
Новичку в NodeJS действительно может быть нелегко. JS — один из языков, в котором часто не существует единственного правильного решения конкретной задачи, а добавленные в ноду модули для работы с файловой системой, http сервером и прочими вещами, характерными для работы на сервере, затрудняют переход даже тем, кто пишет хороший код для браузеров. Тем не менее, я надеюсь, что вы знаете основы этого языка и его работы в серверном окружении, если нет, советую посмотреть замечательный скринкаст, который поможет разобраться в основах. И последнее — я не претендую на какой-то исключительно правильный код и буду рад услышать критику — мы все учимся, и это отличный способ получать знания.
Начнём с файловой структуры
Исходная папка nodejs хранится на сервере по пути /var/www/html/. В ней и будет наш веб-сервер. Дальше всё просто: создаём в ней директорию routing, в которой будет лежать наш скрипт index.js, а также 4 папки — dynamic, static, nopage и main — для динамически генерируемых страниц, статики, страницы 404 и главной страницы. Выглядит всё это так:
nodejs
--routing
----dynamic
----nopage
----static
----main
----index.js
Создаём наш сервер
Отлично, с файловой структурой более-менее определились. Теперь создаём в исходной папке файл server.js со следующим содержимым:
// server.js
// Для начала установим зависимости.
const http = require('http');
const routing = require('./routing');
let server = new http.Server(function(req, res) {
// API сервера будет принимать только POST-запросы и только JSON, так что записываем
// всю нашу полученную информацию в переменную jsonString
var jsonString = '';
res.setHeader('Content-Type', 'application/json');
req.on('data', (data) => { // Пришла информация - записали.
jsonString += data;
});
req.on('end', () => {// Информации больше нет - передаём её дальше.
routing.define(req, res, jsonString); // Функцию define мы ещё не создали.
});
});
server.listen(8000, 'localhost');
Здорово! Теперь наш сервер будет принимать запросы, записывать JSON-данные, если они есть, но пока что будет вылетать с ошибкой, потому что у нас нет функции define в /routing/index.js. Время это исправить.
// /routing/index.js
const define = function(req, res, postData) {
res.end('Hello, Habrahabr!');
}
exports.define = define;
Запускаем наш сервер:
node server.jsЗаходим туда, где он слушает запросы. Если вы не меняли код, это будет localhost:8000. Ура. Ответ есть.
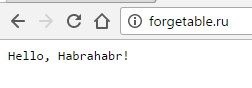
Замечательно. Только это не совсем то, что нам нужно от сервера, правда?
Ловим запросы к нашим API
Да, мы получили ответ, но пока что не слишком близки к конечной цели. Самое время писать логику для нашего роутера.
// /routing/index.js
// Для начала установим зависимости.
const url = require('url');
const fs = require('fs');
const define = function(req, res, postData) {
// Теперь получаем наш адрес. Если мы переходим на localhost:3000/test, то path будет '/test'
const urlParsed = url.parse(req.url, true);
let path = urlParsed.pathname;
// Теперь записываем полный путь к server.js. Мне это особенно нужно, так как сервер будет
// висеть в systemd, и путь, о котором он будет думать, будет /etc/systemd/system/...
prePath = __dirname;
try {
// Здесь мы пытаемся подключить модуль по ссылке. Если мы переходим на
// localhost:8000/api, то скрипт идёт по пути /routing/dynamic/api, и, если находит там
// index.js, берет его. Я знаю, что использовать тут try/catch не слишком правильно, и потом
// переделаю через fs.readFile, но пока у вас не загруженный проект, разницу в скорости
// вы не заметите.
let dynPath = './dynamic/' + path;
let routeDestination = require(dynPath);
res.end('We have API!');
}
catch (err) {
// Не нашлось api? Грустно.
res.end("We don't have API!");
}
};
exports.define = define;
Готово. Теперь мы можем создать
/routing/dynamic/api, и протестировать то, что у нас есть. Я воспользуюсь для этих целей своим готовым скриптом по адресу /dm/shortenUrl.
Определяем, есть ли страница
Мы научились находить скрипты, теперь нужно научиться находить статику. Первым делом пойдём в
/routing/nopage и создадим там index.html. Просто создайте костяк html-страницы, и сделайте один-единственный заголовок h1 с текстом: «404». После этого возвращаемся в /routing/index.js, но теперь мы сосредоточимся на уже написанном блоке catch:// /routing/index.js: блок catch
catch (err) {
// Находим наш путь к статическому файлу и пытаемся его прочитать.
// Если вы не знаете, что это за '=>', тогда прочитайте про стрелочные функции в es6,
// очень крутая штука.
let filePath = prePath+'/static'+path+'/index.html';
fs.readFile(filePath, 'utf-8', (err, html) => {
// Если не находим файл, пытаемся загрузить нашу страницу 404 и отдать её.
// Если находим — отдаём, народ ликует и устраивает пир во имя царя-батюшки.
if(err) {
let nopath = '/var/www/html/nodejs/routing/nopage/index.html';
fs.readFile(nopath, (err , html) => {
if(!err) {
res.writeHead(404, {'Content-Type': 'text/html'});
res.end(html);
}
// На всякий случай напишем что-то в этом духе, мало ли, иногда можно случайно
// удалить что-нибудь и не заметить, но пользователи обязательно заметят.
else{
let text = "Something went wrong. Please contact webmaster@forgetable.ru";
res.writeHead(404, {'Content-Type': 'text/plain'});
res.end(text);
}
});
}
else{
// Нашли файл, отдали, страница загружается.
res.writeHead(200, {'Content-Type': 'text/html'});
res.end(html);
}
});
}
Воодушевляет. Теперь мы можем отдавать страницу 404, а так же html-страницы, которые мы добавляем сами в
/routing/static. В моём случае страница 404 выглядит так: 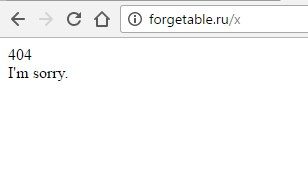
Пара слов об API
Способ организации скриптов — личное дело каждого. На данный момент код в блоке try у меня такой:
let dynPath = './dynamic/' + path;
let routeDestination = require(dynPath);
routeDestination.promise(res,postData,req).then(
result => {
res.writeHead(200);
res.end(result);
return;
},
error => {
let endMessage = {};
endMessage.error = 1;
endMessage.errorName = error;
res.end(JSON.stringify(endMessage));
return;
}
);
По сути, все мои скрипты представляют собой функцию, которая передаёт замыканиями параметры и возвращает промис, и дальнейшая логика на промисах и завязана. В данном контексте такой подход кажется мне очень удобным, так отлов ошибок становится очень лёгким делом. Уже можно, в принципе, переписать эту логику на async / await, но особого смысла для себя я в этом не вижу.
Обрабатываем запросы браузера
Теперь мы уже можем пользоваться нашим сервером, и он будет возвращать страницы. Однако, если вы поместите в
/routing/static/somepage ту же страницу, которая прекрасно работает, например, на апаче, вы столкнётесь с некоторыми проблемами.Во-первых, для этого веб-сервера, как и для, наверное, всех в таком роде, нужно иначе задавать ссылки на css/js/img/… файлы. Если вам хочется подключить к странице 404 css-файл и сделать её красивой, то в случае с апачем мы создали бы в той же папке nopage файл style.css и подключили бы его, указав в тэге link следующее: 'href=«style.css»'. Однако, теперь нам нужно писать путь иначе, а именно: "/routing/nopage/style.css".
Во-вторых, даже если мы подключим всё правильно, то ничего не произойдёт, и у нас всё ещё будет голая страница html. И вот тут мы подходим к самой последней части сегодняшней статьи — дополним скрипт, чтобы он ловил и обрабатывал запросы, которые браузер отправляет сам, читая разметку html. Ну и про favicon не забудем — возьмите фавиконку и положите её в /routing директорию нашего сервера.
Итак, переходим опять в
/routing/index.js. Теперь мы будем писать код прямо перед try/catch:// До этого мы уже получили path и prePath. Теперь осталось понять, какие запросы
// мы получаем. Отсеиваем все запросы по точке, так чтобы туда попали только запросы к
// файлам, например: style.css, test.js, song.mp3
if(/[.]/.test(path)) {
if(path == 'favicon.ico') {
// Если нужна фавиконка - возвращаем её, путь для неё всегда будет 'favicon.ico'
// Получается, если добавить в начале prePath, будет: '/var/www/html/nodejs/routing/favicon.ico'.
// Не забываем про return, чтобы сервер даже не пытался искать файлы дальше.
let readStream = fs.createReadStream(prePath+path);
readStream.pipe(res);
return;
}
else{
// А вот если у нас не иконка, то нам нужно понять, что это за файл, и сделать нужную
// запись в res.head, чтобы браузер понял, что он получил именно то, что и ожидал.
// На данный момент мне нужны css, js и mp3 от сервера, так что я заполнил только
// эти случаи, но, на самом деле, стоит написать отдельный модуль для этого.
if(/[.]mp3$/gi.test(path)) {
res.writeHead(200, {
'Content-Type': 'audio/mpeg'
});
}
else if(/[.]css$/gi.test(path)) {
res.writeHead(200, {
'Content-Type': 'text/css'
});
}
else if(/[.]js$/gi.test(path)) {
res.writeHead(200, {
'Content-Type': 'application/javascript'
});
}
// Опять же-таки, отдаём потом серверу и пишем return, чтобы он не шёл дальше.
let readStream = fs.createReadStream(prePath+path);
readStream.pipe(res);
return;
}
}
Фух. Всё готово. Теперь можно подключить наш css-файл и увидеть нашу страницу 404 со всеми стилями:
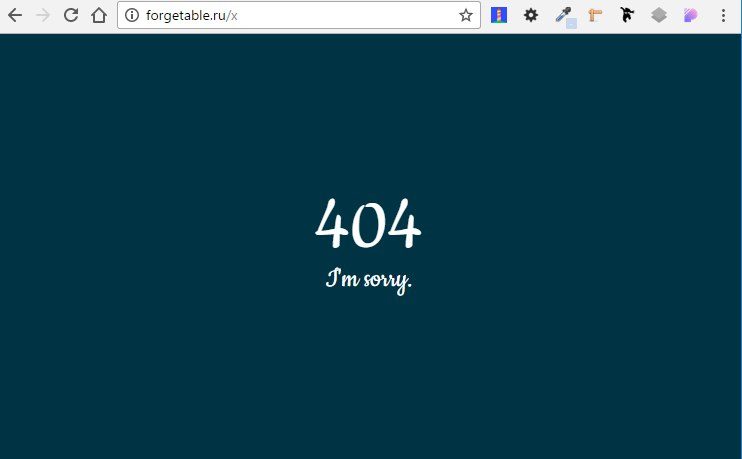
Выводы
Ура! Мы сделали свой веб-сервер, который работает, и работает хорошо. Разумеется, это только начало работы над приложением, но самое главное уже готово — на таком веб-сервере можно поднимать любые страницы, он справляется и со статикой, и с динамическим контентом, и роутинг, на мой взгляд, выглядит удобно — достаточно просто положить соответствующий файл в static или dynamic, и он тут же подхватится, и не надо писать роутинг для каждого конкретного случая.
В общем и целом, работой сервера я очень даже доволен, и сейчас отказался от апача в сторону этого решения, и в целом это был очень интересный опыт. Большое спасибо, что ты, читатель, разделил его со мной, дойдя до этого момента.
UPD: Я не призываю кого-либо использовать этот сервер на постоянной основе. Несмотря на то, что он полностью меня устраивает, в нём нет большого количества нужных для обычного веб-сервера функций и не оптимизирован некоторый готовый функционал, вроде внятного определения mime-типов. Это всё будет в следующих статьях.
Комментарии (96)
mayorovp
26.04.2017 16:36+7Э… и с каких пор понятие "архитектура" стало означать "структура директорий"?

NLO
26.04.2017 16:38НЛО прилетело и опубликовало эту надпись здесь

forgetable
26.04.2017 16:40+1Я же не говорю, что написал инструмент, которым кто-либо должен пользоваться. В первую очередь это была интересная задача, и я думаю, есть люди, которым она тоже интересна. По поводу require я объяснил в комментариях в коде, я знаю, что это не идеальная практика. Спасибо за комментарий!
NLO
26.04.2017 16:56НЛО прилетело и опубликовало эту надпись здесь
forgetable
26.04.2017 17:00+1Я был бы рад, если бы вы по возможности указали мне на ошибки. Спасибо, про статью я на самом деле подумаю, это интересный момент.

bano-notit
26.04.2017 21:52если бы вы по возможности указали мне на ошибки
Сразу бросается в глаза использование regexp в парсе пути...
bano-notit
26.04.2017 21:55Так же радует, как вы определяете mime… Попробуйте нормальные инструменты для этого дела, только сначала нужно проверить, чтобы этот файл вообще существовал.
forgetable
26.04.2017 22:12-2Да, я знаю, что это делается иначе, здесь только самый базовый пример, спасибо. В следующей статье будет много, и это в том числе.
justboris
26.04.2017 16:41+1Ну и конечно же, стоит заметить, что для настоящих сайтов лучше использовать проверенные библиотеки, типа express. Потому что нужно поддерживать разные кодировки, выставлять заголовок content-length и много чего еще.
Для обучающих целей эта статья полезна, но до полноценного сервера нужно сделать много чего еще.
forgetable
26.04.2017 16:44Полностью поддерживаю. Я ни в коем случае не призывал и не призываю использовать что-то подобное. На каких-то своих вещах, которые я буду делать, я буду использовать этот сервер, по работе буду использовать Koa, и это абсолютно нормально.
Shannon
26.04.2017 19:25+1выставлять заголовок content-length и много чего еще.
Не обязательно, так как с HTTP/1.1 поддерживается 'Transfer-Encoding': 'chunked', который node.js выставляет автоматически.
А если будет еще nginx с включенным gzip, то Content-Length заранее и вовсе нет смысла высчитывать, так как nginx всё равно удалит его и поставит 'Transfer-Encoding': 'chunked'.
но до полноценного сервера нужно сделать много чего еще
По сути полноценный сервер это вот:
const http = require('http') http.createServer((req, res) => { let html = 'hello<br>world' res.writeHead(200, { 'Content-Type': 'text/html; charset=utf-8', }) res.end(html) }).listen(8080)
express и остальные это просто удобства, они принципиально ничего особенного не делают. Особенно если взять сторонний роутер и сторонний шаблонизатор. Даже миддлвары можно прикрутить из экспресса.
Поэтому в общем-то у автора уже полноценный сервер с нужными ему удобствами, и даже тот участок, где require в try-catch по сути не проблема, так как уже успешные require nodejs закэширует, и производительность не упадет.
В целом согласен с вашим комментарием, для быстрого/надежного развертывания экспресс или коа лучше подходят, это да.
Просто хорошо, что появляются статьи, которые расширяют понимание ноды дальше экспресса.bano-notit
26.04.2017 21:57+2Помнится написал свою реализацию мидлверов, чтобы не грузить в проект express, ибо там было тупое api. Так что да, по сути модуль http — вот, что нам нужно.
А на проду ставить чистый nodejs без какого-нибудь nginx — просто глупо.
mayorovp
26.04.2017 23:16+2А неуспешные require нода тоже закеширует? Если нет, будет хохма — сервер, который отдает динамический контент быстрее чем статику...

Leopotam
27.04.2017 09:34-1А что делать с HEAD запросом? Там вроде как длина нужна. По крайней мере iOS отказывается качать ipa-бинарники с кривым ответом в длине.
Shannon
27.04.2017 09:57Ничего не делать, всё будет работать. Если не работает, то это проблема реализации приложения, что скачивает бинайрники, а не ios
Leopotam
27.04.2017 10:03-2Это штатный функционал системы: нужен манифест и сам бинарник. Так вот сама система сначала отправляет HEAD запрос и ждет валидный ответ с явным указанием длины, только потом пытается выкачивать через GET. Писал когда-то сервер для подобных вещей, пришлось явно ставить длину в хедере.
forgetable
27.04.2017 10:17-3Да, отличный вопрос. Дело в том, что это всё, несомненно, важные вещи, но цель была немного другая — собрать базовый функционал, который бы вменяемо работал. Другие важные вещи, вроде поддержки кодировок, длины запросов, да даже нормального определения mime-типов, это всё материал для следующих статей.
Shannon
27.04.2017 10:35Писал когда-то сервер для подобных вещей, пришлось явно ставить длину в хедере
Если речь про старую версию ios, где было HTTP/1.0, то только так.
Но в любом случае раздавать бинарники через ноду смысла нет, а если вы раздаете через nginx, то он сам для статики посчитает и выставит нужный размер content-length.Leopotam
27.04.2017 10:40Проблема в том, что это дополнительная обработка / проверка на 1.0 / 1.1, в моем случае вся мета-информация о бинарнике была посчитана заранее — проще было просто отдавать валидный HEAD без body и с длиной + GET без длины. Ну и это был внутренний корпоративный сервис, смысла в nginx не было.
Shannon
27.04.2017 11:19Это не проблема, это просто ваш уникальный опыт со старым HTTP/1.0, который можно не тянуть в текущие реалии.
Если уж HTTP/2.0 почти везде уже давно поддерживается, то HTTP/1.1 тем более
justboris
27.04.2017 12:02Ну, допустим, с content-length разобрались. Но остается еще немало других вопросов.
1) Что будет, если клиент пришлет POST-запрос с многогигабайтным body? Сервер загнется в попытках сохранить его в памяти.
2) Запрос может оборваться на середине. Надо обрабатывать эту ситуацию, чтобы избежать утечки открытых соединений.
Этот список можно продолжать долго. Свой "сервер без фреймворков" стоит писать лишь для того, чтобы наступить на эти грабли самому. Ну и ставить такой сервер наружу в интернет тоже опасно. Ботов-дудосеров, которые ходят по сети и автоматически ищут уязвимости, в интернете хватает.
Shannon
27.04.2017 13:061. Да ничего особенного не будет. Будет какой-нибудь эксепшен вида «RangeError: Invalid string length» и nodejs упадет, после этого владелец донастроит его и проблема решена.
2. node сам после истечения keep-alive прибьет этот запрос.
Полноценный сервер на ноде это те 5 строчек кода.
А перед сервером, на который предполагается что будет кто-то заходить извне, как ни крути лучше поставить nginx, который и body запрос ограничит в размере, и от примитивного ддоса защитит и т.д.
По сути ведь что? Не настроенный экспресс точно так же будет доставлять проблемы, да и пытаться все уровни защиты дублировать на ноде — это оверхед, всё равно nginx лучше с этим справится.
Ставить экспресс или что-то такое, это не то же самое что залить 2 файла на сервер и запустить их.justboris
27.04.2017 14:21Да ничего особенного не будет. Будет какой-нибудь эксепшен вида «RangeError: Invalid string length»
А вот и нет. Приведенный в статье код
req.on('data', (data) => { jsonString += data; }); req.on('end', () => { //... });
Будет записывать все в jsonString, пока не кончится память.
Shannon
27.04.2017 14:30Вот именно этот кусок кода на виртуалке с 2гб памяти, при попытке залить 3гб файл:
/nodejs/server.js:11 jsonString += data; ^ RangeError: Invalid string length
Maiami
27.04.2017 15:21В js строки иммутабельны, и когда что-то плюсуется к строке, то создается новая строка. В итоге память занимает и старая строка, и новая и так далее. Таким образом память кончается намного быстрее, чем кажется, может до 2гб дело даже не дошло. Чтобы этого избежать можно использовать arr.push(newData) и arr.join('')
Но то что ни в одном из этих случаев сам сервер не «загнется», с этим я согласнаmayorovp
27.04.2017 15:33Если бы закончилась память — было бы написано что закончилась память. А тут совсем другая ошибка.

movl
27.04.2017 15:38То, что выделяется новый участок памяти под результат конкатенации, это логично, но почему старый участок не должен освобождаться?
И на сколько я помню конкатенация работает быстрее чем
Array#join.
UPD: пруф
forgetable
27.04.2017 15:41-1Всё верно, а старые строки будут по мере надобности подхватываться сборщиком мусора, так как на них больше нет ссылок.
Maiami
27.04.2017 16:03+2Если бы закончилась память — было бы написано что закончилась память. А тут совсем другая ошибка.
Я и не говорила, что память закончилась, я сказала, что может до 2гб дело и не дошло.
А то, что память таким образом кончается намного быстрее — это особенность строк в js.
Всё верно, а старые строки будут по мере надобности подхватываться сборщиком мусора, так как на них больше нет ссылок.
Нет, не верно. Ссылка на старые строки остается, в этом и проблема
То, что выделяется новый участок памяти под результат конкатенации, это логично, но почему старый участок не должен освобождаться?
Дело в том, что строки не только иммутабельны, но еще и pooled. Поэтому при создании новой строки, старая остается в пуле, и остается там до тех пор пока вручную не нормализовать строку или не удалить весь объект строки
То есть сборщиком мусора сама она не очиститься
И на сколько я помню конкатенация работает быстрее чем Array#join.
UPD: пруф
В этом примере размер массива всего лишь 13 символов. Естественно конкатенация будет быстрее. Речь про огромные массивы строк. Там arr.join будет быстрее, меньше израсходует памяти и вообще будет работать, в отличии от строк, которые могут свалится с такой ошибкой как выше.
При чем я бы вообще рекомендовала вместо arr.push использовать Map.set — будет в 2 раза быстрее чем []movl
27.04.2017 16:09+1Интересная информация, спасибо за ответ. Никогда во внутренности реализаций js не погружался, но видимо стоит.
forgetable
27.04.2017 16:31Я вот прямо сейчас написал ради интереса такую штуку:
const teststring = "" //здесь было 512 utf-8 символов. let string = ""; let multiplier = "2"; setInterval(() => { if(string.length < 1024*1024*2) { string += teststring; console.log('1'); // для отслеживания } }, 10)
Следил встроенным в хром диспетчером задач за потреблением памяти и потреблением памяти javascript. Скрипт сделал всё верно, досчитал до 4096. За это время общая потребляемая память выросла, но даже не на 2 мегабайта. Было видно, как сборщик памяти раз в несколько секунд очищал память на 100-200кб.
mayorovp
27.04.2017 16:36-2Нет, любые строки по умолчанию pooled не являются, в пул попадают только строковые литералы. Результат конкатенации строковым литералом не является.
И на старую строку ссылку никто не удерживает, с этой стороны проблемы нет.
Вот производительность конкатенации в большом цикле и правда хромает, это общая особенность java, c#, javascript и еще кучи других языков.
Maiami
27.04.2017 17:24+2Я вот прямо сейчас написал ради интереса такую штуку:
Скрипт сделал всё верноИ на старую строку ссылку никто не удерживает, с этой стороны проблемы нет.
Строки в js при конкатенации делают 2 вещи:
1. Создается новая строка
2. Новая строка складывается в пул
Если в коде встречается, что новая строка, которую прибавляют к старой уже есть в пуле, то новая строка не создается, просто используется та что уже в пуле. Поэтому если складывать одни и те же строки, то размер, можно сказать, увеличиваться не будет
Но если новая строка всегда новая и в пуле ее нет, начинается ад
Вот правильный пример:
'use strict'; function getRandomStr() { let testString = '' for (let i = 0; i < 512; i++) { testString += '' + Math.random() * 100 | 0 } return testString } let string = "" setInterval(() => { if (string.length < 1024 * 1024 * 2) { string += getRandomStr() console.log(string.length, process.memoryUsage()) } }, 10)
В начале:
974 { rss: 20697088, heapTotal: 5685248, heapUsed: 3913832, external: 9284 }
Спустя 25 секунд:
2097369 { rss: 104075264, heapTotal: 87474176, heapUsed: 65276264, external: 9284 }
Память и не думает очищаться. Но помимо памяти есть еще и накладные расходы на всё это, которые в случае с 2гб файлом переходят разумный предел и выбрасывается исключение до расхода всей доступной памятиforgetable
27.04.2017 17:27-3Сделал вот сейчас же функцию, которая огромное количество раз конкатенирует Math.random() в переменную, чтобы исключить любую возможность кэширования, а потом конкатенирует эту переменную к исходной, одновременно с этим показывал размер в килобайтах строки. На строке в ~134 мбайта нода ела 138 мбайт.
Maiami
27.04.2017 17:28+3Вот выше код, его изучите
forgetable
27.04.2017 17:55Спасибо, понял. Не знаю, почему в моём случае не было такого, нужно будет изучить этот вопрос. Спасибо, о конкатенации строк и памяти вообще нигде ничего нет.
Maiami
27.04.2017 18:05+1Вот еще пример, тут символы, а не цифры, это ближе к тому, что передается в качестве боди:
'use strict'; const iter = 100000 function getRandomStr() { let testString = [] for (let i = 0; i < 512; i++) { testString.push(String.fromCharCode(Math.random() * 255 | 0)) } return testString.join('') } let string = [] for (let i = 0; i < iter; i++) { string.push(getRandomStr()) } console.log((process.memoryUsage().rss / 1024 / 1024 | 0) + 'MB')
Результат:
>node sdfs.js 104MB
И результат довольно быстрый. А вариант с конкатенацией строк
'use strict'; const iter = 100000 function getRandomStr() { let testString = '' for (let i = 0; i < 512; i++) { testString += String.fromCharCode(Math.random() * 255 | 0) } return testString } let string = '' for (let i = 0; i < iter; i++) { string += getRandomStr() } console.log((process.memoryUsage().rss / 1024 / 1024 | 0) + 'MB')
Работает вечность и всё равно в конце выдает:
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory
Спасибо, о конкатенации строк и памяти вообще нигде ничего нет.
Еще как есть. Вот например от одного из разработчиков ноды:
https://habrahabr.ru/post/283090/#comment_9641904forgetable
27.04.2017 18:10В мире много чего есть, только вот найти сложно. Спасибо, это действительно бесценные комментарии.
mayorovp
27.04.2017 18:37Обратите внимание: суммарный объем сгенерированных вами же промежуточных строк — гигабайт для внешнего цикла и еще сто метров во внутреннем. Ой, то есть два гигабайта и еще 200 метров, там же 16ти битная кодировка если я правильно помню.
Тот факт, что итоговое потребление памяти — всего 65 мегабайт, как раз и говорит о том, что строки ни в каком пуле не удерживаются.
Maiami
27.04.2017 18:45+1Второй пример — https://habrahabr.ru/post/327440/#comment_10194348
Результат для arr.push:
>node sdfs.js 104MB
Работает очень быстро
Результат для конкатенации строк работает вечность и всё равно в конце выдает:
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memorymayorovp
27.04.2017 19:00Какое это имеет отношение к пулу строк?
Maiami
27.04.2017 19:49Какое это имеет отношение к пулу строк?
Тот факт, что итоговое потребление памяти — всего 65 мегабайт, как раз и говорит о том, что строки ни в каком пуле не удерживаются.
Вернемся к тому первому примеру:
Длина получившейся строки — 2097369. Каждый символ допустим занимает 16 бит или 2 байта, то есть размер такой строки должен быть 4мб.
А реальный размер занимаемой памяти — 79мб, которая не очищается а только продолжает расти
Это всего лишь 4мб текста, в примере выше передается что-то около 3гб данных. Тут не память раньше кончится, а проблема с накладными расходами на поддержание таких строк начнется, что и произошло
Не знаю как вы умудрились прийти к выводу, что раз памяти в 10 раз (а чем дальше, тем больше) больше расходуется чем надо, то значит всё в порядке со строками
Вот еще пример:
'use strict'; function getRandomStr() { let testString = '' for (let i = 0; i < 512; i++) { testString += '' + Math.random() * 100 | 0 } return testString } const iter = 1000 let string = '' let i = 0 const intr = setInterval(() => { i++ string += getRandomStr() if (i > iter) { stopIntr() } }, 10) function stopIntr() { clearInterval(intr) console.log('Занимает памяти: ' + (process.memoryUsage().rss / 1024 | 0) + 'KB') console.log('Хотя должно занимать всего лишь: ' + (Buffer.from(string).length / 1024 | 0) + 'KB') }
>node sdfs.js Занимает памяти: 77268KB Хотя должно занимать всего лишь: 951KB
Тоесть в 77 раз больше памяти расходует, чем требуется всего лишь на 1000 итераций. В примере с arr.push было 100.000 итераций, а памяти расходовалось всего «104MB»
Их можно бесконечно приводить, суть не изменится, строки иммутабельны и пулед, из-за этого идет большой оверхед по памяти и накладным расходам, которые не заметны если строки маленькие или оптимизатор смог их как-то оптимизировать, но становится очень заметны когда размеры переваливают за разумный предел.
И чтобы этого избежать можно использовать arr.push(newData) и arr.join('')
Это и был мой изначальный совет (слово в слово)
Если вы до сих пор хотите гнуть линию, что никаких удержаний нет, в пул не попадают — то я пожалуй пас.forgetable
27.04.2017 19:54Да, это действительно так работает, хоть мне и не совсем понятна эта логика. Мне кажется, логичнее было бы очищать наименее используемые строки из пула при достижении определённого размера оперативной памяти. В общем, эта вещь отлично помогает при частой конкатенации одних и тех же строк, что используется в разработке на js часто, но собирать большие объемы данных по кусочкам с помощью неё не стоит.
mayorovp
27.04.2017 19:58-3Для того, чтобы опровергнуть гипотезу, достаточно одного контрпримера. Так что даже не буду смотреть очередной, а вернусь к исходному.
В процессе работы исходного примера совершается около 2 * 1024 итераций, каждая из которых добавляет в среднем 1024 символа к строке.
Суммарная длина промежуточных строк — это 1024 (2048 2047) / 2, то есть 2 миллиарда символов или 4 гигабайта.
Потребление памяти — 79 Мб, то есть в 50 раз меньше.
Следовательно, 98% использованной промежуточной памяти было успешно освобождено сборщиком мусора, что противоречит гипотезе о навечном застревании строк в строковом пуле.
Растет же потребляемая память в данном случае, скорее всего, не из-за утечек, а потому что нода таким образом пытается уменьшить число вызовов сборщика мусора.
forgetable
27.04.2017 20:01+2Я повторял этот опыт, и при размере сгенерированного файла в 150мб нода ела под 800 мб памяти и сборка мусора не произошла ни разу. При этом процесс выполнения стал крайне медленным, по одной инерации в секунду примерно, так что особого смысла продолжать не было. Даже если часть памяти бы всё-таки освобождалась сразу, всё равно это не отменяет несостоятельность использования такого метода для получения данных по кускам и склейки их. Тем более, сейчас в ноде Array.join работает не медленнее конкатенации.
mayorovp
27.04.2017 20:06Заметьте: нода ела всего лишь 800 мб! Если бы все строки хранились в пуле — зависимость потребляемой памяти от размера файла была бы квадратичной, а тут разница всего в 5-6 раз.
Время же выполнения тут ни при чем, факт что конкатенация строк в цикле работает медленно — общеизвестен и не имеет никакого отношения к пулу строк.
forgetable
27.04.2017 20:09+2Мне кажется, эти 5-6 раз достаточно критичны для серверных приложений, всё-таки. И тема всё равно интересная, как ни крути.
mayorovp
27.04.2017 20:10Так я же не спорю что они критичны! Я спорю с утверждением что любые строки интернируются в пул строк и становятся недоступны сборщику мусора, потому что это бред.
Maiami
27.04.2017 20:12+1Растет же потребляемая память в данном случае, скорее всего, не из-за утечек,
Абы, да кабы. У вас догадки, а я опираюсь на слова одного из разработчиков ноды и собственные эксперименты.
К тому же это не утечки, а стандартная работа со строками
Я спорю с утверждением что любые строки интернируются в пул строк и становятся недоступны сборщику мусора, потому что это бред.
Не было такого утверждения
что противоречит гипотезе о навечном застревании строк в строковом пуле.
Для того, чтобы опровергнуть гипотезу, достаточно одного контрпримера. Так что даже не буду смотреть очередной, а вернусь к исходному.
Ну если бы мы были в мире, где оптимизатор был совсем туп, то да. Что-то он умеет оптимизировать, и это заметно
И кто сказал про навечное застревание в пуле? Те строки, что сгенерированы в getRandomStr освобождаются, так как они не используются больше нигде, только их финальная копия сохранена в пуле
Когда строки свободны, а когда нет — это чуть поработав с собственным шаблонизатором вы быстро научитесь чувствовать, но это оверхед
Вот чтобы не гадать, и предлагают использовать arr.push (а лучше Map/Set), так как он даже с одинаковым расходом памяти работает быстрее на больших строкахmayorovp
27.04.2017 20:14И кто сказал про навечное застревание в пуле?
Вы:
Дело в том, что строки не только иммутабельны, но еще и pooled. Поэтому при создании новой строки, старая остается в пуле, и остается там до тех пор пока вручную не нормализовать строку или не удалить весь объект строки
Поскольку в приведенном вами коде нет никаких операций нормализации строки или явного удаления объекта — строки в пуле должны оставаться все время работы программы. Чего не наблюдается.
Ну если бы мы были в мире, где оптимизатор был совсем туп, то да. Что-то он умеет оптимизировать, и это заметно
Причем тут оптимизатор? Строки успешно собирает самый обычный сборщик мусора, как и любые другие объекты.
Maiami
27.04.2017 20:20Вы:
И где же?
Поскольку в приведенном вами коде нет никаких операций нормализации строки или явного удаления объекта — строки в пуле должны оставаться все время работы программы. Чего не наблюдается.
Вот я так и думала, что мы будем не по существу, а придираться к словам.
Ну хорошо, вот вам 3 условие, когда строки освобождаются: Они больше нигде не используются, их пул больше не нужен, они стали частью другого пула. Оптимизатор сам умеет понимать когда это произошло, и делает это успешно
Причем тут оптимизатор? Строки успешно собирает самый обычный сборщик мусора, как и любые другие объекты.
Оптимизатор тут при том, что он понимает, когда можно срезать углы, и превращает функцию getRandomStr(), которая прогоняется не один раз, в нечто более быстро и оптимальноеmayorovp
27.04.2017 20:22Ситуацию "они больше нигде не используются" отслеживает не оптимизатор, а сборщик мусора.
Maiami
27.04.2017 20:31+1Ситуацию «они больше нигде не используются» отслеживает не оптимизатор, а сборщик мусора.
Оптимизатор умеет больше и смотрит дальше чем сборщик мусора, уже не говоря про то, что может оптимизировать код, чтобы сборщику мусора и вовсе нечего было делать

mayorovp
26.04.2017 16:45+7Еще ошибки, видимые сходу:
- Страница 404 отдается с кодом 200. Это так и задумано?
- Вместо хардкода в prePath стоило бы использовать __dirname или require.resolve
forgetable
26.04.2017 16:48-1Да, действительно, с кодом 404 вышла ошибка, сейчас исправлю.
__dirname я почему-то пропустил мимо своего взгляда, большое спасибо за совет.
movl
26.04.2017 18:51+2Я бы еще несколько сомнительных моментов добавил.
Если
__dirnameпо некоторым причинам не подходит, то различные базовые константы по хорошему надо хотя бы выносить в конфигурационный файл, или в опции к запуску, или еще куда. Так же увидел что пути через конкатенацию формируются, для этого естьpath.join, а иначе можно напороться на проблемы при запуске сервера под Windows, например.
Дублирующийся код при формирование
Content-Typeи не правильные регулярки, не говоря уже про сам подход определения типа файлов.
/.mp3/.test('test.mp3') // true /.mp3/.test('test.mp3.gz') // true /.mp3/.test('testmp3') // true /.mp3/.test('testmp3test') // true /.mp3/.test('test.MP3') // false
Промисы в одном месте, обратные вызовы в другом в другом выглядят не хорошо. Достаточно просто работа с потоками или методы
fsоборачиваются в промисы, но для подобного примера может это и лишний код.forgetable
26.04.2017 19:02Про __dirname я уже понял, и обязательно добавлю. По поводу базовых констант — это замечательная вещь, и, если буду делать продолжение, обязательно сделаю акцент на конфигурации.
Про регулярные выражения — да, надо исправить, и чтобы она смотрела в конце страницы. Благодарю.
По поводу промисов и коллбеков — на мой взгляд, нет никаких проблем, если коллбек находится там же, где и то, что его вызывает, но в более сложных штуках с большим количеством действий можно было бы и переделать.
Большое спасибо за развёрнутый комментарий
justboris
26.04.2017 19:27А вообще есть библиотека mime.
Я понимаю, что здесь челлендж написать все без библиотек, но тогда хотя бы можно посмотреть как оно там сделано.
forgetable
26.04.2017 19:28-1Спасибо, кстати, интересная штука. Потом было бы интересно сравнить и какие-то вещи скорректировать.

DexterHD
26.04.2017 16:50А еще вот задачка, заставить свой сервер работать в многопроцессорной среде.
forgetable
26.04.2017 16:52-1К сожалению, у меня на VDS одно ядро. Слышал про кластеры, но увы, этим получится заняться только позже.
movl
26.04.2017 18:09+1Для стандартного http сервера, это не задача даже, скорее способ запуска:
$ pm2 start -i 2 server.js

yogurt1
26.04.2017 17:09Интересно очень.
Погуглите PillarJS и понятие BYO-фреймворк
dcversus
27.04.2017 19:44Ищу что такое BYO-фреймворк получаю или ссылку на pillarjs или на этот комментарий. Вы можете дать ссылку на ресурс, который бы объяснял что это такое, пожалуйста.
yogurt1
29.04.2017 22:41BYO — Build you own, собери себе сам
https://pillarjs.github.io/
Берешь нужные компоненты и строишь.
Express, например, использует path-to-regexp и router из PillarJS (ветка 5.0 Express)
yazyk_na_nojkah
26.04.2017 18:53-12> Свой веб-сервер
> ни единого фреймворка
>const http = require('http');
>let server = new http.Server(
Что, правда?
Ваша статья — дерьмо. Hello world работающий по протоколу HTTP.forgetable
26.04.2017 18:55Да, возможно, не совсем корректно было говорить именно эту фразу, но, мне кажется, встроенные в язык библиотеки ну никак не подразумевались.
По поводу статьи — я не ставил себе целью написать апач. Это небольшая работа, и действительно своего рода «hello-world», который я бы с радостью прочёл, только взявшись за nodejs.

jehy
26.04.2017 18:54+1Класс. Старые добрые локальные инклюды — теперь и в node.js.
А идея отдавать статику нодой и отказаться от апача просто прекрасна.

SergeyVoyteshonok
26.04.2017 21:00Почему у вас в коде почти везде с единичным присваиванием let вместо const?
forgetable
26.04.2017 21:03-1Я пока что не слишком свыкся с let/const, к сожалению, а некоторые вещи пишу на автомате и даже не вижу. Спасибо, я разберусь с этим.
SergeyVoyteshonok
26.04.2017 23:05+3Если на автомате, тогда надо наоборот — везде писать const, а там где IDE будет ругаться на повторное присваивание менять на let.
bano-notit
26.04.2017 22:03+1Из комментариев, данных автором, и кода, который он написал в статье, могу резюмировать следующее: человек только только нашёл что такое nodejs, по некоторым соображениям даже только только притронулся к js, поэтому не стоит рассматривать статью как какой-то призыв к действию. Вообще не стоит рассматривать статью как какой-то ценный кусок ума. Просто hello world на публику.
forgetable
26.04.2017 22:47-1Да, частично это правда. Я не призывал людей к тому, чтобы все сделали себе что-то подобное, вовсе нет. Но, когда я только начинал разбираться в nodejs, я бы многое дал за подобную статью. В этом и суть.

xRay
27.04.2017 01:02-3На Go подобный этому «hello world» выглядит лаконичнее

Botchal
27.04.2017 04:39Конечно лаканичнее, но мы же тут про ноду статью читаем. Как поднять вэб-сервер на стандартной библиотеке, уникальная в своём роде статья. А Вы тут со своим Go. Автор чётко выразился, что в своё время он много чего бы отдал за такую статью. Речь идет о годах 4 назад, за это время ничего подобного так и не появилось.
Maiami
27.04.2017 01:43+2server.js
'use strict'; const http = require('http') const routing = require('./routing') http.Server(function (req, res) { let jsonString = '' res.setHeader('Content-Type', 'application/json; charset=utf-8') req.on('data', (data) => { jsonString += data }) req.on('end', () => { routing(req, res, jsonString) }) }).listen(8000)
routing/index.js
'use strict'; const url = require('url') const fs = require('fs') const path = require('path') function show404(req, res) { const nopath = path.join(__dirname, 'nopage', 'index.html') fs.readFile(nopath, (err, html) => { if (!err) { res.writeHead(404, { 'Content-Type': 'text/html; charset=utf-8' }) res.end('' + html) } else { const text = "Something went wrong. Please contact webmaster"; res.writeHead(404, { 'Content-Type': 'text/plain; charset=utf-8' }) res.end(text) } }) } function loadStaticFile(pathname, req, res) { const staticPath = path.join(__dirname, pathname) if (pathname === '/favicon.ico') { } else if (/[.]mp3$/gi.test(pathname)) { res.writeHead(200, { 'Content-Type': 'audio/mpeg' }) } else if (/[.]css$/gi.test(pathname)) { res.writeHead(200, { 'Content-Type': 'text/css' }) } else if (/[.]js$/gi.test(pathname)) { res.writeHead(200, { 'Content-Type': 'application/javascript; charset=utf-8' }) } fs.createReadStream(staticPath).pipe(res) } function router(req, res, postData) { const urlParsed = url.parse(req.url, true) const pathname = urlParsed.pathname if (/[.]/.test(pathname)) { loadStaticFile(pathname, req, res) return } let filepath = path.join(__dirname, 'dynamic', pathname, 'index.js') fs.access(filepath, err => { if (!err) { const routeDestination = require(filepath) routeDestination.promise(res, req, postData) .then(result => { res.writeHead(200) res.end('' + result) }) .catch(err => { res.writeHead(404, { 'Content-Type': 'text/html; charset=utf-8' }) res.end(`${err.name}: ${err.message}`) }) } else { filepath = path.join(__dirname, 'static', pathname, 'index.html') fs.readFile(filepath, 'utf-8', (err, html) => { if (err) { show404(req, res) } else { res.writeHead(200, { 'Content-Type': 'text/html; charset=utf-8' }) res.end('' + html) } }) } }) } module.exports = router
Думаю, от require избавится не получится, всё таки у запрашиваемых модулей могут быть зависимости. Только если все модули переписать соответствующим образом.
А вместо postData можно сделать:
req.on('end', () => { req.body = jsonString routing(req, res) })
Чтобы не пробрасывать постоянно лишнюю переменную

ReklatsMasters
27.04.2017 07:55-2и сейчас отказался от апача в сторону этого решения
Вы серьёзно? Свой костыль вместо нормального сервера? Максимум куда это сгодится — на какие нибудь лабораторные в универе.
forgetable
27.04.2017 08:41-1У меня свой небольшой сервер, на котором я пишу всякое, и мне более чем удобно использовать свой костыль. Если буду писать что-либо по работе, разумеется, буду использовать «нормальный сервер».
ReklatsMasters
27.04.2017 09:27+1Я не очень понимаю, почему вы написали нормальный сервер в кавычках. Нормальным сервером в данном случае может быть любой сервер данных хоть на express, хоть на другом фреймворке. Ваша же статья подталкивает начинающих программистов писать использовать свои малоподдерживаемые костыли.
Shannon
27.04.2017 09:42Там чем у автора не нормальный сервер?
https://habrahabr.ru/post/327440/#comment_10192758
forgetable
27.04.2017 10:13-1Я много раз говорил и повторю ещё раз, что эта статья не призывала и не призывает кого-либо использовать подобное решение на постоянной основе. Это сервер, который я начал писать исключительно для себя, и пока что в нём нет многих важных функций, например. Пока что этот сервер – скорее игрушка для тех, кто хочет сделать что-либо подобное на досуге. Тем не менее, спасибо за комментарии!

stranger777
27.04.2017 09:17Статья-выдох))) из разряда простенько и со вкусом.
А вот тут вы немного не правы:
Пара слов об API
Способ организации скриптов — личное дело каждого.
Представьте, что ваш проект разросся, у него появилась команда и огромная кодовая база, но — «способ организации скриптов — личное дело каждого»… В итоге ориентироваться в таком коде с личными делами — совершенно невозможно, невозможно и написать гайд по коду для вольных программистов гитхаба.
То есть на самом деле способ организации (скриптов или чего-то другого) — одна из первых вещей, о которых надо думать.
Хорошего дня!forgetable
27.04.2017 10:10-1Ну да, я просто имел в виду, скорее, каждую команду. А так — обязательно должна быть чёткая структура в рамках каждого проекта. Спасибо!

paratagas
27.04.2017 14:02В Express, кстати, есть структура проекта по-умолчанию. Создается командой (предварительно нужно установить Express глобально)
express -someFlag -anotherFlag projectFolder
Автору можно было бы создать аналогичную структуру. Тогда она была бы унифицирована со стандартным решением, привычнее бы воспринималась и в случае необходимости упростила бы переход на фреймворк. Заодно можно было бы использовать package.json и запускать сервер стандартнымnpm start
m0sk1t
Неплохо, а будет продолжение?
forgetable
Спасибо! Да, я очень хотел бы сделать продолжение, есть несколько достаточно занятных идей, сейчас как раз занимаюсь их реализацией.
domix32
Еще бы ссылку на гитхаб с дефолтным проектом.
forgetable
Ссылка будет в следующей статье