
В мае вышла новая мажорная версия Apache Ignite — распределенной платформы, оптимизированной для работы с оперативной памятью, которая объединяет в себе хранилище вида ключ-значение с SQL99-совместимой базой данных, предлагая полную ACID-совместимость, высокую доступность, а также близкое к линейному масштабирование с нескольких узлов до тысяч, которые могут размещаться на собственном оборудовании либо в облаке. Ядро Apache Ignite написано на Java, но платформа, помимо экосистемы Java, поддерживает нативную интеграцию с приложениями на .NET и C++.
Apache Ignite эластично масштабируется в рамках одного или нескольких геораспределенных кластеров, предоставляя гибко настраиваемое шардирование и автоматическую ребалансировку при динамическом добавлении или удалении узлов, обеспечивая прозрачный и быстрый доступ к данным и вычислениям путем использования собственного API либо классического SQL.
В версии 2.0 были значительно переработаны многие вещи «под капотом», следствием стала возможность реализации ряда значительных функциональных изменений, часть из которых заметна уже сейчас, а часть появится в ближайших версиях.
Забегая вперед, мы будем проводить 2 мероприятия, которые связаны с Apache Ignite, подробнее о них можно прочитать в конце статьи.

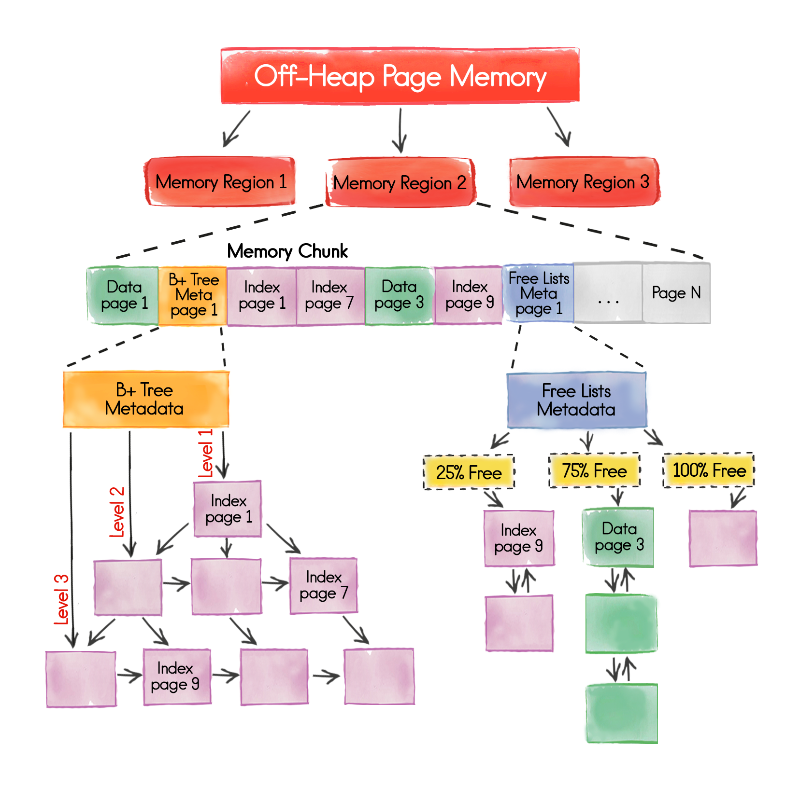
Apache Ignite по умолчанию работает с оперативной памятью, хранит в ней данные в распределенном виде и там же проводит вычисления. Одно из ключевых новшеств версии 2.0 — полностью переработанная архитектура работы с памятью, которая называется Page Memory. И это очень важно.
Новый подход к хранению данных значительно сложнее и продуманнее старого, он позволяет избежать проблем с фрагментацией памяти, значительно ускорить работу с SQL и минимизировать влияние пауз GC на функционирование системы. Более того, новая архитектура позволяет бесшовно работать как с оперативной памятью, так и с диском. В версии 2.0 эта возможность еще отсутствует, но уже в скором времени можно будет узнать о наших планах по развитию в этой области подробнее.
С новой архитектурой можно ознакомиться в общих чертах на рисунке ниже, а также в специальном разделе документации.
Целью Apache Ignite является построение платформы, в которую входит множество тесно интегрированных между собой модулей, не только распределенное хранилище Data Grid, используя которые разработчики могут решать задачи самой разной степени сложности, от совсем легких (я хочу быстрый распределенный кеш) до очень тяжелых (я хочу распределенные HTAP-вычисления в реальном времени на больших данных, которые хранятся в ЦОД-ах в разных уголках Земли, при этом хотелось бы интегрироваться с Cassandra, Spark, Hadoop и т.д.).
К сожалению, связка компонентов для одной из самых «горячих» областей современного IT — машинного обучения — отсутствовала в Apache Ignite. До этого момента.
Apache Ignite 2.0 добавляет поддержку базовой алгебры машинного обучения, адаптированной для распределенных вычислений. Мы понимаем, что пока предлагаем очень низкоуровневые инструменты, и не собираемся останавливаться на этом. В будущих версиях эта базовая алгебра станет основой, на которой мы будем строить распределенные реализации основных алгоритмов машинного обучения: регрессий, деревьев классификации и т.д.
Пока же можно ознакомиться с примерами на GitHub и попробовать пощупать текущий продукт руками.
С этого релиза в Apache Ignite к DML добавляется начальная поддержка DDL. Теперь можно создавать и, что важно, менять индексы, не прерывая работу узлов кластера, используя при этом классический SQL-синтаксис. Это одна из самых долгожданных функций, которую очень просили наши пользователи. И это только начало! В последующих релизах будет появляться все больше DDL-операций, включая CREATE TABLE, ALTER TABLE и т.д. Подробнее о текущих возможностях можно прочитать в документации.
В честь выхода Apache Ignite 2.0 мы планируем провести 2 события:
— вебинар 7 июня, на котором расскажут о новшествах версии 2.0 на английском языке
— Ignition.meetup(), который пройдет в Москве в ближайшее время (будет объявлено отдельно), на нем можно будет обменяться опытом на русском языке, задать вопросы и послушать о реальных кейсах построения решений на платформе
Apache Ignite эластично масштабируется в рамках одного или нескольких геораспределенных кластеров, предоставляя гибко настраиваемое шардирование и автоматическую ребалансировку при динамическом добавлении или удалении узлов, обеспечивая прозрачный и быстрый доступ к данным и вычислениям путем использования собственного API либо классического SQL.
В версии 2.0 были значительно переработаны многие вещи «под капотом», следствием стала возможность реализации ряда значительных функциональных изменений, часть из которых заметна уже сейчас, а часть появится в ближайших версиях.
Забегая вперед, мы будем проводить 2 мероприятия, которые связаны с Apache Ignite, подробнее о них можно прочитать в конце статьи.
Новая архитектура хранения данных
Apache Ignite по умолчанию работает с оперативной памятью, хранит в ней данные в распределенном виде и там же проводит вычисления. Одно из ключевых новшеств версии 2.0 — полностью переработанная архитектура работы с памятью, которая называется Page Memory. И это очень важно.
Новый подход к хранению данных значительно сложнее и продуманнее старого, он позволяет избежать проблем с фрагментацией памяти, значительно ускорить работу с SQL и минимизировать влияние пауз GC на функционирование системы. Более того, новая архитектура позволяет бесшовно работать как с оперативной памятью, так и с диском. В версии 2.0 эта возможность еще отсутствует, но уже в скором времени можно будет узнать о наших планах по развитию в этой области подробнее.
С новой архитектурой можно ознакомиться в общих чертах на рисунке ниже, а также в специальном разделе документации.
Машинное обучение
Целью Apache Ignite является построение платформы, в которую входит множество тесно интегрированных между собой модулей, не только распределенное хранилище Data Grid, используя которые разработчики могут решать задачи самой разной степени сложности, от совсем легких (я хочу быстрый распределенный кеш) до очень тяжелых (я хочу распределенные HTAP-вычисления в реальном времени на больших данных, которые хранятся в ЦОД-ах в разных уголках Земли, при этом хотелось бы интегрироваться с Cassandra, Spark, Hadoop и т.д.).
К сожалению, связка компонентов для одной из самых «горячих» областей современного IT — машинного обучения — отсутствовала в Apache Ignite. До этого момента.
Apache Ignite 2.0 добавляет поддержку базовой алгебры машинного обучения, адаптированной для распределенных вычислений. Мы понимаем, что пока предлагаем очень низкоуровневые инструменты, и не собираемся останавливаться на этом. В будущих версиях эта базовая алгебра станет основой, на которой мы будем строить распределенные реализации основных алгоритмов машинного обучения: регрессий, деревьев классификации и т.д.
Пока же можно ознакомиться с примерами на GitHub и попробовать пощупать текущий продукт руками.
Data Definition Language
С этого релиза в Apache Ignite к DML добавляется начальная поддержка DDL. Теперь можно создавать и, что важно, менять индексы, не прерывая работу узлов кластера, используя при этом классический SQL-синтаксис. Это одна из самых долгожданных функций, которую очень просили наши пользователи. И это только начало! В последующих релизах будет появляться все больше DDL-операций, включая CREATE TABLE, ALTER TABLE и т.д. Подробнее о текущих возможностях можно прочитать в документации.
Также среди изменений
- Ignite.NET: поддержка системы плагинов для Ignite.NET;
- Ignite.C++: удаленный вызов C++-кода на кластере, в этой версии пока только в continuous queries;
- интеграция со Spring Data облегчит внедрение Apache Ignite, позволив легко использовать его с распространенным фреймворком для построения приложений;
- интеграция с RocketMQ;
- поддержка Hibernate 5 L2 кеша;
- и многое другое
Вебинар и Meetup
В честь выхода Apache Ignite 2.0 мы планируем провести 2 события:
— вебинар 7 июня, на котором расскажут о новшествах версии 2.0 на английском языке
— Ignition.meetup(), который пройдет в Москве в ближайшее время (будет объявлено отдельно), на нем можно будет обменяться опытом на русском языке, задать вопросы и послушать о реальных кейсах построения решений на платформе
Поделиться с друзьями

OlegZH
Чрезвычайно интересно! Но вот в чём проблема. Думая над автоматизацией задач машинного обучения (нужной для анализа экспериментальных данных медико-биологических исследований), видимо, рано или поздно, придётся придти к чему-то подобному. Свой вариант делать всё-равно придётся. Но есть уже и готовый!
Можно ли каким-нибудь образом вникнуть в предлагаемый здесь Вами вариант реализации? Имеет ли смысл что-нибудь предлагать, если, в результате понимания реализации и понимания самих методов машинного обучения, появятся идеи, как это можно было (следовало бы) реализовать?
artemshitov
Apache Ignite, кстати, действительно используют для научных исследований, в том числе связанных с медициной и фармацевтикой. Например, технологии Ignite использует E-Therapeutics. Поэтому, да, это один из возможных инструментов, который можно применять в этой отрасли, теперь, когда у нас появляются распределенные алгоритмы машинного обучения, таких применений может быть больше, и они могут становиться более легкими и дешевыми.
Мы планируем в ближайшее время сделать отдельную техническую статью исключительно про машинное обучение в Apache Ignite, думаю, она сможет в структурированном виде ответить на часть вопросов. Также, естественно, можете спросить на какие-то интересующие темы здесь, на Хабре, или, если есть какой-то более плотный интерес, написать в личку, и мы сможем отдельно встретиться и рассказать больше. Мы, естественно, рады мнениям и предложениям, особенно, от людей из отрасли.
OlegZH
Ясно. Мне же было бы крайне соблазнительным, проводя системный анализ предметной области, самому что-нибудь полезное на Хабре написать по этому поводу. Буду следить за Вашими публикациями. Спасибо.
Sibarit
Олег, нам всегда интересны идеи. Напишите Артёму на artem at gridgain.com и он вас познакомит с нужными людьми.