
Всем привет! Хочу поделиться своим переводом интересной статьи Reducing our Redux code with React Apollo автора Peggy Rayzis. Статья о том, как автор и её команда внедряли технологию GraphQL в их проект. Перевод публикуется с разрешения автора.
Переключаемся на декларативный подход в Высшей Футбольной Лиге
Я твёрдо убеждена, что лучший код — это отсутствие кода. Чем больше кода, тем больше вероятности для появления багов и тем больше тратится времени на поддержку такого кода. В Высшей Футбольной Лиге у нас совсем небольшая команда, поэтому мы принимаем этот принцип близко к сердцу. Мы стараемся оптимизировать всё, что нам по силам, либо путём увеличения переиспользуемости кода, либо просто перестав обслуживать определённую часть кода.
В данной статье вы узнаете о том, как мы передали контроль над получением данных в Apollo, что позволило нам избавиться от почти 5,000 строчек кода. К тому же, после перехода на Apollo наше приложение стало не только намного меньше по объёму, оно также стало более декларативным, поскольку теперь наши компоненты запрашивают только те данные, которые им нужны.
Что я подразумеваю под декларативным и почему это так здорово? Декларативное программирование фокусируется на конечной цели, в то время как императивное программирование сосредоточено на шагах, которые требуются для её достижения. React же сам по себе декларативный.
Получение данных с помощью Redux
Давайте взглянем на простой компонент Article:
Предположим, мы хотим отрендерить <Article/> в подключённом <MatchDetail/> представлении, который получает ID матча в качестве props. Если бы мы выполняли это без GraphQL клиента, наш процесс получения данных, необходимых для рендеринга <Article/> мог бы быть таким:
- Когда
<MatchDetail/>монтируется, вызываем action creator для получения данных матча по ID. Action creator диспатчит action, чтобы сообщить Redux о начале процесса получения данных. - Мы достигли точки назначения и возвращаемся с данными назад. Мы нормализуем данные в удобную нам структуру.
- После того, как данные нормализованы, мы диспатчим ещё один action, чтобы сообщить Redux о завершении процесса получения данных.
- Redux обрабатывает action в нашем reducer и обновляет state приложения.
<MatchDetail/>получает все необходимые данные матча через props и отфильтровывает их для рендеринга статьи.
Так много шагов, чтобы просто получить данные для <Article/>! Без клиента GraphQL наш код становится намного более императивным, поскольку нам приходится концентрироваться на том, как мы получаем данные. Но что, если мы не хотим передавать все данные матча для простого рендеринга <Article/>? Вы могли бы построить другой endpoint и создать отдельный набор action creators для получения от него данных, но такой вариант очень легко может стать неподдерживаемым.
Давайте сравним, как бы мы могли сделать то же самое с помощью GraphQL:
<MatchDetail/>подключён к компоненту высшего порядка, который выполняет следующий запрос:
query Article($id: Float!) {
match(id: $id) {
article {
title
body
}
}
}… и это всё! Как только клиент получает данные, он передаёт их в props, которые могут быть далее переданы в <Article/>. Это намного более декларативно, поскольку мы фокусируемся только на том, какие данные нам нужны для рендеринга компонента.
В этом вся прелесть делегирования получения данных GraphQL клиенту, будь то Relay или Apollo. Когда вы начнёте "думать в концепциях GraphQL", вы станете заботиться только о том, в каких props нуждается компонент для рендеринга, вместо того, чтобы беспокоиться о том, как получить эти данные.
В какой то момент вам придётся подумать об этом "как", но это уже забота серверной части, и, соответственно, сложность для front-end резко снижается. Если вы новичок в серверной архитектуре GraphQL, то попробуйте graphql-tools, библиотеку Apollo, которая поможет вам более модульно структурировать вашу схему. Для краткости мы сегодня остановимся только на front-end части.
И хотя этот пост о том, как сократить использование вашего Redux кода, вы не избавитесь от него полностью! Apollo использует Redux под капотом, поэтому вы всё ещё сможете извлекать выгоду из иммутабельности и все клёвые возможности Redux Dev Tools, типа time-travel debugging, так же будут работать. Во время конфигурирования вы можете подключить Apollo к существующему store в Redux, чтобы поддерживать единый "источник правды". Как только ваш store сконфигурирован, вы передаёте его в <ApolloProvider/> компонент, который оборачивает всё ваше приложение. Звучит знакомо? Этот компонент является полной заменой вашего существующего <Provider/> из Redux, за исключением того, что вам потребуется передать ему экземпляр ApolloClient через свойство client.
Прежде, чем мы начнём резать наш Redux код, я бы хотела назвать одну из лучших фукнциональных особенностей GraphQL: поэтапная настройка (incremental adoption). Вам не обязательно совершать рефакторинг всего приложения сразу. После интеграции Apollo с вашим существующим Redux store, вы можете переключаться с ваших reducers постепенно. То же самое применимо и к серверной части — если вы работаете над большим масштабным приложением, вы можете использовать GraphQL бок о бок с вашим текущим REST API, до того момента, пока вы не будете готовы для полного перехода. Справедливое предупреждение: как только вы попробуете GraphQL, вы можете влюбиться в эту технологию и захотить переделать всё ваше приложение.
Наши требования
Перед переходом от Redux к Apollo, мы тщательно подумали о том, отвечает ли Apollo нашим потребностям. Вот на что мы обратили внимание перед тем, как принять решение:
- Агрегирование данных из множественных источников: Матч состоит из данных, получаемых из 4-х различных источников: контент — из нашего REST API, статистика — из нашей MySQL базы данных, медиа-данные — из нашего video API и социальные данные — из нашего Redis хранилища. Первоначально, мы использовали серверный плагин для сбора всех данных в один объект матча перед отправкой на клиент. Надо сказать, он функционирует почти также, как GraphQL! Когда мы поняли это, то стало очевидным, что GraphQL станет идеальным кандидатом для нашего приложения.
- Оперативные обновления, близкие к реальному времени: Во время матча в прямом эфире мы обычно получаем обновления каждую минуту. До Apollo мы обрабатывали обновления с помощью сокетов и диспатчили их в наш reducer матча. Это не было самым ужасным решением, но также и не было самым элегантным, поскольку мы отправляли весь объект матча, чтобы избежать сложных последовательностей. С Apollo же мы запросто можем кастомизировать интервал поллинга (polling) для каждого компонента в зависимости от статуса игры.
- Простая пагинация: Поскольку мы создавали страницу расписания с бесконечной прокруткой списка матчей, то нам нужна была соответствующая обработка подобного рода пагинации без лишней головной боли. Разумеется, мы могли бы создать отдельный собственный reducer. Но зачем писать его самим, когда в Apollo есть функция
fetchMore, которая проделывает за нас всю тяжёлую работу?
Надо сказать, что Apollo удовлетворял не только всем нашим текущим требованиям, он также охватывал и некоторые наши будущие потребности, особенно учитывая то, что в наш roadmap включена расширенная персонализация. И хотя наш сервер в настоящее время доступен "только для чтения", нам в будущем может потребоваться ввести мутации (mutations) для сохранения пользователями их любимых команд. На случай, если мы решим добавить комментирование в режиме реального времени или взаимодействия с фанатами, которые не могут быть решены с помощью поллинга (polling), то в Apollo есть поддержка подписок (subscriptions).
От Redux к Apollo
Момент, которого все ждали! Изначально, когда я только задумалась о написании этой статьи, я собиралась лишь привести примеры кода до и после, но я думаю, что было бы трудно сравнивать вот так напрямую эти два подхода, особенно для новичков в Apollo. Вместо этого я собираюсь подсчитать количество удалённого кода в целом и провести вас через знакомые вам концепции Redux, которые вы сможете применить при создании контейнерных компонентов с помощью Apollo.
Что мы удалили
- reducers матчей (~300 строчек кода)
- action creators & epics, отвечающие за получение данных (~800 строчек кода)
- action creators и бизнес логику, отвечающие за группировку и получение обновлений прямого эфира матчей через сокет (~750 строчек кода)
- actions creators & epics, отвечающие за local storage (~1000 строчек кода). На самом деле, не совсем справедливо включать в общий список этот пункт, так как offline поддержка пока что отложена в нашем проекте, но если мы захотим добавить её снова, то это вполне достижимо с помощью кастомизации функции
fetchPolicyиз Apollo и использованияredux-persistв reducer. - Контейнерные компоненты Redux, которые отделяли логику Redux от презентационных компонентов (~1000 строчек кода)
- Тесты, связанные со всем вышеперечисленным (~1000 строчек кода)
connect() > graphql()
Если вы умеете пользоваться connect, тогда компонент высшего порядка graphql из Apollo вам покажется очень знакомым! Точно так же, как connect возвращает функцию, которая принимает компонент и подключает его к вашему Redux store, также и graphql возвращает функцию, которая принимает компонент и "подключает" его к клиенту Apollo. Давайте посмотрим на это в действии!
Первый аргумент, переданный в graphql это MatchSummaryQuery. Это данные, которые мы хотим получить от сервера. Мы используем загрузчик Webpack для парсинга нашего запроса в GraphQL AST, но если вы не используете Webpack, то вам нужно обернуть ваш запрос в шаблонные строки (template string) и передать его в функцию gql, экспортированную из Apollo. Вот пример запроса на получение данных, необходимых для нашего компонента:
Отлично, у нас есть запрос! Чтобы корректно его выполнить, нам нужно передать в него две переменные $id и $season. Но откуда мы возьмём эти переменные? Вот здесь то и вступает в игру второй аргумент функции graphql, представленный в виде объекта конфигурации.
Этот объект имеет несколько свойств, которые вы может указать для настройки поведения компонента высшего порядка (HOC). Одно из самых важных свойств — это options, принимающее функцию, которая получает props вашего контейнера. Эта функция возвращает объект со свойствами типа variables, что позволяет вам передавать ваши переменные в запрос, и pollInterval, который позволяет настраивать поведение поллинга (polling) у компонента. Обратите внимание, как мы используем props нашего контейнера для передачи id и season в наш MatchSummaryQuery. Если эта функция становится слишком длинной, чтобы писать её прямо в декораторе, то мы разбиваем её на отдельную функцию под названием mapPropsToOptions.
mapStateToProps() > mapResultsToProps()
Наверняка вы использовали функцию mapStateToProps в ваших Redux контейнерах, передавая эту функцию в connect для передачи данных из state приложения в props данного контейнера. Apollo позволяет вам определять похожую функцию. Помните конфигурационный объект, который ранее мы передавали в функцию graphql? У этого объекта есть ещё одно свойство — props, которое принимает функцию, получающую на вход props и обрабатывающую их перед передачей в контейнер. Вы, конечно, можете определить её прямо в graphql, но нам нравится определять её как отдельную функцию mapResultsToProps.
Зачем вам переопределять ваши props? Результат запроса GraphQL всегда присваивается к свойству data. Иногда вам может потребоваться подкорректировать эти данные перед тем, как отправить их в компонент. Вот один из примеров:
Теперь объект с данными содержит не только результат запроса, но также и свойства типа data.loading, чтобы дать вам знать, что запрос ещё не возвратил ответ. Это может быть полезным, если в подобной ситуации вы хотите отобразить другой компонент вашим пользователям, как мы сделали это с <NoDataSummary/>.
compose()
Compose это функция, использующаяся не только в Redux, но я всё же хочу обратить ваше внимание, что Apollo содержит её. Она очень удобна, если вы хотите скомпоновать несколько graphql функций для использования в одном контейнере. В ней вы даже можете использвать функцию connect из Redux вместе с graphql! Вот как мы используем compose для отображения различных состояний матча:
compose отлично помогает, когда ваш контейнер содержит множественные состояния. Но что, если вам нужно выполнять отдельный запрос только в зависимости от его состояния? Здесь нам поможет skip, который вы можете увидеть в конфигурационном объекте выше. Свойство skip принимает функцию, которая получает props и позволяет вам пропустить выполнение запроса, если он не соответствует необходимым критериям.
Все эти примеры демонстрируют, что если вы знаете Redux, то вы быстро вольётесь в разработку на Apollo! Его API вобрало в себя многое из концепций Redux, при этом уменьшая количество кода, которое вам нужно написать для достижения такого же результата.
Я надеюсь, что опыт перехода Высшей Футбольной Лиги на Apollo поможет вам! Как и в случае с любыми решениями относительно различных библиотек, лучшее решение по контролю над получением данных в вашем приложении будет зависеть от конкретных требований вашего проекта. Если у вас есть какие-либо вопросы касательно нашего опыта, пожалуйста, оставляйте комментарии здесь или стучитесь ко мне в Twitter!
Спасибо за прочтение!
Комментарии (103)

vintage
17.06.2017 05:52+3все клёвые возможности Redux Dev Tools, типа time-travel debugging
Интересно, кто-то реально использует эту клёвую возможность? Как-то у меня сомнения по поводу полезности этой игрушки.

plag
17.06.2017 09:04Я активно пользуюсь. При написании кода и дебаге в первую очередь! Также подключили к ravenjs проброс стора в эксепшен, чтобы получать в центре ошибок пользовательское состояние, и через redux dev tools можно удобно загрузить для воспроизведения ошибки, но пока возможностью загрузки не пользовался.

amakhrov
17.06.2017 19:50+1Если все, что приложение делает, — это запрос и отображение данных с бэкенда, то dev tools вряд ли пригодится.
Когда добавляется более-менее сложная логика на клиент — тут уже помогает.
Конкретный пример:
Пишу работу с графом, юзер может драг-н-дропом добавлять вершину, и вершина автоматически по определенным правилам присоединяется к графу. Можно также удалить вершину — тогда оставшиеся вершины соединяются между собой новыми ребрами, чтобы граф всегда оставался связным.
В какой-то момент в процессе тестирования у меня появляется дублирующееся ребро, которого быть не должно. К этому моменту я уже много покликал по графу, добавлял, удалял — воспроизвести проблему с нуля было бы проблематично.
А с открытым Redux Dev Tools я прокликал по истории состояний, нашел первый шаг, который привел к проблеме. Там же из Dev Tools скопировал текущее состояние (json), вставил практически как есть в юнит-тест и затем починил.vintage
18.06.2017 04:27+1Боюсь юнит-тест получился не очень поддерживаемый — какой-то дамп стора, к которому не понятно как пришли.
Да, для поиска неуловимого бага иногда полезно, когда баг виден невооружённым глазом, а не приходится глазами анализировать огромные json-ы в поисках чего-то подозрительного.
amakhrov
18.06.2017 07:59Да нормальный вышел тест. Я потом из дампа выкинул несущественные детали.
А насчет "непонятно как пришли" — так это и не надо. Надо, чтоб переход от этого к состояния к новому правильно происходил.
vintage
18.06.2017 08:44+1Проблема таких тестов, где "не важно как пришли", как раз в том, что со временем некоторые состояния могут стать недостижимыми ввиду изменения требований, и тесты фактически будут тестировать сферическое изменение состояния в вакууме, не имеющее к требованиям никакого отношения.
VolCh
18.06.2017 10:31Это не проблема в целом, если следовать TDD-подходам. Изменение требований должно приводить к падению тестов. Например, если мы исключаем из графа состояний какой-то переход из одного состояния в другое, то тест на этот переход должен упасть лишь потому, что его нет в графе.
vintage
18.06.2017 17:47Состояния сами по себе могут быть достижимы, а их комбинация — нет.
VolCh
19.06.2017 13:11Не очень понимаю о чём речь — пример можно?
vintage
19.06.2017 13:35Допустим у нас список задач.
Раньше задача могла быть в 3 приоритетах (высокий, средний, низкий) и запланирована на 3 промежутка времени (сегодня, на этой неделе, когда-нибудь).
По новым требованиям, задача, назначенная на сегодня, приобретает высокий приоритет.
Получается состояние "низкоприоритетная задача назначенная на сегодня" не достижимо.VolCh
21.06.2017 11:19При реализации этого требования юнит-тест назначения низкоприоритетной задачи на сегодня должен упасть, равно как и тест назначения сегодняшней задачи низкого приоритета. Если таких юнит-тестов не было (назначение приоритета и даты разные методы и ранее никаких требований по связи приоритета и даты не было, поэтому в связке они не тестировались), то такие тесты должны быть созданы в рамках реализации нового требования. Если не созданы, или созданы лишь частично (проверяется что приоритет меняется на высокий при установке сегодняшней даты, но не проверяются попытки изменить приоритет у сегодняшней даты), то должна упасть метрика покрытия кода тестами.
vintage
21.06.2017 12:17Вы забыли с чего всё начиналось? Напомню: у нас есть какое-то состояние стора, применяем к нему какую-то трансформацию, получаем новое состояние. Достижимость исходного состояния мы не проверяем — никакие тесты не упадут, покрытие не пострадает. Единственное, что тут может помочь — формальные контракты с правильно описанными инвариантами. Но в мире JS до этого ещё не доросли.
amakhrov
18.06.2017 08:08+1иногда полезно, когда баг виден невооружённым глазом
Во, интересная мысль!
В моем случае проблема как раз и была из-за того, что баг невооруженным глазом не виден. Визуализация графа еще в разработке. И неправильное ребро было не видно — поверх него были отрисованы другие ребра (правильные). Ошибка проявилась только при попытке сохранения — бэкенд ругался.
Если бы баг был виден сразу невооруженным глазом, то, в принципе, и так было бы понятно как его воспроизвести, без тайм тревела.
vintage
18.06.2017 08:47-2Тогда ручной анализ кучи json-ов сопоставим по сложности с поиском сценария воспроизведения, которое, кстати, можно переложить на менее дорогостоящий персонал.
vintage
17.06.2017 05:57+4store в Redux, чтобы поддерживать единый "источник правды"
Единый источник истины — база данных на сервере. Всё остальное (и redux store в частности) — не более чем, промежуточные кеши на пути к голове пользователя.

napa3um
17.06.2017 08:46+4Выбирая границы рассматриваемой подсистемы можно и в ней определить относительную точку истины. На фронте точкой истинности будет Store (хотя в границах всей клиент-серверной инфосистемы такой точкой будет БД, конечно). Вообще, точка истинности с точки зрения архитектуры совпадает с M[odel] (из MVVM / MVC / Flux / etc.).
vintage
17.06.2017 10:01Ну, если мы вольны сами устанавливать границы, то точкой истины является вообще любая точка :-)
napa3um
17.06.2017 10:09+1Конечно вольны, главное, чтобы выбор был целесообразным в конкретной решаемой задаче (задаче на фронте или бэке, например, или при анализе полной архитектуры). Программисту фронта, пишущему компонент «КарточкаТовара», можно назначить точкой истинности входные параметры конструктора, например, об остальных потоках данных ему думать не обязательно. Разработчик БД в своих задачах может выбрать точкой истинности конкретную таблицу с историей событий, например, а другие таблицы использовать для хранения [де]нормализованных данных, следуемых из истории. Divide et impera.

farwayer
17.06.2017 22:11… до тех пор, пока мы не начинаем разрабатывать offline-first приложения, где локальные данные настолько же важны, как и данные на сервере.
VolCh
18.06.2017 10:52+1Состояние UI на клиенте в базе на сервере, как правило не хранится, по многим причинам. Да и кроме пути из базы к пользователю, есть и обратный путь. И уж на нём каждое нажатие клавиши пользователем записывать в базу не просто накладно, но и небезопасно.
Если у каждого уровня/слоя/модуля/компонента приложения есть свой единый источник правды, то ему безразлично хранятся они в базе на сервере или существуют только в оперативке клиента.
vintage
18.06.2017 17:53-1Так свой или единый, определитесь уж :-)
Я к чему веду: у каждого состояния должен быть единственный источник истины, но он вовсе не обязан быть (да и не может быть по куче причин) единым для всех состояний.
VolCh
19.06.2017 13:15"Свой" значит, что модуль приложения знает об источнике. "Единый" означает, что у модуля один и только один источник.
vintage
19.06.2017 13:37-1Вы для каждого модуля свой redux-store создаёте или что?
VolCh
21.06.2017 11:21+1Грубо — по обстоятельствам. Вводить в общий стор данные, которые нужны одному и только одному модулю в общем случае считаю нецелесообразным. Ну и я не о конкретно Redux.
pawlo16
21.06.2017 14:15Я пробовал так делать в elm — для некоторых модулей собственный изолированный стэйт + изолированные сообщения. В некоторых случаях имхо такой подход оправдан — когда стэйт действительно независимый и им легко управлять. Но в redux без контроля целостности проверок типов-сумм это совершенно невозможно сопровождать
vintage
21.06.2017 19:11-1Модули — это синглтоны. У синглтонов есть большая беда с переиспользуемостью.
pawlo16
21.06.2017 22:59В js — да. Модуль в Elm — это тип модели + функция view (из модели в vdom) + функция update ("редьюсер") + опционально тип сообщения, если модель "мутабельная". На практике всем этим управлять и повторно использовать — можно, при чём без боли.
vintage
22.06.2017 05:21+1Эм… Вывернутый кишками наружу объект? :-)
pawlo16
22.06.2017 10:24-1не, объектов в Elm нет, а кишки можно и открыть, но лучше спрятать. Идея в следующем. Модуль предоставляет :
- тип своего состояния
Stateбез пользовательских конструкторов (прячем кишки) - для инициализации состояния — функцию
init - для настройки
State— типConfig, в котором есть полеtoMsg, определющее, какое сообщение модуль отправляет вверх по иерархии для изменения своего состояния view— функция изStateв виртуальный html соотв.
вот пример использования нормально разработанного модуля
В корне репозитория автор раскрывает концепцию, которую я пытался Вам объяснить)
Пойнт в том, что в гуманном ЯП в redux архитектуре можно создавать реюзабельные модули. Для этого от языка требуется совсем не много :
- иммутабельность
- алгебраические типы данных
В js и ts — соответственно нельзя.
vintage
22.06.2017 10:45Штука, хранящая состояние и функции для работы является "объектом" по определению. Хоть "модулем" вы её назовите, хоть "монадой".
В ts есть и поддержка иммутабельности и алгебраических типов данных.
pawlo16
22.06.2017 11:34-1Монад в Elm нет, и состояние хранится вовсе не в модуле, а в глубинах рантайма, и меняется в соответствии с редакс-архитектурой исключительно из "редьюсеров" :-)
ts есть и поддержка иммутабельности
ага, и выглядит это вот так:
const xs = [1,2,3,4,5]; var ys = xs; ys[1] = 12; console.log(xs[1]===12); // true
и это я ещё молчу про персистентные структуры данных :-)
и алгебраических типов данных.
имхо недостаточная. Лично я вижу много проблем с таким кодом (вы нет?):
export interface State { x: number; xs: string[]; } type Action = { type: 'ACT1' } | { type: 'ACT2' , a: number } | { type: 'ACT3' , b: string } ; function reducer (state: State, action : Action) : State { switch (action.type) { case 'ACT1': return {...state, foo : ""} ; case 'ACT2': return { ...state, bar: undefined }; } };vintage
22.06.2017 20:28Монад в Elm нет, и состояние хранится вовсе не в модуле, а в глубинах рантайма
Оно всегда хранится чёрт-знает где. От прикладного программиста это место скрыто за кучей абстракций.
выглядит это вот так:
const xs = Object.freeze([1, 2, 3, 4, 5]); var ys = xs; ys[1] = 12; // Index signature in type 'ReadonlyArray<number>' only permits reading.
и это я ещё молчу про персистентные структуры данных :-)
А с ними что?
Лично я вижу много проблем с таким кодом
Вы про которые проблемы?
pawlo16
22.06.2017 21:33"Object.freeze" — ок, спасибо за науку) ts развивается быстрее, чем я успеваю за ним следить.
"А с ними что?" — насколько мне известно связные списки и b-tree в ts не подвезли ещё
"Вы про которые проблемы?" — я про то, что компилятор не проверяет наличие всех вариантов сопоставления, а Object.assign позволяет задавать левые проперти. А поскольку в redux тип-сумма сообщения, изменяющего состояние, состоит из дофигища вариантов и они постоянно меняются в процессе разработки — рефакторинг такого кода в ts ужас, а в elm всё хорошо
vintage
22.06.2017 22:01+1насколько мне известно связные списки и b-tree в ts не подвезли ещё
И какая там особая поддержка нужна для них со стороны языка?
я про то, что компилятор не проверяет наличие всех вариантов сопоставления, а Object.assign позволяет задавать левые проперти.
Я не очень понял в чём проблема.
А поскольку в redux тип-сумма сообщения, изменяющего состояние, состоит из дофигища вариантов и они постоянно меняются в процессе разработки — рефакторинг такого кода в ts ужас
Может проблема собственно в редуксе, для которого приходится так извращаться, вместо того, чтобы написать просто:
export class MyStore extends Store { x: number; xs: string[]; ACT1() { this.foo = "" } ACT2(){ this.bar = undefined } }
mayorovp
23.06.2017 08:47На самом деле на Typescript это выглядит вот так:
const xs : ReadonlyArray<number> = [1, 2, 3, 4, 5]; var ys = xs; ys[1] = 12; // Index signature in type 'ReadonlyArray<number>' only permits reading.
А
Object.freeze— это механизм для javascript.vintage
23.06.2017 21:23Зачем вы противопоставляете TS его подмножеству?
mayorovp
23.06.2017 21:27Потому что костыли, придуманные для того подмножества, не являются обязательными в языке со статической типизхацией и развитой системой типов.
vintage
23.06.2017 22:00Статическая типизация не исключает возможность динамического приведения типов. Дополнительная гарантия со стороны рантайма — вовсе не лишняя.
- тип своего состояния
vintage
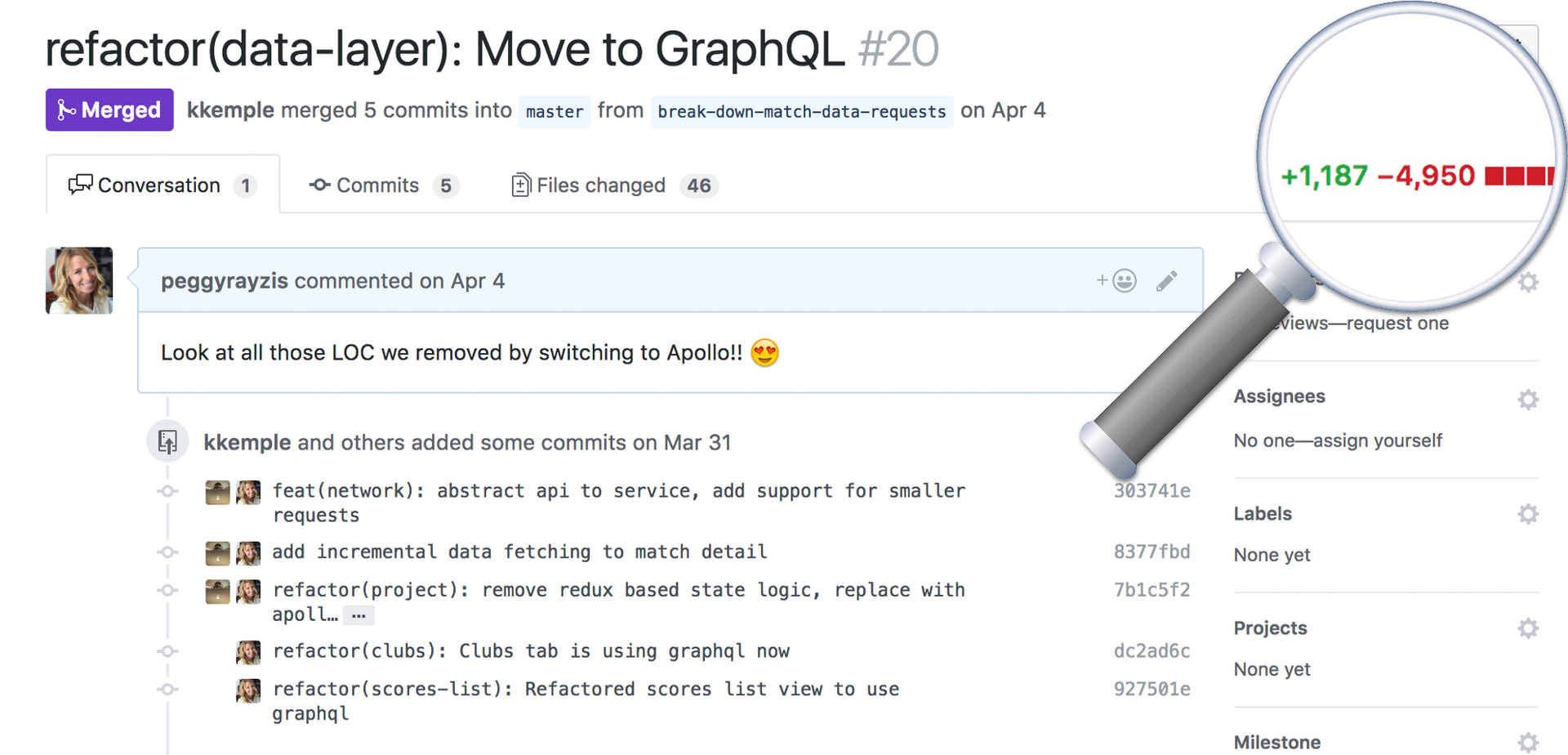
17.06.2017 06:05+9как мы передали контроль над получением данных в Apollo, что позволило нам избавиться от почти 5,000 строчек кода.
Интересно, а когда они говнокодили эти 5000 строчек, им не приходило в голову, что что-то с их инструментарием не так? Ведь можно писать куда меньше кода и без жёсткой завязки на конкретный протокол (GraphQL), если не молиться на React+FLUX.

kmmbvnr
17.06.2017 19:58+1Смысл Redux'а положить данные в единственный store, чтоб потом их можно было легко раскидать по любым компонентам по всему приложению
Если все данные загружаются только в один компонент, там можно просто делать fetch на componentDidMount
SPAHI4
17.06.2017 22:08+1Данные итак хранятся в redux, через graphql они лишь запрашиваются в первый раз, а потом это работает ка
connect от redux.
SPAHI4
17.06.2017 20:10Apollo крут, спору нет. Но существует огромное количество таких же удобных оберток над http api, а не над graphql.
Так что дело не в redux, а в вашем коде.
VolCh
18.06.2017 10:45+2Лично я не пришёл к однозначному выводу, есть ли смысл вводить ApolloProvider (и прочие подобные провайдеры) в иерархию React-компонентов. Как-то очень сильно получается зависит UI от транспортного протокола, перестаёт компонент быть функцией лишь от состояния приложения, оно перестаёт быть единым источником правды, состояние (в широком смысле слова) компонента становится зависимым и от основного стора, и от данных, пришедших с сервера.
Для независимых компонентов а-ля виджеты с внешних источников — вполне годно. А вот для компонентов, зависимых от высших уровней — сомнительно. Пока придерживаюсь подхода, по которому все данные компонента он либо получает самостоятельно, либо из стора (напрямую или через свойства от вышележащих компонентов — нюансы). Варианты типа "получаем из стора id матча и делаем в компоненте запрос на сервер, чтобы получить его данные" стараюсь исключать, реализуя получение на уровне стора, к нему компонент обращается за данными, а уж стор решает делает запрос на сервер, извлечь из кэша или вернуть заглушку.

comerc
18.06.2017 12:21Так ведь экшены с сайд-эффектами — это и есть абстракция над способом получения данных.
получаем из стора id матча и делаем в компоненте запрос на сервер
Просто диспатчим экшен, а откуда придут данные — не наша печаль.
VolCh
18.06.2017 12:42Подход, предлагаемый Apollo Client как основной, нарушает абстракцию — в иерархию компонентов встраиваются знания о том, как и откуда получать данные. И, в общем случае, эти данные в общий стор приложения не попадают.
farwayer
18.06.2017 16:16+1С одной стороны вы правы, и «размазывать» работу с API по всему приложению неправильно. Если понадобиться заменить GraphQL на что-то другое, или наоборот заменить React — будет попаболь.
С другой стороны сама идея GraphQL в том, чтобы представление отвечало за то, какие именно данные нужно запросить с сервера.
Мне кажется, что оптимальный вариант в создании промежуточного слоя. Redux это будет, или что-то другое — не важно. А тут этот слой подло выкинули.
А статья на самом деле про героическое сражение с redux. И причина этого — глупый хайп вокруг него. Redux — хорошая технология, и отлично решает свои задачи. Вот только пихают ее куда ни попадя, а потом плюются.VolCh
18.06.2017 17:06Всё же в идее нет слова "представление", есть "клиент":
GraphQL… gives clients the power to ask for exactly what they need and nothing more
Промежуточный слой(и) так или иначе создаётся. Вопрос куда его пихать. Тут предлагается чуть ли не каждый "умный" компонент в него оборачивать. Я же стараюсь максимально изолировать части приложения друг от друга, компонентам нужно знать только о сторе — едином источнике правды для компонента. Как и когда взаимодействовать с сервером решает он. Он может быть локальным для компонента, но смешивать данные из глобального или вышележащего сторов и локального, по-моему, сильно усложняет поддержку.
vintage
<MatchDetail/> подключён к компоненту высшего порядка, который выполняет следующий запрос:
Это можно ещё сильнее упростить отказавшись от GraphQL:
/article/{id}?fetch=title,body:-)napa3um
Тоже пока не очень понимаю принципиальное отличие GraphQL от «чистого» REST, первое выглядит оверхедом (почти как SOAP) для любой нединамической и неграфовой структуры ресурсов (коих в прикладных задачах подавляющее большинство). Более того, для REST'а есть HATEOAS, который как раз и динамическую (заранее «неизвестную» клиенту) структуру ресурсов позволяет экспозить.
amakhrov
Принципиальное отличие: GraphQL — конкретная спецификация, в то время как REST это парадигма, которую каждый готовит по-своему.
Однозначность спецификации GraphQL позволяет писать и использовать универсальные инструменты: тот же apollo-client, стандартные реализации GraphQL-сервера на разных языках.
napa3um
REST/HATEOAS/HAL — тоже вполне себе спецификация. В том смысле в котором REST готовят по-разному приготовят по-разному и GraphQL — нельзя исчерпывающе специфицировать то, как будет структурироваться в ресурсах прикладная задача.
amakhrov
Как раз GraphQL предоставляет способ формального описания того, "как будет структурироваться в ресурсах прикладная задача" — GraphQL Schema. И формат этого описания — стандартный.
Свой RESTful сервис я тоже смогу как-то формально описать. Но язык этого описания будет какой-то кастомный. Поэтому инструменты для работы с ним мне придется писать самому.
HAL/HATEOAS — это другое. Они позволяют расширить "данные" неким стандартным способом (запросив сущность Пользователь я получаю, помимо имени и имейла, еще ссылки на связанные с этим пользователем сущности).
А GraphQL — это "метаданные". Он описывает, какие типы сущностей вообще есть и как связаны.
napa3um
Спасибо, понял ценность, она в готовых и отлаженных инструментах. Не всё ж в абстракциях витать, иногда и решать прикладные задачи нужно, согласен.
deeptowncitizen
А если к REST добавить swagger?
amakhrov
В плане документации и части инструментов для разработки, наверное, будет похоже.
Но не забываем, что GraphQL и другие задачи решает. В частности, позволяет клиенту указать, какое подмножество данных его интересует в данном запросе (вместо запроса всех атрибутов сущности), позволяет скомбинировать несколько запросов один.
Причем на бэкенде эту логику самостоятельно писать не надо: сам пишешь только запросы к сущностям в БД (логика приложения), а парсинг запросов, фильтрация атрибутов, форматирование результата реализуются библиотечным кодом.
vintage
Выгребать из базы все атрибуты, чтобы отдать клиенту лишь 2 из них — очень по js-ному. :-D
amakhrov
А вам просто потроллить или разобраться?
Я вот, допустим, нигде не говорил, что из базы надо выгребать все атрибуты. В резолвер передается список атрибутов, запрошенных клиентом. Если это важно для производительности, никто не мешает грузить из базы только то, что надо.
В hello-world туториалах это может быть не упомянуто, но это не значит, что так нельзя.
Отсылку к js я вообще не понял. Какое отношение клиентский js имеет к тому, как бэкенд работает с базой, чтобы удовлетворить запрос клиента?
vintage
Ну, то есть "фильтрация атрибутов" реализуется не "библиотечным кодом", а нашим "резолвером".
amakhrov
Хороший аргумент.
Тут два аспекта:
Кроме того, отдельно можно упомянуть работу со связанными сущностями.
Если клиент запросил для основной сущности еще какие-то связанные сущности, то на бэкенде код graphql-библиотеки определит, какие сущности запрошены, вызовет резолверы только для них, и сам объединит результаты в иерархическую структуру ответа.
vintage
Для стандартизации параметра fetch вовсе не обязателньно изобретать целый звездолёт. Даже монструозная odata на фоне GraphQL тут выглядит верхом лаконичности :-)
И вот при чём тут js. "И так сойдёт" — девиз подавляющего большинства js-разработчиков. Что клиентских, что серверных. Ну подумаешь выгребем всю табличку в память, а потом отфильтруем её через lo_dash, зато какой потом простор для оптимизаций. :-)
Если у вас графовая субд, то вы и так можете сделать один запрос к ней за всеми данными. Нет смысла вытягивать их кучей мелких запросов.
Ответ лучше давать в плоском виде, чтобы не дублировать данные (а объём может увеличиваться экспоненциально в некоторых случаях). И работать с плоским ответом потом удобнее, чем с деревом.
napa3um
GraphQL действительно инструмент для «и так сойдёт», но это не недостаток, а фича на «стартапном» рынке. Лучше наделать 100 проектов до уровня «и так сойдёт» за месяц, получить инвестиции в один проект и потом сделать его «как надо» за год. Чем пилить год один проект «как надо», чтобы в итоге убедиться в том, что он никому не нужен.
amakhrov
Все же вы передергиваете :)
Этого я нигде не писал. Всю строку ? всю таблицу.
Для несильно нагруженного бэкенда большой разницы может не быть. Гораздо больше проблем может приносить какой-то тяжелый запрос в базу, а совсем не выборка лишних колонок по первичному ключу.
А вот для клиента размер гораздо чаще имеет значение — качество связи у мобильных клиентов может оставлять желать лучшего.
"И так сойдет" — в данном случае значит, "оптимизируем, когда есть реальная проблема". А не заранее на всякий случай.
Нападки на js-разработчиков все так же непонятны в данном контексте: бэкенд-то не на js написан. А, допустим, на Go. Или на %один из десятка языков, для которых написали библиотечный graphql-сервер%.
Видимо, это что-то личное.
Иногда да, иногда нет. Если все, что требуется — это отобразить данные на экране, то с плоским ответом работать как раз неудобно (
users[project.users[0]].nameвместоproject.users[0].name).С точки зрения дублирования данных — это, конечно, нездорово. Но, наверное, хорошо покрывает сценарии использования в самом фейсбуке.
vintage
Вы не писали, но такой подход к этому приводит.
А можно заранее взять инструмент, который не надо будет "оптимизировать".
Так вы не говнокодьте, а создайте вменяемую модель:
project.users(0).name(), которая абстрагирует вас от клиент-серверного протокола.Например, сценарий "наговнякать и в продакшен"? :-)
amakhrov
vintage — вот непросто же с вами. :)
Голословно. С моей точки зрения — нет, не приводит.
Можно. А можно взять инструмент, который позволит написать проще, пусть будет работать неоптимально. Проще — значит, дешевле будет в поддержке. Не нужно всегда ориентироваться только на производительность.
Это как раз пример работы с иерархичной структурой. Правда же, удобней работать? А вы говорите — неудобно :)
vintage
А можно взять инструмент, который позволит написать проще и оптимальней. Откуда такая убеждённость, что оптимальная ахитектура пренепременно сложна? Переусложнение как правило является следствием "оптимизации" кривой архитектуры.
Работать удобно с графом, а не иерархией.
project.user(0).projects().map( project => project.user(0) )napa3um
Справедливости ради, эти задачи решаются и в REST готовыми библиотеками. Например, https://loopback.io/doc/en/lb2/Fields-filter.html. А мультиплексирование запросов в идеологии REST решается на уровне «ниже», в HTTP2 (да, я согласен, что GraphQL в этом смысле решает «сейчас», а не «потом», когда HTTP2 станет повсеместным). Ещё существуют «протокольные надстройки» (дополнительные ограничения) над REST типа ODATA, но такие решения уже мало отличаются от GraphQL как раз по подходам к работе и инструментарию.
amakhrov
Loopback — интересно, спасибо. Вы, конечно, правы, что можно и в REST сделать. В конце концов, в GraphQL никакого волшебства же нет.
HTTP2 не вполне решает проблемы, решаемые в GraphQL.
Например, у меня в приложении есть проекты, над проектами работают пользователи. И есть функция поиска.
На странице результатов поиска я хочу показать найденные проекты и их пользователей.
С GraphQL это один запрос от клиента на сервер.
С REST клиент вынужден дождаться результатов первого запроса (список проектов), чтобы потом, получив их id, запросить список пользователей на этих проектах.
С HTTP2 можно было бы использовать Server Push в этом сценарии. Но для этого сервер должен как-то знать, что клиенту потребуются связанные сущности. Тогда мы все равно придем к чему-то вроде GraphQL.
napa3um
Нет, в HTTP2 нет никаких «вынужденных» ожиданий, клиент просит у сервера что угодно когда угодно и не заботится о «красивой композиции» запросов, сервер доставит ответы максимально быстро, без лага между ними. Именно в этом потенциальное преимущество HTTP2 и упрощение клиентской логики. Если же вы говорите о композиции ресурсов в ответах, то REST совершенно не мешает вам возвратить в одном ресурсе хоть всю БД (https://loopback.io/doc/en/lb3/Querying-related-models.html, https://loopback.io/doc/en/lb3/Embedded-models-and-relations.html, https://loopback.io/doc/en/lb3/Nested-queries.html), хоть потребность в этом часто указывает на ошибку проектирования структуры ресурсов (говорит о том, что архитектор наабстрагировал ресурсов без учёта «вида работ» над ними, в этом смысле GraphQL выглядит «ленивым проектированием», откладыванием вопроса об оптимальной «нарезке» ресурсов, что для многих проектов/команд действительно может быть более практичным решением).
amakhrov
Ну как же без лага, если второй запрос зависит от результатов первого. Клиент вынужден ждать первого ответа, чтобы послать второй запрос.
GraphQL позволяет убрать это ожидание, посредством того, что клиент сразу заявит, какие связанные данные ему нужны.
Но в одном случае клиент хочет 3 связанных сущности, в другом — пять, в третьем вооще ни одной.
Варианты решения:
napa3um
> если второй запрос зависит от результатов первого
Если зависит, то конечно, и GraphQL тут тоже не поможет в телепатии.
> GraphQL позволяет убрать это ожидание, посредством того, что клиент сразу заявит, какие связанные данные ему нужны.
REST API тоже не запрещает просить связанные-данные сразу, см. ссылки.
> Но в одном случае клиент хочет 3 связанных сущности, в другом — пять, в третьем вооще ни одной.
Да, я согласился и с тем, что GraphQL позволяет отложить проектирование, позволяет не думать _сейчас_, какие и сколько «атомарных» ресурсов попросит клиент. Но это может быть не только плюсом, но и минусом (в плюсах — быстрый старт проекта с минимальной командой, но больше рисков полного рефакторинга в дальнейшем, который обычно производится в современном «стартапном экономическом пространстве» сразу после демонстрации MVP, первых инвестиций и доукомплектации команды квалифицированными кадрами).
Надеюсь, мы этим диалогом примирили REST-энтузиастов и GraphQL-энтузиастов друг с другом :).
vintage
Поможет. Вместе с запросом ресурса вы посылаете так называемый fetch plan (грубо говоря указание какие ссылки развернуть в записи, на какую глубину, и какие поля этих записей вернуть) и сервер помимо самого ресурса вернёт вам и связанные ресурсы, согласно этому плану.
napa3um
Если в таком виде это работает в GraphQL, то это очень похоже на возврат всей БД с обработкой её на клиенте :). Не могу придумать примеров, когда подобный подход может пригодиться («прошу то, чего не знаю и вряд ли смогу обработать, но давайте мне этого неизвестного сразу 5 уровней связности»). Для режима разработки если только, для тулзы, отображающей данные программисту.
vintage
Простой пример (не на GraphQL): надо показать статью на Хабре с комментариями.
Есть модели:
У вас есть slug статьи "user=jin/article=orp", поэтому вы делаете следующий запрос за всеми необходимыми данными:
Он вернёт вам данные по статье, её авторе, все комментарии, информацию о комментаторах и ничего лишнего:
napa3um
Такой пример практичнее, но укладывается и в те схемы REST-запросов, которые я противопоставлял GraphQL в данной ветке комментариев.
P.S.: таки вы прониклись удобством GraphQL в ходе комментирования статьи, изначально выступая за REST. :)
vintage
GraphQL — просто двумерный язык запросов, в урле его не попишешь — в этом его основное неудобство. Мой пример — вариация на тему HATEOAS c fetch-plan.
napa3um
Как вы заметили ранее (и с чем я «эстетически» согласен) — плоские структуры обрабатывать удобнее (меньше потенциальных противоречий в зависимых данных, меньше рассинхронизаций «точек истинности», меньше передаваемых байтов), и весь «иерархизм» я бы по возможности прятал под капотом хранилища ресурсов. Т.е., «в духе REST» я бы как клиент просил сервера отдать мне «СтатьюДляОтображения» (ресурс в терминах бизнес-логики), и этот ресурс бы уже подразумевал встроенность всех «атомарных» (в терминах персистентного слоя архитектуры) ресурсов в возвращаемый ответ. Клиент может и не знать о существовании сущностей «Статья» и «Комментарий», они могут иметь смысл только для персистентного слоя, а не для слоя бизнес-логики. А GraphQL в этом смысле как бы передвигает «бизнеслогическую декомпозицию» с бэка на фронт (позволяя «наляпать» бэк описанием схемы его персистентных ресурсов и забыть о нём, занимаясь экспериментами с композицией ресурсов на фронте, ведь в современном мире часто неизвестно, что потребуется бизнесу от приложения :)). В этом смысле GraphQL — это способ выкинуть сервер приложений, сократив его до адаптера к БД, способ обойтись двухзвенной архитектурой в проектах, в которых трёхзвенная избыточна.
napa3um
(В общем, без конкретной задачи обсуждать «что круче» не имеет смысла, оба подхода могут оказаться удобнее в тех или иных условиях.)
vintage
Это доменные сущности, все о них знают. А "персистентные сущности" — это "таблица А на узле Б содержащая связи Статей и Комментариев".
Ага, и любой долбодятел влёт положит вам базу данных хитрым запросом.
napa3um
> все о них знают
Примерно также, как все считают точкой истинности БД. Программисту фронта «не запрещено» это знать, однако архитектура будет качественнее, если он сможет программировать свой модуль так, будто он об этом может не знать (удобно решать задачи по кускам, не держа в голове весь проект целиком).
> Ага, и любой долбодятел влёт положит вам базу данных хитрым запросом.
А вот это уже и есть те проблемы, до которых проект с GraphQL неизбежно дойдёт в своём развитии. Конечно, в GraphQL хватит возможностей для решения этих проблем, но в итоге сложность и затраченные на разработку ресурсы получатся сопоставимыми с «чистым REST-решением». Ну а плюс GraphQL в том, что эту проблему можно решить «потом», когда она уже станет актуальной (и когда будут деньги на её решение).
napa3um
(Т.е., GraphQL экспозит персистентный слой, а при дальнейшем добавлении в схему данных правил и ограничений на запросы по их извлечению как раз и «обрастёт» бизнес-слоем. Эдакая каша из топора. Получится, возможно, не самая лучшая структура бизнес-логики, размазанная между бэком и фронтом, но зато «бесплатно».)
vintage
Как можно выводить статью и комментарии не зная про статьи и комментарии?
А ещё можно не создавать проблему, чтобы не приходилось потом её героически решать. Впрочем, о чём это я, мы же в топике про Реакт. :-D
napa3um
> Как можно выводить статью и комментарии не зная про статьи и комментарии?
Можно знать о структуре объекта «Статья Для Отображения», одним из полей которого будет массив «Комментариев Для Отображения, Принадлежащих Конкретной Статье Для Отображения». И эти сущности по своей структуре и составу могут иметь очень мало общего с объектами «Статья» и «Комментарий» персистентного слоя архитектуры. Не верю, что вы этого не понимаете :).
> А ещё можно не создавать проблему, чтобы не приходилось потом её героически решать.
Проблемы есть у всех, но все по-разному их формализовывают («Дай имя своей печали, и она уйдёт» :)). В данной ветке я как раз и пытался в диалоге для себя выделить те проблемы, которые сформулировали для себя GraphQL-разработчики и решили своим подходом. В том виде, как я понял эти проблемы, они вполне практичны, но связаны, на мой взгляд, больше не с «механикой» решения, а, скорее, с «экономикой».
vintage
Доменные сущности никак не зависят от способа представления. От того, что вы засунули структуры коментариев в структуру статьи — от этого они не перестали быть отдельными доменными сущностями.
napa3um
Если вы модули всех слоёв архитектуры программирует в терминах доменных сущностей, пронося «Статью» от БД (или даже от ТЗ заказчика) до виджета на сайте в неизменном виде (и не различая бизнес-логику, логику представления и логику хранения), то, наверное, GraphQL как раз подходящий вам инструмент :).
vintage
Да, я храню данные в нормализованном виде, а для доменных сущностей создаю полноценные изоморфные доменные модели, через которые работать — одно удовольствие. GraphQL — костыль к реактовой экосистеме, с которой я связываться не имею ни малейшего желания.
napa3um
Думается, что этот костыль вам не нравится только потому, что он решает как раз те проблемы, что решили вы сами :). «Изоморфные доменные модели» — очень ёмкое название этого костыля как раз, именно так можно назвать «экспозицию персистентного слоя приложения в слой данных клиента». (Но не воспринимайте как критику, «костыльность» и «одно удовольствие» всегда относительны задачам проекта, ресурсам, набору компетенций и инструментов решения команды, реализующей проект.)
VolCh
GraphQL особого отношения к реакту не имеет. Есть модули связи с ним, как есть с тем же ангуляром, не более.
GraphQL по сути — протокол взаимодействия клиента с сервером, направленный на, имхо, упрощение разработки клиентов. Apollo GrphQL Client — реализация этого протокола с высокоуровневой оберткой, упрощающей решения типовых задач.
vintage
Не имеет, но страдает от одних и тех же архитектурных проблем — развесистых json с дублированием данных и их обработкой в процедурном стиле.
VolCh
Да, дублирование данных присутствует в общем случае, как следствие представление графа объектов в виде дерева, но популярные клиенты вполне справляются с его конвертацией обратно в граф с устранением дублирования.
Стиль обработки данных вне уровня протокола обмена лежит.
vintage
А зачем конвертировать граф в дерево, чтобы потом конвертировать обратно в граф? Кроме того, вы недооцениваете масштаб трагедии. Из-за дублирования объём пересылаемых данных может расти экспоненциально от числа узлов. У нас реально были с этим проблемы — вместо 100 кб нормализованных данных, грузилось дерево на 15 мегабайт. Тормозило всё: сервер, собирая это дерево сжирал кучу памяти и процессора, грузилось по сети всё это вечность, а потом и клиент зависал на несколько секунд в обработке кучи данных. Как петух клюнул — сделали, наконец, номализованную выдачу. И мало того, что всё стало летать, так ещё и код обработки капитально упростился. Но, как видим, на чужих ошибках никто не учится, только на своих.
amakhrov
отлично :)