
Ненадёжные (flaky), то есть недетерминированные тесты ведут себя иначе. Они могут показать как положительный, так и отрицательный результат на одном и том же коде. Другими словами, сбой теста может означать, а может и не означать появление новой проблемы. И попытка воспроизвести ошибку путём перезапуска теста на той же версии кода может привести или не привести к успешному проходу теста. Мы рассматриваем такие тесты как ненадёжные, и в конце концов они теряют свою ценность. Если изначальная проблема — это недетерминизм в рабочем коде, то игнорирование теста означает игнорирование бага в продакшне.
Ненадёжные тесты в Google
В системе непрерывной интеграции Google работает около 4,2 млн тестов. Из них примерно 63 тыс. показывают непредсказуемый результат в течение недели. Хотя они представляют менее 2% от всех тестов, но всё равно ложатся серьёзным бременем на наших инженеров.
Если мы хотим починить ненадёжные тесты (и избежать написания новых), то прежде всего нужно понять их. Мы в Google собираем много данных по своим тестам: время выполнения, типы тестов, флаги выполнения и потребляемые ресурсы. Я изучил, как некоторые из этих данных коррелируют с надёжностью тестов. Думаю, что это исследование может помочь нам улучшить и сделать более стабильными методы тестирования. В подавляющем большинстве случаев, чем больше тест (по размеру бинарника, использованию RAM или количеству библиотек), тем менее он надёжен. В остальной статье обсудим некоторые из обнаруженных закономерностей.
Предыдущее обсуждение ненадёжных тестов см. в статье Джона Микко от мая 2016 года.
Размер теста — большие тесты менее надёжны
Мы разбили тесты на три группы по размеру: маленькие, средние и большие. У каждого теста есть размер, но выбор метки субъективен. Инженер определяет размер, когда изначально пишет тест, и размер не всегда обновляется при изменениях теста. Для некоторых тестов эта метка больше не соответствует реальности. Тем не менее, у неё есть некоторая прогностическая ценность. В течение недели 0,5% наших маленьких тестов проявляли свойство недетерминированности, 1,6% средних тестов и 14% больших тестов [1]. Наблюдается явное уменьшение надёжности от маленьких тестов к средним и от средних к большим. Но это всё равно оставляет открытыми много вопросов. Мало можно понять, учитывая только размеры.
Чем больше тест, тем меньше надёжность
Мы собираем некоторые объективные оценки: бинарный размер теста и объём оперативной памяти, используемой во время работы теста [2]. Для этих двух метрик я сгруппировал тесты на две группы равного размера [3] и вычислил процент ненадёжных тестов в каждой группе. Числа внизу — это значения r2 для наилучшего линейного объективного прогноза [4].
| Корреляция между метрикой и прогнозом ненадёжности теста | |
| Метрика | r2 |
| Бинарный размер | 0,82 |
| Используемая RAM | 0,76 |
Рассматриваемые здесь тесты — это по большей мере герметичные тесты, которые выдают сигнал успех/неудача. Бинарный размер и использование RAM хорошо коррелировали по всей выборке тестов, и между ними нет особой разницы. Так что речь не просто о том, что большие тесты скорее будут ненадёжными, а о постепенном уменьшении надёжности с увеличением теста.
Ниже я составил графики с этими двумя метриками для всего набора тестов. Ненадёжность возрастает с увеличением бинарного размера [5], но мы также наблюдаем увеличение разности [6] в линейном объективном прогнозе.
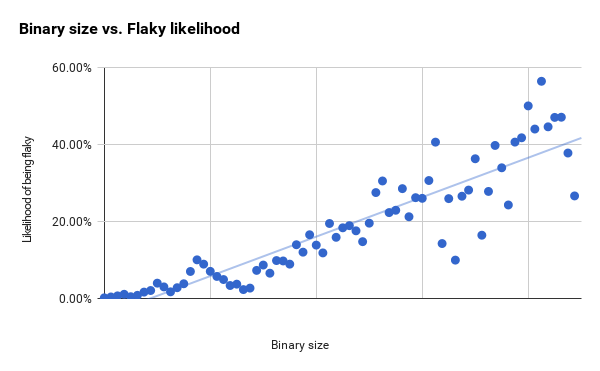
График использования оперативной памяти внизу продвигается более чётко и начинает демонстрировать большие разности только между первой и второй вертикальными линиями.
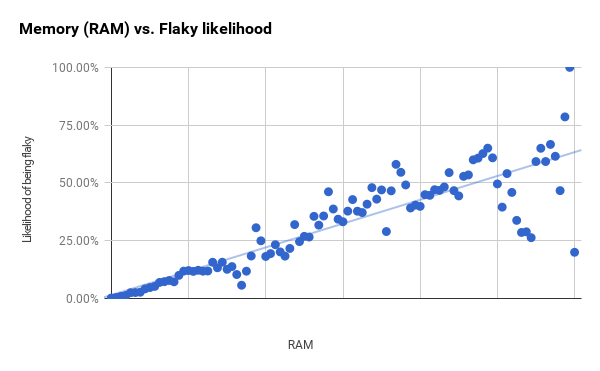
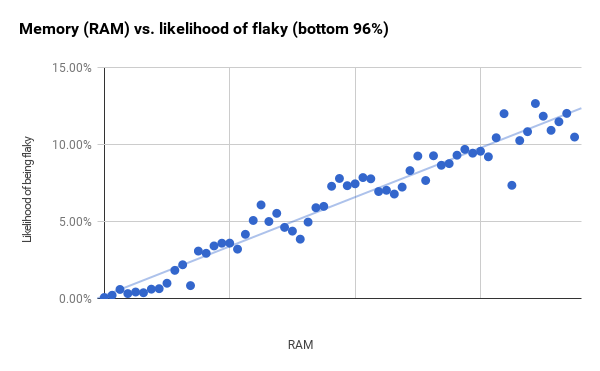
Хотя размеры групп постоянны, но количество тестов в каждой из них разное. Точки справа на графике с большими разностями соответствуют группам, которые содержат гораздо меньше тестов, чем группы слева. Если взять меньшие 96% тестов (которые заканчиваются сразу за первой вертикальной чертой) и затем уменьшить размер групп, то получается гораздо более сильная корреляция (r2 равняется 0,94). Вероятно, это означает, что RAM и бинарный размер имеют гораздо большую предсказательную силу, чем показано на общих графиках.
Определённые инструменты коррелируют с частотой ненадёжных тестов
Некоторые инструменты обвиняют в том, что они являются причиной ненадёжных тестов. Например, тесты WebDriver (будь они написаны на Java, Python или JavaScript), имеют репутацию ненадёжных [7]. Для некоторых из наших обычных тестовых инструментов я вычислил долю ненадёжных тестов, написанных с помощью этого инструмента. Нужно отметить, что все эти инструменты чаще используются при создании тестов большего размера. Это не исчерпывающий список инструментов тестирования, и он покрывает примерно треть всех тестов. В остальных тестах используются менее известные инструменты или там нельзя определить инструмент.
| Ненадёжность тестов при использовании некоторых из наших обычных тестовых инструментов | ||
| Категория | Доля ненадёжных | Доля от всех ненадёжных тестов |
| Все тесты | 1,65% | 100% |
| Java WebDriver | 10,45% | 20,3% |
| Python WebDriver | 18,72% | 4,0% |
| Внутренний инструмент интеграции | 14,94% | 10,6% |
| Эмулятор Android | 25,46% | 11,9% |
Все эти инструменты показывают процент ненадёжности выше среднего. А учитывая, что каждый пятый ненадёжный тест написан на Java WebDriver, становится понятно, почему люди на него жалуются. Но корреляция не означает наличия причинно-следственной связи. Зная результаты из предыдущего раздела, можно предположить, что некий иной фактор уменьшает надёжность тестов, а не просто инструмент.
Размер даёт лучший прогноз, чем инструменты
Можно совместить выбор инструмента и размер теста — и посмотреть, что важнее. Для каждого упомянутого инструмента я изолировал тесты, которые используют этот инструмент, и разделил их на группы по использованию памяти (RAM) и бинарному размеру, по такому же принципу, как и раньше. Затем рассчитал линию наилучшего объективного прогноза и насколько она коррелирует с данными (r2). Потом вычислил прогноз вероятности, что тест будет ненадёжным в самой маленькой группе [8] (которая уже покрывает 48% наших тестов), а также 90-й и 95-й процентиль по использованию RAM.
| Предсказанная вероятность ненадёжности по RAM и инструменту | ||||
| Категория | r2 | Наименьшая группа (48-й процентиль) | 90-й процентиль | 95-й процентиль |
| Все тесты | 0,76 | 1,5% | 5,3% | 9,2% |
| Java WebDriver | 0,70 | 2,6% | 6,8% | 11% |
| Python WebDriver | 0,65 | ?2,0% | 2,4% | 6,8% |
| Внутренний инструмент интеграции | 0,80 | ?1,9% | 3,1% | 8,1% |
| Эмулятор Android | 0,45 | 7,1% | 12% | 17% |
Эта таблица показывает результаты вычислений для RAM. Корреляция сильнее для всех инструментов, кроме эмулятора Android. Если игнорировать эмулятор, то разница в корреляции между инструментами при схожем использовании RAM будет в районе 4-5%. Разница между самым маленьким тестом и 95-м процентилем составляет 8-10%. Это один из самых полезных выводов нашего исследования: инструменты оказывают некое влияние, но использование RAM даёт гораздо большие отклонения по надёжности.
| Предсказанная вероятность ненадёжности по бинарному размеру и инструменту | ||||
| Категория | r2 | Наименьшая группа (33-й процентиль) | 90-й процентиль | 95-й процентиль |
| Все тесты | 0,82 | ?4,4% | 4,5% | 9,0% |
| Java WebDriver | 0,81 | ?0,7% | 14% | 21% |
| Python WebDriver | 0,61 | ?0,9% | 11% | 17% |
| Внутренний инструмент интеграции | 0,80 | ?1,8% | 10% | 17% |
| Эмулятор Android | 0,05 | 18% | 23% | 25% |
Для тестов в эмуляторе Android практически отсутствует корреляция между бинарным размером и ненадёжностью. Для других инструментов можно увидеть большую разницу прогноза ненадёжности между маленькими и большими тестами по по потреблению RAM; до 12 процентных пунктов. Но в то же время при сравнении тестов по бинарному размеру разница прогноза ненадёжности ещё больше: до 22 процентных пунктов. Это похоже на то, что мы видели при анализе использования RAM, и это ещё один важный вывод нашего исследования: бинарный размер важнее для отклонений в прогнозе ненадёжности, чем используемый инструмент.
Выводы
Выбранный разработчиком размер теста коррелирует с ненадёжностью, но в Google недостаточно вариантов выбора размера, чтобы этот параметр действительно был полезен для прогноза.
Объективно измеренные показатели бинарного размера и использования RAM сильно коррелируют с надёжностью теста. Это непрерывная, а не ступенчатая функция. Последняя показала бы неожиданные скачки и означала бы, что в этих точках мы переходим от одного типа тестов к другому (например, от модульных тестов к системным или от системных тестов к интеграционным).
Тесты, написанные с помощью определённых инструментов, чаще дают непредсказуемый результат. Но это в основном можно объяснить бoльшим размером этих тестов. Сами по себе инструменты вносят небольшой вклад в эту разницу по надёжности.
Следует с осторожностью принимать решение о написании большого теста. Подумайте, какой код вы тестируете и как будет выглядеть минимальный тест для этого. И нужно очень осторожно писать большие тесты. Без дополнительных защитных мер есть большая вероятность, что вы сделаете тест с недетерминированным результатом, и такой тест придётся исправлять.
Примечания
- Тест считался ненадёжным, если показывал хотя бы один ненадёжный результат в течение недели.
- Я также принял в расчёт количество библиотек, созданных для теста. В 1%-ной выборке тестов бинарный размер (0,39%) и использование RAM (0,34%) проявляют более прочные корреляции, чем количество библиотек (0,27). Далее я исследовал только бинарный размер и использование RAM.
- Примерно по 100 групп для каждой метрики.
- r2 измеряет, насколько близко линия наилучшего прогноза соответствует данным. Величина 1 означает, что линия полностью совпадает с данными.
- Есть две интересные области на графиках, где точки в реальности показывают обратную тенденцию к общему повышательному тренду. Одна начинается примерно на полпути к первой вертикальной линии и продолжается в течение двух точек данных, а вторая начинается прямо перед первой вертикальной линией, а заканчивается сразу после неё. Здесь размер выборки достаточно большой, так что это вряд ли будет просто случайный шум. Вокруг этих точек есть сгустки тестов, которые более или менее ненадёжные, чем можно ожидать исходя только из бинарного размера. Это перспектива для будущих исследований.
- Расстояние между наблюдаемой точкой и линией объективного прогноза.
- Другие инструменты для веб-тестирования тоже обвиняют, но мы чаще всего используем именно WebDriver.
- Некоторые из предсказанных процентов ненадёжности для самых маленьких групп вышли отрицательными. Хотя в реальности не может быть отрицательной части тестов, но это возможный результат при использовании такого типа прогноза.
Комментарии (8)

aml
27.04.2017 06:27+2Глючит, в основном, асинхронщина. И чем её больше в тесте, тем больше шансов получить неожиданный результат. Интеграционные веб-тесты — это особенно запущенный случай — в них обычно участвует много компонентов, поэтому они страдают больше других.

lany
27.04.2017 11:12Интересно, есть ли устоявшийся перевод flaky? Мы такие тесты называем "мигающими", а тут "ненадёжные". А ещё кто-нибудь как-нибудь называет?

PositiveAlex
27.04.2017 19:40В терминологии xunit есть определение «нестабильного теста» (Erratic Test) (разный результат без модификации системы) и «хрупкого теста» (Fragile Test) (постоянно падающий тест после модификаций системы).
lany
27.04.2017 11:19Тест считался ненадёжным, если показывал хотя бы один ненадёжный результат в течение недели.
Тут непонятно, а что такое "ненадёжный результат". Скажем, произошла регрессия, тест попадал два дня, потом пофиксали регрессию, тест перестал падать. Это явно не flaky. У TeamCity есть четыре эвристики для определения flaky-тестов:
- Частая смена состояния между "падает" и "проходит" в одной и той же билд-конфигурации и/или на одном и том же агенте за определённый период времени (как я понимаю, пороги настраиваются)
- Различный результат для одного и того же коммита, но разных билд-конфигураций (например, под разной OS или на разном железе)
- Различный результат при перезапуске билда без изменений из VCS
- Различный результат при повторном прогоне теста внутри одного билда (например, если задан invocationCount для TestNG-теста)
А что в этой статье имелось в виду?
PositiveAlex
27.04.2017 19:51Согласен. Там говорится о «той же версии кода» — довольно размыто, потому как у кода есть свои зависимости (сторонние модули) и учитывались ли все зависимости этого кода — вопрос. Кроме того, окружение изолированное или нет. Если нет — то еще один фактор сбоя. Кроме того есть зависимости у самого кода теста и чем больше код теста — тем больше он использует код фреймворка.
Можно увидеть, что чем больше тест — тем больше он затрагивает различных зависимостей как внешних, так и внутренних.
И это естественно, на мой взгляд.
pftbest
А что если тест на самом деле хороший, но код который он тестирует содержит race condition, который проявляется только на этом тесте?
sshikov
Или просто неинициализированные данные… а дальше как повезет.
PositiveAlex
Это никак не связано с количеством кода теста и оперативной памятью. Это просто отдельная категория тестов. В противном случае, можно было бы говорить о том, что чем длиннее автотест, тем чаще он тестирует race condition, что на мой взгляд, звучит довольно странно.