
Тема облаков в последнее время становится все более и более востребованной. Теперь уже и в РФ компании всё чаще понимают, зачем им это облако может пригодиться и даже начинают его активно использовать. Чем больше компании проявляют интерес к облакам, тем больше возникает вопросов и к нам, разработчикам софта для облака, — по реализации новых тенденций и технологий, и к сервис-провайдерам, которые обеспечивают отказоустойчивую работу платформы в целом.
В этой статье хотелось бы поделиться опытом лишь об одной из сторон работы облака, но, при этом, возможно, самой сложной и важной — это реализация дискового пространства. Статья подготовлена Андреем Нестеренко, экспертом по облачным технологиям компании MIRhosting, которая является одним из хостинг-провайдеров, использующим Jelastic PaaS, который в прошлом месяце анонсировал открытие третьего региона облачной платформы — в России.

Сначала немного вводной информации о том, как работает облачная платформа в целом. Да, мы говорим именно об облачной платформе, а не о продаже VPS и именованием сего действия Облаком. По нашему пониманию, ключевые отличия это отказоустойчивость (что, в частности, автоматически исключает использование локального хранения данных), доступ к «неограниченному» пулу ресурсов в любой момент времени, и оплата по факту использования этих ресурсов, а не за лимиты или тарифы. Техническая реализация такого облака требует совместной работы всех элементов: оборудование, сеть, оркестрация, техническое сопровождение.
Ниже расскажем о том, как мы реализовали лишь одну составляющую — отказоустойчивое дисковое пространство.
Технологически, хранилище данных работает на базе Virtuozzo Storage. Для тех кто не знаком идея аналогична другим реализациям SDS, наиболее известным решением с открытым исходным кодом является Ceph. Выбор Virtuozzo Storage, а не Ceph связан прежде всего с коммерческой поддержкой и развитием, лучшими характеристиками производительности, и «заточенностью» под живую миграцию контейнеров и как следствие — отказоустойчивостью этих контейнеров. Также важной причиной стало то, что Jelastic предлагает такую интеграцию с VZ SDS из коробки. Я буду писать про Virtuozzo Storage, но с небольшими изменениями. Все это может быть применимо и к Ceph, и к другим аналогичным решениям.
Итак, архитектурно в Virtuozzo Storage есть 2 компонента: Metadata Servers и Chunk Servers. Данные режутся на так называемые chunks, т.е. по сути бинарные «куски». Эти «куски» размазываются по Chunk Servers, которых может и должно быть как можно больше. На практике, Chunk Servers — это отдельный диск (не важно, HDD или SSD или NVME), то есть если у нас есть один сервер с 12 дисками, то у нас будут 12 Chunk Servers, которые обеспечивают RAID 0 производительность. Конечно, таких отдельных серверов должно быть несколько, чтобы гарантировать отказоустойчивость, 5 — минимальное рекомендуемое количество. Чем больше серверов и чанков на них, тем лучше производительность и быстрее репликация в случае выхода из строя отдельных чанк-серверов.
Метаданные сервера, соответственно, управляют всем этим бардаком из кусков данных, размазанных по множеству чанк-серверов. Для корректной работы требуется только один сервер метаданных, однако если он выйдет из строя, то весь кластер станет недоступным. С другой стороны, чем больше серверов метаданных, тем больше проседает производительность, так как любое i/o действие кластера должно записываться на все больше серверов. Также есть классическая проблема с split brain: в случае выхода из строя одного или нескольких серверов метаданных, остальные должны остаться в «большинстве», чтобы быть гарантированно активными и единственными. Обычно для маленьких кластеров делаются 3 сервера метаданных, а для более крупных — 5.
Так выглядит типовой кластер:

(картинка из блога Virtuozzo, думаю, ребята не будут против)
Администратор кластера может установить в глобальных настройках, сколько реплик должно быть гарантированно доступно. Другими словами, сколько чанк серверов может выйти из строя без потери данных? Предположим, у нас физически 3 сервера, в каждом из которых 3 диска (чанк-сервера) и мы поставили рекомендуемое значение: 3 реплики. Первое, что приходит в голову: что произойдет, если выйдет из строя один сервер целиком и, соответственно, 3 чанк-сервера на нем?
Если 3 реплики каких-то данных были записаны как раз на эти 3 чанк-сервера в рамках одного физического сервера, то эти данные будут потеряны, несмотря на то что у нас остались еще 2 физических сервера онлайн с 6 чанк-серверами на них. Чтобы управлять такой ситуацией, можно настроить различного уровня репликации: на уровне чанк-серверов (не рекомендуется), на уровне хостов (по умолчанию) или на уровне стойки и на уровне здания/локации.
Возвращаясь к нашему примеру выше, при использовании значения по умолчанию — на уровне хостов, сервера метаданных автоматически определяют, какие чанк-сервера размещены на одинаковых физических серверах, и обеспечивают репликацию на разные физические машины. Для того чтобы работала репликация на уровне стойки или локации, нужно указать, какая машина находится в какой стойке и/или локации. В этом случае отказоустойчивость будет работать на уровне разных стоек или даже дата-центров. Именно так сделано у нас в MIRhosting: данные распределены на 2 независимых друг от друга дата-центра.
Итак, используя такие технологии SDS, мы получаем теоретически идеальную отказоустойчивость, однако теория и white paper на сайте это одно, а практика и требовательные клиенты — это совсем другое
Первое, с чем пришлось столкнуться, — это сеть. В нормальной ситуации, трафик между чанк-серверами около 200 мбит и редко превышает 500 мбит. Чем больше серверов, тем больше трафик «размазывается» по разным серверам. Но в случае выхода из строя чанк-сервера/серверов начинается срочная репликация, чтобы восстановить правильный баланс данных. И чем больше у нас серверов, чем больше данных пропало, тем больше данных начинает летать по сети, с легкостью создавая 5 гбит и выше. Итак, 10 гбит сеть — это минимальное требование, также как и 9000 MTU (Jumbo frames). Конечно, если мы хотим обеспечивать действительно хорошую отказоустойчивость и общую стабильность работы, то лучше иметь два отдельных 10 гбит коммутатора и подключать каждое хранилище данных через 2 порта.

Кстати, это заодно решает и такой сложный вопрос, как обновление прошивок в коммутаторах.
Второе, что мы решали, — это обеспечение работы кластера на базе двойных дата-центров. Изначально, сеть для хранилища данных работала на чистом L2. Однако с ростом облачной платформы в целом и объёма хранилища данных как её составной, в частности, мы пришли к логичному решению, что нужно переходить на чистый L3. Данный шаг очень сильно завязан на другой теме — работе контейнеров в условиях двойных дата-центров и живой миграции. Сеть для хранилища данных делалась аналогично внутренней и внешней сети контейнеров, для унификации. Тема достойна отдельной статьи, надеюсь это будет интересно сообществу. Каких-либо деградаций производительности с переходом на L3 замечено не было.
Третье и, вероятно, самое важное — это производительность. Клиенты разные, у них разные требования, разные проекты, и в условиях именно публичного облака это становится сложной проблемой. Само по себе это делится на 2 части: общая производительность i/o кластера и различная требуемая производительность для разных клиентов. Начнем с первой.
Во многом, решение вопроса производительности осуществлялось «методом тыка», так как ни в документации, ни в информации от технической поддержки Virtuozzo, как таковых best practices нет. Очень помог один сотрудник технической поддержки Virtuozzo, который потратил минут 30 своего времени по телефону и очень много чего рассказал. Собрав всю имеющуюся информацию, добавив немного мозгов и пропустив через дуршлаг опыта, пришли к следующей схеме:

Compute Node (нода, где запускаются контейнеры) — система работает на SSD, на нем же размещен pfcache. Второй SSD, а в последнее время NVMe — под кеш клиента. И один или два SSD / NVMe для локальных чанков. Использование RAID1 возможно, но представляется нам на данном этапе развития SSD-накопителей не имеющим особого значения, учитывая автоматическое восстановление контейнеров при отказе (failover) в любом случае. Кеш клиента дает меньший эффект, чем chunk на compute node. Система определяет ближайший доступный чанк и старается использовать его для “hot” данных.
Storage Node (нода, которая используется только для чанков, без контейнеров), очевидно, забита SSD и NVMe. HDD исторически ещё используются, по сути, для обеспечения «холодных» реплик.
Кеширование HDD не используется, да и сами HDD стараемся уже полностью заменять на SSD. Те системы хранения, где ещё есть HDD, обязательно работают через хорошую рейд-карту, RAID0, с кешированием операцией записи, что улучшает производительность этих HDD.
Общая доступная производительность кластера напрямую зависит от количество чанков, т.е. дисков.
Вторая задача — это необходимость регуляции i/o в условиях публичного облака и разных запросов клиентов. На каждый контейнер в облаке ставятся определенные i/o лимиты на количество операций (iops) и пропускной способности (io limit throughput). На данный момент, облако MIRhosting дает по умолчанию 500 iops и пропускную способность в 200 Mb/s, что практически равно двойной производительности SATA HDD диска. Для подавляющего большинства клиентов этих цифр более чем достаточно, учитывая, что эти лимиты даются на каждый контейнер, коих клиент может создавать в любых количествах.
Тем не менее, для некоторых клиентов требуется повышенная i/o производительность. Очевидно, что это решается разными лимитами для разных клиентов,. Но экономически не выгодно иметь кластер, способный давать скажем 10 000 iops на каждый контейнер (и иметь соответствующий запас), и продавать его ресурсы с пониженными лимитами.
Есть хорошее решение — это возможности использовать разные уровни в хранилище данных. Скажем, первый уровень у нас будет построен на SSD + HDD, а второй уровень будет построен на SSD + NVMe.
Мы будем обеспечивать заявленные характеристики и делать это экономически целесообразно (что напрямую связано со стоимостью). Переезд контейнеров из одного уровня в другой происходит “вживую” и реализован в Jelastic PaaS также с почасовой оплатой, как и другие ресурсы облака.
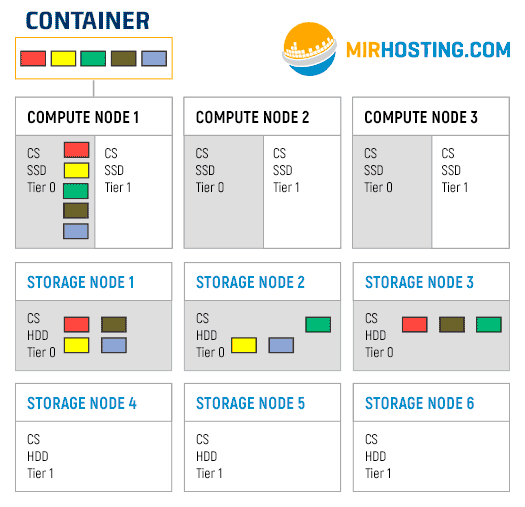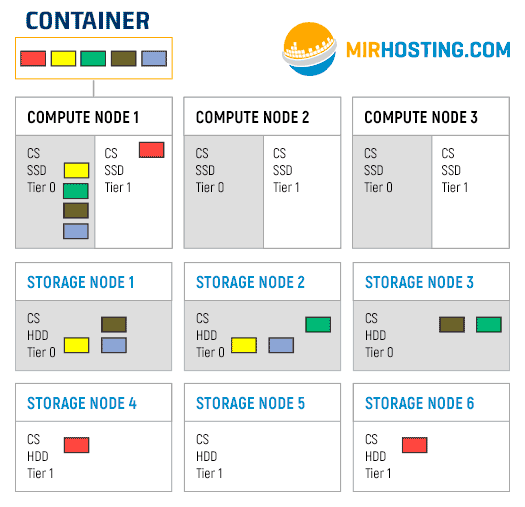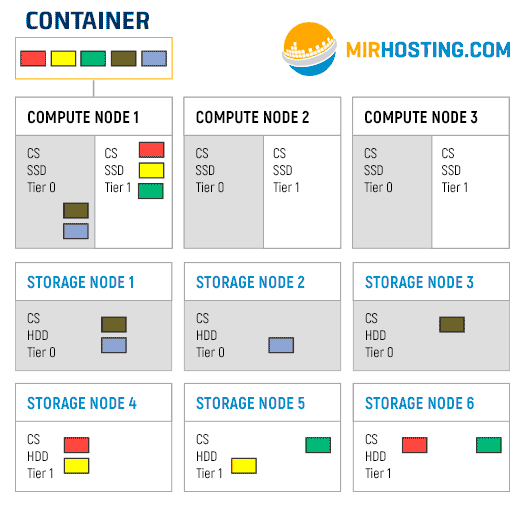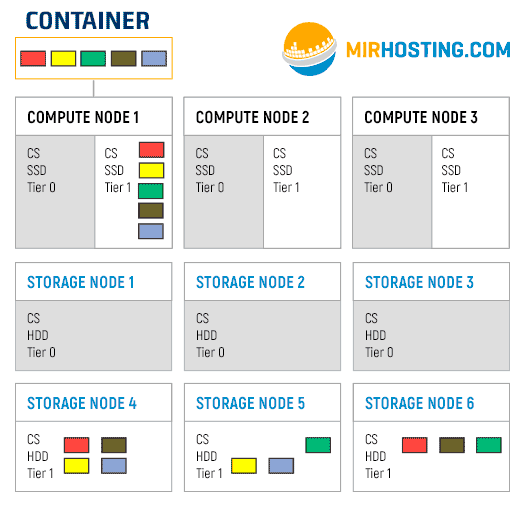
Предположим, у нас есть один контейнер, который расположен на первой Compute node. Его файловая система делится на 5 чанков. Также у нас кластер настроен на использование 3 реплик, то есть каждый чанк будет размещен на 3 разных серверах. Первый слайд гифки — это то, как будут располагаться чанки при размещении на tier 0. Далее показан процесс переползания чанков на носители Tier 1.
На данный момент, ресурсы хранения облака работают достаточно стабильно и сложно представить, как можно жить по-другому. Выход из строя дисков, и даже целиком нод, не создает видимых проблем клиентам и требует плановых действий по замене и добавлению дисков.
P.S. Уже в процессе подготовки этого материала, была опубликована статья habrahabr.ru/post/341168, в которой обсуждаются похожие вопросы и темы. Наша статья отражает несколько иной взгляд на те же задачи и проблемы, и хочется надеяться, что будет полезна сообществу.
Упомянутые минусы в статье было бы интересно также отдельно рассмотреть, но большинство этих минусов связано не с хранилищем данных как таковым, а с более глобальной работой облака, в частности с вопросами миграции.
Если тема интересна, можем поделиться собственными разработками по работе контейнеров в рамках облака на базе двойных дата-центров. В частности, со стороны сети и живой миграции в рамках такой схемы.
В целом, вынужден согласиться с SyCraft, что баги есть, и техподдержка Virtuozzo не всегда может внятно сказать, что и почему случается. Тем не менее, данное решение, по сути, — единственное в своем классе, которое обеспечивает нужный набор сервисов, активно развивается и является коммерческим, то есть поддерживаемым разработчиками.
Попробовать данное решение отказоустойчивого дискового пространства в сочетании с автоматическим распределением и оркестрацией контейнеров с учетом специфики работы конкретного приложения от Jelastic PaaS, а также производительностью MIRhosting инфраструктуры можно зарегистрировавшись по ссылке. Будем рады вашим отзывам.
В этой статье хотелось бы поделиться опытом лишь об одной из сторон работы облака, но, при этом, возможно, самой сложной и важной — это реализация дискового пространства. Статья подготовлена Андреем Нестеренко, экспертом по облачным технологиям компании MIRhosting, которая является одним из хостинг-провайдеров, использующим Jelastic PaaS, который в прошлом месяце анонсировал открытие третьего региона облачной платформы — в России.
Сначала немного вводной информации о том, как работает облачная платформа в целом. Да, мы говорим именно об облачной платформе, а не о продаже VPS и именованием сего действия Облаком. По нашему пониманию, ключевые отличия это отказоустойчивость (что, в частности, автоматически исключает использование локального хранения данных), доступ к «неограниченному» пулу ресурсов в любой момент времени, и оплата по факту использования этих ресурсов, а не за лимиты или тарифы. Техническая реализация такого облака требует совместной работы всех элементов: оборудование, сеть, оркестрация, техническое сопровождение.
Ниже расскажем о том, как мы реализовали лишь одну составляющую — отказоустойчивое дисковое пространство.
Software-defined storage (SDS)
Технологически, хранилище данных работает на базе Virtuozzo Storage. Для тех кто не знаком идея аналогична другим реализациям SDS, наиболее известным решением с открытым исходным кодом является Ceph. Выбор Virtuozzo Storage, а не Ceph связан прежде всего с коммерческой поддержкой и развитием, лучшими характеристиками производительности, и «заточенностью» под живую миграцию контейнеров и как следствие — отказоустойчивостью этих контейнеров. Также важной причиной стало то, что Jelastic предлагает такую интеграцию с VZ SDS из коробки. Я буду писать про Virtuozzo Storage, но с небольшими изменениями. Все это может быть применимо и к Ceph, и к другим аналогичным решениям.
Итак, архитектурно в Virtuozzo Storage есть 2 компонента: Metadata Servers и Chunk Servers. Данные режутся на так называемые chunks, т.е. по сути бинарные «куски». Эти «куски» размазываются по Chunk Servers, которых может и должно быть как можно больше. На практике, Chunk Servers — это отдельный диск (не важно, HDD или SSD или NVME), то есть если у нас есть один сервер с 12 дисками, то у нас будут 12 Chunk Servers, которые обеспечивают RAID 0 производительность. Конечно, таких отдельных серверов должно быть несколько, чтобы гарантировать отказоустойчивость, 5 — минимальное рекомендуемое количество. Чем больше серверов и чанков на них, тем лучше производительность и быстрее репликация в случае выхода из строя отдельных чанк-серверов.
Метаданные сервера, соответственно, управляют всем этим бардаком из кусков данных, размазанных по множеству чанк-серверов. Для корректной работы требуется только один сервер метаданных, однако если он выйдет из строя, то весь кластер станет недоступным. С другой стороны, чем больше серверов метаданных, тем больше проседает производительность, так как любое i/o действие кластера должно записываться на все больше серверов. Также есть классическая проблема с split brain: в случае выхода из строя одного или нескольких серверов метаданных, остальные должны остаться в «большинстве», чтобы быть гарантированно активными и единственными. Обычно для маленьких кластеров делаются 3 сервера метаданных, а для более крупных — 5.
Так выглядит типовой кластер:
(картинка из блога Virtuozzo, думаю, ребята не будут против)
Администратор кластера может установить в глобальных настройках, сколько реплик должно быть гарантированно доступно. Другими словами, сколько чанк серверов может выйти из строя без потери данных? Предположим, у нас физически 3 сервера, в каждом из которых 3 диска (чанк-сервера) и мы поставили рекомендуемое значение: 3 реплики. Первое, что приходит в голову: что произойдет, если выйдет из строя один сервер целиком и, соответственно, 3 чанк-сервера на нем?
Если 3 реплики каких-то данных были записаны как раз на эти 3 чанк-сервера в рамках одного физического сервера, то эти данные будут потеряны, несмотря на то что у нас остались еще 2 физических сервера онлайн с 6 чанк-серверами на них. Чтобы управлять такой ситуацией, можно настроить различного уровня репликации: на уровне чанк-серверов (не рекомендуется), на уровне хостов (по умолчанию) или на уровне стойки и на уровне здания/локации.
Возвращаясь к нашему примеру выше, при использовании значения по умолчанию — на уровне хостов, сервера метаданных автоматически определяют, какие чанк-сервера размещены на одинаковых физических серверах, и обеспечивают репликацию на разные физические машины. Для того чтобы работала репликация на уровне стойки или локации, нужно указать, какая машина находится в какой стойке и/или локации. В этом случае отказоустойчивость будет работать на уровне разных стоек или даже дата-центров. Именно так сделано у нас в MIRhosting: данные распределены на 2 независимых друг от друга дата-центра.
Хватит теории, расскажите что-то действительно интересное
Итак, используя такие технологии SDS, мы получаем теоретически идеальную отказоустойчивость, однако теория и white paper на сайте это одно, а практика и требовательные клиенты — это совсем другое
Первое, с чем пришлось столкнуться, — это сеть. В нормальной ситуации, трафик между чанк-серверами около 200 мбит и редко превышает 500 мбит. Чем больше серверов, тем больше трафик «размазывается» по разным серверам. Но в случае выхода из строя чанк-сервера/серверов начинается срочная репликация, чтобы восстановить правильный баланс данных. И чем больше у нас серверов, чем больше данных пропало, тем больше данных начинает летать по сети, с легкостью создавая 5 гбит и выше. Итак, 10 гбит сеть — это минимальное требование, также как и 9000 MTU (Jumbo frames). Конечно, если мы хотим обеспечивать действительно хорошую отказоустойчивость и общую стабильность работы, то лучше иметь два отдельных 10 гбит коммутатора и подключать каждое хранилище данных через 2 порта.
Кстати, это заодно решает и такой сложный вопрос, как обновление прошивок в коммутаторах.
Второе, что мы решали, — это обеспечение работы кластера на базе двойных дата-центров. Изначально, сеть для хранилища данных работала на чистом L2. Однако с ростом облачной платформы в целом и объёма хранилища данных как её составной, в частности, мы пришли к логичному решению, что нужно переходить на чистый L3. Данный шаг очень сильно завязан на другой теме — работе контейнеров в условиях двойных дата-центров и живой миграции. Сеть для хранилища данных делалась аналогично внутренней и внешней сети контейнеров, для унификации. Тема достойна отдельной статьи, надеюсь это будет интересно сообществу. Каких-либо деградаций производительности с переходом на L3 замечено не было.
Третье и, вероятно, самое важное — это производительность. Клиенты разные, у них разные требования, разные проекты, и в условиях именно публичного облака это становится сложной проблемой. Само по себе это делится на 2 части: общая производительность i/o кластера и различная требуемая производительность для разных клиентов. Начнем с первой.
Во многом, решение вопроса производительности осуществлялось «методом тыка», так как ни в документации, ни в информации от технической поддержки Virtuozzo, как таковых best practices нет. Очень помог один сотрудник технической поддержки Virtuozzo, который потратил минут 30 своего времени по телефону и очень много чего рассказал. Собрав всю имеющуюся информацию, добавив немного мозгов и пропустив через дуршлаг опыта, пришли к следующей схеме:
Compute Node (нода, где запускаются контейнеры) — система работает на SSD, на нем же размещен pfcache. Второй SSD, а в последнее время NVMe — под кеш клиента. И один или два SSD / NVMe для локальных чанков. Использование RAID1 возможно, но представляется нам на данном этапе развития SSD-накопителей не имеющим особого значения, учитывая автоматическое восстановление контейнеров при отказе (failover) в любом случае. Кеш клиента дает меньший эффект, чем chunk на compute node. Система определяет ближайший доступный чанк и старается использовать его для “hot” данных.
Storage Node (нода, которая используется только для чанков, без контейнеров), очевидно, забита SSD и NVMe. HDD исторически ещё используются, по сути, для обеспечения «холодных» реплик.
Кеширование HDD не используется, да и сами HDD стараемся уже полностью заменять на SSD. Те системы хранения, где ещё есть HDD, обязательно работают через хорошую рейд-карту, RAID0, с кешированием операцией записи, что улучшает производительность этих HDD.
Общая доступная производительность кластера напрямую зависит от количество чанков, т.е. дисков.
Вторая задача — это необходимость регуляции i/o в условиях публичного облака и разных запросов клиентов. На каждый контейнер в облаке ставятся определенные i/o лимиты на количество операций (iops) и пропускной способности (io limit throughput). На данный момент, облако MIRhosting дает по умолчанию 500 iops и пропускную способность в 200 Mb/s, что практически равно двойной производительности SATA HDD диска. Для подавляющего большинства клиентов этих цифр более чем достаточно, учитывая, что эти лимиты даются на каждый контейнер, коих клиент может создавать в любых количествах.
Тем не менее, для некоторых клиентов требуется повышенная i/o производительность. Очевидно, что это решается разными лимитами для разных клиентов,. Но экономически не выгодно иметь кластер, способный давать скажем 10 000 iops на каждый контейнер (и иметь соответствующий запас), и продавать его ресурсы с пониженными лимитами.
Есть хорошее решение — это возможности использовать разные уровни в хранилище данных. Скажем, первый уровень у нас будет построен на SSD + HDD, а второй уровень будет построен на SSD + NVMe.
Мы будем обеспечивать заявленные характеристики и делать это экономически целесообразно (что напрямую связано со стоимостью). Переезд контейнеров из одного уровня в другой происходит “вживую” и реализован в Jelastic PaaS также с почасовой оплатой, как и другие ресурсы облака.
Предположим, у нас есть один контейнер, который расположен на первой Compute node. Его файловая система делится на 5 чанков. Также у нас кластер настроен на использование 3 реплик, то есть каждый чанк будет размещен на 3 разных серверах. Первый слайд гифки — это то, как будут располагаться чанки при размещении на tier 0. Далее показан процесс переползания чанков на носители Tier 1.
На данный момент, ресурсы хранения облака работают достаточно стабильно и сложно представить, как можно жить по-другому. Выход из строя дисков, и даже целиком нод, не создает видимых проблем клиентам и требует плановых действий по замене и добавлению дисков.
P.S. Уже в процессе подготовки этого материала, была опубликована статья habrahabr.ru/post/341168, в которой обсуждаются похожие вопросы и темы. Наша статья отражает несколько иной взгляд на те же задачи и проблемы, и хочется надеяться, что будет полезна сообществу.
Упомянутые минусы в статье было бы интересно также отдельно рассмотреть, но большинство этих минусов связано не с хранилищем данных как таковым, а с более глобальной работой облака, в частности с вопросами миграции.
Если тема интересна, можем поделиться собственными разработками по работе контейнеров в рамках облака на базе двойных дата-центров. В частности, со стороны сети и живой миграции в рамках такой схемы.
В целом, вынужден согласиться с SyCraft, что баги есть, и техподдержка Virtuozzo не всегда может внятно сказать, что и почему случается. Тем не менее, данное решение, по сути, — единственное в своем классе, которое обеспечивает нужный набор сервисов, активно развивается и является коммерческим, то есть поддерживаемым разработчиками.
Попробовать данное решение отказоустойчивого дискового пространства в сочетании с автоматическим распределением и оркестрацией контейнеров с учетом специфики работы конкретного приложения от Jelastic PaaS, а также производительностью MIRhosting инфраструктуры можно зарегистрировавшись по ссылке. Будем рады вашим отзывам.
evilbot
А вам хватает производительности 10Гбит сети для стораджа? У нас возникали проблемы с производительностью, из-за того что трафик репликации+трафик на контейнеры/виртуалки был больше чем 10Гбит/с.
gazella
На данный момент 10 гбит хватает более чем. Возможно это связано с количеством нод (чем их больше в кластере, тем меньше трафика стораджа на каждый конкретный сервер). В случае внештатных падений стораджа, трафик репликаций на каждый сервер поднимается до 2-3 гбит. Аплинк коммутаторов конечно уже легко может в 10 гбит упираться, но там 40г и пока далеко до лимитов.
Если упирается в десятку, надо посмотреть что именно расходует полосу, возможно трафик контейнеров а не сторадж? А так решение — добавить двух портовую 10г pcie карту, или уже сразу 40г на будущее, оно не так дорого стоит (относительно конечно). Есть еще вариант с infiniband, нам предлагали на тестирование но так и не дошли до этого. IMHO, это больше под частные облака под корпоративных заказчиков с соответствующими требованиями, мы все же предлагаем публичное облако.
evilbot
Ну мы узнали о том что упираемся в 10Гбит/с в тот момент, когда пришлось отключить одну сетевую карту в бондинге.