
Дмитрий Соболев, Игорь Мастерной, Рафаэль Зубаиров
Не заметить, как быстро растет общий объем собираемых метрик, просто невозможно. Увеличивается не только частота с которой автоматические системы собирают данные, пропускная способность хранилищ данных, но и сам набор метрик, которые мы можем использовать. Эта тенденция наиболее явно выражена в IoT, но и другие отрасли могут похвастаться огромным набором источников данных — публичных или доступных по специальной подписке.
Увеличение объема данных создает новые вызовы для аналитиков и специалистов, работающих над оптимизацией бизнес-задач. Темпы развития мировой экономики увеличиваются, но именно быстрая реакция на изменения на микроуровне позволяет отдельным компаниям расширяться. И здесь на помощь приходят инструменты анализа данных и машинного обучения.
В 2000-х машинное обучение и глубокий анализ данных были уделом университетских групп и специализированных стартапов. Сегодня любая компания имеет доступ к практически неограниченному и алгоритмов, подходов и готовых решений для создания автоматических систем, а также целому набору продуктов для анализа данных.
Машинное обучение сейчас используется не только корпорациями уровня Microsoft и Google, даже небольшие компании могут воспользоваться преимуществами, которые дает качественный анализ данных или система рекомендаций. Если до недавнего времени применение подобных методов требовало найма программистов, аналитиков, дата-сайентистов, то сейчас на рынке появляются сервисы и приложения для машинного обучения, которые позволяют в более дружелюбной форме, с использованием графического интерфейса, обрабатывать данные и строить предсказательные модели. Использовать их способен даже человек с минимальными знаниями в этой области.
Сейчас тройка лидеров в автоматизированном и упрощённом машинном обучении состоит из DataRobot, RapidMiner и BigMl. В этой статье мы подробно рассмотрим RapidMiner — расскажем о том, что он умеет и как может вам облегчить жизнь.
RapidMainer
Любому бизнесу критически важно оценивать показатель “work force” в отдельные периоды времени. Это позволяет планировать бизнес-проекты, которые всегда во многом завязаны на человеческие ресурсы. Дополнительным фактором риска могут служить сезонные всплески простудных заболеваний: каждый год зимой приличный процент сотрудников оказывается на больничных. В результате сроки окончания проектов сдвигаются, а любая компания, разумеется, таких сдвигов хотела бы избежать. В этом может помочь машинное обучение.
С помощью RapidMiner мы проанализируем данные о простудных заболеваниях и построим модель, способную предсказывать вспышки болезней. Исходя из результатов прогноза, компания сможет заранее принять меры и избежать убытков.
Давайте познакомимся с программой:
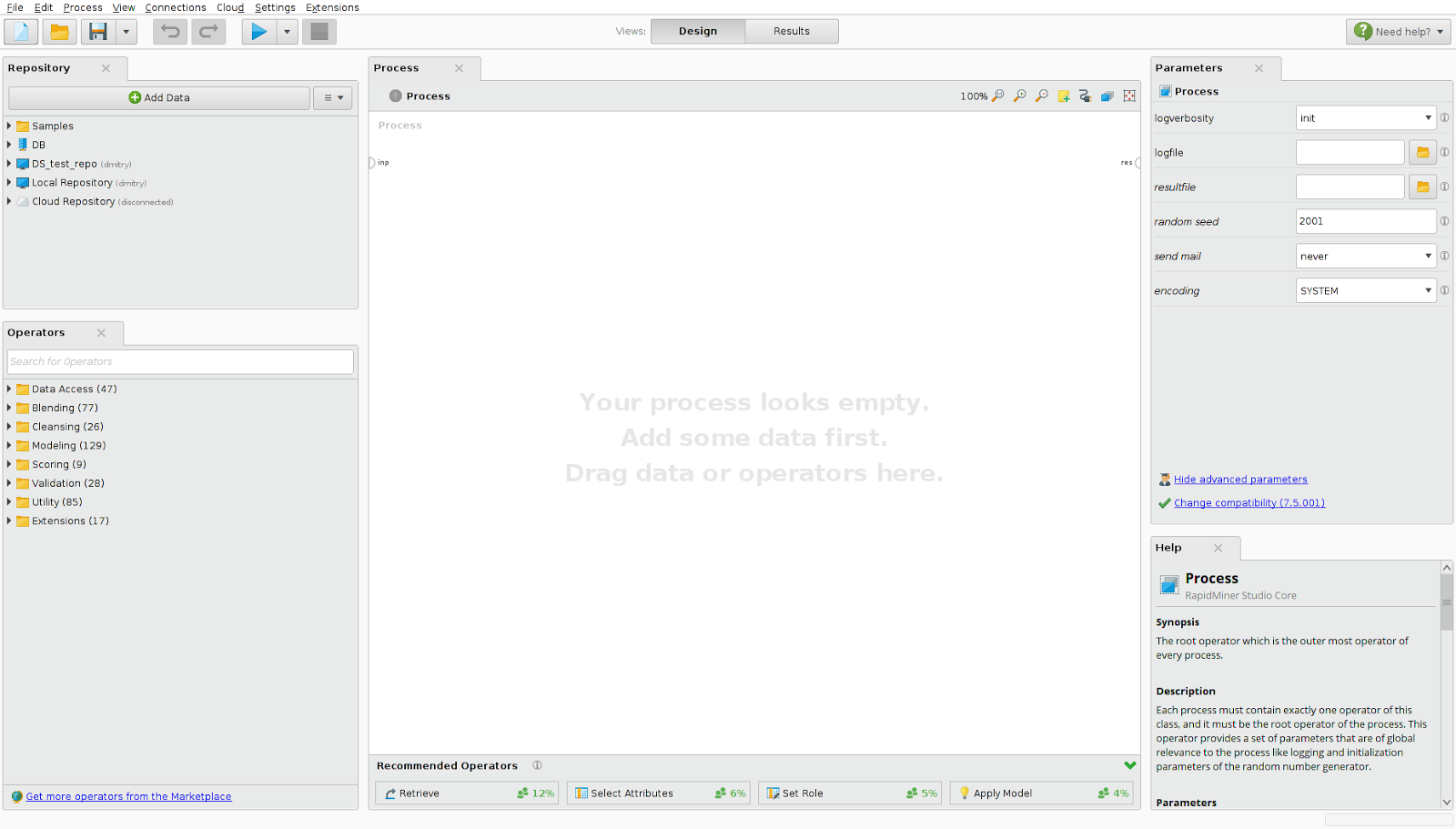
Рис. 1 Экранная форма программы RapidMiner.
В левой части экрана расположены панель загрузки данных и панель операторов. RadpidMiner предоставляет возможность загрузки данных из БД или облачных хранилищ (Amazon S3, Azure Blob, Dropbox). Набор операторов для удобства разделен на категории:
- доступ к данным (работа с файлами, БД, облачными хранилищами, Twitter streams);
- операторы работы с атрибутами датасетов: преобразование типов, дат, операции над множествами и т. д.;
- операторы математического моделирования: прогнозные модели, модели кластерного анализа, оптимизационные модели;
- вспомогательные операторы: запуск Java и Groovy-подпрограмм, анонимизация данных, отправка почтового сообщения, планировщики событий.
Мы описали некоторые из основных категорий, в каждой из которых есть свои подкатегории и различные вариации операторов. Стоит обратить внимание на возможность добавления операторов из постоянно растущего RapidMiner Marketplace. Например, среди доступных расширений имеется оператор, позволяющий преобразовывать наборы данных в time series.
В центральной части экрана расположена рабочая область для создания процессов преобразования данных. С помощью drag and drop мы добавляем в процесс данные, с которыми будем работать, и операторы преобразования данных, моделирования и т. д. Задавая связи между данными и операторами, мы задаем ход выполнения процесса. Внизу по центру панель с подсказками — основываясь на процессах, построенных другими пользователями, она советует вам, какую операцию произвести следующей. Справа панель с параметрами выбранной операции и подробная документация параметров и принципов работы.
Для начала загрузим данные (см. Рис 2) о количестве украинских поисковых запросов в Google, связанных с простудой. Пример данных вы можете увидеть в Таблице 1 раздела Приложения.
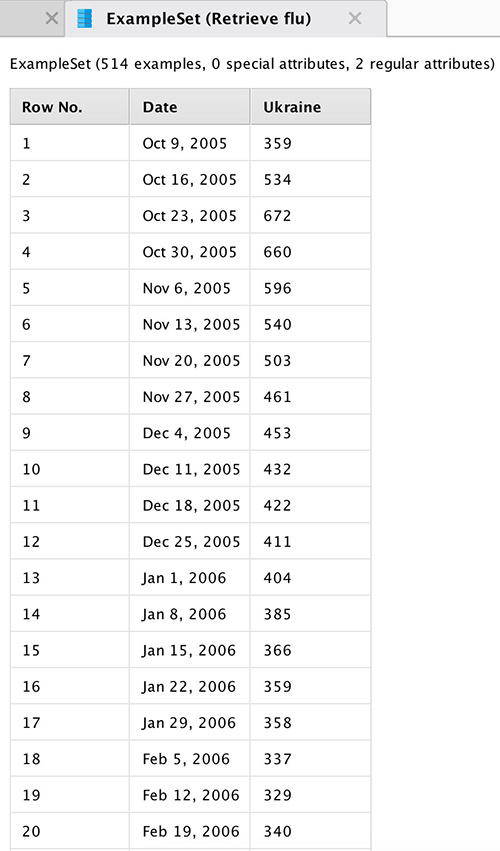
Рис. 2 Вид данных по Украине
Данные представляют собой количество запросов на конец недели с 2005 по 2015 год. При импортировании данных необходимо задать формат даты для корректного построения временных графиков. Соединим выход блока данных с точкой вывода результатов процесса (res). При нажатии кнопки «старт» программа покажет общую статистику. Результаты работы отражены на Рис. 4.
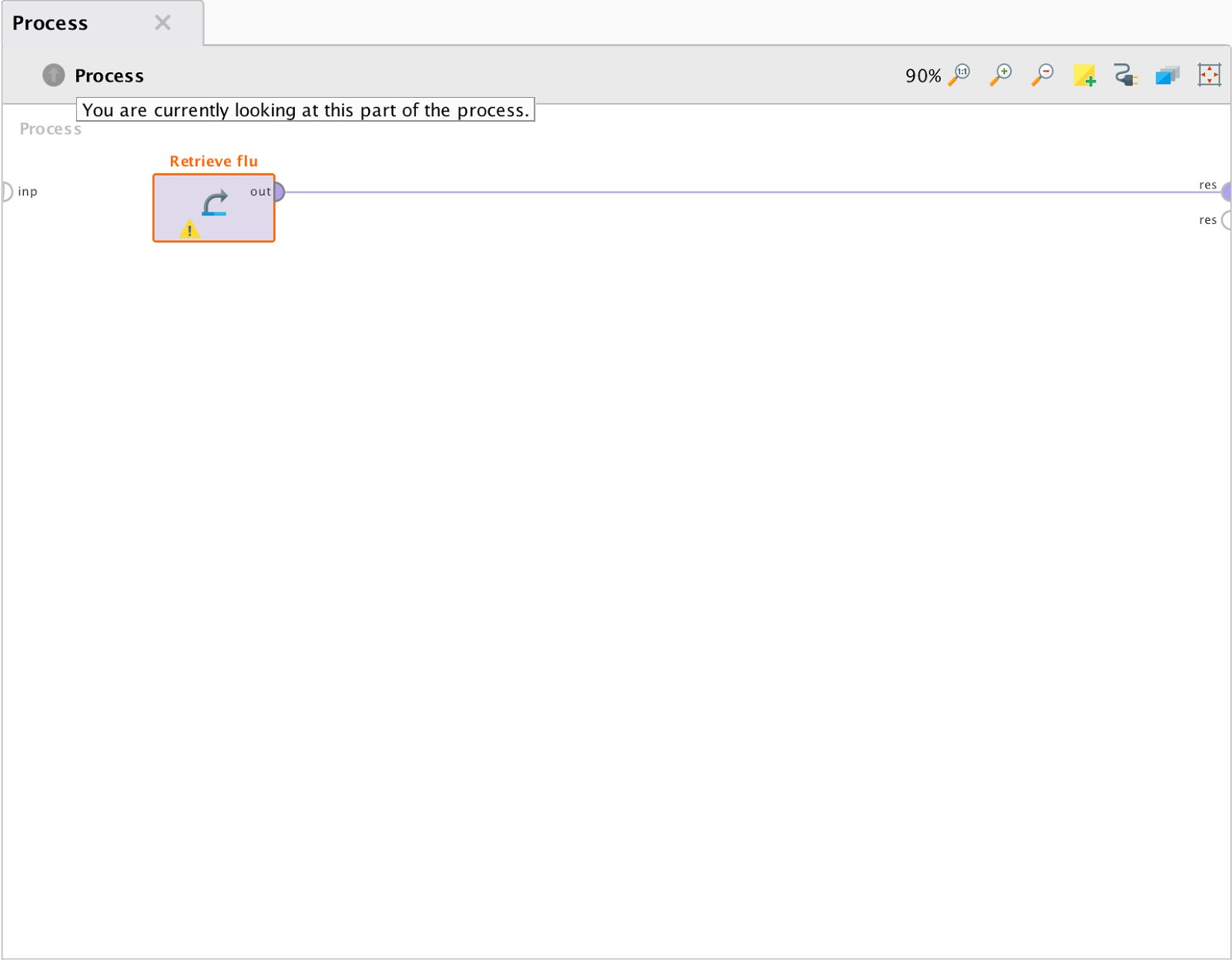
Рис. 3 Процесс формирования общей статистики.
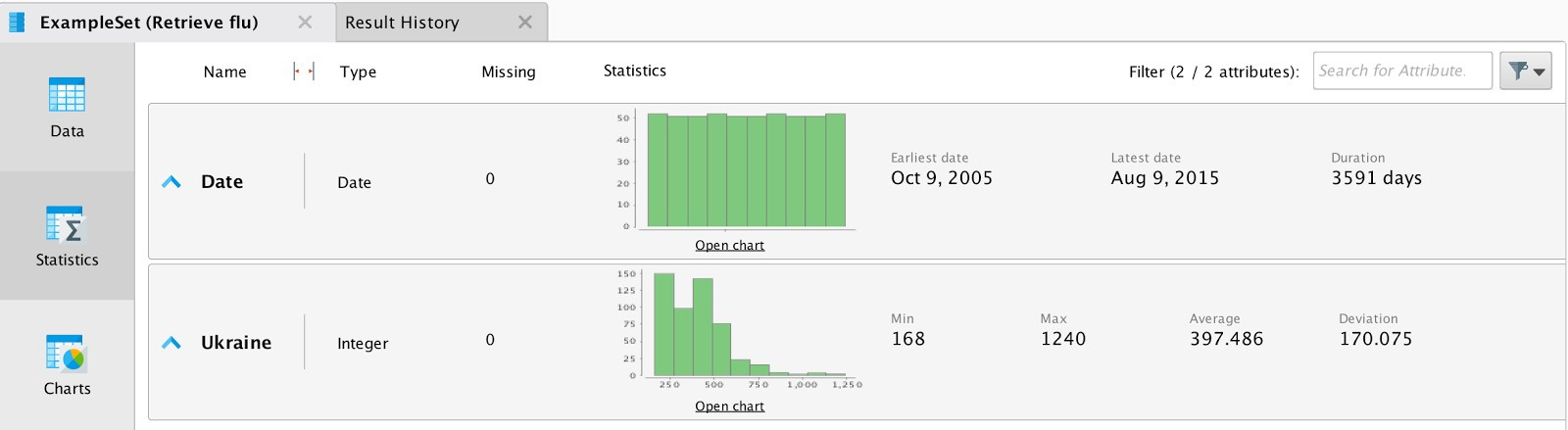
Рис. 4 Общая статистика для данных по Украине.
Используя вкладку Charts, построим график распределения данных (Рис. 5). График отражает очевидную периодичность заболеваемости простудой: первая волна начинается осенью, а пик мы можем наблюдать к февралю. Теперь возьмём данные для России и посмотрим сохранится ли в них такая же периодичность, совпадают ли вспышки с теми периодами, которые мы выделили в Украине. Для этого загружаем новые данные и объединяем их с загруженными ранее; объединение производим по полю Дата с помощью оператора “Join”.
На графиках, изображенных на Рис. 5 и 6, мы можем видеть, что цикличность сохраняется и пики заболеваемости практически совпадают.
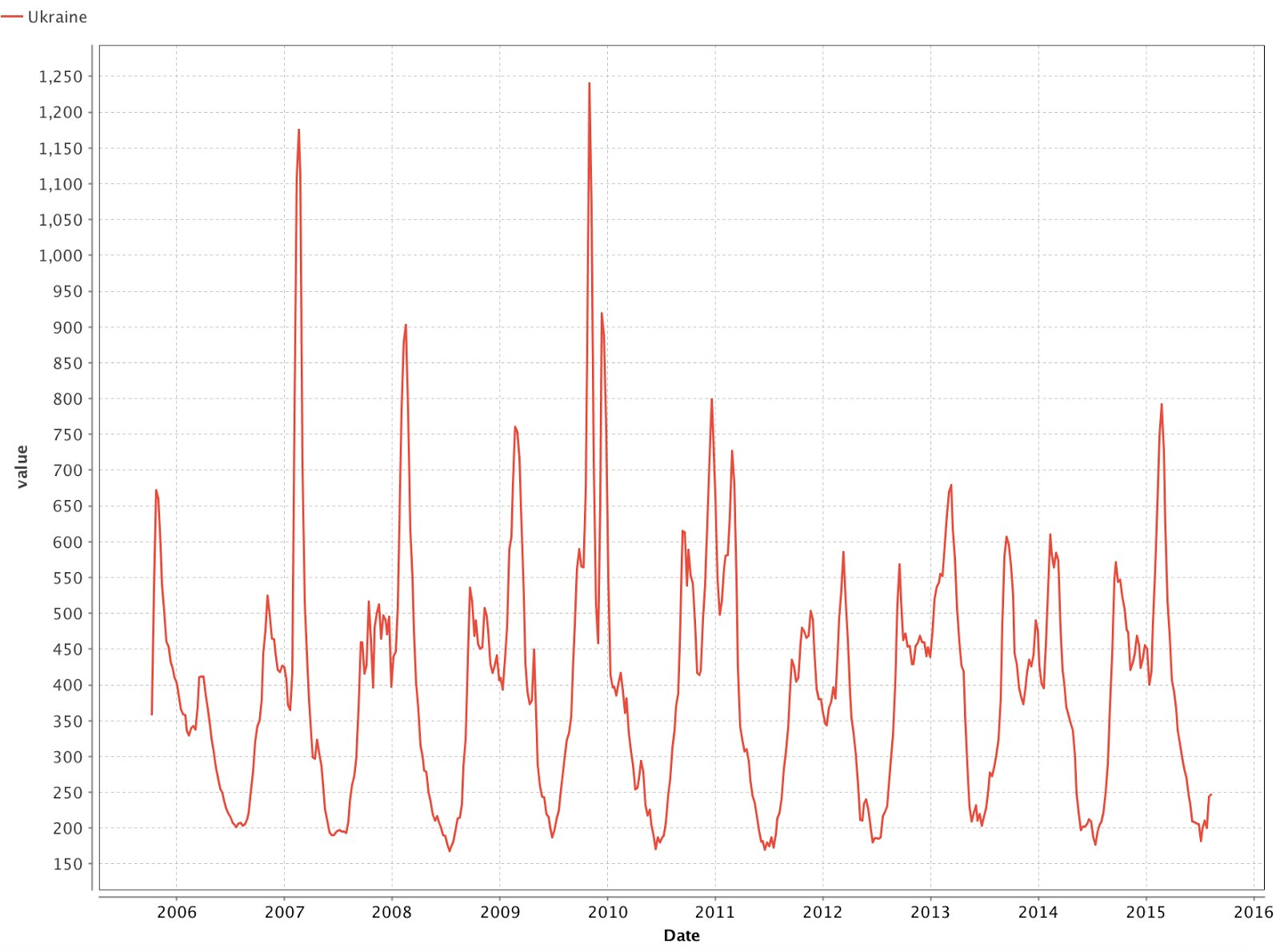
Рис. 5 Количество запросов о простуде с 2005 года.
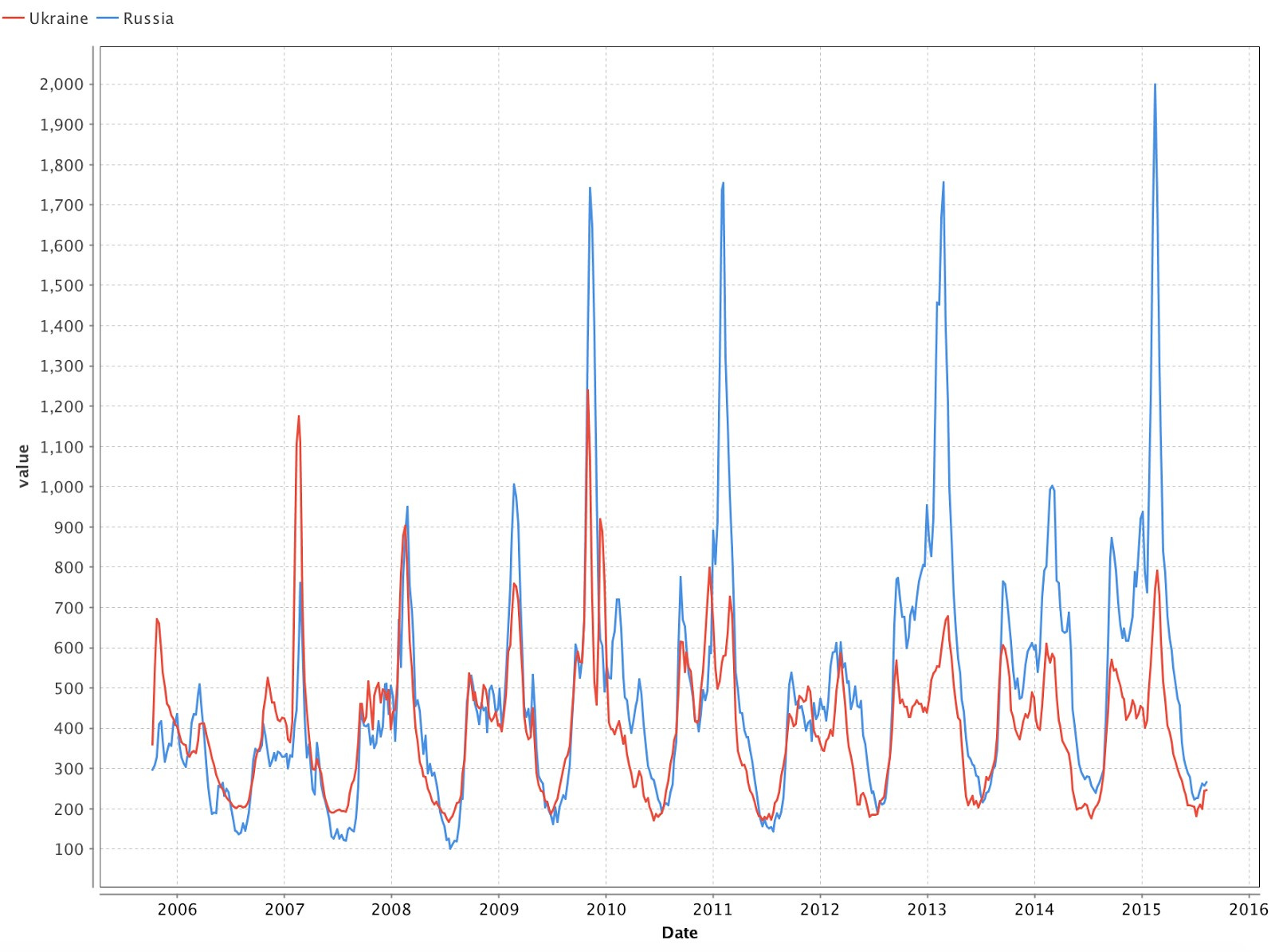
Рис. 6 Данные о простуде для Украины и России.
Построение модели
Перейдем к построению модели, которая будет предсказывать количество заболевших в Украине. Прогнозировать будем значение ряда на следующую неделю на основании значений четырех предыдущих недель (примерно одного месяца). В этой статье мы используем нейронную сеть прямого распространения для прогнозирования временного ряда. Выбор нейронных сетей обоснован простотой подбора параметров модели и их дальнейшего использования. В отличии от моделей авторегрессии и скользящего среднего нейронные сети не требуют проведения корреляционного анализа временного ряда.
На Рис. 7 изображена схема процесса, позволяющего прогнозировать значения временного ряда:
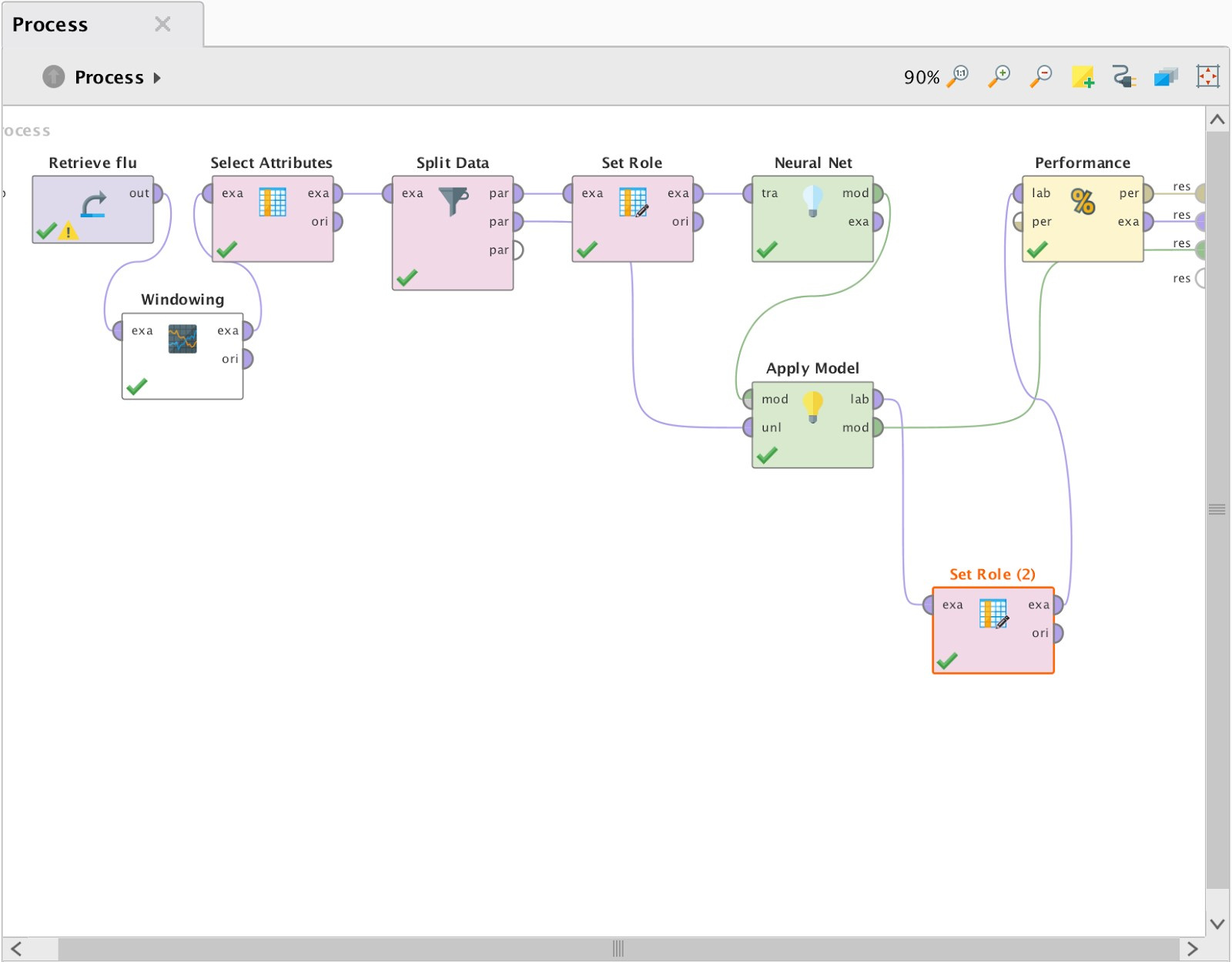
Рис. 7 Процесс построения прогноза в RapidMiner.
Для корректной работы оператора нейронной сети необходимо преобразовать изначальный временной ряд в формат обучающей выборки. Для этого мы использовали оператор Windowing из пакета расширений Series Extension. Таким образом из столбца значений мы получили таблицу вида:
Таблица 1. Представление обучающей выборки для нейронной сети

Далее с помощью оператора “Select Attributes” мы убрали из выборки лишние поля (даты для значений 1—4). Обучение нейронной сети с учителем предполагает наличие обучающей и тестовой выборки, поэтому с помощью оператора “Split Data” мы разделили ВР в пропорции 80 на 20. Согласно документации оператора “Neural Net”, необходимо, чтобы столбец прогнозируемых значений в обучающей выборке имел название/роль “Label”, для чего был использован оператор “Set Role”. Поскольку столбец “Дата прогноза” не участвует в прогнозировании, ему необходимо присвоить роль “Id”. Второй выход оператора “Split Data” и выход “mod” оператора “Neural Net” соединяем с соответствующими входами “ApplyModel”. Оператор “Apply Model” подает на вход натренированной модели контрольную выборку и сопоставляет прогнозируемое и реальное значения. Завершающий этап нашего процесса — оператор “Performance”, необходимый для определения погрешности результатов. Прогнозируемому значению, полученному от “Apply model” с помощью “Set Role(2)”, была присвоена роль “Prediction”.
Рассмотрим параметры используемых операторов нейросети и погрешности вычислений. Опытным путем мы пришли к архитектуре нейронной сети, изображенной на рис 8. Нейронная сеть (deep feed forward neural network) имеет 2 скрытых слоя: 4 нейрона в первом и 12 во втором. В качестве функции активации использовали сигмоиду. Обучение проводилось на нормализованных входных данных с коэффициентом обучения 0.5 и количеством циклов 1500.
Результаты прогнозирования
RapidMiner в качестве результата нашей модели предоставляет три артефакта:
модель: ее графическое представление, параметры и векторы весов;
результаты подсчитанных погрешностей;
выборку тестовых данных, дополненную столбцом прогнозируемых значений.
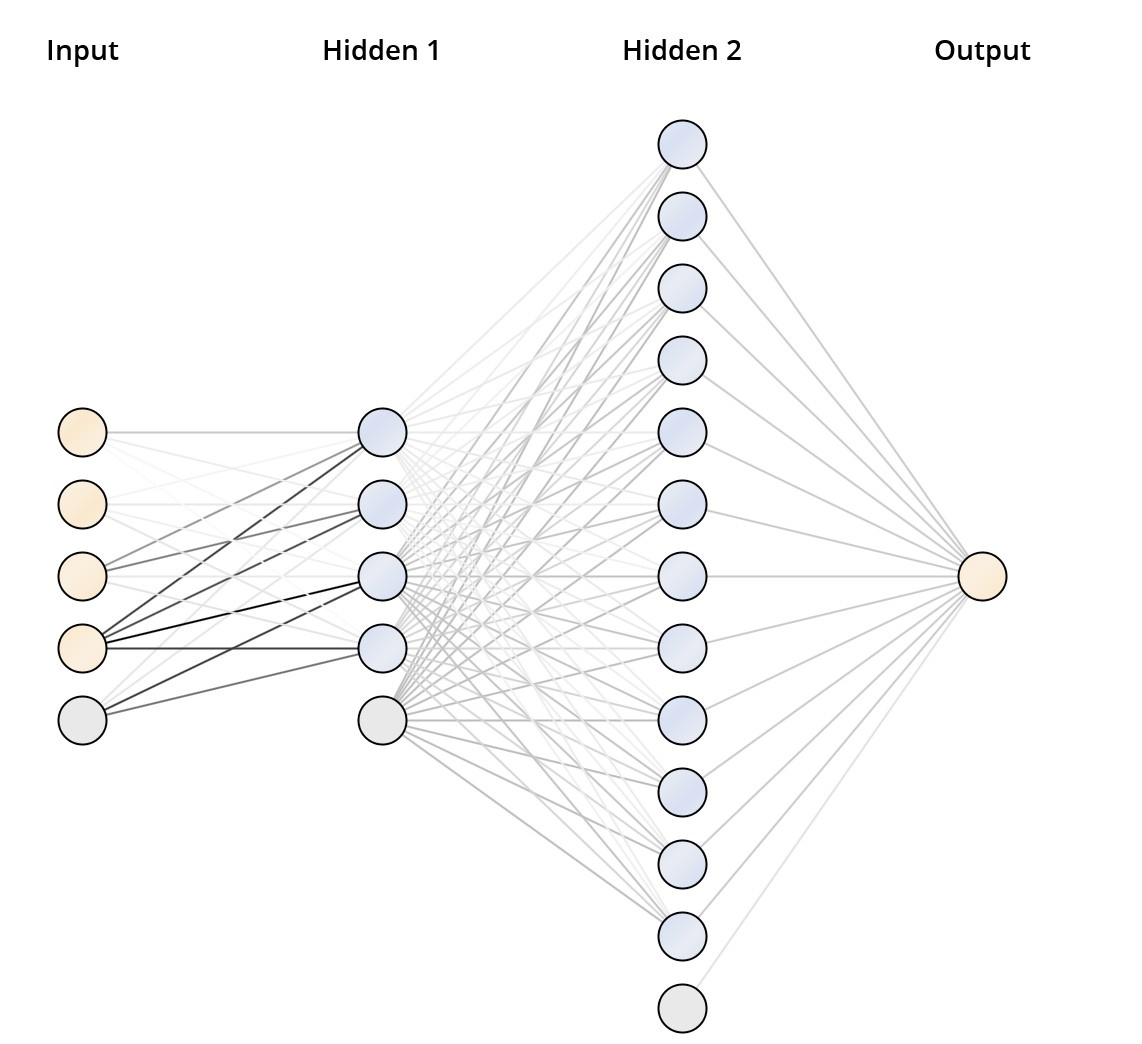
Рис 8. Архитектура нейронной сети
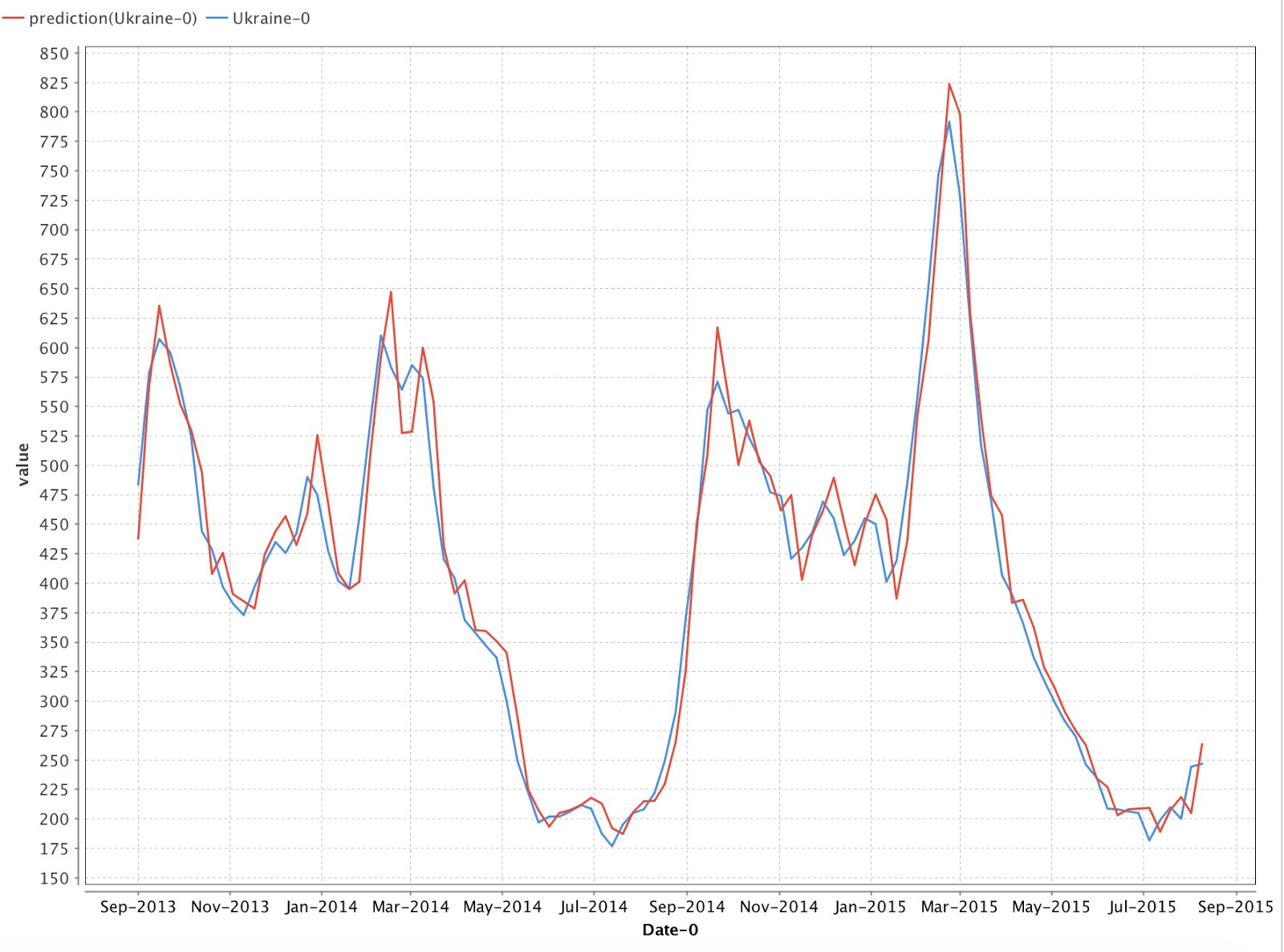
Рис. 9 График прогнозируемых и реальных значений
На рис. 9 мы можем увидеть результат прогнозирования. Как видите, график с предсказанными данными очень близок к реальным данным. Оценим результаты построенной модели, рассчитав погрешность прогноза по формулам (1, 2).
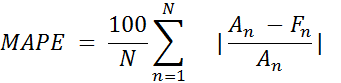
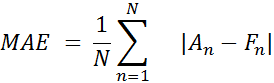
где An— реальное значение, Fn— прогнозируемое значение
В результате вычислений мы получили:
MAPE = 5.47% (3)
MAE = 21.748 (4)
Выводы
Массовое внедрение технологий машинного обучения повлекло за собой создание инструментария различной степени сложности для конечного пользователя. Представленная в статье программа Rapid Miner, снижает порог вхождения для начала изучения технологий Machine Learning.
Если вы используете эту программу, вам не нужно уметь писать код на Python или R. Rapid Miner всячески подсказывает следующее действие в цепочке подготовки данных, тренировки модели, её валидации и оценки точности. Он позволяет автоматически исправлять некоторые ошибки в процессе, может помочь и объяснить отдельные, не до конца понятные вам моменты.
При написании статьи мы изучили функционал RapidMiner. Он довольно обширен и предоставляет возможность применения сложных архитектур нейросетей и более тонкой настройки их параметров: выбора функции активации, конфигурации нейронных связей скрытых слоев и т. д. Наличие лицензии позволяет производить вычисления в облаке Rapid Miner, что должно сократить время обучения и ускорить процесс по дургим характеристикам. Кроме того, лицензия позволяет загружать больше данных и не ограничивает пользователя десятью тысячами строк.
Построенная в статье математическая модель достигла погрешности около 6% на тестовых данных и с некоторыми изменениями может быть использована для прогнозирования роста простудных заболеваний. Однако нашей основной целью было показать простоту и лаконичность использованной программы.
Используя Rapid Miner и подобный подход, любая компания может предсказывать ситуации, подобные вспышкам простудных заболеваний. Превентивные меры, принятые на основе прогноза, позволяют сократить риски и в конечном счете повысить прибыль.
Список использованных материалов
- Google Flu Data Russian Federation
- Google Flu Data Ukraine
- Using RapidMiner for time series forecasting in cost modeling: 1 of 2
Приложения
Таблица 1. Пример данных для Украины и России
| Date | Ukraine | Russia |
|---|---|---|
| 9/10/2005 | 359 | 296 |
| 16/10/2005 | 534 | 307 |
| 23/10/2005 | 672 | 329 |
| 30/10/2005 | 660 | 411 |
| 6/11/2005 | 596 | 417 |
| 13/11/2005 | 540 | 371 |
| 20/11/2005 | 503 | 316 |
| 27/11/2005 | 461 | 341 |
| 4/12/2005 | 453 | 362 |
| 11/12/2005 | 432 | 357 |
| 18/12/2005 | 422 | 415 |
| 25/12/2005 | 411 | 409 |
| 1/1/2006 | 404 | 436 |
| 8/1/2006 | 385 | 362 |
| 15/1/2006 | 366 | 327 |
| 22/1/2006 | 359 | 313 |
| 29/1/2006 | 358 | 304 |
| 5/2/2006 | 337 | 329 |
| 12/2/2006 | 329 | 344 |
| 19/2/2006 | 340 | 413 |
Комментарии (4)

yusman
08.09.2017 10:47Не упомянули что продукт OpenSource(с некоторыми ограничениями).
Давно пользуюсь данным тулом для прототипирования, как ML для домохозяек самое оно. Буквально нажал пару кнопок, получил модель, построил графики и работаешь.
Но делать пока что то серьезное на RapidMiner не удобно.
DanteAlighieri
08.09.2017 13:04ограничения касаются кол-ва записей, которые можно процессить. По моему не более 10 тысяч, если больше — то нужна платная версия. На счет «чего то серьезного», почему то забыл добавить описание возможности создания своих процессов/операторов, а так же возможности добавить оператор скриптов, написанных на Java, или Python.
Тула действительно удобная для быстренького прототипирования и демок перед заказчиками.yusman
08.09.2017 13:53ограничения касаются кол-ва записей, которые можно процессить. По моему не более 10 тысяч, если больше — то нужна платная версия.
Можно скомпилить OpenSource-версию(есть на гитхабе), позволяет обрабатывать больше 10к, но там нет некоторого полезного функционала.
dizzy321
Теперь чтобы стать Data scientist достаточно просто скачать программу?