

Не так давно я написал статью о том, как сделать свой GraphQL сервер на PHP с помощью библиотеки graphql-php и как с его помощью реализовать простое API для получения данных из MySQL.
Теперь я хочу рассказать о том как заставить ваш GraphQL сервер работать с мутациями, а также постараюсь ответить на самые распространенные вопросы в комментариях к предыдущей статье, показав как использовать валидацию данных и затрону тему безопасности самих запросов.
Предисловие
Хочу напомнить, что в данном примере я использую библиотеку graphql-php. Мне известно что помимо нее есть другие решения, но на данный момент нельзя с уверенностью сказать какое из них лучше.
Также уточню, что данной статьей я не призываю вас использовать PHP, вместо Node.js или наоборот, а лишь хочу показать как использовать GraphQL, если вы по собственному желанию или же из-за обстоятельств непреодолимой силы работаете с PHP.
Чтобы не объяснять все сначала — за основу я возьму конечный код из предыдущей статьи. Также его можно посмотреть в репозитории статьи на Github. Если вы еще не читали предыдущую статью, то рекомендую ознакомиться с ней прежде чем продолжать.
В данной статье потребуется посылать INSERT и UPDATE запросы к базе данных. Непосредственно к GraphQL это отношения не имеет, поэтому я просто добавлю в уже имеющийся файл DB.php пару новых методов, чтобы не заострять на них внимание в дальнейшем. В итоге код файла будет следующим:
<?php
namespace App;
use PDO;
class DB
{
private static $pdo;
public static function init($config)
{
// Создаем PDO соединение
self::$pdo = new PDO("mysql:host={$config['host']};dbname={$config['database']}", $config['username'], $config['password']);
// Задаем режим выборки по умолчанию
self::$pdo->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_OBJ);
}
public static function selectOne($query)
{
$records = self::select($query);
return array_shift($records);
}
public static function select($query)
{
$statement = self::$pdo->query($query);
return $statement->fetchAll();
}
public static function affectingStatement($query)
{
$statement = self::$pdo->query($query);
return $statement->rowCount();
}
public static function update($query)
{
$statement = self::$pdo->query($query);
$statement->execute();
return $statement->rowCount();
}
public static function insert($query)
{
$statement = self::$pdo->query($query);
$success = $statement->execute();
return $success ? self::$pdo->lastInsertId() : null;
}
}Итак приступим.
Мутации и переменные
Как я уже упоминал в предыдущей статье, схема GraphQL наряду с Query, может содержать еще один корневой тип данных — Mutation.
Этот тип отвечает за изменение данных на сервере. Подобно тому как в REST для получения данных рекомендуется использовать GET запросы, а для изменения данных POST (PUT, DELETE) запросы, в GraphQL для получения данных с сервера следует использовать Query, а для изменения данных — Mutation.
Описание типов полей для Mutation происходит также как и для Query. Мутации как и запросы могут возвращать данные — это удобно если вы например хотите запросить обновленную информацию с сервера сразу же после выполнения мутации.
Давайте создадим тип Mutation отдельном файле MutationType.php в папке Type:
<?php
namespace App\Type;
use App\DB;
use App\Types;
use GraphQL\Type\Definition\ObjectType;
class MutationType extends ObjectType
{
public function __construct()
{
$config = [
'fields' => function() {
return [
// Массив полей пока пуст
];
}
];
parent::__construct($config);
}
}И добавим его в наш реестр типов Types.php:
use App\Type\MutationType;
private static $mutation;
public static function mutation()
{
return self::$mutation ?: (self::$mutation = new MutationType());
}Осталось добавить только что созданную нами мутацию в схему в файле graphql.php сразу после Query:
$schema = new Schema([
'query' => Types::query(),
'mutation' => Types::mutation()
]);На этом создание мутации завершено, но пока толку от нее мало. Давайте добавим в мутацию поля для изменения данных имеющихся пользователей.
Изменение информации о пользователе
Как мы уже знаем, данные в запрос можно передавать в качестве аргументов. Значит мы можем легко добавить в мутацию поле «changeUserEmail», которое будет принимать 2 аргумента:
- id — идентификатор пользователя
- email — новый адрес электронной почты пользователя
Давайте изменим код файла MutationType.php:
<?php
namespace App\Type;
use App\DB;
use App\Types;
use GraphQL\Type\Definition\ObjectType;
class MutationType extends ObjectType
{
public function __construct()
{
$config = [
'fields' => function() {
return [
'changeUserEmail' => [
'type' => Types::user(),
'description' => 'Изменение E-mail пользователя',
'args' => [
'id' => Types::int(),
'email' => Types::string()
],
'resolve' => function ($root, $args) {
// Обновляем email пользователя
DB::update("UPDATE users SET email = '{$args['email']}' WHERE id = {$args['id']}");
// Запрашиваем и возвращаем "свежие" данные пользователя
$user = DB::selectOne("SELECT * from users WHERE id = {$args['id']}");
if (is_null($user)) {
throw new \Exception('Нет пользователя с таким id');
}
return $user;
}
]
];
}
];
parent::__construct($config);
}
}Теперь мы можем выполнить мутацию, которая изменит E-mail пользователя и вернет его данные:
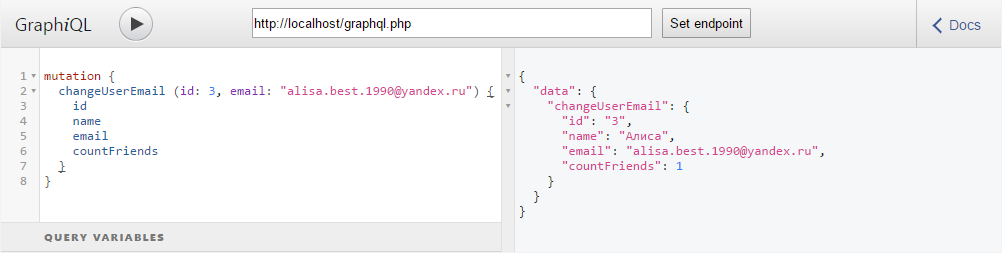
Переменные запроса
Получилось неплохо, но вставлять значения аргументов в текст запроса не всегда удобно.
Чтобы упростить вставку динамических данных в запрос в GraphQL существует специальный словарь переменных Variables.
Значения переменных передаются на сервер вместе с запросом и, как правило, в виде JSON-объекта. Поэтому чтобы наш сервер GraphQL мог с ними работать давайте немного изменим код endpoint добавив в него извлечение и декодирование переменных из запроса:
$variables = isset($input['variables']) ? json_decode($input['variables'], true) : null;И затем передадим их в GraphQL пятым параметром:
$result = GraphQL::execute($schema, $query, null, null, $variables);После чего код файла graphql.php будет следующим:
<?php
require_once __DIR__ . '/vendor/autoload.php';
use App\DB;
use App\Types;
use GraphQL\GraphQL;
use GraphQL\Schema;
try {
// Настройки подключения к БД
$config = [
'host' => 'localhost',
'database' => 'gql',
'username' => 'root',
'password' => 'root'
];
// Инициализация соединения с БД
DB::init($config);
// Получение запроса
$rawInput = file_get_contents('php://input');
$input = json_decode($rawInput, true);
$query = $input['query'];
// Получение переменных запроса
$variables = isset($input['variables']) ? json_decode($input['variables'], true) : null;
// Создание схемы
$schema = new Schema([
'query' => Types::query(),
'mutation' => Types::mutation()
]);
// Выполнение запроса
$result = GraphQL::execute($schema, $query, null, null, $variables);
} catch (\Exception $e) {
$result = [
'error' => [
'message' => $e->getMessage()
]
];
}
// Вывод результата
header('Content-Type: application/json; charset=UTF-8');
echo json_encode($result);Теперь мы можем передать данные в виде JSON (в GraphiQL-расширениях для браузера для этого есть вкладка «Query variables» в нижнем левом углу). А вставить переменные в запрос можно передав их в мутацию подобно тому как передаются аргументы в анонимную функцию (с указанием типа):
mutation($userId: Int, $userEmail: String)После чего их можно указывать в качестве значений аргументов:
changeUserEmail (id: $userId, email: $userEmail)И теперь тот же самый запрос будет выглядеть так:
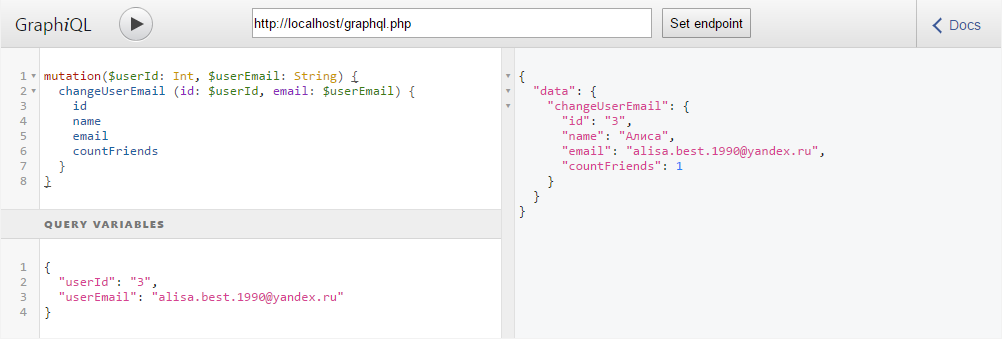
Добавление нового пользователя
В принципе мы могли бы сделать подобную мутацию и для добавления нового пользователя, просто добавив пару недостающих аргументов и убрав id, но мы лучше создадим отдельный тип данных для ввода пользователя.
В GraphQL типы данных делятся на 2 вида:
- Output types — типы для вывода данных (или типы полей)
- Input types — типы для ввода данных (или типы аргументов)
Все простые типы данных (Scalar, Enum, List, NonNull) относятся к обоим видам одновременно.
Такие типы как Interface и Union относятся только к Output, но в данной статье мы их рассматривать не будем.
Составной тип Object, рассмотренный нами в предыдущей части, также относится к Output, а для Input есть аналогичный тип InputObject.
Отличие InputObject от Object состоит в том что его поля не могут иметь аргументов (args) и ресолверов (resolve), а также их типы (type) должны быть вида Input types.
Давайте создадим новый тип InputUserType для добавления пользователя. Он будет похож на тип UserType, только мы теперь будем наследовать не от ObjectType, а от InputObjectType:
<?php
namespace App\Type;
use App\Types;
use GraphQL\Type\Definition\InputObjectType;
class InputUserType extends InputObjectType
{
public function __construct()
{
$config = [
'description' => 'Добавление пользователя',
'fields' => function() {
return [
'name' => [
'type' => Types::string(),
'description' => 'Имя пользователя'
],
'email' => [
'type' => Types::string(),
'description' => 'E-mail пользователя'
]
];
}
];
parent::__construct($config);
}
}И не забываем добавить его в наш реестр типов Types.php:
use App\Type\InputUserType;
private static $inputUser;
public static function inputUser()
{
return self::$inputUser ?: (self::$inputUser = new InputUserType());
}Отлично! Теперь мы можем использовать его чтобы добавить новое поле «addUser» в MutationType.php рядом с полем «changeUserEmail»:
'addUser' => [
'type' => Types::user(),
'description' => 'Добавление пользователя',
'args' => [
'user' => Types::inputUser()
],
'resolve' => function ($root, $args) {
// Добавляем нового пользователя в БД
$userId = DB::insert("INSERT INTO users (name, email) VALUES ('{$args['user']['name']}', '{$args['user']['email']}')");
// Возвращаем данные только что созданного пользователя из БД
return DB::selectOne("SELECT * from users WHERE id = $userId");
}
]Обращаю внимание на то что данное поле имеет один аргумент типа InputUser (
Types::inputUser()) и возвращает только что созданного пользователя типа User (Types::user()).Готово. Теперь мы можем добавить нового пользователя в базу данных с помощью мутации. Данные пользователя передаем в Variables и указываем переменной тип InputUser:
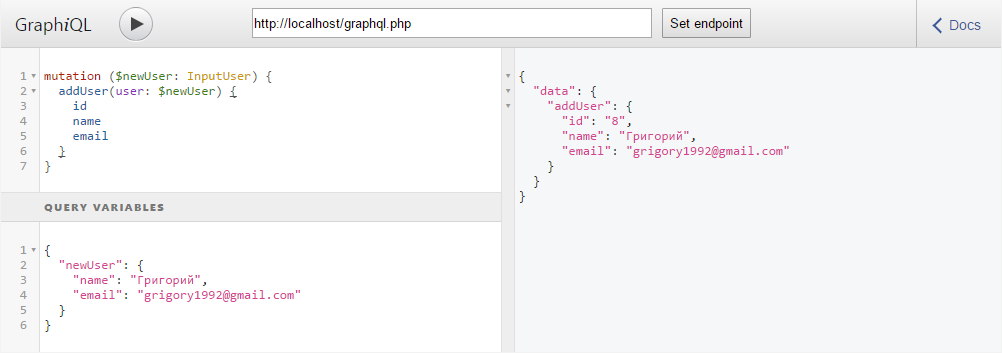
Валидация и безопасность
Я бы разделил валидацию в GraphQL на 2 вида:
- Валидация данных передаваемых вместе с запросом (аргументов и переменных)
- Валидация самих запросов
И хоть в комментариях к предыдущей статье уже не раз говорилось о том, что безопасность вашего приложения находится в ваших руках, а не руках GraphQL, я все же покажу пару простых способов обезопасить свое приложение при использовании graphql-php.
Валидация данных
Все что мы делали до этого в нашем примере никак не защищено от ввода неверных данных.
Давайте добавим простую валидацию данных, обозначив какие аргументы являются обязательными, а также организуем проверку Email.
Чтобы обозначить обязательные аргументы будем использовать специальный тип данных NonNull в GraphQL. Давайте подключим его в наш реестр типов:
public static function nonNull($type)
{
return Type::nonNull($type);
}Теперь просто обернем им типы тех аргументов, которые являются обязательными.
Будем считать что для пользователя в InputUserType.php поля «name» и «email» обязательны для заполнения:
'fields' => function() {
return [
'name' => [
'type' => Types::nonNull(Types::string()),
'description' => 'Имя пользователя'
],
'email' => [
'type' => Types::nonNull(Types::string()),
'description' => 'E-mail пользователя'
],
];
}А для мутации «changeUserEmail» обязательными будут «id» и «email»:
'args' => [
'id' => Types::nonNull(Types::int()),
'email' => Types::nonNull(Types::string())
]Теперь если мы забудем указать какой-либо обязательный параметр, то получим ошибку. Но мы все еще можем указать в качестве E-mail пользователя любую строку. Давайте это исправим.
Для того чтобы мы могли провести проверку полученного E-mail, нам надо создать для него свой скалярный тип данных.
В GraphQL есть несколько встроенных скалярных типов:
- String
- Int
- Float
- Boolean
- Id
С некоторыми из них вы уже знакомы, а предназначение остальных очевидно.
Чтобы создать кастомный скалярный тип данных, мы должны написать для него класс, который будет наследовать от ScalarType и реализовывать 3 метода:
- serialize — сериализация внутреннего представления данных в строку для вывода
- parseValue — парсинг данных в Variables для внутреннего представления
- parseLiteral — парсинг данных в тексте запроса для внутреннего представления
Методы parseValue и parseLiteral для скалярных типов во многих случаях будут очень похожи, но стоит обратить внимание на то, что parseValue принимает в качестве аргумента значение переменной, а parseLiteral объект класса Node, содержащий это значение в свойстве «value».
Давайте наконец-то создадим новый скалярный тип данных Email в отдельном файле EmailType.php. Чтобы не хранить все типы в одной большой куче, я помещу этот файл в подпапку «Scalar» папки «Type»:
<?php
namespace App\Type\Scalar;
use GraphQL\Type\Definition\ScalarType;
class EmailType extends ScalarType
{
public function serialize($value)
{
return $value;
}
public function parseValue($value)
{
if (!filter_var($value, FILTER_VALIDATE_EMAIL)) {
throw new \Exception('Не корректный E-mail');
}
return $value;
}
public function parseLiteral($valueNode)
{
if (!filter_var($valueNode->value, FILTER_VALIDATE_EMAIL)) {
throw new \Exception('Не корректный E-mail');
}
return $valueNode->value;
}
}Остается только добавить очередной тип данных в реестр Types.php:
use App\Type\Scalar\EmailType;
private static $emailType;
public static function email()
{
return self::$emailType ?: (self::$emailType = new EmailType());
}И заменить у всех полей «email» тип String (
Types::string()) на Email (Types::email()). Например полный код MutationType.php теперь будет таким:<?php
namespace App\Type;
use App\DB;
use App\Types;
use GraphQL\Type\Definition\ObjectType;
class MutationType extends ObjectType
{
public function __construct()
{
$config = [
'fields' => function() {
return [
'changeUserEmail' => [
'type' => Types::user(),
'description' => 'Изменение E-mail пользователя',
'args' => [
'id' => Types::nonNull(Types::int()),
'email' => Types::nonNull(Types::email())
],
'resolve' => function ($root, $args) {
// Обновляем email пользователя
DB::update("UPDATE users SET email = '{$args['email']}' WHERE id = {$args['id']}");
// Запрашиваем и возвращаем "свежие" данные пользователя
$user = DB::selectOne("SELECT * from users WHERE id = {$args['id']}");
if (is_null($user)) {
throw new \Exception('Нет пользователя с таким id');
}
return $user;
}
],
'addUser' => [
'type' => Types::user(),
'description' => 'Добавление пользователя',
'args' => [
'user' => Types::inputUser()
],
'resolve' => function ($root, $args) {
// Добавляем нового пользователя в БД
$userId = DB::insert("INSERT INTO users (name, email) VALUES ('{$args['user']['name']}', '{$args['user']['email']}')");
// Возвращаем данные только что созданного пользователя из БД
return DB::selectOne("SELECT * from users WHERE id = $userId");
}
]
];
}
];
parent::__construct($config);
}
}А код InputUserType.php таким:
<?php
namespace App\Type;
use App\Types;
use GraphQL\Type\Definition\InputObjectType;
class InputUserType extends InputObjectType
{
public function __construct()
{
$config = [
'description' => 'Добавление пользователя',
'fields' => function() {
return [
'name' => [
'type' => Types::nonNull(Types::string()),
'description' => 'Имя пользователя'
],
'email' => [
'type' => Types::nonNull(Types::email()),
'description' => 'E-mail пользователя'
],
];
}
];
parent::__construct($config);
}
}И теперь при вводе неправильного E-mail мы увидим ошибку:
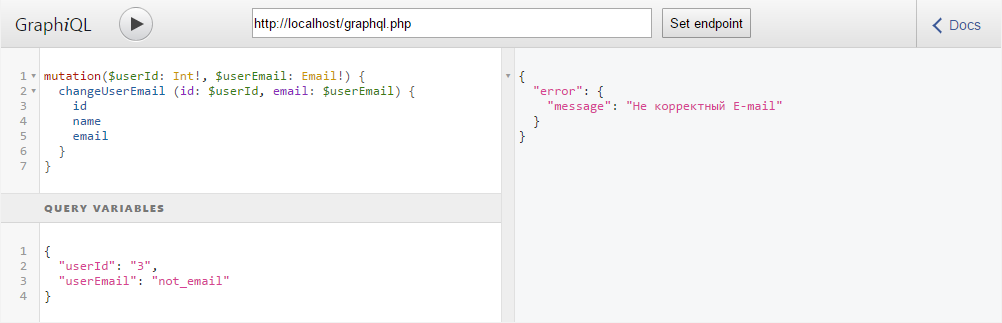
Как можно заметить, теперь в запросе для переменной
$userEmail мы указываем тип Email, а не String. А также добавляем восклицательные знаки после указания типа всех обязательных аргументов запроса.Валидация запроса
Для обеспечения безопасности GraphQL производит ряд операций связанных с валидацией полученного запроса. Большинство из них в graphql-php включены по умолчанию и вы уже сталкивались с ними когда видели ошибки при получении ответа от сервера GraphQL, поэтому я не буду разбирать их все а покажу один — наиболее интересный случай.
Зацикливание фрагментов
Когда вы хотите запросить несколько объектов, у которых одинаковые поля, то вы врядли захотите вводить в запросе один и тот же список полей для каждого объекта.
Для решения этой проблемы в GraphQL существуют фрагменты (Fragments). То есть вы можете один раз перечислить все необходимые поля в фрагменте, а затем использовать этот фрагмент в запросе столько раз — сколько потребуется.
По синтаксису фрагменты напоминают оператор spread в JavaScript. Давайте для примера запросим список пользователей и их друзей с некоторой информацией о них.
Без фрагментов это выглядело бы так:
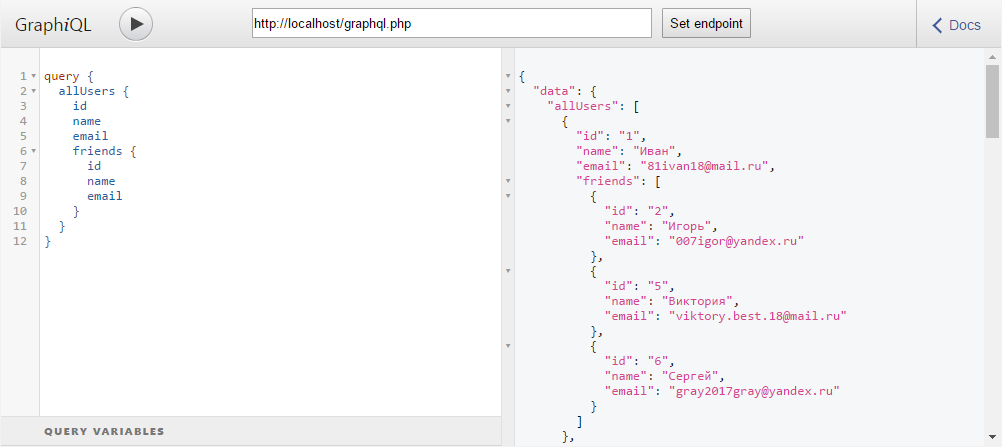
А создав фрагмент
userFields для типа User, мы можем переписать наш запрос так: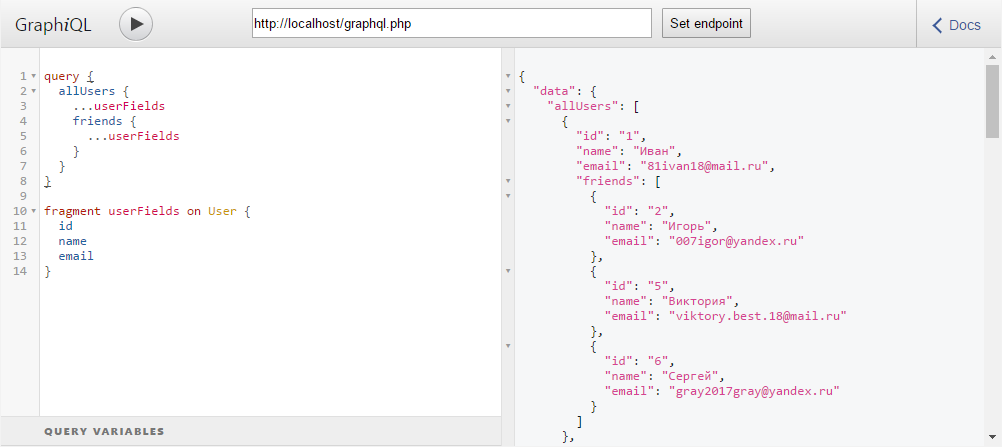
Может в этом случае мы не получаем большой выгоды от использования фрагментов, но в более сложном запросе они точно будут полезны.
Но ведь мы сейчас говорим о безопасности. При чем тут вообще какие-то фрагменты?
А при том что теперь у потенциального злоумышленника появляется возможность зациклить запрос, использовав фрагмент внутри самого себя. И после этого наш сервер наверняка бы упал, но GraphQL не позволит ему это сделать и выдаст ошибку:
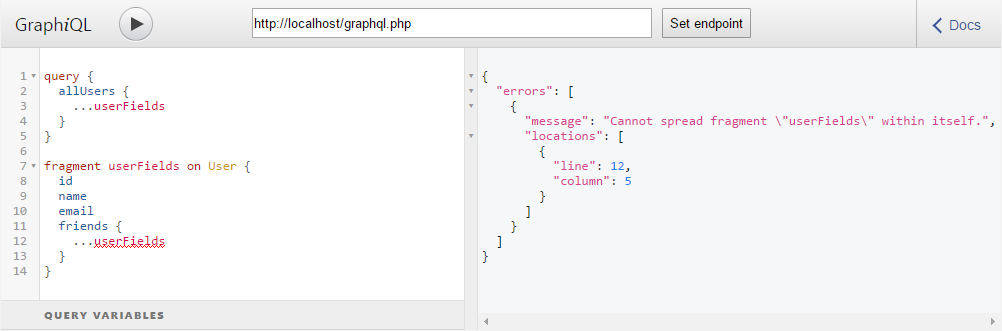
Сложность запроса и глубина запроса
Также, помимо стандартной валидации запроса, graphql-php позволяет задать максимальную сложность и максимальную глубину запроса.
Грубо говоря сложность — это целое число, которое в большинстве случаев соответствует количеству полей в запросе, а глубина — это число уровней вложенности в полях запроса.
По умолчанию максимальная сложность и максимальная глубина запроса равны нулю, то есть не ограничены. Но мы можем ограничить их подключив в graphql.php классы для валидации и соответствующих правил:
use GraphQL\Validator\DocumentValidator;
use GraphQL\Validator\Rules\QueryComplexity;
use GraphQL\Validator\Rules\QueryDepth;И добавив эти правила в валидатор непосредственно перед выполнением запроса:
// Устанавливаем максимальную сложность запроса равной 6
DocumentValidator::addRule('QueryComplexity', new QueryComplexity(6));
// И максимальную глубину запроса равной 1
DocumentValidator::addRule('QueryDepth', new QueryDepth(1));В итоге код файла graphql.php должен выглядеть примерно так:
<?php
require_once __DIR__ . '/vendor/autoload.php';
use App\DB;
use App\Types;
use GraphQL\GraphQL;
use GraphQL\Schema;
use GraphQL\Validator\DocumentValidator;
use GraphQL\Validator\Rules\QueryComplexity;
use GraphQL\Validator\Rules\QueryDepth;
try {
// Настройки подключения к БД
$config = [
'host' => 'localhost',
'database' => 'gql',
'username' => 'root',
'password' => 'root'
];
// Инициализация соединения с БД
DB::init($config);
// Получение запроса
$rawInput = file_get_contents('php://input');
$input = json_decode($rawInput, true);
$query = $input['query'];
// Получение переменных запроса
$variables = isset($input['variables']) ? json_decode($input['variables'], true) : null;
// Создание схемы
$schema = new Schema([
'query' => Types::query(),
'mutation' => Types::mutation()
]);
// Устанавливаем максимальную сложность запроса равной 6
DocumentValidator::addRule('QueryComplexity', new QueryComplexity(6));
// И максимальную глубину запроса равной 1
DocumentValidator::addRule('QueryDepth', new QueryDepth(1));
// Выполнение запроса
$result = GraphQL::execute($schema, $query, null, null, $variables);
} catch (\Exception $e) {
$result = [
'error' => [
'message' => $e->getMessage()
]
];
}
// Вывод результата
header('Content-Type: application/json; charset=UTF-8');
echo json_encode($result);Теперь давайте проверим наш сервер. Для начала введем валидный запрос:
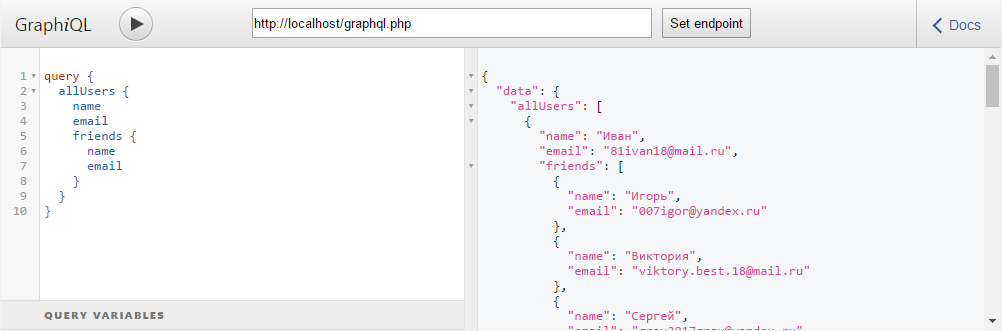
Теперь изменим запрос так, чтобы его сложность была больше максимально допустимой:
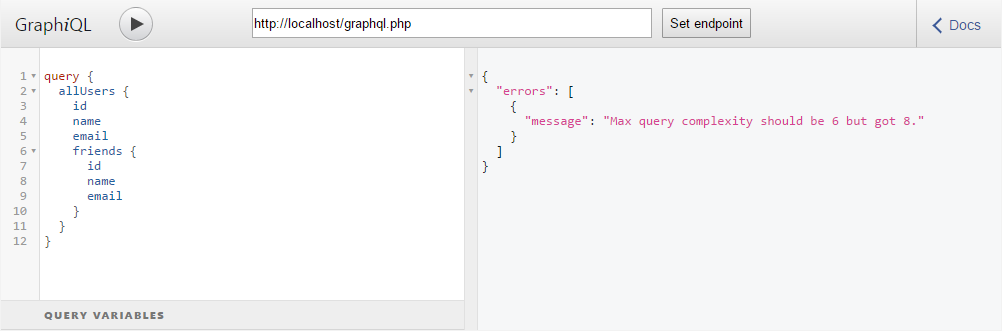
И аналогично увеличим глубину запроса:
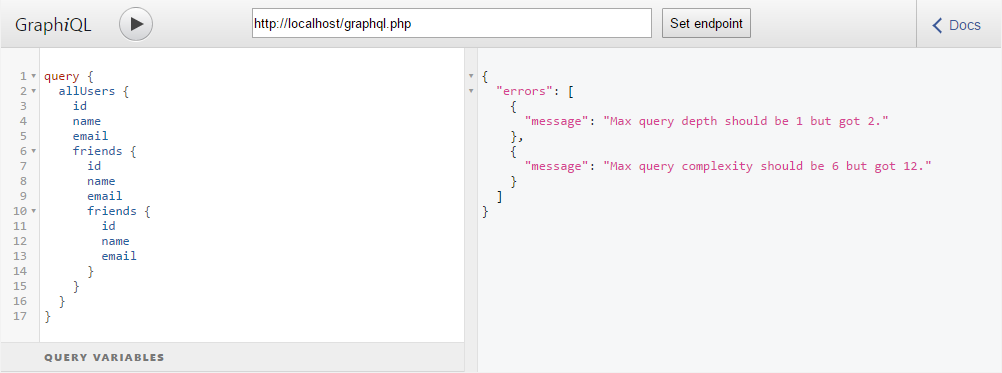
И этот запрос тоже подвергается валидации. Поэтому следует либо отключать валидацию запроса, до загрузки расширения, либо указывать максимально допустимую сложность и глубину больше чем в этом запросе.
В моем расширении для GrapiQL глубина «системного» запроса равна 7, а сложность 109. Учтите этот ньюанс, дабы избежать непонимания того откуда возникают ошибки.
То есть теперь у вас появляется возможность ограничить нагрузку на сервер и бороться с такой проблемой, как Nested attaсk.
Заключение
Спасибо за внимание.
Задавайте вопросы и я постараюсь на них ответить. А также буду вам благодарен если укажете мне на мои ошибки.
Исходный код с исчерпывающими комментариями также доступен на Github.
Другие части данной статьи:
- Установка, схема и запросы
- Мутации, переменные, валидация и безопасность
- Решение проблемы N+1 запросов
Комментарии (14)

taujavarob
26.05.2017 15:25И хоть в комментариях к предыдущей статье уже не раз говорилось о том, что безопасность вашего приложения находится в ваших руках, а не руках GraphQL, я все же покажу пару простых способов обезопасить свое приложение при использовании graphql-php.
Смотрите, обычно у нас есть роли, типа — админ, редактор, зарегистрированный юзер, анонимус.
Конечно мы им, обычно, даём разные урлы (в вашем случае типа localhost/graphql.php )
Это мы на уровни роли разрулим у себя на сервере нашего приложения.
Но, обычно мы знаем (через специфические URI запроса) — что посылать обратно клиенту.
В случае GraphQL — мы имеем большую возможность, что юзер с ролью пришлёт такой запрос на который (на часть которого) у него нет разрешения (нет политики).
К примеру, юзер с ролью анонимус, запрашивая имя, к примеру, не имеет права видеть номер телефон в своём ответе, хотя в своём GraphQL-запросе он это потребовал (указал)!
Вот как разграничить это удобно? И желательно на стадии когда запрос, пришедший на GraphQL сервер для обработки, ещё не выполнился.
Напрашивается, что в этом случае было бы здорово как-то «навешать роли» на схему GraphQL?
Иначе при обработки запроса потребуется через типа if проверять — а имеет ли право эта роль требовать чтобы ей в ответе прислали номер телефона?
Вот о какой безопасно идёт речь, в случае GraphQL. Имхо.

XAHTEP26
26.05.2017 16:17Вот о какой безопасно идёт речь, в случае GraphQL. Имхо.
Просто «в комментариях к предыдущей статье» в основном спрашивали про тяжелые запросы и nested attacks.
Что касается вашего вопроса:
Вот как разграничить это удобно?
Я пожалуй отвечу так: А как вы это делаете сейчас (без GraphQL)?

Fesor
26.05.2017 17:29Конечно мы им, обычно, даём разные урлы
Ну вообще-то урлам (а точнее ресурсам) дела нет до ваших ролей. Так что плохая идея.
Вот как разграничить это удобно?
пользователь запросил несколько филдов. К некоторым из них у него нет доступа. Стало быть для этих филдов мы ничего не возвращаем и добавляем информацию об ошибках.
было бы здорово как-то «навешать роли» на схему GraphQL?
это будет работать только в самых примитивных случаях. Как правило все намного сложнее. В документации к graphql есть вполне себе неплохой момент описывающий основную суть проблемы: Делегируй авторизацию действий слою с бизнес логикой. То есть в ресолвере мы лишь запрашиваем данные, а чуть что — ловим исключение и добавляем в список ошибок для полей.
Иначе при обработки запроса потребуется через типа if проверять — а имеет ли право эта роль требовать чтобы ей в ответе прислали номер телефона?
Давайте так, вот вам бизнес правило: email пользователя можно показывать только самому пользователю, администратору, модератору, друзьям пользователя. Тут уже просто ролями не отделаешься и вам придется делать
if. А так как это "бизнес" правило — его надо проверять на уровне бизнес логики а не во "вьюхе" (а именно вьюхой является резолверы в graphql).
Вот о какой безопасно идёт речь, в случае GraphQL. Имхо.
Graphql = view layer. Authorization = business layer. Я думаю идея понятна.
taujavarob
29.05.2017 20:20Я пожалуй отвечу так: А как вы это делаете сейчас (без GraphQL)?
Очень по разному.
Начиная от доступа к URI по ролям, использование ролей при выводе результатов (уже после основного запроса/запросов) и заканчивая — ставим роль на конкретный метод сервиса (чтоб уж наверняка не «пробило»).
Но дело в том, что мы сейчас знаем — что выдать клиенту — ибо фактически не он, а мы управляем запросом.
А вот GraphQL — тут первую скрипку ведёт клиент. И в этом то и отличие.
Fesorпользователь запросил несколько филдов. К некоторым из них у него нет доступа. Стало быть для этих филдов мы ничего не возвращаем и добавляем информацию об ошибках.
Не факт.
Нам надо как-то понять, что к этой инфе у него нет доступа (например на основании роли — но это надо
где-то прописать).
Вернуть ему можно и null и без ошибки. Или ничего не вернуть и ошибку — но это нюансы реализации, я думаю.
Fesorэто будет работать только в самых примитивных случаях. Как правило все намного сложнее. В документации к graphql есть вполне себе неплохой момент описывающий основную суть проблемы: Делегируй авторизацию действий слою с бизнес логикой. То есть в ресолвере мы лишь запрашиваем данные, а чуть что — ловим исключение и добавляем в список ошибок для полей.
Да, автор пишет — «It is tempting to place authorization logic in the GraphQL layer like so:» И действительно заманчиво туда и помещать — в схему GraphQL.
Автор просто «выбрасывает» проверку роли во вне. Но почему? — Тогда нам придётся во вне строить дерево доступа по ролям.
Не просто «заманчиво» — а нужно помещать роли в в схему GraphQL.
Фактически обработка запроса от клиента должна быть типа такой:
- дерево-запроса-0 — исходное дерево запроса от клиента.
- 1) функция от дерева-запроса-0 -> проверка дерева-запроса-0 на корректность и выдача ошибки (или null в ветке). На выходе дерево-запроса-1
- 2) функция от дерева-запроса-1 -> проверка дерева-запроса-1 на допустимость выдачи (в зависимости от роли клиента) и выдача ошибки (или null в ветке где недопустимо). На выходе дерево-запроса-2
- 3) функция от дерева-запроса-2 -> выполнение запроса и выдача ошибки (если что-то пошло не так с базой...). На выходе дерево-ответа.
- Отправка клиенту дерево-ответа.
FesorДавайте так, вот вам бизнес правило: email пользователя можно показывать только самому пользователю, администратору, модератору, друзьям пользователя. Тут уже просто ролями не отделаешься и вам придется делать if.
Верно. Идеально чтобы там не просто задать список ролей, а был примитивный язык — как он сейчас во многих фреймворках и есть.
Понимаете, на практике, при отсутствие просто настроить доступ по ролям, будет либо распределение URI по ролям (что грубо), либо, если это публичный сервис — типа Google-map — который ничего не скрывает и роли ему до фонаря.
Имхо, конечно, имхо.
Иметь развесистое дерево (схема GraphQL) где каждую ветку, каждый лист было бы просто настроить по ролям — это идеал.
XAHTEP26
29.05.2017 22:19Начиная от доступа к URI по ролям, использование ролей при выводе результатов (уже после основного запроса/запросов) и заканчивая — ставим роль на конкретный метод сервиса (чтоб уж наверняка не «пробило»).
Вот точно так же и с GraphQL. )
Но дело в том, что мы сейчас знаем — что выдать клиенту — ибо фактически не он, а мы управляем запросом.
А вот GraphQL — тут первую скрипку ведёт клиент. И в этом то и отличие.
Клиент может выбирать какие данные запросить из тех, которые ему доступны и задавать их структуру. Вам же остается только ограничить те данные, которые доступны клиенту (как вы это и делаете сейчас) и пусть балуется.
Fesor
29.05.2017 23:58А вот GraphQL — тут первую скрипку ведёт клиент. И в этом то и отличие.
на самом деле отличие незначительное. Просто по умолчанию мы не возвращаем ничего, и далее уже исходя из того что запросил клиент. Мы все еще контролируем схему. А знание о том что юзается дает больше контроля а не меньше.
Автор просто «выбрасывает» проверку роли во вне. Но почему? — Тогда нам придётся во вне строить дерево доступа по ролям.
Потому что проверка прав не является обязанностью view layer.
Не просто «заманчиво» — а нужно помещать роли в в схему GraphQL.
это как помещать бизнес правила в шаблоны. Вы же так не делаете?
Фактически обработка запроса от клиента должна быть типа такой:
как-то так и происходит, просто все эти решения делегируются вашему коду.
Верно. Идеально чтобы там не просто задать список ролей, а был примитивный язык — как он сейчас во многих фреймворках и есть.
Зачем вам примитивный язык если можно написать вполне себе нормальным кодом?
Понимаете, на практике, при отсутствие просто настроить доступ по ролям, будет либо
на практике все решения в духе "можно или нельзя" делегируются отдельным объектам которые за это отвечают.
где каждую ветку, каждый лист было бы просто настроить по ролям — это идеал.
вам никто не мешает сделать простенький декоратор/ивент листенер для ресорверов каждой ноды дерева. Собственно именно так это делается "во многих фреймворках". Просто это не входит в обязанности graphql, но вас никто не останавливает.
taujavarob
01.06.2017 19:49Клиент может выбирать какие данные запросить из тех, которые ему доступны и задавать их структуру. Вам же остается только ограничить те данные, которые доступны клиенту (как вы это и делаете сейчас) и пусть балуется.
Сейчас мне проще это сделать ибо у меня множество URI (точек входа — «дверей») которым я могу сопоставить роли.
В случае GraphQL у меня будет фактически одно URI — "одно окно" — и возникает вопрос — где мне прописывать ограничения?
FesorЗачем вам примитивный язык если можно написать вполне себе нормальным кодом?
Примитивные языки появляются не потому что нельзя писать «нормальным кодом» — а потому что писать в этом случае «нормальным кодом» неудобно из-за boilerplate code.
Fesorвам никто не мешает сделать простенький декоратор/ивент листенер для ресорверов каждой ноды дерева. Собственно именно так это делается «во многих фреймворках». Просто это не входит в обязанности graphql, но вас никто не останавливает.
Изэтой картинки
Fesor
01.06.2017 20:22Примитивные языки появляются не потому что нельзя писать «нормальным кодом» — а потому что писать в этом случае «нормальным кодом» неудобно из-за boilerplate code.
давайте на конкретных примерах. Приведите мне удобный для вас DSL описания прав а дальше будем рассматривать "чем он плох".
Хорошо видно куда они задвинули авторизацию.
я вам больше скажу, ее и в других вариантах (http api, rpc) задвинули тудаже и правильно сделали. однако вас никто не останавливает ее оттуда вытащить и сделать что-то типа мидлвари.
Но если принято решание использовать только и только graphql — то возникает смысл авторизацию двинуть в описание схемы.
role-based авторизация удобна только для простых случаев. Даже в случае с админкой у меня есть проекты где все вроде и админы но права у всех разные. Ну либо мне надо генерить еще и пермутации маленьких "ролей".
Вся эта настройка просто просится разместиться в GraphQL-схеме — ей там самое место.
и бизнес логику тоже так и просится в контроллерах писать. Но самодисциплина это хорошо.
XAHTEP26
01.06.2017 23:48Сейчас мне проще это сделать ибо у меня множество URI (точек входа — «дверей») которым я могу сопоставить роли.
В случае GraphQL у меня будет фактически одно URI — «одно окно» — и возникает вопрос — где мне прописывать ограничения?
Да ведь можно же ограничить сам список полей в схеме. Например, если роль «Авторизованный пользователь», то он может запрашивать поле «messages», а если «Гость», то нет (возвращать null или выводить ошибку).
И в конце концов, если вам хочется, можно сделать несколько endpoint`ов (URI/точек входа/дверей/окон) с разными схемами данных и сопоставлять им соответствующие роли.
Fesor
Хотелось бы все же примеры различных стратегий борьбы с N+1 проблемами.