

Привет, Хабр! Меня зовут Виталий Котов, я работаю в Badoo в отделе QA, занимаюсь автоматизацией тестирования, а иногда и автоматизацией автоматизации тестирования.
Сегодня я расскажу о том, как мы в Badoo упростили работу с Selenium-тестами, научили ребят из отдела ручного тестирования работать с ними и какой профит с этого получили. Прочитав статью, вы сможете оценить трудозатратность каждого из этапов и, возможно, захотите частично перенять наш опыт.
Введение
Со временем количество автотестов становится довольно внушительным, и приходит понимание, что система, в которой количество автоматизаторов – константа, а количество тестов непрерывно растёт, – неэффективна.
В Badoo серверная часть наравне с Desktop Web релизится два раза в день. Об этом очень подробно и интересно рассказал мой коллега Илья Кудинов в статье «Как мы уже 4 года выживаем в условиях двух релизов в день». Я советую ознакомиться с ней, чтобы дальнейшие примеры в этой статье были вам более понятны.
Вполне очевидно, что чем выше покрытие автотестов, тем бoльшее их количество окажется затронутым в процессе релиза. Где-то изменили функционал, где-то поменяли вёрстку и локаторы перестали находить нужные элементы, где-то включили A/B-тест и бизнес-логика для части юзеров стала другой и так далее.
В какой-то момент мы оказались в ситуации, когда правка тестов после релиза занимала почти всё время, которое было у автоматизатора до следующего релиза. И так по кругу. Не оставалось времени на написание новых тестов, на поддержку и развитие архитектуры и решение каких-то новых задач. Что делать в такой ситуации? Первое решение, которое приходит в голову, — нанять ещё одного автоматизатора. Однако у такого решения есть существенный минус: когда тестов снова станет в два раза больше, мы снова будем вынуждены нанимать ещё одного автоматизатора.
Поэтому мы пошли по другому пути, мы решили научить ребят из отдела ручного тестирования работать с тестами, условившись, что в своих задачах они будут самостоятельно править тесты до релиза. Какие плюсы у этого решения?
Во-первых, если тестировщик способен поправить автотест, он тем более способен разобраться в причине его падения. Таким образом, повышается вероятность, что он найдет баг на максимально раннем этапе тестирования. Это хорошо, потому что исправить проблему в этом случае можно быстро и просто, а задача уедет на продакшн в назначенный due date.
Во-вторых, наши автотесты для Desktop Web написаны на PHP, как и сам продукт. Следовательно, работая с кодом автотестов, тестировщик развивает в себе навык работы с этим языком программирования, и ему становится легче и проще понять дифф задачи и разобраться, что там было сделано и куда стоит в первую очередь посмотреть при тестировании.
В-третьих, если ребята правят тесты, они иногда могут выделять время для написания новых. Это и интересно самому тестировщику, и полезно для покрытия.
И последнее, как вы уже поняли, у автоматизатора появляется больше времени, которое он может тратить на решение архитектурных вопросов, ускоряя прохождение тестов и делая их проще и понятнее.
С плюсами разобрались. Теперь давайте подумаем, какие могут быть минусы.
Тестирование задачи начнет занимать больше времени, потому что QA-инженеру придется помимо проверки функционала исправлять тесты. С одной стороны это действительно так. С другой стороны стоит понимать, что маленькие задачи у нас в Badoo превалируют над масштабными рефакторингами, где затрагивается всё или почти всё. О том, почему это так и как мы к этому пришли, хорошо рассказал глава отдела QA Илья Агеев в статье «Как workflow разработки влияет на декомпозицию задач». Следовательно, исправления должны сводиться к нескольким строчкам кода, а это не займет много времени.
В крупных же задачах, где сломалось большое количество тестов, и багов тоже может быть много. Не раз мы сталкивались с ситуацией, когда в процессе починки тестов после таких рефакторингов находились баги, пропущенные при ручном тестировании. А как мы помним, чем раньше мы найдём баг, тем легче его исправить.
Итак, дело за малым – сделать тесты пригодными для того, чтобы в них мог разобраться человек, не имеющий опыта написания автотестов.
Рефакторинг тестов
Первый этап был довольно скучным. Мы принялись за рефакторинг наших тестов, стараясь максимально отделить логику работы теста со страницей от логики самого теста, так, чтобы при изменении внешнего вида проекта было достаточно поправить несколько констант-локаторов, не трогая при этом код самого теста. В итоге у нас получились классы наподобие PageObject. Каждый из них описывает элементы, относящиеся к одной странице или одному компоненту, и методы взаимодействия с ними: дождаться элемент, подсчитать количество элементов, кликнуть по нему и так далее. Мы договорились, что никаких логических проверок типа assert в таких классах быть не должно – только взаимодействие с UI.
Благодаря этому мы получили тесты, которые читаются довольно просто:
$Navigator->openSignInPage();
$SignInPage->enterEmail($email);
$SignInPage->enterPassword($password);
$SignInPage->submitForm();
$Navigator->waitForAuthPage();И простые UI-классы, которые выглядят примерно так:
сlass SignInPage extends Api
{
const INPUT_EMAIL = ‘input.email’;
const INPUT_PASSWORD = ‘input.password’;
const INPUT_SUBMIT_BUTTON = ‘button[type=”submit”]’;
public function enterEmail($email)
{
$this->driver->element(self::INPUT_EMAIL)->type($email);
}
public function enterPassword($password)
{
$this->driver->element(self::INPUT_PASSWORD)->type($password);
}
public function submitForm()
{
$this->driver->element(self::INPUT_SUBMIT_BUTTON)->click();
}
}Теперь, если локатор для пароля изменится, и тест сломается, не найдя нужное поле ввода, будет понятно, как его поправить. Более того, если метод enterPassword() используется в нескольких тестах, изменение соответствующего локатора починит сразу всё.
В таком виде тесты уже можно показывать ребятам. Они читаемые, и с ними вполне можно работать, не имея опыта написания кода на PHP. Достаточно рассказать основы. Для этого мы провели ряд обучающих семинаров с примерами и заданиями для самостоятельного решения.
Обучение
Обучение велось постепенно, от простого к сложному. После первого занятия была задача починить сломанный тест, где нужно было поправить несколько локаторов. После второго занятия требовалось расширить существующий тест, дописав несколько методов в UI-класс и использовав их в тесте. После третьего ребята уже вполне могли написать новый тест самостоятельно.
На основе этих семинаров были написаны статьи в нашу внутреннюю Wiki о том, как правильно работать с тестами и с какими подводными камнями можно столкнуться в процессе. В них мы собрали best practices и ответы на часто задаваемые вопросы: как правильно составить локатор, в каком случае стоит создавать новый класс под тест, а в каком – добавлять тест в уже существующий, когда создавать новый UI-класс, как правильно называть константы для локаторов и так далее.
Сейчас, когда в компанию приходит новый QA-инженер, он получает список тех самых статей из Wiki, с которыми необходимо ознакомиться для работы с автотестами. И когда он в процессе тестирования впервые сталкивается с падающим тестом, он уже во всеоружии и знает, что делать. Само собой, в любой момент он может подойти ко мне или к другому автоматизатору и что-то уточнить или спросить, это нормально.
У нас есть договорённость, что умение QA инженера работать с автотестами, в том числе писать новые – это одно из требований для роста внутри компании. Если ты хочешь развиваться (а кто же не хочет, верно?), надо быть готовым к тому, что придётся заниматься и автоматизацией в том числе.
TeamCity
Наши Selenium-тесты лежат в том же репозитории, где и код проекта. Когда мы только начинали писать первые Selenium-тесты, у нас уже был PHPUnit и некоторое количество unit-тестов. Чтобы не плодить технологии, мы решили запускать Selenium-тесты, используя тот же PHPUnit, и положили их в соседнюю с unit-тестами папку. Пока тестами занимались только автоматизаторы, мы могли вносить правки в тесты сразу в Master, поскольку делали это уже после релиза. И, соответственно, запускали в TeamCity тесты тоже с Master.
Когда ребята начали работать с тестами в своих задачах, мы договорились, что правки будут вноситься в ту же ветку, где лежит код задачи. Во-первых, это обеспечивало одновременную доставку правок для тестов в Master с самой задачей, во-вторых, в случае отката задачи из релиза правки для неё также откатывались без дополнительных действий. В итоге мы начали запускать тесты в TeamCity с ветки релиза.
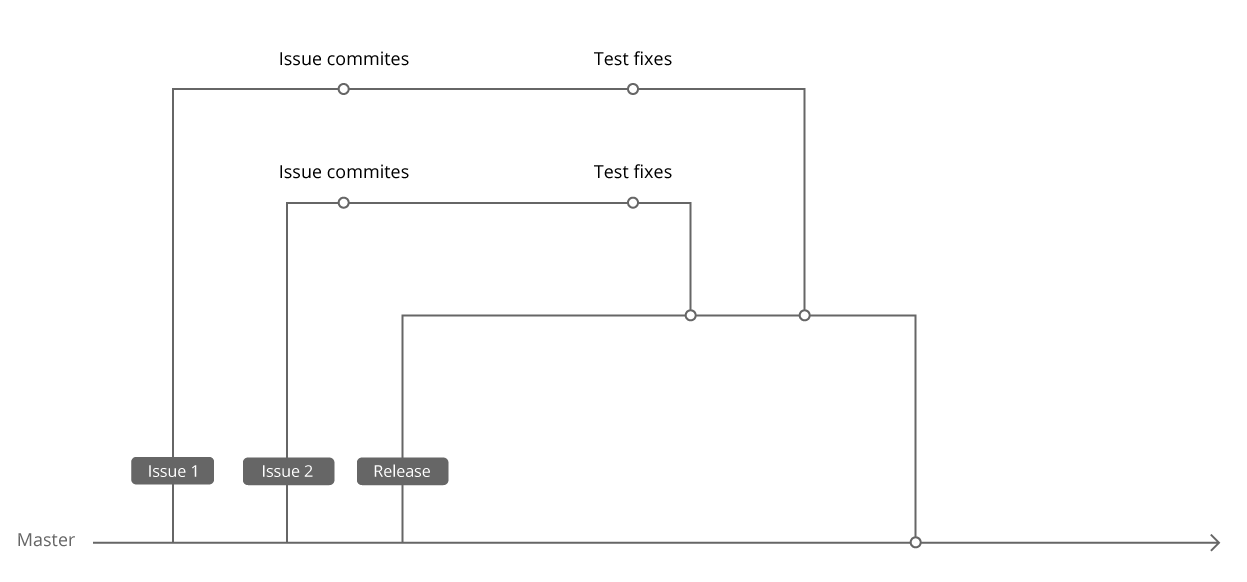
Таким образом, мы получили систему, в которой автоматизатор может следить только за тестами для релиза, а новая задача при этом приходит в релиз сразу с правками для тестов. В такой системе пожизненный зелёный билд обеспечен. :)
Но это ещё не всё.
Запуск тестов по диффу задачи
Гонять все тесты для каждой задачи крайне затратно как по времени, так и по ресурсам. Каждый тест необходимо обеспечить браузером, следовательно, нужно поддерживать мощную Selenium-ферму. Также нужен мощный сервер, на котором будет развёрнут проект и по которому параллельно будет ходить большое число автотестов. А это – дорогое удовольствие.
Мы решили, что было бы круто вычислять динамически для каждой задачи, какие именно тесты стоит запускать. Для этого мы каждому тесту присвоили набор групп, которые привязаны к проверяемым фичам или страницам: Search, Profile, Registration, Chat, и написали скрипт, который отлавливает тесты без групп и пишет соответствующие нотификации автоматизаторам.
Далее перед запуском тестов на задаче мы при помощи Git научились анализировать изменённые файлы. Они по большей части тоже называются как-то похоже на фичи, к которым имеют отношение, или лежат в соответствующих папках:
/js/search/common.js/View/Chat/GetList.php/tpls/profile/about_me_block.tpl
Мы придумали пару правил для файлов, которые не соответствуют названию ни одной группы. Например, у нас часть файлов называется, скажем, не chat, а messager. Мы сделали карту алиасов и, если натыкаемся на файл, который называется messager, запускаем тесты для группы Chat, а если файл лежит где-то в core-папках, то мы делаем вывод, что стоит запустить полный набор тестов.
Конечно, универсального алгоритма решения такой задачи не существует – всегда есть вероятность, что изменение в каком-то классе затронет проект в самом неожиданном месте. Но это нестрашно, поскольку на стейджинге мы запускаем полный набор тестов и обязательно заметим проблему. Более того, мы придумаем правило, как в следующий раз не пропустить подобную проблему и обнаружить её заранее.
Нестабильные и сломанные тесты
Последнее, что осталось сделать, — это разобраться с нестабильными и сломанными тестами. Никто не захочет возиться с сотней упавших тестов, разбираясь, какие из них сломаны на Master, а какие – просто упали, потому что проходят в 50% случаев. Если доверия к тестам нет, тестировщик не будет внимательно их изучать и тем более править.
Бывает, что при релизе больших задач допускается некоторое количество мелких багов, которые незаметны пользователю (например, JS-ошибка, которая не влияет на функционал) и которые можно исправить в следующем релизе, не задерживая выкладку важных изменений на продакшн.
И если с тестировщиком можно договориться, то с тестами всё сложнее – они честно будут находить проблему и падать. Причём, когда баг окажется в Master, тесты начнут падать на других задачах, что совсем плохо.
Для таких тестов мы придумали следующую систему. Мы завели MySQL-табличку, где можно указать название падающего теста и тикет, в котором проблему исправят. Тесты перед запуском получают этот список, и каждый тест ищет себя в нём. Если находит, помечается как Skipped с сообщением, что такой-то тикет не готов, и тест запускать нет смысла.
В качестве багтрекера мы используем JIRA. Параллельно по cron’у гоняется скрипт, который через JIRA API проверяет статусы тикетов из этой таблицы. Если тикет переходит в статус Closed, мы удаляем запись, и тест автоматически начинает снова запускаться.
В итоге сломанные тесты исключаются из результатов прогонов. С одной стороны, это хорошо – на них больше не тратится время при прогоне, и они не «засоряют» результаты этого прогона. С другой стороны, тестировщику приходится постоянно открывать SeleniumManager и смотреть, какие тесты отключены, чтобы при необходимости проверять кейзы руками. Так что мы стараемся не злоупотреблять этой фичей, у нас редко бывает больше одного–двух отключенных тестов.
Теперь вернёмся к проблеме нестабильных тестов. Поскольку речь в статье идёт о UI-тестах, нужно понимать, что это тесты высокого уровня: интеграционные и системные. Такие тесты по определению нестабильны, это нормально. Однако хочется всё же ловить эти нестабильности и отделять от тестов, явно падающих «по делу».
Мы довольно давно пришли к выводу, что стоит логировать запуски всех тестов в специальную MySQL-таблицу. Название теста, время прогона, результат, для какой задачи или на стейджинге был запущен этот тест и так далее. Во-первых, нам это нужно для статистики; во-вторых, эта таблица используется в SeleniumManager – веб-интерфейсе для запуска и мониторинга тестов. О нём однажды я напишу отдельную статью. :)
Помимо вышеперечисленных полей, в таблицу было добавлено новое – код ошибки. Этот код формируется на основе трейса упавшего теста. Например, в задаче А тест упал на строке 74, где он вызвал строку 85, где был вызван UI-класс на строке 15. Почему бы нам не склеить и не записать эту информацию: 748515? В следующий раз, когда тест упадёт на какой-то другой задаче Б, мы получим код для текущей ошибки и простым select’ом из таблицы узнаем, были ли ранее похожие падения. Если были, то тест очевидно нестабильный, о чём можно сделать соответствующую пометку.
Само собой, тесты иногда меняются, и строки, на которых они падают, тоже могут измениться. И какое-то время старая ошибка будет считаться новой. Но, с другой стороны, это происходит не так часто, поскольку, как вы помните, логика теста отделена от логики UI и меняется редко. Так что бoльшую часть нестабильных тестов таким образом мы действительно отлавливаем и помечаем. В SeleniumManager есть интерфейс, позволяющий перезапускать нестабильные тесты для выбранной задачи с целью убедиться, что функционал работает.
Итог
Я постарался подробно, но без излишней дотошности описать наш путь от точки А, где автотестами занималась только группа «избранных» ребят, до точки Б, где тесты стали удобными и понятными всем.
Этот путь состоял из следующих этапов:
- Разработка специальной архитектуры, в рамках которой должны быть написаны все тесты. Рефакторинг старых тестов.
- Проведение обучающих семинаров и написание документации для новых сотрудников.
- Оптимизация работы автотестов: изменение флоу запуска тестов в TeamCity, запуск тестов по диффу для конкретной задачи.
- Упрощение результатов прогона тестов: тестировщик в первую очередь должен видеть те упавшие тесты, которые наверняка связаны с его задачей.
В итоге мы пришли к системе, в которой ручным тестировщикам довольно комфортно работать с Selenium-тестами. Они понимают, как они устроены и как их запускать, умеют их править и могут при необходимости писать новые.
В то же время автоматизаторы получили возможность и время заниматься сложными задачами: создавать более точные системы для отлавливания нестабильных тестов и править их, создавать удобные интерфейсы для запуска тестов и интерпретации результатов прогонов, ускорять и улучшать сами тесты.
Совершенствуйте свои инструменты и делайте их проще в использовании и будет вам «щасте». Спасибо за внимание!
Комментарии (38)

pborodin
04.09.2017 21:00+2Спасибо за статью. Почерпнул для себя пару идей про нестабильные тесты. Расскажите, пожалуйста, поподробнее про SeleniumManager. Это ваша собственная разработка? Что умеет делать этот менеджер? Отдельная статья про SeleniumManager была бы очень кстати.

nizkopal Автор
04.09.2017 21:32+2Спасибо за отзыв.
SeleniumManager — это самописный интерфейс, который упрощает работу с автотестами. Он умеет запускать тесты параллельно по группам, умеет хранить в себе и красиво показывать результаты прогонов для разных задач, независимо от того, где эти тесты были запущены — на облаке, в CI или локально, фильтруя их и указывая особенно подозрительные падения.
Помимо этого там есть интерфейс для добавления тестов в список “сломанных”, графики стабильности тестов и нагрузки на selenium-ноды, список самых частых ошибок и так далее.
Да, я уже подумал о том, чтобы написать про него статью. Но хочется не просто рассказать, какой инструмент у нас есть, а рассказать так, чтобы кому-то захотелось себе такой же, и чтобы этот кто-то уже знал, как его создать. :)
Как только я структурирую эту информацию и найду время облачить ее в слова, выйдет новая статья.webtrium
05.09.2017 19:49Интересная публикация, спасибо! А в TeamCity нет средств параметризации для создания параметризованных сборок, к примеру для запуска тестов по группам? Для стека JAVA + Testng + Jenkins есть возможность завести параметры groups и для каждого метода-теста указать группу, к которой он принадлежит (вида Test(groups = {«all», ..}), и в дальнейшем запускать необходимую. Ну и Allure — для отображения состояния тестов в графическом виде.
nizkopal Автор
05.09.2017 20:57В TeamCity много чего есть. Я с ним пять лет работаю и постоянно натыкаюсь на что-то новое. :)
То, о чем Вы говорите, там есть.
couldron
04.09.2017 21:00+1Спасибо, хорошая статья.
Можно немножко подробностей из внутренней Wiki?
Например, как составлять локатор.nizkopal Автор
04.09.2017 22:53+2Там довольно много рекомендаций, которые работаю для нашего проекта.
По поводу локаторов. Например, новые локаторы мы стараемся писать на css, однако если правится локатор, который уже написан на xpath, переводить его на css не стоит — высока вероятность, что этот локатор складывается с другим.
Еще пример. Бывает, что в xpath-локаторе у одного тега описывается сразу два класса:
//div/a[contains(@class,"added active")]
То лучше эти два класса разделять вот так:
//div/a[contains(@class,"added")][contains(@class,"active")]
Дело в том, что классы элементам довольно часто добавляются динамически через JS, а значит асинхронно. И порядок, в котором классы будут добавлены, может меняться. В итоге элемент не будет находиться, а тест будет падать через раз.
Или как правильно работать с SVG, используя xpath-локаторы.
В целом там довольно много примеров, все не перечислить. Мы туда добавляем все знания, которые кажутся нам важными или из-за которых мы сталкивались с какими-то сложностями.nizkopal Автор
04.09.2017 23:05+2Вот, нашел еще одно хорошее правило в Wiki:
Локаторы должны быть привязаны к классам и тегам так, чтобы было ясно назначение элемента. За локатор вида
//span[1]/div[3]/form[1]/input[3]расстрел вне очереди.
Такие дела :)

lxsmkv
04.09.2017 21:04+2За год работы я добился от нашей автоматизации того, что если тест падает, он указывает на действительную проблему в системе. Я не делаю насильственной популяризации автоматизации в проекте, но добился за год того, что ко мне приходят и спрашивают, можно ли функцию автоматически протестировать, я пишу им для этого тест. (Или говорю, мол, нет, слишком затратно, или что тест не будет стабильным). Или после изменений разработчики прогоняют UI-тесты через локальную сборку (DevBuild) и сравнивают результаты на регрессию. Для меня все это хороший знак.
Инструментт тестирования у нас в принципе простой, но никто не хочет этим заниматься помимо основной работы. Да и я видел какие разработчики пишут юнит-тесты, не надо на них вешать автоматизацию :) У меня даже есть гипотеза, что разработчики подсознательно не видят крайних случаев, потому что мозг знает что если их увидеть, то это выльется в дополнительную работу.

isxam
04.09.2017 21:18Не совсем понятен воркфлоу в ситуации, когда правят тесты сами тестировщики.
Правильно ли я понимаю, что разработчик не прогоняет тесты, этим занимается тестер, попутно определяя тест упал, условно, из-за изменений в верстке либо из-за бага? Или разработчик фиксит тесты упавшие по багам, а требующие апдейта тестов падения оставляет тестировщику?
И поскольку Вы пишите, что ранее тесты фиксились от релиза до следующего релиза, то в продакшен код попадал с красными тестами (возможно неработающим функционалом)?
Помимо вышеперечисленных полей, в таблицу было добавлено новое – код ошибки. Этот код формируется на основе трейса упавшего теста. Например, в задаче А тест упал на строке 74, где он вызвал строку 85, где был вызван UI-класс на строке 15. Почему бы нам не склеить и не записать эту информацию: 748515?
line 1 -> line 2 -> line 3 = 123
line 12 -> line 3 = 123
может разделители? или такое опущено за маловероятностью?)nizkopal Автор
04.09.2017 21:42+1По поводу воркфлоу. Все тесты у нас запускаются автоматически, когда задача готова — код написан и прошел код-ревью. Когда она попадает к тестировщику, он уже видит список сломанных тестов.
Для unit-тестов у нас отдельный флоу. Если для какой-то задачи падает unit-тест, то AIDA (о ней можно почитать тут — https://habrahabr.ru/company/badoo/blog/169417/) оповещает разработчика, и он сам правит тест.
Если же ломается интеграционный тест, то тестировщик занимается им самостоятельно. Он определяет, почему тест сломался. Если это баг, задача возвращается на доработку. Если что-то изменилось и тест надо поправить, тестировщик его правит в той же ветке, где и код задачи, после чего отправляет задачу в релиз.
Бывают сложные кейзы, когда для починки теста не обойтись изменением одного или двух локаторов. Тогда все уже зависит от желания и квалификации тестировщика. Если он может, он переписывает тест. Если не может или задача срочная и на это нет времени, этим занимаются автоматизаторы. Тут все строится на интересе и на взаимовыручки.nizkopal Автор
04.09.2017 21:44+1Да, забыл про второй вопрос.
У нас код в тест-классах всегда начинается с методов-тестов. Если в классе есть какие-то вспомогательные функции, они всегда лежат ниже по коду. Само собой, приведенный Вами пример имеет право на существование, но в нашей архитектуре крайне маловероятен.
saw_tooth
04.09.2017 23:15Мы договорились, что никаких логических проверок типа assert в таких классах быть не должно – только взаимодействие с UI
Очень интересно… что вы тогда тестируете
1. Ввел креды: logtester/passtester
2. Зашел на страницу — как мне узнать под тем ли я юзером? Нужно найти метод который мне вернет юзера так? А что если таких проверок 10000, если это какая нить форма огромная?
Второй момент, Вы показали только код ваших инпутов, а теперь покажи ваши километровые трайкетчи метода submitForm() и waitForAuthPage(), ведь ошибок может быть масса — как вы их разделяете? Простой пример ошибка валидатора пароля: слишком короткий, и запрещенные символы.
В общем, не хочу Вас обидеть или еще что, но Ваша идея (ту которую я увидел из кода) — это плохой стиль. При такой вариации, сложно делать data-driven тесты, сложно так же управлять потоками данных (представьте лапшу из if, если Ваш фреймворк будет тестировать форум с большим discretionary access control).
На самом деле, немного оффтопа, за время, которое я провел за автотестами, у меня выработался набор небольших правил:
— Композиция, никакого наследования, никаких гетеров/сеттеров, меньше тра/кетчей, все только по тай-маутам (элемент должен появиться рано или поздно, если нет — упали)
— PageObject не всегда хорош, Widget/Elements куда удобнее, особенно когда на проекте 100500 разных Drop-Down листов и не только.
— Все проверки строго по данным, которые берутся из базы/мусора/бумажки. В фреймворке только проверка перехода через страницу (деление страниц до тех пор, пока не будет уникального идентификатора). Страница должна самодостаточно себя определить, как абстрактный элемент теста: страница корзины одинакова — будет она вызвана из личного кабинета, или из айтема покупки, а вот виджеты «Добавленные покупки» уже будет другой, в таком случае в страницу Корзина я могу добавить автопроверку в конструктор при переходе на нее, и если переход состоялся куда я не ожидал (нет на страницы скажем h1 «Корзина») то я «заваливаюсь».
— Приучитесь писать run-конфигурации для тест-энвайромента: есть 100 тестов, они все разрозненны, но есть тест сьюты, которые должны проверять функциональности. Берем пачку тестов, засовываем в конфигурацию, прикрепляем в бранчу/тикету/ — готово. Это облегчает запуск, и всегда из ранее готовых тестов можно «набрать» нужную функциональность, обозвать для нее конфигурацию, и запускать.nizkopal Автор
04.09.2017 23:23+1Спасибо за Ваш интерес к нашему коду. К сожалению, я не увидел в Вашем комментарии четко сформулированного вопроса, только поток сознания. :)
Что касается оффтопа, то может Вам стоит написать статью о том, как Вы организовываете свой код тестов и какой профит с этого имеете? С удовольствием почитаю. Только соберите мысли в порядок и пишите побольше наглядных примеров. Удачи!
fonBlaser
05.09.2017 07:49Интересная статья, большое спасибо!
Интересно, а с какими трудностями сталкивались при обучении Manual QA чтению и модификации тестов? Все таки тесты — это тоже исходный код, техническая часть. Были ли сложности с пониманием тех или иных принципов авто-тестирования, и какие именно?
P.S.: Очень хотелось бы помочь своим мануальщикам начать использовать авто-тесты, вот и интересуюсь о подводных граблях :)nizkopal Автор
05.09.2017 10:55+1Тут, как и с любым инструментом, надо начинать знакомиться с простых вещей. Можно показать, как запускать тесты. Если это сделано неудобно, стоит сначала оптимизировать процесс. Чем проще запустить тест, тем чаще его будут запускать.
Далее важно сделать удобный вывод репорта об ошибке. У нас он пишет, какой user был авторизован, делает скриншот и HTML-слепок, пишет строку для перезапуска теста в консоли и так далее.
Сами тексты ошибок, которые формируются, если элемент не найден или какой-то assert не сработал, стоит писать подробно. Так, чтобы глядя на скриншот было понятно, в чем проблема.
Только когда тесты готовы к тому, чтобы ими можно был легко пользоваться, стоит привлекать тестировщиков или девелоперов к их использованию. Тут важно не спугнуть. :)
Что касается работе с кодом, само собой все приходит с опытом. Волне нормально, если допускаются стилистические или даже логические ошибки. Для этого есть код-ревью, где более опытный коллега может подсказать верное решение.
Главное начать! А опыт придет.
He11ion
05.09.2017 10:34Есть вопрос — ловите ли как-то «false positive» тесты — вроде assert(1,1) — они всегда будут зелеными, независимо от изменений кода.
nizkopal Автор
05.09.2017 10:47+1Добрый день.
Да, конечно, иногда бывает так, что тест проверяет фичу не в полном объеме и пропускает что-то. Обычно такое отлавливается как раз ручными тестировщиками, которые находят баг руками и видят, что тест его пропустил.
Если это не долго, тестировщик может сам добавить нужную проверку. Если же это займет существенное время, ставит тикет.
Более того, у нас устроено так, что для любого тикета с пометкой баг автоматически ставится QA-тикет на дописание нужного теста. Это очень удобно и положительно влияет на покрытие.

Palomnik
05.09.2017 14:33Добрый день, есть два вопроса:
1) Вы определяете покрытие тестами? Если да, то как?
2) Так как система большая, а разработчиков тестов много, как вы определяете, что автотесты взаимонепересекающиеся? Т.е. что нет двух автотестов которые частично или полностью проверяют одно и то же?nizkopal Автор
05.09.2017 15:42Добрый день.
1) Да, мы ведем учет тестов. Само собой, речь идет не о покрытий строк кода, как для unit-тестов. Ведь даже простое открытие страницы чаще всего затрагивает много классов и методов, хотя мы еще ничего не проверили. Для функциональных тестов мы считаем, какое количество фич мы покрыли автотестами, из общего их количества. У нас есть внутренний документ, где мы ведём подобную статистику.
Когда появляется новый функционал на сайте, мы дописываем его в этот документ, и покрытие падает. Когда пишем тесты — покрытие снова оказывается на прежнем уровне. Так мы развиваем покрытие «в ширину».
Помимо этого, как я уже писал в одном из комментариев, если тестировщик находит баг, который автотестами был пропущен, мы ставим тикет на автоматизацию. Это помогает «углубиться» в тестирование фичи, покрывая ее особенно уязвимые кейзы.
2) Существует некоторое конечное число направлений, в которых мы развиваем автоматизацию у нас в компании. Биллинг и интерфейсы, Desktop Web, Mobile Web, iOS и Android приложения, тестирование API и так далее. За каждый компонент отвечает один человек. Он знает, какие тесты есть, и через его код-ревью как правило проходит весь-весь-весь новый код, связанный с его зоной ответственности. Таким образом он следит за повторениями.
Помимо этого у нас есть внутренние документы, которые я описал выше. Они тоже помогает в решении такой задачи.
Palomnik
06.09.2017 01:06По первому вопросу: а что если мануальщики находят баги? Они покрываются тестами? В обязательном порядке все или вы как-то их приоритезируете/выбираете?
По второму вопросу, как я понимаю, упирается в мейтенера и то, что автотесты, в том числе, требуют документации?

Wolonter
05.09.2017 14:350.
В какой-то момент мы оказались в ситуации, когда правка тестов после релиза занимала почти всё время, которое было у автоматизатора до следующего релиза.
Вы поднимаете тесты после релиза? Почему не до?
1.
В какой-то момент мы оказались в ситуации, когда правка тестов после релиза занимала почти всё время, которое было у автоматизатора до следующего релиза.
Почему поднятием тестов занимается не программист? Зачем лишнее звено — автотестер?
2.
функционал
Функциональность.
3.
Первое решение, которое приходит в голову, — нанять ещё одного автоматизатора.
Именно это решение вы и реализовали, разве нет? Вы попытались сделать из «ручных тестеров» «автоматизаторов», но почему-то не путем повышения квалификации, а путем снижения порога входа и упрощением системы тестов (что само по себе стоит дорого)
4.
Когда ребята начали работать с тестами в своих задачах, мы договорились, что правки будут вноситься в ту же ветку, где лежит код задачи.
До этого не так? Как вы убивались об версионирование кода приложения и кода тестов?
5. Вы не считаете порочным деление на «автоматизаторов»" и «ручных тестеров»? Автоматизация всего лишь инструмент. Ваши автоматизаторы тестировать умеют?
Спасибо большое, очень интересная статья.nizkopal Автор
05.09.2017 16:05Вы поднимаете тесты после релиза? Почему не до?
Я здесь не достаточно корректно написал, согласен. Имеется в виду, что как только релиз оказывается на стейджинге, у нас есть где-то 4 часа на его проверку, прежде чем он окажется на продакшене. В какой-то момент мы оказались в ситуации, когда все эти 4 часа уходили на следующее.
Мы проверяли каждый тест, если он падал из-за бага, искали тикет, который этот функционал сломал, чтобы либо запатчить, либо откатить, в зависимости от серьезности проблемы.
Если же тест падал из-за изменений, мы либо чинили его, если это было быстро и у нас еще оставалось время, любо откладывали его починку и проверяли функционал руками. Само собой, работать в такой суматохе было довольно сложно, к тому же мы рисковали иногда в спешке ошибочно решить, что тест падает, «это не страшно, поправлю потом».
Сейчас тестирование релиза происходит куда спокойнее.
Почему поднятием тестов занимается не программист? Зачем лишнее звено — автотестер?
Именно запуском тестов у нас вообще занимаются скрипты или CI, в зависимости от окружения. Все автоматизированно.
Что касается починкой тестов. У нас в компании написанием функциональных тестов занимается отдел тестирования. Это наш инструмент для более тщательной и быстрой проверки функционала. Следовательно и починкой занимаемся тоже мы. Во-первых, мы уже знаем как эти тесты устроены, так как сами их разработали, во-вторых, когда тест падает, именно нам нужна информация о том, почему он упал. Может быть это не тест надо править, а тикет переоткрывать.
Именно это решение вы и реализовали, разве нет? Вы попытались сделать из «ручных тестеров» «автоматизаторов», но почему-то не путем повышения квалификации, а путем снижения порога входа и упрощением системы тестов (что само по себе стоит дорого)
В чем-то Вы правы, мы действительно научили ребят из ручного тестирования работе с тестами. Но те задачи, которые они решают, это еще не все задачи, которые в целом существуют в автоматизации.
Они, по сути, работают уже с готовым фреймворком и готовым окружением, в рамках которых пишут новые тесты или правят старые. Но поддержание этой архитектуры, создание базового кода, настойка автозапусков, обновление selenium, браузеров и прочего тоже занимает время. Этим у нас уже по большей части занимаются автоматизаторы.
До этого не так? Как вы убивались об версионирование кода приложения и кода тестов?
До этого мы запускали тесты с ветки Master и вносили изменений тоже в Master. В целом такой подход работал. Но иногда были сложности, да. Например, мы вносили правки к задаче, которая еще была в релизе, а потом ее откатывали. Сейчас, когда мы запускаем тесты с ветки релиза, все стало удобнее и лучше.
Вы не считаете порочным деление на «автоматизаторов»" и «ручных тестеров»? Автоматизация всего лишь инструмент. Ваши автоматизаторы тестировать умеют?
Лично я такое деление не считаю порочным. У нас это скорее не вопрос способности, а определение зоны ответственности. Я прихожу каждый день на работу, пью кофе и сажусь работать с автотестами. Кто-то приходит, кушает булочку и садится тестировать задачи. Каждый занимается своим делом. :)
Спасибо за Ваши вопросы и Ваш отзыв.

Sad_Bro
05.09.2017 17:29Вы используете Codeception?
Если да то чем обусловлен выбор кроме того что cам продукт написан на php? Если использовали менйстрим решения на вроде testNG можете сказать почему не его?
ps. Сам начинал с Codeception, и сейчас перейдя на TestNG и Robot, ловлю себя на мысли как же там было удобно и просто писать тесты.nizkopal Автор
05.09.2017 18:12Когда только начинали писать selenium-тесты, скачали себе последнюю на тот момент версию Facebook Webdriver Framework (https://github.com/facebook/php-webdriver). Сами тесты писали, используя Phpunit Framework (https://github.com/sebastianbergmann/phpunit).
Однако у нас появлялись какие-то свои решения и хотелки, которые мы самостоятельно вносили в FB Framework. Сейчас он довольно сильно переписан и имеет мало общего с текущей версией.
У нас есть внутренние проекты, которые мы покрываем новой версией FB Framework и собираем все через Composer, стараясь не влезать в код библиотек. Не могу сказать, что это принесло какие-то плюшки против собственного фреймворка. Просто эти проекты поменьше и тестов там тоже меньше.
Codeception мы не пробовали внедрять. В тесты для боевого проекта это будет сделать неоправданно сложно. Возможно мы опробуем его на каком-то из внутренних проектов и тогда я напишу свое мнение. :)

Gennadii_M
06.09.2017 09:49Вообщем, было принято решение не нанимать автоматизаторов с улицы, а делать автоматизаторов внутри. Чем это не увеличение штата. Принципиально другим решением было бы какое-о изменение процесса, которое вело бы к более стабильным тестам или что-то вроде того. Ваше решение — это увеличение manpower так или иначе. А что делать мануальным тестировщикам, которые из-за увеличения загрузки автоматизацией, не будут успевать делать свои задачи? Они кого будут привлекать и обучать своим активити? Или они всё же будут кого-то нанимать?
nizkopal Автор
06.09.2017 13:44Принципиально другим решением было бы какое-о изменение процесса, которое вело бы к более стабильным тестам или что-то вроде того.
Одно другому не мешает. Со стороны тестов тоже были сделаны изменения. Я об этом писал в той части, где рассказывал о подготовительных работах, о TeamCity, и о сломанных и нестабильных тестах.
А что делать мануальным тестировщикам, которые из-за увеличения загрузки автоматизацией, не будут успевать делать свои задачи?
Вы же понимаете, что автоматизаторы не бегают среди прикованных цепями ручников, заставляя во что бы то не стало править тесты и наливать себе кофе?
Если у тестировщика задача сверх срочная и большая — хотя я упоминал в статье, что такое бывает не часто и давал ссылку на статью, где мы рассказываем, как планируем сроки — само собой, он может обратиться за помощью ко мне или другому автоматизатору и мы поможем ему поправить тесты. Главное, что мы сделает это до того, к задача окажется в релизе. Это и есть то принципиально новое, о чем Вы спрашиваете, как мне кажется.
Если же в задаче надо поправить один-два локатора, согласитесь, это не сильно замедлит тестирование задачи и не отнимет много времени у тестировщика.
NeverIn
Какой бонус получает ручной тестировщик от того, что у него добавляется еще и автоматизация? Он занимает позицию автотестера? Или получает как ручной, а работает как автоматизатор? Исходя из текста вы против роста штата автоматизаторов.
nizkopal Автор
Спасибо за вопрос. Чтобы ответить на него, прежде всего я предлагаю разделить автоматизацию, как позицию в отделе QA, и автотесты — инструмент для тестирования.
Любой тестировщик, если он чувствует ответственность за свою работу, хочет, чтобы его задача была протестирована хорошо. Автотесты — это прерасный инструмент, позволяющий легко и быстро проверить регрессию, убедиться, что все работает как раньше. Умение работать с автотестами упрощает тестирование задачи. А чтобы уметь работать с автотестами, нужно этому научиться.
Что касается позиции автоматизатора, то, по моему опыту, далеко не все хотели бы заниматься этим на фултайм. Кому-то интереснее тестировать проект на уязвимости, кому-то заниматься менеджментом, иметь компонент и отвечать за него, кому-то интересно заниматься другими тулзами для тестирования. А кто-то любит разнообразие и вполне непрочь написать один или два теста в неделю. Но чтобы чаще, увольте!
Никто не заставляет насильно сидеть и заниматься тестами сверх определенного минимума — уметь разобраться в упавшем тесте, быть способным его поправить или описать баг, которые этот тест поймал. Вот, пожалуй, и все.
DSLow
Можно было бы в одну строку уместить «Они ничего не получают сверху. По нашим ожиданиям они должны быть рады интересным задачам и возможностям».
nizkopal Автор
Можно было и так написать. Но я боялся, что подобной формулировкой не донесу свою основную мысль. Автотесты — это инструмент, который в умелых руках упрощает и ускоряет работу тестировщика. Умение с ним работать — само по себе профит. Не считая того, что это дополнительный навык работы с кодом в целом, что довольно важно в IT-индустрии.
eloin
Это не совсем так.
1. Лиды учитывают вклад ручных тестировщиков в автоматизацию при проведении ревью (подробнее можно почитать тут: habrahabr.ru/company/badoo/blog/331570). Т.е. наличие автоматизации влияет на размер премии.
2. Кроме того, суммарный вклад в автоматизацию влияет на внутренний уровень сотрудника департамента QA (чем больше вклад, тем больше вероятность подняться на следующий уровень; чем выше уровень, тем выше з/п).
3. Ну и на самом деле даже в ручное тестирование мы стараемся набирать высококлассных специалистов, что позволяет нам в рамках одного уровня делать з/п одинаковой и ручным тестировщикам, и автоматизаторам (уверяю вас, задачи на ручное тестирование у нас ничуть не менее интересные/сложные/трудоемкие, чем задачи на автоматизацию).
rmpl
Не знаю, как в Badoo, но крутой ручной тестировщик by design не получает меньше крутого автоматизатора :) Поэтому не понимаю ваш вопрос.
Free_ze
By design работа автотестера предполагает наличие специальных навыков, это должно учитываться. Так что дело здесь, скорее, в различной степени «крутости». Типичные автотестеры получают выше типичных мануальщиков.
Marsikus
Обычно на вакансиях Manual QA, которые я видел, величина зарплаты поменьше.
Но там где мне приходилось работать, разделения на manual и automation QA не было. Все были вовлечены в автоматизацию, соответсвенно от senior qa ожидают больших навыков автоматизации, чем от junior.