

Приятного чтения!
Предисловие
Изучать программирование очень важно, если мы хотим научиться анализировать данные. Вне всякого сомнения «наука о данных» должна выполняться на современных компьютерах, но у нас есть выбор между использованием графических интерфейсов готовых программных продуктов и программированием на существующих языках. Мы оба, я и Гаррет, убеждены в том, что программирование в современном мире является неотъемлемой и жизненно важным навыком для тех, кто постоянно работает с данными. Графический интерфейс, несмотря на все свои удобства, препятствует хорошему анализу данных:
- Воспроизводимости (возможность воссоздать предыдущие результаты)
- Автоматизации (возможность быстро получить результаты при изменении данных)
- Коммуникации (Код — это всего лишь текст, поэтому его проще понять. Обучаясь, очень легко получить помощь, будь то Google Groups, электронная почта, Stack Overflow и др)
Не бойтесь программировать! Любой может научиться программировать при правильной мотивации, а эта книга организована таким образом, чтобы поддерживать вас мотивированным. Это не справочник; это книга о трёх проблемах. Книга проведёт вас через увлекательные основы языка R и даже позволит заглянуть на следующий уровень сложности. Настоящие задачи являются лучшим способом обучения, потому что вы не запоминаете функции вне контекста, вы изучаете их для решения проблем из реального мира. Вы будете обучаться выполняя задания.
В процессе обучения программированию вы будете разочаровываться/расстраиваться. Обучение новому языку требует времени и терпения. Стоит помнить, что разочарование это естественное чувство, появление которого необходимо фиксировать и воспринимать как положительный момент. Разочарование это способ мозга лениться, отвлекая ваше внимание на вещи более простые и весёлые. Если вы действительно хотите обрести хорошую форму, то необходимо продолжать работать, несмотря на всю боль тела. Если вы действительно хотите научиться программировать, то необходимо заставлять мозг концентрироваться и включаться в работу. Запомните этот момент, потому что это означает, что вы приступили к растяжке — растяжке самого себя. Каждый день заставляйте себя двигаться вперед и скоро вы станете уверенным программистом.
Мы надеемся, что чтение нашего совместного труда с Гарретом принесёт вам удовольствие.
Вступление
Эта книга научит вас программировать на языке R. Ваш путь начнётся с загрузки данных и закончится написанием собственных функций (которые с легкостью превзойдут функции других пользователей языка R). Однако это не обычное введение в язык R. Я хочу помочь вам стать датологами (аналитиками), так же как и компьютерными специалистами, поэтому эта книга будет фокусироваться на навыках программирования для решения задач в датологии.
Главы в книге разделены и отсортированы в порядке возрастания сложности реализации трёх практических проектов. Я выбрал эти проекты по двум причинам. Во-первых, они отображают широкие возможности языка R. Вы научитесь загружать данные, собирать и разбирать объекты, писать собственные функции и использовать все доступные в R инструменты, такие как if-else конструкции, for циклы, классы, пакеты, средства отладки. Проекты так же научат вас писать векторизованный код, который использует всё мощь языка R.
Однако, что важнее всего, проекты научат вас решать логические задачи в науке о данных — а задач действительно много! Работая с данными нам необходимо их хранить, извлекать и изменять большие массивы значений без внесения погрешностей. В процессе обучения мы научимся не только программировать на R, но и использовать наше мастерство программиста для поддержания своей работы в качестве датолога.
Не каждому программисту необходимо быть датологом, поэтому не каждому программисту будет полезна эта книга. Вы найдете эту книгу полезно для себе, если относитесь к одной из следующих категорий:
- Вы уже используете R в качестве статистического инструмента, но хотите научиться писать собственные функции и симуляции на R.
- Вы хотите научиться программировать и видите смысл в изучении языка способного работать с данными
Одним из больших разочарований в этой книге является отсутствие упоминаний и рассмотрения использования языка R в традиционных приложениях — модели и графы. Я воспринимаю R как типичный язык программирования. Почему такой узкий фокус? R проектировался как инструмент, который поможет специалистам анализировать данные. Он обладает множеством превосходных функций для построения графиков и моделирования. В результате множество статистов используют R, как если бы он был обычным программным обеспечением — они изучают только те функции, которые им необходимы, но не обращают внимание на остальное.
Часть №1
Проект 1: утяжеленные игральные кости
Компьютеры позволяют собирать, манипулировать, визуализировать массивы данных и всё это со скоростью, которая удивила бы вчерашних ученых. Вкратце, компьютеры дают вам научную суперсилу! Однако, чтобы научиться пользоваться этими суперсилами на полную, вам необходимо будет обзавестись навыками программирования.
Как ученый занимающийся данными и способный программировать, вы сможете повысить свои навыки в следующих направлениях:
- Запоминать (хранить) большие массивы данных
- Запрашивать данные
- Производить сложные вычисления над большими объемами данных
- Выполнять повторяющиеся задания без скуки
Компьютеры могут решать все эти задачи быстро и безошибочно, что позволяет вашему сознанию заниматься тем, что у него лучше всего получается: принимать решения и наделять смыслом.
Звучит потрясающе? Замечательно! Приступим.
Будучи студентом в колледже я мечтал поехать в Лас-Вегас. В то время я был уверен, что знание статистики поможет мне сорвать большой куш. Если именно это подтолкнуло вас к изучению науки о данных, то прошу вас присесть. У меня для вас плохие новости. На длинной дистанции даже статистик проиграет множество денег в казино. А всё потому, что в каждой отдельной игре шансы на выигрыш больше у казино. Однако всегда можно найти лазейку. Вы можете зарабатывать деньги — надежно. Всё что необходимо делать — стать владельцем казино.
Хотите верьте, хотите нет, но R может вам в этом помочь. На всём протяжении книги мы будем использовать R для создания трёх виртуальных объектов: пару игральных костей, которые мы сможем бросать; колоду карт, которую сможем тасовать и раздавать; слот-автомат в котором смоделируем игру из настоящего игрального терминала. После этого, всё что вам необходимо будет сделать, так это добавить немного графики и открыть счет в банке (и получить несколько государственных лицензий), и вы в деле! С остальными деталями разберетесь сами.
Проекты кажутся незначительными, но в действительности каждый из них позволит заглянуть глубоко «под капот» R. После их завершения вы станете экспертом в области анализа и обработки данных. Вы научитесь хранить данные в памяти компьютера, обрабатывать их, приводить их к другому типу, производить преобразования и т.д. Так же вы научитесь сами писать программы на R, которые затем могут быть использованы для анализа данных и симуляции.
Если симуляция игровых автоматов (игральных костей, карт) кажется вам детской забавой, то подумайте вот о чем: игра на игровых автоматах это процесс. Раз вы можете смоделировать его, значит вы сможете смоделировать другие процессы. Эти проекты предоставляют конкретные примеры использования компонент языка R: объекты, типы данных, классы, нотации, функции, переменные среды, циклы, условные операторы, векторизацию. Первый проект познакомит вас с основами языка R, которые в дальнейшем помогут вам изучить всё перечисленное ранее.
Первая задача проста: написать код на R, который будет моделировать бросание двух игральных костей. После этого мы изменим веса значений игральной кости для того, чтобы вы стали больше выигрывать :)
В этом проекты вы научитесь как:
- Использовать R и RStudio
- Выполнять команды на R
- Создавать объекты
- Писать свои функции и скрипты
- Загружать и использовать пакеты
- Генерировать тестовые данные
- Строить графики
- Использовать документацию
Не бойтесь, если вам кажется, что информации слишком много и вы не успеете с ней разобраться. Эти темы еще будут затрагиваться на протяжении 2 и 3 проектов.
Глава №1
Основы основ
Эта глава является обзорной по языку R, что позволит вам приступить к программированию без промедления. Вы создадите две виртуальные игральные кости, которые будут генерировать случайные значения. Если вы раньше не программировали — не бойтесь, эта глава научит вас всему что необходимо.
Для того, чтобы смоделировать игральные кости необходимо описать их свойства. Физический объект мы в компьютер не поместим, а если и поместим, то вряд ли потом получится его собрать обратно, но мы можем сохранить информацию об объекте в памяти компьютера.
Какую информацию необходимо сохранить? У игральной кости есть шесть различных «кусочков» полезной информации: результатом броска игральной кости может быть только одно значение из 6 (1, 2, 3, 4, 5, 6). Эти данные мы можем сохранить как набор целочисленных значений.
Давайте разберемся сперва с сохранением этих значений, а потом рассмотрим метод «броска» игральных костей.
Пользовательский интерфейс R
Перед тем как просить свой компьютер сохранить определенные значения, необходимо научиться с ним разговаривать. А вот здесь нам на помощь уже приходят R и RStudio. RStudio даёт возможность разговаривать с компьютером, а R — язык, на которым вы будете разговаривать. Запустите RStudio.
Интерфейс RStudio прост. Вводите команды в консоли RStudio, нажимаете Enter для их выполнения. Код, который вы вводите в консоль называется командой, потому что он приказывает компьютеру выполнить определенные действия. Строка на которой вводится команда называется командной строкой. После того, как вы вводите в командную строку что-то и нажимаете Enter, компьютер выполняет эту команду и выводит результат на экран. Сразу же после результата выполнения предыдущей команды появляется новая строка запроса RStudio.
Например, если вы введете 1+1 и нажмете Enter, RStudio выведет:
> 1+1
[1] 2
>
Вы, наверно, обратили внимание на [1] сразу перед результатов вычислений. R всего лишь говорит нам, что это первая строка результатирующего вывода.
Некоторые команды возвращают более одного значения и они могут занимать несколько строк. Например, команда 100:130 возвращает 31 значение; она создаёт последовательность целых чисел от 100 до 130. Обратите внимание, что цифры в квадратных скобках отображаются в самом начале первой и второй строки вывода. Эти значения говорят о том, что вторая строка начинается с 26 значения из последовательности. В большинстве случаев вы можете игнорировать значения в квадратных скобках:
> 100:130
[1] 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124
[26] 125 126 127 128 129 130
>
Оператор «двоеточие» (:) возвращает все целочисленные значения между двумя числами. Это простой способ создавать целочисленные последовательности.
Когда происходит компиляция?
В некоторых языках, таких как C/Java/C++/FORTRAN, необходимо преобразовывать читаемый код в машинный, перед тем как выполнить его. Если вы ранее программировали на одном из этих языков, то, наверно, задаётесь вопросом, а необходимо ли компилировать код в R. Ответ: нет. R является динамическим языком программирования, это значит что R автоматически интерпретирует ваш код, как только вы запускаете его на выполнение.
Если вы введете неполную команду и нажмете Enter, R отобразит продолжение запроса на ввод — "+". Либо завершите ввод команды, либо нажмите Esc, чтобы прервать его и начать заново:
> 5-
+ 1
[1] 4
>
Если вы введете команду, которую R не может распознать, то будет выведено сообщение об ошибке. Если вы когда-либо увидите сообщение об ошибке, не паникуйте. R всего лишь сообщает вам о том, что не смог выполнить определенную команду по какой-то причине. Вы можете затем попробовать другую команду, в следующей командной строке:
> 3 % 6
Error: unexpected input in "3 % 6"
>
Как только вы почувствуете себя свободно работая в командной строке, можете делать всё, что делает самый продвинутый калькулятор. Например, начнем с базовой арифметики:
> 2 * 3
[1] 6
> 4 - 1
[1] 3
> 6 / (4 - 1)
[1] 2
>
R обрабатывает хэштеги (#) по особому. Никакая команда не будет выполнена после хэштега (#). Это делает хэштеги полезными при комментировании или документировании кода. Хэштег известен в R как «символ комментария».
Отмена команд
Некоторые команды в R могут выполняться длительное время. Вы можете прервать выполнение комбинацией ctrl+c, однако помните, что и само прерывание команды может занять длительное время.
Теперь, когда вы знаете как использовать R, давайте создадим виртуальную игральную кость. Оператор ":", с которым мы уже встречались несколько страниц назад, позволяет удобно создать группу чисел от 1 до 6.
Оператор ":" возвращает вектор, одномерный массив чисел:
> 1:6
[1] 1 2 3 4 5 6
Вот так и выглядит виртуальная игральная кость! Но не спешите расстраиваться, это еще не всё. Выполнение команды «1:6» всего лишь создаёт и отображает целочисленный вектор, но мы его нигде не сохраняем. Если мы хотим иметь возможность повторно использовать эти числа, то необходимо их где-то сохранить. В этом нам поможет создание объектов.
Объекты
R позволяет сохранять данные в объектах. Что представляет собой объект? Всего лишь имя, которое используется для обращения к сохраненным данным. Например, вы можете сохранить данные в объектах a или b. В любом месте, где R встречает объект он заменяет его хранящимся внутри значением, например:
> a <- 1
> a
[1] 1
> a + 2
[1] 3
1. Чтобы создать объект в R придумайте ему имя и воспользуйтесь символом "<-" для сохранения данных. R создаст объект, присвоит ему имя и сохранит всё то, что находится справа от "<-".
2. Когда вы спрашиваете R, что же находится в «a», то R выводит сохраненные данные на следующей строке.
3. Вы так же можете воспользоваться созданными объектами в последующих командах.
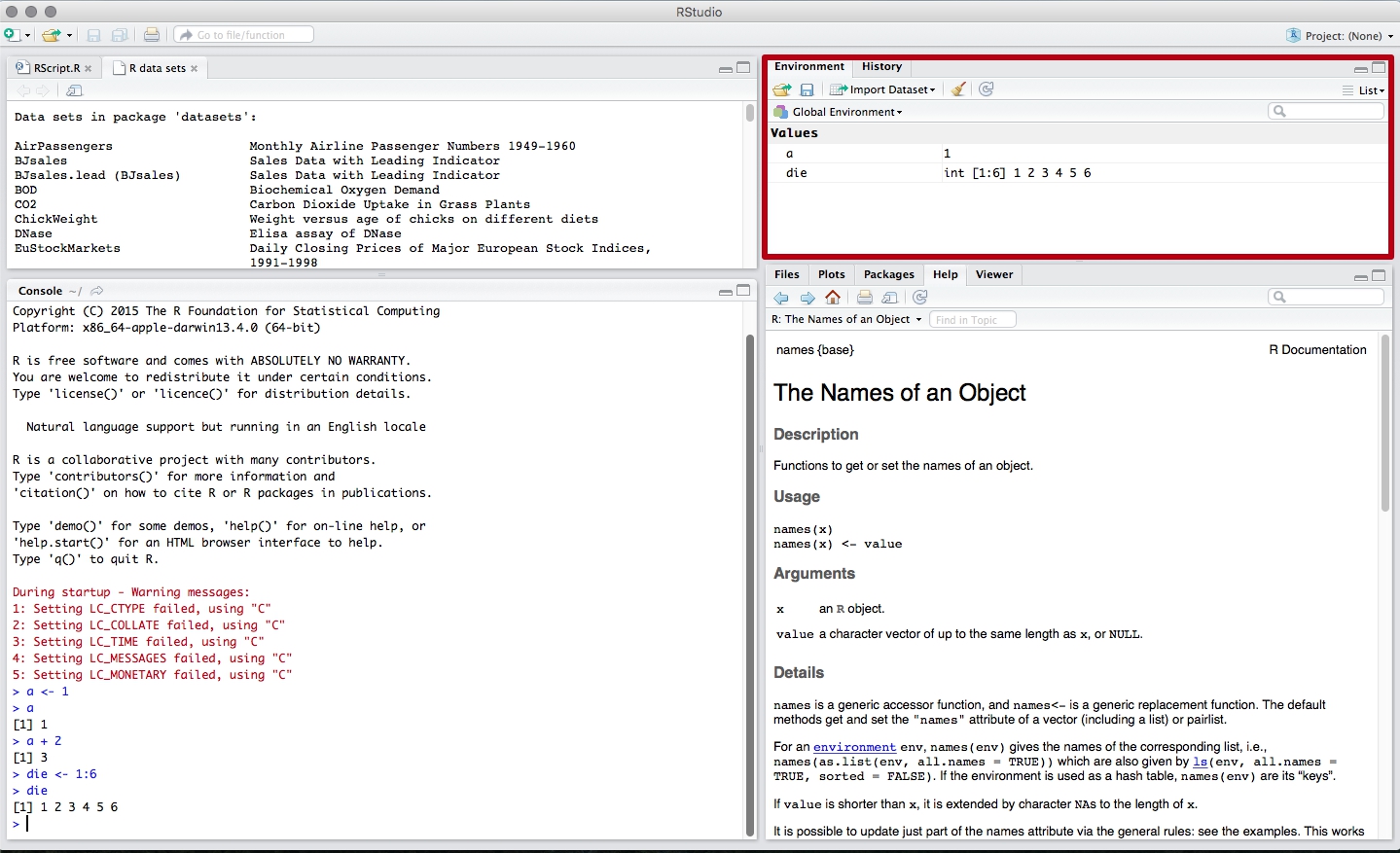
Другой пример, код ниже создаёт новый объект с именем die содержащий числа от 1 до 6. Чтобы увидеть, что содержит объект просто введите имя объекта и нажмите Enter.
> die <- 1:6
> die
[1] 1 2 3 4 5 6
После того, как вы создали объект он появится в панели переменных RStudio. В этой части интерфейса вы сможете найти все созданные объекты со времени запуска RStudio.
Вы можете называть объекты в R как угодно, однако есть несколько базовых правил. Во-первых, имя объекта не может начинаться с цифры. Во-вторых, имя не может содержать специальные символы — ^, !, $, @, +, -, /, *.
| Правильные имена | Неправильные имена |
|---|---|
| my_var | ^mean |
| FOO | 2nd |
| b | !bad |
Стоит помнить, что в R переменные Name и name являются двумя разными переменными.
R перезаписывает любую ранее сохраненную информацию в объекте без каких-либо запросов на разрешение осуществления этого действия. Поэтому хорошей практикой является отказ от повторного использования уже существующих переменных:
> my_number <- 1
> my_number
[1] 1
> my_number <- 999
> my_number
[1] 999
С помощью функции ls() вы можете получить список имён переменных, которые уже используются:
> ls()
[1] "a" "die" "my_number"
Вы так же можете просто посмотреть на панель переменных в RStudio, чтобы определить, какие имена переменных уже используются и какие данные в них хранятся.
Теперь у вас есть виртуальная игральная кость, которая хранится в памяти компьютера. В любой момент вы можете получить к ней доступ просто введя в командную строку die. Что вы можете делать с игральной костью? Достаточно много. R заменит объект его содержимым в любой команде. Поэтому, например, вы можете выполнять различные арифметические операции над значениями игральной кости. Математика не так важна при броске игральной кости, однако при работе с множеством данных станет незаменимым помощником. Давайте посмотрим, как и что можно сделать:
> die - 1
[1] 0 1 2 3 4 5
> die / 2
[1] 0.5 1.0 1.5 2.0 2.5 3.0
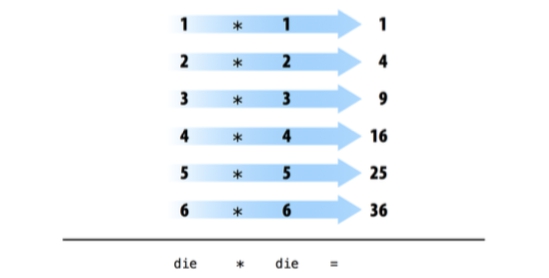
> die * die
[1] 1 4 9 16 25 36
Если вы большой фанат линейной алгебры (а кто нет?), то вы наверняка заметили, что R не всегда следует правилам матричного умножения. Вместо этого R использует по-элементное умножение. Когда вы работаете с множеством чисел, R применит определенную операцию к каждому элементу в множестве по-отдельности. Например, когда мы запускаем на выполнение die — 1, то R вычитает единицу из каждого элемента в die.
При использовании нескольких векторов в операциях, R сперва производит выравнивание длин векторов и лишь затем поэлементно выполняет саму операцию. Например, при выполнении операции die * die, R выравнивает длины двух векторов, а затем умножает первое значение из первого вектора на первое значение из второго вектора, и т.д., до тех пор, пока все элементы не будут перемножены. Результатом этой операции будет новый вектор такой же длины, как и оба перемножаемых вектора.
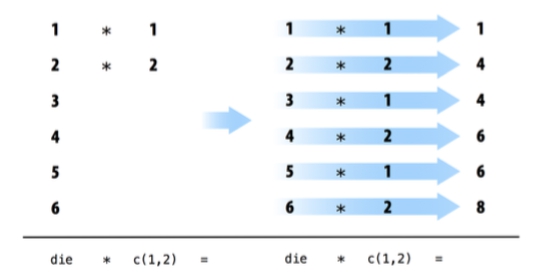
Если вы передаёте R два вектора различной длины, то R «повторит» / «зациклит» вектор меньшей длины до тех пор, пока он не станет равен по длине большему вектору. Изменение меньшего вектора не является постоянным изменение (исходный вектор не меняется), он дополняется только на время операции. Если длина большего вектора не кратна длине меньшего вектора, то R выдаст предупреждение. Такое поведение известно как vector recycling (векторная переработка) и позволяет R выполнять по-элементные операции:
> 1:4
[1] 1 2 3 4
> die
[1] 1 2 3 4 5 6
> die + 1:2
[1] 2 4 4 6 6 8
> die + 1:4
[1] 2 4 6 8 6 8
Warning message:
In die + 1:4 :
longer object length is not a multiple of shorter object length
По-элементные операции крайне важны в R, так как позволяют обрабатывать группы значений в определенном порядке. Когда вы приступите к работе с множеством данных, по-элементные операции позволят убедится в том, что данные одного наблюдения точно соответствуют данным из другого наблюдения. По-элементные операции так же упрощают создание собственных функций и программ на R.
Однако не думайте, что в R отказались от традиционного матричного произведения. Вам всего лишь надо воспользоваться нужным оператором.
Для внутреннего произведения воспользуйтесь оператором %*%, а для внешнего — %o%.
> die %*% die
[,1]
[1,] 91
> die %o% die
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 2 3 4 5 6
[2,] 2 4 6 8 10 12
[3,] 3 6 9 12 15 18
[4,] 4 8 12 16 20 24
[5,] 5 10 15 20 25 30
[6,] 6 12 18 24 30 36
Вы так же можете транспонировать матрицу используя функцию t и вычислить её определитель с помощью функции det.
Не беспокойтесь, если вы не знакомы с этими функциями. Их описание просто найти в документации, к тому же, в этой книге они вам не понадобятся.
Теперь, когда вы разобрались, как выполнять математические операции над значениями игральной кости, давайте посмотрим, каким образом мы можем запрограммировать бросок (выбрасывание костей). Для броска игральной кости понадобится нечто более магическое, чем базовая арифметика; вам необходимо будет случайным образом выбрать одно из значений игральной кости. А вот для этого вам понадобится функция.
Функции
R изначально содержит множество полезных и удивительных функций, которые вы можете использовать для таких задач как, например, генерирование случайной выборки. Например, вы можете округлить число функцией round(), или вычислить факториал числа функцией factorial(). Использовать функции достаточно просто. Пишете имя функции, которую хотите использовать, а в круглых скобках данные над которыми необходимо произвести вычисления:
> round(3.1415)
[1] 3
> factorial(3)
[1] 6
Данные, которые вы передаёте в функцию называются аргументом функции. Аргументом могут быть как необработанные данные (raw data), объекты или другие функции R. В последнем случае R будет выполнять функции в порядке уменьшения их вложенности.
> mean(1:6)
[1] 3.5
> mean(die)
[1] 3.5
> round(mean(die))
[1] 4
К нашему счастью в R есть функция, которая может помочь нам с реализацией броска игральной кости. Вы можете смоделировать бросок игральной кости используя функцию sample. Функция sample принимает два аргумента: вектор x и именной параметр size. Функция sample вернет size элементов из вектора x.
> sample(x = 1:4, size = 2)
[1] 2 1
Чтобы симулировать бросок игральной кости и получить в качестве результата одно числовое значение, установите x равным die и выделите/выберите один случайный элемент.
При каждом запуске у вас будет разное значение:
> sample(x = die, size = 1)
[1] 2
> sample(x = die, size = 1)
[1] 6
> sample(x = die, size = 1)
[1] 1
Множество функции в R принимают несколько аргументов, которые помогают выполнять им поставленную задачу. Вы можете передавать в функцию сколько угодно аргументов до тех пор, пока каждый из них разделен запятой.
Вы могли обратить внимание на то, что я присвоил значения die и 1 определенным именным аргументам функции sample — x и size. Каждый аргумент в функции R имеет своё имя. Вы можете уточнить, какие значения каким аргументам присваивать, как это было показано в предыдущем примере. Это становится крайне удобно делать, когда вы передаете множество параметров в одну функцию; именованные аргументы исключают ошибки с передачей не тех данных не тем аргументам. Использование имён является решением каждого и не является обязательным. Вы можете замечать, что пользователи R часто не указывают наименование первого аргумента функции. Предыдущий код может быть переписан следующим образом:
> sample(die, size = 1)
[1] 2
> sample(die, 1)
[1] 2
Очень часто имя первого аргумента не слишком содержательно и, чаще всего понятно какие данные необходимо передать в функцию первыми.
Как вам узнать, какие имена аргументов необходимо использовать? Если вы попробуете использовать имена, которые функция не ожидает, то скорее всего получите сообщение об ошибке:
> round(3.1415, corners = 4)
Error in round(3.1415, corners = 4) : unused argument (corners = 4)
Если вы сомневаетесь, какие имена аргументов можно передавать в функцию, то можете воспользоваться функцией args, которая выведет список всех возможных именных аргументов определенной функции. Для этого поместите имя функции в круглые скобки в качестве аргумента — args(имя функции). Например, вы видите, что функция round принимает два аргумента — один с именем x, второй с именем digits:
> args(round)
function (x, digits = 0)
NULL
> args(sample)
function (x, size, replace = FALSE, prob = NULL)
NULL
> args(args)
function (name)
NULL
Заметили ли вы, что именной аргумент digits в функции round установлен в 0 по умолчанию? Зачастую функции в R принимают необязательные параметры, такие как digits. Эти аргументы считаются необязательными потому, что им уже присвоено значение по умолчанию. Вы можете передать новое значение для такого параметра, если хотите, или воспользоваться предоставляемым по умолчанию. Например, round округлит чисто до ближайших 0 значений после запятой по умолчанию. Для того, чтобы перезаписать значение по умолчанию передайте новое:
> round(3.14151617, digits = 3)
[1] 3.142
Вам стоит указывать именные аргументы после первого или второго аргумента функции, когда вызываете функцию с множеством аргументов. Почему? Во-первых, это поможет понять код вам и другим разработчикам. Зачастую понятно к чему относятся передаваемые данные в первом и втором аргументах. Однако вам понадобится феноменальная память, чтобы помнить все последующие имена аргументов для всех существующих функций в R. Во-вторых, что более важно, это позволит избежать досадных ошибок.
Если вы не используете именные аргументы, то R автоматически сопоставит аргументы с параметрами в том порядке, в котором вы их передали. Например, в приведенном ниже примере, первое значение die будет присвоено переменной x, второе значение 1 будет присвоено size.
> sample(die, 1)
[1] 2
Чем больше аргументов вы будете передавать, тем больше становится вероятность расхождения порядка передачи аргументов. В результате, значения могут быть переданы не тем аргументам. Именованные аргументы исключают такие ошибки. R всегда корректно присвоит значение именному аргументу, вне зависимости от порядка в котором они следуют.
> sample(size = 1, x = die)
[1] 4
Выборка с восстановлением
Если вы установите size = 2, то вы почти смоделировали броски игральных костей. Перед тем как запускать этот код подумайте минуту, что же не так?
sample вернет два числа, одно для каждой игральной кости:
> sample(size = 2, x = die)
[1] 5 3
Я сказал «почти» потому, что этот метод работает немного не так, как мы того ожидаем. Если мы запустим код выше несколько раз, то заметим, что второе значение никогда не будет совпадать с первым, что значит мы никогда не сможем выбросить две тройки или две шестёрки. Что происходит?
По умолчанию, sample осуществляет выборку без восстановления. Чтобы разобраться, что же это означает, представьте, что sample размещает все значения die в урне (корзине). Затем sample произвольным образом достаёт из корзины значения один за одним для построение выборки. После того как sample использовал выбранное значение, назад оно не возвращается и не может быть повторно использовано. Поэтому, если в первый раз выпало значение 6, то во второй раз оно уже не сможет выпасть; 6 больше нет в корзине.
Побочным эффектом такого поведения является зависимость последующих бросков от предыдущих. В настоящем мире, однако, когда вы бросаете пару игральных костей, каждая кость не зависит от других. Если на первой игральной кости выпадает 6, то это не препятствует выпадению 6 и на второй игральной кости. Вы можете воссоздать такое поведение в sample просто передав дополнительный аргумент replace = TRUE.
> sample(die, size = 2, replace = TRUE)
[1] 1 1
Аргумент replace = TRUE изменяет работу функции sample. Наш первоначальный пример с корзинками является хорошим способом показать принцип работы sample с заменой / восстановлением и без. sample с заменой после выбора произвольного значения из корзины возвращает его обратно. В результате мы добились нужного эффекта.
Выборка с восстановлением это простой способ создавать независимые случайные выборки (бла-бла-бла...). Каждое значение в вашей выборке будет выборкой размером 1, которая не зависит от других значений. Правильный способ моделировать бросок пары игральных костей:
> sample(die, size = 2, replace = TRUE)
[1] 6 4
Можете себя похвалить; вы только что реализовали свою первую симуляцию на R! У вас теперь есть метод для моделирования броска игральной кости. Если вы хотите сложить выпавшие значения игральных костей, то можете просто передать результат работы sample в функцию sum.
> dice <- sample(die, size = 2, replace = TRUE)
> dice
[1] 3 3
> sum(dice)
[1] 6
Что произойдет, если вы вызовете dicе несколько раз? Сгенерирует ли R новую пару значений для каждого броска? Давайте попробуем:
> dice
[1] 3 3
> dice
[1] 3 3
> dice
[1] 3 3
Нет. Каждый раз, когда вы вызываете dicе в R, в качестве результата будут выведены те значения, которые однажды были сохранены в этом объекте.
Однако, было бы логично иметь объект, который был бы в состоянии при каждой симуляции броска генерировать новую пару значений. Вы можете это реализовать написав свою собственную R функцию.
Пишем свои собственные функции
Вспомним, что у вас уже есть работающий код на R, который моделирует бросок двух игральных костей:
> die <- 1:6
> dice <- sample(die, size = 2, replace = T)
> dice
[1] 2 5
Вы можете перепечатать этот код в консоль R каждый раз, когда хотите выполнить новый бросок игральных костей. Однако, это достаточно странный способ. Было бы гораздо удобней использовать этот код единожды в нашей функции и затем её вызывать. Этим мы сейчас и займемся. Мы собираемся написать функцию roll, которую вы сможете использовать для симуляции броска виртуальной игральной кости. Когда вы закончите, функция будет работать следующим образом: каждый раз при вызове roll(), R будет возвращать сумму значений двух выброшенных игральных костей.
> roll()
> 8
> roll()
> 3
> roll()
> 7
Функции могут показаться чем-то магическим и причудливым, однако они не более чем тип объекта в R. Функции содержат не данные, а код. Этот код хранится в таком формате, который позволяет его повторно использовать в других программах.
Конструктор функции
Каждая функция в R состоит из трёх основных частей: имени, тела, списка аргументов. Чтобы написать собственную функцию вам понадобиться создать три эти части и сохранить их в объекте с помощью функции function():
my_function <- function() {}
function создаст функцию из любого R кода, который вы разместите между открывающей и закрывающей фигурными скобками. Например, вы можете перенести весь ваш предыдущий код броска игральной кости в функцию:
> roll <- function() {
+ die <- 1:6
+ dice <- sample(die, size = 2, replace =T)
+ sum(dice)
+ }
После открытия фигурной скобки командная строка R будет ожидать ввода оставшихся команд до тех пор, пока не найдет закрывающую фигурную скобку функции.
Не забудьте сохранить результат функции function в R объект. Этот объект теперь станет функцией. Чтобы воспользоваться новой функцией введите имя объекта, открывающую и закрывающую круглые скобки:
> roll()
[1] 7
> roll()
[1] 10
> roll()
[1] 11
Вы можете считать скобки после имени объекта триггером, который запускает код внутри объекта на выполнение. Если же вы введете имя функции без скобок, то R покажет вам непосредственно код хранимый в объекте функции:
> roll
function() {
die <- 1:6
dice <- sample(die, size = 2, replace =T)
sum(dice)
}
Код, который вы поместили в функцию называется телом функции. Когда происходит выполнение функции в R, R выполнит весь код, который находится в теле функции и вернет значение, которое будет вычислено на последней строке. Если на последней строке никакое значение не возвращается, то значит и ваша функция ничего не вернет.
Вот код, который отобразит результат после выполнения на последней строке:
> dice
> 1 + 1
> sqrt(2)
А вот код, который не отобразит результаты после выполнения на последней строке:
> dice <- sample(die, size = 2, replace = TRUE)
> two <- 1 + 1
> a <- sort(2)
Заметили разницу? Эти строки кода не возвращают значение в командную строку; они сохраняют значения в объекте.
Аргументы
Что было бы, если бы мы удалили одну строку из нашего кода и переименовали переменную die в bones:
> roll2 <- function() {
+ dice <- sample(bones, size=2, replace=T)
+ sum(dice)
+ }
Если теперь вызвать функцию roll2, то вы получите сообщение об ошибке. Для корректной работы функции нужен объект bones, но такого объекта не существует:
> roll2()
Error in sample(bones, size = 2, replace = T) : object 'bones' not found
Вы можете передать bones в качестве аргумента функции roll2. Для этого необходимо указать имя аргумента в круглых скобках в объявлении функции:
> roll2 <- function(bones) {
+ dice <- sample(bones, size = 2, replace = TRUE)
+ sum(dice)
+ }
Теперь функция roll2 будет работать в том случае, если вы передадите ей bones. Вы можете воспользоваться этим для того, чтобы выбрасывать различные типы игральных костей.
Запомните, что мы бросаем две игральные кости:
> roll2(1:4)
[1] 5
> roll2(1:6)
[1] 8
> roll2(1:20)
[1] 12
Обратите внимание, что при вызове roll2 будет по-прежнему возвращать ошибку, если не передавать значения аргументу bones.
> roll2()
Error in sample(bones, size = 2, replace = TRUE) :
argument "bones" is missing, with no default
Можно предотвратить появление этой ошибки при подобном вызове, указав аргументу bones значение по умолчанию. Сделать это можно следующим образом:
> roll2 <- function(bones = 1:6){
+ dice <- sample(bones, size = 2, replace = TRUE)
+ sum(dice)
+ }
Теперь вы можете спокойно вызывать функцию roll2 симулирующую бросок двух игральных костей:
> roll2()
[1] 8
> roll2(1:100)
[1] 82
Вы можете передавать своим функциям неограниченное количество аргументов. Для этого необходимо перечислить их имена через запятую между круглыми скобками при объявлении функции. При каждом запуске функции, R автоматически заменит имя аргумента значением, которое было передано для него. Если никакого значения передано не было, то R воспользуется значением по умолчанию.
Подводя итоги, function используется для объявления собственных функций в языке R. Код функции помещается между двумя фигурными скобками. Аргументы указываются после имени функции через запятую между двумя круглыми скобками.
После того как вы написали свою функцию, R будет воспринимать её как и любую другую функцию. Только представьте насколько это полезно и удобно. Вы когда-то пробовали создавать новую функцию для Excel и добавить её на панель с меню? Или новый тип анимации в качестве новой опции в PowerPoint? Когда вы работаете с языком программирования, то всё это вам становится доступно. Во время обучения языку R вы научитесь создавать новые, настраиваемые, воспроизводимые инструменты для любых случаев. В 3 части мы подробнее рассмотрим функции.
Запомните:

Скрипты
Продолжение следует…
Комментарии (14)

lxsmkv
14.01.2018 21:47Вкратце, компьютеры дают вам научную суперсилу! Однако, чтобы научиться пользоваться этими суперсилами на полную, вам необходимо будет обзавестись навыками программирования.
В первую очередь нужно научиться понимать инструменты статистики. Как бездарно порой используют статистику в управлении проектами, напоминает о том, что компьютер мозги не заменит.

savvadesogle
15.01.2018 10:02Что лучше использовать для работы с данными: Python или R?
Условие 1: Python хорошо известен
Условия 2: ни R ни Python не известны
Буду благодарен, если еще и объясните почему лучше выбрать R вместо Python.OlegUV
15.01.2018 10:32+1я писал и на Python и на R. Пожалуй, самый ощутимый, интегральный, плюс R — скорость получения конечного презентабельного результата, от простенького статичного отчёта до аккуратного интерактивного сайта, с таблицами, графиками и прочим. По такой скорости R превосходит Python, наверно, в разы.
CheY
15.01.2018 14:17Ещё иногда важным отличием оказывается то, что под R больше узкоспециализированных пакетов, которые сложно найти не только под Python, но и под другие языки. Зачастую это просто обвязка вокруг проверенных временем C/C++-библиотек.
Например, однажды надо было придумать алгоритм, завязанный на распределении пользователей по территории, что подразумевало использование равномерного разбиения нашего голубого шарика на ячейки. Нашёлся хороший проект DGGRID, который берёт на себя всю математику. И именно для R тут же нашёлся пакет, который даёт интерфейс к DGGRID + визуализацию через gdal и shapefile'ы. То есть переход между шагами «найти инструмент» и «проверить алгоритм» был максимально плавным и незаметным: 10 минут на чтение сайта DGGRID, 5 минут на поиск пакета для R, ещё 10 минут на чтение доки к нему, и вот я уже гружу тестовый датасет и смотрю на красивую визуализацию карты.
Ну, а про кучи различных статистических узкоспециализированных или малопопулярных методов, реализованных в пакетах к R (например, equipercentile equating), я уж молчу. Тут скорее сказывается то, что R более привычен тем, чей фокус смещен от программирования в науку. Поэтому такие пакеты в CRAN появляются быстрее любого другого языка. Почему так вышло — не знаю.
А вот со всем, что касается собственно программирования и написания не просто скриптов, а реально работающих и поддерживаемых программ, у R дела обстоят гораздо скромнее. Во многом тут сказывается куча legacy и незаточенность под современные нужды. Также есть особенности самого языка, которые могут быть непривычны тем, кто использует более традиционные языки — им просто может быть сложно понимать ваш код. Советую сразу после знакомства с основами идти читать про пакеты от tidyverse, например. Они очень приятно преображают R и делают написание кода на нём гораздо приятнее. И, к сожалению, именно про написание не скриптов, а реальных программ и организации их, про язык R как язык программирования книг я не встречал.
lxsmkv
15.01.2018 20:30Для своей дипломной (4 года назад) я использовал R для сбора данных с веб страниц (web scraping), и последующей обработки данных. Так вот, для скрейпинга это не подохдящий инструмент, медленно и ненадежно. Сегодня я бы заюзал для сбора данных python, а статистичекий анализ делал бы в R.

WTYPMAH
15.01.2018 22:24По ссылке хорошая инфографика для сравнения R и Python — у каждого свои плюсы и минусы. Как и в любом сравнении любых языков :)
www.datacamp.com/community/tutorials/r-or-python-for-data-analysis
Alexey_mosc
15.01.2018 13:33Я пишу на R в области data science. За несколько месяцев получается разработать прототип сервиса, переписывание полного функционала которого на продакшн-ЯП заняло бы годы. Плюс симпатичная презентация результатов (markdown, shiny, ggplot2).
nikolajbezcelovecnyj
15.01.2018 22:24Интересно а будет ли вариант в читаемом виде? ну там fb2, epub или на худой конец pdf
IP-human
15.01.2018 22:24R очень хороший язык, но несколько необычный. Это лучший язык в мире по критерию количества кода на получаемый результат. То есть, на один напечатываемый символ вы получаете больше всего результата, как в виде (обработки) данных так и в виде видимого (графического) результата. Пакетов в нем многие тысячи, которые буквально делают всё-всё. Он является проблемно ориентированным языком, нацеленный на переработку данных статистики и любых вычислений с массивами данных, а также представлений их в графическом виде, которых тысячи, и которые настраиваются под любой вкус.
Необычность R заключается в том что это довольно старый язык, вроде 70-х годов, но при этом его можно назвать чисто объектным, по существу там есть только объекты и ничего кроме объектов. Нет типов данных как таковых, есть внутренние режимы хранения данных и объединения объектов в иерархические структуры. Нет скалярных переменных, а все переменные являются векторными, поскольку все вычисления в нем векторные. Вектор основная структура в нем, причем все значения в нем могут быть именованы, вообще, всё в нем может быть иметь имя и любые другие атрибуты что вы пожелаете им приписать. Вектора объединяются в матрицы и массивы, столбцы и строки могут быть именованы. Все структуры хранятся в списках (картежах), таблица данных является по существу списком векторов.
Будучи объектным языком, однако он появился до еще распространения объектно-ориентированного подхода, поэтому там очень необычная реализация основанная на чисто функционально-ориентированном интерфейсе. По существу весь синтаксис там из C, плюс идеи работы с массивами из Алгола. Функция это тоже просто объект, который можно менять на лету, по существу все функции в нем это замыкания всегда. Вы никак не можете указывать никаких прототипов классов, объектов, интерфейсов (кроме набора параметров функций). Функции все полиморфны, параметры можно передавать любого типа, она сама с ними разбирается. С++ понятия класс в нем нет, атрибут класс это введенная надстройка для вызова генерик-функций (методов категориального класса), аналогов C++ темплэйтов.
Хотя язык полностью встроено поддерживает объектно-ориентированную триаду (инкапсуляция, полиморфизм, наследование), достигает он это настолько необычным способом, в основном потому что в его синтаксисе нет способа описать тип переменной (поэтому это даже не то что строготипизированный язык, а даже не слабо типизированный. то есть вообще н типизированный), но при этом также нет способа и нарушить правила этой триады. Чистые сложные объекты в языке используются редко, но например стэк и ggplot2 являются сложными объектами; основным понятием в нем является простая функция. Именно на основе функций создаются объекты, ведь каждая функция в нем автоматом является конструктором объекта, поэтому достаточно из нее вернуть структуру (список) и он становится объектом, при этом методы объекта там передаются как и другие члены объекта. Поскольку у переменных нет понятия типа, то присвоение к приватным члены класса, это внутренние переменные функции-конструктора, происходит специальным знаком присвоения "<<-". Да, необычное свойство это что в языке аж четыре знака присвоения (=,<-,->,<<-)! Так же необычным свойством, что доступ к членам объектов происходит не всем привычной точкой, когда язык создавался это было еще не общепринято, а знаком $ или сложным оператором доступа к элементам списка [[ ]]. Точка в нем это обычный символ, который может быть в любом имени, который используется в надстройке генерик-функций классов. В языке есть все концепции правящие бал до 2000-х годов, например создание произвольных бинарных операторов. Замечательным лаконичным свойством является то, что все языковые конструкции рассматриваются как операторы, и поэтому все конструкции блоков {}, условных и циклических выражений возвращают значение, которое можно использовать в комбинации с другими операторами. Отсюда в языке нету такого тернарного сишного оператора ?:, его просто заменяет более читабельная конструкция if()else.
В общем, язык замечательный, хотя он изначально создавался как чисто интерпретирующий, сейчас в нем есть JIT-компилятор. Осваивается мгновенно, хотя требует некоторого приспособления к его образу мысли, в том числе в том что вся работа в нем может быть только через тестирование (во встроенной среде) и чтение встроенных справок (поскольку типизированности нет, функции могут принимать любой набор нетипизированных параметров, полный полиморфизм, отсюда следствие, есть полный набор встроенных экзамплов и демок по любой теме), зато в результате очень быстрое программирование с написанием малого количества кода, но большим количеством результата.WTYPMAH
18.01.2018 10:02+1Далеко не со всем согласен…
его можно назвать чисто объектным,
R поддерживает около 7-ми парадигм, включая функциональную, процедурную и ООП.
Нет типов данных как таковых, есть внутренние режимы хранения данных и объединения объектов в иерархические структуры
Типы данных есть и их целых 7 — numeric, integer, complex, logical, character, NA, NULL. И каждый из этих типов может быть представлен в базовой структуре вектора (включая сам вектор, matrix, array, data.frame, list) + дополнительные структуры factor и formula + расширяемые структуры различных пакетов.
всё в нем может быть иметь имя и любые другие атрибуты что вы пожелаете им приписать
Т.к. базовая структура вектор, то атрибуты хранятся на его уровне — отдельный элемент вектора не может иметь свой отдельный аттрибут, он просто индексируется из векторного атрибута.
Вы никак не можете указывать никаких прототипов классов, объектов, интерфейсов (кроме набора параметров функций)
В объектах класса S4 вы можете все это сделать — определить слоты, прототипы и т.д.
Ну и дальше много чего написано исходя из предположения, что нет системы типов, хотя она по факту есть, но динамическая. Кстати возможна реализация и строго-типизированной системы через S4-объекты.
Shtucer
Серьёзно? Вы планируете публиковать всю книгу здесь, на Хабре?