.events. Изначально я сделал ее для скоростного обмена событиями в моих библиотеках графов. Но и здесь она работает отлично как диспатчер.
Наконец, anvaka/query-state привязывает строку запроса двунаправленным байндингом к выбору языка программирования
В заключение
Этот проект был моим вечерним хобби на протяжении последних двух месяцев. Не смотря на все недостатки облаков тегов, мне было очень интересно.
Я искренне надеюсь, что вам тоже понравилось это исследование :)!
Спасибо, дорогой читатель, за ваше внимание. И отдельное спасибо моей половинке за ее бесконечную поддержку и подсказки.
Комментарии (65)

scronheim
25.01.2017 07:19Lua — единственный язык программирования в котором нецензурное слово вошло в топ. Можете найти?
Нашел слово на букву F :) а чуть ниже Mohammed
Crystal_HMR
25.01.2017 17:12Я тоже нашел, но у меня по просмотру контекста созрел вопрос о том, кто же эти ребята, которые наштамповали 40k этих слов :D Как какие-то школьники, и вправду


FForth
25.01.2017 07:46Не увидел какой нибудь статистики по конкатенавным языкам и в частности Forth (Форт) :)
P.S. т.е. работа будет продолжаться? или название статьи корректироваться?anvaka
25.01.2017 07:59Сейчас классификатор языков полностью полагается на расширение файла. Если язык программирования уникально идентифицируется расширением, его легко добавить к списку. В случае Forth'a, расширение .fs пересекается с F#, FilterScript и GLSL.
Можно ли использовать .forth, .frt и .4th как основные расширения для этого языка?FForth
25.01.2017 08:22Лучше полагаться на контекст файла т.к. даже Github раньше по расширению .f относил данные файлы к Фортран языку. .forth .frt .4th вполне могут относится к Форт или Форто подобным языкам. Расширение .spf к SP-Forth может быть соотнесено. Ещё не учитываемый момент — это когда на языке (например Си) реализуется какой нибудь вариант Форт языка, но при этом Forth (Форт) тег не появляется в классификации проекта на Github.
P.S. «Знаки» препинания (:;. ) значимые слова в Форт :)
Ассемблеры планируется добавить в проект.
atikhonov
25.01.2017 09:29А можете добавить R? расширение такое же.
anvaka
25.01.2017 11:31+1Добавил. С R могут быть не совсем аккуратные результаты. Rebol использует такое же расширение. И ресурсные файлы тоже… Дайте, пожалуйста, знать если что-то будет выглядеть совсем неправдоподобно.
atikhonov
25.01.2017 11:46Спасибо! Похоже на правду, только много попаданий универсальных слов — the, in, is из строк комментариев (начинающихся с #)
aGGre55or
25.01.2017 11:19Не увидел bash (.sh). Из ассемблеров были бы интересны m68k (.s) и z80 (.$H, $R).
FForth
25.01.2017 09:21Хорошо бы было, если информацию по словам в комментариях можно было бы отключать
и иметь более подробный контекст вывода применения того или иного слова (с расширением колонки или вывода в основную зону)reforms
25.01.2017 21:49Хорошо бы еще добавить информацию о среднем кол-ве вхождений слова в 1 файле, например, return — 68,848,062 + в среднем 10 раз в 1 файле и общее кол-во проанализированных файлов одного типа.




delvin-fil
25.01.2017 10:13-2Мдя, на assm теперь не пишут…
FForth
25.01.2017 10:51Пишут, но не так массово и проекты не обязательно располагают на Github,
есть ещё также, например, на sourceforge. «Массовый» проект на ассемблере — Kolibri OS расположен на своей площадке. Ассемблерные файлы встречаются в тех или иных проектах.
P.S. С расширением ассемблерных файлов могут быть нестыковки и ассемблеры бывают такие разные
и для разных процессоров (контроллеров). Одно из расширений на Github .s
delvin-fil
25.01.2017 11:21-5Ждал минуса и дождался. :)
FForth
25.01.2017 15:06+2Специально для минусующих: в направлении «дискредитации» ассемблерного и не только языка :)
Десять мнений: какой язык программирования учить первым/


Ogra
25.01.2017 11:01Elixir есть, а Эрланга нет, жалко.
FForth
25.01.2017 11:23Многих нет языков, даже по классификации Github, например VHDL, VERILOG,
А, если посмотреть сколько языков представлено на текущий момент в проекте rosettacode то коллизий по расширению файлов заметно добавится. Про «экзотику» типа HiAsm можно даже не упоминать. :)
P.S. Была какая то библиотечка представлена на Github по распознаванию языков программирования в недавних новостях.anvaka
25.01.2017 11:35Не эта https://github.com/github/linguist?
Было бы здорово иметь такую модель на javascript'e. Тогда можно было бы проводить классификацию прямо на BigQuery, как user-defined function.FForth
25.01.2017 13:36Да, вероятно эта библиотека.
С использованием javascript, возможно, может оказаться полезным такой проект https://github.com/isagalaev/highlight.js (автоматического определения и подсветки языка)
Anarions
25.01.2017 11:32Вы ещё какие-то диалоги запарсили — поэтому много «разговорного» тескста пробилось близко к топу.
anvaka
25.01.2017 11:34О каком языке идет речь?
В целом, я не делаю никакого структурного анализа кода. Только разбиваю на строки/слова и веду подсчет. Файлы группируются по расширению — здесь могут быть неточности и коллизии между языками.


Deosis
25.01.2017 12:17В Go самым популярным словом оказалось err. В этом языке нет исключений?
В Go принято возвращать 2 значения: результат и ошибку.
Кстати, это единственный язык, в котором название переменной оказалось популярнее ключевых слов. (либо я не заметил другие)
Также The стабильно держится в лидерах, жаль, что только из-за комментариев.
Стоит собрать статистику без ключевых слов, так как они занимают половину верхних позиций.

DaneSoul
25.01.2017 12:52В левой колонке логичней было бы не общее количество для слова указывать, а его частоту среди всех выделенных слов языка.
И графики таких частот были бы весьма интересны — насколько плавно убывает частота использования.



reforms
25.01.2017 17:12Позволю себе свои измышления по поводу языка java, согласно:
1. import=102,703,904 2. return=68,848,062 3. public=63,437,224 4. if=48,541,265 5. the=48,123,547 6. org=41,378,185 7. String=38,064,156 8. this=36,756,897 9. new=36,359,075 10. null=34,932,524 11. int=32,221,928 12. java=32,155,509 13. void=27,724,726 14. i=26,995,773 15. Override=26,626,591
Самый популярный тип — java.lang.String;
Самый популярный примитивный тип int;
Самая популярная конструкция — if, куда же без них;
Значимое количество методов не возвращающих ничего void,
Самое распрастраненное наименование переменной i — циклы рулят;
Самое распрастраненное слово в java-doc the
В java больше открытого public чем закрытого(private) и наследуемого(protected)
Конечно есть нюансы, но куда без них :)
За статью спасибо.
Mingun
25.01.2017 19:13Судя по 15-й позиции ещё иерархии довольно большие, много переопределённых методов:
@Override void someMethodName();reforms
26.01.2017 10:01+1Это Вы хорошо подметили.
Вот еще несколько выводов, опять же с допущениями:
Часто встречаемая ошибка — IOException
Java классы довольно хорошо докумнтированны
Литералов true и false примерно одинаково (12,989,940/12,745,131)
Java пронизана языками и технологиями:
— SQL / JDBC
— XML / JSON
— Regexp
— JUnit /
Не плохо покрыта тестами

firegurafiku
25.01.2017 18:04Пунктуация, операторы и числа игнорируются.
Тем не менее, в топ языка Lua вкралось число
0x00(неужели в языке, где нет встроенных побитовых операций, так часто используются шестнадцатеричные константы?).

anvaka
25.01.2017 18:34Наверное, мне стоило уточнить, что только в десятеричной системе числа игнорируются.
Если на гитхабе поискать 0x00 extension:lua то можно найти примеры
Mingun
26.01.2017 17:48Тем не менее, в топ языка Lua вкралось число 0x00 (неужели в языке, где нет встроенных побитовых операций, так часто используются шестнадцатеричные константы?).
Судя по всему (и по ссылке из соседнего комментария), Lua активно используется в интернете вещей, что в принципе логично, ведь его интерпретатор очень маленький и написан на C, а значит его можно портировать практически куда угодно. Практически везде константа
0x00является частью каких-то двоичных данных, вероятнее всего, прошивки.

marliotto
25.01.2017 18:43В плане развития можно еще сделать разбитие по области применения слов.
Т.е. имена классов, функций, переменных.
Я иногда, чтобы определиться с именем класса/функции делаю поиск по гитхабу, какое название чаще используется, то у себя и использую

1111paha1111
25.01.2017 21:18+1Только начал читать и мелькнула мысль о том кто мог бы быть автор. И не ошибся. Шедеврально! Очень познавательно, спасибо за труды!
namwen
25.01.2017 21:42+1Очень круто, но было бы правильно найти способ скипать комментарии (понимаю, что практически невозможно) — из-за них слишком сильно меняется расклад. К примеру, самое популярное слово в C# — summary (а это документация через ///), а так же «to», «the» — что однозначно из комментариев и в таком духе. Но проект даже в таком виде — вау.


drcolombo
26.01.2017 18:29Не для холивара, конечно, но первая же ссылка в статье ведет на список слов в JavaScript. Как-то автоматически промотал в конец — самое не популярное слово validate :) Не любят веб-девелоперы валидировать на стороне клиента ничего, походу :)
maisvendoo
Как-то странно — то что в паскале самое популярное слово end, это и ежу понятно, но почему такой отрыв аж в 600k от begin, они ведь всегда ходят парой?
anvaka
Есть предположение, что if-then-else-end блоки добавляют к популярности end'a
Ivan_Kotov
Там такой конструкции вроде нет, зато есть case-end
mgouline
Еще try-finally-end.
anvaka
Интересно! Спасибо за поправки!
maisvendoo
Точно. Тогда вопрос снят
Danik-ik
Открывать блок, который кончается на end, в Паскале могут, навскидку:
Begin
try
Case
Record
Class
Object (да, было и такое)
… и, бонусом:
Program
Unit
Danik-ik
То есть про program я ступил, там есть begin
Danik-ik
Зато есть ещё library