
Здравствуйте, меня зовут Саша, я написал самый быстрый ресайз изображений для современных х86 процессоров. Я так утверждаю, поскольку все остальные библиотеки, которые я сумел найти и протестировать, оказались медленнее. Я занялся этой задачей, когда работал над оптимизацией ресайза картинок на лету в Uploadcare. Мы решили открыть код и в результате появился проект Pillow-SIMD. Любой желающий с легкостью может использовать его в приложении на языке Python.
Любой код выполняется на конкретном железе и хорошей оптимизации можно добиться, только понимая его архитектуру. Всего я планирую выпустить 4 или 5 статей, в которых расскажу как применять знание архитектуры железа для оптимизации реальной задачи. Своим примером я хочу побудить вас оптимизировать другие прикладные задачи. Первые две статьи выйдут в течение недели, остальные — по мере готовности.
О задаче
Под «ресайзом изображений» я понимаю изменение размеров изображения с помощью ресемплинга методом сверток. Ресемплинг производится над массивом 8-битных RGB пикселей в память, без учета декодирования и кодирования изображений, однако с учетом выделения памяти под конечное изображение и с учетом подготовки коэффициентов, необходимых для конкретной операции.
Вот так строго. Никаких трюков (вроде декодирования из джипега изображения меньшего размера) и никакого комбинирования алгоритмов, только честное измерение работы конкретного алгоритма. Трюки и оптимизации частных случаев можно применить позже, они не предмет рассмотрения этой серии статей.
… с помощью ресемплинга методом сверток. Что?
Чтобы было понятно, что конкретно нуждалось в оптимизации, я расскажу, что такое ресемплинг свертками. Свертка (правильно говорить свертка дискретных значений, т.к. пиксели изображения дискретны) — это очень простая математическая операция. У нас есть какой-то ряд значений №1 (коэффициенты) и ряд значений №2 (данные, в нашем случае интенсивность каналов пикселей). Результат свертки этих двух рядов будет сумма произведений всех членов попарно. Вот так просто — сумма произведений. Матан закончился, не успев начаться.
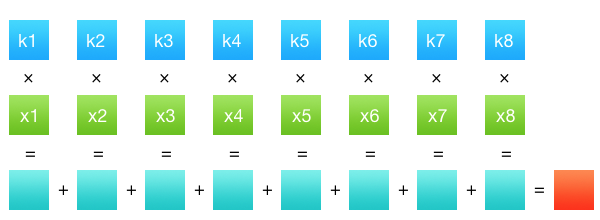
Осталось понять, как именно эта операция связана с ресайзом. Ряд значений №2 — это ряд пикселей исходного изображения. Ряд значений №1 — это коэффициенты, получающиеся из фильтра. Фильтр — это такая функция, которая определяет, как именно мы будем сворачивать значения. Может быть вы замечали в окошке ресайза в Фотошопе или другом графическом редакторе выпадающее меню с фильтрами — билинейный, бикубический, иногда Ланцош. Это и есть этот фильтр. А вот получившееся в результате свертки значение — это интенсивность одного канала одного пикселя конечного изображения. Т.е. чтобы получить изображение размером M?N пикселей, нам нужно сделать M?N?C операций свертки, где С — количество цветовых каналов. Да, посчитать весь пиксель одной операцией не получится, значения разных каналов независимы и должны считаться отдельно.
Функции фильтров не бесконечны, их значения не равны нулю лишь в центральной части: для билинейного фильтра это диапазон значений от –1 до 1; для бикубического от –2 до 2, для Ланцоша от –3 до 3 (правда бывают и другие разновидности Ланцоша).
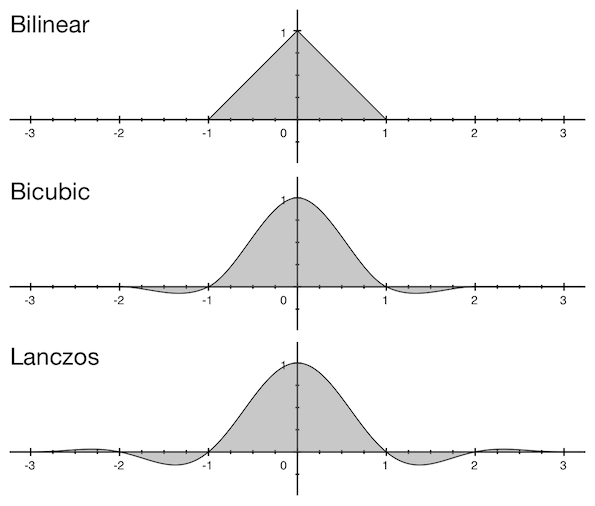
Эти числа называют окном фильтра, т.к. фильтр применяется только в этом диапазоне, а за его пределами равен нулю. Соответственно ряд исходных пикселей, необходимый для свертки, берется в радиусе размером в окно фильтра помноженном на коэффициент уменьшения (или на единицу, если происходит увеличение). Думаю, это лучше объяснить на примере. Нам нужно уменьшить изображение шириной 2560 пикселей до ширины 2048, используя бикубический фильтр. Допустим, мы хотим найти значение 33-го пикселя конечного изображения. У бикубического фильтра размер окна равен двум, а коэффициент уменьшения получается 2560/2048 = 1,25, поэтому нам нужно будет взять строку пикселей исходного изображения от floor((33 - 2) ? 1,25) до ceil((33 + 2) ? 1,25). Т.е. с 38-го по 44-й пиксель. Для этих же пикселей высчитываются значения коэффициентов.
До этого момента я говорил о ряде коэффициентов и ряде пикселей, упуская из виду факт, что изображение — это вообще-то двумерная структура. И вроде по логике, сворачивать нужно не линию, а какую-то область исходного изображения. Но одно из свойств свёрток заключается в том, что операцию можно провести отдельно по вертикали и по горизонтали, сделав два прохода. Грубо говоря, это позволяет уменьшить сложность одной свертки с O(n?) до O(2n) (на самом деле меньше, но все равно существенно).
Почему все же свертки
Вообще, фраза «ресайз изображения» несет в себе минимум информации о том, что нужно сделать. Она говорит, что мы должны получить изображение конечного размера, используя оригинальное, с сохранением геометрии изображенных объектов. Но использовать исходное изображение можно по-разному. Можно например для каждого конечного пикселя поставить в соответствие один пиксель из исходного и взять его без изменений. Это называется метод ближайшего соседа. Картинка получается грубой, рваной, неприятной:

Так происходит потому, что в конечном изображении была использована очень малая часть исходных пикселей (на приведенном выше примере меньше одного процента). Информацию из тех пикселей, которые не попали в конечное изображение, мы потеряли.
А вот как выглядит ресемплинг с помощью сверток:

Ресемплинг с помощью сверток правильно учитывает вклад каждого исходного пикселя в конечное изображение. Он универсален, т.к. дает одинаково хороший и предсказуемый результат для широкого диапазона коэффициентов масштабирования, не содержит искажений геометрии на локальном уровне (с оговоркой, что используется фильтр, не дающий таких искажений, т.к. некоторые фильтры все же дают). И вообще, он весь такой правильный и хороший со всех сторон, кроме одной: производительности.
Pillow
Pillow — это библиотека для работы с изображениями на языке Python, развиваемая сообществом во главе с Alex Clark и Eric Soroos. В Uploadcare Pillow использовался еще до того, как я пришёл в команду. Тогда мне это показалось странным — работа с изображениями была одной из основных задач, зачем было брать для нее библиотеку, завязанную на язык. Не лучше ли взять тот же ImageMagick, у которого тонна функций, которым пользуются миллион разработчиков, уж в нем наверняка все должно быть хорошо с производительностью. По прошествии нескольких лет, могу сказать, что это была удача как для меня, так и для Pillow. Как выяснилось, производительность обеих библиотек на старте была примерно одинаковой, но я очень сомневаюсь, что у меня хватило бы сил сделать для ImageMagick что-то такое, что я сделал для Pillow.
Pillow — это форк очень старой библиотеки PIL. Исторически, для ресайза в PIL не использовались свёртки. Первая реализация ресайза на свёртках в PIL появилась в версии 1.1.3 и была доступна при использовании фильтра ANTIALIAS, название которого подчеркивало то, что остальные фильтры использовали менее качественные алгоритмы. В сети до сих пор можно часто встретить уже не актуальные рекомендации использовать при ресайзе в PIL (и в Pillow, как приемнике) только фильтр ANTIALIAS.
К сожалению, у ANTIALIAS была довольно низкая производительность. Я полез в исходный код, чтобы посмотреть, что можно сделать, и оказалось, что реализация ресайза для ANTIALIAS (то есть свертки), может быть использована и с остальными фильтрами. А сама константа ANTIALIAS соответствует фильтру Ланцоша, у которого большое окно (±3), и поэтому он достаточно медленный. Самая первая оптимизация, которую я хотел сделать — включить свёртки для билинейного и бикубического фильтров. Так стало бы возможным у себя в приложении использовать более дешёвый бикубический фильтр (с окном ±2) и не слишком потерять в качестве.
Дальше мне было интересно посмотреть на код самого ресайза. Я без труда нашёл его в этом модуле. И хоть я и пишу в основном на питоне, я сразу заметил несколько сомнительных мест с точки зрения производительности. После нескольких оптимизация я получил прирост в 2,5 раза (это будет описано в следующей статье). Потом я стал экспериментировать с SIMD, переводить все вычисления на целые числа, агрессивно разворачивать циклы и группировать вычисления. Задача была чрезвычайно интересной, в голове всегда были еще пара идей, как улучшить производительность. Я погружался в кроличью нору все глубже и глубже, периодически проверяя очередную гипотезу.
Постепенно код становился все больше, а скорость все выше. Часть наработок отдавалась обратно в Pillow. Но SIMD-код было трудно перенести, потому что он написан для конкретной архитектуры, а Pillow — кроссплатформенная библиотека. Поэтому было решено сделать не кроссплатформенный форк Pillow-SIMD. Версии Pillow-SIMD полностью соответствуют версиям оригинальной Pillow и добавляют ускорение некоторых операций.
В последних версиях Pillow-SIMD с AVX2 ресайз работает от 15 до 30 раз быстрее, чем в первоначальном PIL. Как я уже говорил в самом начале, это самая быстрая реализация качественного ресайза, которую мне удавалось протестировать. Можно посмотреть страничку, на которой собраны результаты бенчмарков разных библиотек.
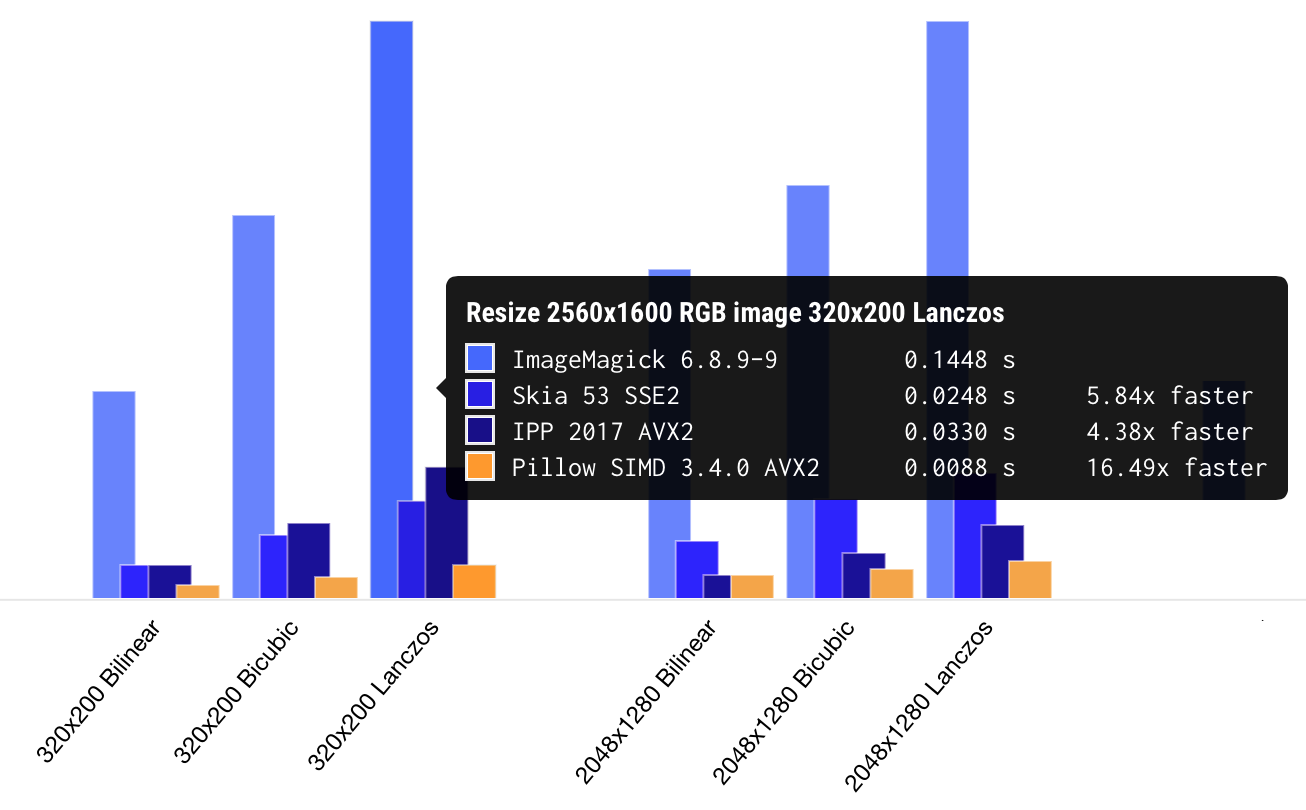
Что меня радует в случае с Pillow и Pillow-SIMD, это то, что это реальные библиотеки, которые реально использовать даже начинающему разработчику. Это не кусок кода, опубликованный на Stack Overflow, который непонятно куда воткнуть. И не «примитивные блоки», из которых как из конструктора нужно собирать каждую операцию. И даже не сложная C++ библиотека с запутанным интерфейсом, которая компилируется полчаса. Это одна строчка установки, одна строчка импорта библиотеки, одна строчка загрузки изображения и, «эй, мам, смотри, я пользуюсь самым быстрым ресайзом в своем приложении».
Замеры производительности
В статьях я буду выкладывать замеры производительности в виде таблицы, в которой исходное изображение разрешением 2560?1600 пикселей ресайзится до разрешений 320x200, 2048x1280 и 5478x3424 с использованием билинейного, бикубического и фильтра Ланцоша (т.е. всего 9 операций). Исходное изображение взято достаточно большое, чтобы не поместиться полностью в кеш процессора третьего уровня. При этом фактическое содержимое изображения не имеет значения с точки зрения производительности, можно ресайзить хоть пустой белый лист, хоть черный, хоть фоточку вашего кота. Вот пример результатов библиотеки Pillow версии 2.6, до любых оптимизаций.
Scale 2560?1600 RGB image
to 320x200 bil 0.08927 s 45.88 Mpx/s
to 320x200 bic 0.13073 s 31.33 Mpx/s
to 320x200 lzs 0.16436 s 24.92 Mpx/s
to 2048x1280 bil 0.40833 s 10.03 Mpx/s
to 2048x1280 bic 0.45507 s 9.00 Mpx/s
to 2048x1280 lzs 0.52855 s 7.75 Mpx/s
to 5478x3424 bil 1.49024 s 2.75 Mpx/s
to 5478x3424 bic 1.84503 s 2.22 Mpx/s
to 5478x3424 lzs 2.04901 s 2.00 Mpx/sВторой столбец здесь это время в секундах, а третий — пропускная способность исходного изображения для данной операции. То есть, если операция заняла 0,2 с, то пропускная способность будет 2560?1600/0,2 = 20,48 мегапикселей в секунду.
Исходное изображение ресайзится до разрешения 320?200 за 164 миллисекунды. Ну что, вроде неплохо. Может быть вообще не нужно оптимизировать, оставить как есть? Ну, если вспомнить, что разрешение фоток с мобильных телефонов сейчас в среднем имеет размер 12 мегапикселей, то все получается не так радужно. Фотка с айфона будет уменьшаться полсекунды без учета распаковки. Учитывая другие операции, в минуту вы можете обработать ?80 картинок, а в час — около 5000. Текущая нагрузка на наш сервис около 130 тысяч запросов в час. Нам бы понадобилось 26 AWS c4.large серверов, работающих на пределе, чтобы справиться с такой нагрузкой. В реальности же у нас задействовано всего 4 сервера, нагрузка на которые в горячие часы около 40%.
Если бы такой эффект удалось экстраполировать до масштабов планеты и заменить весь код, занимающийся ресайзом картинок, на более эффективный, польза была бы огромной. Десятки тысяч сэкономленных серверов, сотни киловатт электричества. А это уже одна миллионная от мирового потребления. Да можно было бы спасти планету!
Дальше: Часть 1, общие оптимизации
Комментарии (66)

bak
14.02.2017 11:39+3Выглядит круто. И всё же почему бы не добавить поддержку SIMD в основной Pillow — динамически определять доступность SIMD и переключаться между реализацией на лету?

homm
14.02.2017 11:43Для компиляции SSE4 и AVX2 кода нужны разные флаги компиляции у отдельных файлов. Сейчас система сборки бинарных питоновских модулей недостаточно гибкая, чтобы так сделать. Подробнее есть в readme.

Gorthauer87
14.02.2017 11:56А разве эти флаги влияют на доступные интринсики?
bak
14.02.2017 12:57+2Можно к примеру положить оптимизированную версию в отдельный модуль, который будет собираться с нужными флагами. А в pillow добавить от него зависимость.

4144
15.02.2017 17:56+1Для gcc можно использовать target атрибуты. И не надо ни каких флагов компиляции.
Но могут быть проблемы с LTO, если использовать одно имя функции с разными реализациями и атрибутами target.
Без lto, должно быть все хорошо. Либо можно обойти проблему использую функции с уникальными именами и собственную реализацию выбора функции на основе поддержки разных видов simd (я пока такое не делал)
Пример в wiki: https://gcc.gnu.org/wiki/FunctionMultiVersioning
Из недостатков, clang такое не поддерживает и надо обкладывать все через #ifdef/#define
ony
21.02.2017 16:14

kAIST
14.02.2017 11:58+1Не подскажите, где нибудь есть мануал, как собрать под windows? В нескольких проектах у меня как раз нужен быстрый резайс.
homm
14.02.2017 12:17Не пробовал собирать последние версии, но ранние собирал, там флаги те же, функции те же. Так что смотрите папку winbuild оригинального репозитория.
nckma
14.02.2017 12:03+4Если бы такой эффект удалось экстраполировать до масштабов планеты и заменить весь код, занимающийся ресайзом картинок, на более эффективный, польза была бы огромной. Десятки тысяч сэкономленных серверов, сотни киловатт электричества. А это уже одна миллионная от мирового потребления. Да можно было бы спасти планету!
Почему-то сразу вспоминаю про сервера, которые майнят биткоин.
IliaSafonov
14.02.2017 12:53+1Круто, поздравляю! С нетерпением жду продолжения!
Однако было бы корректнее привести результаты замеров времени не на единственной системе MacBook Pro, а на нескольких разных компьютерах.
Кроме того, однажды был у меня с оптимизацией такой случай: качество ухудшилось по сравнению с референсной реализацией. Вы бы показали/рассказали, что сравнение с результатами ImageMagic/OpenCV совпадает бит в бит или визуально совпадает, но численно отличается не более чем 1 градацию для 8 bpp, и т.п.homm
14.02.2017 13:00+4Однако было бы корректнее привести результаты замеров времени не на единственной системе MacBook Pro, а на нескольких разных компьютерах.
Там как минимум три системы. Если у кого-то есть возможность, прошу протестировать на процессорах AMD. Я не смог найти ни одного живого хостинга на этом процессоре.
Вы бы показали/рассказали, что сравнение с результатами ImageMagic/OpenCV совпадает бит в бит
Планирую добавить какую-то метрику отклонения, да.
splav_asv
15.02.2017 00:17+1Попробовал прогнать на домашней машине. Тикет завёл, как просили.
homm
15.02.2017 03:14
В целом все довольно предсказуемо и мало отличается от Интела. Заметно, что ImageMagick и Pillow 2.6 (до всех оптимизаций) тормозят сильнее, чем на Интеловских процессорах. Скорее всего это сказано с ложной зависимостью по данным, о которой будет сказано с следующей статье, и которая была исправлена в GCC 4.9. Если же у вас GCC 4.9 или старше, то можно предположить, что фикс, который устраняет зависимость по данным на Интелах, не делает этого на AMD, что конечно очень печально.
Так же примечательно, что при повороте на 90° и 270° в Pillow 2.6 должно быть сильное проседание из-за неэффективного использования кеша, но его нет. Точнее оно совсем слабое. Такое же слабое проседание видно на серверных процессорах, но у них кеш по 20 мегабайт, они могут себе это позволить. А вот у вашего процессора всего 2 мегабайта на ядро, поэтому я не до конца понимаю, как ему это удается.
splav_asv
15.02.2017 08:08Версия gcc 6.3.1, крайне свежая. Если нужно еще что проверить(например с другой версией gcc) или еще какая-то информация — обращайтесь.
andybelo
14.02.2017 12:59-18После слов «быстрый Питон дальше не читал»

Tirael78
14.02.2017 14:08+3а с чего вдруг такой пафос?
быстрый — суждение оценочное, на надо быть самым быстрым, это ни к чему, нужно быть достаточно быстрым чтобы решать поставленными перед языком задачами, и Python с ними справляется, последнее время все успешнее и успешнее, а если нет, то существует возможность добавить ему скорости и весьма существенно, иными словами он для своих задач вполне хорош, так как если к вам в руки попал молоток не все превратилось в гвозди
DjOnline
14.02.2017 13:27+1Теперь можно так же заняться ускорением экспорта в Jpeg. Например здесь было такое решение несколько лет назад https://habrahabr.ru/post/139970/, но это с CUDA.
Roman_Kh
14.02.2017 14:20Возможно я чего-то не понял, но я взял
opencvи просто вызвалresize:
2560 x 1600 --> 320 x 200 bicubic = 3 ms
А у вас SIMD SSE4 — 7.7 ms, а SIMD AVX2 — 5.7 ms, то есть в 2-2.5 раза медленнее.Tsimur_S
14.02.2017 15:01+11Судя по всему opencv не делает нормальный resampling после bicubic, сравните результат после opencv и после pillow bicubuc тут https://python-pillow.org/pillow-perf/#resampling. Там же описаны причины почему нету opencv в этом бенчмарке.
К тому же приводить свои результаты только одной либы и сравнивать с результатами автора это дурной тон, у вас с автором разное железо и разные условия тестирования.
IliaSafonov
14.02.2017 15:03+1Возможное объяснение здесь: «In these benchmarks, we measure the throughput on single CPU core, not minimum achievable execution time.» Т.е., условно говоря, автор делает измерения в одном потоке, а OpenCV на вашем компьютере решает задачу в 4 потока.
homm
14.02.2017 15:17+8Дело в том, что в opencv для ресайза не используется метод сверток. Там используется тот же метод, что и в Pillow до версии 2.7 для bilinear и bicubic и тот же метод, что используется в элементе canvas в браузерах. Отсылаю вас почитать статью Ресайз картинок в браузере. Все очень плохо. Отличие минимальное — при уменьшении изображения, окно не увеличивается на коэффициент уменьшения, как в свертках. Но это радикально влияет на качество и скорость. Для примера я возьму ту же картинку, что в статье (7000???2926 > 512???214).
Вот код:
im = cv2.imread('pixar.jpg') im = cv2.resize(im, (512, 214), interpolation=cv2.INTER_CUBIC) cv2.imwrite('pixar.cv2.png', im)
Вот результат:

Как видите, он намного ближе к nearest neighbor. В зависимости от задачи вы можете рассматривать такой алгоритм или считать его недопустимым.

popov654
14.02.2017 14:53+2Спасибо вам за познавательную, и главное, понятную статью) Метод изложен очень доходчиво и наглядно, очень классно написано.
Я был бы, однако, очень благодарен, если бы вы подсказали мне какую-то ссылку, где так же понятно описывается принцип упрощения свёртки до двух проходов. Потому что на данный момент мне не ясно, как это может давать идентичный результат (мы ведь по сути не можем при таком сценарии учесть влияние диагональных пикселей из окна фильтра).0serg
14.02.2017 15:32+3Каждый пиксель после горизонтальной свертки становится комбинацией нескольких соседних пикселей по горизонтали. Последующий проход вертикальной свертки комбинирует между собой уже не пиксели исходного изображения, а эти «комбинации по несколько пикселей». Скажем в фильтре 5x5 если нас интересует угол (-2, 2) то на этапе горизонтальной свертки мы посчитаем пиксель p_horizontal[2] = weighted_sum( [-2,2], [-1,2], [0,2], [1,2], [2,2] ) а затем подставим в p = weighted_sum(p_horizontal[-2], [-1], [0], [1], [2]); несложно видеть что в эту сумму войдет и [-2.2] с каким-то весом.
Это работает не для всех возможных 2D сверток, а только для специального их подкласса называемого свертками с «сепарабельными» ядрами. К счастью для ресайза почти все ядра сепарабельные.
Но вообще статья нужна, да. Там много всего интересного.popov654
14.02.2017 17:54Спасибо, кажется понял)
При вертикальной свёртке мы «добавим» пиксели из вертикальной «линейки» с нужными коэффициентами, в каждом из которых уже просуммирована его горизонтальная «линейка». И плюс «своя» линейка уже учтена. Да, всё супер.
Единственное что — если докопаться до коэффициентов, там может оказаться некоторый косяк.
Например, я хочу взять фильтр 3х3 для простоты, и крайние пиксели взять с коэффициентом 0.4. Тогда после горизонтальной свёртки мы добавим 0.4 для крайних элементов в нижней линейке, а при вертикальной мы добавим уже 0.4*0.4=0.16, то есть квадрат коэффициента у нас будет. Тогда как логичнее, наверное, использовать квадратный корень (типа пропорционально расстоянию). Если фильтр не билинейный, то там конечно расстоянию вовсе не пропорционально, но я к тому, что всё равно коэффициенты этой матрицы надо бы пересчитать при таком методе будет :)
popov654
14.02.2017 15:00И ещё касаемо экономии ресурсов хотел бы высказать мнение: даже если опустить тот момент, что такое большое разрешение обычно не нужно, и призвано оно когда-то было скорее сгладить визуально недостатки изображения в случае плохой камеры (для современных моделей смартфонов уже не особо актуально) — всё равно более рационально сжимать изображение до загрузки, а не после. Таким образом, мы экономим и ресурсы сервера, и сетевой канал (который, кстати, не всегда достаточно хороший, чтобы быстро загружать фотографии по 12 мегапикселей).
Я понимаю, что ваш сервис рассчитан на браузеры. Но может, это повод разработчикам современных мобильных браузеров задуматься об API для ресайза картинок? Или, как альтернативный вариант — попытаться использовать Canvas и JavaScript (и кто-то, кажется, на Хабре уже писал про оптимизацию ресайза ровно для тех же целей, разгрузить бэкенд и ускорить загрузку картинок в облако).homm
14.02.2017 15:19+2кто-то, кажется, на Хабре уже писал про оптимизацию ресайза ровно для тех же целей
Это был я
Ресайз картинок в браузере. Все очень плохо
Ресайз картинок в браузере. Все может стать еще хуже


BattleAngelAlita
14.02.2017 18:05-1Ресайзить на GPU будет на порядок быстрее.
homm
14.02.2017 18:15+1Осталось только найти открытые кодеки для PNG, WEBP и JPEG на GPU. Потому что иначе еще нужно распакованные данные туда-сюда гонять, а сделать это быстрее скорости чтения памяти невозможно. А скорость ресайза с AVX2, запущенного ядрах так на восьми, уже больше скорости чтения памяти. И откуда тогда возьмется ускорение на порядок?

basilbasilbasil
14.02.2017 23:12https://habrahabr.ru/post/306566/
homm
14.02.2017 23:24+3Интересно, к какому слову по вашему мнению относится материал по ссылке. К «открытые» или к «кодеки PNG, WEBP»?
BattleAngelAlita
15.02.2017 06:52+1Вот этот результат:
Scale 2560?1600 RGB image
to 5478x3424 lzs 2.04901 s 2.00 Mpx/s
Он Uncompress -> Resize -> Compress? Или просто Resize?
Ну и 8 ядер с AVX2 это уже процессоры для энтузиастов стоимостью >1000$homm
15.02.2017 15:57Он Uncompress -> Resize -> Compress? Или просто Resize?
Из статьи:
Ресемплинг производится над массивом 8-битных RGB пикселей в память, без учета декодирования и кодирования изображений, однако с учетом выделения памяти под конечное изображение и с учетом подготовки коэффициентов, необходимых для конкретной операции.
Ну и 8 ядер с AVX2 это уже процессоры для энтузиастов
Это почти любой серверный процессор.
mkarev
14.02.2017 20:41+1Это называется метод ближайшего соседа. Картинка получается грубой, рваной, неприятной. Так происходит потому, что в конечном изображении была использована очень малая часть исходных пикселей
Быть может из-за эффекта наложения спектров?
Для уменьшения изображения — фильтруем сигнал ФНЧ, а потом прореживаем
Для увеличения — разбавляем сигнал нулями и потом фильтруем ФНЧ
Частота среза ФНЧ = ширине спектра сигнала после уменьшения / до увеличения
Свертка технически это и есть КИХ фильтр, АЧХ которого определяют коэффициенты свертки.homm
14.02.2017 21:26Если честно, я не понял ваш вопрос )
Я для примера описал самый примитивный способ ресайза — метод «ближайшего соседа». Что будет если фильтровать, прореживать, разбавлять, как вы предлагаете? Ну, очевидно будет какой-то другой метод, метод «не ближайшего соседа». Методов-то на самом деле больше двух, просто мне интересны именно свертки, потому что сейчас это самый распространенный метод качественного ресайза.
0serg
15.02.2017 13:07+1mkarev говорит о математике стоящей за ресайзом свертками. Ресайз сверткой и конкретные ядра использующиеся для нее — это просто практическая реализация некоторых принципов общей теории цифрового представления сигналов. В её рамках объяснение о «очень малом числе исходных пикселей» не релевантно; можно в частности легко сделать очень паршивый ресайз сверткой который будет давать, гм, своеобразную картинку используя при этом все пиксели изображения. А реальная проблема — это наложение спектра, «алиасинг» при дискретизации сигнала. Но в общем это тема отдельной статьи, математику ресайза очень мало кто знает и понимает.

ternaus
14.02.2017 22:07+1Большое спасибо. Замечательный проект и замечательный пост. Пара вопросов.
[1] cv2 умеет делать resize для картинок с большим количеством каналов > 3. PIL-SIMD так умеет или надо разрезать на куски по 3 слоя, менять размер, и склеивать обратно? (В задаче про спутниковые снимки на Kaggle приходится работать вплоть до 20 каналов.)
[2] cv2 автоматически распараллеливает операцию resize. PIL-SIMD так умеет?
[3] Рабоче-крестьянский вопрос — если забить на производительность, какой тип сверток субъективно обеспечивает наилучшее качество? Cubic?
homm
14.02.2017 22:45+4Все же правильно Pillow-SIMD. PIL давно мертв.
Максимум 4 восьмибитных канала на изображение. Есть режимы 1 восьмибитный канал, 1 float и 1 канал 32-битный int, но ни один из них сейчас не ускорен SIMD.
По разным ядрам сейчас нет распараллеливания. Но даже из Питона распараллелить по потокам довольно просто. Дело в том, что Сишный код отпускает GIL и возможна работа в несколько потоков. Кроме того, если готовы вложить время, то есть очень старый пулреквест, в котором пробовали прикрутить OpenMP. Он на удивление просто прикручивается для GCC. Как и в любом опенсорсе, что-то делается если кому-то это нужно. В моем приложении, если честно, параллельная обработка не сильно нужна, я гонюсь за максимальным throughput.
- Субъективно? Мне бикубик больше нравится. Ланцош более резкий благодаря более глубоким отрицательным долям. Иногда эта резкость идет в плюс, иногда подпорчивает результат. А бикубик очень стабильный результат дает.

kosmos89
15.02.2017 13:19На сколько я понимаю, ни одна из библиотек не учитывает, что почти все изображения сохранены в пространстве sRGB, и не делают для них гамма коррекцию перед сверткой и после. Соответственно, изображения выглядят темнее, чем должны.
homm
15.02.2017 14:18Совершенно верно, ни одна из библиотек не делает гамма-коррекции во время ресайза, потому что:
- Гамма-коррекция и ресайз — не связанные операции. В идеале ресайз должен проходить в линейном цветовом пространстве, поэтому ресайз не делает никаких преобразований. Все преобразования должны быть до и после.
- Вы правильно написали «почти все изображения». Главное слово тут «почти». И нужно делать преобразование не из sRGB в линейный и обратно, а полноценный менеджмент цветов используя тот цветовой профиль, который прикреплен к изображению.
- Гамма коррекция не является операцией преобразования даже из sRGB в линейный и обратно. Не говоря о других цветовых пространствах.
Так что этот вопрос не связан с ресайзом напрямую.
kosmos89
15.02.2017 16:52+1Если делать ресайз флотовых данных, то можно и не учитывать, а если конвертить во флоат не хочется или не можется, и входные и выходные данные в 8bpc, то придется. Иначе будут огромные потери в точности.
homm
16.02.2017 00:07+2На самом деле для преобразования
8 bit sRGB>linear RGB>8 bit sRGBбез потерь не нужен float, достаточно 12 бит. С 16 битами уже можно почти без потерь совместить premultiplied alpha и линейны RGB, там все ошибки будут при alpha < 12 (из 255).
16-битный режим в Pillow очень хотелось бы (и ресайз в 16 битах для этого далеко не самое сложное), но пока никто этим не занимался.

kovserg
15.02.2017 14:20+1На скорость масштабирование может влияет не только скорость вычислений. Но и как часто вы промахиваетесь мимо кэша и предсказаний brunch prediction. Попробуйте разбить изображение на блоки разных размеров и сравнить скорости. Более того блоки получаются независимыми и легко параллелятся на разные ядра процессора.
Уверяю вас что "матан не закончен". При уменьшении изображений есть свои тонкости вот попробуйте свой алгоритм на такой картинке

Мой компьютер не поддерживает ни AVX2 ни AVX512, но это не мешает использовать CUDA.
Так выглядит результат афинных преобразований вообще без фильтров 50% 0°
50% 0°
 50% 15°
50% 15°
 50% 30°
50% 30°
 62.5% 45°
62.5% 45°
 /8 0°
/8 0°
 /8 7°
/8 7°
 *5.5 15°
*5.5 15°homm
15.02.2017 14:31Уверяю вас что "матан не закончен".
Смотрите ответ выше.
Мой компьютер не поддерживает ни AVX2 ни AVX512, но это не мешает использовать CUDA.
Так используйте, я не против. А SSE4 тоже не поддерживает?
kovserg
15.02.2017 17:20У меня MIPS SIMD в тв-приставке и ARM NEON в телефоне и планшете, в одном из ноутов SSE4+FMA4, в другом SSE4.2+AVX, даже есть один с SSE2.

ErmIg
15.02.2017 18:21+2У меня есть небольшая собственная библиотечка по обработке изображений. Тоже есть оптимизации под практически все расширения x86, Arm, PowerPC. В ней есть функция SimdResizeBilinear. Конечно сравнивать напряму нельзя. Но при ресайзе изображения (1920х1080 -> 1728x972) получается для одного потока: (Gray-8 — 0.426 мс, BGR-24 — 2.477 мс, BGRA-32 — 2.063 мс).
homm
16.02.2017 00:11Я правильно понимаю, что это bilinear все с тем же фиксированным окном, т.е. дающий хороший результат только при увеличении? Не смог до конца разобраться в коде.
kovserg
16.02.2017 01:25bilinear это линейная интерполяция по 4 соседям (см. SimdBaseResizeBilinear.cpp)
А при увеличении хороший результат bspline для фоток и точный вариант по площадям для сканов текстов, чертежей и карт. Билинейное при увеличении даёт не естественное размытие.
newisus
17.02.2017 00:45homm, скажите, вы сравнивали точность вычислений для своего подхода и приведённых выше библиотек (ImageMagic, IPP, Skia)?
Вы считаете промежуточные вычисления через float для Bicubic и Lanczos интерполяций?homm
17.02.2017 01:21вы сравнивали точность вычислений для своего подхода
https://github.com/uploadcare/pillow-simd/blob/simd/3.4.x/Tests/test_image_resample.py
и приведённых выше библиотек (ImageMagic, IPP, Skia)
Нет.
Вы считаете промежуточные вычисления через float для Bicubic и Lanczos интерполяций?
Нет.

random1st
20.02.2017 13:19+4Использовал такой хак для ресайза с Pillow. Если позволял размер изображения, сначала ресайзил до двойного требуемого размера без антиалиасинга, потом результат до нужного с антиалиасингом. Ускорение было весьма существенное, результат практически идентичен.
homm
20.02.2017 15:03результат практически идентичен
Это конечно неправда. Вы могли посмотреть какую-то конкретную картинку и не увидеть различий, но в общем случае различия очень существенные.
homm
20.02.2017 16:04+3Слушайте, я попробовал и это гениально на самом деле. Понятно, что для качественного ресайза не годится и относится к «трюкам и оптимизациям частных случаев». Но для супердешевого ресайза для какой-нибудь последующей обработки самое то.
from PIL import Image im = Image.open('pixar.jpg') im.resize((1024, 428), Image.NEAREST).resize((512, 214), Image.BICUBIC).save('pixar.2x.bic.png')

По скорости очень впечатляет:
In [3]: %timeit im.resize((1024, 428), Image.NEAREST).resize((512, 214), Image.BICUBIC) 100 loops, best of 3: 2.99 ms per loop In [4]: %timeit im.resize((512, 214), Image.BICUBIC) 10 loops, best of 3: 31.1 ms per looprandom1st
20.02.2017 18:14А Вы можете как-нибудь объективно оценить, насколько хуже качество картинки в этом случае?
homm
20.02.2017 20:21+1Визуальные алгоритмы сложно оценивать объективно. Но вот еще материал для субъективного сравнения:
Image.NEAREST (0.5 ms) cv2.INTER_CUBIC (2.6 ms) ваш метод (1.66 ms) Image.BICUBIC (40 ms)




Это сильное уменьшение этого изображения. Как видите, по соотношению цена/качество очень хорошо. Еще ваш алгоритм можно тюнить, изначально уменьшая в другое число раз.
random1st
21.02.2017 00:09Ради справедливости должен сказать, баян не мой, я на этот хак где-то на просторах сети наткнулся. Но он мне существенно облегчил жизнь.
random1st
21.02.2017 00:26+2Да, еще хотел сказать касаемо AWS. Детально описывать не буду, но есть отличный способ организовать практически моментальный ресайз при использовании S3. Заключается в развертывании кода ресайза на AWS Lambda и подписке ее на ивенты с S3. С точки зрения использования выглядит это так — кладем картинку на S3, и дальше стучимся по заранее определенным url за уже готовыми картинками. С учетом данного способа создается впечатление, что все отрабатывает практически моментально.
Durimar123
99% хабра это не радует, а однозначно огорчает.
homm
Если вы в состоянии внедрить в свой проект кусок кода на Си со Stack Overflow, то можете сделать то же самое с кодом с гитхаба, разве нет? (раз, два).