

С чего начинается любой проект по ИТ-инфраструктуре? Если вы подумали о чем-то вроде: админы собрались, обсудили и кто-то предложил решение, — то с высокой вероятностью попали в точку. Именно так обстоят дела с эксплуатацией в российских компаниях, и у нас до недавнего времени тоже.
В статье расскажу о том, как мы потратили 5 миллионов и почти полгода на то, чтобы убедиться: отличных специалистов и энтузиазма недостаточно для внедрения чего-либо масштабного.
Все началось с осознания того, что пара-тройка огромных монолитных приложений в основе платежного сервиса — это громоздко и неудобно. Верстка, Портал и Биллинг Яндекс.Денег обслуживались отдельно несколькими командами эксплуатации, которые накатывали обновления и следили за работой систем. Процесс, работавший стабильно годы, начал сбоить, когда в компании стали формироваться проектные команды и частота релизов возросла экспоненциально.
Увеличилось и количество конфликтов при работе с одними и теми же участками кода, не говоря уже о приемочном тестировании, которое порой длилось больше месяца. Что в таких случаях делают современные компании? Делят свои монолиты на множество мелких (микро-) сервисов.
ОК, переходим на микросервисы
Больше сервисов — больше нагрузки на сопровождение. Ведь теперь в день выходит по 5-10 релизов. По старому процессу каждый из них после тестирования нужно вручную накатить на несколько узлов — выходило до 100 ручных обновлений в день. С учетом необходимости обновления тестовых стендов, число которых равно количеству команд, цифра исчислялась тысячами ручных операций.
Даже команда лучших инженеров эксплуатации с внутривенной подачей кофеина не осилит ежедневное обновление тысяч систем — все это нужно автоматизировать. Сказано — сделано: из эксплуатации выделили группу DevOps, которой поручили заниматься автоматизацией. Ну как выделили — некоторое время они вместе с админами занимались текучкой и проектной работой, а потом уже отделились под конкретные задачи.
Программисты и тестировщики терпеливо ждали волшебного решения, а воодушевленные большой амбициозной задачей ребята из DevOps трудились с утра до вечера над инфраструктурой автоматической установки релизов и развертыванием тестовых стендов «по кнопке».
Чтобы лучше понимать происходящее, разберемся в том, как в команде DevOps-ов представляли систему сборки и тестирования на первом этапе:
Создаем универсальный сценарий сборки каждого приложения для любого окружения.
Создаем настройки для сборки приложений для боевого и различных тестовых окружений.
Разворачиваем среду виртуализации, позволяющую создавать тестовые окружения с настройками по шаблону.
При каждом релизе собираем и устанавливаем обновленное приложение на боевое окружение, а также на каждое из существующих тестовых окружений.
- Тонкие настройки и изменения, которые проводятся в процессе релиза на боевом окружении, повторяем вручную на каждом из тестовых.
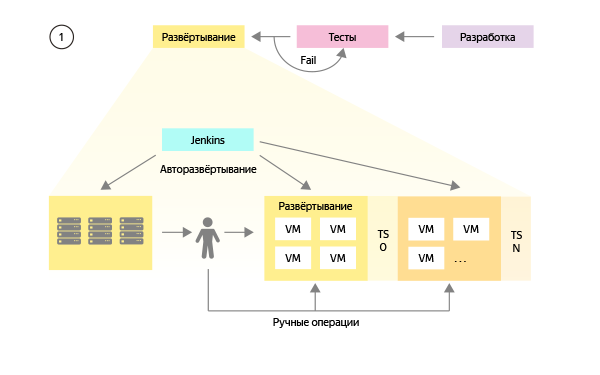
Со временем планировали еще настроить GUI для управления всеми процессами и постепенно избавиться от ручных операций на всех типах окружений.
Прошло несколько месяцев
Собранная в лаборатории система виртуальных стендов и сборки релизов Ansible-Jenkins столкнулась с реальным миром. И тут первое же производственное тестирование выявило несколько фундаментальных проблем:
Один более-менее работающий стенд собирался вручную за несколько недель, а не часов. Потребности за время ожидания выросли с десятков до нескольких сотен стендов, что отодвигает срок завершения работ куда-то в следующий век.
Попутно выяснилось, что каждый стенд использует около 200 ГБ дискового пространства. Если помножить этот объем на число требуемых стендов — это дает какие-то неприличные цифры ежедневного «оборота» дискового пространства;
- У разных команд методы разработки, тестирования, конфигурирования и развертывания сервисов немного отличались. Поэтому предложенный вариант полностью не устроил ни одну из команд разработки.
Вы ведь помните, что администраторы привыкли работать без руководителя проектов? При обнаружении вороха проблем они обычно складывают их все в «бэклог» и решают по очереди. Когда же ситуация накаляется, они продолжают делать все то же самое, но быстрее или больше.
Вообще, мало что способно деморализовать специалиста так же сильно, как низкая оценка его упорного труда и частая смена приоритетов. К сожалению, мы наступили на эти грабли, так как усилия эксплуатации были направлены не в ту сторону. Результат закономерен: новый процесс в срок не заработал, а вот старый окончательно сломался, подбросив разработчикам и тестировщикам ворох проблем.
Параллельно началась мучительная пора попыток использовать прибывающие новые стенды. Так как каждый такой стенд добавлял ручной работы по его обновлению, очередь задач у админов стала стремительно расти, а отношение разработчиков к этому проекту — столь же стремительно ухудшаться.
Разведка всему голова
Даже самую неудобную проблему важно вовремя признать и начать работать над ее устранением. Наша ключевая ошибка была связана не с технологиями, она заключалась в недостаточном внимании к управлению проектом, определению требований и оценке ожиданий заинтересованных сторон:
DevOps-ы в принципе не могли сделать этот проект в одиночку. Пока в него не включились разработка и тестирование, вся работа по большому счету делалась в стол.
Разработчиков и тестировщиков вообще мало спрашивали, что им нужно. Сисадмины сосредоточились на задачах деплоя, а разработчики и тестировщики очень нуждались в инструменте, позволяющем автоматически поднимать стенды и прогонять тестовые сценарии.
У бизнес-заказчика были ограничения по ресурсам. Разработка новых процессов и поддержание старых в него просто не вмещались. Это обнаружили слишком поздно.
- И самое банальное: без проектного менеджера вся история сводилась к обещаниям завершить работу завтра-послезавтра, но результатов не появилось и через полгода.
Когда прошла первая эмоциональная реакция и все ключевые люди встретились вместе для обсуждения своих «хотелок», стало очевидным, что решать проблему нужно сначала. Только на этот раз мы отнеслись к этому как к проекту в разработке: с целью, требованиями, сроком, ресурсами, заказчиками, ответственным, планом работ, техническим решением и т.д.
Собранные заново требования включали детали, которые мы пропустили на первой итерации. Детали, оказавшиеся роковыми.
При втором подходе мы учли:
сколько и какие тестовые стенды будут нужны через пару лет, а не прямо сейчас;
какой объем данных должен быть в каждом тестовом стенде;
как стенды будут изолированы друг от друга и от боевого окружения;
какие требования у команд разработки к их обновлению;
как на стендах будут работать тестировщики;
- как будут проверяться связи тестового окружения с внешними сервисами.
Понимание деталей разделило казавшийся цельным проект на подпроекты, связанные с обеспечением виртуального пространства, сетевой изоляции, доставки обновлений, возможности конфигурировать приложения и т.д.
В результате самым работоспособным оказался вариант, при котором есть ровно две среды: боевая и эталонная тестовая. А всё множество командных тестовых сред создается клонированием эталонного стенда с настроенными компонентами. При таком раскладе командам разработки нужно будет сделать минимум изменений в своих компонентах и заглушках внешних сервисов. А уменьшение объема тестовых данных в 20 раз позволит перенести БД внутрь стендов. Изоляцию стендов обеспечат сетевые инженеры на уровне подсетей и настроек DNS-серверов.
Доработанная схема выглядит так:
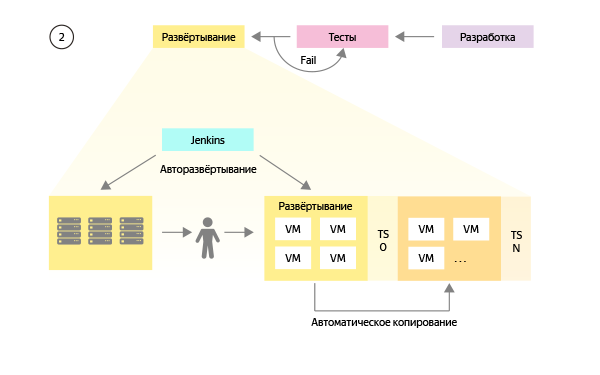
Небольшое визуальное отличие на схеме (меньше ручных операций) в работе меняет очень многое, так как перенос изменений на все тестовые среды происходит автоматически и больше не требует пристального внимания инженеров.
Выводы после прохождения «сада граблей»
Можно подумать, что все вышесказанное очевидно. Однако вещи, очевидные в одной области, не всегда очевидны в другой. Есть огромное количество примеров, когда масштабные инфраструктурные проекты в эксплуатации изменяются «на коленке». Можно успешно менять ДЦ, запускать новые офисы, переезжать с СУБД на СУБД, выезжая на компетенции инженеров, уже делавших такие проекты раньше.
Но когда попадается проект, в котором эксплуатации нужно действовать сообща с разработкой, поддержкой и много чем еще, вероятность провала без проектного управления возрастает многократно. А много ли вы видели выделенных менеджеров инфраструктурных проектов в софтверных компаниях?
Вместо заключения в духе «они поженились, жили долго и счастливо» приведу выводы, которые мы сделали на будущее:
Проектная работа необходима системным администраторам точно так же, как и разработчикам. Без руководителя проектов у каждого участника будет свое видение, что в конечном счете не позволит всей команде прийти в заданную точку.
Нет ничего хуже для мотивации специалиста, чем осознание бесполезности потраченного на задачу времени. Чтобы время не тратилось впустую, должно быть четкое понимание, каких целей нужно достичь участникам проекта и для чего. Нам очень помогли регулярные встречи разработчиков, тестировщиков и админов.
Нужно обязательно найти способ проверять и пытаться использовать промежуточные результаты работы системных администраторов, чтобы впоследствии не пришлось перечеркнуть весь их многомесячный труд.
- Даже команда лучших инженеров с идеальной мотивацией в вакууме не компенсирует ущерб от несогласованности действий головы и ног.
Интересно, а как работают над масштабными ИТ-проектами в вашей компании — не сталкивались ли вы с аналогичными проблемами проектного управления?
Комментарии (5)

ConceptDesigner
22.02.2017 12:13У нас пишется ТЗ и работы выполняются строго по нему. Время от времени ТЗ корректируется, но согласовывается с заказчиком. И обычно корректировки затрагивают смену дизайна и прочие бантики.
А если не секрет, подскажите, 5 миллионов каких денежных единиц вы потратили?
Dimmentio
22.02.2017 12:45ТЗ в разработке давно уже норма вещей. А вот ТЗ у системных администраторов внедряется сложно. Какое оно у вас: насколько большое, как сформулированы требования, с какой детализацией описана реализация, включает ли в себя план работ? Что касается затрат — конечно, в рублях))
ConceptDesigner
23.02.2017 01:48У нас когда идет разработка нового функционала, садятся разработчики, админы и представитель от конечных пользователей. И в ТЗ попадают только те пожелания, которые получают одобрение от всех участников. Бывает, что из-за невозможности безболезненно накатить новый функционал у клиентов (на что обычно как раз и указывают админы), функционал приходится переосмысливать и иногда даже отказываться от него. Для каждого клиента у нас развернута своя виртуальная среда, и как это упростить, мы пока не придумали. Возможно, у нас поток обновлений не такой интенсивный, как у вас.
anatan
Да так же все и работают. Сталкивались конечно. И читали "Как тестируют" правильные компании.
Но у нас каждый ищет свой путь(
строит свой велосипед), знаете же.Большой плюс, что у вас одна версия в продакшене, и следующая на тесте.
В нашем случае на продукте, который не менее масштабный и тиражируемый, сопровождается около трех последних активных версий и плюсом до пяти разных старых версий, которые стоят у клиентов.
Такая же примерно схема как у вас на текущей версии разработки и n-ое количество стендов под более ранние версии.
Что-то в начале писали про 5 миллионов, я так и не понял по тексту на что вы их потратили. А в целом согласен, размах тестирования зависит от целей и финансов. Руководитель всего этого также нужен. Тут вообще обеими руками «за». Никаких особых секретов то тут и нет. Просто грамотный и работающий производственный процесс.
Dimmentio
С пятью миллионами все просто — для значимых проектов у нас есть практика оценочно проверять их стоимость. Это не расходы на покупку софта или услуги подрядчиков, это пересчет времени наших специалистов в деньги. Мы раз в полгода-год берем все прямые расходы (зарплата, премии, налоги) и косвенные (аренда, связь, общие расходы) и расчитываем стоимость человеко-дня по ключевым ролям. Не стремимся к точности до копейки, достаточно грубой оценки. Зато благодая этому можно для любого проекта очень быстро прикинуть его планируемую и фактическую стоимость для компании. Очень помагает осознавать масштаб инициатив или сравнивать с аналогичной стоимостью на рынке у аутсорсеров / интеграторов.