
Носимые устройства сейчас в моде, но используются в основном для фитнеса и спорта. Как найти им другое применение? Что они могут рассказать о нашем здоровье и продолжительности жизни? А главное — как оценивать поступающие с них данные? Руководитель направления mHealth R&D в компании Gero Тимофей Пырков прочитал отличную лекцию, посвящённую локомоторной активности человека.
Под катом — расшифровка и большинство слайдов.
Мой доклад не столько про старение, сколько про общее состояние здоровья вообще. И источником данных о здоровье является информация с трекеров, то есть информация о двигательной активности пользователя, по-английски locomotor.
Наша компания Gero — небольшая. занимаемся разработкой лекарственных препаратов, используя компьютерные программы, а также поиском биомаркеров о состоянии здоровья. И в том числе пытаемся понять, как здоровье человека меняется в зависимости от наличия или отсутствия заболеваний и от старения организма в целом. Публикуем работы в научных журналах, а источник наших данных — это обычно открытые датасеты, содержащие в себе информацию от многих пользователей о геноме в виде транскриптомов, протемов, анализов крови. В том числе нас интересует двигательная активность. Оказалось, что довольно много такой информации известно. Собирается она с помощью акселерометров. Например, с браслетов, которые можно носить на запястье. И есть открытый датасет NHANES, где достаточно много такой информации для десятков тысяч пользователей. Еще сотрудничаем с UK Biobank, в котором такой информации намного больше, уже для сотни тысяч пользователей, но она не находится в открытом доступе.

Что такое двигательная активность? Собирается она очень простым способом. Пользователь носит какой-то девайс, в котором есть акселерометр, он записывает ускорение с какой-то частотой, обычно в несколько герц — 50 или 100. Это может быть просто шагомер. Шагомер обычно пользователю выдает информацию об общей активности — например, сколько шагов в день ты сделал. Но в том числе шагомер записывает ее с большей частотой именно поминутно. То есть выглядит такой трек записи примерно как изображено на середине слайда. Это сэмпл за два дня с одного пользователя. Видно, что есть доминирующий эффект от циркадного ритма. То есть ночью никакой активности нет — пользователь спит. Днем он как-то ходит, когда-то больше, когда-то меньше. Иногда может даже пойти на пробежку.
Что с такой информацией можно делать? Обычно, когда человек покупает фитнес-трекер, например, или ставит себе приложение на телефон для мониторинга фитнеса, оно выдает ему очень простую информацию в виде общего среднего пульса или числа шагов за день. Можно использовать такую информацию. Но кажется, если посмотреть на нее более детально, узнаешь больше о состоянии здоровья или о том, что происходит с организмом. И вообще, data выглядит примерно таким образом. Дальше надо понять, где тут science. Science, наверное, в том, чтобы сравнивать одних пользователей с другими. Пытаться понять, кто старше, кто моложе, кто здоровее, у кого какие-то проблемы со здоровьем. Может быть, надо уже идти к врачу. Вопрос, как сравнить трек, который изображен на слайде. Напрямую не сравнишь среди пользователей, потому что туда замешана большая составляющая индивидуального социального поведения. Кто-то на работу ходит раньше, кто-то позже, у каждого свое расписание. На выходных кто-то предпочитает отлежаться, поспать, кто-то — наоборот, поработать, кто-то — на фитнес пойти. Понятно, что эта информация — не совсем о физиологии, не совсем о состоянии здоровья, а больше о социальном поведении и социальном статусе. Поэтому, естественно, возникает желание получить какой-то дескриптор такой даты, провести feature engineering, который отбросит ненужные для нашего анализа социальные паттерны поведения и оставит существенную информацию о физиологии.
Мы смотрим на такие треки, и первое, что мы подмечаем, — временные ряды. Они похожи по своему поведению на стохастический процесс. Естественно, возникает желание посмотреть в учебник, посмотреть, как описываются такие процессы.
Самый простой пример — марковский процесс, и он точно описывается набором переходов из состояния в состояние. Поэтому мы берем такие треки со всех пользователей, разбиваем их на разные состояния. В нашем случае это очень простая процедура: просто по количеству шагов каждую минуту мы бьем весь трек на состояния с низкой, средней, высокой и очень высокой активностью. Дальше, проходясь по треку, подсчитываем вероятность перейти из одного в другое. Таким образом получаем фичу, дескриптор, описывающий каждого пользователя, индивидуальную локомоторную подпись, отпечаток пальца. Выглядит он как матрица наборов переходов состояний: из низких в высокие и наоборот. Здесь приведена картинка интенсивности переходов для одного человека.
Получили такой дескриптор. Что можно из него узнать о физиологии? Вот наша цель. Самые большие физиологические изменения, связанные с возрастными изменениями.

Поэтому мы в первую очередь хотим увидеть, как такое довольно грубое описание позволяет узнать что-то о физиологии.
Про возрастные изменения в двигательной активности можно посмотреть в литературе. Там известны довольно простые вещи, известны давно. Это, например, падение полной активности, это видно по уровню. В том числе можно посмотреть на спектр такого временного ряда. Здесь приведены средние спектры для условно молодой и старой группы — 35 и 45 лет соответственно. То есть это люди в расцвете сил. И — уже пожилые, 70-80, синие и зеленые. Видно, что в целом спектральная мощность понижается при старении человека.
Есть еще одна известная и довольно интересная вещь, которую нельзя просто получить, смотря на цифру. Сколько шагов ты проходишь каждый день — это скореллированность поведенческих мотивов во времени. Это именно та фича, которую можно получить из анализа intraday Data, то есть поминутное количество шагов каждую минуту. Я не буду останавливаться на этом подробнее, но вкратце скажу, что наш дескриптор позволяет узнать из локомоторной активности и такие фичи тоже.
Поэтому мы считаем, что у нас достаточно хорошее усреднение сигнала происходит с помощью такого подхода, с помощью такого feature engineering. Мы высредняем из дескриптора все ненужные фичи, касающиеся социальных особенностей, которые могли бы нам помешать, и при этом оставляем всю существенную информацию о физиологии.
Дальше, получается, мы дату собрали, предобработали, получили какие-то дескрипторы, и хотим теперь что-то узнать о состоянии здоровья. Для этого существует, грубо говоря, две группы методов: supervised и unsupervised. Supervised — обучение моделей с контролем. То есть у вас обычно есть какая-то метка — например, возраст, диагнозы — и вы пытаетесь построить модель именно под нее. А unsupervised-методы позволяют что-то узнать о структуре данных. В нашем сигнале хорошо то, что это просто акселерометр — достаточно дешевый способ собирать данные. Такие данные можно собирать даже с помощью смартфонов, и они есть для большого количества людей. В итоге получаем датасет, где количество семплов достаточно большое. Здесь становится возможным применять unsupervised-методы, то есть не заставлять модель подстраиваться под какой-то диагноз, а просто посмотреть, как устроены данные.
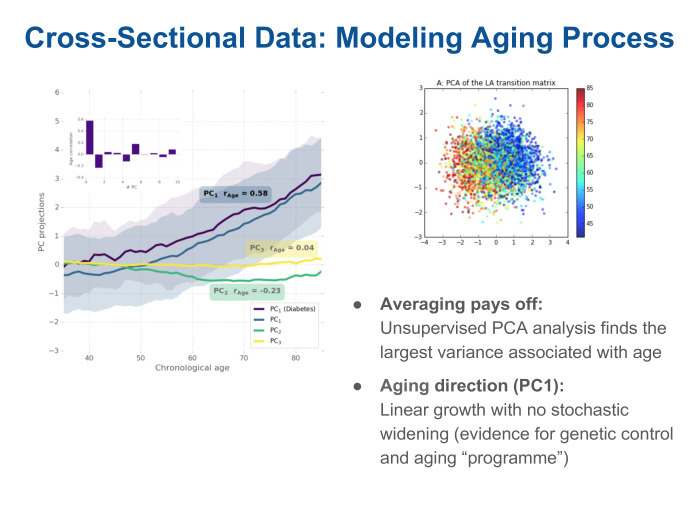
Мы применяем анализ главных компонент — самый очевидный способ закластеризовать данные, посмотреть, что в них содержится. И видим на графике слева, что есть несколько компонент — они ранжированы по степени того, насколько они описывают вариабельность данных. Самая большая вариация связана с возрастом. Проекция на эту компоненту проплачена в зависимости от возраста пациентов. Видно, что она линейно растет с возрастом. И это единственное направление, которое коррелирует с возрастом. Фактически мы, обратившись к такому сигналу, получили версию биологического возраста с обычного трекера, записывающего число шагов.
Что мы можем делать дальше. Поскольку это биовозраст, он довольно шумный, но тем не менее позволяет отранжировать пользователей по, допустим, возрастной когорте. Для чего он может пригодиться? Например — чтобы предсказывать влияние каких-то состояний здоровья или диагнозов на продолжительность жизни.
И в этой связи возникает вопрос: как оценить его точность? Мы получили модельку, описыающую старение. Может как-то дать поправку на то, что больной человек — более старый, или наоборот, занимается фитнесом, ведет здоровый образ жизни и кажется моложе своих лет? Вопрос, какая точность у каждой модели? Смотрим на оценку точности ранжирования времен дожития: такие данные собираются параллельно с медицинскими опросниками, их часто сопровождает follow up, где за каждым пациентом проводится наблюдение в течение нескольких ближайших лет, обычно 5-10. Часто в таких датасетах есть информация о том, что пациент жив, с ним все хорошо. Или, наоборот — прошло столько-то лет, и он скончался от болезни или от старости.
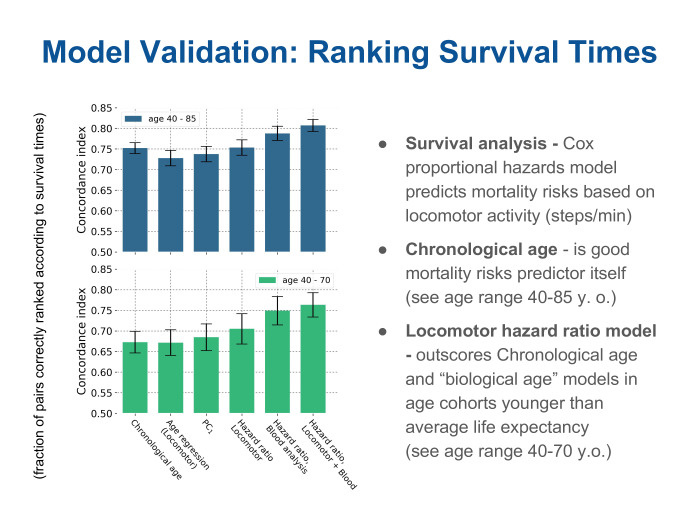
Мы можем посмотреть, насколько точно разные метрики ранжируют пациентов по времени дожития. И видим здесь, что для двух возрастных когорт приведены такие метрики точности. Они называются сoncordance index и говорят о том, какая доля пар была отранжирована правильно.
Видим, что первый столбик — настоящий возраст пациента, хронологический возраст. Он представляет собой довольно высокую метрику, его значение достаточно высокое по сравнению со всеми остальными методами. Следующие два столбика — разные модели для возраста. Один из них — supervised-метод: с помощью регрессии мы пытались построить возраст. Другой — проекция на главную компоненту, которую мы нашли unsupervised-способом. Эту проекция мы обозвали просто биовозрастом. И видим довольно забавную картину. Действительно, в плане ранжирования по временам дожития эти две модели биовозраста примерно так же, если угодно, хороши или плохи, как если просто посмотреть на паспортный возраст пациента и сделать очевидный вывод — чем ты моложе, тем больше вероятность того, что ты проживешь еще дольше, и наоборот. Но следующие три столбика справа — разные модели, такие специальные, не для биовозраста, а модели предсказания рисков смертности. По-английски hazards model — модель рисков, угроз, опасности, но на самом деле речь идет именно о предсказании рисков смертности, или вероятности того, что каждый пациент умрет в течение какого-то ближайшего времени. Мы видим, что модели, построенные на дескрипторе, получаемом просто с локомоторного сенсора, позволяют в когорте людей до средней продолжительности жизни… Смотрим нижний рисунок. Видно, что три зеленых столбика справа — разные модели. Одна — просто на локомоторном дескрипторе, а две другие с подключением дополнительных параметров — таких, как анализ крови, — позволяют существенно улучшить качество предсказания, качество оценки. Это особенно хорошо для людей, которые еще моложе средней продолжительности жизни. Но эффект становится не таким заметным на верхнем графике, где есть все пациенты, в том числе и очень старые. Значит, границы применимости есть и на сегодняшний день хронологический возраст достаточно точно говорит нам: если ты уже очень старый человек, то способов как-то продлить себе жизнь — мало.
Но на самом деле, вся эта история довольно интересна с точки зрения анализа здоровья в популяции. Другими словами, риски смертности имеют вероятностную природу. Поэтому для каждого конкретного пользователя шагомера такая информация вряд ли будет очень интересна и даже вряд ли полезна. Кто, действительно, будет в районе 40 или даже 70 лет сильно задумываться о том, как повлиять на свою продолжительность жизни — скоро ли я постарею, скоро ли я умру? Поэтому хочется понять, какую еще информацию, более актуальную для пользователя, можно извлечь.
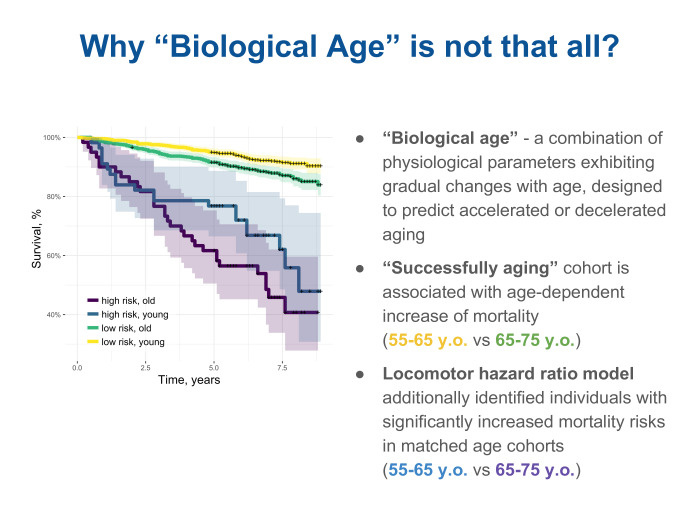
Здесь нам приходит на помощь анализ мета-даты и попытка разобраться, почему наша модель дает какое-то улучшение по сравнению с простой оценкой по возрасту, сравнить, посмотреть, в чем на самом деле разница, что такого локомоторный дескриптор, дескриптор о двигательной активности, может рассказать о состоянии здоровья, о физиологии организма — кроме оценки, что такой-то старше, а такой-то моложе. Мы взяли две возрастные группы и дополнительно посмотрели в каждой из них когорту, ранжированную по оценке рисков смертности по нашим дескрипторам, разделив их таким образом на старую и молодую. Это желтый и зеленый сверху. Но желтый и зеленый — так называемые успешно стареющие люди, successfully aging, есть такой термин в англоязычной литературе. И проплатили (нрзб. — прим. ред.) для них кривые дожития. Чем выше кривая, тем больше на каждое время follow up остается живых пациентов. Видим, что среди успешно стареющих людей потихоньку нарастает вероятность смерти. Другими словами, кривая дожития постепенно снижается от желтой для более молодых к зеленой. Но при этом модель, построенная по локомоторному дескриптору, позволяет также выделить когорту с повышенными рисками по ее оценке. И мы смотрим на такие кривые дожития и видим, что они существенно ниже и в них не так хорошо прослеживается зависимость от возраста. Это синий для молодых и высокий риск, и фиолетовые для чуть более старых, тоже с высоким риском. Отсюда мы понимаем, что есть какие-то характеристики физиологии, которые можно узнать, не отправляя человека в больницу, не беря у него каких-то анализов крови или генома, а просто наблюдая за тем, как он двигается, через сенсор в браслете или, может быть, даже в телефоне.
Хочется понять, какой же эффект видит локомоторный трек.
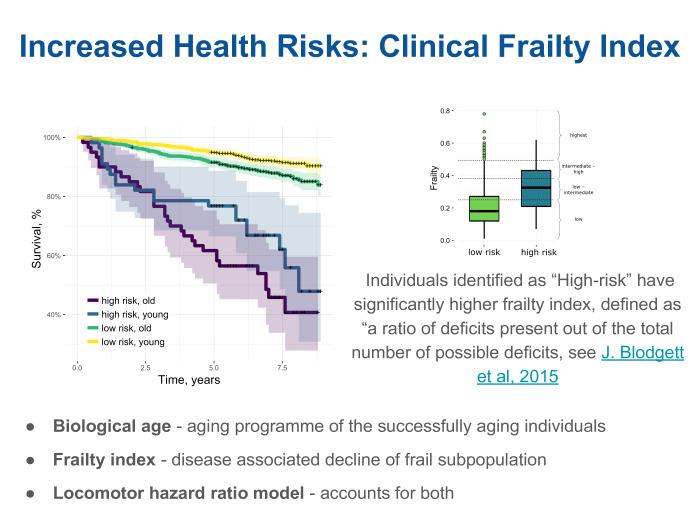
Мы посмотрели и выяснили, что в клинике часто используется индекс немощности — frailty index. Очень простая вещь. Существует список известных хронических заболеваний. Их, например, сотня, и каждый пациент может у доктора на анализе через опросник заполнить список. Доктор скажет, что у пациента из этого списка наблюдается 15 заболеваний, а у другого 30, а у третьего 50. И frailty index — доля заболеваний, наблюдаемых из списка. Оказалось, что, действительно, наша модель, построенная по локомоторной активности человека, довольно хорошо в каждой возрастной когорте коррелирует с этим индексом. Фактически, оказывается, что есть две независимых компоненты. Одна показывает, насколько в среднем организмы стареют. Можно замерить этот эффект через локомоторную активность. Но есть и другая компонента, которая оценивает общее состояние здоровья независимо от возраста. Мы эти две компоненты называем биовозрастом и frailty и видим, что наш довольно простой подход уже способен учитывать оба перечисленных эффекта.
Все-таки остается вопрос, что для каждого человека персонально?

Про старение, может быть, не очень интересно, но мы можем вспомнить, что на самом деле стареют все, стареют медленно. Действительно, эффект от старения будет виден через много-много лет. Но есть какие-то параметры здоровья, а на самом деле даже и того, какой образ жизни ведет каждый человек. Они, может быть, не столь заметны здесь и сейчас, но неизбежно и неумолимо приведут к каким-то серьезным последствиям для здоровья через много лет.
Самый известный, самый большой эффект на продолжительность жизни оказывают два стиля жизни. Один из них — курение, второй — диабет. Диабет — не совсем стиль жизни, но часто это диабет второго типа, очень сильно связанный с ожирением. Поэтому условно мы можем его называть связанным с lifestyle. Мы смотрим на датасеты, с которыми работаем. Видим, что, действительно, есть такая информация в метадате. Видим, что наша модель может популярно отскорить популяцию некурильщиков. На верхнем графике она обозначена светлым. Она против курильщиков, для них она предсказывает повышенные риски, повышенное hazard ratio. Более того, она может предсказывать в некотором смысле в дозозависимой степени. То есть видно, что темным цветом показаны так называемые heavy smokers — те, которые выкуривают больше пачки в день. А те, у кого меньше пачки в день, находятся в промежуточном положении между некурящими и курильщиками.
Модель наша была построена на датасете NHANES, зеленым слева. Для диабета — то же самое. У диабетиков этот лайфстайл, повышенный hazard, тоже сенсится.
Очень хорошо было получить доступ к другим датасетам. То есть мы построили модель на одном датасете. NHANES — американский датасет, National Health And Nutrition Examination. Другими словами, там есть данные по крови, по локомоторике, и достаточно большое количество опросников, заполняемых в клинике. Мы посмотрели на другой датасет. Это английский датасет UK Biobank. В нем тоже есть локомоторные данные, тоже есть кровь, генетика и метаданные из медицинских опросников. И мы были очень рады увидеть, что без каких-либо дополнительных изменений, без тюнинга и без претрейнинга модель довольно легко переносима на другой датасет. Показательно здесь то, что в одном датасете был один девайс, а в другом другой. В NHANES это был одноосевой акселерометр, который носится на поясе, примерно как рация у меня здесь. А в UK Biobank это был совершенно другой девайс — трехосевой акселерометр, который пациенты носят на запястье как фитнес-трекер. И мы видим, что все трекеры одинаковые, и если мы окажемся в состоянии какую-то информацию извлекать из модели на датасете, то у нас будут хорошие шансы просто взять и перенести на кейсы из реальной жизни.
Это все, опять же, больше приближено к индивидуальной истории. Здесь есть лайфстайлы и ты в состоянии применить какую-то интервенцию с помощью лайфстайла, узнав, например,, что курение или ожирение сказывается на здоровье и продолжительности жизни. Можно бросить курить, пойти на фитнес. Но именно историю локомоторный дескриптор по-прежнему не позволяет точно предсказать, по крайней мере с такой картинки. Да, мы видим, что группы разделяются, но по-прежнему с большим перекрытием, ведь мы действительно оцениваем риски для общего здоровья, а не конкретно у человека с ожирением. Этот курит, этот ходит на фитнес, много спит и вообще молодец.

История становится более персональной, если мы посмотрим в литературу. Мы увидим, что желтым цветом на верхнем графике показаны кривые выживания в течение всей жизни для некурящих, фиолетовым — для курильщиков, а также для тех, кто курил, но бросил до 35 или 45 лет. Видим — и это известный факт, — что у тех, кто бросил курить в относительно молодом возрасте, эффект от такого нездорового образа жизни обратимый.
Внизу на картинке — результат наших расчетов, наших предсказаний. Мы видим, что never smokers — слева светлым — по-прежнему имеют самые низкие оценки риска смертности по модели на локомоторном дескрипторе. А у тех, кто курит в настоящее время, оценки самые высокие. Это я показывал на предыдущем слайде, и здесь все согласуется. Но одновремено мы видим, что часть пациентов, которые зарепортили, что раньше курили, но бросили, действительно имеют более здоровое состояние организма даже просто по локомоторному дескриптору. Другими словами, риски у них в среднем по популярности находятся между некурильщиками и курильщиками. Таким образом, эта история становится более приближенной к конечному пользователю.

Почему курение, почему ожирение? На самом деле не потому, что нам интересно заниматься только ими, а потому что это образы жизни, для которых очень хорошо изучен эффект, оказываемый на состояние здоровья, на продолжительность жизни. Он известен и он достаточно велик. Он составляет, если смотреть на продолжительность жизни по популярности, до 10 лет. Это много. Про здоровье даже говорить нечего. Но на самом деле мы можем взять датасет NHANES — там довольно много информации. Я привел график о том, какие еще группы диагнозов, анализов или параметров стиля или образа жизни могут в принципе коррелировать с оценкой рисков из шагомера. Здесь, на графике, они проплачены, это так называемый volcano plot. По горизонтали — wellness score. На самом деле речь идет о том же самом hazard ratio, но с отрицательным знаком, потому что мы хотим всю историю давать в виде фидбека консьюмерам, пользователям девайсов, шагомеров и смартфонов, и не очень хотим сразу пугать. Ту же самую информацию мы им хотим преподнести в более user friendly-виде. Берем и просто проходимся по всем полям метаданных, делим пользователей на группы, смотрим, насколько велика разница в популярности с одной меткой и с другой, и насколько они значимы, оцениваем по p-value. Видим, что, действительно, у нас довольно большой список, включающий в себя вещи, связанные с лайфстайлом, употреблением алкоголя, курением, нарушением сна, физической активностью, даже связанные с occupation — родом занятости. Потом — медицинские анализы: биохимия, где много параметров оказались связанными с локомоторным дескриптором; body composition — в основном это состояние опорно-двигательного аппарата и скелета; анализы dietary, связанные с питанием, и также связанная с ним body weight — масса тела, диабет. Если захотеть, можно найти много параметров, которые будут коррелировать с тем, как ты двигаешься и как твое движение может засенсить обычный фитнес-трекер, используемый не для подсчета шагов или километров, которые ты пробежал, а для оценки состояния здоровья в целом.
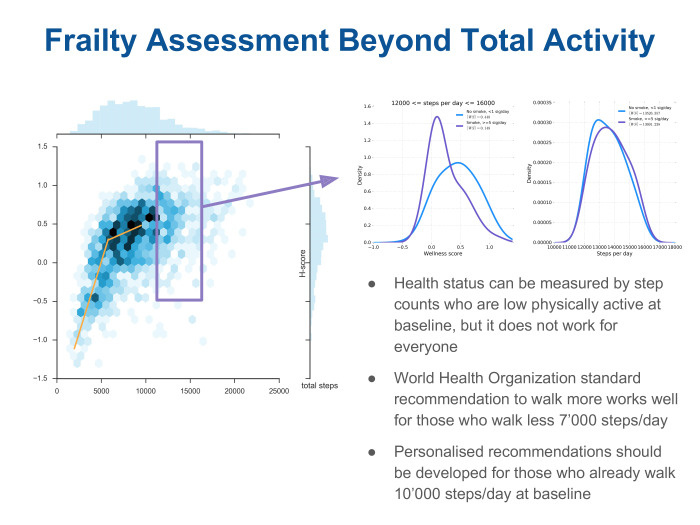
На самом деле, число шагов в день, которое обычно показывают фитнес-приложения или фитнес-трекеры, — она не то чтобы совсем не связана со здоровьем. График показывает scatter plot пациентов в координатах количества шагов в день, среднее за неделю, — против оценки риска смертности. Здесь он показан с другим знаком. Другими словами, перед нами то, что мы называем wellness score уже для пользователей. И видим, что для тех, кто ходит очень мало, примерно до 7 тыс. шагов в день, количество пройденных шагов уже является очень неплохим показателем состояния здоровья. Корреляция между риском, который оценивается по модели, и количеством шагов — очень хорошая. Но все меняется для тех людей, которые ходят. Обычно если покупаешь такой фитнес-трекер, не каждый же день занимаешься фитнесом. Но он все равно должен какую-то информацию показывать. Он дает общую рекомендацию: «Ходи больше, будешь здоровее». Это оказывается не совсем так для тех, кто уже ходит много — от 12 до 16 тыс. шагов в день. Для них видно, что на правовой гистограмме мы уже не можем разделить курильщиков от некурильщиков по количеству шагов. А вот по локомоторному дескриптору, который мы используем на средней гистограмме, они по-прежнему разделяются. Иначе говоря, такой подход позволяет более точно оценить физиологию организма.
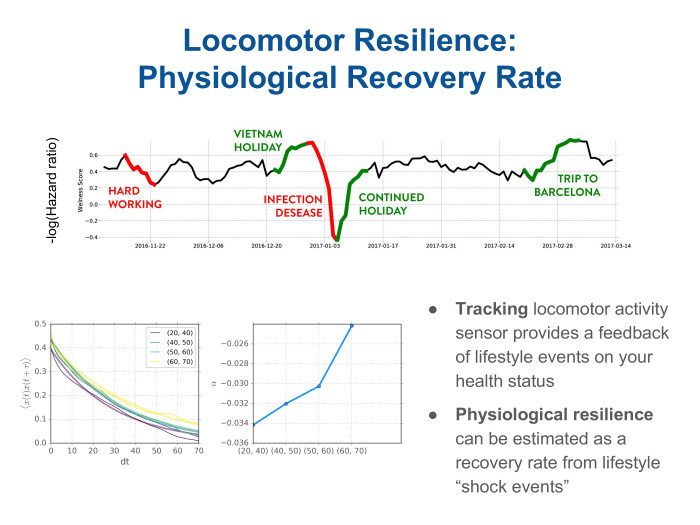
Как это может выглядеть для пользователя? Мы попросили одного из наших сотрудников попробовать проассоциировать изменения в его треке, который он записывал в течение нескольких месяцев, с какими-то событиями в жизни. И действительно, видим, что это неслучайные изменения. Здесь красным и зеленым подсвечены тренды в изменениях его wellness score, определенные алгоритмы. Они действительно ассоциируются с какими-то событиями. Понижение — это обычно усталость или болезнь. Повышается он, когда человек едет в отпуск.

У меня довольно академическая презентация, но на самом деле мы очень рассчитываем сделать приложение для пользователей девайсов. И у нас уже есть пилотное приложение, которое работает с трекерами Fitbit. Оно позволяет залогиниться, подписаться, чтобы получить оценку компонентов BIH и Wellness score, frailty-компоненту. К приложению будет прикручен API для других трекеров. Пока мы работаем только с Fitbit, то есть можно будет своими силами попробовать загрузить, не автоматически. И мы рассчитываем, что через месяц-другой оно уже будет доступно для iPhone, чтобы можно было использовать трек с шагомеров в телефоне.
У меня всё, спасибо.
Под катом — расшифровка и большинство слайдов.
Мой доклад не столько про старение, сколько про общее состояние здоровья вообще. И источником данных о здоровье является информация с трекеров, то есть информация о двигательной активности пользователя, по-английски locomotor.
Наша компания Gero — небольшая. занимаемся разработкой лекарственных препаратов, используя компьютерные программы, а также поиском биомаркеров о состоянии здоровья. И в том числе пытаемся понять, как здоровье человека меняется в зависимости от наличия или отсутствия заболеваний и от старения организма в целом. Публикуем работы в научных журналах, а источник наших данных — это обычно открытые датасеты, содержащие в себе информацию от многих пользователей о геноме в виде транскриптомов, протемов, анализов крови. В том числе нас интересует двигательная активность. Оказалось, что довольно много такой информации известно. Собирается она с помощью акселерометров. Например, с браслетов, которые можно носить на запястье. И есть открытый датасет NHANES, где достаточно много такой информации для десятков тысяч пользователей. Еще сотрудничаем с UK Biobank, в котором такой информации намного больше, уже для сотни тысяч пользователей, но она не находится в открытом доступе.
Что такое двигательная активность? Собирается она очень простым способом. Пользователь носит какой-то девайс, в котором есть акселерометр, он записывает ускорение с какой-то частотой, обычно в несколько герц — 50 или 100. Это может быть просто шагомер. Шагомер обычно пользователю выдает информацию об общей активности — например, сколько шагов в день ты сделал. Но в том числе шагомер записывает ее с большей частотой именно поминутно. То есть выглядит такой трек записи примерно как изображено на середине слайда. Это сэмпл за два дня с одного пользователя. Видно, что есть доминирующий эффект от циркадного ритма. То есть ночью никакой активности нет — пользователь спит. Днем он как-то ходит, когда-то больше, когда-то меньше. Иногда может даже пойти на пробежку.
Что с такой информацией можно делать? Обычно, когда человек покупает фитнес-трекер, например, или ставит себе приложение на телефон для мониторинга фитнеса, оно выдает ему очень простую информацию в виде общего среднего пульса или числа шагов за день. Можно использовать такую информацию. Но кажется, если посмотреть на нее более детально, узнаешь больше о состоянии здоровья или о том, что происходит с организмом. И вообще, data выглядит примерно таким образом. Дальше надо понять, где тут science. Science, наверное, в том, чтобы сравнивать одних пользователей с другими. Пытаться понять, кто старше, кто моложе, кто здоровее, у кого какие-то проблемы со здоровьем. Может быть, надо уже идти к врачу. Вопрос, как сравнить трек, который изображен на слайде. Напрямую не сравнишь среди пользователей, потому что туда замешана большая составляющая индивидуального социального поведения. Кто-то на работу ходит раньше, кто-то позже, у каждого свое расписание. На выходных кто-то предпочитает отлежаться, поспать, кто-то — наоборот, поработать, кто-то — на фитнес пойти. Понятно, что эта информация — не совсем о физиологии, не совсем о состоянии здоровья, а больше о социальном поведении и социальном статусе. Поэтому, естественно, возникает желание получить какой-то дескриптор такой даты, провести feature engineering, который отбросит ненужные для нашего анализа социальные паттерны поведения и оставит существенную информацию о физиологии.
Мы смотрим на такие треки, и первое, что мы подмечаем, — временные ряды. Они похожи по своему поведению на стохастический процесс. Естественно, возникает желание посмотреть в учебник, посмотреть, как описываются такие процессы.
Самый простой пример — марковский процесс, и он точно описывается набором переходов из состояния в состояние. Поэтому мы берем такие треки со всех пользователей, разбиваем их на разные состояния. В нашем случае это очень простая процедура: просто по количеству шагов каждую минуту мы бьем весь трек на состояния с низкой, средней, высокой и очень высокой активностью. Дальше, проходясь по треку, подсчитываем вероятность перейти из одного в другое. Таким образом получаем фичу, дескриптор, описывающий каждого пользователя, индивидуальную локомоторную подпись, отпечаток пальца. Выглядит он как матрица наборов переходов состояний: из низких в высокие и наоборот. Здесь приведена картинка интенсивности переходов для одного человека.
Получили такой дескриптор. Что можно из него узнать о физиологии? Вот наша цель. Самые большие физиологические изменения, связанные с возрастными изменениями.
Поэтому мы в первую очередь хотим увидеть, как такое довольно грубое описание позволяет узнать что-то о физиологии.
Про возрастные изменения в двигательной активности можно посмотреть в литературе. Там известны довольно простые вещи, известны давно. Это, например, падение полной активности, это видно по уровню. В том числе можно посмотреть на спектр такого временного ряда. Здесь приведены средние спектры для условно молодой и старой группы — 35 и 45 лет соответственно. То есть это люди в расцвете сил. И — уже пожилые, 70-80, синие и зеленые. Видно, что в целом спектральная мощность понижается при старении человека.
Есть еще одна известная и довольно интересная вещь, которую нельзя просто получить, смотря на цифру. Сколько шагов ты проходишь каждый день — это скореллированность поведенческих мотивов во времени. Это именно та фича, которую можно получить из анализа intraday Data, то есть поминутное количество шагов каждую минуту. Я не буду останавливаться на этом подробнее, но вкратце скажу, что наш дескриптор позволяет узнать из локомоторной активности и такие фичи тоже.
Поэтому мы считаем, что у нас достаточно хорошее усреднение сигнала происходит с помощью такого подхода, с помощью такого feature engineering. Мы высредняем из дескриптора все ненужные фичи, касающиеся социальных особенностей, которые могли бы нам помешать, и при этом оставляем всю существенную информацию о физиологии.
Дальше, получается, мы дату собрали, предобработали, получили какие-то дескрипторы, и хотим теперь что-то узнать о состоянии здоровья. Для этого существует, грубо говоря, две группы методов: supervised и unsupervised. Supervised — обучение моделей с контролем. То есть у вас обычно есть какая-то метка — например, возраст, диагнозы — и вы пытаетесь построить модель именно под нее. А unsupervised-методы позволяют что-то узнать о структуре данных. В нашем сигнале хорошо то, что это просто акселерометр — достаточно дешевый способ собирать данные. Такие данные можно собирать даже с помощью смартфонов, и они есть для большого количества людей. В итоге получаем датасет, где количество семплов достаточно большое. Здесь становится возможным применять unsupervised-методы, то есть не заставлять модель подстраиваться под какой-то диагноз, а просто посмотреть, как устроены данные.
Мы применяем анализ главных компонент — самый очевидный способ закластеризовать данные, посмотреть, что в них содержится. И видим на графике слева, что есть несколько компонент — они ранжированы по степени того, насколько они описывают вариабельность данных. Самая большая вариация связана с возрастом. Проекция на эту компоненту проплачена в зависимости от возраста пациентов. Видно, что она линейно растет с возрастом. И это единственное направление, которое коррелирует с возрастом. Фактически мы, обратившись к такому сигналу, получили версию биологического возраста с обычного трекера, записывающего число шагов.
Что мы можем делать дальше. Поскольку это биовозраст, он довольно шумный, но тем не менее позволяет отранжировать пользователей по, допустим, возрастной когорте. Для чего он может пригодиться? Например — чтобы предсказывать влияние каких-то состояний здоровья или диагнозов на продолжительность жизни.
И в этой связи возникает вопрос: как оценить его точность? Мы получили модельку, описыающую старение. Может как-то дать поправку на то, что больной человек — более старый, или наоборот, занимается фитнесом, ведет здоровый образ жизни и кажется моложе своих лет? Вопрос, какая точность у каждой модели? Смотрим на оценку точности ранжирования времен дожития: такие данные собираются параллельно с медицинскими опросниками, их часто сопровождает follow up, где за каждым пациентом проводится наблюдение в течение нескольких ближайших лет, обычно 5-10. Часто в таких датасетах есть информация о том, что пациент жив, с ним все хорошо. Или, наоборот — прошло столько-то лет, и он скончался от болезни или от старости.
Мы можем посмотреть, насколько точно разные метрики ранжируют пациентов по времени дожития. И видим здесь, что для двух возрастных когорт приведены такие метрики точности. Они называются сoncordance index и говорят о том, какая доля пар была отранжирована правильно.
Видим, что первый столбик — настоящий возраст пациента, хронологический возраст. Он представляет собой довольно высокую метрику, его значение достаточно высокое по сравнению со всеми остальными методами. Следующие два столбика — разные модели для возраста. Один из них — supervised-метод: с помощью регрессии мы пытались построить возраст. Другой — проекция на главную компоненту, которую мы нашли unsupervised-способом. Эту проекция мы обозвали просто биовозрастом. И видим довольно забавную картину. Действительно, в плане ранжирования по временам дожития эти две модели биовозраста примерно так же, если угодно, хороши или плохи, как если просто посмотреть на паспортный возраст пациента и сделать очевидный вывод — чем ты моложе, тем больше вероятность того, что ты проживешь еще дольше, и наоборот. Но следующие три столбика справа — разные модели, такие специальные, не для биовозраста, а модели предсказания рисков смертности. По-английски hazards model — модель рисков, угроз, опасности, но на самом деле речь идет именно о предсказании рисков смертности, или вероятности того, что каждый пациент умрет в течение какого-то ближайшего времени. Мы видим, что модели, построенные на дескрипторе, получаемом просто с локомоторного сенсора, позволяют в когорте людей до средней продолжительности жизни… Смотрим нижний рисунок. Видно, что три зеленых столбика справа — разные модели. Одна — просто на локомоторном дескрипторе, а две другие с подключением дополнительных параметров — таких, как анализ крови, — позволяют существенно улучшить качество предсказания, качество оценки. Это особенно хорошо для людей, которые еще моложе средней продолжительности жизни. Но эффект становится не таким заметным на верхнем графике, где есть все пациенты, в том числе и очень старые. Значит, границы применимости есть и на сегодняшний день хронологический возраст достаточно точно говорит нам: если ты уже очень старый человек, то способов как-то продлить себе жизнь — мало.
Но на самом деле, вся эта история довольно интересна с точки зрения анализа здоровья в популяции. Другими словами, риски смертности имеют вероятностную природу. Поэтому для каждого конкретного пользователя шагомера такая информация вряд ли будет очень интересна и даже вряд ли полезна. Кто, действительно, будет в районе 40 или даже 70 лет сильно задумываться о том, как повлиять на свою продолжительность жизни — скоро ли я постарею, скоро ли я умру? Поэтому хочется понять, какую еще информацию, более актуальную для пользователя, можно извлечь.
Здесь нам приходит на помощь анализ мета-даты и попытка разобраться, почему наша модель дает какое-то улучшение по сравнению с простой оценкой по возрасту, сравнить, посмотреть, в чем на самом деле разница, что такого локомоторный дескриптор, дескриптор о двигательной активности, может рассказать о состоянии здоровья, о физиологии организма — кроме оценки, что такой-то старше, а такой-то моложе. Мы взяли две возрастные группы и дополнительно посмотрели в каждой из них когорту, ранжированную по оценке рисков смертности по нашим дескрипторам, разделив их таким образом на старую и молодую. Это желтый и зеленый сверху. Но желтый и зеленый — так называемые успешно стареющие люди, successfully aging, есть такой термин в англоязычной литературе. И проплатили (нрзб. — прим. ред.) для них кривые дожития. Чем выше кривая, тем больше на каждое время follow up остается живых пациентов. Видим, что среди успешно стареющих людей потихоньку нарастает вероятность смерти. Другими словами, кривая дожития постепенно снижается от желтой для более молодых к зеленой. Но при этом модель, построенная по локомоторному дескриптору, позволяет также выделить когорту с повышенными рисками по ее оценке. И мы смотрим на такие кривые дожития и видим, что они существенно ниже и в них не так хорошо прослеживается зависимость от возраста. Это синий для молодых и высокий риск, и фиолетовые для чуть более старых, тоже с высоким риском. Отсюда мы понимаем, что есть какие-то характеристики физиологии, которые можно узнать, не отправляя человека в больницу, не беря у него каких-то анализов крови или генома, а просто наблюдая за тем, как он двигается, через сенсор в браслете или, может быть, даже в телефоне.
Хочется понять, какой же эффект видит локомоторный трек.
Мы посмотрели и выяснили, что в клинике часто используется индекс немощности — frailty index. Очень простая вещь. Существует список известных хронических заболеваний. Их, например, сотня, и каждый пациент может у доктора на анализе через опросник заполнить список. Доктор скажет, что у пациента из этого списка наблюдается 15 заболеваний, а у другого 30, а у третьего 50. И frailty index — доля заболеваний, наблюдаемых из списка. Оказалось, что, действительно, наша модель, построенная по локомоторной активности человека, довольно хорошо в каждой возрастной когорте коррелирует с этим индексом. Фактически, оказывается, что есть две независимых компоненты. Одна показывает, насколько в среднем организмы стареют. Можно замерить этот эффект через локомоторную активность. Но есть и другая компонента, которая оценивает общее состояние здоровья независимо от возраста. Мы эти две компоненты называем биовозрастом и frailty и видим, что наш довольно простой подход уже способен учитывать оба перечисленных эффекта.
Все-таки остается вопрос, что для каждого человека персонально?
Про старение, может быть, не очень интересно, но мы можем вспомнить, что на самом деле стареют все, стареют медленно. Действительно, эффект от старения будет виден через много-много лет. Но есть какие-то параметры здоровья, а на самом деле даже и того, какой образ жизни ведет каждый человек. Они, может быть, не столь заметны здесь и сейчас, но неизбежно и неумолимо приведут к каким-то серьезным последствиям для здоровья через много лет.
Самый известный, самый большой эффект на продолжительность жизни оказывают два стиля жизни. Один из них — курение, второй — диабет. Диабет — не совсем стиль жизни, но часто это диабет второго типа, очень сильно связанный с ожирением. Поэтому условно мы можем его называть связанным с lifestyle. Мы смотрим на датасеты, с которыми работаем. Видим, что, действительно, есть такая информация в метадате. Видим, что наша модель может популярно отскорить популяцию некурильщиков. На верхнем графике она обозначена светлым. Она против курильщиков, для них она предсказывает повышенные риски, повышенное hazard ratio. Более того, она может предсказывать в некотором смысле в дозозависимой степени. То есть видно, что темным цветом показаны так называемые heavy smokers — те, которые выкуривают больше пачки в день. А те, у кого меньше пачки в день, находятся в промежуточном положении между некурящими и курильщиками.
Модель наша была построена на датасете NHANES, зеленым слева. Для диабета — то же самое. У диабетиков этот лайфстайл, повышенный hazard, тоже сенсится.
Очень хорошо было получить доступ к другим датасетам. То есть мы построили модель на одном датасете. NHANES — американский датасет, National Health And Nutrition Examination. Другими словами, там есть данные по крови, по локомоторике, и достаточно большое количество опросников, заполняемых в клинике. Мы посмотрели на другой датасет. Это английский датасет UK Biobank. В нем тоже есть локомоторные данные, тоже есть кровь, генетика и метаданные из медицинских опросников. И мы были очень рады увидеть, что без каких-либо дополнительных изменений, без тюнинга и без претрейнинга модель довольно легко переносима на другой датасет. Показательно здесь то, что в одном датасете был один девайс, а в другом другой. В NHANES это был одноосевой акселерометр, который носится на поясе, примерно как рация у меня здесь. А в UK Biobank это был совершенно другой девайс — трехосевой акселерометр, который пациенты носят на запястье как фитнес-трекер. И мы видим, что все трекеры одинаковые, и если мы окажемся в состоянии какую-то информацию извлекать из модели на датасете, то у нас будут хорошие шансы просто взять и перенести на кейсы из реальной жизни.
Это все, опять же, больше приближено к индивидуальной истории. Здесь есть лайфстайлы и ты в состоянии применить какую-то интервенцию с помощью лайфстайла, узнав, например,, что курение или ожирение сказывается на здоровье и продолжительности жизни. Можно бросить курить, пойти на фитнес. Но именно историю локомоторный дескриптор по-прежнему не позволяет точно предсказать, по крайней мере с такой картинки. Да, мы видим, что группы разделяются, но по-прежнему с большим перекрытием, ведь мы действительно оцениваем риски для общего здоровья, а не конкретно у человека с ожирением. Этот курит, этот ходит на фитнес, много спит и вообще молодец.
История становится более персональной, если мы посмотрим в литературу. Мы увидим, что желтым цветом на верхнем графике показаны кривые выживания в течение всей жизни для некурящих, фиолетовым — для курильщиков, а также для тех, кто курил, но бросил до 35 или 45 лет. Видим — и это известный факт, — что у тех, кто бросил курить в относительно молодом возрасте, эффект от такого нездорового образа жизни обратимый.
Внизу на картинке — результат наших расчетов, наших предсказаний. Мы видим, что never smokers — слева светлым — по-прежнему имеют самые низкие оценки риска смертности по модели на локомоторном дескрипторе. А у тех, кто курит в настоящее время, оценки самые высокие. Это я показывал на предыдущем слайде, и здесь все согласуется. Но одновремено мы видим, что часть пациентов, которые зарепортили, что раньше курили, но бросили, действительно имеют более здоровое состояние организма даже просто по локомоторному дескриптору. Другими словами, риски у них в среднем по популярности находятся между некурильщиками и курильщиками. Таким образом, эта история становится более приближенной к конечному пользователю.
Почему курение, почему ожирение? На самом деле не потому, что нам интересно заниматься только ими, а потому что это образы жизни, для которых очень хорошо изучен эффект, оказываемый на состояние здоровья, на продолжительность жизни. Он известен и он достаточно велик. Он составляет, если смотреть на продолжительность жизни по популярности, до 10 лет. Это много. Про здоровье даже говорить нечего. Но на самом деле мы можем взять датасет NHANES — там довольно много информации. Я привел график о том, какие еще группы диагнозов, анализов или параметров стиля или образа жизни могут в принципе коррелировать с оценкой рисков из шагомера. Здесь, на графике, они проплачены, это так называемый volcano plot. По горизонтали — wellness score. На самом деле речь идет о том же самом hazard ratio, но с отрицательным знаком, потому что мы хотим всю историю давать в виде фидбека консьюмерам, пользователям девайсов, шагомеров и смартфонов, и не очень хотим сразу пугать. Ту же самую информацию мы им хотим преподнести в более user friendly-виде. Берем и просто проходимся по всем полям метаданных, делим пользователей на группы, смотрим, насколько велика разница в популярности с одной меткой и с другой, и насколько они значимы, оцениваем по p-value. Видим, что, действительно, у нас довольно большой список, включающий в себя вещи, связанные с лайфстайлом, употреблением алкоголя, курением, нарушением сна, физической активностью, даже связанные с occupation — родом занятости. Потом — медицинские анализы: биохимия, где много параметров оказались связанными с локомоторным дескриптором; body composition — в основном это состояние опорно-двигательного аппарата и скелета; анализы dietary, связанные с питанием, и также связанная с ним body weight — масса тела, диабет. Если захотеть, можно найти много параметров, которые будут коррелировать с тем, как ты двигаешься и как твое движение может засенсить обычный фитнес-трекер, используемый не для подсчета шагов или километров, которые ты пробежал, а для оценки состояния здоровья в целом.
На самом деле, число шагов в день, которое обычно показывают фитнес-приложения или фитнес-трекеры, — она не то чтобы совсем не связана со здоровьем. График показывает scatter plot пациентов в координатах количества шагов в день, среднее за неделю, — против оценки риска смертности. Здесь он показан с другим знаком. Другими словами, перед нами то, что мы называем wellness score уже для пользователей. И видим, что для тех, кто ходит очень мало, примерно до 7 тыс. шагов в день, количество пройденных шагов уже является очень неплохим показателем состояния здоровья. Корреляция между риском, который оценивается по модели, и количеством шагов — очень хорошая. Но все меняется для тех людей, которые ходят. Обычно если покупаешь такой фитнес-трекер, не каждый же день занимаешься фитнесом. Но он все равно должен какую-то информацию показывать. Он дает общую рекомендацию: «Ходи больше, будешь здоровее». Это оказывается не совсем так для тех, кто уже ходит много — от 12 до 16 тыс. шагов в день. Для них видно, что на правовой гистограмме мы уже не можем разделить курильщиков от некурильщиков по количеству шагов. А вот по локомоторному дескриптору, который мы используем на средней гистограмме, они по-прежнему разделяются. Иначе говоря, такой подход позволяет более точно оценить физиологию организма.
Как это может выглядеть для пользователя? Мы попросили одного из наших сотрудников попробовать проассоциировать изменения в его треке, который он записывал в течение нескольких месяцев, с какими-то событиями в жизни. И действительно, видим, что это неслучайные изменения. Здесь красным и зеленым подсвечены тренды в изменениях его wellness score, определенные алгоритмы. Они действительно ассоциируются с какими-то событиями. Понижение — это обычно усталость или болезнь. Повышается он, когда человек едет в отпуск.
У меня довольно академическая презентация, но на самом деле мы очень рассчитываем сделать приложение для пользователей девайсов. И у нас уже есть пилотное приложение, которое работает с трекерами Fitbit. Оно позволяет залогиниться, подписаться, чтобы получить оценку компонентов BIH и Wellness score, frailty-компоненту. К приложению будет прикручен API для других трекеров. Пока мы работаем только с Fitbit, то есть можно будет своими силами попробовать загрузить, не автоматически. И мы рассчитываем, что через месяц-другой оно уже будет доступно для iPhone, чтобы можно было использовать трек с шагомеров в телефоне.
У меня всё, спасибо.
Поделиться с друзьями
Комментарии (5)

Zibx
11.06.2017 22:12Может лучше часы на электронных чернилах с недельным временем жизни? Ресурс у вас есть и на рынке после продажи pebble освободилась как раз такая ниша.

kloppspb
12.06.2017 01:19+1Что с такой информацией можно делать?
Отличный вопрос! Расшифровать ЭКГ в динамике за полгода — единицы врачей могут. Да и те увольняются, либо по
старости, либо из-за зарплаты.
А ипохондрикам трекеры впаривать — другая тема, OK :)

pro_co_ru
12.06.2017 11:54+1Интересно, что будет с людьми у которых нестандартное поведение, например, человек молод и здоров, но по этой аналитике попадёт в группу риска? Так можно и до кондрашки довести :)
AslanKurbanov
Такой бы трекер-браслет заиметь, который к фазам сна, активности и др. учитывал еще время работы на компьютере или планшете.
Можно, наверное, както определить, что ты печатаешь или мышкой водишь или както электронно. И тогда страховые компании сумели бы оценить и роль компьютеров в продолжительности жизни. Такого нашествия электронных устройств не было за всю историю человечества, и кто знает влияют ли они меньше курения и алкоголя.