

В последнее время я все чаще и чаще слышу про GraphQL. И в интернете уже можно найти немало статей о том как сделать свой GraphQL сервер. Но почти во всех этих статьях в качестве бэкенда используется Node.js.
Я ничего не имею против Node.js и сам с удовольствием использую его, но все-таки большую часть проектов я делаю на PHP. К тому же хостинг с PHP и MySQL гораздо дешевле и доступнее чем хостинг с Node.js. Поэтому мне кажется не справедливым тот факт, что об использовании GraphQL на PHP в интернете практически нет ни слова.
В данной статье я хочу рассказать о том, как сделать свой GraphQL сервер на PHP с помощью библиотеки graphql-php и как с его помощью реализовать простое API для получения данных из MySQL.
Я решил отказаться от использования какого-либо конкретного PHP фреймворка в данной статье, но после ее прочтения вам не составит особого труда применить эти знания в своем приложении. Тем более для некоторых фреймворков уже есть свои библиотеки основанные на graphql-php, которые облегчат вашу работу.
Подготовка
В данной статье я не буду делать фронтенд, поэтому для удобного тестирования запросов к GraphQL серверу рекомендую установить GraphiQL-расширение для браузера.
Для Chrome это могут быть:
Также понадобится создать таблицы в БД и заполнить их тестовым набором данных.
В таблице «users» будем хранить список пользователей:
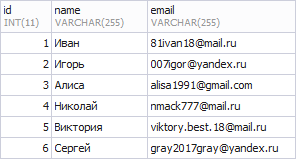
А в таблице «friendships» связи типа «многие-ко-многим», которые будут обозначать дружбу между пользователями:
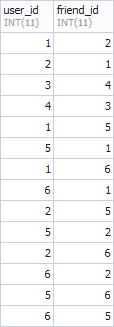
Дамп базы данных, как и весь остальной код, можно взять из репозитория данной статьи на Github.
Hello, GraphQL!
Для начала необходимо установить graphql-php в наш проект. Можно сделать это с помощью composer:
composer require webonyx/graphql-phpТеперь, по традиции напишем «Hello, World».
Для этого в корне создадим файл graphql.php, который будет служить конечной точкой (endpoint) нашего GraphQL сервера.
В нем подключим автозагрузчик composer:
require_once __DIR__ . '/vendor/autoload.php';Подключим GraphQL:
use GraphQL\GraphQL;Чтобы заставить GraphQL выполнить запрос необходимо передать ему сам запрос и схему данных.
Для получения запроса напишем следующий код:
$rawInput = file_get_contents('php://input');
$input = json_decode($rawInput, true);
$query = $input['query'];Чтобы создать схему сначала подключим GraphQL\Schema:
use GraphQL\Schema;Конструктор схемы принимает массив, в котором должен быть указан корневой тип данных Query, который служит для чтения данных вашего API, поэтому сначала создадим этот тип.
В простейшем случае тип данных Query должен быть экземпляром класса ObjectType, а его поля должны быть простых типов (например int или string), поэтому подключим классы предоставляющие эти типы данных в GraphQL:
use GraphQL\Type\Definition\Type;
use GraphQL\Type\Definition\ObjectType;И создадим тип данных Query:
$queryType = new ObjectType([
'name' => 'Query',
'fields' => [
'hello' => [
'type' => Type::string(),
'description' => 'Возвращает приветствие',
'resolve' => function () {
return 'Привет, GraphQL!';
}
]
]
]);Как можно заметить тип данных обязательно должен содержать имя (name) и массив полей (fields), а также можно указать необязательное описание (description).
Поля типа данных также должны иметь обязательные свойства «name» и «type». Если свойство «name» не задано, то в качестве имени используется ключ поля (в данном случае «hello»). Также в нашем примере у поля «hello» заданы необязательные свойства «description» — описание и «resolve» — функция возвращающая результат. В этом случае функция «resolve» просто возвращает строку "Привет, GraphQL!", но в более сложной ситуации она может получать какую-либо информацию по API или из БД и обрабатывать ее.
Таким образом, мы создали корневой тип данных «Query», который содержит всего одно поле «hello», возвращающее простую строку текста. Давайте добавим его в схему данных:
$schema = new Schema([
'query' => $queryType
]);А затем выполним запрос GraphQL для получения результата:
$result = GraphQL::execute($schema, $query);Остается только вывести результат в виде JSON и наше приложение готово:
header('Content-Type: application/json; charset=UTF-8');
echo json_encode($result);Обернем код в блок try-catch, для обработки ошибок и в итоге код файла graphql.php будет выглядеть так:
<?php
require_once __DIR__ . '/vendor/autoload.php';
use GraphQL\GraphQL;
use GraphQL\Schema;
use GraphQL\Type\Definition\Type;
use GraphQL\Type\Definition\ObjectType;
try {
// Получение запроса
$rawInput = file_get_contents('php://input');
$input = json_decode($rawInput, true);
$query = $input['query'];
// Содание типа данных "Запрос"
$queryType = new ObjectType([
'name' => 'Query',
'fields' => [
'hello' => [
'type' => Type::string(),
'description' => 'Возвращает приветствие',
'resolve' => function () {
return 'Привет, GraphQL!';
}
]
]
]);
// Создание схемы
$schema = new Schema([
'query' => $queryType
]);
// Выполнение запроса
$result = GraphQL::execute($schema, $query);
} catch (\Exception $e) {
$result = [
'error' => [
'message' => $e->getMessage()
]
];
}
// Вывод результата
header('Content-Type: application/json; charset=UTF-8');
echo json_encode($result);Проверим работу GraphQL. Для этого запустим расширение для GraphiQL, установим endpoint (в моем случае это «localhost/graphql.php») и выполним запрос:
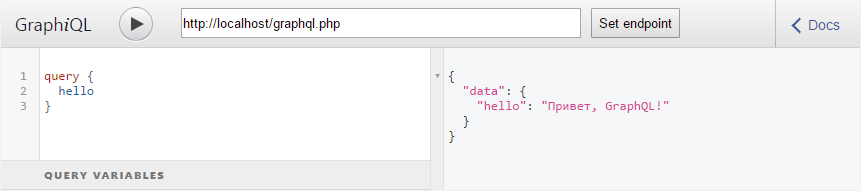
Вывод пользователей из БД
Теперь усложним задачу. Выведем список пользователей из базы данных MySQL.
Для этого нам понадобится создать еще один тип данных класса ObjectType. Чтобы не нагромождать код в graphql.php, вынесем все типы данных в отдельные файлы. А чтобы у нас была возможность использовать типы данных внутри самих себя, оформим их в виде классов. Например, чтобы в типе данных «user» можно было добавить поле «friends», которое будет являться массивом пользователей такого же типа «user».
Когда мы оформляем тип данных в виде класса, то не обязательно указывать у него свойство «name», потому что оно по умолчанию берется из названия класса (например у класса QueryType будет имя Query).
Теперь корневой тип данных Query, который был в graphql.php:
$queryType = new ObjectType([
'name' => 'Query',
'fields' => [
'hello' => [
'type' => Type::string(),
'description' => 'Возвращает приветствие',
'resolve' => function () {
return 'Привет, GraphQL!';
}
]
]
]);Будет находиться в отдельном файле QueryType.php и выглядеть так:
class QueryType extends ObjectType
{
public function __construct()
{
$config = [
'fields' => [
'hello' => [
'type' => Type::string(),
'description' => 'Возвращает приветствие',
'resolve' => function () {
return 'Привет, GraphQL!';
}
]
]
];
parent::__construct($config);
}
}А чтобы в дальнейшем избежать бесконечной рекурсии при определении типов, в свойстве «fields» лучше всегда указывать не массив полей, а анонимную функцию, возвращающую массив полей:
class QueryType extends ObjectType
{
public function __construct()
{
$config = [
'fields' => function() {
return [
'hello' => [
'type' => Type::string(),
'description' => 'Возвращает приветствие',
'resolve' => function () {
return 'Привет, GraphQL!';
}
]
];
}
];
parent::__construct($config);
}
}При разработке проекта может появиться очень много типов данных, поэтому для них лучше создать отдельный реестр, который будет служить фабрикой для всех типов данных, в том числе и базовых, используемых в проекте. Давайте создадим папку App, а в ней файл, Types.php, который как раз и будет тем самым реестром для всех типов данных проекта.
Также в папке App создадим подпапку Type, в которой будем хранить все наши типы данных и перенесем в нее QueryType.php.
Теперь добавим пространство имен и заполним реестр Types.php необходимыми типами:
<?php
namespace App;
use App\Type\QueryType;
use GraphQL\Type\Definition\Type;
class Types
{
private static $query;
public static function query()
{
return self::$query ?: (self::$query = new QueryType());
}
public static function string()
{
return Type::string();
}
}Пока в нашем реестре будет всего 2 типа данных: 1 простой (string) и 1 составной (query).
Теперь во всех остальных файлах вместо:
use GraphQL\Type\Definition\Type;Подключим наш реестр типов:
use App\Types;И заменим все ранее указанные типы, на типы из реестра.
В QueryType.php вместо:
Type::string()Будет:
Types::string()А схема в graphql.php теперь будет выглядеть так:
$schema = new Schema([
'query' => Types::query()
]);Чтобы получить пользователей из базы данных, необходимо обеспечить интерфейс доступа к ней. Получать данные из базы можно любым способом. В каждом фреймворке для этого есть свои инструменты. Для данной статьи я написал простейший интерфейс который может подключаться к MySQL базе данных и выполнять в ней запросы. Так как это не относится к GraphQL, то я не буду объяснять как реализованы методы в данном классе, а просто приведу его код:
<?php
namespace App;
class DB
{
private static $pdo;
public static function init($config)
{
self::$pdo = new PDO("mysql:host={$config['host']};dbname={$config['database']}", $config['username'], $config['password']);
self::$pdo->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_OBJ);
}
public static function selectOne($query)
{
$records = self::select($query);
return array_shift($records);
}
public static function select($query)
{
$statement = self::$pdo->query($query);
return $statement->fetchAll();
}
public static function affectingStatement($query)
{
$statement = self::$pdo->query($query);
return $statement->rowCount();
}
}В файле graphql.php добавим код для инициализации подключения к БД:
// Настройки подключения к БД
$config = [
'host' => 'localhost',
'database' => 'gql',
'username' => 'root',
'password' => 'root'
];
// Инициализация соединения с БД
DB::init($config);Теперь в папке Type создадим тип данных User, который будет отображать данные о пользователе. Код файла UserType.php будет таким:
<?php
namespace App\Type;
use App\DB;
use App\Types;
use GraphQL\Type\Definition\ObjectType;
class UserType extends ObjectType
{
public function __construct()
{
$config = [
'description' => 'Пользователь',
'fields' => function() {
return [
'id' => [
'type' => Types::string(),
'description' => 'Идентификатор пользователя'
],
'name' => [
'type' => Types::string(),
'description' => 'Имя пользователя'
],
'email' => [
'type' => Types::string(),
'description' => 'E-mail пользователя'
],
'friends' => [
'type' => Types::listOf(Types::user()),
'description' => 'Друзья пользователя',
'resolve' => function ($root) {
return DB::select("SELECT u.* from friendships f JOIN users u ON u.id = f.friend_id WHERE f.user_id = {$root->id}");
}
],
'countFriends' => [
'type' => Types::int(),
'description' => 'Количество друзей пользователя',
'resolve' => function ($root) {
return DB::affectingStatement("SELECT u.* from friendships f JOIN users u ON u.id = f.friend_id WHERE f.user_id = {$root->id}");
}
]
];
}
];
parent::__construct($config);
}
}Значение полей можно понять из их свойства «description». Свойства «id», «name», «email» и «countFriends» имеют простые типы, а свойство «friends» является списком друзей – таких же пользователей, поэтому имеет тип:
Types::listOf(Types::user())Необходимо также добавить в наш реестр пару базовых типов, которые мы раньше не использовали:
public static function int()
{
return Type::int();
}
public static function listOf($type)
{
return Type::listOf($type);
}И только, что созданный нами тип User:
private static $user;
public static function user()
{
return self::$user ?: (self::$user = new UserType());
}Возвращаемые значения (resolve) для свойств «friends» и «countFriends» берутся из базы данных. Анонимная функция в «resolve» первым аргументом получает значение текущего поля ($root), из которого можно узнать id пользователя для вставки его в запрос списка друзей.
В завершении изменим код QueryType.php так, чтобы в API были поля для получения информации о конкретном пользователе по его идентификатору (поле «user»), а также для получения списка всех пользователей (поле «allUsers»):
<?php
namespace App\Type;
use App\DB;
use App\Types;
use GraphQL\Type\Definition\ObjectType;
class QueryType extends ObjectType
{
public function __construct()
{
$config = [
'fields' => function() {
return [
'user' => [
'type' => Types::user(),
'description' => 'Возвращает пользователя по id',
'args' => [
'id' => Types::int()
],
'resolve' => function ($root, $args) {
return DB::selectOne("SELECT * from users WHERE id = {$args['id']}");
}
],
'allUsers' => [
'type' => Types::listOf(Types::user()),
'description' => 'Список пользователей',
'resolve' => function () {
return DB::select('SELECT * from users');
}
]
];
}
];
parent::__construct($config);
}
}Тут чтобы узнать идентификатор пользователя, данные которого необходимо получить, у поля «user» мы используем свойство «args», в котором содержится массив аргументов. Массив «args» передается в анонимную функцию «resolve» вторым аргументом, используя который мы узнаем id целевого пользователя.
'args' => [
'id' => Types::int()
]Вместо:
'args' => [
'id' => [
'type' => Types::int()
]
]Теперь можно запустить сервер GraphQL и проверить его работу таким запросом:
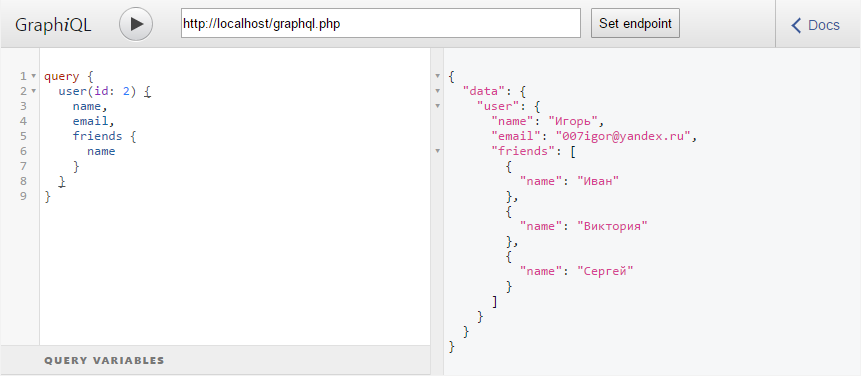
Или таким:
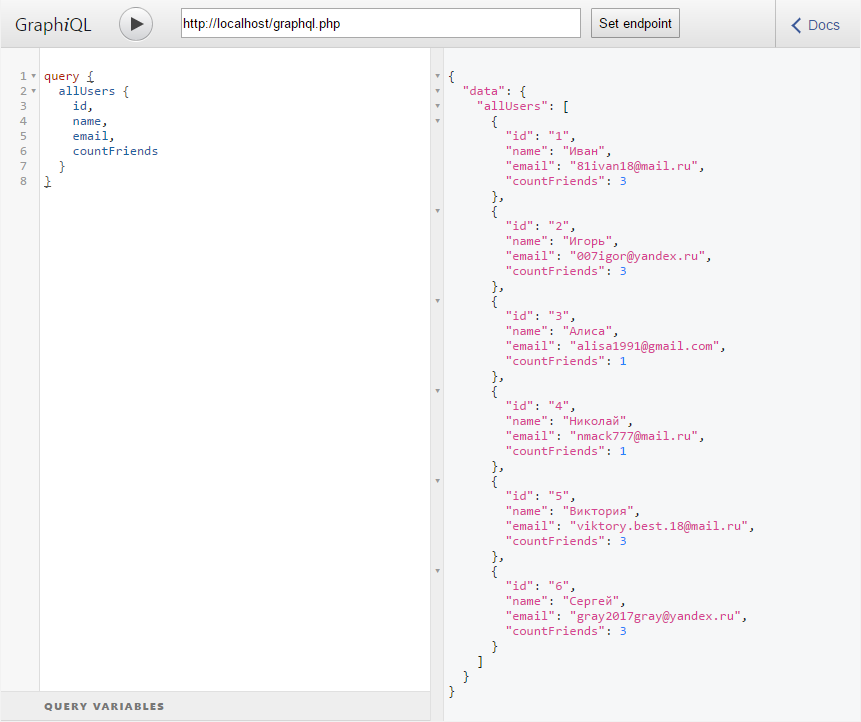
Или любым другим.
Заключение
На этом все. Читайте документацию. Задавайте вопросы в комментариях. Критикуйте.
Если данная статья будет интересной не только мне, то я напишу еще несколько статей про GraphQL на PHP, в которых постараюсь рассмотреть вопросы которые обошел стороной.
Также рекомендую почитать исходный код с комментариями на Github.
Комментарии (39)

RidgeA
06.05.2017 12:42-10NodeJS сможет с лёгкостью отправить одновременно несколько запросов на связанные сущьности. Например, если надо вытянуть данные человека, его друзей, его посты, сообщения. Запросы на друзей, сообщения и посты можно отправить параллельно. В PHP, насколько я знаю, такой возможности нет (за исключением особых извращений)

XAHTEP26
06.05.2017 12:54+4Ну во первых в этой статье я не говорю что надо использовать PHP, а не Node.js. Я просто рассказываю как использовать GraphQL, если вы используете PHP. А про преимущества и недостатки этих языков можно спорить бесконечно.
Во вторых на PHP конечно нельзя параллельно выполнить подобные запросы. Но во многих случаях можно написать более сложные запросы к БД, которые за один раз получат всю или почти всю необходимую информацию, но в данной статье я не стал усложнять код, потому что это бы усложнило его понимание.RidgeA
06.05.2017 18:12-6Я к пытался сказать, что PHP плох, NodeJS хорош. Каждый язык — просто инструмент. И каждый язык имеет свои сильные и слабые стороны. Как по мне профит от использования GraphQL не в последнюю (хотя и не единственную) очередь заключается в возможности распараллеливания запросов, когда за различные сущьности отвечают различные сервисы.

hlogeon
06.05.2017 22:09+1Вот уж в отправке асинхронных запросов к БД в PHP никаких проблем нет. Но как правило даже этого ненужно.
himik_od_ua
06.05.2017 14:17https://github.com/Youshido/GraphQL советую присмотреться. Реализует почти все из протокола, есть подход как инлайн конфигурации, так и OO. По опыту использования советую
XAHTEP26
06.05.2017 22:11Спасибо. Я слышал и про эту библиотеку, но так как она не полностью реализует спецификацию, то решил пользоваться graphql-php. Но соглашусь — по стилю эта реализация мне тоже нравится больше. Обязательно рассмотрю её.

Fesor
06.05.2017 23:29пробовал, ни та ни другая реализация graphql под php не понравились. В целом Youshido/GraphQL понравилась больше чем webonyx/graphql-php, однако под последнюю проще писать обертки и фасады упрощающие дела. В целом я еще недостаточно набаловался с обеими.

Fedcomp
06.05.2017 15:31А что по поводу безопасности самого graphql?

zelenin
06.05.2017 15:36а что не так с безопасностью?
Fedcomp
06.05.2017 15:44+1Ну во первых можно намеренно слать самые тяжелые запросы, даже те, которых на фронтенде нет. Во вторых при вытагивании ресурсов было бы неплохо еще всякие политики безопасности иметь, например не показывать удаленных пользователей, сообщения находящиеся в определенных разделах и так далее.
zelenin
06.05.2017 15:51+1https://habrahabr.ru/post/326986/#comment_10183788
Любая спецификация api не защищает от вас от вашей реализации.

SPAHI4
06.05.2017 20:18+1Это решается точно так же, как и в других API. Или в моделях, если graphql — это просто обертка, или через middleware

taujavarob
06.05.2017 21:19-2Похоже не дошли ещё до безопасности в GraphQL.
Типа свежая хипстерская технология.
Имхо.XAHTEP26
06.05.2017 22:22+2Вот я удивляюсь. Под каждой статьёй про GraphQL обязательно кто нибудь спросит про безопасность. Но ещё сильнее меня удивляет то, что после комментариев, в которых говорится: «безопасность вашего приложения зависит от вас, а не от GraphQL» — вы делаете вывод, что безопасности в GraphQL нет.
zelenin
07.05.2017 00:02+1рассмотрим любую спецификацию любого api, например rest. Что должен получить клиент при запросе GET /api/orders? Все 100000 заказов, если в конкретной реализации разработчик не позаботился о том, чтобы данный запрос был с дефолтными page=1&limit=20 (условно). Точно также работает и graphql. Это спецификации доступа к данным, а не про безопасность.

igordata
07.05.2017 22:12если в конкретной реализации разработчик не позаботился о том,
и кстати в этот момент это API перестаёт быть REST и становится «просто ещё одно кастомное API на URL и HTTP»zelenin
07.05.2017 22:17не совсем. рест вообще не спека, а крайне общая парадигма, в своей основе имеющая понятия ресурсов и методов доступа к ним. О пагинированности листингов оно не говорит.
Fesor
08.05.2017 01:08в этот момент это API перестаёт быть REST
Я вам больше скажу. Если у вас клиент не использует HATEOAS — у вас не REST. Мобилки не умеют в гипертекст. А сделать так чтобы у нас все на клиенте декларировалось гипертекстом — получится недо-браузер и десяток человеко-лет разработки. Это никому не нужно.
Так что сойдемся на rest-like и норм.
Fesor
07.05.2017 01:49стандарты типа jsonapi вообще никаких решений в этом ключе не предоставляют и никто не замарачивается.
Fesor
06.05.2017 23:32graphql никак не решает проблемы безопасности. Это лишь более-менее стандартизированный прикладной протокол передачи данных. Аутентификацию/авторизацию вы уже сами делайте. Точно так же как graphql не решает вопросов пагинации, фильтраци и т.д.
Что дает graphql, и это по настоящему мощная штука, это полный контроль за тем как ваша API используется. Вы можете анализировать запросы, смотреть что чуваки мол чаще запрашивают глубокие короткие графы, что позволит вам улучшить ваше API и сделать его удобнее для клиента. Так же это упростит эволюционный подход к разработке API (решение проблемы версионизации API — не версионизировать API).
zelenin
07.05.2017 00:04проникся? помню, в том году ты еще был скептически настроен.
Fesor
07.05.2017 01:48Ну в целом оно решает мои проблемы. Причем неплохо. Тут больше агрессивный маркетинг напрягал.
hlogeon
07.05.2017 04:45А я вот все смотрю на него, смотрю. Домашние проекты даже некоторые делал с GraphQL, но вот в реальных проектах пока не решаюсь.
Fesor
08.05.2017 01:09Я уперся в то что с мобильными клиентами все не так просто. Ну то есть есть всякие Apollo но мне лично не очень нравится такой подход. Под андроид есть неплохой примерчик с кодогенерацией, но я не мобильщик и все жду пока наши ребята потыкают.

Alexeyco
06.05.2017 21:23Скажите, пожалуйста, а nested attacks как-то предполагаются?
{ authors { firstName posts { title author { firstName posts{ title author { firstName posts { title [n author] [n post] } } } } } } }XAHTEP26
06.05.2017 22:33Насколько я знаю в реализациях GraphQL на PHP пока нет готового решения этой проблемы, но думаю в будущем она появится. А пока можно просто накладывать определённые ограничения на вложенности или время выполнения запроса. Или же создать что-то вроде реестра доступных запросов и тогда, если запроса полученного сервером не будет в реестре, то он не будет выполняться. Хороший ответ на подобный вопрос есть тут: http://stackoverflow.com/questions/37337466/how-do-you-prevent-nested-attack-on-graphql-apollo-server
Alexeyco
07.05.2017 16:33Спасибо, именно оттуда я и взял этот запрос, как можно заметить. Просто я из лучших побуждений хочу, чтобы как можно больше решений, использующих GraphQL, сразу обращали внимание на подобную опасность.


lowadka
07.05.2017 20:37Возможно я чего-то не понимаю, или этот подход не для меня, поэтому ответьте пожалуйста на вопрос:
Сейчас, грубо говоря, мы подгоняем хранение данных под то, как они будут использоваться. Т.е. данные в базах могут быть специально нормализованы под какой-то высоконагруженный endpoint и от этого будет профит. Но ведь получается сам подход GraphQL этому противоречит? А как с таким подходом борются с нагрузками?zelenin
07.05.2017 22:26Сейчас, грубо говоря, мы подгоняем хранение данных под то, как они будут использоваться
это объяснимый, но нехороший способ решать проблемы.
Т.е. данные в базах могут быть специально нормализованы под какой-то высоконагруженный endpoint и от этого будет профит.
обычно все-таки при использовании в качестве бэка sql-решений имеют нормализованную базу и заточенную под фронт денормализованное быстрое хранилище.
Но ведь получается сам подход GraphQL этому противоречит?
GraphQL не предъявляет никаких требований к хранилищу. Используйте любое на какое хватит ума и опыта. В ресолверах могут быть тяжелые запросы с джойнами к sql-хранилищу либо быстрые запросы к redis/mongo/elasticsearch/solr.
Fesor
08.05.2017 01:13мы подгоняем хранение данных под то, как они будут использоваться. Т.е. данные в базах могут быть специально нормализованы под какой-то высоконагруженный endpoint и от этого будет профит.
обычно как раз таки мы денормализуем данные под то, как они будут использоваться. Можно делать из одного набора данных несколько видов проекций под разные задачи. И вот от этого будет сильный профит в плане производительности.
Но ведь получается сам подход GraphQL этому противоречит?
нисколько. Это по сути агрегатор. Фэйсбук его по сути создавал решать простую проблему. У вас есть 5 серверов и нам надо сделать 5 запросов что бы забрать данные на один скрин. В итоге нам проще сделать своего рода фасад над нашим сервером который будет агрегировать данные так как их хочет видеть клиент. Будете вы делать для филда запрос по HTTP или в базу — это уже деталь реализации.
Koc
08.05.2017 11:59я правильно понимаю, что на выборку из 50 пользователей будет сгенерировано еще +50 запросов на получение кол-ва друзей для каждого? Это можно как-то одним пакетным запросом через
WHERE INрешить?XAHTEP26
08.05.2017 12:22В данном примере — да. Для каждого пользователя будет ещё отдельный запрос друзей, но как я уже писал ранее — это я сделал чтобы максимально упростить пример. Вы же можете написать любой запрос к базе данных и потом полученные результаты обработать в ресолвере как вам надо.
Koc
08.05.2017 12:24Покажите тогда пример как эту ситуацию можно обыграть через +1 запрос с
WHERE INXAHTEP26
08.05.2017 12:33+1Конкретно про решение проблемы n+1 можете почитать здесь:
http://webonyx.github.io/graphql-php/data-fetching/#solving-n1-problem
Это документация к библиотеке graphql-php и в ней этот случай описан. Если все равно возникнут вопросы — задавайте.
malinichev
Однозначно пригодится! В закладки