
Ну что ж, начнем с того, что такое GraphQL?
GraphQL — это стандарт декларирования структуры данных и способов получения данных, который выступает дополнительным слоем между клиентом и сервером.
Одной из основных фичей GraphQL является то, что структура и обьем данных определяется клиентским приложением.
Рассмотрим пример простого запроса пользователя.
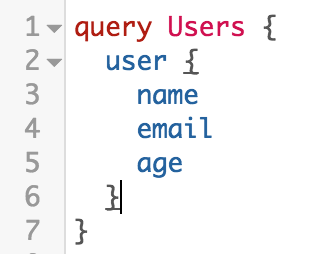
Клиент точно указывает, какие данные он хочет получить, используя декларативную, графо-подобную структуру, которая очень напоминает формат JSON.
В данном случае клиент запрашивает три поля (name, email и age). Но он может запрашивать как одно поле, к примеру name, так и произвольное количество полей, которые определены в типе user на GraphQL сервере.
В таком подходе, помимо удобства, у нас уменьшается либо количество запросов, либо обьем данных на транспортном уровне.
GraphQL облегчает агрегацию данных из нескольких источников.
Давайте рассмотрим простую клиент-сервер архитектуру.

У нас есть клиентское приложение и один сервер. Транспорт данных выглядит довольно просто,
не важно, какой именно протокол передачи данных для этого используется. В случае http мы посылаем запрос и получаем ответ, все довольно просто.

Как я уже говорил, GraphQL является дополнительным слоем между клиентом и сервером, и если посмотреть на эту архитектуру, то использование GraphQL выглядит вроде как избыточно.
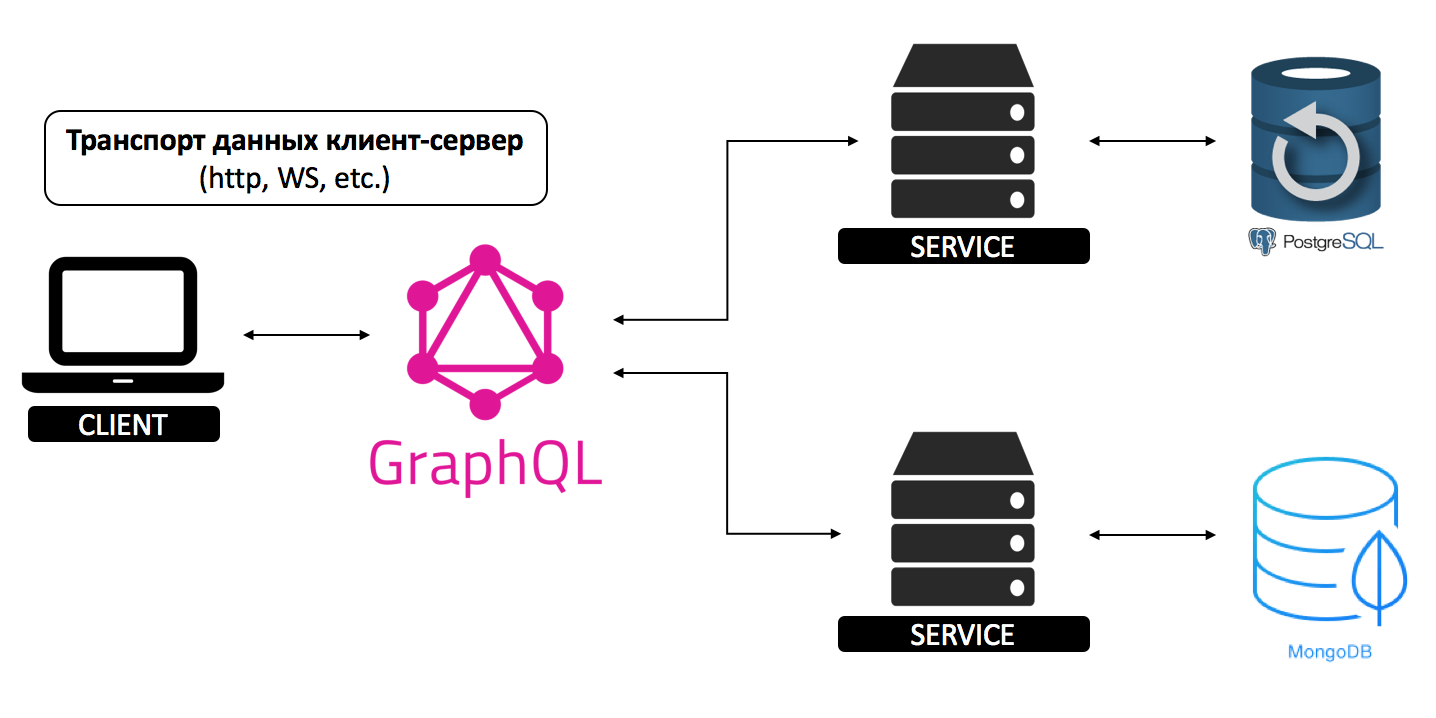
Но как только добавляется еще один сервис, все становится на свои места.
Сервисы могут быть написанными на любом языке программирования, взаимодействовать с разными базами данных, Sql или NoSql, могут иметь разные API. Работать при такой архитектуре становиться довольно сложно, а добавление каждого нового сервиса требует много ресурсов.
Это классическая проблема масштабирования проекта, и наверняка при работе с несколькими сервисами вы используете какой либо «API Gateway».
GraphQL и является этим стандартизированным «API Gateway». Транспорт данных клиент-сервер может выполнятся с помощью любого протокола (http, ssh, ws, cli, etc.).
Клиент запрашивает ресурсы у GraphQL сервера используя GraphQL запрос. GraphQL сервер анализирует запрос, рекурсивно проходит по графу и выполняет для каждого поля его «resolver» функцию. Когда все данные по запросу будут собраны, GraphQL сервер вернет ответ.
Важно отметить, что добавление нового сервиса не влияет на существующее приложение. За счет того, что клиент определяет, какие данные он хочет получить, можно не боясь расширять существующие типы.
Система типов
GraphQL использует систему типов для описания данных.
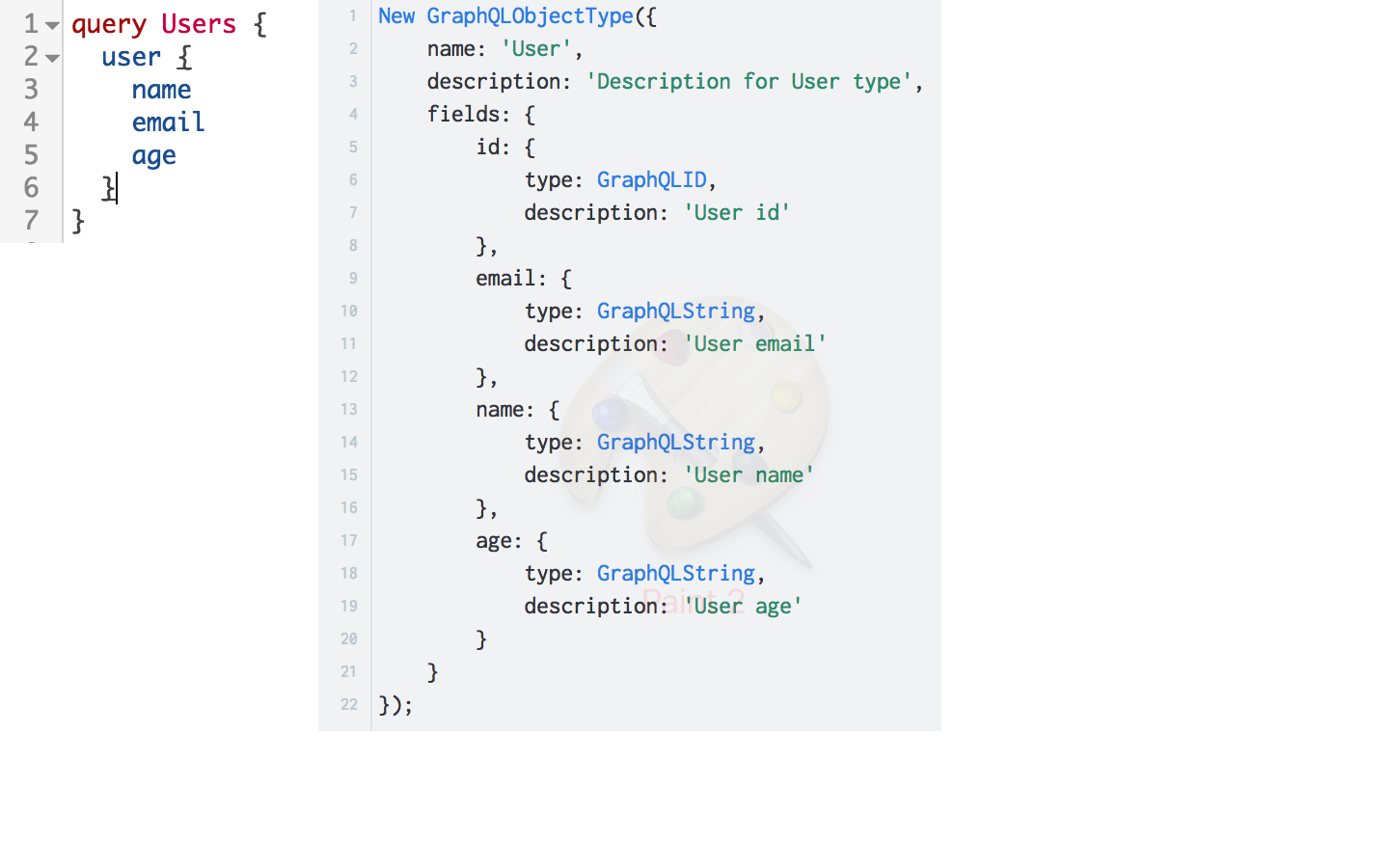
В GraphQL поля могут быть представлены как базовыми, так и пользовательскими типами. В данном примере поле user представлено пользовательским типом User. У типа User описан набор полей, которые представлены базовыми типами.
Таким образом и реализуется графо-подобная структура неопределенного уровня вложенности.
Сравнение GraphQL API и REST API
- Зависимость от протокола передачи данных.
GraphQL не зависит от протокола передачи данных, может использовать любой (http, ws, ssh, cli, etc.)
REST базируется на http протоколе, и зависит от него.
- Единая точка входа. ( Entry point )
В GraphQL для работы с данными мы всегда обращаемся к единой точке входа — GraphQL серверу. Изменяя структуру, поля, параметры запроса мы работаем с разными данными.
В REST API каждый путь (route) представляет собой отдельную точку входа.
- Возможность возвращать разные форматы данных.
GraphQL может возвращать только JSON формат.
REST в данном случае более гибкий. REST API может возвращать данные в различных форматах — JSON, XML и т.д., это зависит от заголовков http запроса, и от самой имплементации API.
- Декларация, документация, инструменты разработки
GraphQL дает возможность написания документации непосредственно в коде (inline documentation).
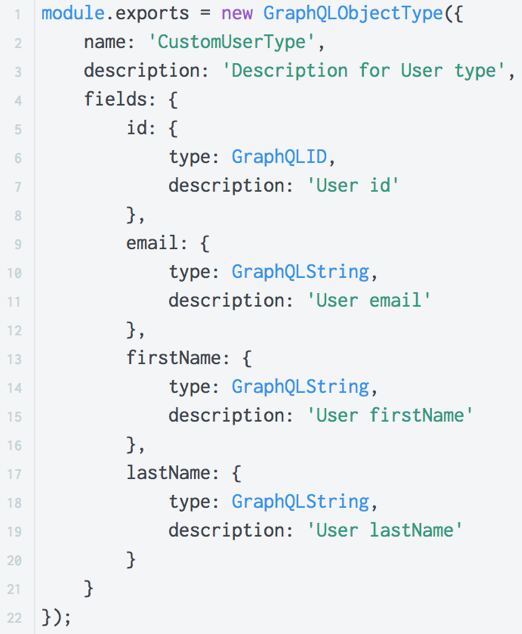
В GraphQL мы можем описать любой созданный нами тип. Для этого при создании типа нужно в поле «description» описать, для чего данный тип нужен. Эту документацию умеют парсить различные утилиты, IDE, что очень упрощает работу с GraphQL.
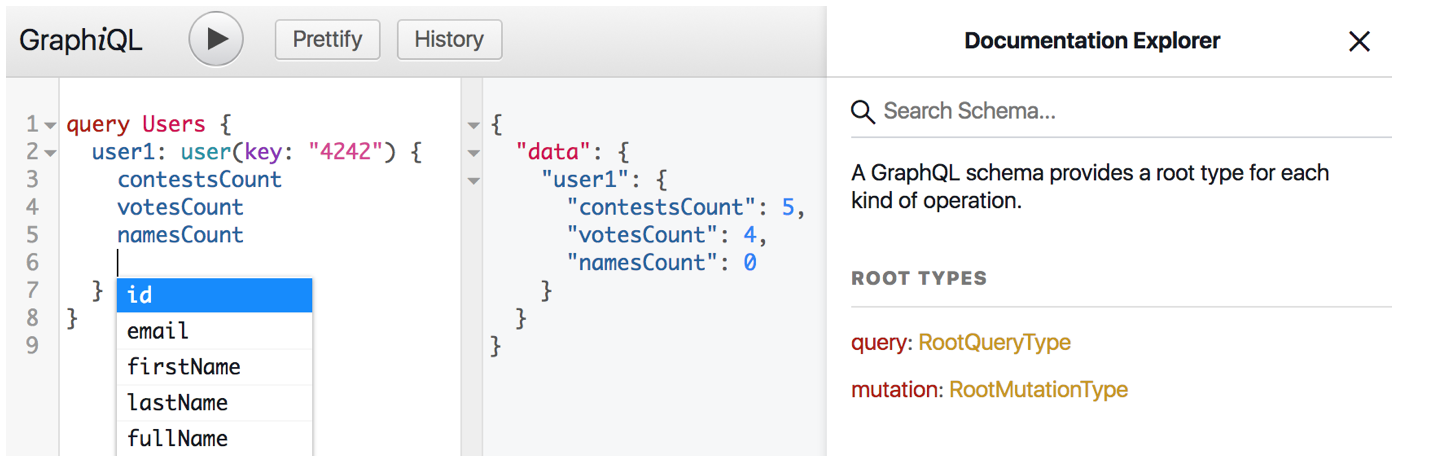
Также, GraphQL из коробки имеет свой IDE, который работает в браузере и называется GraphiQL.
GraphiQL хранит историю запросов, подсвечивает синтаксис, подсказывает поля, которые мы можем запросить у текущего типа, парсит документацию. Это заметно упрощает написание запросов.
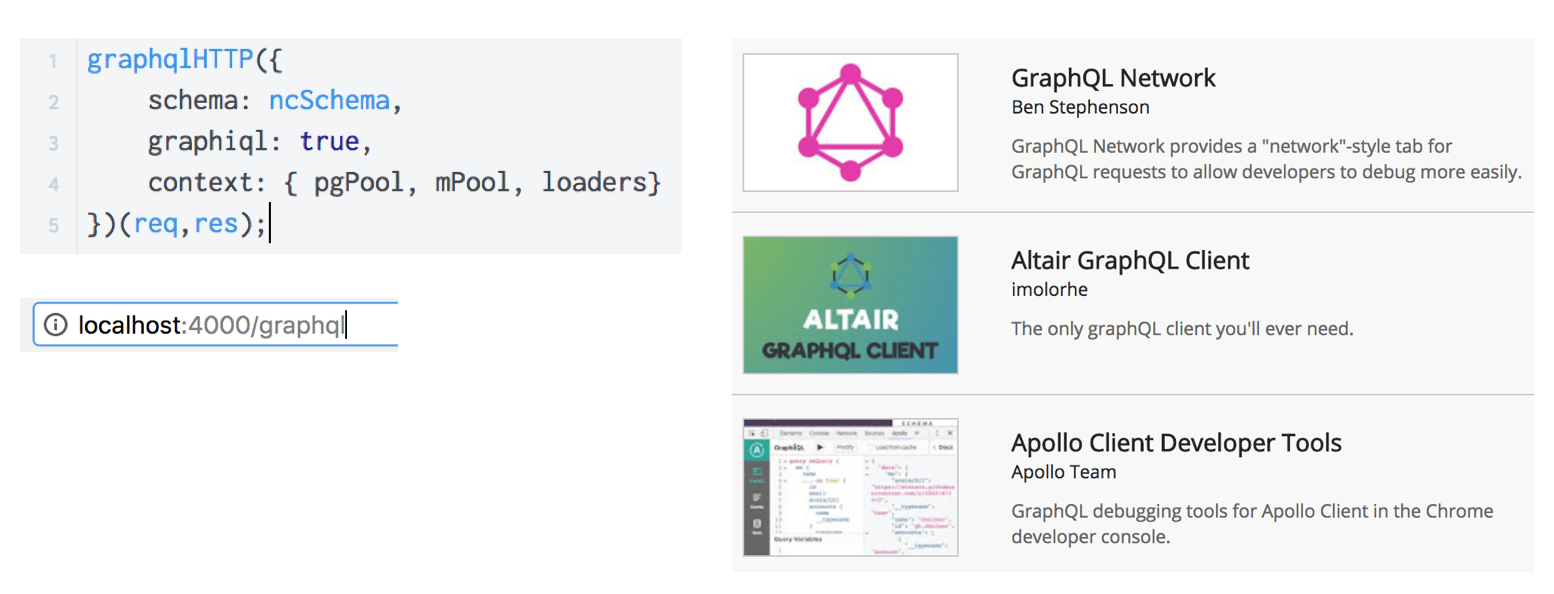
GraphiQL можно включить через конфигурацию GraphQL, с помощью настройки graphiql = true и перейдя по пути <имя домена>/graphiql. Либо же можно использовать одно из расширений для браузера, которые имеют практически одинаковую функциональность но разный UI.
REST не имеет подобной функциональности, но есть возможность её реализовать используя SWAGGER.

- Возможность формировать структуру и объем данных на клиенте
Cобственно, это одна из основных фичей GraphQL, формат и структура данных определяется на стороне клиента. В REST формат и структура данных жестко определены на сервере.
- Передача аргументов в запрос

Делая вывод из предыдущих пунктов, вы наверняка уже знаете ответ, за счет того что GraphQL — это единая точка входа то в GraphQL, мы имеем возможность передать аргументы на любой уровень вложенности.
В REST каждый путь представлен как отдельная точка входа, в таком случае передать аргументы мы можем только для всего запроса.
На этом конец первой части, вторая часть добавится в скором времени. Всем спасибо!)
Комментарии (90)
oxidmod
04.12.2017 18:03REST основан на http протоколе, соответственно зависит от него.
Вы уверены?
www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm
VladimirZaets Автор
04.12.2017 18:40Спасибо, тут конечно возможно не совсем корректная фраза, в плане формулировки. Тут правильно говорить не «основан», а «базируется». Фактически т.к REST — это лишь архитектурный стиль по этому фактически может использоваться разный протокол, SNMP, SMTP и другие, но все же REST имеет ограничения.
oxidmod
04.12.2017 18:50Какие? REST концептуально требует всего 2 вещей:
1. Чтобы каждый ресурс имел уникальный идентификатор, по которому его можно найти.
2. Чтобы каждый запрос на получение или изменение ресурса содержал всю информацию, необходимую для его выполнения.
VolCh
04.12.2017 22:32Скорее наоборот, HTTP базируется на принципах REST.

Crafter2012
06.12.2017 01:45Вот уж воистину все новое — это хорошо забытое старое)
пысы. зря вас заминусовалиVolCh
06.12.2017 06:13Собственно принципы REST были сформулированы Роем Филдингом в 2000-м году и были использованы при работе над спекой HTTP 1.1. Наверное, минусуют за то, что конкретную версию HTTP не указал :)
maxzh83
04.12.2017 18:25Самое забавное, что REST, скорее всего, никуда не делся, он остался на backend (на рисунке Service) и свой трафик все равно отправляет. Т.е. с клиента запрашиваем одно поля, graphQL получает от сервиса все поля и отфильтровывает одно. Интересно насколько такое решение сажает производительность в сложных запросах.
oxidmod
04.12.2017 18:30Ну трафик то ходит, но между бекенд(-ом/ами) и graphQL-сервером он ходит внутри ДЦ (что обычно дешево или даже бесплатно и довольно быстро), а вот уже в мир уходит только то что нужно
maxzh83
04.12.2017 18:37Верно, но взамен получаем задержку в запросе на обработку данных graphQL сервером и потенциально бутылочное горлышко в виде единой точки входа. Еще вопрос, насколько легко масштабируются такие graphQL сервера
VladimirZaets Автор
04.12.2017 18:53Задержка на агрегацию данных является минимальной даже при холодном старте, далее данные достаются из кэша. Про проблеме в единой точке входе я так понимаю имеется в виду нагрузка на сервер? «Еще вопрос, насколько легко масштабируются такие graphQL сервера» — одним из основных пойнтов как раз является простота масштабирования GraphQL API. Возможно как расширять существующие типы так и описывать новые.
maxzh83
04.12.2017 23:41Вопрос не про агрегацию, а про обработку. Т.е. graphQL сервер должен принять запрос, валидировать его, разобрать, сформировать запрос к сервису, получить ответы от всех сервисов, собрать ответ клиенту. На это требуется время, которое плюсуется к времени ответа от сервиса. Вот я о чем. Кэш отчасти спасает ситуацию, но иногда данные меняются часто. Ну и тут же опять вопрос кто будет поддерживать кеш graphQL сервера актуальным (обновлять)?
VolCh
04.12.2017 23:51Если агрегации данных от нескольких сервисов нет, то можно не говорить про graphQL-сервер — запрос к сервису это обычный вызов репозитория или что-то там у вас дергают rest-контроллеры или их аналоги. По сути, можно считать graphQL-слой очень умным фильтром-трансформером в цепочке типа
response = Json.serialize(graphQL.filter(userRepository.getAll(), request));

aspcartman
04.12.2017 18:33Не обязательно. В некоторых компаниях между сервисами общение происходит по RPC, отличному от http/rest. А их, помимо grpc, великое множество. Просадка имеется не в производительности, а в latency. И это на больших масштабах вполне приемлемая цена за масштабируемость.
maxzh83
04.12.2017 18:38Не обязательно, поэтому и написал «скорее всего». Я описывал тот кейс, когда до graphQL уже были работающие сервисы
VolCh
04.12.2017 22:36Рисунок довольно схематический, graphQL сервер отдельный совсем не обязателен, а апп-сервер (бэкенд) может сам отдавать graphQL, обеспечивая, например, прямой маппинг на SQL.

greabock
04.12.2017 19:17GraphQL использует систему типов для описания данных
Нормальные люди используют sdl для декларации схемы =)
schema { query: Query } type Query { users: [User!]! } type User { name: String! email: String! age: Int! friends: [User!]! }eshimischi
04.12.2017 19:26Фреймворк, который построен по принципу Graphcool sdl деклараций схем GraphQL, в репозитарии все инструменты, очень круто.

SerafimArts
04.12.2017 19:361) Это не фрейм, а SAAS/BAAS решение, которое в реальности мало кому нужно.
2) Это не «по принципу», а наоборот, ребята, которые внедрили SDL в GraphQL, т.е. первоисточник этих схем.eshimischi
04.12.2017 19:36GraphQL Backend Development Framework
SerafimArts
04.12.2017 19:42Ну может я чего не знаю…
Можете, пожалуйста, кинуть ссылку на установку этого фрейма? Я вот, например хочу скачать, поставить, настроить роутинг, настроить резолверы и проч. А не пользоваться их веб мордой. ;)eshimischi
04.12.2017 19:48См. здесь, там расписано что делать, приведены примеры реализации для React, Vue и тд, есть даже IDE со всякими плюшками Playground, необязательно деплоить к ним на сервер, можно запускать локальные версии
SerafimArts
04.12.2017 19:58Видимо я ошибался. Я лишь поверхностно проглядывал туториалы и брал «на поиграться», но везде и всюду предлагалось использовать их как BAAS решение, ни слова про докер в мануалах.
Спасибо! Буду теперь знать.eshimischi
04.12.2017 19:59Не за что, я сам в процессе разработки и долго выискивал оптимальное решение для GraphQL, залез в исходники graphcool и увидел все что искал :)
eshimischi
04.12.2017 20:02И кстати блог у них полезно читать, там все по полкам разложено Server basics
SerafimArts
04.12.2017 19:34+1Это всё же экспериментная фича, которая лишь 4 дня назад сдвинулась с мёртвой точки (мой любимый pull/90). А до этого её никто не трогал два года.
Так что я бы сказал не «нормальные люди», а те, кому просто деваться некуда. Насколько я помню, реализация SDL парсеров/компилеров есть лишь на JS, PHP иRubyпричём у каждой свои фичи и/или недоработки.
1) JS: github.com/graphql/graphql-js
2) PHP: github.com/railt/railt
3)Ruby: github.com/rmosolgo/graphql-ruby
UPD: Посмотрел, там свой DSL, а не нативная схема, так что только два варианта. Может кто ещё знает что на других языках?
lRandoml
04.12.2017 20:39Возможность формировать структуру и объем данных на клиенте
Я правильно, что на практике сервер всё равно поддерживает предопределённые запросы и наборы полей под конкретные кейсы? Если да, то в чём тут преимущество?SerafimArts
04.12.2017 20:50Я правильно, что на практике сервер всё равно поддерживает предопределённые запросы и наборы полей под конкретные кейсы?
Не факт, зависит от реализации сервера.
Если да, то в чём тут преимущество?
Стандартизация критериев выборки. Использование:
query { user { id, login, avatar, friends(latest: 10) { id, login } } }
Вместо, например:
/api/1.0/users?fields=id,login,avatar&with=friends.id,friends.login&count=friends:10
Или нечта подобного.lRandoml
04.12.2017 22:23А какие варианты реализации этого на сервере? Просто зачастую то, в каком виде данные хранятся и то, в каком виде они возвращаются, совершенно разные вещи. Поэтому непонятно, как реализовать такой универсальный обработчик. Ведь в зависимости от того, какие поля нужны, приходится сильно варьировать запрос, чтобы не убить производительность. Плюс если какие-то поля вернуть в списке — не проблема, то другие вычислять для каждого элемента — дорого и имеет смысл только при запросе деталей одного элемента
VolCh
04.12.2017 22:51Типичный вариант до оптимизации быстродействия — из репозитория ORM вытягивается нужный граф (желательно с lazy) и фильтруется по запросу.
GreedyIvan
04.12.2017 23:14Ведь в зависимости от того, какие поля нужны, приходится сильно варьировать запрос, чтобы не убить производительность.
Архитектурно неправильно графом ходить в хранилище данных. Граф является интерфейсом (точнее поля типа данных, для которого строится схема графа) к репозиторию. Каждый тип данных (пользователь, статья и т.п.) — это репозитории, к которым обращается граф. Как эти репозитории получают данные, как они их агрегируют, кешируют — это их детали реализации.
Рассмотрите абсолютно любую бизнес-модель с позиции, что у вас есть универсальный апи-метод, позволяющий получить каждое из полей этой модели. Как это поле будет собираться — это дело самой бизнес-модели. Можно анализировать граф-запрос, но сама логика графа подразумевает, что запрашиваться будет самый разный набор полей, поэтому чаще всего эффективнее кешировать либо всю модель, либо поля модели.
При использовании графа ответственность смещается с SLA на конкретный эндпоинт (с соответствующими уровнями оптимизации запросов) на SLA доступа ко всем предоставляемым данным. Решается задача не оптимизации медленных запросов к данным, а как отдавать данные вне зависимости от того, какие там могут быть запросы.maxzh83
04.12.2017 23:59Решается задача не оптимизации медленных запросов к данным, а как отдавать данные вне зависимости от того, какие там могут быть запросы.
Я так понял, вопрос был в том, как реализовать такой механизм и не убить производительность. Очень сложно сделать реализацию быстрой выборки чего-угодно. Вместо этого делают фиксированный набор полей, на выборку которого затачивают запрос и т.д.GreedyIvan
05.12.2017 00:16Вместо этого делают фиксированный набор полей, на выборку которого затачивают запрос и т.д.
Эти технологии применяются на разных слоях приложения.
Если в модели есть сложно вычисляемое поле, то на уровне агрегации данных модели решается задача, как это поле получать быстро.
Перед графом же ставится задача отдать любое запрошенное поле модели.
В конце концов такие модели с тяжелой логикой получения данных обзаводятся слоем кеша со сквозной записью.
Если самим графом за данными не ходить, четко разделяя уровни ответственности, то этой проблемы просто нет как таковой.

SirEdvin
05.12.2017 00:17Никак. Поэтому на самом деле мало кто пользуется graphql и мало кто пытается. Потому что все сводится обычно или к потери производительности, или к тому, что оборачивают rest api в этот ваш graphql. Куча компаний не умеют делать даже что-то похожее на согласованный REST, а тут уже graphQL. Не к добру это.
Ну и к тем, кто предлагает просто смапить orm с graphQL. Так обычно не работает, потому что нужна еще куча внутренних проверок, например, имеет ли пользователь доступ к этой записи. И их может быть довольно много.
VolCh
05.12.2017 00:31+1Куча компаний не умеют делать даже что-то похожее на согласованный REST, а тут уже graphQL
Проблема "согласованного REST" прежде всего в том, что REST — это архитектурный принцип, который каждый толкует как хочет даже в теории, не говоря о конкретной имплементации. graphQL же чётко описанный стандарт с референсной имплементацией.
Так обычно не работает, потому что нужна еще куча внутренних проверок, например, имеет ли пользователь доступ к этой записи.
Решаемо, на разных уровнях и задачах по разному. Никто не мешает, например, в резолвер заинжектить сервис авторизации и проверять хоть запросы к хранилищу, хоть ответы.
SirEdvin
05.12.2017 00:45Проблема "согласованного REST" прежде всего в том, что REST — это архитектурный принцип, который каждый толкует как хочет даже в теории, не говоря о конкретной имплементации. graphQL же чётко описанный стандарт с референсной имплементацией.
А вы знаете в чем проблема "одного единого стандарта"? Ну и да, странно звучит, вот ребята используют какой-то sdl, а в стандарте его нет. GraphQL это тоже идея, все-таки. А структуру все все равно будут делать по своему.
Решаемо, на разных уровнях и задачах по разному. Никто не мешает, например, в резолвер заинжектить сервис авторизации и проверять хоть запросы к хранилищу, хоть ответы.
Я не говорю, что это невозможно, но это означает, что вам надо будет это делать. Инжектить сервис авторизации, потом еще инжектить сервис для проверки ip-whitelist, а потом еще помнить для какой модели что использовать, а что нет. Тут просто уйма веселый архитектурных проблем, которые позволял избегать REST.

helions8
05.12.2017 00:57+1А вы знаете в чем проблема «одного единого стандарта»? Ну и да, странно звучит, вот ребята используют какой-то sdl, а в стандарте его нет. GraphQL это тоже идея, все-таки. А структуру все все равно будут делать по своему.
sdl это какой-то инструмент сбоку для описания схемы, у меня в Эликсире там тоже свой дсл, но для клиента это будет тот же самый GraphQL, по стандарту. Это не идея, можно пойти и скачать спецификацию. Спецификации REST в природе не существует.
VolCh
05.12.2017 01:13А структуру все все равно будут делать по своему.
Язык запроса стандартизирован, так сказать, де-юре, а передача запросов и ответов по HTTP де-факто (а может и де-юре тоже, не вникал).
Тут просто уйма веселый архитектурных проблем, которые позволял избегать REST.
GraphQL легко сводится к типичным JSON REST(ish) API c "бесплатным бонусом" в виде возможности получать не все данные, которые может сервер отдать, а только необходимые. Если у вас в архитектуре есть слой, который отвечает за выборку данных из хранилища с учётом прав пользователя, его IP, и прочих метаданных запроса, сессии и т. д., то GraphQL ендпоинт будет лишь ещё одним интерфейсом к нему.
helions8
05.12.2017 01:46Http де-факто, как самый популярный транспорт. В стандарте ничего специфичного для него нет, да и разработчики заявляли, что GraphQL is protocol agnostic.
GreedyIvan
05.12.2017 00:56Когда используется схема «клиент -> запрашивает данные через граф -> который, опираясь на описание типов, запрашивает нужные данные в нужных репозиториях -> которые, основываясь своей бизнес-логике, запрашивают данные из своих хранилищ», то вопросов, для чего нужен граф и какие задачи он решает, не возникает.
Почти всем нерешаемые проблемы графа связаны с тем, что его пытаются применить не по назначению. Возьмем, например, пагинацию.
Есть ОРМ, которая поддерживает работу с графом. Прикручиваем пагинатор к ОРМ и через этот пагинатор ходим напрямую в ОРМ. И имеем все те проблемы, которые описывают в каждой второй статье применения графа.
Как это решается через вышеописанную схему?
Создается тип пагинированных данных. Интерфейс репозиториев расширяется, чтобы они умели отдавать данные согласно новому типу данных. Как результат пагинатором ОРМ пользуются репозитории. А граф запрашивает у репозиториев данные соответствующего типа. Задача получения данных и оптимизации запросов остается на уровне модели, которую использует репозиторий для работы с хранилищем.
GreedyIvan
04.12.2017 21:30Я правильно, что на практике сервер всё равно поддерживает предопределённые запросы и наборы полей под конкретные кейсы? Если да, то в чём тут преимущество?
Я выделил бы два ключевых преимущетва.
У нас есть универсальный геттер для данных. На уровне описания типов бизнес-моделей описываются их поля и связи (поля с типами других моделей). На основе этих типов потом строится вся схема графа. Бонусом можно на основе внутренней логики регулировать, какие типы кто будет видеть. Если в описании схемы какого-то запрошенного поля нет (вырезано из-за отсутствия прав), то запрос с таким полем не пройдет сам по себе. Логика резолва всех указанных в графе полей спускается на уровень ниже, для которого декларируемые поля являются интерфейсом, согласно которому сервис должен уметь возвращать данные
Второе преимущество в сеттерах (мутации). С одной стороны для каждой операции бизнес-логики пишется своя мутация (как бы аналог эндпоинта в рест), но из-за вышеописанного преимущества с декларативным способом описания, методы бизнес-логики превращаются в мутации, где наборы полей описываются таким же декларативным методом. А сама бизнес-логика уходит на следующий уровень, для которого мутация становится просто интерфейсом.
В итоге поддержка апи сводится к декларации получаемых данных и декларации методов изменения данных. Сама реализация же может делаться где угодно и как угодно, пока она использует описанные в графе декларации в качестве интерфейса.
VolCh
04.12.2017 22:48На практике часто (можно даже сказать по умолчанию для внутренних API) клиент может выбрать весь граф объектов, которы может собрать бизнес-логика в принципе.
VladimirZaets Автор
04.12.2017 23:05Не соглашусь, зачастую набор данных для view существенно меньше чем может вернуть API.
Самый банальный пример опять таки с пользователем. Допустим у нас залогиненый пользователь и мы должны отображать его имя и аватарку в хеде страницы. В таком случаи нам нужно всего 2-3 поля, а не данные по всему интерфейсу пользователя. К тому же можно увеличить TTI за счёт того что первым запросом запрашивать данные для видимой пользователем части экрана, а остальное подгружать лениво.VolCh
04.12.2017 23:43+1Фишка GraphQL в том, что во вью (ответе сервера) всегда ровно столько данных, сколько нужно клиенту (фронту). Нужны только имя и аватарка — выбираете только их, нужны паспортные данные друзей друзей друзей — выбираете их. У вас неограниченная (логически в теории, на практике разработчики бэкенда могут ограничивать по соображениям экономии ресурсов и безопасности, да и сами вы можете не захотеть ждать результатов "семиэтажного" запроса, который выполняется полчаса) возможность обходить предоставленную через GraphQL модель.
helions8
04.12.2017 23:48+1Посмотрите на проблему с точки зрения клиента, в особенности – мобильного, на слабом канале, когда очень желательно получать минимум требуемых данных, без лишнего «мусора». Отсюда и «шейпинг» возвращаемых данных клиентом при запросе. В случае решения а-ля REST (т.к. это уже ни разу не REST, а JSON RPC какой-то) приходится или плодить кучу эндпоинтов на каждый чих, либо снабжать ресурс кучей get-параметров, определяющих результат, что, по-факту, и есть переизобретение GraphQL. Да, можно сказать, что возможные запросы предопределены, но в зависимости от набора полей в запросе, нормальный бекенд будет делать разные запросы в хранилище. Банальный пример – не делать лишний запрос или join для вложенной коллекции модели, если ее не просили.
y3u
04.12.2017 22:35-1С каких пор оборачивание SQL запросов в HTTP перестало быть моветоном?
VladimirZaets Автор
04.12.2017 22:35Не совсем понимаю где вы увидели оборачивание SQL запросов в HTTP?
SerafimArts
05.12.2017 06:16Ну там же целых две буквы совпадают в названиях, как же это можно не заметить? =)
</irony>

Legion21
05.12.2017 01:49Вот вопрос, стоит ли GraphQL того, чтобы бросать все и внедрять его, если и без него все работает идеально??? (Не только в плане производительности, но и клиент-серверной коммуникации в целом)
VolCh
05.12.2017 10:06А в плане разработки? Как часто ваши фронтендеры просят бэкендеров добавить в API то или иное (уже существующее в бэкенд-модели поле или целый граф), а то и целый новый ендпоинт, выдающий те же данные, что и другие, но в другом шейпе?
Для проектов, не испытывающих особой нужды в низкоуровневых плюшках GraphQL, могут оказаться полезными архитектурные, снижающие зависимость фронтов от бэкенда.
h0use
05.12.2017 03:15GraphQL без сомнения очень интересная технология, но большой вопрос как для него строить секьюрити, если я могу с помощью REST разбить получение, к примеру полных деталей пользователя и сокращенных (без sensitive data), просто создав два REST endpoint с разными пермиссиями на них, то как это сделать с QraphQL?
GreedyIvan
05.12.2017 09:57Это делается на уровне генерации типа данных для схемы. Если в схеме нет какого-то типа или поля в типе, то их запрос приведет к общей ошибке обработки запроса (запрос несуществующего типа или несуществующего поля).
В общем случае это решается наличием соответствующего функционала у репозитория. Тип возвращаемых данных — это один из его интерфейсов. Используя этот тип данных репозиторий преобразует внутреннее хранение полученных из хранилища данных в стукруту, которая передается пользователю. Аналогичным образом граф у репозитория получает этот тип данных в соответствующем формате.
Ограничение доступа остаётся на уровне репозитория, который сам фильтрует, по своей внутренней логике, какие поля кому доступны. Что клиент не может получить у этого репозитория недоступные ему поля (потому что всякая выдача проходит через преобразование в этот тип данных), что граф, запрашивая схему для типа данных, получает только тот набор полей, который доступен данному пользователю.
VolCh
05.12.2017 10:20Добавлю, что вы можете создать два типа данных (запроса), например, UserPublic и UserPrivate, что будет аналогом двух ендпоинтов. Или в резолвере одного типа User проверять права и отдавать специальные значения для полей, к которым доступа нет.
GreedyIvan
05.12.2017 10:45Добавлю, что вы можете создать два типа данных (запроса), например, UserPublic и UserPrivate, что будет аналогом двух ендпоинтов
Это нарушает саму идеологию графа. Запросить пользователя мы можем в любом месте любого запроса, который имеет связь с пользователем: { article { user { id } } }
Если мы будем использовать разные названия типов в зависимости от прав, то убъем универсальность доступа к данным.VolCh
05.12.2017 12:24Тем не менее это рабочее решение.
Fortop
06.12.2017 19:23Это и сразу выглядит как костыль в рамках GraphQL напрочь убивающее большую часть его пользы.
А уж в рамках одного из комментариев выше
В случае решения а-ля REST (т.к. это уже ни разу не REST, а JSON RPC какой-то) приходится или плодить кучу эндпоинтов на каждый чих, либо снабжать ресурс кучей get-параметров
Сам GraphQL выглядит как банальное «not invented here»
koloritnij
05.12.2017 18:47Если всё упростить, то получиться, что у вас есть Map<String, Object> и запрос по получению данных из неё по ключу. Т.е. вы можете просто не заполнять эти поля если нету соответствующих прав.
sovaalexandr
05.12.2017 18:47Видимо пермишны на атрибуты вешать и в fine-grained авторизацию уходить.
n0ne
06.12.2017 12:18Вообще не проблема или я не понял вопроса (-:
Если у пользователя есть пермишины — он получает полные данные, скажем так, выполняется один запрос, если нету, то другой. Это если вы хотите решать на клиенте.
Если Вы решите это выяснять на сервере, то просто сами решаете, что возвращать пользователю в зависимости от его уровня доступа, так сказать.

BuranLcme
05.12.2017 11:21Сколько ни читаю посты об GraphQL, не могу понять чем он принципиально лучше существующих уже давным давно URI-совместимых query language-ей. Например, RQL или odata. Они прекрасно решают проблему выбора необходимых полей, поддерживают фильтрацию, паджинацию и все остальное. В отличии от GraphQL они не противопоставляют себя REST-у, а отлично его дополняют. Таким образом, сравнивать GraphQL нужно не с голым REST, а с существующими языками запросов.
Система типов для описания данных, в свою очередь, очень похожа на также давно существующую JSON Schema.VolCh
05.12.2017 14:29Если говорить о REST как типичных HTTP RESTish API, то они идеологически плохо поддерживают не CRUD операции над ресурсами. Приходится придумывать виртуальные ресурсы типа /process/123/approve для расширения списка доступных действий над ресурсом, когда и ресурса собственно нет.
oxidmod
05.12.2017 15:00Что вас смущает?
1. Ресурс определяется идентификатором /process/123
2. Запрос содержит информацию, необходимую для выполнения (какой ресурс, и что с ним сделать)VolCh
05.12.2017 15:29Идентификатор (URI) /process/123/approve, а по факту в модели области нет даже сущности Process, не говоря о её методе approve, только идентификатор для связи сущностей. В СУБД просто sequence без таблицы, а можно генератор айдишников сделать вообще базу не трогая.
Нет ресурса, который можно посмотреть по GET /process/123, близкое только GET /process/123/status, возвращающй коллекцию статусов связанных сущностей. Нет ничего, что можно отправить PUT /process/123 или PUT /process/123/status, только POST /process/123/, где verb — один из полутора десятка глаголов.
oxidmod
05.12.2017 15:44Вот неплохая статья на тему
dzone.com/articles/restful-service-design-how-to-overcome-the-crud-naVolCh
05.12.2017 16:03+1Хороший пример того, что мне не нравится в типичном REST — введение дополнительных абстракций (в примере — виртуального идентификатора и подресурса, который не ресурс) для… даже не знаю для чего. Чтобы соотвествовать семантике HTTP? Но вроде даже она не вводит понятия подресурсов.
GreedyIvan
05.12.2017 12:22Сколько ни читаю посты об GraphQL, не могу понять чем он принципиально лучше существующих уже давным давно URI-совместимых query language-ей. Например, RQL или odata. Они прекрасно решают проблему выбора необходимых полей, поддерживают фильтрацию, паджинацию и все остальное. В отличии от GraphQL они не противопоставляют себя REST-у, а отлично его дополняют.
Киллер-фича графа — отсутствие необходимости версионировать апи. Из чего вытекает простота использования и поддержки точки взаимодействия клиента и приложения.
Граф противопоставляется ресту, потому что идеологически граф не общается с хранилищем, а только с репозиториями. Рест-апи в своем развитии обзаводится особыми эндпоинтами, которые получают сложные наборы данных и обзаводятся слоем логики, позволяющем получить эти данные из хранилищ наиболее оптимальным способом. И очень часто при внедрении графа возникает именно вопрос о том, как это повторить для графа. Никак. Граф не должен знать ничего о том, как хранятся данные. Он должен знать только то, какой севрис обслуживает какие типы данных.BuranLcme
05.12.2017 15:00Киллер-фича графа — отсутствие необходимости версионировать апи. Из чего вытекает простота использования и поддержки точки взаимодействия клиента и приложения.
А почему вы считаете, что у других языков запросов есть потребность в версионировании?

iit
05.12.2017 14:04+1Внезапно в данный как раз занимаюсь одним бизнес приложением с использованием этой технологии и могу много чего интересного рассказать.
На бэке стоит внезапно php и laravel для подключения используется единственная более-менее адекватный коннектор который по сути обертка над этой либой
На фронте используется React + Apollo
И так на backend находятся 25 таблиц в postgres причем 4 из них содержат jsonb поля с произвольным содержанием.
А теперь головные боли:
1) backend
Для того чтобы graphql заработал нужно описать запросы типы и мутации.
В коробке с graphql идет целая куча примитивных типов — вроде числа, строки, boolean и т.д
Далее идут структурные типы вроде объектов — причем для описания своего объекта необходимо описать ВСЕ поля объекта на основе существующих полей. в итоге 25 объектов в среднем с 8-10 полями — это ОЧЕНЬ много описаний. Но это еще не все внезапно нет готового типа для произвольного json — типы должны быть точно описаны. Но добавить свой тип в принципе возможно — пришлось добавить тип json самостоятельно. Связи указываются как поле которое ссылается на другой тип.
Хорошо у нас есть типы объектов но сами по себе они бесполезны! необходимы запросы к объектам на основе эти типов. предположим я желаю 2 типа запросов на каждый объект первый — показать по id или по другому ключевому полю и второй — показать все по каком-либо набору критерию. В итоге мы уже описываем аргументы. В итоге по 2-5 аргументов на каждую сущность в каждом запросе по два на сущность — и это опять достаточно много описаний.
Далее мутации — если взять 3 мутации (удалить, добавить, изменить) то опять описываем аргументы, для мутаций уже те самые 8-10 полей и это опять куча аргументов + еще правила валидации для каждого поля в каждой мутации.
Смотрим видим что необходимо создать просто огромное количество кода для описания graphql для CRUD+list для 25 объектов.
В итоге рвем на голове волосы от чисто объема кода и пишем некий генератор который используя рефлексию и немного doctrine/dbal шерстит наши таблицы и генерирует поля для наших типов и аргументы для наших запросов и мутаций. Сам генератор принимает список объектов и какие поля/аргументы не надо генерировать.
Все это месяц работы.
2) фронт
Здесь нам опять необходимо описать наши 50 запросов и 150 мутаций — хорошо есть генератор из php который выдаст нам схему и мы определим хитрый Higher-Order Component (HOC) который будет принимать конфиг из серии
Объект
- поля
- запросы
- аргументы запроса
- поля запроса
- мутации
- аргументы мутации
- поля мутации
После чего генерирует код наших запросов/мутаций (graphql-tag), и прописывает их в props нашего объекта.
Хорошо — теперь бы нам пробросить наши запросы в props наших объектов.
Для этого внезапно Apollo предлагает свои HOC который принимают graphql-tag и пробрасывают свойства в объект. И для контроля выполнения запросов еще один HOC.
В итоге получаем эдакий толстый бургер где наши 2 HOC это 2 булки — один для предоставления и генерации запросов, второй для того чтобы упростить вызов этих запросов а между ними уже лежит начинка в виде HOC для каждого запроса/мутации.
После чего строим 25 data-table оборачиваем их в наш HOC с разными конфигами и радуемся.
Все это звучит понятно просто и легко но по факту это достаточно сложная работа.
Итог:
- Если у вас более 5 объектов в системе и вы не хотите её делать год одному и 3 месяца одной командой из 5 человек — не используйте graphql.
- если вы не используете специальный saas/baas или другой софт который использует graphql из коробки и умеет генерировать запросы/мутации на основе типов — не используйте graphql.
- если у вас не graphqlCool фреймворк например meteor не используйте graphql
Big_Shark
05.12.2017 15:54А чем бы вам помог REST? Если у вас 25 таблиц, и к каждой нужен крад, то получается вам надо написать 125 эндпоинтов, и все это с фильтрацией, валидацией, и прочим. Не думаю что это заняло бы меньше времени.
maxzh83
05.12.2017 16:30Все, конечно, зависит от выбранного стека технологий, но под REST уже много удобных инструментов появилось. Например, в мире Java есть Spring Data Rest, с помощью которого для реализации кейса с 25 таблицами не нужно писать ни одного endpoint руками. Достаточно описать 25 сущностей в виде название сущности, список полей с типами и собственно все. Таблицы в БД и эндпоинты (CRUD) будут сделаны автоматически, с пейджингом и сортировкой
iit
05.12.2017 16:48Собственно мне и пришлось реализовать подобные генераторы для graphql с костылями в велосипедами ибо ручками такой объем кода не потяну физически.
iit
05.12.2017 16:391) Я не говорю что сам протокол graphql плох
2) Имхо для описание одного REST ресурса потребуется чуть меньше времени чем на описание 1 типа 3 мутаций и 2 запросов и единственный два плюса в graphql против REST это возможность выбрать список полей (включая условные выборки) и простая выборка полей связанных объектов — собственно для чего мне он и нужен — из 25 объектов 22 можно вытянуть по зависимостям имея на руках любой из них.
3) Для использования graphql нужен отдельный сервер relay/meteor а для бэка остальных платформ кроме node.js остается только использовать Apollo клиент а эти ребята полны сюрпризов я скажу — например могут внезапно выпилить поддержку Redux в новой версии и одновременно закрыть доки на старую, плюс не допилить доки на новую в итоге документацию приходиться вытаскивать их кэша гугла.
4) Для REST есть куча готовых генераторов которые позволят автоматизировать занудное создание ресурсов а для graphql мне пришлось писать такой генератор самому — причем аж 2 раза — первый для сервера а второй для клиента.
n0ne
06.12.2017 12:34У меня Apollo на фронте и на сервере. Получаю просто удавольствие от GraphQL.
Всё пишется просто, комфортно.
И вообще не понял, причём тут graphqlCool к meteor. От слова совсем.
GreedyIvan
05.12.2017 15:53А теперь головные боли:
Добавьте ещё головную боль в виде размазанной бизнес-логики по мутациям / орм с кучей дублируемого кода, для чего пришлось использовать написать генераторы кода.
Как итог можно смело прогнозировать, что через определенное время проект будет быстрее и дешевле переписать, чем развивать. Так что не используйте graphqliit
05.12.2017 16:44+1А бизнес логика как и положено лежит бизнес слое который собственно и инжектируется через DI в типы мутации и запросы, слава DDD при желании можно переписать все на REST тупо генерированием тех же REST ресурсов для каждого объекта логики.
n0ne
06.12.2017 13:00Видимо, я использую какой-то другой GraphQL (((-:
Ну и не только я, всякие канторки поменшьше, типа Facebook ((((-:
Быстрее и дешевле делать на GraphQL. Так что используйте GraphQL!iit
06.12.2017 13:52У меня Apollo на фронте и на сервере.
В случае если использовать изоморфные приложения как у вас тогда все просто и понятно, но как эксперимент — попробуйте представить, просто представить что backend у вас не ваш любимый node.js а на java или например как в моем случае php.
Попробуйте описать 2 раза типы мутации и запросы ручками для клиента на том-же Apollo и следом за этим описать эти-же типы запросы и мутации на сервере используя например
- php = laravel + folklore/graphql
- java = Spring + graphql-java
я бы посмотрел на это =)
P.S
используйте GraphQL только если у вас изоморфное приложение на платформе node.jsn0ne
06.12.2017 16:36Если Вы используете разные бэкенды — это не проблема GraphQL, это вопрос либо неправильной, либо странной архитектуры.
Клиенту фиолетово, что там на бэкенде, лишь бы он отдавал нужные ему данные в правильном формате. Если так сложно и больно делать бэкенд на php или чём-то там ещё, сервер на expresse поднимается несколькими строчками кода и забывается вся эта боль (-:
Посмотрел на graphql-java: не нашёл ничего страшного и сверхъестественного. У себя думаю для некоторых пользователей попробовать поднять GraphQL на Elixir-e.
Так что всё выше Вами описанное — это не проблемы GraphQL.VolCh
06.12.2017 18:30Разные бэкенды — это не неправильная или странная архитектура, а, ровно наоборот, выбор языка бэкенда лучше подходящего для той или иной задачи.
И дело не в том, что сложно сделать бэкенд на PHP, а в том, что схему графа придётся описывать дважды в случе сервера и клиента на разных языках. В общем случае — сколько языков используется с одной схемой — столько раз придётся описать.
n0ne
06.12.2017 18:41Вот именно, если бэкенды для разного — это да, нормально использовать разное. В таком случае вообще не проблема поднять ещё крохотный бэкендик на expresse() и не иметь никаких проблем. (((-:
Может я не так понял, но выше предлагали писать одно и тоже на php и на java.
И опять же: это всё — не проблема GraphQL.
GreedyIvan
06.12.2017 23:59И дело не в том, что сложно сделать бэкенд на PHP, а в том, что схему графа придётся описывать дважды в случе сервера и клиента на разных языках.
А зачем на клиенте схему описывать?VolCh
07.12.2017 14:40С разными целями от поддержки инструментами разработки до валидации готового запроса на клиенте до отправки на сервер. Ну и есть клиенты, которые предоставляют высокоуровневый API для клиентских приложений на основании схемы.
rraderio
06.12.2017 17:05Это проблема инструментов а не GraphQL
github.com/graphql-java/graphql-java-tools
rraderio
Спасибо за статью.
Будут ли части про «Persisted Queries», ошибки, пагинацию, аутентификацию?
VladimirZaets Автор
Спасибо за доброе слово) Да, это будет во второй части. Контент уже есть, предполагаю что будет в ближайшие дни.