
Чтобы объяснить, что такое высокоскоростной интерфейс TWIME, придется начать издалека. То, чем торгуют на бирже называется торговым инструментом — у него есть цена и его можно купить или продать. Торговым инструментом может быть, например, баррель нефти, акция Сбербанка или пара валют. Срочный рынок — это сегмент Московской биржи, на котором торгуют производными инструментами (деривативами) – фьючерсами и опционами.
Основная функция биржи —принимать заявки на покупку/продажу торговых инструментов, сводить заявки в сделку по строгим правилам и выдавать информацию о совершенных сделках.
Соответственно, у бирж бывает несколько типов интерфейсов. Торговые интерфейсы позволяют совершать сделки и получать оперативную информацию о совершенных сделках. Именно торговые интерфейсы биржи наиболее критичны ко времени отклика. Реализующий протокол TWIME шлюз — это новый, самый быстрый, торговый интерфейс к срочному рынку.
Прежде чем ответить на вопрос, как нам удалось ускорить доступ на биржу, мы расскажем, зачем это нужно было делать.
Когда-то давно заявки биржи принимались по телефону. Сведение заявок происходило в ручном режиме. Latency от выставления до сведения заявок в сделку исчислялось секундами, а то и минутами.
В настоящее время заявки биржа принимает по оптическим каналам связи лучших российских ЦОДов, а сведение происходит на лучшем «железе». Соответственно, время выставления заявок сейчас составляет десятки микросекунд. Согласитесь, тренд на снижение времени выставления заявки налицо.
В первую очередь, такая необходимость вызвана конкуренцией бирж. Клиенты хотят выставить заявку как можно быстрее, чтобы опередить других клиентов, причем, опередить на всех биржах стразу. Такой подход позволяет совершать сделки по лучшей цене, когда цена движется. При этом, по большому счету, неважно как долго сводится заявка внутри системы. Главное успеть занять очередь раньше конкурентов.
Зачем бирже нужна низкая latency?
Не секрет, что биржа получает доход с каждой сделки, попавшей в книгу активных заявок. Тарифы, конечно, меняются и различаются на разных рынках, биржах, но все они похожи в том, что чем больше пропускная способность, тем больше операций совершается и денег зарабатывается.
Со временем отклика все сложнее. Бирже нужно ровное, без всплесков, время отклика. Так как иначе нарушается принцип «Fair Play». Если у одного пользователя заявка выставилась за Х мкс, а у другого за 10Х мкс, и при этом задержка произошла именно на стороне биржи, то появляется угроза упущенной прибыли, что сильно огорчает трейдера. Невозможно сделать время отклика строго одинаковым у всех, свести дисперсию latency к 0, однако всегда следует к стремиться такому показателю.
Важна ли медиана времени отклика для биржи? Для клиентов медиана важна только если она не отличается от медианы других клиентов. В противном случае она не существенна. Один из последних трендов в биржестроении — это когда биржа замедляет сама себя. Начался такой тренд с небезызвестной книги Майкла Льюиса “Flash Boys” и продолжился летом 2016го, когда SEC (Securities and Exchange Commission) приняла решение сделать одну из таких замедленных бирж публичной.
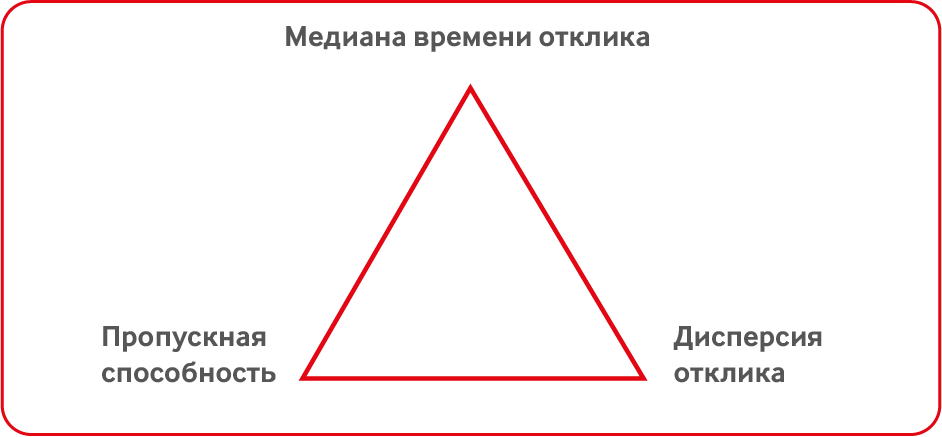
Важна ли медиана времени отклика для биржи? Этот вопрос остается открытым. Как правило, приходится искать компромисс между пропускной способностью, медианой и дисперсией latency. Например, отключение алгоритма Нейгла уменьшает медиану, но уменьшает и пропускную способность. Таких примеров можно привести много.
Какие торговые интерфейсы есть у срочного рынка? Об этом мы писали в нашем блоге ранее, поэтому повторим лишь в общих чертах.
Раньше самым быстрым интерфейсом был CGate API – набор библиотек с единым API. CGate общается с биржей через закрытый внутренний протокол биржи. Хотя этот интерфейс и самый быстрый, но, так как его протокол закрыт и требуется линковка с библиотекой, то возникают естественные ограничения по поддерживаемым языкам и платформам, и нет возможности использовать FPGA, чего хотели бы многие наши клиенты.
Еще один торговый интерфейс — FIX. Он довольно удобен для клиентов, так как протокол FIX — это старый, проверенный временем стандарт для выставления заявок. Под него создано огромное количество библиотек и FPGA-решений. К сожалению, на срочном рынке этот интерфейс несколько медленнее CGate.
И большинство клиентов естественно предпочитали CGate. Теперь мы разработали новый интерфейс, он быстрее CGate, не требует линковки, годится для FPGA, при этом в его разработке использованы самые передовые отраслевые стандарты – и имя ему TWIME (Trading Wire Interface for Moscow Exchange).
Как нам удалось уменьшить время отклика?
Мы провели кропотливый анализ имеющихся биржевых интерфейсов. Работа продолжалась все лето 2015 года. К осени у нас был готовый прототип, который показывал latency в 10 мкс в сторону ядра. Это было на порядок быстрее самого быстрого на тот момент интерфейса. К декабрю мы запустили паблик тест, а в апреле началась полноценная эксплуатация.
При разработке наиболее быстрого интерфейса мы сосредоточились на трех аспектах:
- Архитектура системы, концептуальные изменения в интерфейсах.
- Новый протокол, который взял лучшее от предшественников.
- Алгоритмы – частные улучшения в реализации логики шлюза.
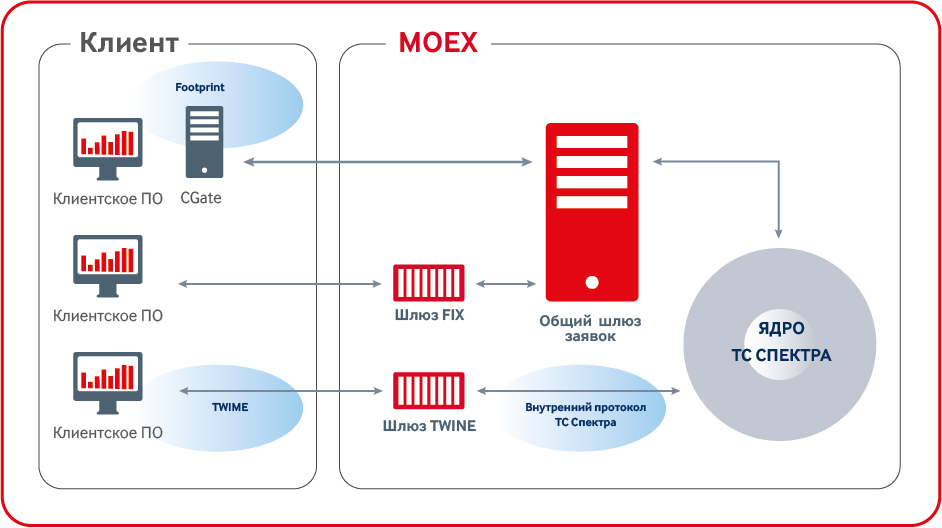
Мы срезали углы в архитектуре. Самый большой угол — это общий шлюз заявок, через который раньше проходили все сообщения в ядро, в том числе и нечувствительные ко времени отклика, так называемые неторговые приказы. Этот шлюз выполняет функции мониторинга, аутентификации и flood-контроля. В итоге мы реализовали нужную функциональность внутри нашего шлюза TWIME, а лишнюю выкинули. Таким образом получилось избежать лишнего хопа в сети, так как обычно общий шлюз и ядро располагались на разных боксах.
Мы запрещаем подключаться к бирже через шлюз TWIME (посылать TCP SYN) чаще, чем раз в секунду с одного адреса. Это позволило сократить ущерб от неправильно написанных клиентских приложений и попыток злонамеренного ущерба.
В новом шлюзе мы используем выставление заявок по численному идентификатору, это немного усложняет нашим клиентам получение правильного идентификатора инструмента, но позволяет уменьшить наши сообщения.
При разработке нового торгового протокола мы использовали рекомендации Fix Community, сообщества организаций, заинтересованных в унификации доступа к различным торговым площадкам.
За основу нашего сессионного уровня мы взяли FIXP, на презентационном уровне мы используем SBE, а уровень приложений с одной стороны для эффективности максимально приближен к внутреннему формату сообщений ядра торговой системы, а с другой стороны использует семантику FIX. В результате получился очень простой для реализации клиентов протокол. Мы получили положительные отзывы от производителей решений для торговли на основе FPGA.
Бирж много, их сотни, участникам торгов получается дорого поддерживать зоопарк из протоколов. Простота и унифицированность нашего протокола позволяет надеяться, что клиенты TWIME смогут использовать более передовое железо и тратить время разработчиков на оптимизацию, а не на реализацию нестандартных протоколов.
Кто-нибудь использовал Google ProtoBuf? На некоторых тестах SBE показывает ускорение в десятки раз по сравнению с GPB. SBE — это как структуры языка С, которые отправляются в сеть «как есть», путем передачи в системный вызов send указателя на структуру и sizeof структуры. Соответственно, сериализация и десериализация является просто С-style cast во время компиляции. На самом деле все чуть сложнее, но достоинства и недостатки такого подхода, думаю, понятны.
Каждое сообщение в TWIME имеет фиксированный размер. Первое поле в каждом сообщении — размер сообщения без заголовка, а второе — идентификатор типа сообщения – структуры. По типу сообщения можно однозначно получить длину, но это был бы лишний switch, что долго. Еще два поля в заголовке — это идентификатор схемы и версия схемы. Это все стандартный заголовок SBE. Дальше идут поля бизнес логики: цена, инструмент, клиентский счет.
Протокол более эффективен, чем FIX, потому что у нас используется бинарное кодирование. Например, в FIX время с точностью до миллисекунд занимает 19 байт, в TWIME время с точностью до наносекунды занимает 8 байт. Это количество наносекунд от юниксовой эпохи.
Так же он более эффективен, чем внутренний протокол биржи (Plaza2), размер сообщений у нас меньше в среднем в 4 раза за счет отсутствия внутренних полей ядра.
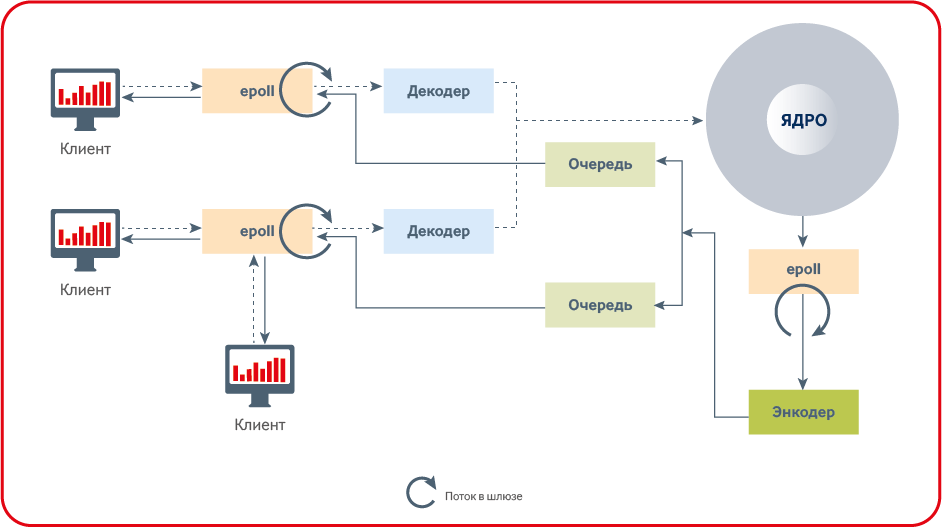
Самый главный секрет низкой latency заключается в отсутствии блокировок на критическом пути.
Мьютексы не могут использоваться в low-latency приложениях на критичном пути, так как время одного слайса времени (минимальное время выделяемое ОС программам) планировщика ОС обычно больше время обработки заявки. Выделение памяти не может производиться на критическом пути так как там используется мьютекс.
Количество контекст свитчей необходимо сводить к минимуму с помощью affinity и realtime scheduling. В идеале – лучше вообще не иметь context-switch для рабочих потоков.
Кому-то это может показаться банальностью, но отсутствие мьютексов и выделений памяти на критическом пути, а также сведение переключений контекста к минимуму — необходимое условие успеха low-latency приложения.

Одна из оптимизаций, которую мы сделали, касается работы с heartbeat. Значительная часть наших клиентов постоянно в течение дня присылают и получают сообщения, в таком случае сразу видно, что клиент активен и heartbeat не нужен. Мы требуем, чтобы клиент присылал heartbeat только в отсутствие прочих сообщений.
Разрыв сессии по пропущенному heartbeat очень важен для клиентов биржи. Так как есть возможность заранее попросить биржу отменить все заявки в случае разрыва соединения.
Поэтому алгоритм, который используется в других интерфейсах требует перерегистрацию события по таймеру на каждом сообщении. Что в свою очередь означает необходимость вытащить событие по таймеру из хипа реактора и добавить новое событие в хип (и это на каждое новое сообщение от клиента!).
В новом шлюзе мы пошли по другому пути. При подключении нового пользователя у нас регистрируется событие по таймеру на реакторе. На каждое сообщение от клиента взводится флаг о том, что сообщение было. При срабатывании события по таймеру мы проверяем флаг и опускаем его. Если флаг не был поднят — клиент отключается с ошибкой, что пропущен heartbeat.
Такой подход не позволяет точно вызвать событие ровно через определенный интервал после последнего сообщения. Поэтому новый шлюз отключает клиентов в течение отрезка от одного до двух интервалов после последнего полученного сообщения. Это тот компромисс, на который мы решили пойти ради ускорения работы шлюза.
Каждое сообщение, которое клиент присылает на биржу, по сути, является официальным документом, который надо сохранить и обработать. В какой момент считается, что сообщение пришло на биржу? Сообщение считается технически пришедшим на биржу, если оно было подтверждено TCP ACK.
Получается, в случае чрезмерной нагрузки на биржу есть несколько путей, что можно делать с сообщениями. Игнорировать их нельзя, отклонить без веской причины тоже нельзя, можно накапливать в памяти, например, класть в очередь в оперативной памяти. Так вел себя общий шлюз заявок. Не самый эффективный способ работы с сообщениями, может потребоваться много памяти и лишние копирования сообщений.
В новом шлюзе мы пошли по другому пути, мы читаем из сокетных буферов только те сообщения, которые можем обработать. В случае большой нагрузки на шлюз забьется TCP буфер на стороне сервера и клиентам перестанут приходить TCP ACK сообщения. Таким образом клиент при забитых буферах и асинхронных сокетах получит ошибку EAGAIN и сможет сам принять решение о том стоит ли в ситуации чрезмерной нагрузки на биржу продолжать торговать как прежде или сменить стратегию.

Один из наиболее интересных алгоритмов в нашем шлюзе — алгоритм приоритетного размера пакета.
Предположим, один из клиентов, используя супербыстрое железо и гениальный код, научился присылать сообщения на биржу быстрее, чем биржа успевает их обрабатывать: означает ли это, что биржа в такой ситуации будет вынуждена обслуживать только одного клиента? Определенно — нет, ведь это было бы нечестно по отношению к менее быстрым участникам торгов.
Решение проблемы, которое использовалось раньше предполагало отслеживание количества сообщений от каждого клиента и распределение времени шлюза между клиентами. В новом гейте мы нашли более простое решение. На каждой итерации полинга сокетов, мы читаем не более чем заранее установленное N-ое количество байт. Таким образом, если один из клиентов прислал 100 сообщений в одном TCP сегменте, второй прислал 15 сообщений, третий 5 сообщений, а приоритетный размер пакета стоит в 10 сообщений, то на первой итерации полностью будут обработаны только сообщения от третьего клиента. Сообщения от первого клиента займут 10 итерации полинга реактора, а второго две итерации.
Еще одна оптимизация которую мы сделали в новом шлюзе — использование статической схемы вместо динамической как было раньше.
Схема — это набор сообщений и полей в них. В случае, когда поля сообщений не известны во время компиляции — это динамическая схема, а если поля известны на этапе компиляции, то получаем уже схему статическую. Оба подхода имеют свои положительные и отрицательные стороны. В первом случае один и тот же код может работать с разными схемами; во втором — изменение схемы требует перекомпиляцию кода. Статическая схема позволяет компилятору сделать множество дополнительных оптимизаций, например, при записи сообщений в лог. Код записи в лог сообщений из статической схемы будет, скорее всего, заинлайнен компилятором, за счет того что количество и типы полей известны еще на этапе компиляции.
Материал подготовлен Николаем Висковым — инженером Московской Биржи.
Комментарии (7)

javapowered
06.02.2017 21:30«Мы получили положительные отзывы от производителей решений для торговли на основе FPGA.»
Если это не коммерческая тайна, то интересно от каких именно производителей? Может сразу плату FPGA сможете посоветовать, которая подходит для TWIME? Давно хочу что-нибудь такое потрогать.
atd
06.02.2017 22:01> Мы получили положительные отзывы от производителей решений для торговли на основе FPGA
Тут всё прекрасно.
Производителям фпга (и прочего дорогого делеза) главное впарить вам железку по цене нового авто премиум класса, да желательно ещё с саппорт-планом за $$$$. Они ради этого готовы петь дифирамбы кому угодно. Рисовать самые радужные картины, типа «купи наш GigaMegaBlaze40GXX и начни зарабатывать миллиарды».
Можно купить хоть самую быструю фпга, но почитайте внимательно про «справедливое» распределение ордеров.
Вашу фпга будут обгонять более хитрые ребята, решившие проблему пропихивания ордеров в несколько логинов, или ещё чем-нибудь, что там наша дорогая биржа придумает. А ей и так неплохо, разводят на покупку 100500 логинов, тем и кормятся.javapowered
07.02.2017 12:36На текущий день это возможно и так. Но видно (медленное) стремление биржи к решению этой проблемы. Думаю постепенно FAST и TWIME будут улучшаться, а с каждым улучшением актуальность FPGA возрастает. Сделаю смелое предположение что доходы биржи от логинов очень не велики, по сравнению с другими статьями доходов.

novoselov
07.02.2017 00:33Вы не сравнивали SBE с FlatBuffers?

Moscow_Exchange
07.02.2017 12:24Мы выбирали из тех протоколов, которые перечислены тут http://www.fixtradingcommunity.org/pg/structure/tech-specs/encodings-for-fix.

Readme
11.02.2017 12:34Вызывает вопросы «новый интересный алгоритм» обработки пакетов. Можете ли вы прояснить некоторые моменты?
На каждой итерации полинга сокетов, мы читаем не более чем заранее установленное N-ое количество байт
Не означает ли это, что здоровая конкурентная очередь на входе в ядро намеренно превращается планировщиком вочередь курильщикакарусель (Round-robin)?
… означает ли это, что биржа в такой ситуации будет вынуждена обслуживать только одного клиента? Определенно — нет, ведь это было бы нечестно по отношению к менее быстрым участникам торгов.
Если я не ошибаюсь, именно для этого существует flood-контроль (с весьма весомыми санкциями) и логины с разными пропускными способностями; данное же заявление (вкупе с предудыщим), имхо, практически нивелирует преимущества логинов, и звучит одновременно как маркетинговый лозунг и оправдывание Биржи в неспособности (нежелании?) обеспечить достаточную производительность для конкурентной обработки заявок.
можно накапливать в памяти, например, класть в очередь в оперативной памяти.… Не самый эффективный способ работы с сообщениями, может потребоваться много памяти и лишние копирования сообщений.
В новом шлюзе… мы читаем из сокетных буферов только те сообщения, которые можем обработать. В случае большой нагрузки… забьется TCP буфер на стороне сервера
клиент при забитых буферах… получит ошибку EAGAIN и сможет сам принять решение о том стоит ли… продолжать торговать… или сменить стратегию
Серьёзно? То есть вместо того, чтобы честно формировать очередь заявок (да, именно в памяти!), шлюз признаётся в DoS при большой нагрузке, оправдывая это «неэффективностью» способа разгребания буферов? И да,EAGAIN, скорее всего, выльется в тот же самый пресловутый флуд (по крайней мере, первые несколько отказов), возвращая нас к предыдущим вопросам логинов и карусели, и вряд ли приведёт к «смене стратегии»: участник торгов далеко не один, и крайне маловероятно, что именно он вызовет DoS (а если и он, то ему ничтоже сумняшеся прописывается живительный flood-бан).
Eddik
Уважаемая биржа, когда вы наконец сделаете FAST трансляцию данных без искусственного замедления? Кулибины, вооружившись навыками реверс инжиниринга вашего клиентского софта, обходят в два счета что участников с супер быстрым TWIME, что без него.