
Недавно коллега задал привычные уже вопросы про «зачем ходить на конференции» и «зачем смотреть записи на YouTube». Так как это друг, а не просто какой-то произвольный человек, захотелось ответить более обстоятельно, детально и по чесноку. К сожалению, в режиме онлайн, при живом общении, сделать это сложно: просто не упомнишь всех подробностей. С другой стороны, это отличная тема для хабрапоста: можно один раз написать развёрнутый обзор и потом, как истинный социофоб, отвечать на все вопросы ссылками на Хабр.
Идея проста: надо взять наиболее популярные доклады с JPoint 2017, кратенько пересказать, о чём там речь, почему это круто и зачем нужно лично мне. Каждый из этих докладов заслуживает отдельного разбора, но вначале — краткий обзор первой десятки. Поехали!

Интересно, что именно на этой конференции в топ попали два кейноута. Кейноуты по определению задают дух и тон конференции, они расчитаны на "вдохновение" и "расширение кругозора". Чтобы на узкой технологической конференции кейноут попал в топ — это надо постараться. Тем не менее, они все здесь. Программный комитет добился этого нехитрым приёмом: первый кейноут — традиционно популярный научпоп, второй делает Шипилёв (спикер-рецидивист, серийный делатель самых лучших докладов).
Чтобы сравнить свои ощущения от просмотра доклада, рядом с каждым из них будет средняя оценка участников конференции.
10. Задача о коллективной (без)ответственности
Спикер: Алексей Савватеев; оценка: 4.38 ± 0.04.
Яркий доклад от популяризатора науки, в особенности — математики и теории игр. Доклад основывается на собственных исследованиях и на работе Оливера Харта и Бенгта Хольмстрёма (лауреатов Нобелевской премии по экономике 2016 года, которую дали за теорию контрактов).
Сначала даётся некая вводная для тех, кто забыл (или никогда не знал) базовые вещи про теорию игр и контракты. Этим отличается кейноутный доклад от «хардкора»: автор не сказал «все, кто завалил в вузе матчасть — встали и вышли из зала». Вместо этого он коротко и доходчиво объясняет тему на примерах, так что становится понятно кому угодно. Например, теорию контрактов можно использовать следующим образом: если у нас есть какая-то обычная кодерская контора, то строится модель всех вовлечённых лиц (работников, работодателя и т.п.) и в дальнейшем работодатель может управлять этой системой не с помощью прямых приказов, а с помощью тонко выбранных стимулов.
Алексей приводит большое количество примеров таких контрактов, в том числе и плохо работающих. Например, рассказывает о том, как с помощью неверно выбранных правил можно случайно заблокировать автомобильное движение. Короче, общая задача в том, как организовать процесс правильно.
По цепочке примеров мы приходим к объяснению равновесия Нэша на примере задачи о турникетах. Нэш — это тот товарищ, который был главным героем фильма «Игры разума», получил Нобелевку по экономике в 1994 году и Абелевскую премию по математике в 2015. Нэш доказал очень общую теорему существования равновесия в играх. Приводятся такие актуальные примеры, как деньги и вера в их стоимость и сравнительная уверенность в качестве преподавания в вузах.
Очень круто, что Алексей прямо в ходе доклада организовал brainstorm вместе с аудиторией — и в аудитории реально были люди, способные поддержать беседу. Обычно такие попытки выглядят жалко, но в данном случае они как бы были частью доклада. К сожалению, почувствовать этого на записи нельзя, но это был один из немногих докладов, где я присутствовал вживую. В таком формате обсуждали, например, вторую часть задачи о турникетах.

И наконец, на основе этого мы переходим к центральной теме доклада: о том, как к докладчику обратились с просьбой решить задачу неуплаты налогов при высоком уровне коррупции. Строится модель, формализуется задача и вопрос решается в рамках теории игр, в ходе чего мы натыкаемся на ряд очень интересных следствий и наблюдений.
Вообще говоря, это предполагалось стать критической статьей, но понятно, что моих знаний в теории игр никогда не хватит, чтобы критиковать настоящего учёного на его поле боя. Правильно ли он выбрал модель? Корректны ли расчёты? Да чёрт его знает. В первую очередь меня зацепил образ мышления автора, который можно проследить как в видеозаписи доклада, так и при общении вживую. Этот способ мышления — он как почерк.
Все программисты так или иначе решают проблему моделирования на своих языках программирования, но в случае Алексея разговор идёт о крайне сложных реальных проблемах, которые натягиваются на очень высокоуровневые математические абстракции, что вместе позволяет построить весьма контринтуитивные выводы и проверить их на практике. Для меня кейноутная ценность этого доклада именно в этом — в мгновении внезапного просветления и прозрения, когда начинаешь видеть «Матрицу» простых вещей другими глазами.
9.?Перформанс: Что В Имени Тебе Моём?
Спикер: Алексей Шипилёв (Red Hat); оценка: 4.38 ± 0.03.
Ещё один кейноут, на этот раз про перформанс. Вначале Лёша обсуждает критерии успешной разработки. Конечно же, грамотно примазывается к аудитории, рассказав о том, что главный критерий бизнеса — это бабло, а мы, программисты, зарабатываем тонну бабла!
Пока аудитория не оправилась от лести, начинается бомбардировка более печальными техническими вещами типа общения с безопасниками. Из чего делается вывод, что перформанс в топе влияния на успешность проекта — не самая важная штука. Забавно это слышать от чувака, который перформансом занимается — обычно всякий кулик хвалит своё болото.
Дальше сравнивается корректная программа и быстрая программа, и приводится слайд с кривой имени Ш. Имхо, этот слайд — один из самых просветляющих моментов, позволяющий найти себя в Общей Картине Всего. Если из доклада хочется посмотреть всего один слайд, то вот он.

Лёша аккуратно проходится по всем уровням диаграммы, и лично для меня эти рассуждения имеют весьма чёткое применение. Например, это хорошо формализованный список аргументов в определении перформансной стратегии и для борьбы с вредными утверждениями типа «профилировать нужно или нормально, или вообще никак» (когда находимся в зелёной зоне). Обсуждается и кнут с его «преждевременной оптимизацией» в роли главного аргумента всех споров. И как продать начальству свою работу по улучшению перфоманса. И что делать, когда к тебе приходят продавать какую-то дичь, типа новой супербыстрой базы данных.
Заспойлерю пару слайдов:


Таких слайдов там невообразимое количество, и что характерно — все они строго по делу. Что, в общем, и стоило ожидать от чувака, который этим зарабатывает на жизнь. Не сказать, что это какие-то супертайные знания, но для меня их ценность — в максимально чёткой, вылизанной формулировке и организации информации.
Примеры, конечно, там жесть: какие-то куски кода из javac с падением скорости компиляции от 2 до 8 минут, доказательства через закон Амдала и Universal Scalability Law и т.п. Хотя откуда бы у Лёши другие примеры?
Есть подозрение, что какие-то эксперты по перформансу затаили теперь злобу на докладчика, ибо он в одном докладе сдал все их основные секреты и темы консультаций.
8.?Будущее Kotlin: Стратегия и тактика
Спикер: Андрей Бреслав (JetBrains); оценка: 4.41 ± 0.08.
Кто не слышал ничего про Kotlin? Ну точно не мы. Все новости переполнены Котлином, интернет бурлит, и вот к нам на огонёк приходит руководитель этого проекта — Андрей Бреслав. Андрей рассказывает именно о будущем языка и платформы, поэтому он вполне может ошибиться, но менее ценным это доклад не делает.
Во-первых, интересно, что Андрей действительно может говорить от имени продукта. Он может говорить сразу целиком рынками: будет ли драться Kotlin за Big Data со Scala, будет ли он сражаться за Data Science с Python. Если на первых слайдах он говорит: «Our creed: Pragmatic Language for Industry (Interop, Tooling, Safety) for JVM, JS and Native platforms» — значит, так оно и есть. На этом слайде можно закрыть дискуссии в чатиках на тему, является ли поддержка отличающихся от JVM платформ реальным приоритетом.
Тут же Андрей объясняет, что они не стараются добиться, чтобы любую программу можно было запустить на любой платформе. «Write once, run everywhere» — это для Java, а котлиновцы этим заниматься не будут. Это тоже ценный кусочек мозаики — ценный для того, кто уже прямо сейчас проектирует Kotlin-ориентированные архитектуры. Имхо, для архитекторов этот доклад неоценим тем, что можно с берега начать понимать, с кем ты связался и на что собираешься подписываться.

Там же из зала можно было задать другие неудобные вопросы типа: а когда будет поддержка Objective-C, полезные библиотеки типа сокетов в Kotlin Native и т.п. Вопросы неудобные, но Андрей как-то выкрутился :-) Очень много было вопросов именно про native, в докладе всерьёз обсуждалось применение Kotlin в embedded. Был вопрос про Kotlin на Arduino и zero cost abstractions и обсуждение, что, если писать для Arduino как для сервера — это, вообще-то, полный отстой.
Вообще, доклад получился очень специфический. О планах, амбициях, стратегии.

Очевидно, что он является очень важным для всех, кто уже связывает своё будущее с Kotlin. Для всех остальных… Ну, скажем так, каких-то особо «продающих» кусков доклада — «съешь меня», «выпей меня», «купи меня» — не было, и это очень меня подкупило. Чуваки стали уже такими толстыми, что им даже не нужно продаваться и трясти рекламными буклетами на каждом углу. С другой стороны, если тебе изначально хотелось понять, на кой чёрт тебе Kotlin — с этим тут негусто, и определяться придётся по каким-то косвенным признакам.
Для меня основная польза этого доклада была в не высказанной явно, но прослеживающейся идее: Kotlin будущего — это не тот Kotlin, который есть сейчас. Если сейчас меня по мелочи что-то раздражает, то в будущем это скорее всего будет исправлено. В частности, люди серьёзно задумываются над такими вещами, как метапрограммирование, которое для меня стало блокером для Golang на большом спектре задач. Очень достойная идея о том, что плагин в компилятор автоматически становится плагином в IDE, что при внедрении кодогенераторов Golang опять же может стать болью, и надо её решать. Короче, Kotlin можно брать как стратегическое решение с большим будущим.
7.?Верификация Java байт-кода: когда, как, а может отключить?
Спикер: Никита Липский (Excelsior); оценка: 4.42 ± 0.07.
Завязка такова, что Никита делал простой студенческий доклад об анатомии JVM.

На нём выяснилось, что не только студенты, но и взрослые матёрые разрабы зачастую имеют пробелы в базовых знаниях и не понимают, как работает верификатор байткода.
Такие штуки как GC не требуются спецификацией, и в принципе сборку мусора можно отключить (н-р с помощью Epsilon GC). В противоположность этому, байткод жёстко прописан в JVMS и на один и тот же байткод VM должна отдать один и тот же результат (вне зависимости, корректен он или нет). В результате верификатор пишется один раз, и потом про него забывают. (До поры до времени, мы-то знаем, что Value Types потребуют изменений в верификаторе.) И поэтому в мире есть от силы десяток человек, которые когда-либо писали верификаторы, и Никита — один из них.
Вот в этом слайде всё содержание доклада:

И к вопросу, «зачем ходить на конференции» и «зачем смотреть записи» — в текстовом виде в интернете сложновато добыть связное изложение этих вопросов.
Забавная фотка — количество людей, которые смотрели class-файл изнутри. Почти весь зал. Хм, зачем им это? :-) Если честно, до того, как я начал копаться в кишках JVM и просто кодил веб-приложухи, у меня даже мысли не возникало начать изучать такие подробности, скукота же (на самом деле нет).

Вначале Никита даёт развёрнутую вводную о том, какова структура class-файла, что такое байткод и какие там бывают инструкции и т.п.
Присутствует игра «кто хочет стать миллионером», как Gil Tene, и разные интересные примеры.

Дальше мы вместе с Никитой пробегаемся по стадиям загрузки класса в JVM (loading, linking, initializing) из пятой главы JVMS. Верификация — это первая стадия этапа линковки. После чего мы опускаемся в подробности верификации: проверки на статические (static constraints) и структурные ограничения (structural constraints). Статические проверки делаются в два прохода, на выходе получается control flow graph байткода метода, а структурные ограничения проверяют более сложные вещи, например, что глубина стека в каждой инструкции должна быть определенной величины для любого пути исполнения.
Магия верификатора работает на статическом потоковом анализе, который иногда объясняют в институтах на теории программирования или теории схем программ. Сразу было понятно, что Никита уж как-то слишком складно излагает эту часть — и оказывается, он ведет лекции по потоковому анализу. Каким-то образом сквозь Программный комитет конференции в этом месте просочилась матчасть про полурешётки свойств и так далее.

Вся эта матчасть, тем не менее, легко ложится на привычные джависту вещи вроде Stack Map Frame и конкретные байткоды. Про это есть куча хороших иллюстраций. Более того, мы можем даже посчитать реальное время выполнения задачи верификации, и что с этим сделали в Java 5. После чего обсуждается множество разных чисто практических вещей.
Лично для меня этот доклад дал прочное обоснование (как с точки зрения теории, так и практики) о том, почему рекомендации отключать верификатор байткода (java -jar -Xverify:none MyApp) — это чистое безумие, и что к критике верификатора нужно относиться с большой долей скепсиса. Кроме того, это может здорово помочь при использовании таких библиотек, как ASM (рекомендации по использованию ASM даны прямо по ходу доклада).
6.?Проклятие Spring Test
Спикеры: Кирилл Толкачев (Альфа-Лаборатория) и Евгений Борисов (Naya Technologies); оценка: 4.45 ± 0.05.
Это чисто практический доклад, рассказывающий, как тестировать куски своих микросервисов и применять различные принципы, обсуждаемые в докладе.
Он очень отличается от предыдущих докладов про устройство JVM обилием близких сердцу веб-разработчика вещей вроде живой демонстрации чата, написанного на Spring с использованием стандартной архитектуры с REST и очередями. Рассматриваются животрепещущие вопросы на тему, что мы можем по-быстрому замокировать, а что у нас развалится при использовании наивного подхода.
В качестве акта лёгкого троллинга докладчики тестируют не какие-то произвольные веб-сервисы, а мозг Баруха Садогурского (@jbaruch) и Егора Бугаенко (@yegor256). По условию задачи, ответы Баруха — кэшируются, а Егор может со временем менять мнение и обязательно перед ответом раздумывает (получает данные с помощью очереди).

Писать про этот доклад особо не имеет смысла — его надо именно смотреть. Докладчики живо и интересно показывают основы тестирования с помощью Spring — не только какие-то сухие факты, а именно разработку с нуля до работающего приложения. Интересно, что изначально многие вещи намеренно делаются неправильно и потом эволюционным путём допиливаются до идеала.
Я точно пересмотрю этот доклад в следующий раз, когда нужно будет делать проект на Spring и Spring Boot. Стало понятнее, зачем нужен @SpringBootTest (сделать тест на полный контекст, поменять properties, сделать тесты с определенным скопом — пакет/конфигурация/автоскан), чтобы сохранить изоляцию теста — нужен @TestConfiguration, а @SpringBootConfiguration нужен только для сигнализации @SpringBootTest, что ему пора остановиться. В целом, стало понятно, что тестирование с использованием Spring может быть быстрым, но кэш легко поломать, и для тестов следует использовать только @TestConfiguration.
Имхо, повторюсь, в этом докладе важнее сам процесс разработки и понимание его эволюции, чем конкретный финальный список выводов. Самостоятельно к тем же выводам прийти можно, конечно — но с бездарной потерей огромного количества времени.
5.?Spring – Глубоко и не очень
Спикер: Евгений Борисов (Naya Technologies); оценка: 4.46 ± 0.05.
Ещё один доклад Жени Борисова, который отлично дополняет уже присутствующий в топе «Проклятие Spring Test».
Выводы из доклада, внезапно, даются на первом же слайде, поэтому давайте пробежимся по ним:
- Spring не идеален, но лучше ничего нет. И он всё равно достаточно хороший, поэтому мы его любим;
- На Spring можно и нужно строить свою платформу;
- Не бойтесь его чинить, но не забывайте, что он чинит себя сам;
- Читайте в спеке про обновления.
Женя начинает доклад с известного слайда:

Это к вопросу о том, зачем нужно общаться вживую с разработчиками, ходить на конференции и смотреть свежие записи. Вот это наблюдение Жени я прочувствовал на своей шкуре: значительная часть утверждений про Spring либо враньё, либо безнадежно устарело.
Например, идея самовпрыскивания. При использовании транзакционности бин, который вызывает собственный метод, должен использовать не this, а прокси на себя. Для этого нужно заинжектить самого себя (точнее не самого себя, а собственный прокси). Откуда берётся такая ситуация — Женя подробно объясняет. Это не работало до Spring 4.3, хотя можно было воспользоваться аннотацией @Resource, и иногда это срабатывало, а в XML это работало всегда. Начиная со Spring 4.3 начали работать @Autowired и @Inject, но не стандартный Java-конфиг (семантика Java не позволяет сделать такую хитрую штуку). И всё это заняло четыре с половиной года, начиная с создания бага в трекере Spring.
Следующий пример — про проклятый PropertySourcesPlaceholderConfigurer. Сколько эта штука (точнее, её кастомные реализации) кровушки из меня попила. Женя указывает на то, что в версии 4.2 нужно было его в джаваконфиге указывать как static (иначе всё упадёт с ошибкой), а в свежих версиях — можно либо указать только @PropertySource, либо не указывать вообще, если это Spring Boot. Между этими вещами — тоже годы.
Примеры, кстати, жгут напалмом. Например, циркулярные зависимости между бинами иллюстрируются примером с мужем, который инжектит внутрь себя жену.

Из этих примеров я вынес мысль, что пихать логику в @PostConstruct для блокирующего запуска бизнес-логики — это плохо. Если честно, все эти годы такая мысль даже не приходила в голову (ну это потому что я быдлокодер, бывает) — ведь все эти проблемы решаются тщательно подобранными костылями. Женя рассказывает, как правильно писать такой костыль — самодельную аннотацию @Main, которая делает понятно, что.
Грубо говоря, делается eventListener (новый компонент, в нём над методом — аннотация @EventListener, а в параметрах — какой event мы хотим отловить). Нам нужен ContextRefreshedEvent. Потом необходимо пробежаться по BeanDefinition'ам, найти и дернуть @Main. Но при этом для того, чтобы всё это заработало под Spring Boot, нужно провести определённые манипуляции. Здесь я всё это описывать не буду, кому интересно — посмотрит доклад. Тем более, что для людей, не погружённых в Spring, вся эта магия методов с названиями длиннее 80 символов кажется какой-то дичью. Впрочем, в докладе рассказывается, как сделать, чтобы вся эта дичь подключалась автоматически просто с помощью добавления зависимости в Maven, дабы вам не приходилось каждый раз лезть в этот ад.
И дальше рассказывается ещё много интересных, а иногда и совершенно запретных вещей с написанием BeanFactoryPostProcessor и разруливанием версий Spring. Уверен, что существуют люди, которые наслушались Женю, применили всё это неправильно и потом их сожгли живьём :-)
В целом, доклад позволяет лучше понять, как работает Spring, Spring Boot, и самое главное — нюансы идеологии, которые простым чтением джавадоков не понять. Тут нужно вмешательство и совет опытного Spring-джедая, коим Женя и является. Этот доклад (и другие доклады Жени) стоит пересмотреть сразу же, как стандартных возможностей начнёт не хватать, и захочется написать побольше BeanPostProcessor и BeanFactoryPostProcessor.
4.?Повесть о том, как один инженер HTTP/2 Client разгонял
Спикер: Сергей Куксенко (Oracle); оценка: 4.47 ± 0.06.
Как все, наверное, уже знают, HTTP/2 aka RFC 7540 — это протокол, придуманный господами из Google или ещё кем-то, чтобы заменить старый ламповый HTTP/1.1.
Основную роль в дальнейшем повествовании играют несколько отличий /2 от /1.1:
- Бинарный формат (использование Frames)
- Мультиплексирование множества запросов в единственном TCP соединении
<Request> => <Stream> => <Frame> ... <Frame>
- Сжатие заголовков (HPACK aka RFC 7541)
По сути, HTTP/2 — это такая низкая транспортная подложка, решающая конкретные проблемы предыдущего стандарта.
С другой стороны, в OpenJDK есть JEP 110, «HTTP Client», который был выпущен в рамках JDK 9, но пока не стал частью Java SE. Его выпустили ровно настолько, что его можно посмотреть и обсудить. Выглядит оно примерно так, как и можно ожидать: конструктор с урлами, синхронный и асинхронный API и т.п. Клиент универсальный и работает как с HTTP/1.1, так и с /2.

Докладчик и есть тот человек, который занимался перформансной работой над этим клиентом, о чём он в дальнейшем и рассказывает. Цель в том, чтобы получить достаточно быстрый клиент за разумное время работы разработчика.
Вначале он его побенчмаркал, в надежде, что, возможно, в клиенте и менять особо ничего не надо. В качестве конкурента для сравнения использовался клиент Jetty.

Как-то печально вышло. В данном случае была известная проблема с TCP_NODELAY, если кто-то помнит, что это такое. Про некоторые особо известные косяки люди иногда просто забывают. Тем не менее, Сергей утверждает, что все эти вещи — это не какие-то тайные знания, и типичные косяки очень легко гуглятся и изучаются любым новичком.
Интересно, как это устроено в голове у настоящего специалиста по перформансу. Не у дилетанта какого-то, а у самого настоящего. Он не читал спеку по протоколу до самого последнего момента. Профилировал, писал перформансные тесты, смотрел интерфейс профайлера — но полез читать спеку только в самый последний момент, когда оказалось, что существуют жирные функции, которые отжирают много ресурсов, но по названию непонятно, что они делают. То есть рефлекс «всегда вначале читай спеку», возможно — не самый правильный.
С другой стороны, раз уж читаешь спеку, читай её аккуратно и используй встроенные в неё хаки. После использования нужных хаков клиент начал обгонять Jetty — вот что сила спеки животворящей делает!
В докладе всё это иллюстрируется на реальных данных из предметной области написания HTTP-клиента. Например, предыдущий пример по спеку иллюстрировался процедурой расширения окна в HTTP/2. Наверное, для какой-то части аудитории этот вопрос сам по себе является актуальным, и все примеры с граблями там — это реально полезно. Для меня, если честно, было не очень: в повседневной практике веб-быдлокодинга ты обычно используешь такие библиотеки, однажды раз и навсегда написанные суперпрофессионалами.
Кроме этого, есть ещё набор забавных лайфхаков. Существует миф, что перформансник круглые сутки сидит в Mission Control и делает на его основе какую-то чёрную магию. В практике Сергея, скорей всего он просто будет валить логи в файл и смотреть их подручными способами вот так:


Сразу после этого наглядно показывается, как в сетевой библиотеке можно рефакторить жирный код под глобальным локом в быструю очередь. Блокировки — зло, и простым рефакторингом можно выжать многое.
Параллельно развенчиваются мифы о том, что переход от GC на пулы автоматически сделает нам хорошо — в реальности же можно прийти к ситуации, когда мы не имеем от пулов ничего хорошего, но имеем все минусы работы без пулов.

Там ещё много интересного, но нельзя же хабрапост превращать в огромный сборник скриншотов (хотя хочется).
В целом, доклад оставляет ощущение хорошо переданного майндсета инженера-перформансника, занимающегося работой с сетью, которым внезапно можешь оказаться ты сам. И в качестве бонуса позволяет пройтись по типичным граблям разработки HTTP-клиента.
3.?Fast and Safe Production Monitoring of JVM Applications with BPF Magic
Спикер: Sasha Goldshtein (Sela Group); оценка: 4.49 ± 0.07.
Итак, мы переходим к первой тройке. Этот доклад был особо сложным для понимания. Дело в том, что в целях написания этой статьи я пересматривал все записи на двукратной скорости. Саша сам по себе говорит быстрее обычного человека, плюс весь доклад ведётся на английском языке. Эта комбинация реально выносит мозг, так что если вы слушаете его в первый раз — стоит включить стандартную скорость.
Суть в том, что тот софт, который обычно используется для мониторинга приложения на C++ или Python и на котором Саша собаку съел, можно отлично использовать и для мониторинга JVM-приложений. Всё это будет, конечно, на Linux.
Глобальная задача доклада такова:

В этом плане сразу бросается в глаза слово BPF, о котором многие даже не подозревают. В принципе, в интернете можно найти и другие доклады на схожую тематику, но не применительно к Java.
Я не буду спойлерить весь этот чудесный доклад, а начну с небольшой затравочной истории, которая у непосвященного может вызвать священный трепет.
Доклад начинается с обсуждения других средств мониторинга, с учётом статуса их разработки (все инструменты поделены на новые, стабильные и мёртвые). Например, стабильные вещи типа: ftrace, perf, SystemTap (он требует компилировать и динамически загружать модули ядра — в том числе, на продакшне). Есть новые штуки: SysDig (очень простая, но фич мало), BPF с биндингами на разные языки. Есть ещё много разного — dtrace for Linux, ktap, LTTng и т.п.
Дальше мы выясняем, какие вещи можно узнать про JVM. Оказывается, в JVM есть специальные трейспоинты, которые можно включить и соединяться к ним внешним софтом:

Кроме того, Саша написал тулзу tplist, которую можно вызывать как tplist -p `pidof java` и которая отображает всё это в виде плоского списка, чтобы не нужно было глазами вычитывать.
Интересно, что у всех этих поинтов есть параметры, так что если мы грепнем по monitor__waited, то обнаружим структуру из четырех полей (signed, unsigned, unsigned, signed). К сожалению, кроме типов значений, просто так мы о параметрах ничего не узнаем. Но инфу всё-таки можно отрыть в .stp-файлах, хотя и не в самой удобной форме. Как минимум, оттуда можно вытянуть имена аргументов.
Дальше, чтобы перейти к BPF, Саша приводит пример приложения, которое нужно отладить на проде: понять, какой кусок кода печатает в консоль ересь, при условии, что отладчиком подключиться нам не дадут. Задача ужасная, обычный админ сбежит от неё в ужасе. Нужно подключить -XX:PreserveFramePointer (дающий 3% оверхеда), и дальше используется утилита trace из BCC:
trace `SyS_write (arg1==1)` "%s", arg2' -U -p `pidof java`trace обязательно запускается под рутом. Дальше мы говорим, что надо трейсить (в данном случае — SyS_write — сискол на запись), выставляем условие ((arg1==1)), сообщение для вывода ("%s", arg2), -U — userspace call stack, ну, и конечно фильтрануть по PIDу. Получается как-то так:

Дальше с помощью предварительно написанной скриптятины (create-java-perf-map из perf-map-agent) превращаем адреса методов в их настоящие названия методов в Java.
Дальше нужно немного покопаться в выхлопе наших команд — и ура! Мы только что получили конкретное место, которое выводит нужные строчки.
Можете провернуть такой фокус у себя на проде: непривычный к такому тулингу обыватель может посчитать это магией и поверить во всё, что угодно. В следующий раз можно будет сказать админу, что ты умеешь читать его мысли и поднимать мёртвых.
Этот доклад переполнен такими фантастическими штуками, которые на самом деле объясняются использованием продвинутого тулинга, в том числе утилит из BCC.
Java-приложение слишком часто собирает мусор с помощью System.gc() и хочется узнать — почему? Да пожалуйста, только кроме -XX:PreserveFramePointer придётся включить ещё и -XX:+ExtendedDTraceProbes — очень дорогую опцию, которую не получится держать на постоянку. Если часто просить админа включать и выключать её — он может догадаться, что ты не настоящий некромант (на самом деле, ты хуже — ты джавист, который сейчас вынесет ему мозг). Ну и после этого провести адский ритуал, о котором рассказывает Саша: нужно будет аттачнуться к method__entry.
Кроме того, Саша расскажет, чем плох perf (спойлер: выталкивает слишком много данных для анализа в юзерспейсе) и о всяких таких вещах.
Очень рекомендую прослушать и сделать выводы из этого доклада совершенно всем, кто занимается перформансом Java-приложения на платформе GNU/Linux. Это абсолютный must have.
2.?Сделаем Hibernate снова быстрым
Спикер: Николай Алименков (EPAM); оценка: 4.51 ± 0.04.
Что когда-нибудь ещё придётся увидеть Hibernate в топе докладов на втором месте — оказалось сюрпризом, если не шоком. Hibernate — это такая штука, которую выпустили в 2001 году. Разве за все эти годы про него не сказано всё, что только возможно? Остались ли ещё люди, которые будут это слушать?
Остались. Но только в случае, если это действительно хороший доклад, а Николай Алименков — именно тот человек, который разбирается в сортах Hibernate. В течение лет эдак пяти он делает доклады с холиворными названиями типа «Почему я ненавижу Hibernate» или «Босиком по граблям Hibernate», и так далее — список велик, и часть из них можно пересмотреть на YouTube.
Хочется сказать, что озвученная в заголовке проблема мне действительно близка. Люди используют Hibernate неправильно, отказываются думать мозгом, не читают умных книжек и потом плачут, что «Hibernate тормозит». С одной стороны, это вызывает такое неприятное ощущение, нечто среднее между жалостью и снобским презрением. С другой стороны, если у системы такой API, что с большинство пользователей не может освоить его в течение почти 17 лет — с таким API явно что-то не так.
Николай в первом же слайде делает disclaimer на тему, что это только его персональный опыт. Но в данном случае наш опыт полностью совпадает.

Доклад начинается с небольшой обязательной вводной о том, что же такое Hibernate, какую задачу он решает — универсальный ООП-адаптер на все базы данных, показывает, что Hibernate работает не магически, а внутри себя использует всё тот же JDBC, JTA в контейнере и так далее. Взглянув всю цепочку уровней абстракции, мы понимаем, что на перформанс может влиять любая её часть и любой переход, и чтобы их улучшать — надо уметь их измерять.
Для измерения предлагается использовать логи самого Hibernate (hibernate.generate_statistics=true, логгер org.hibernate.stat на уровне DEBUG и т.п.) либо писать микробенчмарки на JMH.
Для того, чтобы посмотреть, какие запросы уходят в базу, предлагается использовать всевозможные datasource proxy (p6spy, datasource-proxy и т.п.) и смотреть сырые данные. Можно поставить какой-нибудь counting interceptor — чтобы посчитать, сколько физических запросов отправилось в базу. Ну и конечно, можно в самом Hibernate включить логирование запросов.
Дальше Николай показывает, как много интересного можно вычитать в логе Hibernate даже относительно сравнительно небольшого запроса. Лог кричит и визжит, что у тебя всё неправильно, и нужно срочно переделывать. (Правда, обычно его никто не читает, пока гром не грянет.) В том числе лог рассказывает, как читать статистику в логах, куда и на что тратилось время.
В докладе рассказывается об основных вещах, которые можно и нужно тюнить. Например, настройки JDBC, такие как правильная реализация connection pool — в зависимости от выбранного пула, перформанс может отличаться в разы. Стоит взглянуть на размер батча, рассмотреть возможность перехода на нативные запросы или даже использовать голый JDBC в Session.doWork(), если всё действительно плохо.
Николай не гнушается пробежаться по проблемам, которые все якобы должны знать, но на самом деле все забивают. Например, знаменитая N+1. Если вам кто-то говорил, что «мнение, что N+1 — это проблема, устарело», то… нет, так не пойдёт. Это просто от лени и нежелания думать. Не беда — за тебя подумал докладчик: далее следует огромная секция про то, как уменьшать количество запросов, включая такие сравнительно редко используемые фичи, как NamedEntityGraph (это фича не Hibnerate, а JPA, но одно другому не мешает).
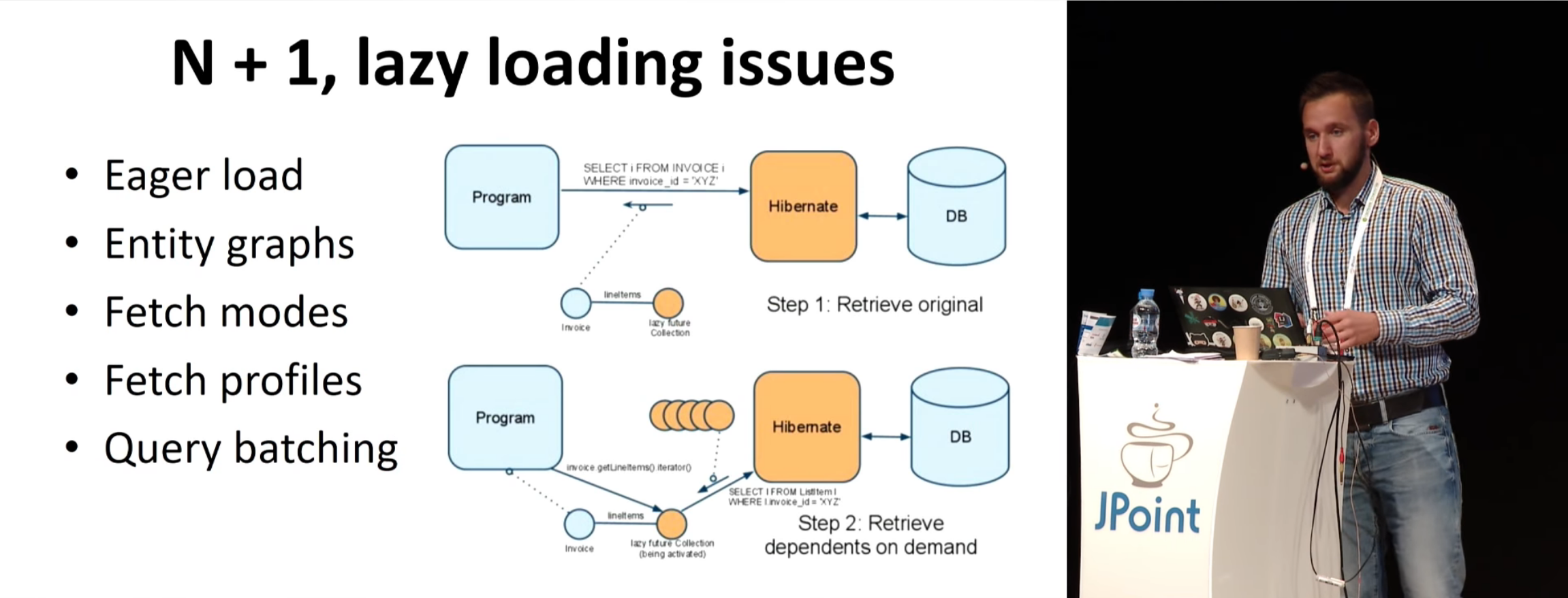
Дальше по ходу рассматриваются батчи, second level cache и так далее. Ясно, что все, кто действительно работал с Hibernate, знают про second level cache, но не все понимают, как это работает, и самое главное — что транзакционный режим есть только у каких-то отдельных решений (потому что этот режим слишком тяжеловесный). Рассматривается способ работы Query Cache и так далее и тому подобное.

В целом, этот доклад не рассказывает каких-то действительно новых вещей, которые никто раньше не знал или которые нельзя найти в документации. Но он даёт очень чёткий и проверенный в бою чек-лист вещей, которые можно и нужно тюнить при работе с Hibernate. Как же этот доклад пролез в топ? Мне кажется, секрет в том, что этот курс на самом деле — идеальный курс молодого бойца, пройти который в особенности стоит перебежчикам из других технологий типа Ruby. Представьте, что вы нанимаете людей, которые раньше пользовались другими решениями (не Hibernate) — вы можете либо потратить несколько дней на адскую работу по составлению своего «курса молодого бойца», а можете просто отдать им видеозапись этого доклада. И уже поверх него наворачивать «мясо» по раскрытию разных специальных тем и инструментов.
1.?Shenandoah: сборщик мусора, который смог
Спикер: Алексей Шипилёв (Red Hat); оценка: 4.64 ± 0.04.
И наконец, наш победитель. Как всегда, это доклад Лёши.
А это ведь странно. Как получается, что он раз за разом делает самые популярные доклады? Давайте оглянемся назад на наш рейтинг: Hibernate использует значительная часть аудитории (допустим, треть), Spring — тоже немало. Почти каждому приходилось мониторить и разбираться с перформансом на проде и так далее. Но писать свой Garbage Collector?
Кажется, тут играет свою роль загадочная русская душа, тяготеющая к небывалому хардкору. Если посмотреть на людей, выползающих после доклада Шипилёва из зала, то большинство из них как будто оплавились от вспышки сверхновой. (Некоторые, конечно, ничего не слушали и смотрели на картинки — им норм.)
Кстати, как вы, наверное, помните, я пишу эту статью, пересматривая все доклады на двукратной скорости. На этой скорости Лёша говорит так быстро и такие страшные вещи, что у меня из ушей потекла кровь.
Собственно, возвращаясь к теме. Доклад — о новом Garbage Collector под названием Shenandoah, который делает команда Лёши. Его отличие в том, что он работает с очень низкими паузами. Слово «Shenandoah» читается как «Шенандоа» (как национальный парк в США и река в нём) или в обиходе просто «Шинандa» (с ударением на последний слог).
Во-первых, доклад начинается с предложения до его прослушивания прочитать GC Handbook. Дело в том, что большинство алгоритмов GC берётся из этого учебника, а все новшества — это некие небольшие дополнения к ним. Но раз мы уже на докладе — уже поздно читать GC Handbook. Придётся ближайший час выживать без него.
Первые слайды — это крупная картина вещей, происходящих вокруг GC. Ландшафт существующих решений и место Shenandoah в этом мире.

Крупно рассматривается, как устроена в Shenandoah куча, как работает цикл сборки и так далее.

Там есть две паузы, но они субмиллисекундные, и для большинства задач этого более чем достаточно. Главное достижение в том, что жирная часть, которая в другом коллекторе ушла бы в паузу, в случае Shenandoah делается параллельно с коллектором.
Дальше рассматриваются все стадии этого процесса. Вначале — Concurrent Mark, который в принципе решён человечеством в различных GC, но не без проблем, влияющих на производительность. ЧТОБЫ НАЙТИ МУСОР — НУЖНО ДУМАТЬ КАК МУСОР!

Рассказываются о преимуществах и недостатках этих подходов (включая первый, реализованный в Epsilon GC, который написал Лёша же).
Рассматриваем чёрно-серо-белый алгоритм Дейкстры. Видим, как при выполнении STW-сборки граф волнообразным движением перекрашивается из белого в серое, а потом в чёрное.

Узнав, как устроен STW, смотрим на concurrent-реализацию, её проблемы и решения (incremental update и snapshot-at-the-beginning — SATB).

Конечно, всё это приправлено кучей ассемблера и совершенно адских рассуждений, которые нужно переслушивать по нескольку раз :-)

В конце концов мы приходим к выводу, что в init mark и final mark самое жирное — это rootset, и корень зла — размер этого рутсета.
Но это только начало, потому что concurrent copy — куда сложней, чем concurrent mark. Мы снова возвращаемся к тому, как работает stop the world.

Думаю, дальше описывать происходящее нет смысла, потому что — смотрите цитату с картинки. Это однозначно лучший доклад про Garbage Collection, сделанный на русском языке. А может быть, лучший доклад про Garbage Collection вообще.
Кроме того, у него есть продолжение, сделанное осенью на Joker 2017, но пока что ещё не выложенное в публичный доступ.
Рекомендую посмотреть этот доклад трём основным категориям слушателей:
- Специалистам, плотно работающим с JVM и её перформансом, которым в точности нужно представлять работу Shenandoah и работу GC вообще;
- Всем, кому хочется узнать больше о магии, благодаря которой работает наша Java-платформа;
- Всем, кому так или иначе нужно прочитать о GC. Потому что в интернете информации о внутреннем устройстве GC сильно меньше, чем хотелось бы. Детали реализации, очевидно, не являются частью стандарта, чтобы сесть и почитать. Информацию о них можно взять только из таких вот уникальных докладов.
Заключение
В этой статье мы кратко рассмотрели все самые популярные доклады на JPoint 2017. Вполне возможно, по большинству из них будут выпущены отдельные статьи на Хабре с подробными расшифровками.
Крайне рекомендую самостоятельно пробежаться по всем этим докладам и сделать собственные выводы. Каждый из них занимает всего около часа.
История JPoint на этом, конечно, не заканчивается. В этом году, 6-7 апреля, на площадке Конгресс-центра ЦМТ в Москве пройдёт следующий JPoint 2018, на котором будет много новых, интересных и полезных докладов. Приобрести билеты можно уже сейчас.
Комментарии (6)

artem_dobrovinskiy
11.01.2018 10:57Одного меня коробит от «чуваков», разбросанных по статье? Я этого слова со школы не слышал.


bisor
Спасибо за статью и видео!
olegchir Автор
На днях сделаю ещё одну статью с лучшими докладами, на этот раз по JBreak-2017. Stay tuned.
olegchir Автор
Готово.