
Приоритетная структура кода
В разработке электронных устройств грань между разработчиком-схемотехником и разработчиком-программистом очень размыта. Что уж говорит о том, кто должен писать RTL под FPGA.
С одной стороны, RTL — это территория схем, с другой стороны, ресурсы FPGA дешевеют, синтезаторы умнеют. Цена ошибки RTL дизайнера для FPGA не превышает цены ошибки программиста, а созданные схемы можно также обновлять и наращивать по функциональности, как обычную прошивку процессора.
Производители микросхем тоже не отстают, стали паковать ПЛИС в один корпус с процессором, даже Intel выпустил процессор для PC с FPGA внутри, купив для этого известного производителя ПЛИС Altera.
Думаю всем истинным программистам Вселенная шлет сигналы, что им просто необходимо изучить RTL и начать писать “код” для FPGA не хуже, чем под их привычные процессоры.
Когда-то давно, я проходил этот путь и позволю себе дать несколько советов для ускорения.
Для начала, нужно выбрать язык описания. На текущий момент использование языков типа System Verilog, SystemC и т.п., именно для создания схем, больше похоже на сделку с дьяволом, чем на работу. Поэтому еще в строю старинные и базовые VHDL и Verilog. Я попробовал оба и советую использовать последний. Verilog более дружествен по синтаксису программистам, да и в целом как-то посовременней.
Если вы твердо решили пройти этот путь, то я полагаю, что вы уже знаете ключевые слова и стандартные конструкции Verilog. Вы потратили какое-то время и понимаете, что в описании аппаратуры все происходит одновременно, а не по очереди, как в программах.
Мы пока оставим вопрос мета-стабильности и гонки сигналов, для этого ограничимся только синхронными схемах с синхронным сбросом, а всякую комбинаторику и асинхроньщину оставим старой школе.
В описаниях схем очень важна структура кода, об организации которой и пойдет речь далее. Структура не только повышает читаемость и поддерживаемость кода, но также влияет на результат работы итоговой схемы.
Настоящие RTL-дизайнеры мыслят “схемно”, они организуют код в блоки и этим определяют его структуру. Мы не будем сразу менять образ мышления, а будем создавать “программисткие” описания. Мы сосредоточимся на том, что хотим получить, а создание подходящей для этого схемы, оставим синтезатору. Все как с языками высокого уровня, пишем код, а оптимизацию и перевод в машинные коды вешаем на компилятор.
Плата за такой подход примерно та же, чуть менее оптимальный с точки зрения ресурсов результат, но как сказано выше цена ресурсов снижается, поэтому не будем жалеть патроны. Cинтезаторы к текущему моменту здорово поумнели, но все же некоторые проблемы имеются, рассмотрим пример:
input clk; //тактовый сигнал
input data_we; //сигнал разрешения записи от внешнего модуля
input [7:0] data; //данные от внешнего модуля
reg [7:0] Data; //данные
reg DataRdy; //флаг готовности данных
reg [7:0] ProcessedData; //обработанные данные
//прием данных по фронту клока ----------------------
always @(posedge clk)
begin
if(data_we == 1’b1) //если есть сигнал записи
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
end
пример кода №1Пока никаких проблем нет, прием выделили в отдельный блок, все удобно и понятно. Теперь допустим, дальше у нас идет работа с полученными данными, и нам хочется снять флаг DataRdy по окончанию обработки данных, чтобы понимать, когда придут новые данные.
//обработка по фронту клока ----------------------
always @(posedge clk)
begin
if(DataRdy == 1’b1) //если есть новые данные
begin
//обработка данных
ProcessedData <= Data;
DataRdy <= 1’b0; //снимаем флаг, данные обработаны
end
end
пример кода №2Вот теперь начинаются проблемы, у любителей Xilinx точно, но думаю, что и другие синтезаторы будут солидарны. Cинтезатор скажет, что у сигнала DataRdy два источника меняющих его значения, он меняется по фронту сигнала в 2 блоках и неважно, что тактовый сигнал один.
Может показаться, что синтезатор не знает какое значение задать, если выполняются условия смены в обоих блока одновременно, когда DataRdy имеет значение 1
//в первом блоке
if(data_we == 1’b1)
DataRdy <= 1’b1;
...
//во втором блоке
if(DataRdy == 1’b1)
DataRdy <= 1’b0;
пример кода №3Но модификация кода решающая этот конфликт не поможет.
//прием данных по фронту клока ----------------------
always @(posedge clk)
begin
//если есть сигнал записи, и снят флаг данных
if((data_we == 1’b1)&&(DataRdy == 1’b0))
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
end
пример кода №4Логически все верно, никаких конфликтов нет, но синтезатор настойчиво будет жаловаться на двойной источник сигнала, и договориться с ним не получиться. Нельзя в разных блоках менять один сигнал, чтобы все получилось, надо и прием, и обработку поместить в один блок.
И тут первое предложение, а давайте у нас в модуле будет вообще всего 1 блок always, и все, что делает наш модуль, мы разместим в этом блоке, наш пример станет выглядеть так
input clk; //тактовый сигнал
input data_we; //сигнал разрешения записи от внешнего модуля
input [7:0] data; //данные от внешнего модуля
reg [7:0] Data; //данные
reg DataRdy; //флаг готовности данных
reg [7:0] ProcessedData; //обработанные данные
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//если есть сигнал записи, и снят флаг данных
if((data_we == 1’b1)&&(DataRdy == 1’b0))
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
else if(DataRdy == 1’b1) //если есть флаг данных
begin
//обработка данных
ProcessedData <= Data;
DataRdy <= 1’b0; //снимаем флаг, данные обработаны
end
end
пример кода №5Теперь все работает, но модуль стал уже не таким понятным, явного разделения на прием и обработку нет, все в одну кучу. Тут нам на помощь приходить одно очень приятное свойство языка Verilog. Если в одном блоке вы совершаете несколько присвоений одной переменной (говорим о неблокирующих присвоениях), то выполнится последние из них (Стандарт Verilog HDL IEEE Std 1364-2001). Правильнее сказать, что выполняются они все в описанном порядке, но так как все такие присвоения происходят одновременно, то переменная примет последние присвоенное значение.
То есть, если написать так:
input B;
reg [2:0] A;
always @(posedge clk)
begin
A <= 1;
A <= 2;
A <= 3;
if(B) A <= 4;
end
пример кода №6То A примет значение 3 в случае, если В ложь, а если все же В истина, то А примет значение 4, в этом можно убедиться на следующем изображении

Рис1. Временная диаграмма симуляции поведения описания №6
Это полностью описанная стандартом и синтезируемая конструкция, что дает нам интересные возможности, нет необходимости делать сложные цепочки конструкции if — else if разделяя, когда переменной присвоить одно значение, а когда другое. Вы просто можете написать условие и значение переменной, написать это не думая о других условиях и присвоениях этой переменной, написать это как бы изолированно от другого кода.
Далее останется расположить такие присвоения в правильном порядки, тем самым задать их приоритеты на случай одновременного выполнения, и все получится само. Это очень удобный способ управления кодом, при этом контролируемый синтезатором, а не человеком.
В следующем примере показано, как это может выглядеть
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//прием данных, наименьший приоритет -----
if(...) Data <= data;
//обработка данных, средний приоритет ----
if(...) Data <= Func(Data);
//сброс, наивысший приоритет -------------
if(reset_n == 1’b0)
Data <= 0;
end
пример кода №7Куда бы вас не завела кривая создания модуля, вы можете быть уверенными, что состояние сброса, перекроет все что вы натворили выше, вы можете сделать сколько угодно ошибок в логике, сброс произойдет и задаст переменной описанное в блоке сброса значение.
Также вы можете быть уверенными, что если у вас вдруг совпадут в один момент времени условия обработки и приема данных, то вы обработаете данные, а не затрете их новыми пришедшими. Это произойдет потому, что обработка в нашем коде стоит ниже, она более приоритетная. Если вдруг в какой-то момент вы поймете, что важнее не потерять приходящие данные, поменяйте блоки местами и тем самым измените приоритеты.
Если у вас несколько интерфейсов, которые могут изменить данные, вы опять же просто располагаете участки кода реализующие интерфейс друг за другом, и тем самым расставляете приоритеты доступа к данным.
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//прием данных по 1 интерфейсу,
//наименьший приоритет -------------------
if(master1_we)
Data <= data1;
//прием данных по 2 интерфейсу,
//приоритет выше первого -----------------
if(master2_we)
Data <= data2;
//обработка данных, средний приоритет ----
if(need_process)
Data <= (Data << 1);
//сброс, наивысший приоритет -------------
if(reset_n == 1’b0)
Data <= 0;
end
пример кода №8Симуляция работы описания можно видеть на рисунке ниже
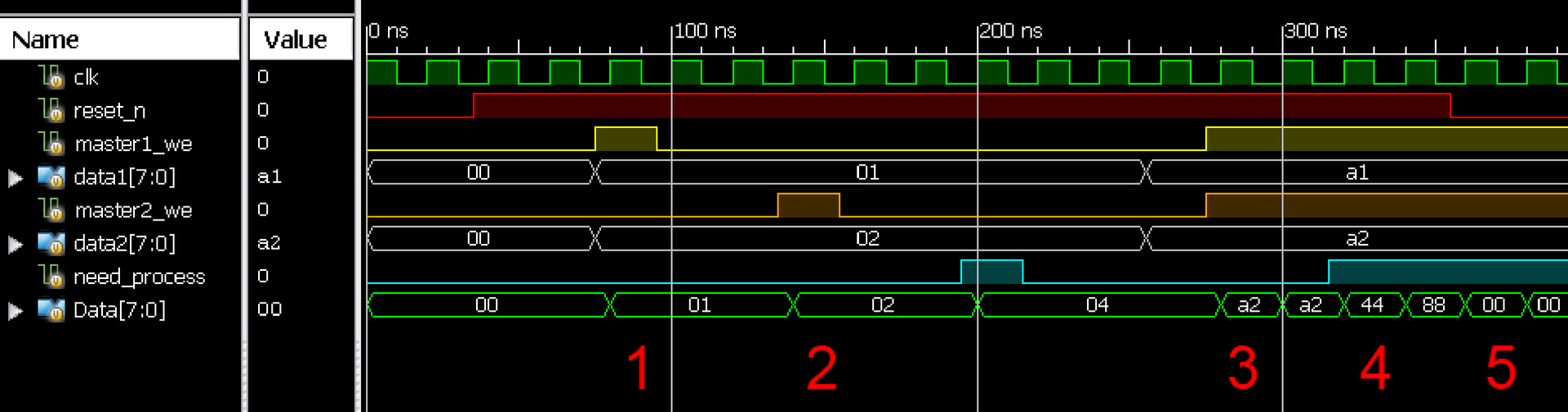
Рис2. Временная диаграмма симуляции поведения описания №8
Эта система управляется несколькими ведущими устройствами и арбитраж между ними получился автоматически. Когда мастера управляют схемой по очереди (фаза 1 и 2, рис. 2), она получает данные от каждого из них, но если вдруг несколько мастеров выдадут данные одновременно (фаза 3, рис. 2), то схема использует данные от более приоритетного мастера, интерфейс которого описан ниже, от второго в нашем примере.
При этом сброс схемы перекрывает все сигналы (фаза 5, рис. 2), а обработка выше по приоритету любого из мастеров, но ниже сброса (фаза 4, рис. 2).
Вернемся к начальному примеру, и покажем его конечный вариант описания:
input clk; //тактовый сигнал
input data_we; //сигнал разрешения записи от внешнего модуля
input [7:0] data; //данные от внешнего модуля
reg [7:0] Data; //данные
reg DataRdy; //флаг готовности данных
reg [7:0] ProcessedData; //обработанные данные
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//прием данных -------------------------------
//приоритет 0
if(data_we == 1’b1)//если есть сигнал записи
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
//обработка данных --------------------------
//приоритет 1
if(DataRdy == 1’b1) //если есть флаг данных
begin
//обработка данных
ProcessedData <= Data;
DataRdy <= 1’b0; //снимаем флаг, данные обработаны
end
end
пример кода №9Даже не нужно в блоке приема проверять, что DataRdy имеет нулевое значение, блок обработки перекроет по приоритету блок приема, и сбросит флаг DataRdy, даже если во время обработки поступят новые данные. А поменяв блоки местами, мы не пропустим никаких новых данных.
input clk; //тактовый сигнал
input data_we; //сигнал разрешения записи от внешнего модуля
input [7:0] data; //данные от внешнего модуля
reg [7:0] Data; //данные
reg DataRdy; //флаг готовности данных
reg [7:0] ProcessedData; //обработанные данные
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//обработка данных --------------------------
//приоритет 0
if(DataRdy == 1’b1) //если есть флаг данных
begin
//обработка данных
ProcessedData <= Data;
DataRdy <= 1’b0; //снимаем флаг, данные обработаны
end
//прием данных -------------------------------
//приоритет 1
if(data_we == 1’b1)//если есть сигнал записи
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
end
пример кода №10После обработки данных сбрасывается флаг DataRdy, но если одновременно с этим моментом к нам приходят новые данные, блок приема перекроет приоритет сброса и опять поставит флаг DataRdy, и данные (факт их обновления) не потеряются, данные будут обработаны в следующем цикле.
Что дает такая организация кода?
Код разделен на понятные блоки, перед ними можно дать пространные комментарии, что делает каждый блок. Мы имеем возможно задавать приоритеты блокам, перекрывая присвоения одного блока другим, при это не связываем их в огромные неудобные списки if — else if — else if. Можно удалить или “закомментировать” блок, вставить между любыми блоками еще один, остальная часть кода продолжит работать без правок.
Поскольку у нас единый always, то нет конфликтов двойных источников сигнала, если в какой-то момент мы решим изменять сигналы в разных структурных блоках. Мы просто меняем сигнал где и когда нам надо. Не надо организовывать никаких “хэндшейков” и “пробрасывать” дополнительные сигналы, как в случае отдельных always.
Код управляем, читаем, изменяем, существует по понятным законам, вам не надо собирать приоритетные шифраторы и подавать их на мультиплексоры интерфейсов, собирая все сигналы в шины и прикидывать все условия изменения сигнала.
Все что вам надо, просто описать поведение схемы, что вы от нее хотите, задать приоритеты расположением блоков описания и отдать все это на обработку синтезатору. Можете быть уверены, он прекрасно справится с поставленной задачей и выдаст схему с желаемым поведением, уж синтезатор Xilinx точно, но думаю и другие будут солидарны.
Комментарии (33)

Kopart
13.02.2017 10:57Есть сомнения, что при таком описании асинхронного ресета он будет правильно воспринят при синтезе.

GolikovAndrey
13.02.2017 12:09-1Строго говоря есть документ со стандартными конструкциями описания под каждый синтезатор, и даже иногда семейство ПЛИС. Асинхронный сброс и установка входит в набор стандартных конструкций. Чтобы синтезатор правильно воспринял ту или иную конструкцию она должна быть описана согласно документу. Так что в общем случае ваши сомнения обоснованы, асинхронный сброс может быть обработан неверно в таком описании.
Но в предложенном варианте я ограничился синхронными схемами.
С асинхронными сигналами есть сложность связанная с тем что реально он работает по уровню, а в верилоге описывается как действие по фронту. То есть это некое такое соглашение что мы описываем так, хотя понимаем что работать будет эдак.


Daffodil
13.02.2017 11:10+2Ну т.е. это вы такой небольшой конвейер написали одним always блоком? — вполне стандартный подход. У меня даже была мысль когда-то написать небольшой процессор одним always-блоком.
Кстати современные SystemC синтезаторы поддерживают запись сигнала из разных процессов, если это происходит на разных тактах — просто вставляют мультиплескор. Запись сигнала из разных процессов на одном такте — undefined behavior.

dsmv2014
13.02.2017 12:14Подход правильный. Я использую подобные конструкции для сигнала сброса на VHDL. Это прекрасно работает.
Но вот при сравнении VHDL и Verilog надо помнить, что VHDL имеет очень серьёзное преимущество. Это структуры, которые определяются типом record. Это позволяет очень сильно упростить описание сложных шин, например AXI. Но это уже есть в System VerilogDaffodil
13.02.2017 12:37А в SystemC есть modular interfaces, которые позволяют посылать AXI транзакции с помощью простых function-call'ов вроде axi_master.send_write_request (address, data, flags)
Daffodil
13.02.2017 12:42Да и шаблоны в C++ мощнее чем record'ы в VHDL, можете ли вы например написать record для AXI payoad'a с параметризируемой шириной адреса и данных?
dsmv2014
13.02.2017 12:59Написать могу. И даже в некоторых системах это будет промоделировано. С++ предлагает более высокий уровень программирования, сейчас это активно развивается и возможно будет активно использоваться. А может и не будет — пока это не понятно. А VHDL это имеет с 1976 года (если я не ошибаюсь). Лично я тип record использую ~16 лет.

ilynxy
13.02.2017 15:25+3Для начала, нужно выбрать язык описания. На текущий момент использование языков типа System Verilog, SystemC и т.п., именно для создания схем, больше похоже на сделку с дьяволом, чем на работу. Поэтому еще в строю старинные и базовые VHDL и Verilog.
Ну что за вопиющее ретроградство. SystemVerilog это надмножество Verilog'a и все конструкции там будут работать (за редчайшими исключениями). Но в SystemVerilog'e значительное количество приятных плюшек, в том числе затрудняющих стрельбу по задним конечностям (это я про синтез, удобство верификации SystemVerilog просто без шансов рвёт Verilog). Ознакомьтесь, пожалуйста, с документом «Verilog Gotchas». Там приводятся типичные ошибки, которые допускают программисты на Verilog/SystemVerilog и как их избегать. Думаю Ваш взгляд на best practices несколько изменится.
Что касается чисто философского вопроса: «думать как программист» vs «думать как схемотехник». По собственному опыту «воспитания» из «программистов обычных C/C++» -> «программистов обычных Verilog/SystemVerilog» пришёл к выводу, что пока не изменится мышление с, условно так скажем, «последовательного» на «параллельное» ничего хорошего из под них не получить. Есть, конечно, SystemC и подобные инструменты и когда-нибудь они будут доминировать, но пока качество генерации ни по размеру ни по частоте не дотягивает до грамотно написаного вручную кода. Собстна, ситуация напоминает историю с Assembler/C vs «языки с более высоким уровнем абстракции». Вот интел прикупил альтеру, ждём когда процесс программирования FPGA станет более человечным. Даёшь Java/C#-подобное для ПЛИСов =)GolikovAndrey
13.02.2017 15:56-1Естественно я пишу и на SystemVerilog тоже, а также я имею некоторый опыт проблем даже со стороны симуляторов по полноте поддержки систем верилога не говоря про синтезаторы. Именно поэтому пока бы я его не рекомендовал, особенно тем кто только начинает.
Да вы правы, все очень похоже на переход с ассемблера на С и далее, и аргументы примерно такие же. Поживем увидим чем дело кончится.
Спасибо за мнение, мне правда это важно.
ilynxy
13.02.2017 16:30Естественно я пишу и на SystemVerilog тоже, а также я имею некоторый опыт проблем даже со стороны симуляторов по полноте поддержки систем верилога не говоря про синтезаторы. Именно поэтому пока бы я его не рекомендовал, особенно тем кто только начинает.
Я, собственно, ограничен только Quartus/ModelSim, а потому не могу судить о поддержке SV в других инструментах. Но в этих поддерживается практически всё (впрочем, синтезатор Quartus'a несколько ограничен, но это экзотика).
Вот чего мне не хватает так это иерархии в SV. То есть в проекте не может быть два модуля с одним именем, поскольку namespace для модулей не завезли (package может содержать много чего, имитируя namespace, но модули содержать, увы, не может). VHDL предлагает концепцию library, что вполне может заменить namespace, но мне лень шлёпать по кнопкам в таком количестве. VHDL слишком «шумный» и строгий. Впрочем это его плюс в качестве самодокументации кода и отсеивания кучи ошибок уже на этапе компиляции (если VHDL скомпилировался, вероятность, что оно заработает правильно выше чем в SV).GolikovAndrey
13.02.2017 17:17-1Сталкивался с неполной поддержкой интерфейсов, а они по моему мнению составляют львиную долю преимуществ. Вам повезло у вас очень хорошая среда для SV. У ксалинкса большой бардак с этим, фактически 6 серию они по SV не поддержали. Некоторые АСИК тулзы тоже имеют неприятные приколы.
nerudo
13.02.2017 17:18К сожалению приходится порой сталкиваться, в Vivado, к примеру, с сообщениями типа is not supported yet. Так что приходится быть осторожным…
GAYVER
13.02.2017 17:02+3в процессе прочтения статьи почему то вспомнилось высказывание — физик-ядерщик легко научится штукатурить, но вот штукатур никогда не запустит ядерный реактор. так и тут — «железячник» легко станет программистом, программист врядли станет «железячником».
автор предлагает за недостаток опыта платить — плохо написан код, синтезатор плохо уложит все в кристалл, никогда не получатся хорошие частоты в проекте. чтобы компенсировать это, прийдется покупать более дорогие плисины, с большим запасом по необходимым ресурсам. а хорошая плисина это не микруха за 5 рублей.
и таки да, чтобы синтезатор выдал хороший результат — его надо очень тонко настраивать. а это еще бОльший порог вхождения, нежели обладание «схемотехническим» складом ума. более того — и хороший программист должен быть «схемотехником». без знания того, как выполняется каждый конкретный оператор, откуда берутся операнды, сколько на это тратиться тактов и времени — невозможно писать хороший, быстрый код. но таких программистов еденицы. гораздо больше тех кто тупо накидывает операторы, а компилятор там сам разберется что и куда запихнуть. такие программисты часто заканчивают в макдональдсе на свободной кассе :)GolikovAndrey
13.02.2017 17:13-1Есть разные рынки. Иногда время выхода продукта на рынок определяет все дальнейшие продажи. Приборы на этом рынке очень дорогие, а продажи очень маленькие и потому совершенно не важно сколько вы потратили на плис 400 долларов или 1000. Ровно как не важно смогли вы выжать из спартана 6, например, 150 МГц, когда для вашей задачи хватает и 50. Также не надо забывать вопросы прототипирования и макетирования, проверили идею, а потом отдали на вылизывание и оптимизацию профессионалам.
ilynxy
13.02.2017 18:28Также не надо забывать вопросы прототипирования и макетирования, проверили идею, а потом отдали на вылизывание и оптимизацию профессионалам.
Вот, кстати, да. Поиск инженера, который умеетнатянуть сову на глобусtiming closure для уже существующего проекта вполне такая обычная практика.
GAYVER
14.02.2017 10:09-3хммммм, только сейчас обратил внимание на ваше фио. на форуме электроники вроде есть персонаж с такими же. не вы, случаем ))?
Есть разные рынки. Иногда время выхода продукта на рынок определяет все дальнейшие продажи. Приборы на этом рынке очень дорогие, а продажи очень маленькие и потому совершенно не важно сколько вы потратили на плис 400 долларов или 1000
все верно. но можно же потратить не 1000 и не 400, а, к примеру, 100 :). и уложиться в требования и дополнительно навариться.
Также не надо забывать вопросы прототипирования и макетирования, проверили идею, а потом отдали на вылизывание и оптимизацию профессионалам.
покупать для обкатки тестового проекта плис за космические деньги… разумный подход :). конечно, если у вас таких идей в голове море, и все перспективные, и есть кому это потом спихивать для натягивания совы на глобус, то да — есть смысл 1 раз купить хорошую отладочную плату за хорошие деньги
в общем в чем в целом мне не понравилось в том что вы пропагандируете… русские инженеры всегда отличались умением слепить из г… на пулю, и выжать из минимального набора материалов максимальный результат. именно поэтому наше оружие самое эффективное, самое надежное и самое недорогое. а тот подход что вы пытаетесь оправдать — используют наши западные партнеры. пофиг на все, у нас есть технологии и бабки — мы можем себе позволить компенсировать непрофессионализм своих инженеров тоннами бабла. нужна нам частота 150, но из-за кривого проекта потолок 50? пофигу, чтобы успеть обработать поток данных сопоставимый со 150 мегагерцами, поставим 3 плисины по 50. и еще одну впендюрим — чтобы коммутировать потоки
GolikovAndrey
14.02.2017 11:02+1Не стоит вам так под одну гребенку русских инженеров.
Хорошие инженеры что у нас, что у них славятся умением найти правильный компромисс для решения поставленной задачи.
А бросаться в крайности и агрессивно на всех нападать удел неудачников.
Творческих успеховGAYVER
15.02.2017 13:44-2агрессивно нападать? это где я нападал? примеры можно?
под одну гребенку? тут да, согласен — далеко не все наши инженеры образцовые специалисты.
все умеют находить компромисс? тоже согласен — правильный компромисс все умеют найти. только какие критерии для сравнения этих компромиссов? решение поставленной задачи? не подходит. а вот тактико-технические характеристики в проекции на затраты по их достижению — вот это уже ближе. и что то мне подсказывает что тут поле безоговорочно остается за нашими инженерами.
nerudo
14.02.2017 11:32Подозреваю это от того, что оценка труда русского инженера — примерно на уровне посудомоя цивилизованной страны. Если годовая зарплата инженера как одна хорошая микросхема — то действительно, почему бы не поизгаляться?
areht
14.02.2017 07:20> «железячник» легко станет программистом
Видел я результаты такого труда, не надо переоценивать возможности железячников.

ef_end_y
13.02.2017 23:58У вас простой пример. Для сложных случаев, когда все таки хочется разбить на блоки большой кусок кода, наверное есть смысл вводить промежуточные сигналы и их в одном отдельном месте разгребать через приоритеты. Правильно мыслю?
GolikovAndrey
14.02.2017 07:10Это скорее уже вопрос правильного деления на подмодули. Я не призываю чтобы на все устройство был один файл. Надо бить «программу» на функциональные блоки и на верхнем уровне работать уже с сигналами блоков.
GAYVER
14.02.2017 10:57-1кстати, зря не призываете )). плодить сущности и потом мудохаться с прокидыванием сигналов между блоками… это говорю как человек, который собирал итоговый проект для тестирования и отладки )). приходилось сталкиваться с крайностями — и с тем что внутри одного небольшого устройства чуть ли не каждый счетчик был вынесен в отдельный блок, и с тем что большое устройство (процессор, памяти, алу, блоки управления, итд итп) было описано одним куском кода — тупо подряд куча процессов, хрен пойми что откуда и куда идет, на что влияет и по какому принципу вообще этот сигнал назван.
сам придерживаюсь золотой середины — по минимум крупных блоков, собраных на топ-лвл, и в пределах одного блока все устройства работающие на 1 частоте описаны в одном процессе. логически разбиты на отдельные блоки (интерфейсные части, области управления, делители частоты, итд), снабжены понятными комментариями (начало-конец блока, назначение, пояснения по управляющим сигналам — что откуда и куда), но описаны все в одном месте
GAYVER
15.02.2017 14:05кстати, свежий пример от вивады, на откуп (в том числе) которой предлагается отдавать львиную долю работы — убито 2 рабочих дня 3 инженеров на вычисление элементарной ошибки — два источника для одного сигнала. собирающий топ-лвл скопипастил блок и в одном месте не переименовал сигнал. и вивада схавала — ни одного ворнинга/еррора. схавали симуляторы — ни одной неопределенки при моделировании. а вот при отладке в железе начались чудеса…
GolikovAndrey
15.02.2017 17:56Такая ошибка отлавливается на этапе синтеза. Если такого не происходит то вероятнее всего сигнал был объявлен как wor или wand которые могут иметь несколько источников. В этом случае незачем обвинять инструменты, они сработали как вы написали.
Виной произошедшему плохая архитектура вашего проекта, плохая структура кода и возможно бедная верификация.
GAYVER
16.02.2017 15:39т.е. в том что синтезатор схавал 2 источника сигнала виновата плохая структура кода и плохая архитектура проекта? по-моему дальнейший диалог не имеет смысла
nerudo
16.02.2017 10:58Без конкретного разбора примера неинтересно. Но если боитесь отстрелить себе ногу — пользуйтесь VHDL, там вольностей сильно меньше. Хотя в виваде да, немного странно. Multiple drivers оно обнаруживает не на синтезе а уже при трассировке кристалла.
И, главное, если не отдавать работу «виваде», то как?GolikovAndrey
16.02.2017 15:48да вот человек утверждает что добился такого эффекта в VHDL, я бы тоже с удовольствием взглянул бы на то что на самом деле там произошло. Но он вроде как не хочет больше с нами говорить:)
nckma
Интересный подход, но мне кажется, что он размывает мысленную связь между написанным кодом и представлением, как это будет выглядеть в RTL viewer.
Когда я пишу always @(posedge clk) if(a) b<= data; то я мысленно представляю, что это будет регистр с сигналом разрешения записи.
Когда я пишу always @(posedge clk) if(a) b<= data else b<=data2; то для меня это мультиплексор данных на входе регистра. Я так пишу и представляю. С вашим подходом такое мысленное представление не получится (или его труднее увидеть).
Причем я заметил, что громоздкие конструкции, где много if-else как правило выглядят в RTL viewer ужасно (много мультиплексоров) и схема в ПЛИС становится медленной, Fmax падает.
То есть, громоздкие конструкции с многими if-else, которые выбирают приоритет выполнения операций есть проблемы. Желательно их избегать, желательно не более 2х последовательных if-else. Синтезатор то их синтезирует — вроде бы проблем нет. Но будет ли удачно все потом упаковано фитером?
В вашем подходе так же присутствуют «незримые if-else» на которые вы предлагаете не обращать внимания, мол синтезатор справится. Эдакое движение в сторону высокоуровневых языков программирования.
Ну не знаю… не уверен…
GolikovAndrey
Все верно, вы просто обладаете «схемным» мышлением и занимаетесь описанием именно схем. Плюсы вашего подхода максимальная эффективность, минусы он требует большего опыта, определенного типа мышления и вы лишаете синтезатор свободы творчества и вариантов оптимизации, во всяком случае ограничиваете.
Действительно я пытаюсь сместить акцент с описание схемы на описание результата, пытаясь упростить и ускорить процесс, перекладывая часть обязанностей на синтезатор. Сейчас много кто перестал считать такты контроллеров в угоду удобных шаблонов и архитектур. Я предлагаю такое же движение, но в области ПЛИС.